一種基于ARMv8架構CPU的算法加速方法
2023-09-27 08:16:06王靜嬌
雷達與對抗 2023年3期
孟 承,王靜嬌
(中國船舶集團有限公司第八研究院,南京 211153)
0 引 言
實時性是雷達信號處理領域一個不可忽視的指標,算法的運行速度是決定整個流程性能的關鍵。典型雷達的信號處理算法流程通常包括脈沖壓縮、動目標顯示、恒虛警率檢測[1-2]等。這些算法中包含一些基礎算法,例如三角函數、快速傅里葉變換、復數求模、拷貝等。目前,在ARMv8[3]架構的CPU平臺上,除了基本的標準庫外,還有一些開源的算法庫可以使用,如NE10、FFTW、OpenCV[4]等。這些庫函數可以滿足雷達信號處理開發人員對算法正確性以及精度的需求,但是在處理速度上,部分庫函數如三角函數、復數求模函數等在大規模流水使用時很難達到性能指標。
本文以基礎函數atan2為例,對其性能進行優化和硬件平臺實際測試,并與標準庫函數進行性能對比,其他函數按類似的優化方法,同樣可以得到性能提升。
1 加速原理介紹
(1)高速緩存
CPU內部與主存之間有一級、二級、三級高速緩存區,其特點是容量依次變大,運行速度依次降低,如圖1所示。
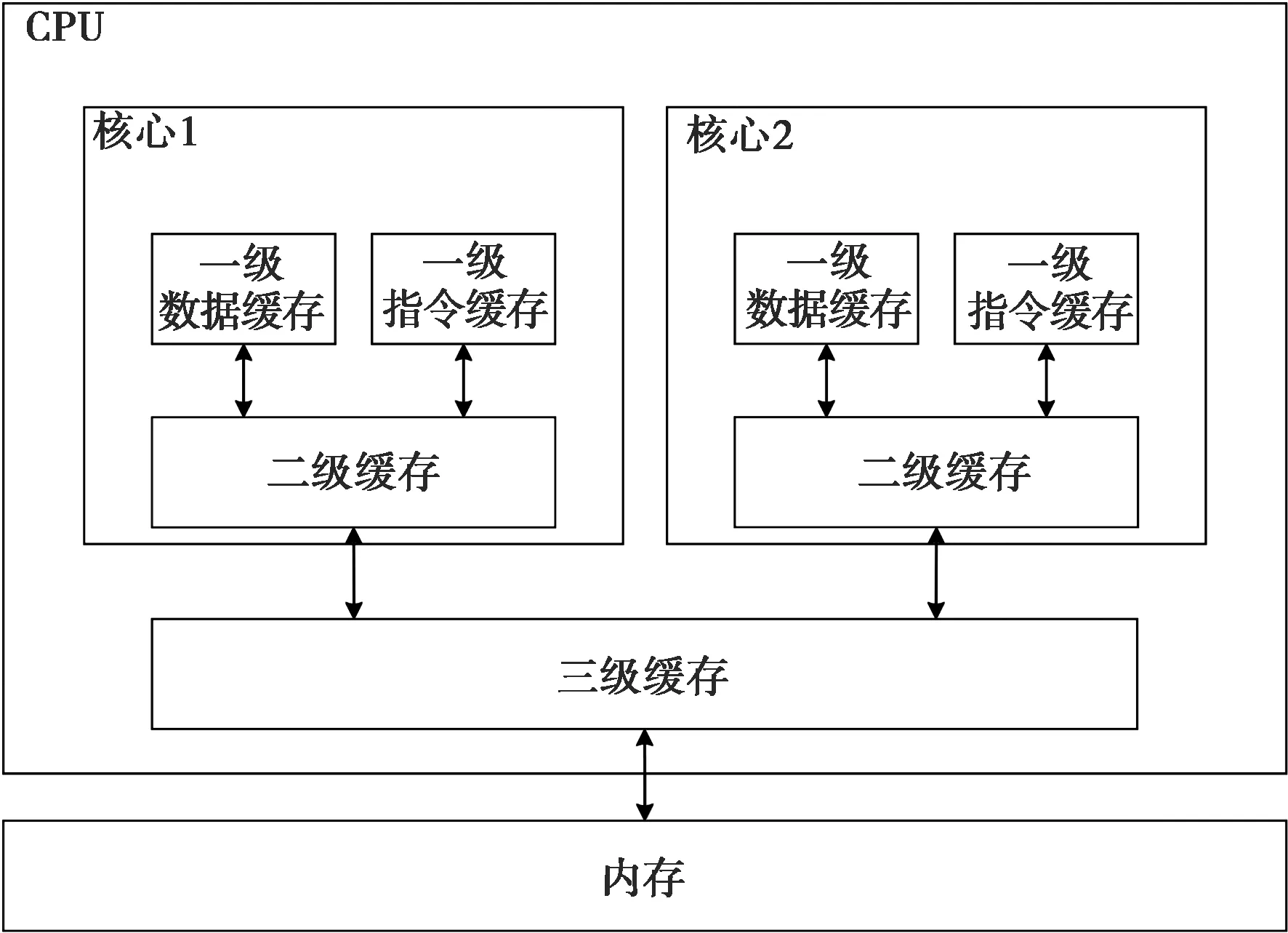
圖1 CPU緩存結構
如圖2所示,CPU整個工作流程包括取指、譯碼、執行和數據更新。由于CPU特殊的存儲結構,指令和數據都需要從內存中按照三級緩存、二級緩存、一級緩存依次搬運,數據的搬運最小單位為塊(通常為64字節),而不是以字節為單位[5]。CPU會先在最快的一級緩存中尋找需要的數據,如果沒有發現,則繼續往下一層尋找,以此類推。因此,針對CPU的性能加速可從以下幾個方面進行:單個指令周期內完成盡可能多的操作;數據按照內存位置順序處理,提高緩存命中率等。
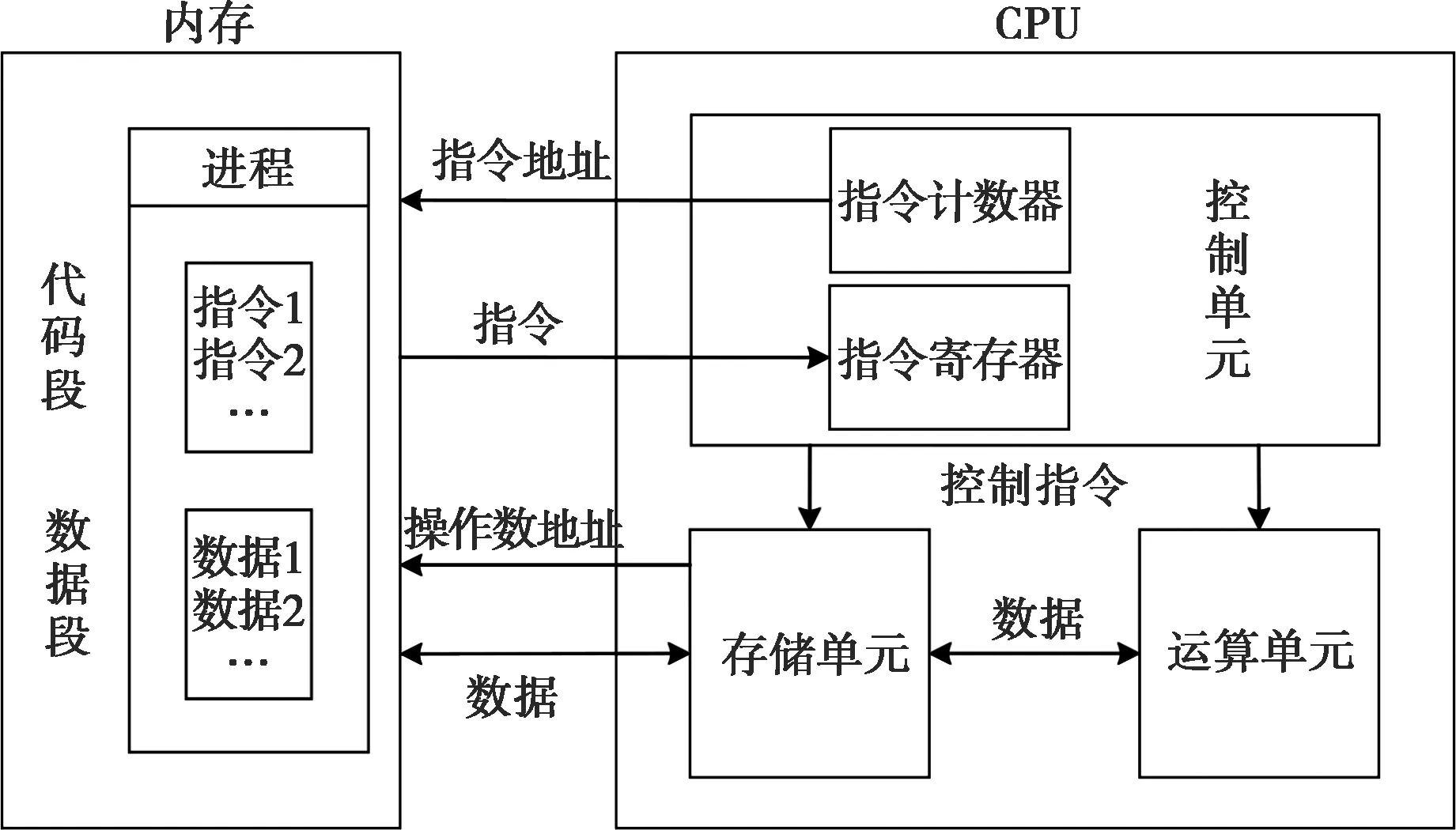
圖2 CPU工作流程
(2)Neon指令集
Neon指令集是單指令多數據(Single Instruction Multiple Data,SIMD)技術在ARM上的實現,利用同一個命令控制多個單元以達到并行處理的效果,提供了寬度為128 bit的向量運算。
針對“單個指令周期內完成盡可能多的操作”,本文基于Neon指令集,在ARMv8架構CPU上重新實現基礎函數,以達到加速效果。
2 算法具體設計
本文的atan2(y,x)功能實現基于OpenCV開源庫的算法流程進行Neon指令重寫,所有使用的函數皆由arm_neon.h頭文件[6]中定義,主要流程如圖3所示。
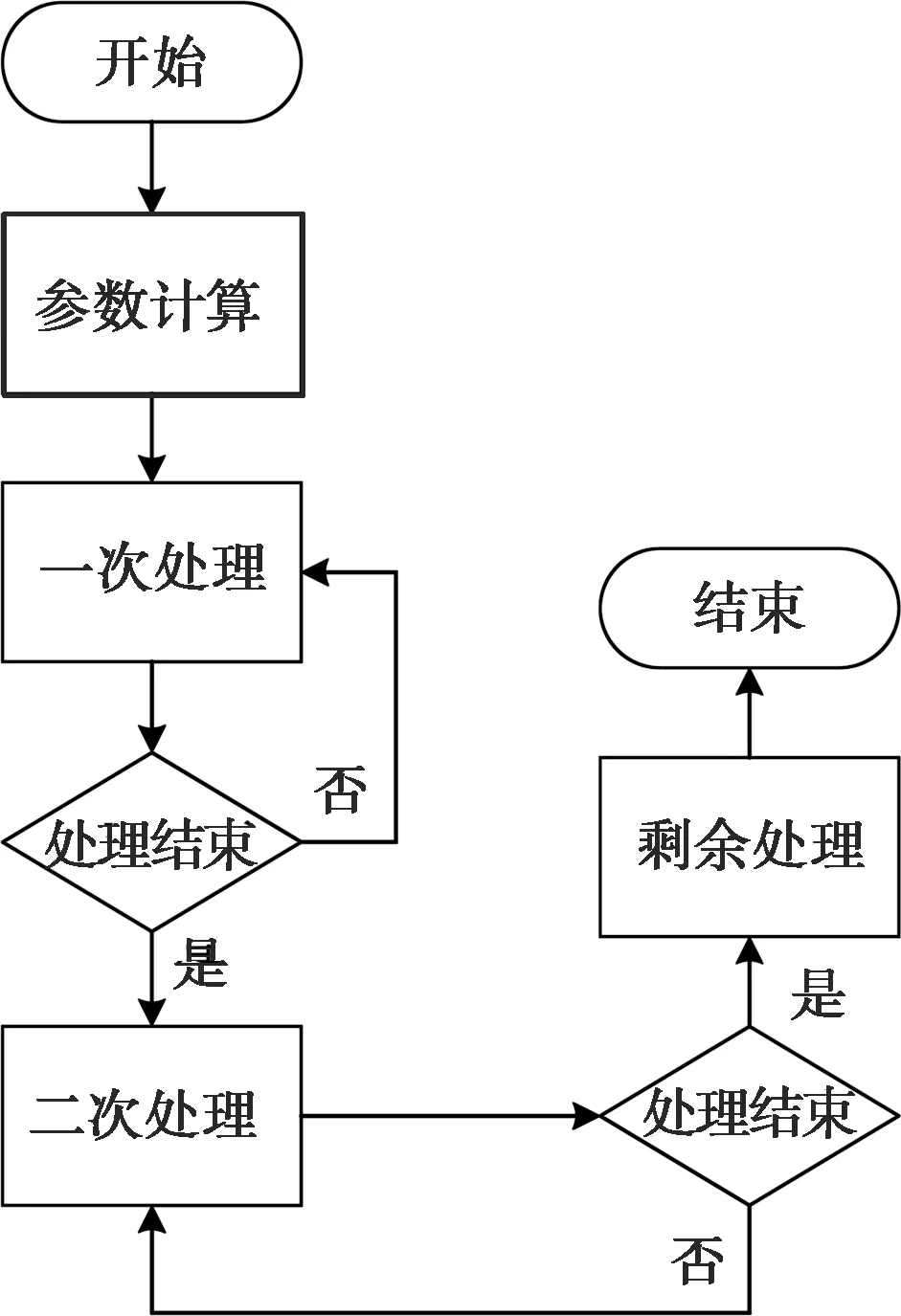
圖3 算法主要流程
(1)參數計算
ARMv8架構CPU提供了32個128 bit的浮點寄存器,Neon指令集可以操作整個寄存器。本算法首先計算一次處理和二次處理的次數。一次處理每次以4個浮點寄存器為單位進行計算,即每次對64字節的數據進行操作。例如對32位float類型的數據進行加法操作,調用8個浮點寄存器,一次操作即可完成對16個浮點數與另外16個浮點數的加法計算。二次處理每次以單個浮點寄存器為單位進行計算,即每次對16字節的數據進行操作,一次操作可以并行計算4個浮點數。最后計算一次處理和二次處理后的數據剩余量,將未處理的長度信息傳遞給剩余處理環節,一般來說在16個字節以內。
(2)一次處理
處理流程如圖4所示。

圖4 atan2處理流程
首先是元素導入,利用vld1q_f32函數將要計算的數據導入到預先按照數據類型聲明好的向量中,便于后續使用。
其次是條件語句轉換,條件跳轉是影響緩存不能命中的最大因素,所以這里考慮采用條件語句轉換,以增加Cache命中概率,進一步提升運行性能。本算法進行轉換時,先計算出各條件的系數(符合條件,系數值為1,否則為0),然后將各條件內的計算與其系數相乘,最后將所有的結果相加,例如條件A>B,可使用vcgtq_f32(A,B)函數計算該條件的系數(128位浮點寄存器的返回值由4組32 bit數據組成,符合條件時,每組數據所有bit位為1,否則為0);其次,使用vshrq_n_u32函數將系數返回值以組為單位右移31位,將返回值每組32 bit數據的大小轉換為1和0兩種,便于后續計算。
再次是相關計算,根據頭文件約束的函數對向量寄存器進行加減乘除等運算來復現算法流程,包括向量加(vaddq_f32)、向量除(vdivq_f32)、向量乘(vmulq_f32)等。
最后是元素導出,計算過程皆在向量寄存器中進行,臨時數據或者結果也保存在向量寄存器中。單次計算結束后需要使用vst1q_f32函數將向量中的結果數據導出至指定的數據空間。
(3)二次處理
二次處理的流程與一次處理相同,區別在于二次處理每次僅處理16字節的數據,寄存器使用量是一次處理的四分之一。
(4)剩余處理
在經過一次處理和二次處理后,剩余的數據長度一般不超過16字節,如果是32位float類型的數據,此時元素個數不超過4個。此時對剩余元素的計算直接使用OpenCV函數庫原本的c語言算法實現即可。
3 測試方案與結果分析
測試環境如表1所示。

表1 測試環境
本文對比測試方案如下:
(1)創建float類型的數據數組A、B和C,數據為-500到500的隨機數,測試時元素長度按照32/64/128/256/512/1 024/2 048/4 096/8 192依次設定;
(2)每次計算將數組中A和B的所有元素進行atan2(A,B)運算,結果保存至數組C中。每次時間測試進行10 000次,然后求每次計算的耗時平均值,單位為μs。分別測試兩種計算方式的耗時,一種為直接使用math.h中定義的atan2函數計算,另一種即本文使用neon指令集改寫的算法;
(3)選取1 024元素點的結果數據,分別將兩種方式計算得出的結果保存至文件,然后由matlab進行對比分析。
圖5為耗時對比圖,表2為具體測試數據。可以看出,經過本文算法改寫后,atan2函數的計算速度提升了1 000%左右。
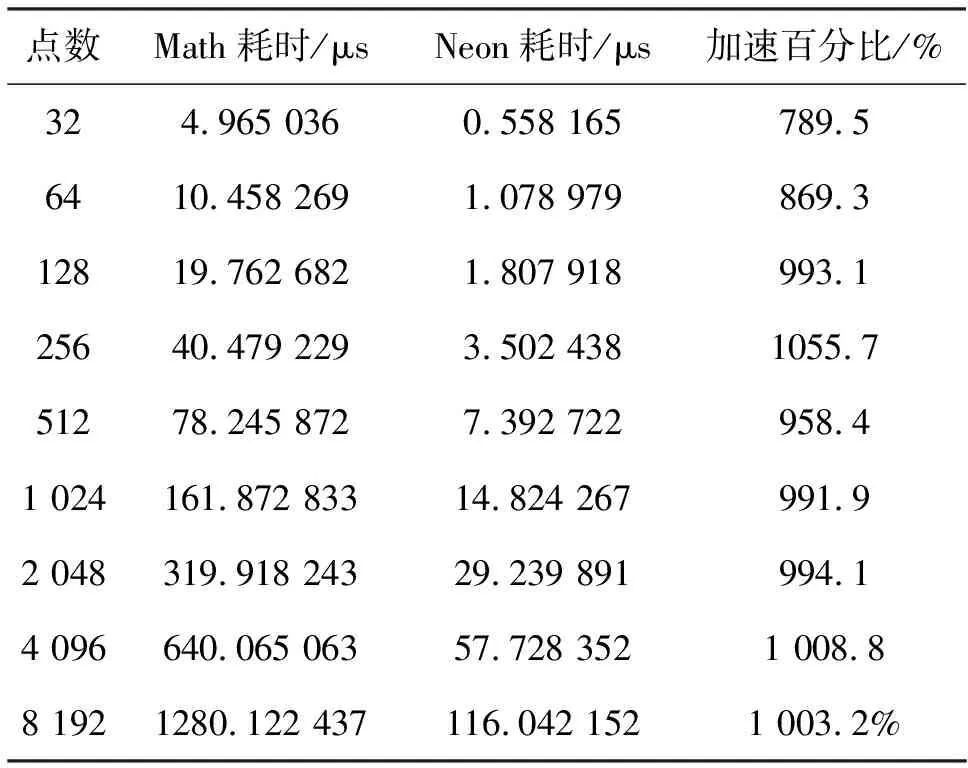
表2 耗時測試數據

圖5 atan2函數耗時對比
由圖6可以看出,本文改編的atan2算法與c標準庫中的atan2函數計算結果基本一致。通過計算結果差值與c標準庫計算的值作比,得出誤差百分比,如圖7所示,可看出結果誤差比值不超過0.025%。
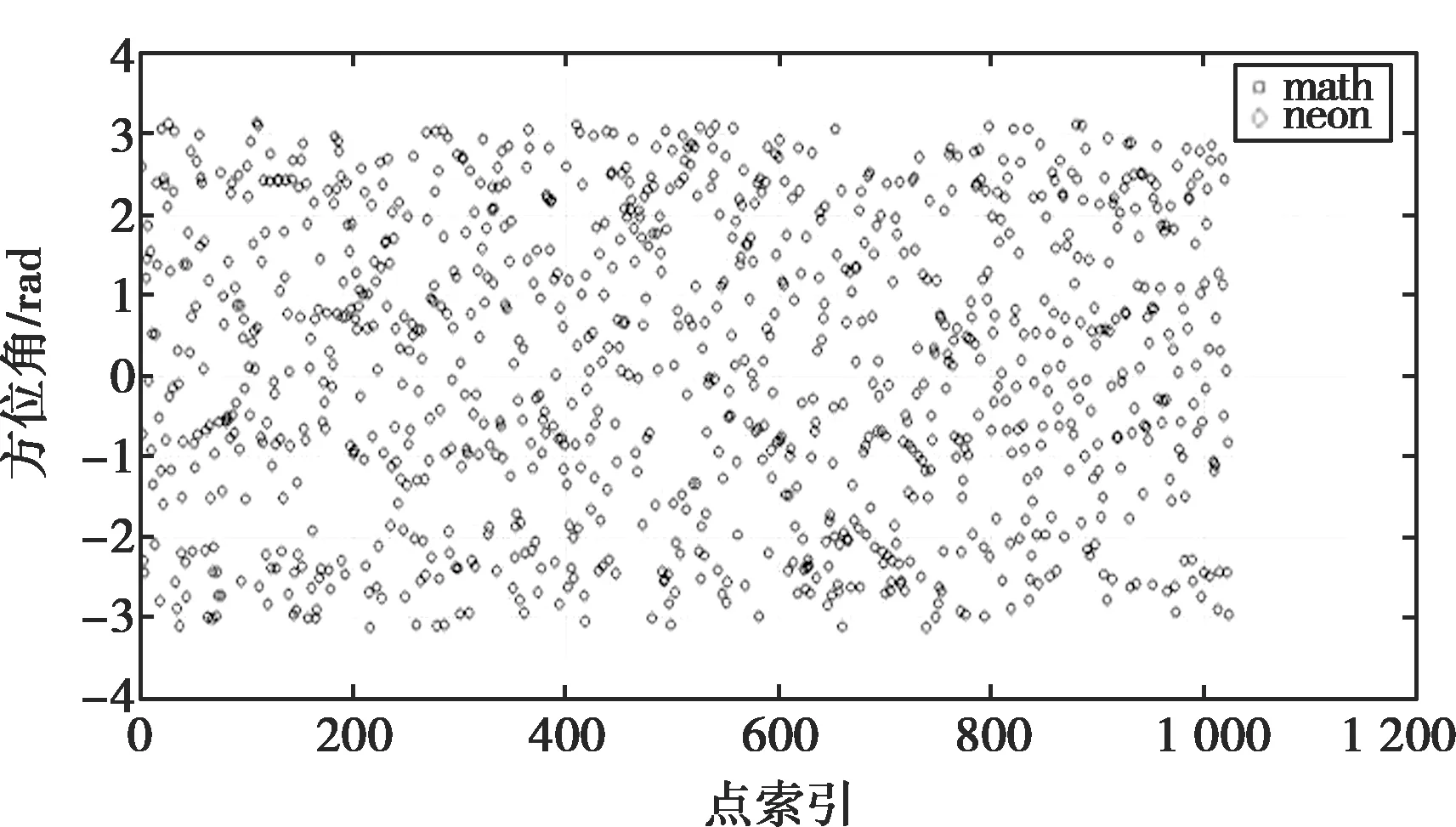
圖6 atan2函數結果對比
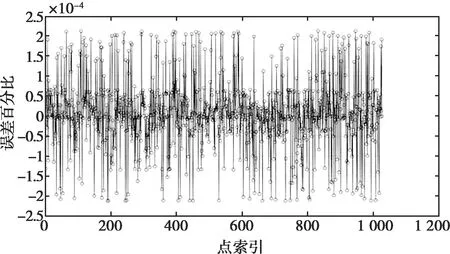
圖7 atan2函數結果誤差
4 結束語
本文基于ARMv8架構CPU平臺,基于Neon指令集,以常用的atan2函數為例,對其進行算法優化和性能提升。實驗結果表明,本文所采用的方式相比于c標準庫對算法的運行速度有顯著提升,也能保證一定的精度,同時該優化算法通過相似的步驟也可以推廣到其他基礎函數中,從而可以提升整個雷達信號處理算法的實時性。
后續工作可在兩方面展開:一是可以采用更加靈活、高效的匯編語言或者使用內聯匯編,以尋求更好的性能;二可以按照統一的標準接口規范,重寫更多的基礎算法,封裝成庫,便于雷達信號處理開發人員使用。
