基于遺傳算法的礦山裝備制造企業排程優化
2023-09-24 06:51:54李濤
礦山機械 2023年9期
關鍵詞:生產
李 濤
中信重工機械股份有限公司 河南洛陽 471039
隨 著全球制造業市場的競爭越來越激烈,如何提高生產計劃排程效率成為礦山裝備制造企業提高市場競爭力的重要手段[1]。該類型企業生產的產品屬于重型裝備,擁有復雜的產品結構和生產流程,具有生產周期長、重復率低、單件小批量等特點,對生產系統的柔性要求較高。同時,不同零部件需要多個工廠協作來完成生產,進一步增加了生產管理的難度。因此,該類型企業需要利用先進的 APS 系統來輔助不同分廠進行生產計劃排程,同時實現對幾十甚至上百個訂單的生產排程,以達到提前預警和按期交貨等目標[2]。
生產計劃排程是礦山裝備制造企業生產管理的核心環節,影響生產效率和客戶滿意度。通過基于遺傳算法的排程優化研究,可以有效解決承制工廠 (生產分廠) 零部件的工序、車間和資源調度等問題,以此提高生產計劃排程的效率和精度,降低成本和時間浪費[3]。此外,該研究可以為礦山裝備制造企業生產管理提供技術支持和決策依據,提升企業的市場競爭力。
1 研究內容和目標
礦山裝備制造企業目前多采用以訂單為驅動的生產模式,對生產系統的柔性要求較高,故需要利用先進的 APS 系統來輔助不同承制工廠 (生產分廠) 進行生產計劃排程。分廠級的排程算法需要嵌入到 APS系統中[4],根據企業生產管理部門分配的生產任務和給定的關鍵節點計劃,并考慮多個訂單的零部件生產工單結構順序、物料可用性以及上游工序預期完成時間等信息,解決零部件工序的車間和資源調度等問題。根據不同工單的工序、優先級、來料準備等特點,將各個工單的各個工序合理地排布在可行的車間、資源和時間節點,在滿足交貨期的同時,降低成本,提高運營和生產效率。該算法將公司級主生產計劃和年度滾動計劃中確定下來的關鍵時間節點,在組批算法中得到的合成工單作為輸入,并與其緊密銜接,從而實現在規定的時間跨度和交貨期內,對關鍵工單排程。
初級 APS 系統的排程算法是將工單工序的排程工作拆分為了車間級別和資源級別,并進行優化。此類算法雖然可以做到減少跳線,并能在滿足父子工單關系的條件下,對工序進行合理安排,但也存在一定的不足:將所有工單一起考慮,問題規模太大,難以對影響生產交期較大的關鍵路徑上的工單進行優先滿足;2 個層級算法的基本邏輯都是基于簡單的規則形式進行實現,因此排程方案具有很大的局限性。
基于遺傳算法的優化排程算法針對關鍵路徑工單進行生產排程,再基于此對非關鍵路徑工單進行排程,同時考慮了工單之間的父子關系、工單內部的順序、車間之間的較少跳線、關鍵節點等,對“工單—父子關系—工序—車間—設備—時間節點”進行了排程和優化。與此同時,該算法基于企業整體的信息集成,融合企業內部多部門和內外部協同生產節點信息的更新以及物料達成等信息,以實現對企業內外多部門的生產協同進行整體統籌。
2 遺傳算法
2.1 基本原理
遺傳算法是由 John Holland 于 20 世紀 70 年代提出的一種基于種群的元啟發式算法[5-6]。該算法依據自然選擇和自然遺傳學機制進行隨機全局搜索,在搜索過程中自動獲取和積累有關搜索空間的知識,采用概率化的尋優方法,不需要確定的規則就能自動獲取和指導優化的搜索空間,自適應地控制搜索過程。
遺傳算法主要利用遺傳操作 (交叉、變異等) 對群體中的個體進行全部或部分替換,不斷適應環境,進化到更優的狀態。與其他優化算法相比,遺傳算法適用范圍廣,具有全局尋優能力、高可靠性、高并行性等優點,被廣泛應用于組合優化、機器學習、人工智能、神經網絡等領域[7-8]。
2.2 遺傳算法框架
遺傳算法的基本思想是模擬生物進化過程搜索最優解,因此,其過程包括個體的選擇、交叉、變異等要素,形成了遺傳算法的框架。其中,個體表示可行解決方案;種群是個體的集合。遺傳算法主要通過不斷對種群中的個體進行操作,來逐漸搜索最優解。
遺傳算法的框架為[9]:
(1) 初始化,隨機生成一組初始個體,即種群;
(2) 適應度評價,對種群中的每個個體的成本、效益和適應度等進行評價;
(3) 選擇操作,根據適應度大小,選擇一定數量的個體作為父代;
(4) 交叉操作,隨機選擇一對父代,利用交叉算子實現基因交換,產生新的個體;
(5) 變異操作,對新的個體進行一定的概率變異操作,產生新的解決方案;
(6) 替換操作,根據適應度,選擇新個體和舊個體進行替換,形成新的種群;
(7) 結束判斷,達到指定迭代次數或滿足精度要求時終止,返回最優解。
2.3 基本操作
2.3.1 編碼和解碼
在遺傳算法中,個體需要進行編碼和解碼。編碼是將決策變量轉換成目標函數值,計算機可處理的二進制表達式的過程。不同的編碼方式適用于不同類型的函數問題,例如,二進制編碼適用于多目標函數優化;浮點編碼適用于連續性變量的優化;排列編碼適用于旅行商問題等。解碼是指將二進制編碼重構為原始問題的過程。
2.3.2 選擇操作
選擇操作是根據適應度大小,選擇一部分個體作為父代,這里的適應度通常定義為目標函數值或評價函數值。優秀的個體被選中,不良的個體被淘汰。常見的適應度選擇方法有輪盤選擇、錦標賽選擇、最小競標賽等。
2.3.3 交叉操作
交叉操作是指將選出的父代進行重組操作,產生新的個體。重組的方式常見有單點交叉、多點交叉、均勻交叉、基因重組等,交叉方式也根據問題的性質進行調整。對于連續性變量問題,可以采用基于結果隨機化的交叉方式,比如 BLX-α 交叉;對于多目標問題,則可以采用向量交叉,實現多目標優化。
2.3.4 變異操作
變異操作是指在交叉操作后對個體進行一定概率的操作,產生新的解決方案。變異操作通常是單點變異,即隨機選擇一個基因位置,并改變其值。在實際應用中,變異率設置過大會導致算法陷入局部最優解,因此應該根據具體問題進行設置。
2.3.5 替換操作
替換操作是在交叉和變異操作后,根據適應度,選擇新個體和舊個體進行替換,形成新的種群。常見的替換方式有全替換、部分替換等。
2.4 遺傳算法的優缺點
遺傳算法作為一種常用的優化算法,其優缺點如下[10]。
2.4.1 遺傳算法的優點
(1) 可以尋找全局最優解,具有較強的全局尋優能力;
(2) 算法具有較高的可靠性,能夠避免局部最優解;
(3) 算法具有高度的并行性,可以利用并行處理技術進行優化;
(4) 算法適用范圍廣,可以用于多種類型的問題。
2.4.2 遺傳算法的缺點
(1) 遺傳算法的收斂速度相對較慢,需要較多的迭代次數;
(2) 在編碼、交叉、變異等操作中需要設置一系列參數,參數對算法效果影響較大;
(3) 操作不當時,遺傳算法也有可能造成早熟現象,即過早收斂到局部最優解。
3 排程優化
3.1 輸入信息
遺傳算法的輸入信息包括:
(1) 產品對應的物料信息;
(2) 資源及日歷信息;
(3) 需要生產的工單、工序和工藝信息,包括父子工單關系、工序順序以及工單的最早開始時間和最晚結束時間 (節點交期);
(4) 生產時間期量工序生產時間和提前期,換線時間,制造效率 (用于修正實際的制造時長);
(5) 物料供應鏈信息物料庫存、采購、到貨等信息;
(6) 生產計劃,包括公司級主生產計劃、年度滾動計劃中確定的關鍵時間節點;
(7) 工單、工序的預排車間信息,如有此信息,則基于此進行車間線體排程;
(8) 外協線體及其能力約束,可以為無限,對應外協無限產能概念。
3.2 排程算法框架
產品的生產時長主要取決于該訂單關鍵路徑上的工單生產時長。該部分工單的生產時間較長或其所占用關鍵的設備資源有限,如何對關鍵路徑上的工單進行生產排程是個重要問題。另外,除了關鍵路徑上的生產工單外,由于產品結構復雜且零部件繁多,故而也需要對所有的非關鍵路徑的工單進行排程。首先利用遺傳算法對關鍵路徑工單進行排程優化,然后考慮父子工單關系等約束,利用一定的規則對非關鍵路徑工單進行排程,分廠級 APS 排程算法框架圖如圖1所示。

圖1 分廠級 APS 排程算法框架Fig.1 Branch level APS scheduling algorithm framework
3.3 關鍵路徑工單排程
首先對不同訂單的關鍵路徑使用遺傳算法進行排程。
(1) 針對離散型裝備制造企業的排程,考慮父子工單關系以及工單內部的工序,設計合理的編碼規則;
(2) 考慮車間減少跳線以及資源設備在成本、時間、優先級等方面的權重考量,設計合理的解碼規則;
(3) 初始化種群;
(4) 設計合理的適應度函數,并對其進行計算,篩選出更優解;
(5) 對種群進行選擇、交叉、變異操作,產生下一代遺傳編碼;
(6) 重復以上過程,對排程結果不斷迭代優化,直到滿足條件,得到最終的排程優化結果。
3.4 非關鍵路徑工單排程
在關鍵路徑工單排程計劃的基礎上,基于優先級規則對非關鍵路徑工單進行啟發式的排程。同樣,也需要考慮工單的父子關系、工單內部的工序順序、工單工序的車間線體選擇、工單工序的資源設備選擇以及開始生產時間節點等內容。
根據離散型裝備制造企業生產組織方式,整個協同制造體系包括很多外部協同制造過程,包括工藝性和能力性外協,因此在以上排程算法和規則中,將外部協同制造作為一個車間線體 (該車間實際為一個虛擬車間,僅用于表示工單的外部協同制造),根據企業“無限產能”的理念,可以將該車間的產能設置為無限大,也可以設置一定的約束。
3.5 多訂單關鍵路徑工單生產排程算法
3.5.1 編碼規則
算法的關鍵點之一便是編碼規則。遺傳算法通過染色體的基因信息對索要決策的內容進行編碼。針對離散型裝備制造企業的生產排程,筆者提出了一個同時考慮父子工單以及工序的編碼方式。
首先,染色體中每個數字代表對應工單編號,如:工單 1、2、3 等,同一數字出現的次數代表該工單擁有的工序數量,而同一數字出現的先后順序則代表工單內部的工序順序。如圖2 所示,Oi,k表示第i個工單的第k道工序。從左至右,O3,1代表工單 3 的第1 道工序;O1,1代表工單 1 的第 1 道工序;O2,1代表工單 2 的第 1 道工序;O2,2代表工單 2 的第 2 道工序,以此類推。通過這種編碼方式即可實現工單內不同工序順序的排序。
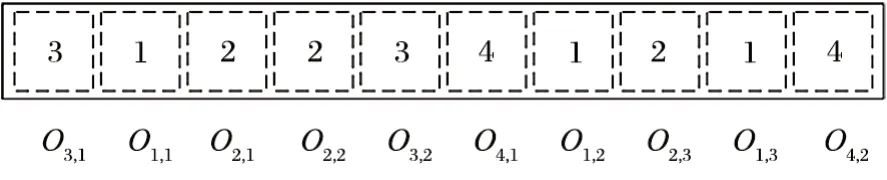
圖2 染色體示例Fig.2 Chromosome example
其次,在實際的生產過程中,必須滿足父子工單的順序關系。因此,本部分的染色體編碼規則可根據BOM 結構/工單樹中的父子工單關系,對訂單中多工單的加工順序進行調整。具體的,找到父子工單關系中最高層級的父工單,并以此作為染色體調整起點,依次向下一層級進行修復。修復的過程如下:對每一個父工單對應的工序節點進行檢查,若該父工單工序的右側存在子工單工序,則兩者交換,直到父工單的全部工序檢查完畢,順延至下一層級重復修復過程。以“1→4”為例,假設工單 1 是工單 4 的子工單,那么染色體的修復過程如圖3 所示。
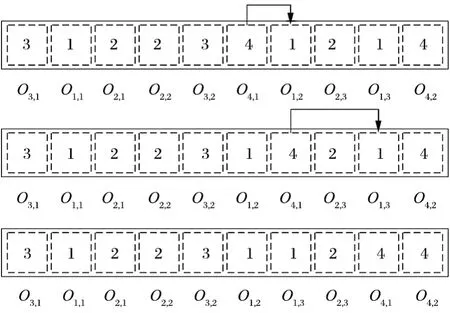
圖3 染色體修復過程Fig.3 Chromosome repair procedure
通過以上的編碼規則和調整修復過程,即可實現染色體工單內部工序順序以及父子工單關系的要求。
3.5.2 解碼規則
在種群解碼過程中,采用基于空閑時間段的主動調度工序解碼方法以獲得可行序列解,即新的待排序工序需要同時滿足車間分配、資源分配、以及考慮物料問題,在對已排序工序開工時間不產生影響的基礎上,根據當前機器空閑時間,安排至最早可開工的時間點。
3.5.3 車間分配
對工單中不同工序進行車間分配,總體目標是減少同一工單在不同車間之間的轉換,從而減少跳線時間和降低跳線成本。通過構建整數規劃模型的方法,以工單工序之間的跳線最小化為目標,對工單內部各道工序進行車間分配決策。模型參數包括各工單的工序以及對應的車間信息。對每一個工單運行一次分配決策,可完成對所有工單的車間預分配工作。
模型的目標函數為
式中:wi,i+1,m,n為工序i到工序i+1 之間,從車間m跳線到車間n的成本 (權重);yi,i+1,m,n為 0~1 決策變量,若為 1,則代表工序i到工序i+1 之間,從車間m跳線到車間n;xi,m為 0~1 決策變量,若為 1,則代表工序i分配到車間m內;xi+1,n為 0~1 決策變量,若為 1,則代表工序i+1 分配到車間n內。
第1 個約束用于保證每道工序只可能被分配到一個車間;第 2、3、4 個約束用于保證,只有當跳線真實發生的情況下,0~1 決策變量的值才為 1;第 5、6、7 個約束規定變量類型。
另外,也可在此模型中增加負荷平衡等因素和目標,即在對工單工序分配車間的過程中,考慮不同車間資源的負荷平衡,最小化跳線。
3.5.4 資源分配
在車間分配的基礎上,對車間的資源進行工序分配。采取啟發式基于資源權重規則的資源分配方法,將各項需要考慮的資源約束限制賦予不同的權重,并累加在一起,選取最合適該道工序的資源。各項資源約束限制有:加工成本最小、間隔時間最小、工作完工時間最小、該工作與前一道工序的工作的時間間隔最小、制造時間最少和占用負荷量最小的資源。
3.5.5 排程結果
基于染色體編碼,從左到右依次對工序進行排程。考慮前序工單完成時間+物料提前期 (若物料充足,則提前期為 0),逐一安排工序—車間—機器—時間點。甘特圖排程結果如圖4 所示。灰色部分代表物料沒有及時到達造成的提前期,通過以上解碼方法生成完整的排程結果。

圖4 甘特圖排程Fig.4 Gantt chart scheduling
利用企業集成的信息平臺,將不同訂單生產中與其他部門或外部協同工廠生產節點信息以及物料可用性等信息更新到模型中,從而得到與實際生產過程更為匹配的生產計劃排程方案。
3.5.6 適應度函數
遺傳算法中判別解 (染色體) 的好壞,是通過適應度函數的計算來實現。采用的函數計算規則如下:權重 (1)×生產成本+權重 (2)×最大完工時間+權重(3)×關鍵時間節點逾期懲罰項。
3.5.7 交叉、變異算子
交叉算子包括:①單點交叉,通過選取兩條染色體,在隨機選擇的位置點上進行分割并交換右側的部分,從而得到兩個不同的子染色體;②兩點交叉,是指在個體染色體中隨機設置了兩個交叉點,然后再進行部分基因交換;③多點交叉,是指在個體染色體中隨機設置多個交叉點,然后進行基因交換;④ 部分匹配交叉,保證每個染色體中的基因僅出現一次,通過該交叉策略在一個染色體中不會出現重復的基因。在交叉操作結束后,對染色體的可行性進行判斷,如果不可行,則進行修復。
變異算子包括:①將位翻轉突變應用于二進制染色體時,隨機選擇一個基因,其值被翻轉 (求補);②將交換突變應用于二進制或整數的染色體時,將隨機選擇 2 個基因并交換其值;③倒換突變應用后,將選擇一個隨機基因序列,并將該序列中的基因順序打亂 (或倒換)。在變異操作結束后,對染色體的可行性進行判斷,如果不可行,則進行修復。
3.6 基于規則的非關鍵路徑工單生產排程算法
在關鍵路徑工單已經排程完畢的基礎上,采用基于優先級規則的啟發式分配方法,再對非關鍵路徑工單進行相應的排程。
(1) 考慮父子工單將工單進行層級分解,從最高層級父工單開始進行工單分層,排程規則均從最高層級父工單開始,依次運行算法排程。
(2) 考慮同層級工單、工序順序選中當前層級的工單 (由于同層級,因此互不影響),根據優先級進行排序,并由高到低依次輸入算法。優先級的規定除人為指定外,可以將以下幾點進行自由組合并排出優先級:交貨期 (升序/降序)、工單最早開始時刻 (升序/降序)、工單人為優先級 (升序/降序)、工單制造數量(升序/降序)、工單最晚結束時間 (升序/降序)、工單余裕度 (升序/降序)、先到先做 (升序/降序)。
(3) 開始時間節點的排程方法對工序進行排程需要同時滿足車間分配、資源分配以及考慮物料問題,且對已排序工序開工時間不產生影響的基礎上,根據當前機器空閑時間,安排至最早可開工的時間點,即不存在可以加工任意可加工工序的空閑時間段。
4 結語
通過對遺傳算法進行介紹,重點闡述了遺傳算法在礦山裝備離散制造企業排程優化模型設計應用的研究過程。在研究過程中,進一步驗證了遺傳算法具有較高的求解效率和廣泛的適應性。
遺傳算法能夠尋找全局最優解,保證算法的全局尋優能力,但是在編碼、交叉、變異等操作過程中,需要設置一系列參數。其對參數的選取十分敏感,選取不合理,可能會影響算法的效果。此外,遺傳算法的收斂速度相對較慢,需要較多的迭代次數,因此算法在處理大規模或者高維度優化問題時比較困難。
在未來的理論研究和算法模型應用中,可以利用遺傳算法結合其他方法,如人工神經網絡、模擬退火等來進行研究,以進一步提升算法的效率與精度。另外,如何解決算法早熟現象和局部最優解等問題,值得進一步深入研究。
猜你喜歡
江蘇安全生產(2022年9期)2022-11-02 07:01:24
中國化肥信息(2022年7期)2022-08-31 01:28:54
山東冶金(2022年2期)2022-08-08 01:50:42
小學科學(學生版)(2020年10期)2020-10-28 07:52:12
中國化肥信息(2020年7期)2020-03-19 01:54:02
中國軍轉民(2017年6期)2018-01-31 02:22:28
消費導刊(2017年24期)2018-01-31 01:29:23
中國制筆(2017年2期)2017-07-18 10:53:09
現代企業(2015年4期)2015-02-28 18:48:06
汽車零部件(2014年11期)2014-09-18 11:57:16
