基于時變濾波經驗模態分解和SSA-LSSVM的變壓器內部機械故障診斷方法*
2023-09-22 04:52:00張甜瑾邵心悅陳子豪吳金利
電機與控制應用 2023年9期
臧 旭, 張甜瑾, 邵心悅, 楊 嵩, 陳子豪, 吳金利
(1.國網江蘇省電力有限公司鎮江供電分公司,江蘇 鎮江 212000;2.河海大學 能源與電氣學院,江蘇 南京 211100)
0 引 言
變壓器作為電力系統的關鍵設備,對保障供電可靠性具有重要意義。然而,隨著其投入運行的時間越來越長,變壓器內部往往會產生鐵心松動等潛伏性機械故障[1],故障一旦累積嚴重,將會危及電力系統的整體安全。因此,對變壓器內部的機械故障進行診斷,對防止電力系統可能發生的危害有非常重要的意義。目前,振動分析法已經被大量運用于變壓器鐵心或繞組等內部機械故障的檢測中,成為當下的研究熱點[2-4]。
變壓器振動信號是通過吸附于箱體表面的振動傳感器采集來獲得,該方法實施簡單、操作方便,且采集的全過程不會影響變壓器的運行狀態。變壓器鐵心受磁致伸縮效應的影響產生振動,而鐵心發生松動故障等缺陷時變壓器的振動狀態必定發生改變[5-6],因此利用振動分析法進行變壓器內部機械故障診斷是可行的。
文獻[7]利用變壓器振動信號頻譜變化以辨別鐵心與繞組的故障,指出變壓器高次諧波分量主要由鐵心振動產生,而基頻同時受鐵心與繞組振動影響,其為判別鐵心和繞組等變壓器主要故障奠定了理論基礎。文獻[8]將經驗模態分解(EMD)運用于可分離變壓器鐵心與繞組各自的振動信號中,所得分離信號頻譜與正常狀態下一致,取得了一定的效果。文獻[9]將集合經驗模態分解(EEMD)應用于變壓器振動、聲音信號的模態分量峭度特征提取上,試驗結果表明該方法提取出的特征量能夠反映時域和頻域特征,有利于變壓器狀態的判定。上述方法均在各自場合實現了一定效果,但是EMD方法本身存在模態混疊的問題, 這會影響信號處理的準確性,EEMD方法雖然引入白噪聲減弱了模態混疊的嚴重程度,但是可能會掩蓋掉原始信號的某些信息。雖然目前已有相關改進方法,但是仍存在較多不足。文獻[10]提出采用互補集合經驗模態分解提取氣體絕緣金屬封閉輸電線路(GIL)機械故障特征的方法,雖然解決了EEMD中白噪聲遺留的問題,但仍存在分解過剩的問題。時變濾波經驗模態分解(TVFEMD)是在EMD的基礎上引入時變濾波技術的一種信號處理方法,該方法能夠提高頻率分離性能,解決EMD過程中產生的模態混疊問題。
麻雀搜索算法作為新型智能優化算法,具有出色的尋優能力,已成功應用于故障診斷、狀態評估和預測等方面。文獻[11]采用麻雀搜索算法優化了詳盡可能性模型(ELM)的輸入權值并隱藏層節點偏置,提高了油浸式變壓器故障診斷模型的準確率。
綜上所述,本文提出一種基于時變濾波經驗模態分解和麻雀搜索算法優化最小二乘支持向量機(SSA-LSSVM)的變壓器內部機械故障診斷方法,對變壓器鐵心不同程度的松動進行診斷識別。首先,采用TVFEMD對振動信號進行分解獲取多個模態分量(IMF);然后,選取相關性最優的IMF分量,并計算其樣本熵;進一步地,利用所求熵值構建特征向量集;最后,利用SSA優化的LSSVM模型實現變壓器鐵心內部潛伏性機械故障的診斷。試驗結果表明,相較于傳統的故障分類模型,所提方法能夠更加準確地識別變壓器內部的機械故障和不同故障程度。
1 基于TVFEMD的變壓器振動信號特征提取
1.1 TVFEMD基本原理
TVFEMD算法設計時充分考慮了EMD方法的不足,其最大特點在于采用非均勻B樣條近似作為時變濾波器從而完成篩選過程,同時,充分利用瞬時幅度和頻率信息,自適應地設計了局部截止頻率[12],TVFEMD方法具體實現過程如下。
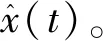
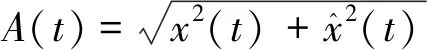
(1)
瞬時相位可表示為

(2)
考慮由N個窄帶分量組成的多分量信號可表示為
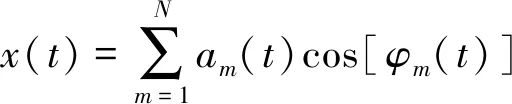
(3)
式中:am(t)為第m個分量瞬時幅值;φm(t)為相位。
當N=2時,可得:
cos[φ1(t)-φ2(t)]
(4)
a1(t)a2(t)·cos[φ1(t)-φ2(t)])}+
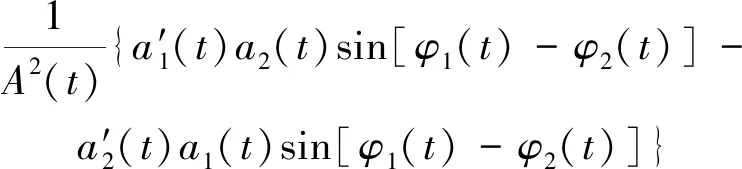
(5)
假設a1(t)和a2(t)的變化速度比cos[φ1(t)-φ2(t)]慢得多,那么當cos[φ1(t)-φ2(t)]= -1時,A(t)取最小值。此時的關系為
cos[φ1(tmin)-φ2(tmin)]=-1
(6)
將式(6)代入式(4)和式(5)中,可得:
Amin(t)=|a1(tmin)-a2(tmin)|
(7)
φ′(tmin)A2(tmin)=
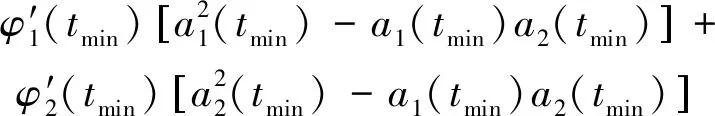
(8)
又由于:
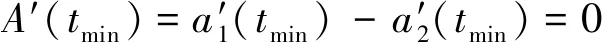
(9)
通過聯立式(6)~(9),可解得a1(tmin)、a2(tmin)、φ1(tmin)和φ2(tmin);同理,類似的方法可求得a1(tmax)、a2(tmax)、φ1(tmax)和φ2(tmax)。隨后,通過插值可以求得a1(t)、a2(t)、φ1(t)和φ2(t),但求解上述方程十分困難。因此,利用下列方法進行替代,具體為

(10)
因為a1(t)和a2(t)波動較小,所以b1(t)和b2(t)可依次利用A({tmin})和A({tmax})插值得到。假設a1(t)≥a2(t),則
a1(t)=[β1(t)+β2(t)]/2
(11)
a2(t)=[β2(t)-β1(t)]/2
(12)
進一步地,令:

(13)
聯合式(5),可得:
η1(tmin)=φ′(tmin)A2(tmin)
(14)
η2(tmax)=φ′(tmax)A2(tmax)
(15)
h1(t)和h2(t)可通過φ′({tmin})A2({tmin})和φ′({tmax})A2({tmax})插值求得。有如下表達式:
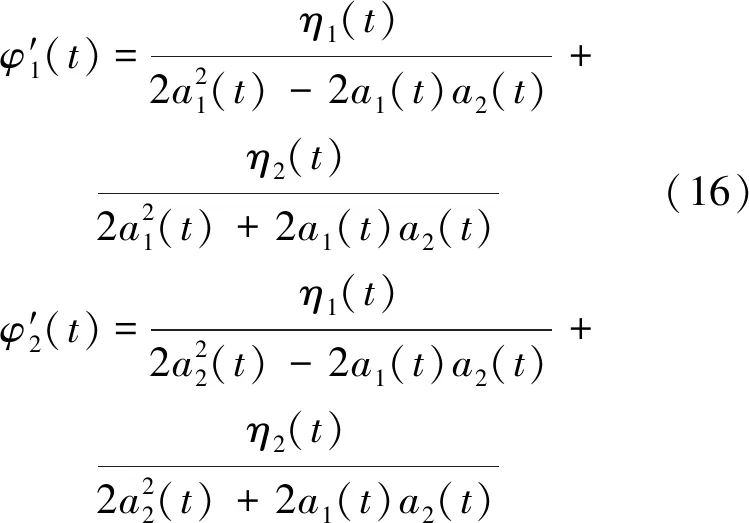
(17)
可得局部截止頻率為
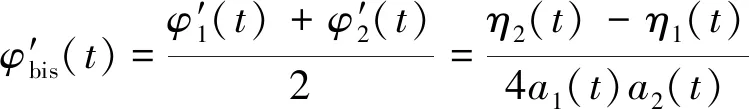
(18)
由此可得:
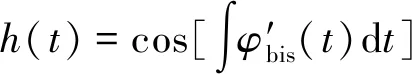
(19)
對x(t)應用該B樣條近似濾波器,即將h(t)極值點作為節點,近似結果為m(t)。該方法設置的終止條件為

(20)
式中:BLoughlin(t)為瞬時帶寬;φavg(t)為瞬時平均頻率。
當θ(t)≤ξ時,x(t)即為一個IMF分量;否則,將x(t)-m(t)重新按照上述過程進行試驗直到符合條件為止。
1.2 相關系數法
相關系數可以衡量分解后的信號與原始信號的相關性,從而剔除相關性較小的信號分量。首先計算原始信號自相關函數與各IMF分量自相關函數的相關系數,然后確定閾值標準,選取相關性最大的IMF分量,從而提高特征向量建立的準確性。相關系數計算表達式如下
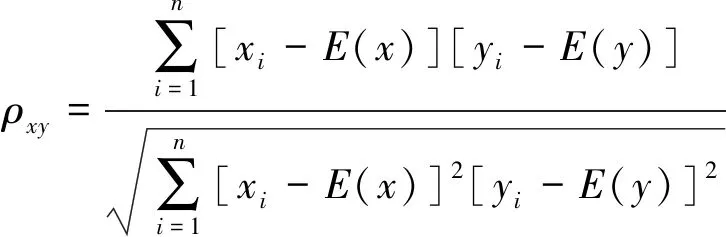
(21)
式中:E(x)、E(y)為兩種信號x、y的均值。
相關性最大的閾值標準求解表達式為
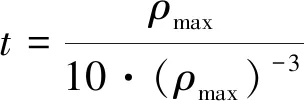
(22)
式中:ρmax為相關系數的最大值。
1.3 樣本熵
樣本熵常用于衡量系統時間序列的復雜度[13]。通過對經TVFEMD后的變壓器振動信號的各IMF分量分別計算樣本熵,可定量描述每種故障程度下變壓器的振動特征。計算樣本熵的具體步驟如下。
(1) 將時間序列分為n-m+1個序列:
Xi(t)=[xi(t),xi+1(t),…,xi+m-1(t)]
(23)
式中:m為維數,1≤i≤n-m+1;n為序列數據個數。
(2) 計算dij=max|xi+k(t)-xj+k(t)|,該式表示Xi(t)與Xj(t)中元素距離的最大值,其中0≤k≤m-1。
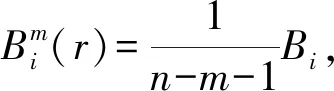
(4) 維數為m+1時,重復步驟(a)~(c)。
(5) 所求樣本熵可表示為
SampEn(m,r,n)=lnφm(r)-lnφm+1(r)
(24)
2 基于麻雀搜索算法優化的LSSVM算法
2.1 麻雀搜索算法
麻雀搜索算法(SSA)啟發于麻雀覓食與逃避捕食者的行為,是一種新型智能優化算法[14]。下面簡要介紹SSA的具體過程。
在麻雀群體中,每只麻雀的行為大致可分為下列情況。
(1) 充當發現者,搜索食物;
(2) 充當跟隨者,追蹤某發現者;
(3) 偵察危險,若危險則棄食。
假設共有N個麻雀,每次迭代計算的過程中,選取P個位置最優的麻雀作為發現者,其他的(N-P)個則作為跟隨者。
在d維解空間中,每只麻雀位置為X=(x1,x2,…,xd)。每代發現者的位置更新公式為

(25)
式中:Xi,j為第i個麻雀第j維信息,j=1,2,…,d;t為當前迭代次數;itermax為最大迭代次數;α∈(0,1];R2∈[0,1]為安全值;ST∈[0.5,1]為預警值;Q為標準正態分布隨機數。
每代跟隨者位置更新公式為
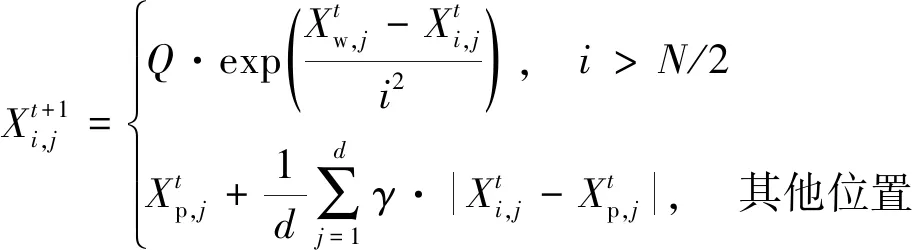
(26)
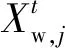
每代中隨機選取10%~20%個體意識到危險,位置更新公式為
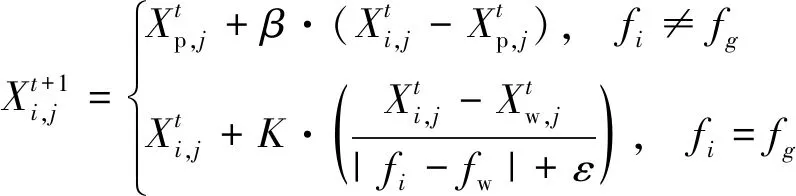
(27)
式中:b為標準正態分布的隨機數;K∈[-1,1];e為較小數,防止分母為零;fi為當前麻雀的個體適應度值;fw為最差位置的適應度值;fg為最佳位置的適應度值。
因此,SSA尋優的步驟即先將種群分為發現者和跟隨者,再根據式(27)~式(29)更新種群位置,在此基礎上更新當前全局最差和最佳個體的位置,在達到最大迭代次數前重復上述步驟,直至最后獲得最佳位置。
2.2 SSA-LSSVM診斷模型
LSSVM是一種廣泛使用的機器學習算法,主要用于模式分類識別等領域[15-18]。該算法是傳統支持向量機(SVM)的一種擴展,其將支持向量機中松弛變量的不等式約束改為等式約束,從而可以通過求解線性方程組的方式來求解LSSVM的值。其中,具有徑向基函數(RBF)核函數的LSSVM的兩個參數——正則化參數c和核函數參數s對SVM模型的性能影響很大,直接關系到最終的分類精度。因此,本文選擇將SSA應用于LSSVM的c、s參數尋優中,以獲得最佳的模型識別精度。采用SVM診斷過程中的準確率作為適應度函數可表示為
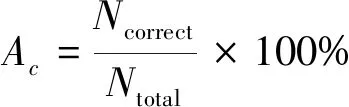
(28)
式中:Ncorrect為識別正確的樣本數;Ntotal為全部樣本個數。
3 基于TVFEMD和SSA-LSSVM的變壓器內部機械故障診斷模型
本文所提基于TVFEMD和SSA-LSSVM的變壓器內部機械故障的診斷步驟具體如下。
(1) 采集變壓器振動信號,并將振動信號數據分為訓練樣本數據與測試樣本數據兩類;
(2) 對原始變壓器振動信號進行降噪處理,并利用所提TVFEMD方法對處理后的振動信號進行分解;
(3) 獲取分解得到的模態分量;
(4) 利用相關系數法選取與原始振動信號相關性最高的IMF,并求其樣本熵值;
(5) 利用步驟(4)所得到的樣本熵值構建特征量;
(6) 根據上述步驟(1)~步驟(5)分別得到訓練樣本與測試樣本的特征向量,并將其輸入SSA-LSSVM模型中進行識別診斷。
綜上所述,所提變壓器內部機械故障診斷方法的流程圖如圖1所示。
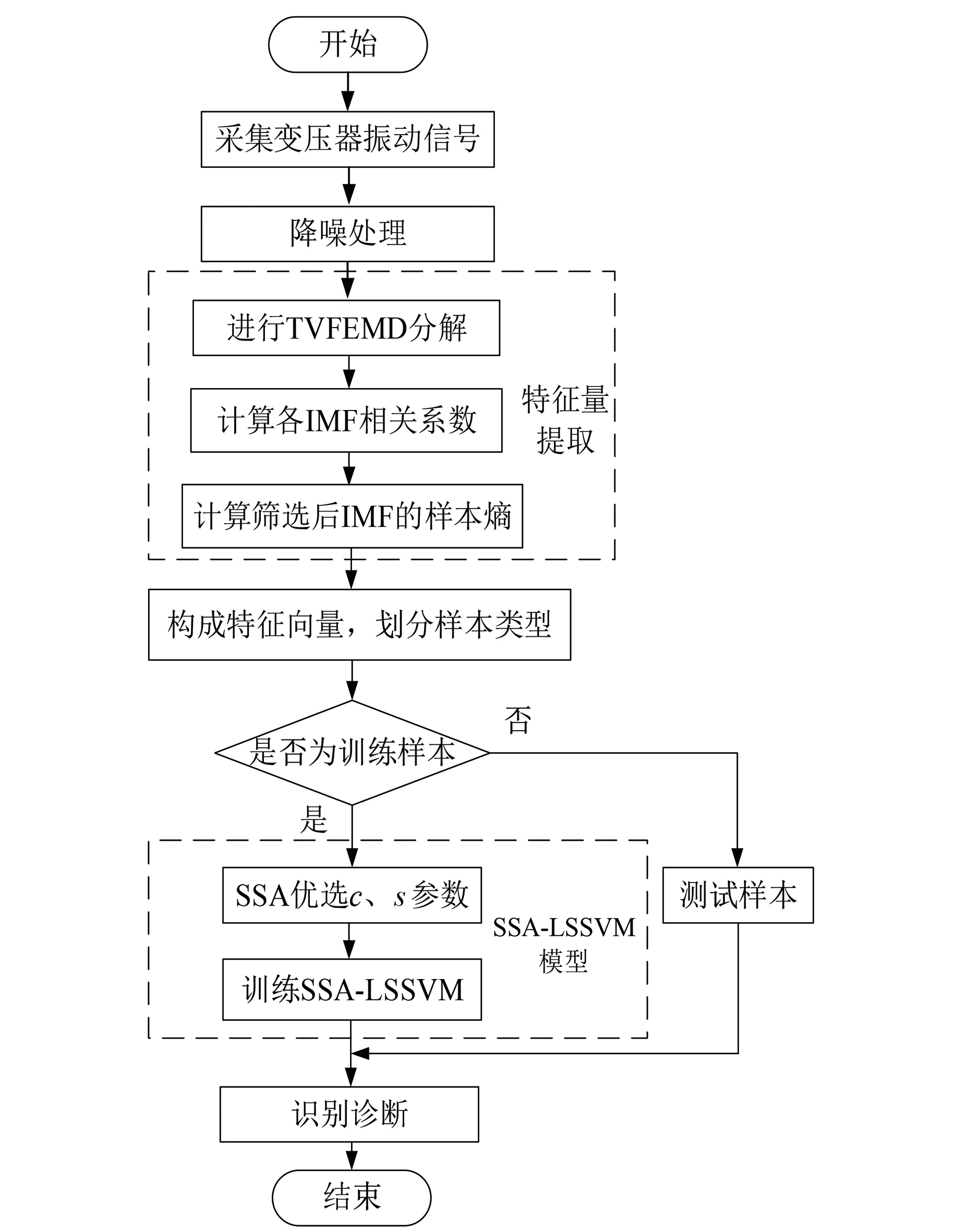
圖1 故障診斷流程圖
4 試驗結果驗證與分析
本文對一臺10 kV變壓器進行鐵心松動故障模擬試驗。具體地,通過改變變壓器鐵心松動程度來模擬變壓器內部機械狀態的變化,將采集到的振動信號用于后續的故障診斷過程中。試驗時將三個振動傳感器置于變壓器油箱頂部,分別記為測點1、測點2和測點3,具體測點位置如圖2所示。需要說明的是,傳感器采用型號為1A212E的IEPE型壓電式加速度傳感器,采樣頻率為20 kHz。

圖2 變壓器測點布設圖
在試驗開始前,對變壓器進行抽油、吊罩操作,通過改變鐵心的壓緊螺母預緊力來實現鐵心松動故障過程的模擬。本試驗主要模擬了正常狀態、鐵心松動25%狀態和鐵心松動50%狀態這三種典型故障狀態。整體試驗原理示意圖如圖3所示。調壓器輸入380 V額定電壓,變壓器空載運行,振動傳感器采集的數據經采集儀被計算機接收。其中,采集儀的型號為DH5922D。
以測點2位置的數據為例,本文測得的變壓器三種不同狀態的振動信號如圖4所示。
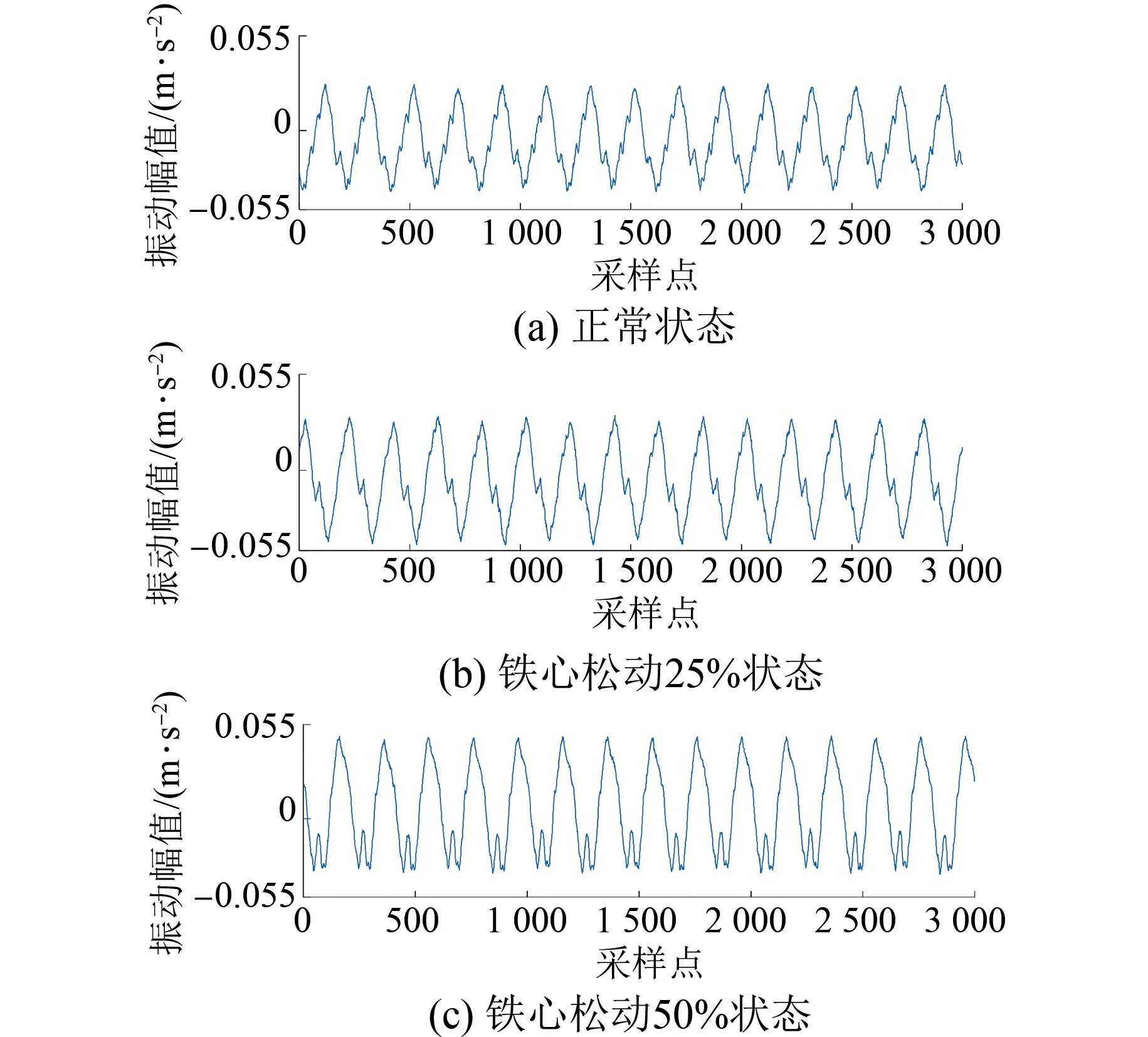
圖4 變壓器不同狀態2號測點位置振動信號
本文進一步利用TVFEMD對上述三種變壓器的振動信號分解,所得IMF分量如圖5所示。需要說明的是,為了充分有效地提取振動信號特征信息,避免出現模態混疊和分解過剩的情況,本文選擇模態分量個數為6。
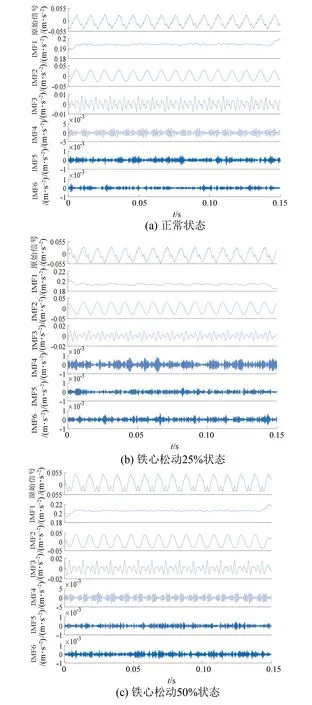
圖5 TVFEMD分解圖
為避免特征冗余,采用相關系數法確定分解后所得6層IMF分量與原始信號的相關性。變壓器三種狀態下每個IMF分量的相關系數值如表1所示。值的注意的是,表1中的狀態1、狀態2和狀態3分別表示正常狀態、鐵心松動25%狀態和鐵心松動50%狀態。
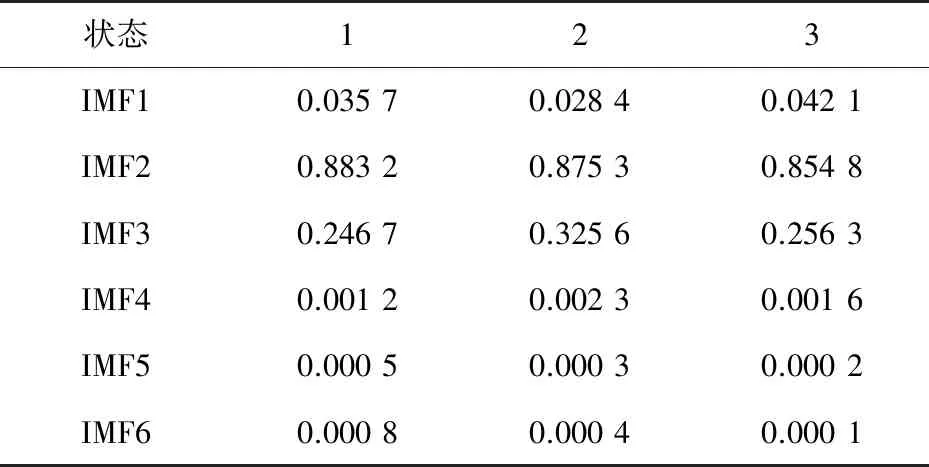
表1 三種狀態下每個IMF分量相關系數值
根據式(24)得到閾值標準為0.060 8,由表1可知,6層IMF分量中只有IMF2與IMF3符合標準,其余分量應在特征提取時被剔除。因此,計算各狀態下IMF2與IMF3的樣本熵,計算結果如表2所示。
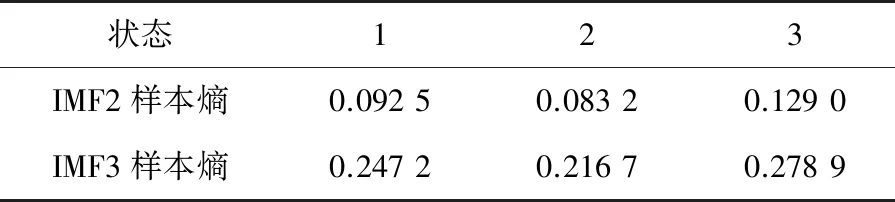
表2 IMF2與IMF3樣本熵計算結果
由此,即構成一組特征向量,該特征向量由IMF2與IMF3的樣本熵組成, 將其分別輸入到LSSVM、PSO-LSSVM和SSA-LSSVM模型中進行分類識別。其中,訓練樣本為200組,測試樣本為120組。各模型的測試分類準確率如圖6所示,其中狀態1、狀態2和狀態3分別表示正常狀態、鐵心松動25%狀態和鐵心松動50%狀態。
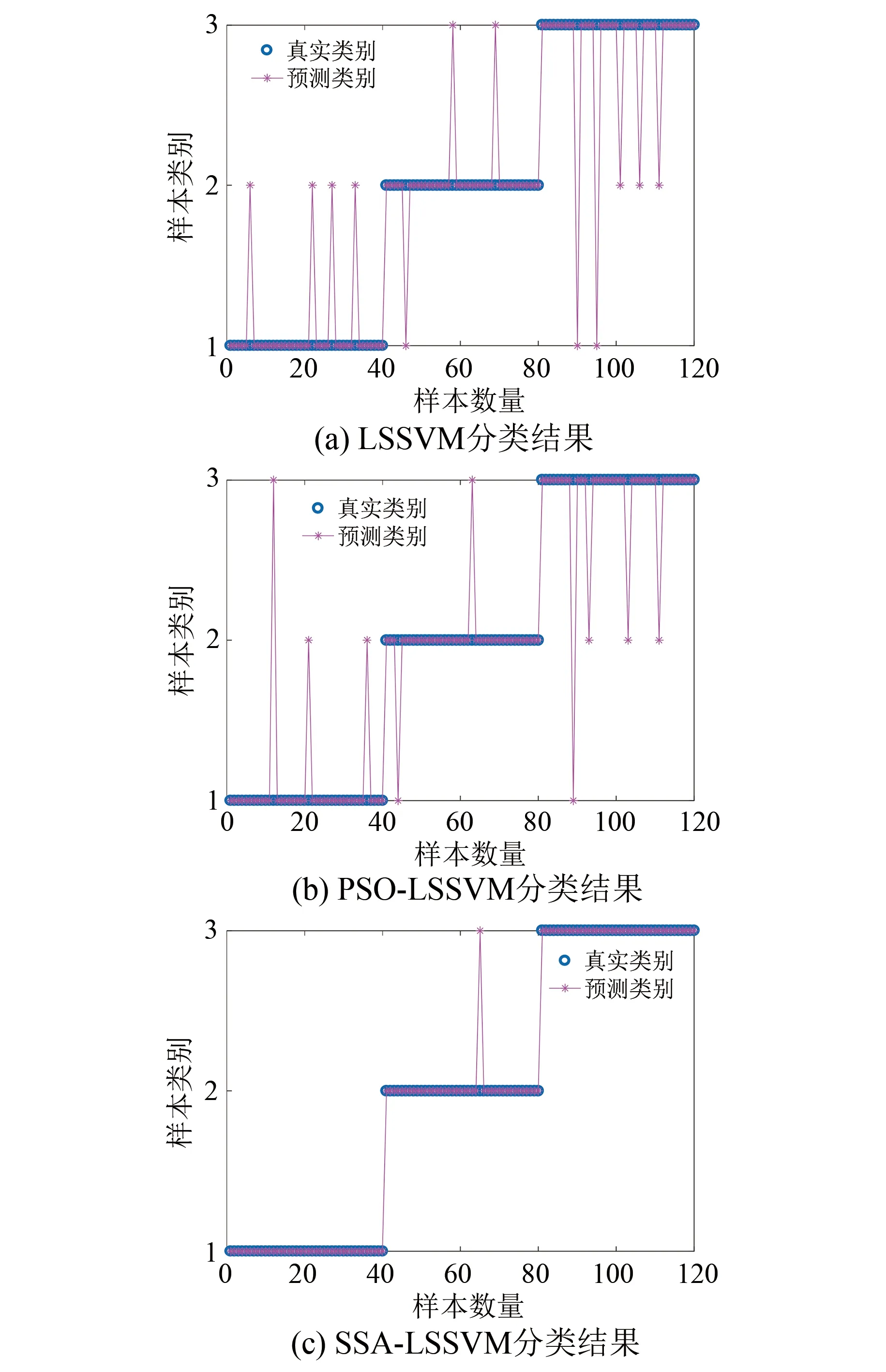
圖6 不同方法的分類結果
由圖6可知,傳統LSSVM模型與PSO-LSSVM模型在識別三類變壓器鐵心狀態特征時均出現了識別錯誤的情況,而SSA-LSSVM模型僅出現了一次識別出錯。這表明本文所提方法的分類識別效果更優。
為了進一步說明本文所提方法的優越性,計算了上述三種識別模型在識別變壓器鐵心松動故障時的單一診斷準確率和整體診斷準確率,其結果如圖7所示。
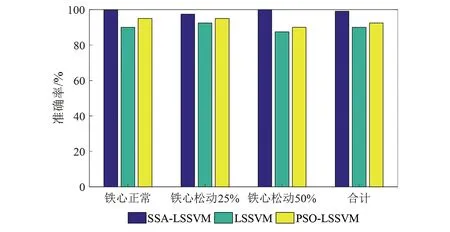
圖7 三種識別模型診斷準確率的對比
由圖7可知,文中所提基于TVFEMD和SSA-LSSVM的變壓器內部機械故障診斷方法對各程度的鐵心松動故障均有較高的診斷準確率,且所提算法的診斷準確率均高于其他算法。整體來看,基于SSA-LSSVM模型的診斷準確率達到99.17%,而其他兩種對比模型的診斷準確率分別為90%和92.5%。這也表明SSA對LSSVM的參數優化效果更好,構建的故障診斷模型準確率更高,可為變壓器檢修策略的制定提供相應指導。
5 結 語
本文提出了一種基于TVFEMD和SSA-LSSVM的變壓器內部機械故障診斷方法,得到的結論如下。
(1) 所提TVFEMD特征提取方法能夠準確有效地提取變壓器振動信號所蘊含的狀態特征,解決了傳統經驗模態分解中存在的模態混疊和分解過剩的問題;
(2) 利用相關系數法確定了與原始振動信號相關性最大的IMF分量,有效避免了特征冗余現象,提高了所建特征向量集的有效性和準確性;
(3) 構建的SSA-LSSVM診斷模型具有出色的診斷能力,對變壓器內部潛伏性故障的診斷準確率達到了98%以上,實現了高診斷準確率的診斷目標。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08
通信電源技術(2018年3期)2018-06-26 06:33:30
現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38
通信電源技術(2016年3期)2016-03-26 07:13:46
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
