基于CS及ECS索引的后向鏈式流推理
2023-10-09 02:13:42韓裕镥顧進廣李奇緣
計算機應用與軟件 2023年9期
韓裕镥 顧進廣 李奇緣
(武漢科技大學計算機科學與技術學院 湖北 武漢 430065)
(湖北省智能信息處理與實時工業系統重點實驗室 湖北 武漢 430065)
(武漢科技大學大數據科學與工程研究院 湖北 武漢 430065)
(國家新聞出版署富媒體數字出版內容組織與知識服務重點實驗室 湖北 武漢 430065)
0 引 言
在當前的大數據時代,實時的語義數據不斷增長,如何處理這種不斷到達的數據仍然是一個挑戰,特別是針對語義Web的實時流處理,一方面語義Web的表示有相對固定的標準及格式,但是流處理方面目前并沒有統一的標準,因此設計整個流系統的架構十分困難。另一方面,當前在靜態RDF圖上有很多關于RDFS的推理方法,但是在RDF數據流上很少見,傳統的流處理是將輸入的數據流轉換為特定的關系后執行臨時查詢及推理來處理此類語義流數據,由于數據轉換和基于磁盤的存儲可能會非常昂貴,因此該方法通常假定數據不會頻繁更改,而且它在實時性處理方面有很多不足。其次,諸如無處不在的物聯網場景通過在人與對象、人與人、對象與對象之間生成大量流數據來重新定義信息的價值。通過實時應用人工智能、機器學習、優化技術,以及將傳統數據處理和數據分析應用于歷史數據,這些數據具有轉化為即時知識并最終提供服務的巨大潛力[1]。流推理結合了推理和流處理技術,這種結合使得能夠處理從大量源連續產生的動態和異構數據,動態處理多個流,并實現實時服務。但是目前已經提供的流推理服務是相當昂貴的,而且標準的數據流管理系統并不支持流推理服務。
在近幾年中,RDF流處理(RDF Stream Processing,RSP)社區為解決上述問題做出了一些貢獻。但總體來看,大多數工作要么忽略數據量可能龐大的情況,要么忽略RDF數據流的推理能力。目前關于靜態RDF圖的RDFS推理有很多方法,但是在RDF流上很少,RDF流推理系統需要解決對非常動態的輸入進行推理的問題,同時也要在推理準確性及推理效率之間權衡,有可能一分鐘前推理的知識在這一刻已經不成立,因此流推理系統需要很強的時效性,而且研究表明,流推理中平均推理延遲占整體處理時間的45%到65%,遠高于傳輸和其他數據處理時間[2]。
針對以上難題,本文在實時流數據處理引擎Esper的基礎上,設計一個基于CS及ECS索引的后向鏈式流處理方法。Esper可以使用類似于SQL的EPL語言來處理持續的流數據,它并不是先存儲數據再注冊一個查詢語句,而是先注冊查詢后去檢索持續的流數據,類似一個關系數據庫的顛倒。目前基于ECS的靜態查詢具有較好的性能,但是并不支持推理,本文將CS及ECS索引與后向鏈式流推理相結合。
1 相關工作
本節首先介紹RDF數據流和RDFS流推理的基本概念,然后對與本文工作方向相近的研究進行介紹和分析。資源描述框架(RDF)和SPARQL是W3C關于在網絡上表示和查詢圖數據的建議,RDF基本組成為三元組,基本結構是t∈
RDFS是在RDF的基礎上定義了一系列規則,它是一種可擴展的知識表示語言,可以用來創建描述類、子類和RDF資源屬性的詞匯,以便于進行推理,如表1的RDFS推理規則集。而推理則是一個產生新知識、挖掘隱含知識的過程,在RDF表示中表現為從已有的RDF圖中利用一系列規則產生更大的RDF圖的過程。
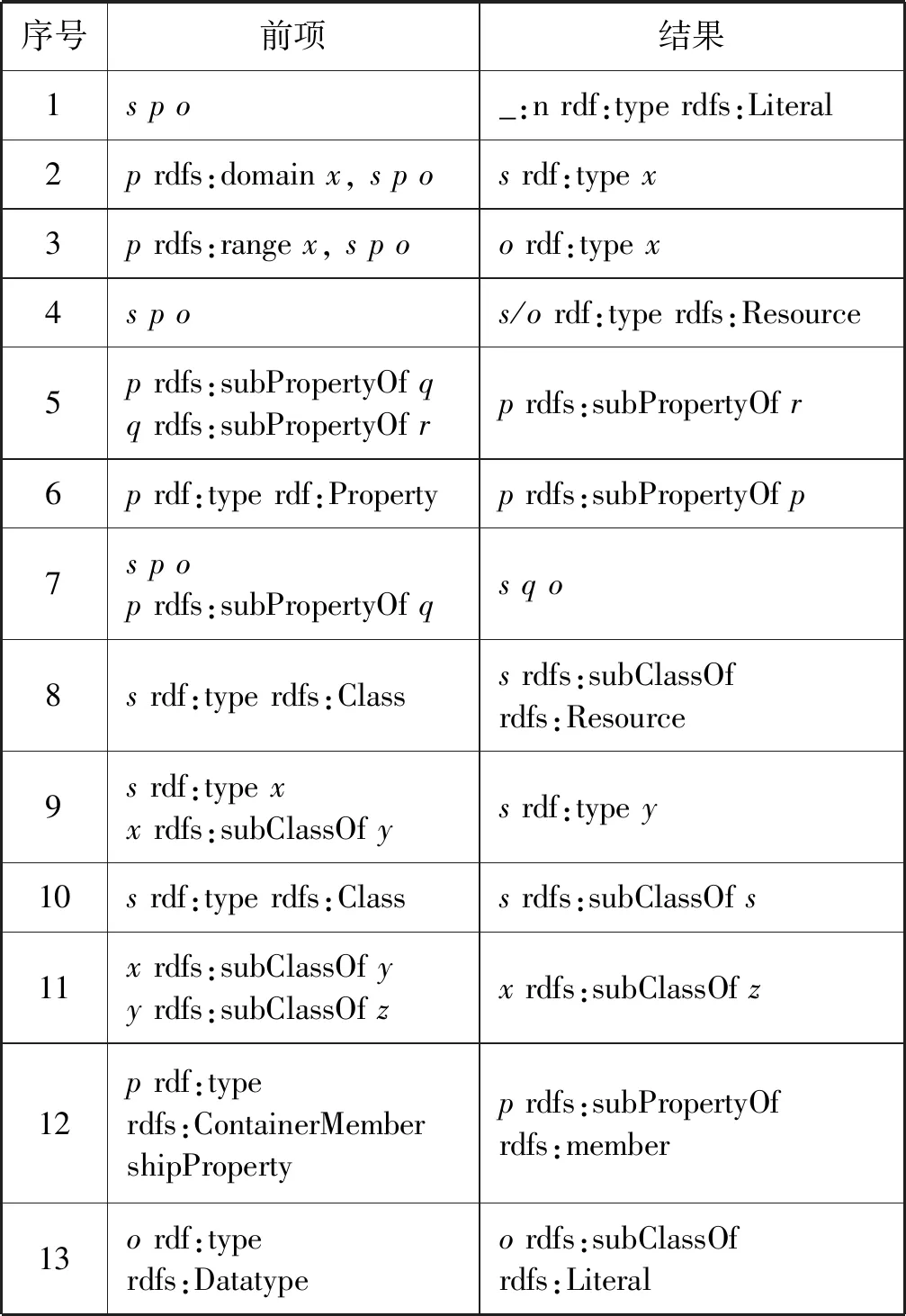
表1 RDFS規則集
為了從RDF數據流中獲得更多的信息,目前的方法是在現有RSP引擎中添加推理功能。受智能城市的物聯網用例的影響,本文首先提出了將推理技術與數據流相結合的理論。盡管RDF流推理的最初思想是在十年前提出的,但是RDF流推理的發展仍處于起步階段。像C-SPARQL或StriderR[4]這樣的系統允許通過RDF流進行RDFS++的推理,但是對時間邏輯運算符的表達仍然存在局限性。
TrOWL[5-6]是最早開發RDF流推理的系統之一,TrOWL能夠即時計算并維持推斷結果的合理性。開源 ELK推理程序的目標是支持OWL到EL的配置文件,它是ConDOR項目的一部分,該項目主要研究基于“結果驅動”的推理程序。盡管ELK最初不是為RDF流推理量身定制的,但仍然認為LiteMat可以依靠ELK的TBox分類工具。StreamRule[7]及其并行化版本StreamRuleP[8]都使用RSP引擎進行數據流預過濾,使用Clingo[9]作為ASP 求解器。BigSR[10]中BSP實現的表達能力可以完全涵蓋StreamRule和StreamRuleP。此外,對StreamRule/StreamRuleP的評估表明,平均吞吐量約為C-SPARQL 和CQELS的2倍,具有秒級別的延遲,但是集中式方法限制了StreamRule和StreamRuleP的性能。
Laser[11]和Ticker[12]都是基于LARS[13]框架的流處理系統,但是由于引入了外部的ASP引擎Clingo而使得性能下降,同時Laser也不能進行分布式的流處理,因此BigSR在Laser的基礎上解決了這一問題。
Cichlid[14]是基于Spark大數據處理框架的分布式語義網推理機,有著較高的推理性能,EMSR[15]是在 Cichlid的基礎上加入了基于變量的優化聯接算法,減少了聯接的時間。表2總結了各RSP引擎和流推理系統的性能和特點。
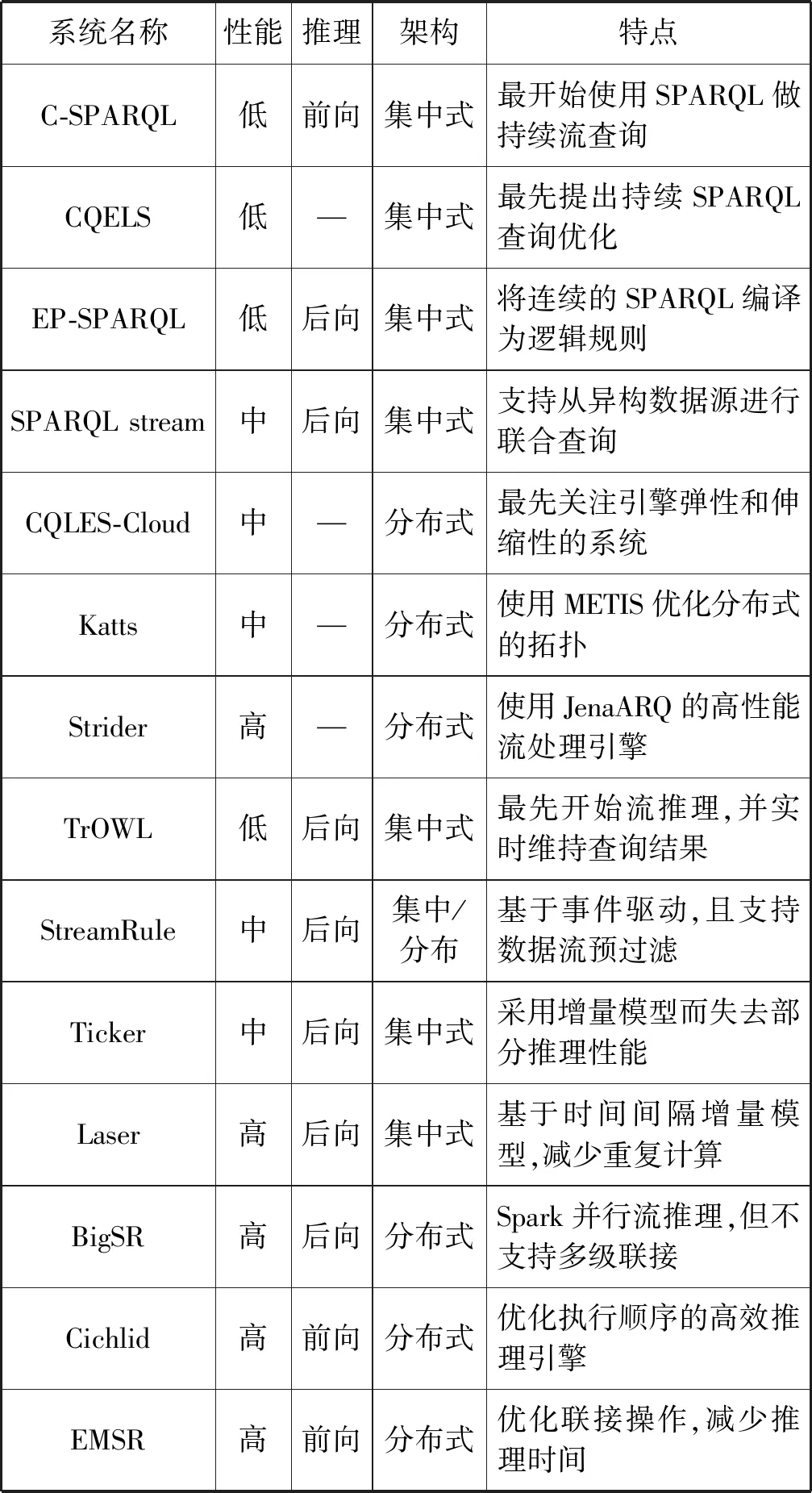
表2 RDF流處理引擎現狀
2 基于CS及ECS索引的后向鏈式流推理
2.1 RDF流查詢總體系統架構
如圖1展示的是基于CS及ECS的RDF流查詢的總體結構,本文在利用擴展特征集的基礎上,加入了基于查詢語句的語義數據流后向推理方案,描述了整個架構的設計,提出了ECS索引算法及查詢過程中的圖匹配算法,構建了一個高效的語義數據流后向查詢引擎。本文共有三個核心模塊,首先是加載新的RDF數據集并提取三元組特征集(CS)索引和擴展特征集(ECS)索引,其次是基于ECS索引的后向推理,最后是處理SPARQL查詢并獲取結果。
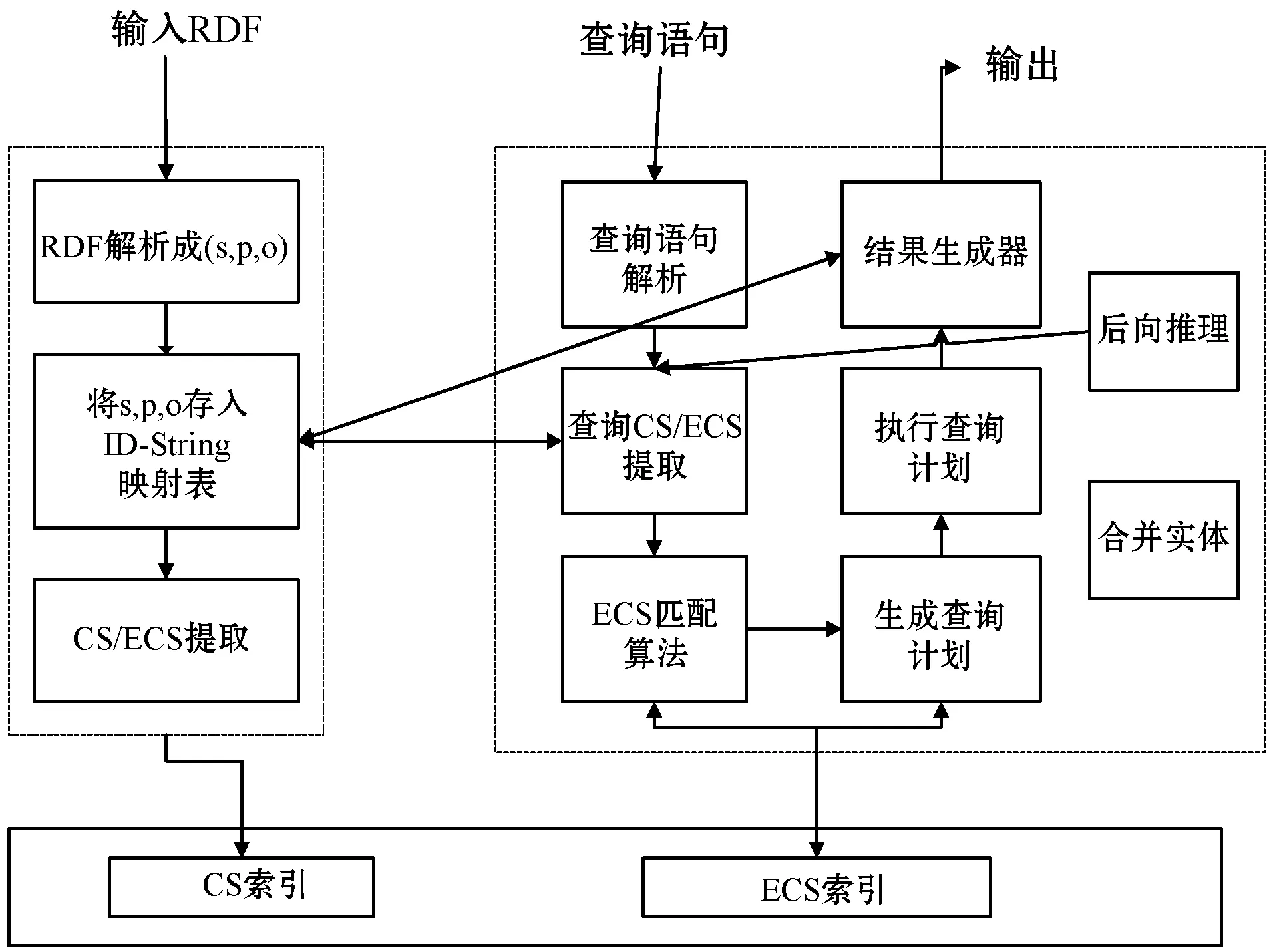
圖1 RDF流查詢總體架構
2.2 RDF數據載入
為了減少RDF數據內存占用,本節采用Triplebit[16]中的存儲結構,將三元組作為連續的4字節大小的整數存儲在內存中,其中每個三元組的主語、謂語和賓語分別被分配一個自增的不重復ID。在加載階段,將每個三元組的結構設定為大小為4的向量,前三個向量分別對應主語、謂語和賓語的ID,最后一個位置指向其主語的CS索引,在數據載入階段,都初始化為默認值-1,如圖2所示。

圖2 數據載入
對每個RDF保留4個字節,并根據主語和CS索引進行排序,按照這種思路即使10億個三元組也最多只需要4 GB的內存空間,因此在一定程度上減少了內存占用。另外,本文也按照ECS中數據載入的方法,將三元組中IRI前綴進行壓縮,生成對應的映射詞典,減少在后續操作中字符串解析的時間,并為最后輸出的標識查詢結果進行拼接,返回可讀的字符串數據。
2.3 索引提取與建立
2.3.1CS索引
CS索引是特征集合[17],是表示從一組主語集合都擁有的一組公共屬性p1,p2,…,pn,通過對數據集的三元組進行線性掃描,可以檢索所有CS的集合[18]。首先按主語對三元組進行排序,并在主語中找到新的屬性組合時構造新的CS,換句話說,當我們對具有同一主語的三元組進行遍歷時,我們將聚合這些三元組的屬性。并且當迭代繼續進行時,對于下一個主語,我們對聚合屬性的位圖進行哈希處理,并檢查其是否已經存在,如果沒有,我們將使用這些屬性創建一個新的CS,每個CS被分配一個唯一的整數標識符,并保存定義它的屬性的位圖,其中每個位對應于位圖中是否存在此屬性。在此迭代過程中,我們通過將三元組向量的第四個元素設置為分配給CS的整數標識符,根據主語節點的CS將三元組與CS關聯,即圖2中CS索引位置。
然后,我們按三元組的CS對其進行排序,將主語保留為第二排序鍵,并在SPO表中構造一個大的三元組表以進行一個查詢周期的持續存儲。CS索引在此表的頂部構造為B+樹,其中的鍵由CS的ID定義,通過維護SPO表中每個CS的開始和結束索引,我們可以使用此索引來獲取與特定CS相關的三元組。這樣,CS索引可以根據對象的CS對所有三元組進行劃分,并允許我們通過簡單的范圍掃描輕松評估給定節點或變量周圍的屬性。CS索引構造過程如圖3所示。
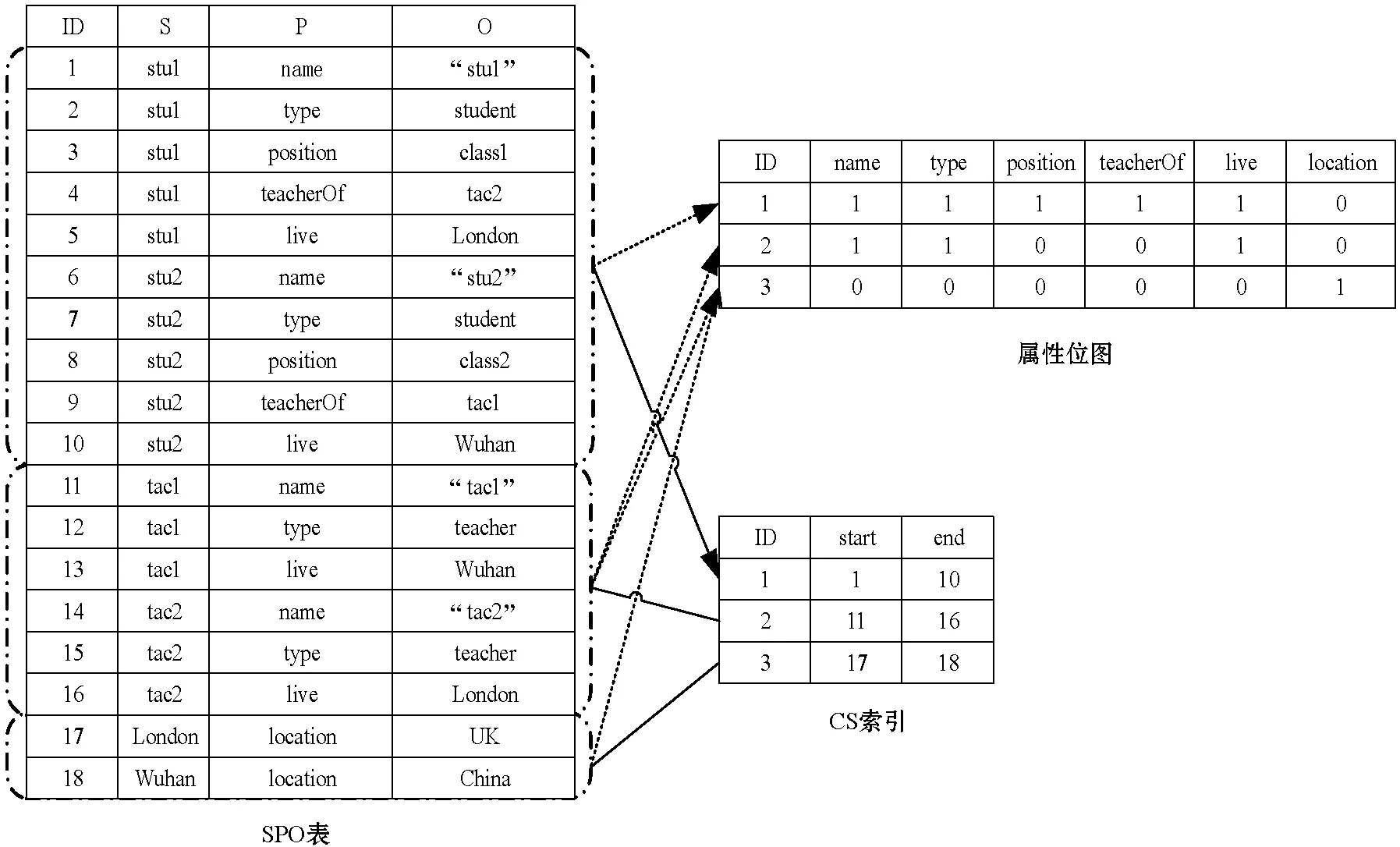
圖3 CS索引構造過程
2.3.2ECS索引
ECS是擴展特征集,建立CS索引后,下一步是提取ECS,并建立ECS索引。提取ECS的一種簡單方法是對整個數據集執行賓語和主語聯接,掃描結果行,并為主語和賓語的CS的每種不同組合創建一個新的ECS,但是有一種更有效的方法是利用先前計算的CS索引。具體來說我們利用CS索引并遍歷所有CS對,其中CS對是一組CS映射表,用于保存三元組的主語和賓語聯接。如圖3中的CS索引S1(ID為1)、S2(ID為2)和S3(ID為3),當S1、S2和S3的三元組之間的聯接結果不為空時,我們將根據三元組主語的CS構造一個新的ECS,如S1和S2聯接得到2個聯接結果(stu1和tac2,stu2和tac1),S1和S3聯接得到2個聯接結果(stu1和London,stu2和Wuhan),S2和S3聯接得到2個聯接結果(tac1和Wuhan,tac2和London),總共表示6個新的ECS。
然后,我們可以存儲ECS以及對其主語和賓語CS的ID標識符的引用,以及其中包含的三元組。與CS一樣,每個ECS都分配有唯一的整數標識符。但是與CS索引對數據集中的所有三元組進行分區相比,ECS索引僅對與有效ECS有關的三元組進行分區,即其主語和賓語聯接具有非空CS的三元組,這些是描述資源之間路徑的三元組。我們將這些三元組存儲為PSO表,并在此表的頂部將ECS索引構建為B+樹,其中每個ECS定義了屬于它的一系列連續三元組。圖4所示為ECS索引結構。之后,獲取特定ECS的三元組只需要對PSO表進行簡單的范圍掃描即可。事實上,PSO表的大小遠小于SPO表的大小,因為后者包含所有三元組輸入數據,而許多三元組不屬于有效的ECS,這些要么是其賓語是帶有文字描述表示的三元組,要么其節點是單一無相連的三元組,因此用空CS來描述。

圖4 ECS索引結構
2.4 基于CS及ECS的后向推理
本節在CS及ECS索引的基礎上,描述如何進行后向鏈式推理。為了便于理解,本文根據上述的RDF流數據建立了一個簡單的查詢語句,如圖5所示,表示居住在同一個城市的兩個人中,一個是學生一個是老師,并且是師生關系。

圖5 查詢語句示例
結合背景知識發現,學生的種類有很多,例如本科生和畢業生都是學生的子類,例如查詢中的學生x;同理老師也有數學老師和化學老師等多種類型,如老師y。在進行查詢的時候,需要將所有學生x和老師y的子類三元組全部包含進去,才是所有滿足查詢條件的三元組。因此,需要進行后向鏈式推理得到所有x和y的隱含信息。
推理的第一步是根據查詢條件和背景知識進行反向迭代。背景知識中三元組的數量是相對較少的,其中定義了數據集各個實體和屬性之間的關系,在LUBM數據集中約為170個。在查詢條件{?x type student}下,根據規則9,滿足條件{?s type ?t,?t subClassOf student}的三元組也是滿足上述查詢要求的,然后在背景知識中匹配是否有滿足的實體t,如果存在則繼續向上遞歸尋找。在進行向上尋找的過程中,可以根據條件直接篩選出滿足條件的結果,但是本文并沒有這么做,因為篩選出合適的結果需要遍歷輸入三元組,對于多次迭代這種開銷是非常巨大的。本文采用了與前向推理相反的后向推理鏈,得到滿足背景知識和查詢條件的實體。其次是將滿足查詢條件和背景知識的實體進行合并。由于一個查詢條件有多個滿足的實體,例如本科生和畢業生都是學生的實體,因此需要將這些實體進行合并。根據之前關于特征集的介紹,特征集是關于一組具有相同謂語屬性的RDF三元組,通過后向推理得到的實體必然也要具有同樣的謂語屬性,因此將推理得到的實體進行合并。后向推理過程如圖6所示。
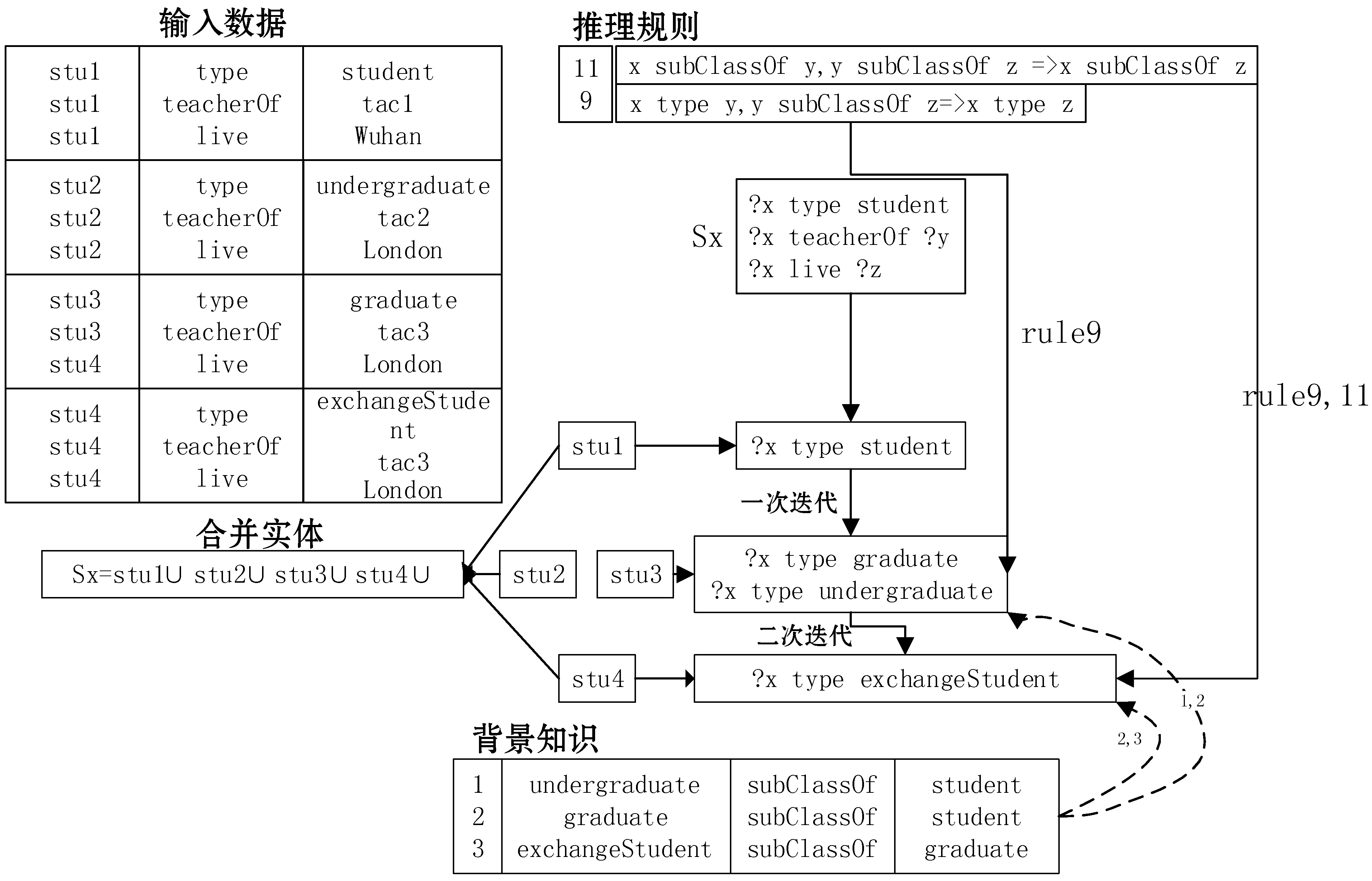
圖6 后向鏈式推理
可以發現,每次的迭代是利用上層推理結果、背景知識和推理規則共同推理完成的。只將上層推理結果和背景知識作為推理的前項,而不遍歷整個輸入數據,一方面是因為這兩個部分的數據量很小,迭代較快,減少性能開銷,另一方面是因為可以利用CS索引結構的特點,如果知道三元組的謂語就可以快速得到所有滿足該謂語的三元組。
2.5 查詢處理
本節在ECS索引的基礎上,描述如何進行RDF流查詢。為了便于理解,本文根據上述的RDF流數據建立了一個如圖5所示的簡單的查詢語句,表示居住在同一個城市的兩個人中,一個是學生一個是老師,并且是師生關系。
本節將在這個查詢的基礎上,分別從查詢語句解析和提取ECS查詢圖、ECS查詢圖和ECS索引的匹配、查詢計劃和執行三個步驟講述RDF流查詢的過程。
2.5.1查詢解析和提取索引
首先,查詢解析器會將傳入的查詢語句轉換為ECS查詢圖。因此,第一步要提取查詢節點的特征集CS,如2.3.1節中描述的CS索引建立方法,然后根據2.3.2節中ECS索引建立的方法,在查詢模式下找到ECS,并在查詢ECS之間創建鄰接表。此過程與加載RDF流數據時的ECS提取相同,但是這次是對查詢的三元組執行。確定了查詢ECS及其之間的聯接后,我們按它們出現的順序遍歷這些聯接,以便在ECS查詢圖中標識這些聯接鏈,即一系列賓語和主語的聯接。因為查詢語句和ECS索引中的數據都是非常少的,所以這個查詢解析步驟效率很高。
查詢解析過程如圖7所示,根據圖5的查詢示例,首先將查詢語句表示成BGP,如圖7中的4個節點x、y、z、w表示查詢語句中的未知參數,student和teacher表示已知的節點參數,節點與節點之間的邊表示已知屬性。通過BGP中的相連的未知節點和已知參數,轉換成對應的CS索引圖,在轉換過程中,每個節點是由多個推理得到的實體合并而成,如圖7中Sx、Sy和Sz表示對未知節點的CS索引。通過查詢語句中的謂語需求和屬性位圖,將需要查詢CS索引和CS索引表聯立起來。
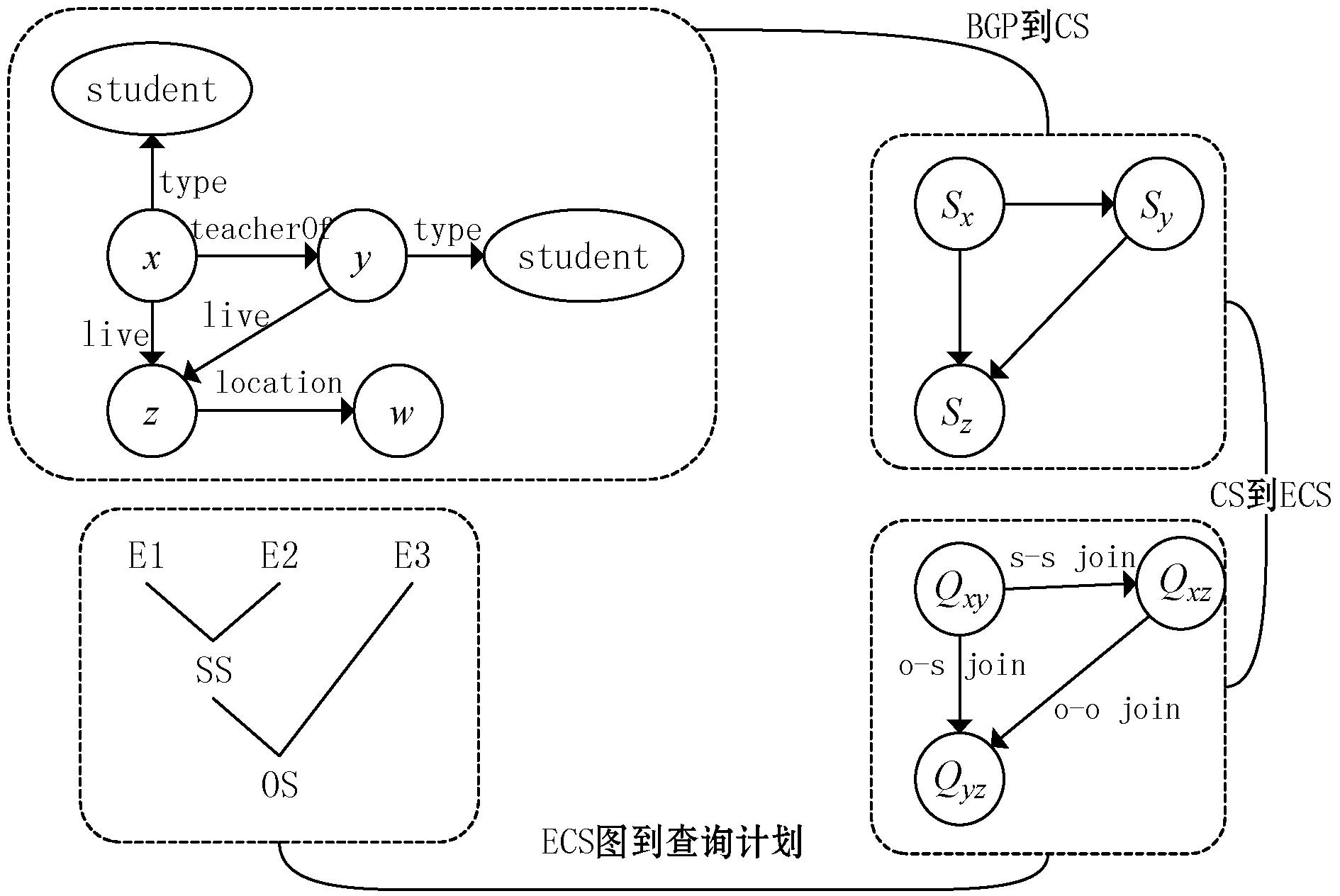
圖7 查詢解析過程
轉換成CS圖后,將相連的兩個CS和有向邊轉換成一個ECS,例如Sx和Sy轉換成Qxy;將CS中所有的節點轉換成ECS后,相鄰的ECS節點之間通過相同的CS索引進行聯接操作,例如Qxy和Qxz之間,通過相同的Sx進行聯接。根據ECS索引結構是由主語和賓語組成的,因此聯接一般有以下幾種情況,ss、so、os、oo,表示起始節點的主語或賓語和終止節點的主語和賓語相聯接,例如os表示起始節點的賓語和終止節點的主語進行聯接。ECS索引算法如算法1所示。
算法1ECS索引算法設計
輸入:Feature set CS and triples mapping table CSMap。
輸出:Extended feature set ECS and Adjacency lists between ECS ecsLinks。
begin
var ecsMap=Map
var subjectCSMap=Map
var objectCSMap=Map
for(SiinCSMap)
for(SjinCSMap)
if(triples.size()>0)
ecs=newECS(Si,Sj)
ecsMap.put(ecs,sort(triples))
subjectCSMap.get(Si).add(ecs)
objectCSMap.get(Sj).add(ecs)
ecsLinks=newMap()
for(Si in objectCSMap.keys)
if(Si ? subjectCSMap.keys)
continue
for(ECSleftinobjectCSMap.get(Si))
for(ECSrightinsubjectCSMap.get(Si))
ecsLinks.get(ECSleft).add(ECSright)
returnecsMap, ecsLinks
end
2.5.2ECS查詢圖和ECS索引匹配
從圖7中可以看出,每一個查詢ECS即圖中的Qxy等,都可以與ECS索引中的0到多個ECS匹配,因此對于查詢ECS和ECS索引之間必然存在一個匹配機制,我們用Query={CSqleft,CSqright}表示一個查詢ECS,用Ecs={CSleft,CSright}表示一個ECS索引,其中參數CS都表示組成ECS的兩個CS索引,則式(1)必然成立。
CSqleft?CSleft,CSqright?CSright
(1)
并且對于組成查詢ECS和ECS索引的主語和賓語的CS,其屬性位圖必然也存在對應的關系。例如查詢語句中對于x變量需要3個屬性type、live和teacherOf,但是在屬性位圖3中,該CS是擁有5個屬性的,并且包含需要查詢的3個,因此有:
pQ?pE
(2)
在此基礎上,制定了對查詢Query的評估方法,對于所有滿足該查詢的ECS的三元組,用m(Query)表示,tp(En)表示與該ECS有關的所有三元組,則評估如下:
Query=tp(E1)∪tp(E2)∪…∪tp(En),Ei∈m(Query)
(3)
通過對ECS圖進行深度優先遍歷,可以將查詢ECS與ECS索引進行匹配。本文在帶有ECS圖的鄰接列表上進行迭代,并以每個ECS為起點,搜索匹配的ECS。圖模式匹配算法通過遞歸實現,如算法2所示。
算法2ECS圖模式匹配算法
輸入:Adjacency lists between ECS ecsLinks, A chain of query ECSs c(q0…qn-1)。
輸出:A linked list of ECS sets that match the ECSs ecsMatches。
begin
var ecsMatches=Map
for(einecsLinks.keySet())
matchData(e, ecsLinks, c(q0…qn-1), ecsMatches)
returnecsMatches
matchData(e, ecsLinks, c(q0…qn-1), ecsMatches)
begin
if(q0.subjectCS.bitmape.subjectCS.bitmap OR
q0.property?e.properties)
returnnull
if(visited(e) OR c.size==1)
returnecsMatches
visited.add(e)
ecsMatches.get(q0).add(e)
forechildin ecsLinks.get(e)
matchData(echild, ecsLinks, c(q0…qn-1), ecsMatches)
end
end
通過在ECS圖上執行深度優先遍歷,可以確保查詢中連續匹配的ECS已鏈接到數據中,此過程的輸出是ECS索引中與ECS查詢鏈匹配的一組ECS鏈。
在圖7的示例中,定義了3個查詢ECS,分別是Qxy、Qxz和Qyz,該算法會將E1(ID為1的ECS索引)匹配到對應的Qxy,因為E1是其子集,表示所有x是y的學生的關系;其次,將E2匹配到Qxz,表示所有學生x居住在地點z的關系;最后將E3匹配到Qyz,表示所有老師y居住在地點z的關系。
2.5.3查詢計劃和執行
查詢計劃為匹配ECS鏈相對應的三元組的各個集合決定聯接執行順序,查詢計劃根據查詢鏈有兩種排序策略,第一種是根據不同查詢鏈之間的公共屬性,盡早濾除無關三元組,稱為外部排序;第二種是根據特定查詢鏈減少ECS之間的賓語和主語聯接的中間結果,這些中間結果對最終結果無關,稱為內部排序。首先為了獲取整個查詢鏈的外部排序,需要根據鏈中的每一個項的執行成本進行計算,讓整個查詢鏈的成本最小。一般情況下根據升序成本對鏈進行排序,即對于鏈中任何一項都有如下狀態:
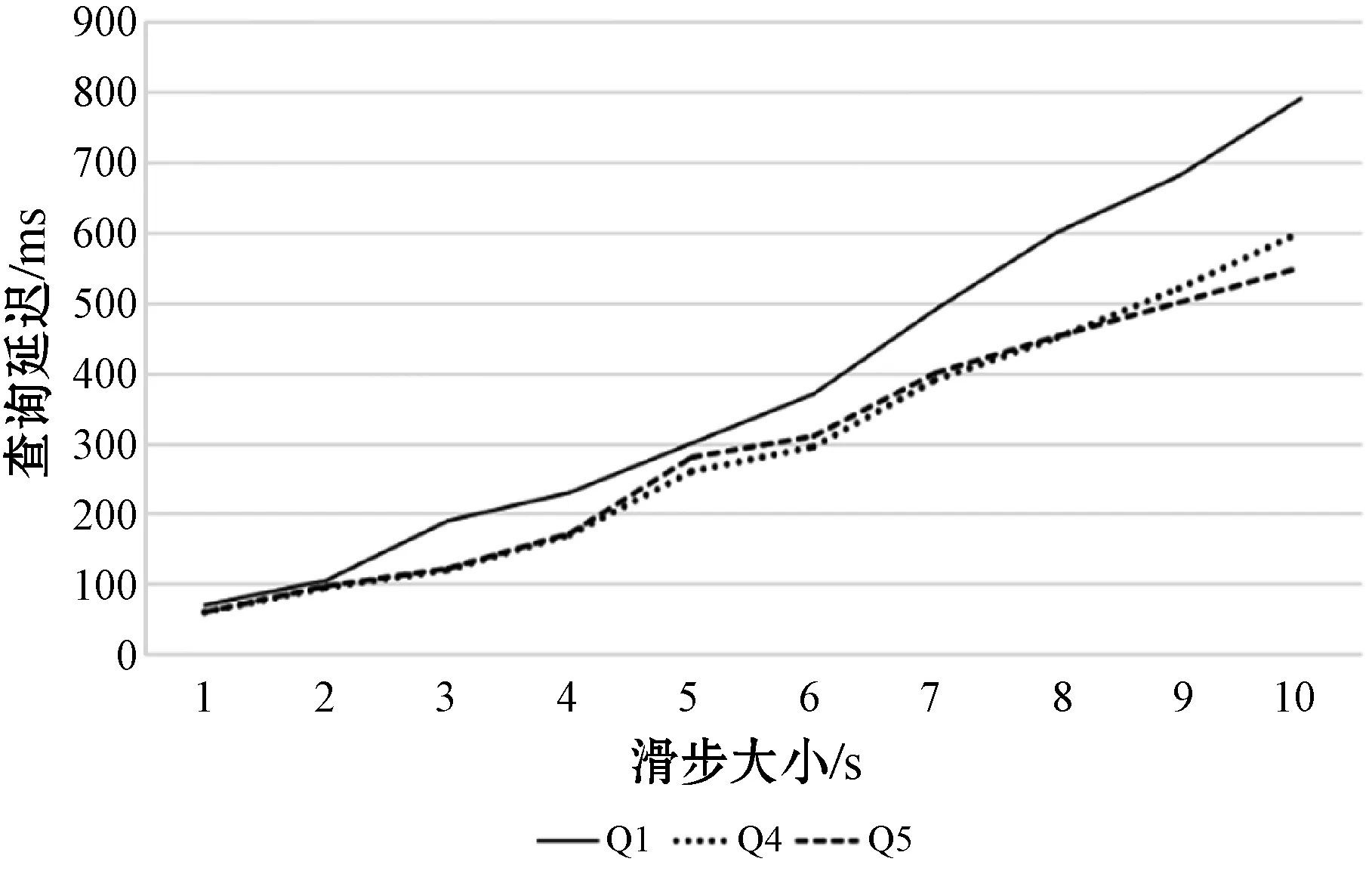
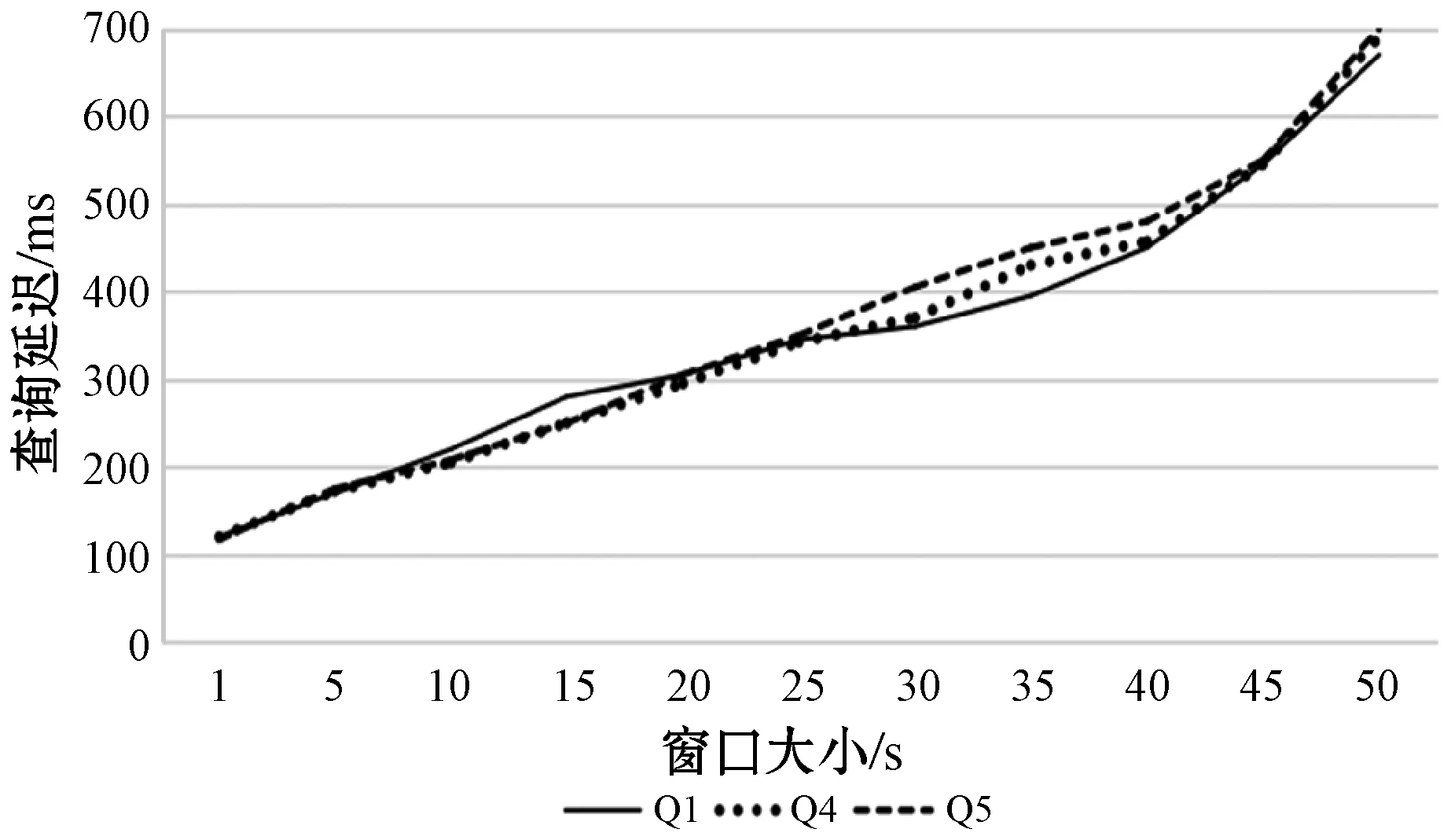
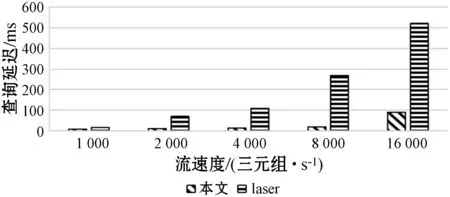
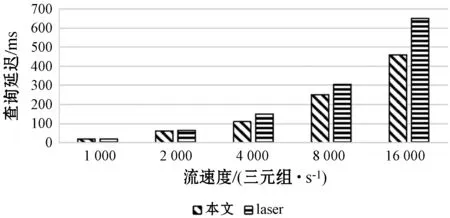
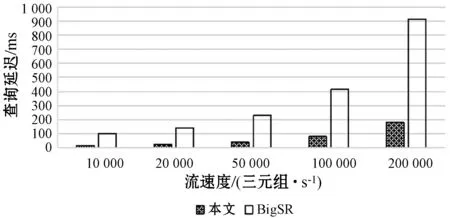
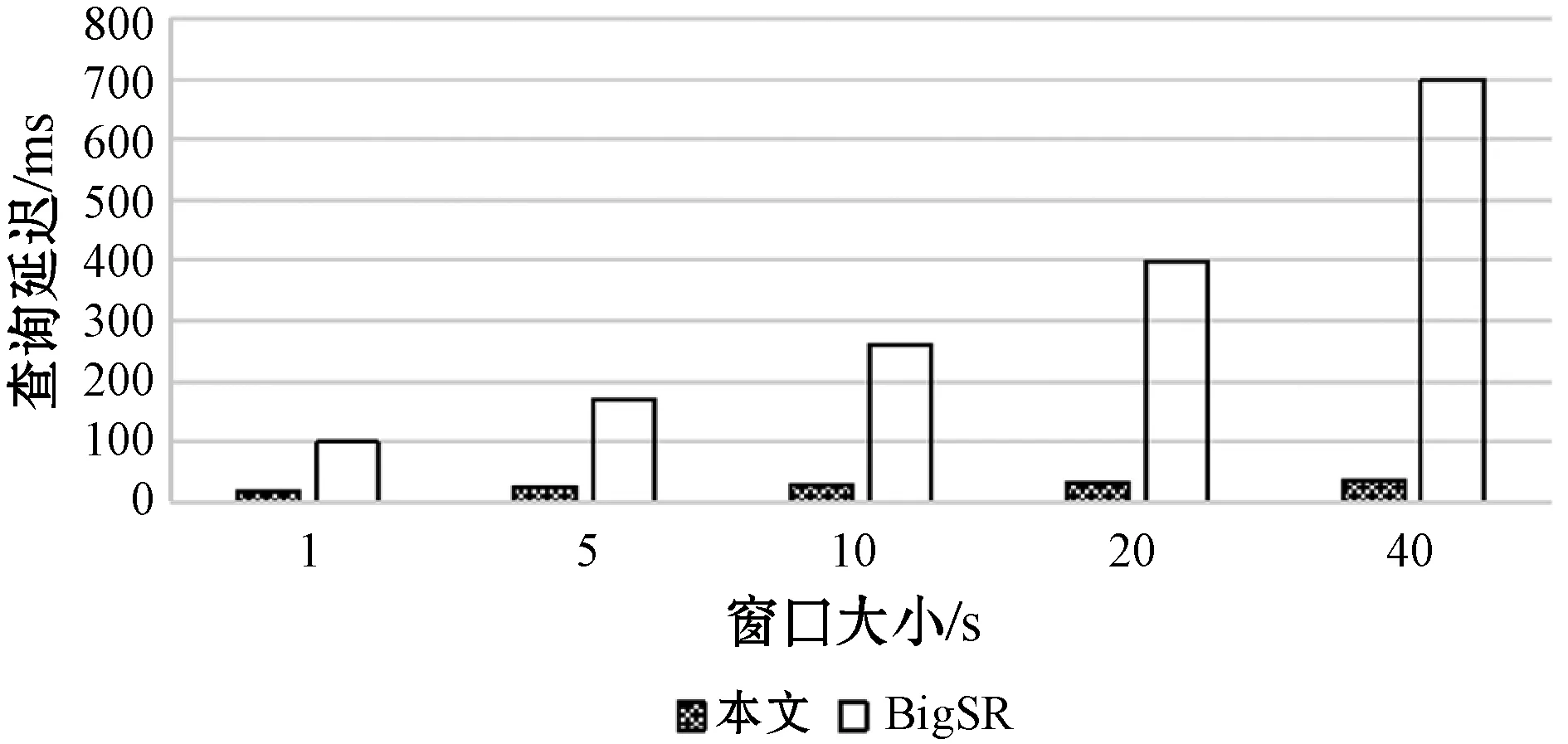
St=Orderi (4) 根據式(4)可以通過鏈中每一項的成本得到排序結果,對于每一項的成本,根據式(1)所示的每一個查詢都可能有約束條件,定義了如下對成本的評估規則,對于查詢中沒有約束條件的,如圖7中的Qxy,其成本是查詢其所有三元組的成本,如式(3)所示,查詢Query的評估方法是與該ECS有關的所有三元組,因此其成本就是查詢所有三元組的查詢成本,進一步地,一個查詢Query的成本公式如下: (5) 對于查詢中有一個或者兩個約束條件的,例如Qxy有一個,而Qyz有兩個,其成本為固定值1。對于鏈中連續的ECS相互聯接的成本,本文利用遞歸的方式定義了如下方法: cost(chain1~n)=cost(chain1~n-1)×fos(Queryn) (6) 式中:fos(Queryn)是第n個查詢進行os聯接的乘數。遞歸開始的首項是由一個ECS組成的鏈,其成本為該ECS的成本;對于一個Query={CSleft,CSright},其中:CSleft表示主語特征集;CSright表示賓語特征集。其乘數fos取決于其賓語和主語聯接操作產生的聯接數據行數,并且定義為Query中每個主語的不同賓語的比率,因此fos(Query)的計算公式如下: fos(Query)=|OQuery|/|SQuery| (7) 式中:OQuery表示查詢Query中的賓語特征集CSright的不同主語個數,SQuery表示查詢Query中的主語特征集CSleft的不同主語個數。通常遞歸函數開銷都比較大,之所以采用這種評估標準的依據是因為第一個ECS的綁定的三元組都遠小于數據集,因此遞歸成本很小。 為了獲得內部排序,本文考慮到鏈中的所有ECS都通過賓語和主語聯接鏈的,可以向左或向右一次擴展一個ECS的現有節點或子鏈。基于此,本文采用一種簡單的試探法,該試探法從成本最低的ECS開始,并從左或右選擇成本最小的ECS來擴展鏈。雖然其他方法使用動態規劃算法來根據所采用的統計信息找到最佳的連接順序,以減少中間結果,但在圖模式匹配階段已經執行了大量的三元組過濾,因此,順序不會嚴重影響查詢處理器的性能。 通過外部排序和內部排序可以很明確地找到一條成本最小的執行計劃。通過查詢ECS索引并加入匹配鏈的每個ECS的三元組,可以單獨執行每個查詢鏈。在執行的最后步驟中,使用公共屬性的散列聯接來聯接多個查詢鏈,并且在評估單個鏈時動態創建聯接表。當從內存中檢索ECS時,將來自于ECS的三元組和來自于CS的三元組之間執行合并聯接,可以實現ECS的主語和賓語的屬性的檢索,獲取所有主語和賓語后,即可獲取對應的聯接結果。 實驗代碼基于Java8,數據集使用的是標準LUBM。實驗使用的操作系統是Windows 10,CPU是Intel(R) Core(TM) i7-6700U,主頻3.40 GHz,內存16 GB。實驗采用LUBM標準數據集,并從流數據大小、傳入窗口大小和滑步大小幾個方面測試系統的整體性能,主要測試整個查詢的延遲及單位時間內處理查詢的數量。 針對整個后向鏈式查詢,本文將與目前比較流行的基于后向鏈式推理的Laser和BigSR做對比實驗,后向推理過程是和查詢語句相關聯的,因此本文設計在推理結果相同的前提下,對比整個系統延遲。查詢語句中,Q1用來查詢少量的直接關聯實體;Q2用來查詢大量的直接關聯實體;Q3用來查詢間接關聯實體;Q4用來查詢大量的需要推理的實體;Q5用來查詢少量的需要推理的實體。 流數據大小對該策略的影響如圖8所示,其中窗口大小和滑步大小都是1 s,可以發現,隨著流數據的增大,系統的延遲和吞吐量也相應增大,整個系統的推理性能會逐漸降低,這也體現了本文在處理瞬時數據流極大的情況會存在一定的缺陷。 圖8 流速度變化 如圖9所示的滑步大小對該策略的影響,其中窗口大小和滑步大小保持一致,流數據每秒2萬,從結果可以發現,隨著滑步逐漸增大,系統的延遲和吞吐量也相應增大,與圖8結果很相似,對于處理滑步極大的情況在存在一定的缺陷。 圖9 滑步大小變化 窗口大小對該策略的影響如圖10所示,其中滑步為1 s,流數據每秒10萬,可以發現,隨著窗口的逐漸增大,系統的吞吐量呈線性增大,但是延遲卻增幅很小,平均每增大50萬吞吐量,延遲增大60 ms,并且在上述條件下,極限性能能達到接近500萬三元組每秒的吞吐量。 圖10 窗口大小變化 綜上所述,本文提出的后向流處理系統在處理瞬時數據流特別大的情況下存在一定的性能缺陷,例如每秒都會產生百萬流數據并且需要在短時間得到查詢結果的場景;但是需要處理窗口很大,但是滑步很小的場景,比如城市交通監管、天氣檢測等一段時間內的實時監測系統,本文有很大優勢。 由于Laser目前沒有合適的公共數據集作測試,因此本文采用了與Laser相同的數據生成器作為數據流。本文設計的查詢語句主要測試數據聯接的性能,這也是Laser架構中性能比較出眾的一個。實驗分為了兩組,分別是窗口大小為1 s和5 s,流數據相同并逐漸增大,實驗結果如下。從圖11和圖12的實驗結果可以看出,在窗口為1時,本文的后向推理的性能更高,隨著數據流的增大,查詢延遲也在增加,但是增幅不大。在窗口為5時,本文方法相對而言延遲增幅較大,但是仍然比Laser有一定的優勢,上升的主要原因是數據流只有一個特征集,因此進行聯接操作會產生大量的耗時,也從另一個方面說明了,對于查詢特征集單一的查詢語句,本文方法在數據大的時候延遲上升加快。綜上所述,本文的后向推理方案在對比Laser在窗口和滑步相同時,有著很大的性能優勢;但是隨著窗口的增大,本文方法性能下降相對較快,是因為Laser采用了基于時間段增量模型來減少重復計算。 圖11 窗口為1時對比結果 圖12 窗口為5時對比結果 在與BigSR的對比實驗中,因為BigSR不支持多級聯接,因此本文設計了相對應的多組查詢,并選取了其中一個有代表性查詢Q3的結果進行了對比。本文根據目前提出的方法設計了流速度和窗口大小作為主要的變量指標,分別為保持窗口大小為1不變,改變流速度和保持流速度為1萬個三元組不變,改變窗口大小,并將查詢延遲和吞吐量作為主要的衡量指標。 從圖13中的實驗結果可以發現,在窗口不變時,隨著流速度的增大,吞吐量也增大,同時查詢延遲也增大,增幅與BigSR的增幅類似,基本呈線性增長,主要是因為目前的并行推理機還存在一定的優化空間。從圖14中的實驗結果可以發現,在流速度不變時,隨著窗口的增大,BigSR的查詢延遲也呈線性增長,但是本文方法并沒有明顯上升,是因為本文提出的基于后向鏈式的流推理極大程度地減少了無關結果,并且本文的擴展特征集在數量聯接數量較少時,其性能非常高。 圖13 流速度變化對比結果 圖14 窗口變化對比結果 本文針對現有的后向鏈式流推理在查詢數據效率低的問題,通過有效地利用CS和ECS索引,并結合查詢語句提出一個高效的后向鏈式流推理方法。首先描述了整個架構圖;其次詳細描述了CS索引和ECS索引的提取和建立過程;然后根據查詢語句建立查詢ECS圖,通過圖匹配算法將查詢ECS圖和ECS索引聯接起來獲取查詢ECS鏈;進一步根據ECS查詢鏈中每個ECS的成本使用遞歸策略得到最小成本執行計劃。并和Laser、BigSR進行了對比實驗,實驗表明本文方法有一定的性能優勢,但是仍然存在一些不足,例如大規模RDF流的CS及ECS構建效率問題。另外,本文在與Laser的對比實驗中,在窗口逐漸增大時,其性能降低相對較快,而Laser則比較平穩,因此下一步可以考慮將Laser中減少重復計算的增模型相結合,進一步提升后向推理的性能。3 實驗與結果分析
3.1 實驗配置
3.2 實驗場景設置
3.3 實驗結果分析

4 結 語
