基于CNN-GRU-CTC的藏族學生普通話發音偏誤檢測
2023-10-11 06:15:22梁青青周小燕趙春艷
蘭州文理學院學報(自然科學版) 2023年5期
關鍵詞:檢測
梁青青,周小燕,趙春艷
(蘭州文理學院 傳媒工程學院,甘肅 蘭州 730000)
普通話作為中國這一多民族國家的通用語言,在推廣文化教育、提升全民族素質、繁榮社會經濟、促進各民族、各地區之間的交流發揮著非常重要的作用[1].作為藏族學生,他們不僅要精通藏語,還要掌握普通話,這不僅可以提高藏族學生的語言表達能力,還有利于他們適應新時代復雜多變的社會結構.由于大部分藏族學生從小就用藏語交流,加上漢字儲備量不夠,導致藏族學生在學習普通話時存在不會發音、發音不準確、自信心不足等問題[2]近年來,計算機輔助語音訓練系統 (Computer Assisted Pronunciation Training System,CAPT )因可以幫助學習者及時發現和糾正錯誤發音,避免重復錯誤發音形成習慣[3],提高學習者的學習效率而受到學者的關注.
計算機輔助語音訓練系統的關鍵技術之一是精確的語音識別技術.卷積神經網絡(CNN)不僅可以顯著提高語音識別的準確度,而且已經成功應用于CAPT中.IBM、微軟、百度等多家機構相繼推出了自己的CNN模型,在英文領域識別準確率達到95%,科大訊飛語音研究院王海坤等[4]提出了深度全序列卷積神經網絡的語音識別框架,并為漢母語人群開發了普通話在線訓練系統.
基于上述研究,本文針對以藏語為母語的學習者發音偏誤問題進行研究,提出基于CNN-GRU-CTC的端到端的發音偏誤檢測方法[5],設計并錄制了藏族學生的普通話發音偏誤語料庫.該語料庫覆蓋了所有音節,設計了64種偏誤類型,錄制了7 200句語音語料進行測試,通過實驗精確找出具體的發音偏誤,并給出反饋,為他們提供面向計算機輔助發音訓練系統的技術.
1 語料庫設計
1.1 漢語發音特點
漢語屬于漢藏語系,現代漢語是語素-音節文字.從記錄的語音單位來看,一個漢字和一個音節是相對應的.一個漢字的讀音就是一個帶調音節.除了零聲母外,音節由聲母和韻母構成,而韻母又包括韻頭、韻腹和韻尾.一個音節可以沒有輔音聲母,也可以沒有韻頭和韻尾,但都有聲調和韻腹.構成音節的漢語拼音有23個聲母,24個韻母,陰平、陽平、上聲和去聲4個聲調.
1.2 藏語特點
藏語是由字母組合形成的拼音文字,每個字母都有自己的發音.字母的組合是由音與音之間的拼合而組成的.藏語有30個輔音字母和4個元音字母,即所有藏文字都是由這34個字母組成的.
1.3 文本語料設計
發音偏誤檢測需要對藏語發音者與漢語普通話發音偏誤情況進行分析,文本語料庫應具備以下條件:①文本語料庫應覆蓋漢語普通話中所有由聲母、韻母和聲調組合而成的音節;②藏語在發音時濁輔音和輔音韻尾趨于簡化,在構建文本語料庫時需要對這兩種情況做到全覆蓋;③需要考慮聲調發生變化的情況,例如:由2個三聲的字組成詞時,第1個字通常需變為二聲;一些詞語及句子中存在聲調變成輕聲的情況.
1.4 語音語料的錄制
(1)錄音者應該盡量選擇普通話發音不是很好的且藏語為母語的學生,他們平時說普通話較少,發音更容易出錯,對發音偏誤檢測更具有代表性;
(2)錄音者在說普通話時應存在一定的口音,這樣對偏誤檢測覆蓋更廣泛;
(3)錄音環境選擇無背景噪聲的專用錄音棚,錄音設備選擇專用麥克風,通過電腦軟件提示聲音的頻率和音量大小,保證聲音大小前后一致,增加對檢測的準確度;
(4)音頻語料的采樣率設置為44.1 kHz,采樣大小為16位.
按照以上要求,本文設計了1 200句以藏語為母語的學生學習普通話的文本語料,并以此建立藏族學生學習普通話的偏誤語音語料庫.語料庫由6名(3男3女)藏族的大一學生參與錄制.
2 模型建立
采用基于語音識別的框架,分別考察發音音素偏誤和發音聲調偏誤.
2.1 發音偏誤整體檢測流程
文中使用基于自動語音識別(Automatic Speech Recognition,ASR)框架來進行發音偏誤檢測[6],具體檢測的流程如圖1所示.系統首先輸入要檢測的語句,將學習者的語音通過ASR檢測器來進行檢測識別,同時通過發音字典得到聲學模型的建模單元和語言模型建模單元間的映射關系,以及對應的標準化轉錄[7];然后,系統根據識錄是否一致來判斷發音的正確性;最后,根據二者不同向發音者反饋糾正方法.

圖1 發音偏誤檢測流程
2.2 發音偏誤CNN-GRU-CTC模型的建立
卷積神經網絡(CNN)由輸入層、隱含層和輸出層組成,隱含層包括CNNV卷積層、ReLU激活層、Pool池化層、FC全連接層,具有學習能力[8].本文利用深度全序列卷積神經網絡進行建模.它將一句語音轉換為一張圖像作為輸入,避免語音信號進行傅里葉變換后使用濾波器來提取特征導致頻譜上信息的丟失.該模型由5部分組成,具體結構如圖2所示.

圖2 CNN- GRU-CTC結構
第1部分為輸入層,輸入完整包含原始頻譜信號的二維語譜圖.由于使用梯度下降算法進行學習,該數據不能直接放進卷積神經網絡進行訓練,因此,需要對其進行標準化處理.為了使批處理中的所有語句長度相同,需要對輸入數據進行零填充;第2部分是卷積,主要對輸入數據進行特征提取,這一部分包含了6個CNN層,2個最大池化MaxPool層,然后是對其進行歸一化處理.這部分通過對輸入層的數據進行提取和處理,得到詳細的聲學特征參數;第3部分是GRU層,它可以更好地捕捉深層連接,并改善梯度消失問題,用來獲得更詳細的時間聲學特征;第4部分是時間分布密集層(MLP)層[9],該層輸出值被傳遞到Softmax邏輯回歸進行分類輸出;最后一部分是CTC輸出層,用來生成預測音素序列.
3 實驗及結果分析
3.1 模型訓練
該模型將標準發音庫作為訓練集,將偏誤發音庫作為測試集,語譜圖作為整個模型的輸入特征參數[10].首先對語音信號進行加窗、分幀和提取語譜圖.本實驗使用的窗函數為漢明窗,以20 ms為一幀,幀移為10 ms.卷積層是由3個卷積-卷積-池化對組成,卷積層參數包括卷積核大小、步長和填充,6個卷積層的卷積核大小設置為3×3,步長為2×2.MaxPool最大池化層左右是特征融合和降維,每個池化層的池化窗口大小設置為2×2.訓練過程中學習率 (Learning Rate)設置為0.008,批次大小(Batch Size)設置為16,數據輪次(Epoch)設置為300次,采用 Tensorflow和Keras工具包來實現模型訓練.
3.2 評價指標
實驗的結果共有4種:①正確接受(True Acceptance,TA).一個待測試正確發音樣本,經過算法對比被檢測為正確發音;②錯誤拒絕(False Acceptance,FA).一個待測試正確發音樣本,經過算法對比被檢測為錯誤發音;③錯誤接受(False Acceptance,FR).一個待測試錯誤發音樣本,經過算法對比被檢測為正確發音;④正確拒絕(True Rejection,TR).一個待測試錯誤發音樣本,經過算法對比被檢測為錯誤發音.
根據這4種檢測結果對系統的性能通過錯誤接受率(False Acceptance Rate,FAR)、錯誤拒絕率(False Rejection Rate,FRR)、檢測準確率(Detection Accuracy Rate,DAR)來衡量.FAR(式1)表示發音者的錯誤發音被系統認為正確的百分比,FFR(式2)表示發音者的正確發音被系統認為錯誤的百分比,DAR(式3)表示系統的檢測結果與發音者的發音結果一致的百分比,這3個評計算公式為:
(1)
(2)
(3)
3.3 實驗結果
在上述3個評價指標中,在保證較高正確率的前提下,降低另外兩類錯誤率.實驗結果表明,在該模型下,系統檢測準確率為88.55%,錯誤拒絕率為7.16%,聯合錯誤率為14.94%,與文獻[11-13]相比各個指標都取得了較好效果,不同模型實驗結果如表1所列.同時本文的數據不需要手工標注和強制對齊數據,該模型可以檢測聲母、韻母和聲調偏誤,檢測范圍更廣.
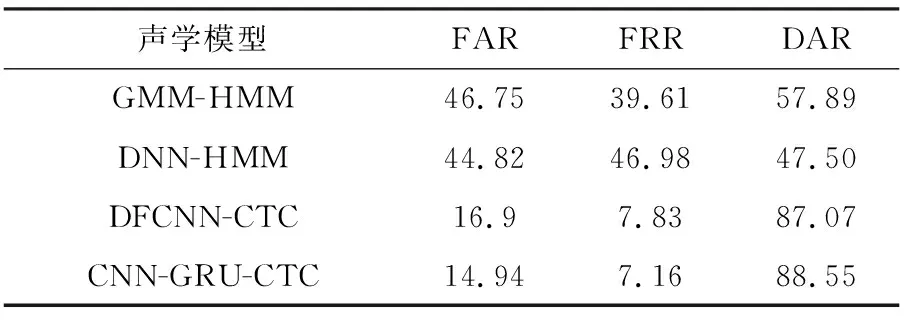
表1 不同模型實驗結果
為了分析具體的發音偏誤情況,本文將發音偏誤分為聲母偏誤、韻母偏誤和聲調偏誤3種類型,并對其做了統計,對比情況如圖3所示.

圖3 3類偏誤占比對比
從圖3可知,藏族學生在學習普通話時聲調的偏誤最多,其次是韻母,聲母相對比較容易掌握.雖然漢語和藏語都屬于同一個語系,但是這兩者的聲調系統差異較大,在學習中需要加強.
由于聲調的偏誤較多,本文在陰平、陽平、上聲、去聲和輕聲中分析了每種聲調的偏誤情況,結果如圖4所示.
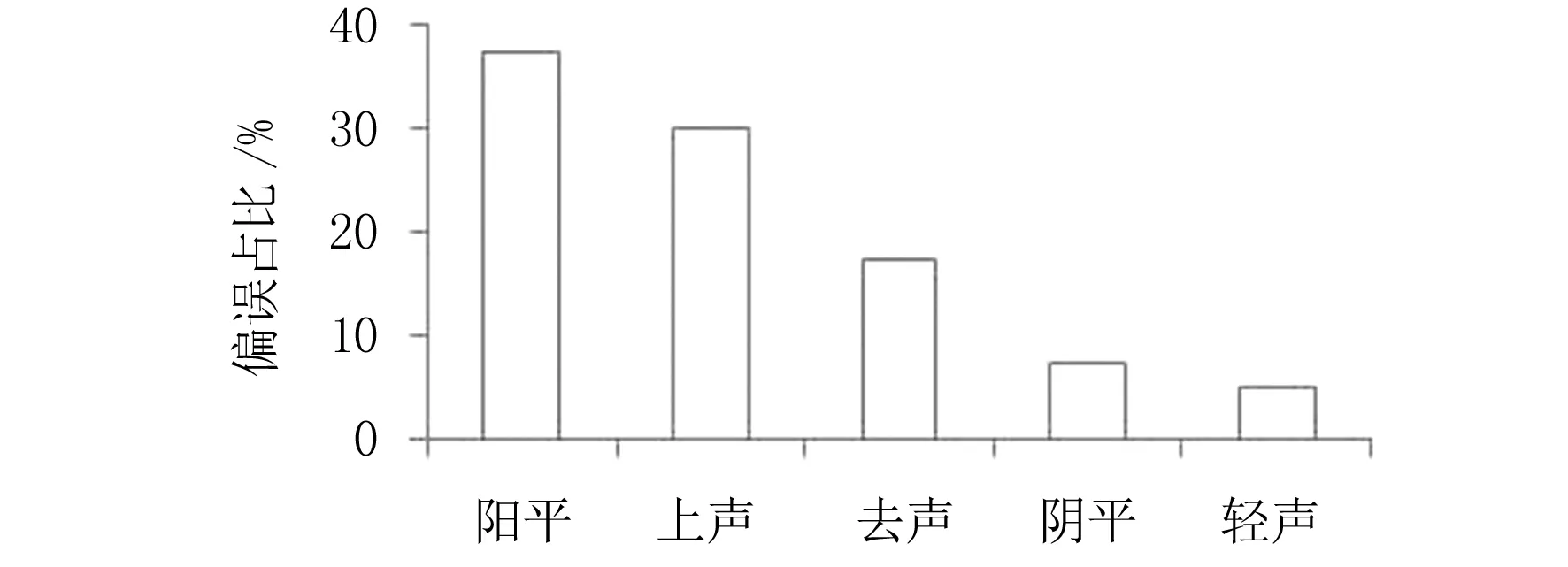
圖4 5種聲調發音偏誤檢測結果
從圖4可知,藏族學生在學習普通話時,對陰平、上聲和去聲的區分程度較差,在學習的過程中需要對這3種聲調進行加強.陰平和輕聲相對比較容易感知,學習起來比較容易.
實驗中藏族學生對普通話的21種聲母感知檢測如圖5所示.實驗結果表明,藏族學生在普通話發音中,存在n與l、g與k、h與f分不清楚的情況,舌根前音z、c、s 和舌根后音zh、ch、sh也容易被混淆,這些聲母在學習中本就是難點,因此這幾種情況需要特別加強練習.
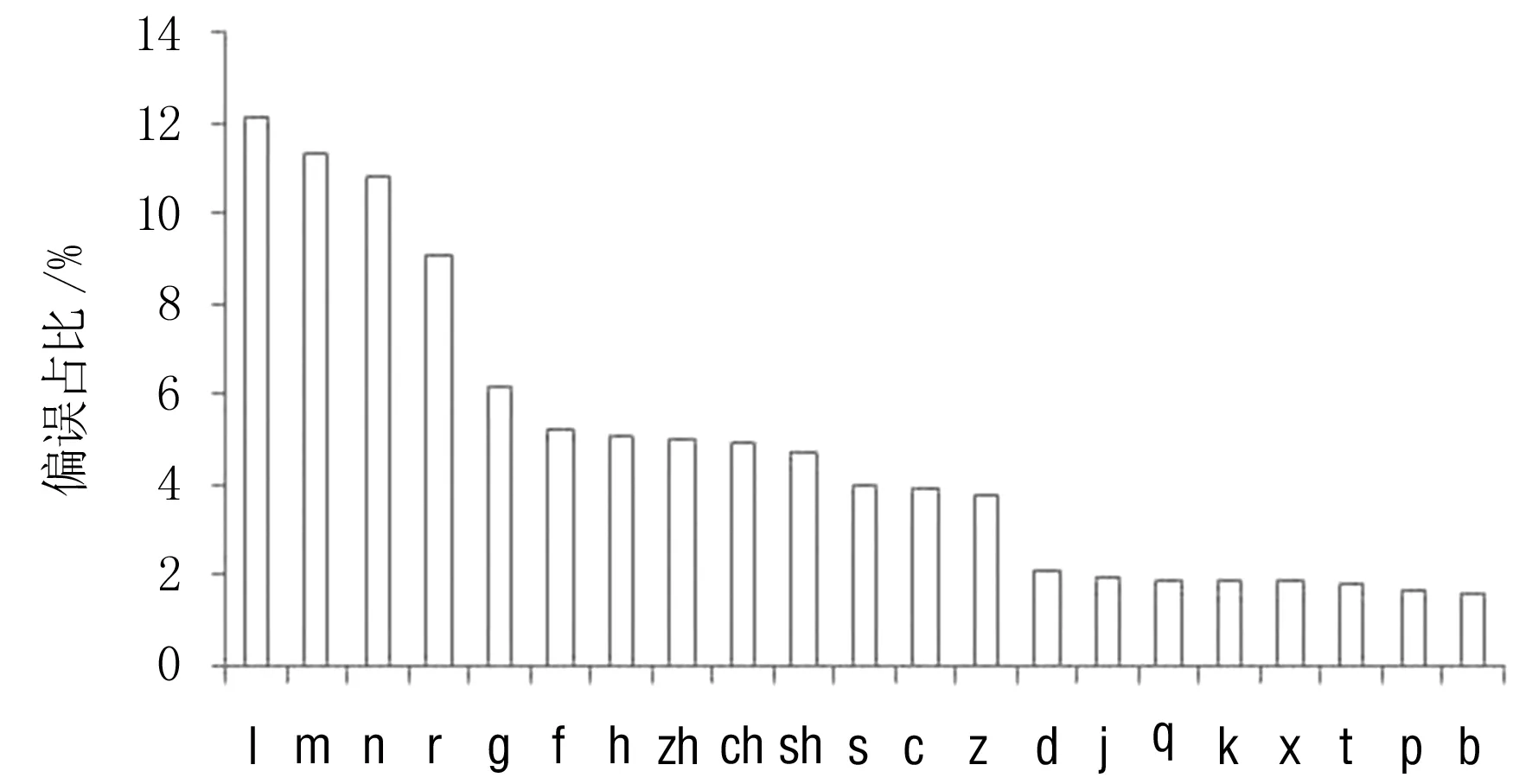
圖5 21種聲母發音偏誤檢測結果
38種韻母發音偏誤統計結果如圖6所示,本實驗重點研究前10種偏誤情況,這10種韻母發音偏誤的統計結果如圖7所示.結果顯示,錯誤頻率最高的為“Ng”,也就是日常的“嗯”字,該音容易被發音為“en”.另外發音偏誤主要集中在韻尾為“ng”的情況,也就是普通話中的后鼻音,多數情況下這種音節容易被發音為前鼻音,以上結果需要在學習時加強關注.
圖6 38種聲母發音偏誤檢測結果
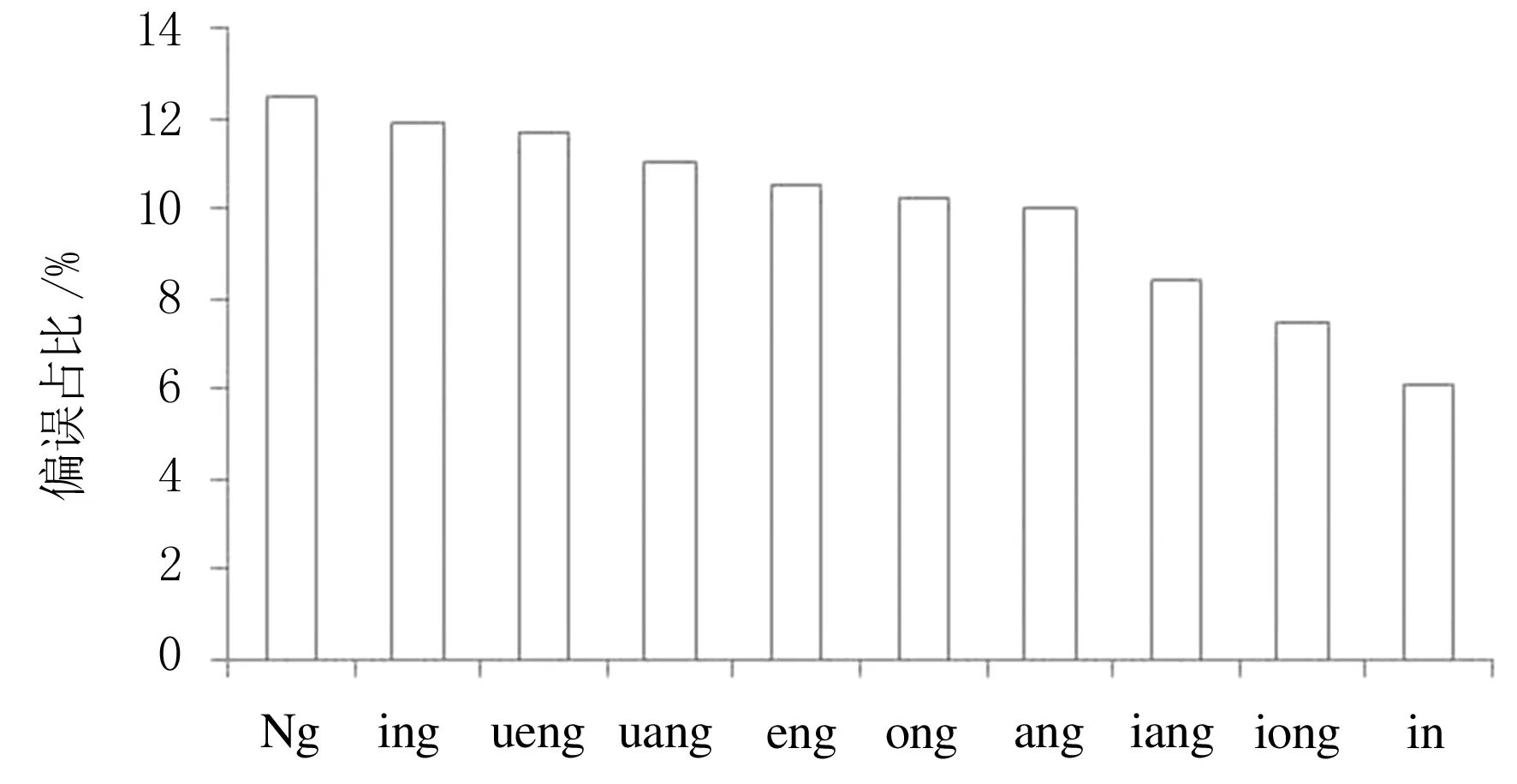
圖7 10種高頻韻母發音偏誤檢測結果
4 結論
本文設計并錄制了藏族學生學習普通話的發音偏誤語料庫,建立了基于CNN-GRU-CTC模型的發音偏誤檢測系統.實驗結果表明該方法可以有效提供發音偏誤信息,為藏族學生學習普通話提供幫助.今后我們會選擇更多來自不同方言區的人加入語料錄制,繼續完善語料庫建設,將其它深度學習方法應用到發音偏誤檢測上提高檢測精度.
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
