應(yīng)用多尺度混合卷積網(wǎng)絡(luò)的腦電信號(hào)特征提取與識(shí)別
2023-10-09 02:50:12王蒙昊方慧娟龔亨翔羅繼亮
王蒙昊, 方慧娟, 龔亨翔, 羅繼亮
(1. 華僑大學(xué) 信息科學(xué)與工程學(xué)院, 福建 廈門(mén)361021;2. 華僑大學(xué) 福建省電機(jī)控制與系統(tǒng)優(yōu)化調(diào)度工程技術(shù)研究中心, 福建 廈門(mén) 361021)
腦機(jī)接口(BCI)通過(guò)解碼人類思考時(shí)的腦神經(jīng)活動(dòng)信息,建立大腦與外界之間的直接信息傳輸通道[1].BCI是一項(xiàng)有潛力改變世界的尖端技術(shù),具有十分廣泛的應(yīng)用.在醫(yī)療方面,BCI可以幫助中風(fēng)患者、身體殘疾的人[2];在非醫(yī)療方面,BCI可以控制小車(chē)、機(jī)器人[3].由于實(shí)現(xiàn)BCI技術(shù)的關(guān)鍵在于腦電信號(hào)(EEG)的高識(shí)別率,因此,BCI研究的首要任務(wù)是腦電信號(hào)特征的提取和識(shí)別[4].
近年來(lái),對(duì)腦電信號(hào)特征的有效提取以及分類的研究也越來(lái)越深入.研究主要分為機(jī)器傳統(tǒng)學(xué)習(xí)方法和機(jī)器深度學(xué)習(xí)方法.機(jī)器傳統(tǒng)學(xué)習(xí)方法依賴特定的領(lǐng)域知識(shí),通常需要使用手工特征提取器(通道濾波共空間(FBCSP)[5]、小波變換[6]和快速傅里葉變換等),將提取的特征輸入到魯棒性較高的線性判別器(LDA)或者支持向量機(jī)(SVM)中進(jìn)行分類.
機(jī)器深度學(xué)習(xí)方法不但具有比傳統(tǒng)方法更強(qiáng)大的擬合能力,還可以自動(dòng)提取腦電信號(hào)特征.Lawhern等[7]提出了EEGNet模型,使用卷積神經(jīng)網(wǎng)絡(luò)(CNN)模塊[8]提取空間和時(shí)域特征,提取能力更強(qiáng),魯棒性更好.Ingolfsson等[9]提出了EEG-TCNet模型,將一種專門(mén)為時(shí)間序列設(shè)計(jì)的卷積神經(jīng)網(wǎng)絡(luò)TCNet[10]模塊與CNN模塊相結(jié)合,增強(qiáng)模型的時(shí)域提取能力,達(dá)到更好的效果.Mane等[11]提出FBCNet模型,使用多種不同截止頻率的低濾波器提取不同維度的信息,以增強(qiáng)模型的頻域提取能力.Song 等[12]提出EEG-Conformer模型,將CNN模塊與通道注意力機(jī)制(SE)模塊結(jié)合,增強(qiáng)模型空域與時(shí)域特征提取能力.此外,文獻(xiàn)[13-15]還提出通訊信息進(jìn)程(CSP)模塊與CNN模塊的結(jié)合、長(zhǎng)短期記憶(LSTM)模塊與CNN模塊的結(jié)合的模型.
以上研究增強(qiáng)了時(shí)-頻-空域的特征提取能力,主要圍繞CNN+其他模塊.考慮到腦電信號(hào)的個(gè)體和時(shí)間差異性,腦電信號(hào)相關(guān)的信息會(huì)出現(xiàn)在頻譜的多種波段上,每層僅使用單一大小的卷積核提取特征,會(huì)丟失一些有用的特征.如果能使用多種不同大小的卷積核,并引入新穎的特征提取架構(gòu),有望進(jìn)一步提高腦電信號(hào)特征提取和識(shí)別能力.本文應(yīng)用多尺度混合卷積網(wǎng)絡(luò)的腦電信號(hào)特征提取與識(shí)別.
1 EEG-MSTNet模型
1.1 總體架構(gòu)
EEG-MSTNet模型主要由3個(gè)模塊構(gòu)成:多尺度卷積(MCNN)模塊、SE模塊和時(shí)域殘差(TRN)模塊.EEG-MSTNet模型總體架構(gòu),如圖1所示.圖1中:BN為批正則化層;ELU為指數(shù)線性單元激活層;Pool為池化層;Lambda為函數(shù);Dense為全連接操作.

圖1 EEG-MSTNet模型總體架構(gòu)Fig.1 Overall structure of EEG-MSTNet model
首先,通過(guò)4組并行的卷積模塊(即多尺度卷積1)將EEG信號(hào)從低緯度的信號(hào)編碼到高緯度的信號(hào),并將拼接到一起的信號(hào)送入下一個(gè)模塊.其次,通過(guò)核的大小與通道數(shù)相關(guān)的深度卷積沿通道方向卷積高維信號(hào).最后,再用4組可分離的2D卷積(即多尺度卷積2)進(jìn)一步提取特征.
輸出的時(shí)間序列特征包含時(shí)-頻-空3個(gè)維度豐富的信息,將其送入到SE模塊,突出時(shí)間序列中最重要的通道信息,提升模型學(xué)習(xí)效率同時(shí)降低特征冗余.通過(guò)TRN模塊,提取出更具有判別性的高維時(shí)域特征,對(duì)信號(hào)進(jìn)行分類.
整體網(wǎng)絡(luò)的參數(shù)設(shè)置,如表1所示.表1中:大部分參數(shù)是根據(jù)實(shí)驗(yàn)效果設(shè)定的最優(yōu)參數(shù);小部分參數(shù)(如多尺度卷積核大小)結(jié)合了對(duì)頻率域的分析和實(shí)驗(yàn)效果而設(shè)置的參數(shù);Softmax為函數(shù).
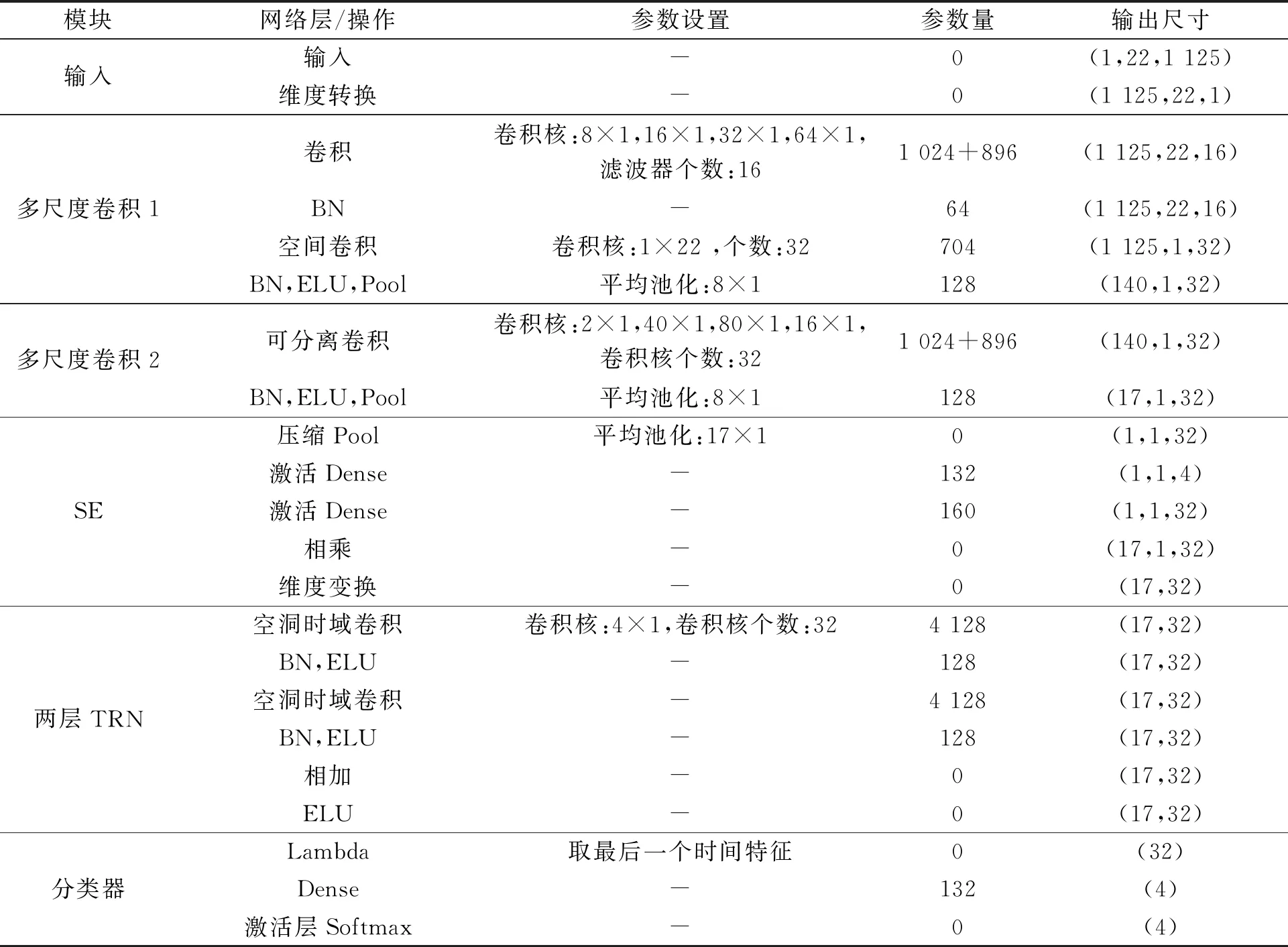
表1 EEG-MSTNet模型的參數(shù)Tab.1 Parameters of EEG-MSTNet model
1.2 數(shù)據(jù)預(yù)處理和輸入特征信息
原始的MI-EEG模型信號(hào)沒(méi)有經(jīng)過(guò)任何預(yù)處理,將其直接輸入到EEG-MSTNet模型中.根據(jù)標(biāo)簽標(biāo)的每個(gè)開(kāi)始的時(shí)間點(diǎn),將session數(shù)據(jù)切分成多個(gè)trial數(shù)據(jù).輸入模型的trial數(shù)據(jù),xi∈RC×T,其中,C為輸入腦電信號(hào)的通道數(shù);T=t×f代表了每個(gè)EEG信號(hào)的采樣點(diǎn)個(gè)數(shù),t為運(yùn)動(dòng)想象切分的持續(xù)時(shí)間,f代表采樣率.基于運(yùn)動(dòng)想象分類任務(wù)可以被定義為建立x和相應(yīng)類別y之間的映射,模型的目標(biāo)是對(duì)訓(xùn)練集{x,y}的學(xué)習(xí),盡可能擬合該映射.對(duì)于BCI-Ⅳ-2a數(shù)據(jù)集,每個(gè)trial數(shù)據(jù)取1.5~6.0 s的數(shù)據(jù),采樣頻率為250 Hz,故采樣點(diǎn)C為22,18個(gè)session共切分成5 184個(gè)trial數(shù)據(jù).
1.3 卷積神經(jīng)網(wǎng)絡(luò)模塊
CNN模塊是一類使用卷積操作且具有深度結(jié)構(gòu)的神經(jīng)網(wǎng)絡(luò)的統(tǒng)稱,最早應(yīng)用于計(jì)算機(jī)視覺(jué),解決了當(dāng)時(shí)圖像分類難的問(wèn)題,現(xiàn)在也應(yīng)用于多種領(lǐng)域,其中,卷積成為模型提取特征基礎(chǔ)結(jié)構(gòu).1維卷積操作對(duì)腦電信號(hào)進(jìn)行提取,卷積操作把卷積核與輸入信號(hào)按位相乘并求和.這種操作可考慮周?chē)c(diǎn)對(duì)當(dāng)前點(diǎn)的影響,從而提取腦電信號(hào)的局部特征,卷積后的輸出特征為
(1)
式(1)中:x為信號(hào)的輸入特征;w為卷積核的權(quán)值;t0為信號(hào)當(dāng)前時(shí)刻;K為卷積核的大小.
將1維卷積操作拓展為矩陣操作,即
(2)
CNN模塊,如圖2所示.圖2中:Spatial Conv為空間卷積;Ave Pool是平均池化;Separable Conv為可分離卷積.CNN模塊主要包括卷積層、池化層、激活層,以及全連接層.卷積層的層與層之間通過(guò)局部連接、權(quán)值共享,大幅減少參數(shù)量的同時(shí),也提升了模型的魯棒性.隨著對(duì)機(jī)器學(xué)習(xí)研究的不斷深入,現(xiàn)階段的CNN模塊增加了批正則化層和丟棄層加快模型的訓(xùn)練并減少過(guò)擬合,使用ELU激活層替代線性整流函數(shù)(RELU),使模型取得更好的訓(xùn)練效果.
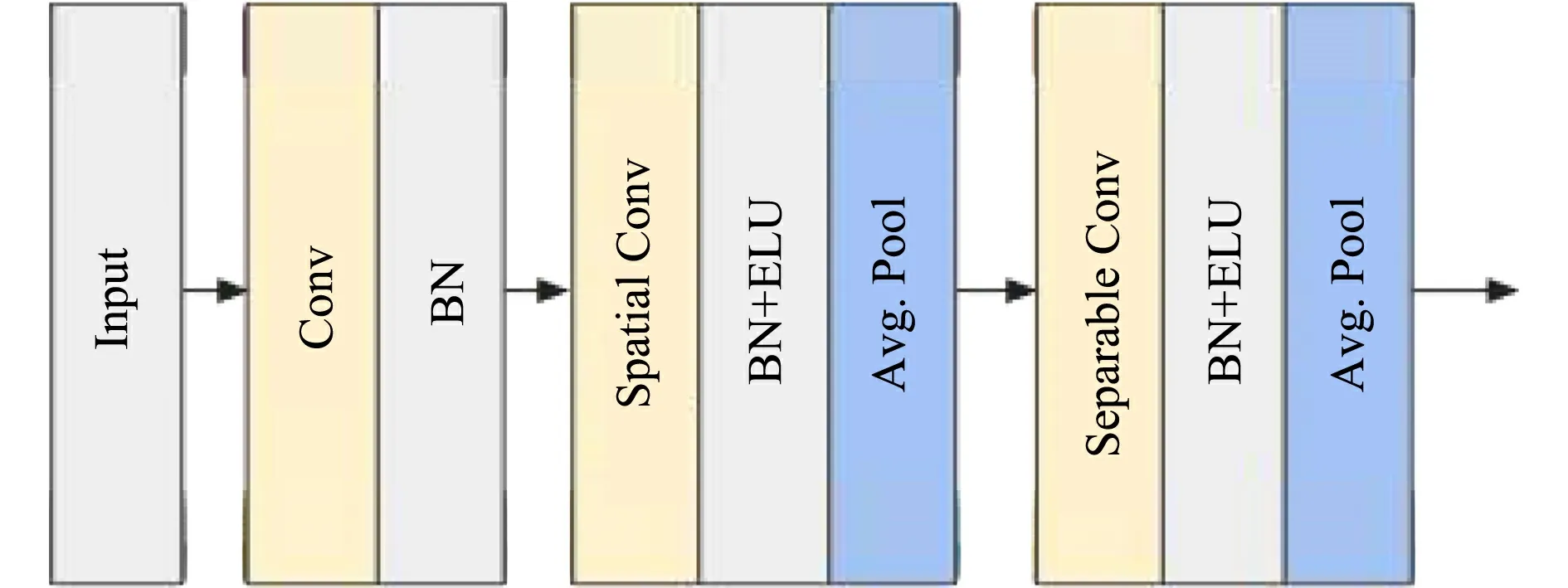
圖2 卷積神經(jīng)網(wǎng)絡(luò)模塊Fig.2 Module of convolutional neural network
端到端的CNN模塊作為基線模型可以自動(dòng)提取腦電信號(hào)的特征,提取分為3個(gè)部分.1) 使用F1個(gè)大小為(1,64)的卷積,主要提取頻譜特征;2) 使用D個(gè)大小為(C,1)的深度卷積,主要提取通道特征;3) 使用F1×D個(gè)大小為(1,16)的卷積,主要提取時(shí)域特征.基線模型在第2,3部分使用大小為(1,8)的平均池化減小的維度、ELU激活層;在第1,3部分使用丟棄層;在每個(gè)部分都使用批正則化層.
1.4 多尺度卷積模塊
MCNN包含了4組不同大小的卷積核,對(duì)信號(hào)提取特征,大尺度卷積核可以捕獲低頻率的整體特征,小尺度卷積核可以捕獲高頻率的局部特征,通過(guò)對(duì)局部和整體特征的整理,可以有效地增強(qiáng)卷積的特征提取能力,即
(3)
式(3)中:i為卷積第i的的分支;N為分支數(shù),N=4.
卷積神經(jīng)網(wǎng)絡(luò)第1,3層使用多尺度卷積,增強(qiáng)模型對(duì)頻域和時(shí)域信息的提取能力.多尺度卷積神經(jīng)網(wǎng)絡(luò)總體架構(gòu),如圖3所示.圖3中:Average表示取平均值.多尺度卷積1分別使用4組大小不同的卷積,其中,64取1/4的采樣率,可以提取4 Hz以上的頻譜特征.4組卷積可以分別提取4,8,16,32 Hz的頻譜信息,近似對(duì)應(yīng)腦電的θ,α,β波.由于卷積神經(jīng)網(wǎng)絡(luò)第2層后跟著一個(gè)(1,8)的平均池化,信號(hào)降采樣到32 Hz,故多尺度卷積2使用4組大小不同的卷積(圖3(b)),對(duì)(500.0,250.0,125.0,62.5 ms)信息進(jìn)行解碼,增強(qiáng)模型對(duì)不同時(shí)間信息特征的提取能力.

(a) 多尺度卷積1 (b) 多尺度卷積2圖3 多尺度卷積神經(jīng)網(wǎng)絡(luò)模型總體架構(gòu)Fig.3 Overall structure of multi-scale convolutional neural network model
1.5 通道注意力機(jī)制模塊
SE模塊啟發(fā)于卷積圖像領(lǐng)域2D SE模塊[16-17],能自適應(yīng)地關(guān)注重要的通道.SE模塊有兩個(gè)優(yōu)勢(shì):1) 經(jīng)過(guò)MCNN模塊輸出的特征存在一定的冗余,SE模塊可以除去非必要的特征信息;2) 在少量增加參數(shù)量和計(jì)算量情況下,增加模型的特征提取能力,關(guān)注更加重要的特征.SE模塊主要包括壓縮和激發(fā)兩個(gè)部分.壓縮部分主要解決通道相關(guān)性的問(wèn)題,通過(guò)對(duì)MCNN模塊提取的高維時(shí)序特征U進(jìn)行全局池化處理,將特征的時(shí)域維度T進(jìn)行壓縮,只留下通道維度m.第q個(gè)通道特征mq表達(dá)式為
(4)
式(4)中:Uq為第q個(gè)通道維度的時(shí)序特征;L為時(shí)序特征在時(shí)域維度的長(zhǎng)度;Fa表示取均值函數(shù).
通過(guò)兩層全連接層(先縮小再還原至原通道數(shù)C)完成激活,再通過(guò)權(quán)重W生成所要的權(quán)重信息,其中,W是通過(guò)學(xué)習(xí)得到的,第q個(gè)通道權(quán)重特征Sq表達(dá)式為
Sq=Fex(mq,W)=δ(W2(W1mq)).
(5)
式(5)中:W1和W2分別為兩層全連接的權(quán)值矩陣;δ為sigmoid激活函數(shù);Fex為激發(fā)函數(shù).
將通道權(quán)重與原特征層進(jìn)行加權(quán)處理,得到突出重要通道信息的時(shí)間序列,即
fq=Fscale(Uq,Sq)=Uq×Sq.
(6)
式(6)中:Fscale表示相乘函數(shù).
1.6 時(shí)域殘差模塊
TRN模塊加深卷積的層數(shù),Chen等[18]發(fā)現(xiàn)加深網(wǎng)絡(luò)的層數(shù)到一定數(shù)量之后,準(zhǔn)確率反而下降了.殘差結(jié)構(gòu)通過(guò)添加網(wǎng)絡(luò)直連結(jié)構(gòu),可以改善網(wǎng)絡(luò)層數(shù)增加帶來(lái)的梯度消失和網(wǎng)絡(luò)退化問(wèn)題,其表達(dá)式為
y=F(x)+x.
(7)
式(7)中:x為輸入特征,F(x)表示對(duì)x進(jìn)行卷積操作的輸出.
時(shí)域殘差模塊與殘差模塊有兩點(diǎn)不同:1) 時(shí)域殘差模塊采用因果卷積,阻止任何之前信息進(jìn)入到未來(lái),這樣輸出時(shí)間t只有t及之前的時(shí)刻;2) 時(shí)域殘差模塊采用空洞卷積,感受野指數(shù)型地增加.時(shí)域殘差網(wǎng)絡(luò)架構(gòu),如圖4所示.圖4中:Dilated Causal Conv為空洞時(shí)域卷積;Optional表示可選.

圖4 時(shí)域殘差網(wǎng)絡(luò)架構(gòu)Fig.4 Network achitecture of temporal residual convolutional
感受野計(jì)算公式為
RFS=1+2(KT-1)(2a-1).
(8)
式(8)中:RFS為感受野;a為時(shí)域殘差塊的個(gè)數(shù);KT卷積核大小.
MSTNet模型使用2個(gè)時(shí)域殘差塊,每個(gè)殘差塊由32個(gè)卷積核大小為4的空洞卷積構(gòu)成,故經(jīng)時(shí)域殘差模塊輸出的特征的一個(gè)點(diǎn)可以感受19個(gè)元素.將SE模塊輸出的維度為(32,17)的時(shí)間序列輸入到時(shí)域殘差模塊后,最后一個(gè)點(diǎn)已經(jīng)感受到所有時(shí)間維度的信息,故只需將最后一個(gè)維度為(32,1)的高維時(shí)間特征送入到分類器(使用Softmax)的全連接層,對(duì)信號(hào)進(jìn)行分類.
2 實(shí)驗(yàn)結(jié)果與分析
2.1 實(shí)驗(yàn)數(shù)據(jù)集
采用BCI Competition Ⅳ-2a公開(kāi)數(shù)據(jù)集[19]訓(xùn)練和評(píng)估EEG-MSTNet模型,它的數(shù)據(jù)量有限且數(shù)據(jù)包含在偽跡之中,因此,對(duì)腦電解碼來(lái)說(shuō)是一個(gè)十分具有挑戰(zhàn)的任務(wù).數(shù)據(jù)共有5 184個(gè)trials,受試者有9名(每名受試者在不同天做了兩個(gè)session,每個(gè)session有6個(gè)runs,每個(gè)runs有48個(gè)trials,左手12個(gè),右手12個(gè),雙腳12個(gè),舌頭12個(gè)),運(yùn)動(dòng)想象3~6 s(從6 s十字架消失后,開(kāi)始短暫休息).EEG通道有22個(gè)電極,EOG通道有3個(gè)電極,電極頻率為250 Hz,帶通濾波頻率為0.5~100.0 Hz.session1為訓(xùn)練集(有標(biāo)簽),session2為測(cè)試集.
2.2 實(shí)驗(yàn)設(shè)置
EEG-MSTNet模型由GPU顯卡(NVIDIA RTX-3080Ti 12 GB)進(jìn)行訓(xùn)練和測(cè)試,采用TensorFlow框架.訓(xùn)練配置如下:權(quán)重初始化均采用Glorot歸一;優(yōu)化方法采用Adam;學(xué)習(xí)頻率設(shè)置為0.001;批大小為64;訓(xùn)練采用分類交叉熵?fù)p失函數(shù),對(duì)每名受試者分別訓(xùn)練10次,盡可能保證所有模型達(dá)到最好的泛化效果,次數(shù)設(shè)置為1 000,采用提前停止技術(shù),容忍度設(shè)為50(也就是當(dāng)模型連續(xù)經(jīng)過(guò)50次訓(xùn)練后,準(zhǔn)確率沒(méi)有繼續(xù)提升,停止訓(xùn)練);訓(xùn)練集和測(cè)試集劃分比例為1∶1.
2.3 評(píng)估方法
采用準(zhǔn)確率Pa和Kappa系數(shù)ζk更準(zhǔn)確客觀地評(píng)估模型.Pa的計(jì)算式為
(9)
式(9)中:Ti為第i類中預(yù)測(cè)正確的樣本數(shù);Ii為第i類的樣本數(shù);n為類別的數(shù)量.
ζk的計(jì)算式為
(10)
式(10)中:n是類別的數(shù)量;Pe是預(yù)測(cè)與實(shí)際一致性的概率,當(dāng)Pe為0.8~1.0時(shí),概率幾乎完全一致,當(dāng)Pe為0.6~0.8時(shí),概率高度一致.
2.4 消融實(shí)驗(yàn)
為了探究EEG-MSTNet模型的有效性,采用消融實(shí)驗(yàn)評(píng)估EEG-MSTNet模型中每個(gè)模塊的效用.EEG-MSTNet模型中每個(gè)模塊對(duì)性能的貢獻(xiàn),如表2所示.表2中:t為訓(xùn)練時(shí)間.
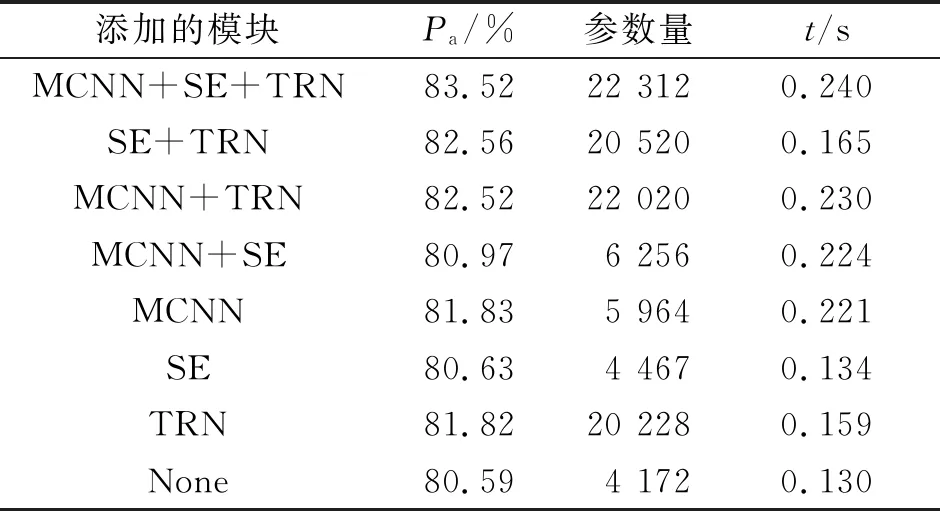
表2 EEG-MSTNet模型中每個(gè)模塊對(duì)性能的貢獻(xiàn)Tab.2 Contribution of each model in EEG-MSTNet model to performance of classification
由表2可知;None模塊(卷積神經(jīng)網(wǎng)絡(luò),基準(zhǔn)模塊)全面考慮時(shí)域、頻域和空域信息,平均準(zhǔn)確率為80.59%,與其相比,MCNN模塊的準(zhǔn)確率提升了1.24%.TRN模塊準(zhǔn)確率提升1.23%,SE模塊準(zhǔn)確率幾乎沒(méi)有提升;兩個(gè)模塊及以上準(zhǔn)確率均獲得較大的提升,SE+TRN模塊的準(zhǔn)確率為82.56%,準(zhǔn)確率比基準(zhǔn)模塊提升1.97%,說(shuō)明SE模塊要連接其他模塊才能發(fā)揮SE模塊的效果;MCNN+SE+TRN模塊比基準(zhǔn)模塊準(zhǔn)確率提升2.94%,其最高分類準(zhǔn)確率為95.83%,平均準(zhǔn)確率為83.52%.
由表2還可知;相比于基準(zhǔn)模型,MCNN模塊增加1 792的參數(shù)量,SE模塊增加295的參數(shù)量,TRN模塊將增加16 056的參數(shù)量,這是由于高維特征圖的數(shù)量是低維特征圖的32倍,導(dǎo)致卷積層的參數(shù)量劇增,可以改用可分離卷積,大幅降低參數(shù)量.由于采用了提前停止技術(shù),每個(gè)模塊訓(xùn)練輪數(shù)不一致,采用訓(xùn)練總時(shí)間除以訓(xùn)練輪數(shù)作為訓(xùn)練時(shí)間,可以看到SE模塊對(duì)訓(xùn)練時(shí)間的影響較小,而MCNN模塊對(duì)訓(xùn)練時(shí)間的影響較大,MCNN+SE+TRN模塊的訓(xùn)練時(shí)間為0.240 s,較基準(zhǔn)模塊需要多消耗0.110 s,處于可接受的范圍.
2.5 對(duì)比實(shí)驗(yàn)


表3 EEG-MSTNet模型與其他相似模型的平均準(zhǔn)確率比較Tab.3 Comparison of average accuracy of EEG-MSTNet modole with other similar modoles
EEG-MSTNet模型與近期研究模型的性能比較,如表4所示.由表4可知:采用3種模塊的EEG-MSTNet混合神經(jīng)網(wǎng)絡(luò)模型無(wú)論是在Pa還是ζk均優(yōu)于近期研究的模型.

表4 EEG-MSTNet模型與近期研究模型的性能比較Tab.4 Performance comparison of classification for the proposed model and recent research models
3 結(jié)束語(yǔ)
EEG-MSTNet模型可以端到端地進(jìn)行腦電信號(hào)的特征提取與識(shí)別,不需要手工提取特征,它主要由MCNN模塊、SE模塊和TRN模塊組成.MCNN模塊增強(qiáng)卷積神經(jīng)網(wǎng)絡(luò)的時(shí)頻域特征提取能力,將原始的EEG信號(hào)編碼為一個(gè)高維的時(shí)間序列.SE模塊通過(guò)壓縮與激發(fā)突出時(shí)間序列中最重要的通道信息.TRN模塊從時(shí)間序列中提取更高維的時(shí)域特征.消融實(shí)驗(yàn)表明,EEG-MSTNet模型的每個(gè)模塊都對(duì)分類性能的提升做出了貢獻(xiàn),表明了這種混合架構(gòu)設(shè)計(jì)的有效性.雖然每個(gè)模塊會(huì)增加模型的參數(shù)量和訓(xùn)練時(shí)間,但在可接受的范圍內(nèi).值得注意的是,使用SE模塊后要連接其他模塊,才能發(fā)揮SE模塊的效果.同時(shí),通過(guò)與其他模型進(jìn)行對(duì)比[24-25],EEG-MSTNet模型有很強(qiáng)的競(jìng)爭(zhēng)力.雖然EEG-MSTNet模型在運(yùn)動(dòng)想象領(lǐng)域進(jìn)行測(cè)試,但是其設(shè)計(jì)思路對(duì)腦電信號(hào)的其他領(lǐng)域甚至圖像語(yǔ)音領(lǐng)域都有很好的借鑒意義.
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
