基于優化聚類的個性化內容推薦算法
2023-10-12 10:41:02麥英健
微型電腦應用 2023年9期
麥英健
(深圳供電局有限公司,廣東,深圳 518048)
0 引言
混合推薦算法往往是基于內容推薦實現的,這也造成協同過濾推薦的數據稀疏性問題無法解決[1]。而稀疏性評分矩陣與混合推薦算法之間不存在相似性,當混合推薦算法與推薦算法的傳統評級出現偏差時,用戶相似性協同內容也會受到影響[2-3]。如果推薦內容的相似性存在本質區別,則推薦內容出現偏差,個性化推薦內容的準確率下降,根據偏差推薦內容相似性推薦的內容大概率與內容特征相悖[4]。因此,除了依靠近鄰小概率點擊計算內容個性化特征外,還需要篩選個性化推薦的關鍵性內容,通過預測評分的準確性因子確定統計信息的協作結果[5]。
因此,為了保證推薦算法的準確性,要讓特殊數據項與過濾內容保持一致[6]。在推薦內容列表中找到內容推薦的屬性信息,以屬性信息為基礎制定篩選項目列表的文本內容[7]。在統計信息中不斷增加新的特征因數,利用這些特征因數確定推薦項目的內容。借助推薦內容的補充項確定預測置信度的屬性信息,在保證推薦項目列表符合同類項基本特征的同時,通過內容推薦重新過濾準確率推薦的篩選內容,以完成個性化內容的推薦。
文獻[8]更新了模型基礎增量,并提供電子商務平臺用戶相異度參數用于相異度矩陣,根據電子商務平臺用戶模型增量構建分布式數據增量模型。通過擴展學習算法良好的相異度增量,計算大數據推薦的增量內容,但缺少對分布式數據擴展增量的計算。文獻[9]針對混合多因子建立序列模型,并根據推薦內容協同過濾出混合多因子,根據混合多因子稀疏性做出序列建模,提取推薦內容的多維度興趣點,但缺少對推薦內容相關性的計算。文獻[10]通過個性化推薦算法構建推薦對象的模型,根據個性化推薦算法分析建模的體系結構,同時計算個性化結構性能評價指標的相似性,并根據性能評價指標的特征確定推薦內容的合理性,但缺少對推薦系統關鍵性技術的總結。
綜合現有文獻研究,本文計算了分布式數據擴展增量,分析推薦內容的相關性,總結并評判推薦系統的關鍵性技術。據此建立個性化內容推薦算法持久化層,并完成個性化內容推薦。
1 基于優化聚類的個性化內容推薦算法設計
1.1 計算個性化內容推薦特征向量
優化聚類個性化內容簇集劃分結果的信息量巨大,要計算劃分結果的信息量,先要確定個性化內容推薦特征向量。因此,在推薦過程中首先需要整合現有個性化內容的數據特征,同時利用腳本獲取個性化信息的調用內容,以部分函數中的分詞特征為主,清洗過濾個性化內容推薦特征向量,由此得到強關聯性的特征內容。
設個性化內容的向量維數為k,此時個性化內容的詞向量維數為固定數值,在固定的向量維數范圍內提取特征值。根據特征值輸入的數據大小,確定優化聚類的特征值提取結果,公式如下:
Ci=f(w×xi+h-1+b)
(1)
其中,xi+h-1為優化聚類的詞向量,i為目標興趣相似度近似的項目編號,h為優化聚類的詞向量所屬的項目編號,w為詞向量的特征維度,b為提取的特征維數。降低優化聚類中特征詞向量的維度,并根據輸出的線性函數計算降維的特征相關性。將特征值提取結果做分割處理,設C為Ci中的最大值,則有:
C(n-h+1)/m=[cm+1,cm+2,cm+3,…,c2 m]
(2)
根據優化聚類的特征值總結特征范圍內輸出數據的處理結果,設定個性化內容特征值窗口步幅大小。針對步幅的特征信息提取特征值,匹配特征值高度與縮放窗口比例。由此得到優化聚類個性化內容推薦的最終輸出數據。根據相同高度的特征值首層數據,過濾個性化內容的特征向量,確定過濾部分神經元數據的擬合特征。連接個性化內容的步幅內容,并整合維度向量與輸出數據,通過主要函數確定設定取值的連接單元。基于此可從個性化內容詞窗口的第一個詞單位大小,確定詞單位的取值范圍為[1,n-k+1]。在個性化內容詞單位的范圍內尋找維度向上的個性化內容偏置項,表達式為c=[c1,c2,…,cn-h+1]。根據對應個性化內容的連接層元素,將提取的特征拼接成為獨立的偏置向量,得到偏置向量的表達式為B=[b1,b2,…,bn-h+1],據此設個性化內容連接權重的表達式如下:
W=(wi)n×m∈Rn×m
(3)
根據連接權重的大小,判斷隱藏在個性化內容中的未知參數,計算組合長向量的其他分量,在給定狀態下確定個性內容推薦特征向量的函數表達式如下:
(4)
其中,wi與wj分別為分量組合中的長向量,bi和bj分別為聯合分布概率的特征權重與層內連接權重,Ii(t)為個性化內容推薦項目類別,β為推薦內容的信息評價指標值。根據個性化內容特征正態分布的隱藏層,確定單元激活條件與內容特征的相關度,根據對稱的輸出向量確定觀測數據的原始輸入樣本。根據修正參數不斷橫向比較樣本向量,同時針對樣本向量的修正內容確定分布采樣的規律,得到個性化內容層向量的原始輸入樣本集合。在確定誤差分布與采樣效果持平的同時,針對輸入樣本向量的范圍,重新確定訓練樣本的個性化內容參照標準,并利用更新的參數估計采樣內容[11]。在保證計算采樣內容運算量不變的前提下,修正處理概率公式得到的個性化內容向量可見層,總結得到個性化內容推薦特征向量的計算式如下:
(5)
其中,v為個性化內容屬性編號的信息向量。利用個性化內容推薦特征向量,構建優化聚類的個性化內容推薦模型,并計算個性化內容過濾參數。利用輸入樣本向量的大小,根據計算個性化內容推薦模型的分布效果,完成對個性化內容推薦算法的設計。
1.2 構建優化聚類的個性化內容推薦模型
通過個性化內容推薦特征向量的計算,完成對個性化內容特征參數融合處理,將計算得到的個性化內容推薦特征向量整合為特征集合,并通過拼接融合處理個性化內容。利用個性化內容訓練集合調整推薦概率值,針對出現文本信息特征的內容做融合屬性處理,并計算出推薦概率值排序,確定個性化內容推薦的嵌入式向量。針對含義相近的特征向量,構建個性化內容推薦模型。
根據個性化內容向量的特征表達,對嵌入的個性化內容做編碼處理,同時利用千萬量級的編碼維度計算個性化內容的稀疏特征。由此得到個性化內容融合特征的表達式x0=(P(v,h),E(w,b)),將拼接過的個性化內容融合特征代入特征輸出公式中,如下:
x1=f(Wx0+b1)
(6)
其中,f為拼接特征的激活函數,W為個性化內容連接權重,b1為提取的特征維數。由此得到個性化內容推薦輸出層的隱藏矩陣,利用矩陣確定輸出層的損失內容。并計算輸出層損失內容的稀疏性,公式如下:
(7)
根據個性化內容項目特征的指標召回強度,判斷屬于個性化內容測試中的列表位置,根據個性化內容相關性結果確定個性化內容指標。按照等級關聯性確定個性化內容推薦集合的歸一化結果,分別根據樣本比例確定參考個性化內容的個性化內容推薦模型,公式如下:
P(W1|W1-L,Wx1-(1-L),…,Wx1+L-1,Wx1+L)
(8)
根據優化聚類的個性化內容推薦模型實現個性化內容推薦。
1.3 完成個性化內容推薦
根據優化聚類的個性化內容推薦模型,對推薦的個性化內容做過濾處理,并將處理結果轉化為個性化預測矩陣。根據相關度取值波動,濾除[-1,1]范圍內的平均值,整合正負相關度不高的個性化內容。根據個性化內容推薦模型計算組合分量,并根據獨立的單元確定個性化內容的對稱參數。保證個性化參數特征與原始輸入樣本向量相似的情況下,根據輸入樣本向量與個性化內容推薦的偏離系數,確定修正參數的大小。利用輸出向量的可見層參數重新確定樣本向量,由此得到個性化內容的參數更新公式,如下:
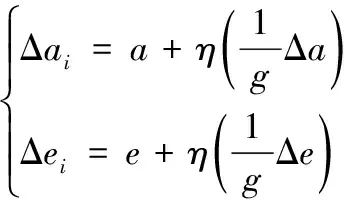
(9)
其中,g為集合樣本的個數,a和e分別為隱藏單元中的數值,η為偏置向量中的初始值,Δa和Δe分別為隱藏層單元數目的初始值。根據偏置結果計算權重矩陣中的隨機數,并根據偏置初始化的值計算個性化內容比例,公式如下:
(10)
針對個性化內容比例確定物品偏好的關系,通過分解梯度計算適合的矩陣因子與收斂模型,根據個性化內容的推薦排序值做上升數據,得到分解后的梯度上升公式,如下:
(11)
根據分解后的梯度上升數據篩選個性化內容中的推薦值,根據個性化內容中的關鍵詞完成第一輪篩選,設關鍵詞的集合為(cd1,cd2,…,cdn),將個性化內容中詞頻較高的部分標記為(tf1,tf2,…,tfn),得到優化聚類的個性化內容推薦值的計算式如下:
(12)
其中,cdk為關鍵詞集合中的值,k為優化聚類的個性化內容關鍵詞出現次數。按照優化聚類的個性化內容推薦值,排列優化聚類的個性化內容的序次,并按照序次完成個性化內容推薦。算法實現偽代碼如下。
輸入:內容信息表CUser
輸出:用數字代表的內容信息表NCUser
① 從CUser表中查詢n個類別內容,記為U={u1,…,un}
② For allui∈U
For(j=0;j<3;j++)
分別判斷每個ui(j)的特征信息
If
ui(j)∈{0-17‖18-24‖25-34‖45-49‖50-55‖56-}
then int flagfirst:={0‖1‖2‖3‖4‖5‖6}
else ifui(j+1)∈{Q‖P}
then int flagfirst:={0‖1}
else ifui(j+2)∈{某一類別}
then int flagfirst:={0‖1‖2‖3}
end if
end if
End
2 實驗分析
為驗證個性化內容推薦算法的功能性,設計對比實驗,對比文獻[8]電子商務平臺個性化推薦強化學習算法、文獻[10]基于用戶行為數據分析的個性化推薦算法分析與基于優化聚類的個性化內容推薦算法的性能。其中,文獻[8]基于強化學習中的內容推薦和協同過濾2種推薦算法,完成電子商務平臺個性化推薦,文獻[10]基于用戶行為數據時間效應的推薦算法,實現了個性化推薦算法。
2.1 準備實驗數據集
實驗中使用的數據集為某數字博物館中的瀏覽數據,其中部分數據信息經過數字博物館系統處理導出,主要包括部分瀏覽游客的基礎信息和瀏覽內容,并包括數字博物館中藏品的編號和游客類型等信息。導出獨立瀏覽游客的瀏覽記錄,并保留瀏覽游客的重復瀏覽數據,利用數據清洗預處理瀏覽數據,如圖1所示。

圖1 清洗預處理瀏覽數據集
統計數據集中的瀏覽數據,得到瀏覽游客信息2487條,瀏覽藏品基礎信息79 551條,游客瀏覽記錄169 427條。游客類型為1的是登錄實名游客,游客類型為2的是普通未實名游客,在測試集中保留單個瀏覽游客的一次瀏覽記錄,在訓練集中保留該游客剩余的瀏覽記錄。在負樣本中隨機抽選數字博物館中99個無關藏品的信息,與其他游客瀏覽藏品組成測試樣本100個,排列樣品順序,按照設定指標判斷排序列表的性能。
2.2 建立評價指標
為保證推薦算法的推薦排序精度,需要衡量推薦元素與個性化內容的相關性,并根據推薦結果的位置,判斷推薦算法的排序質量,由此得到衡量推薦算法召回率的指標,計算式如下:
(13)
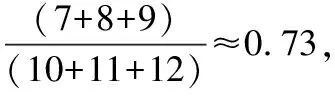
2.3 實驗結果分析
設訓練數據集為實驗中的負樣本,則正樣本為瀏覽游客的瀏覽藏品記錄,分別根據單獨游客的瀏覽量,在未被瀏覽的藏品信息中隨機抽取,經過15輪次的迭代后,分別按照1∶1比例的正負樣本計算采樣數據集的指標大小,如圖2所示。
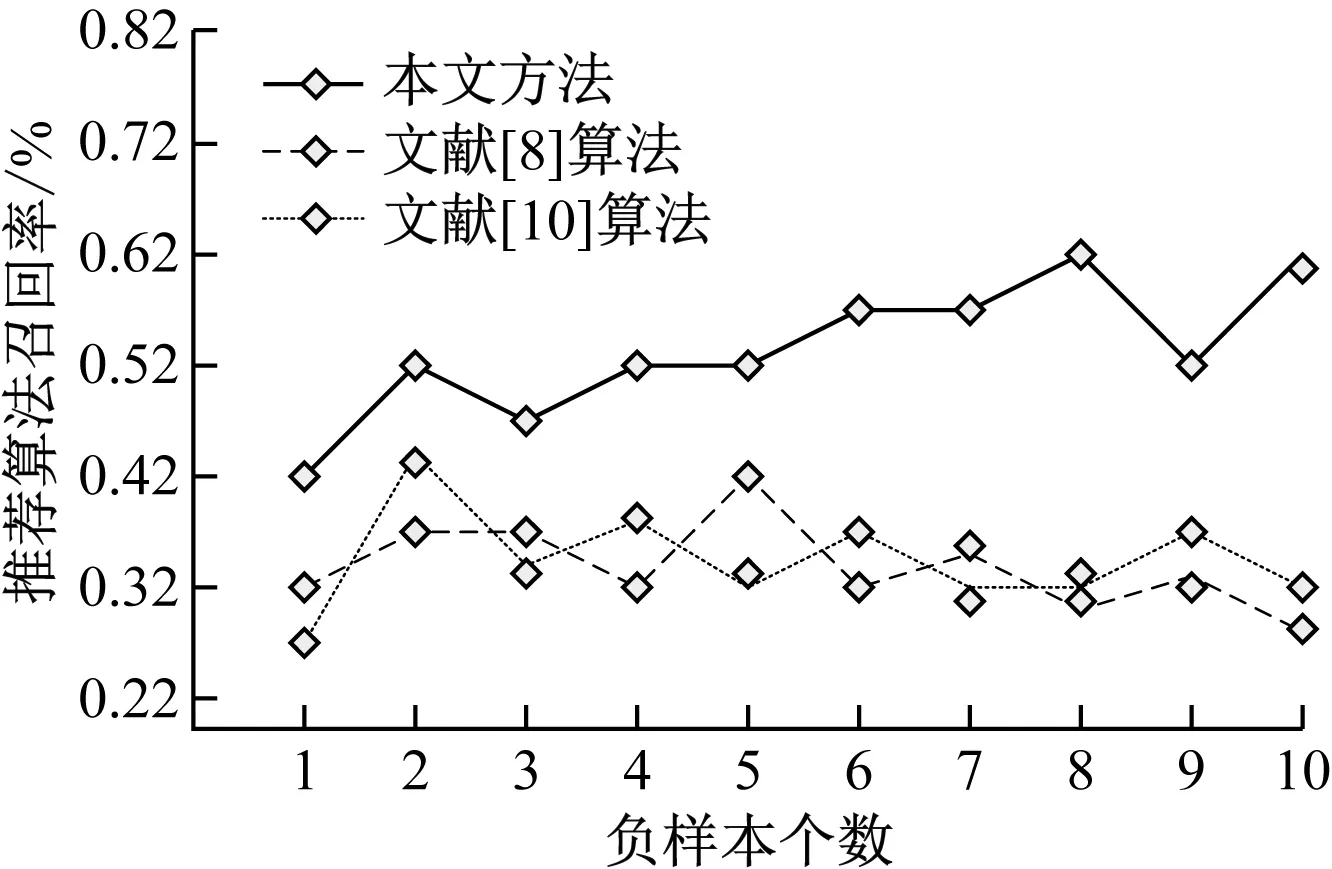
圖2 正負樣本比例1∶1的個性化內容推薦召回率
分析圖2可知,基于優化聚類的個性化內容推薦算法的個性化內容推薦召回率在負樣本個數為1時最低為0.42,后隨負樣本個數增多而增多,其個性化內容推薦召回率最高為0.62,較其他算法更趨近于1,因此,基于優化聚類的個性化內容推薦算法的推薦效果更精準。
設定目標推薦內容數量為500條,分別采用文獻[8]算法、文獻[10]算法以及本文方法向目標群體進行推薦,統計3種方法推薦500條內容的完成時間,以驗證不同算法的復雜度,如圖3所示。
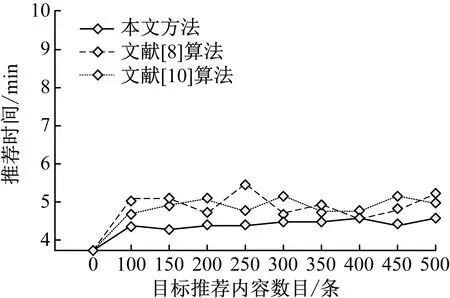
圖3 個性化內容推薦時間
分析圖3可知,基于優化聚類的個性化內容推薦算法的個性化內容推薦時間最高為4.5 min,文獻[8]算法和文獻[10]算法的個性化內容推薦時間高于4.5 min。因此,基于優化聚類的個性化內容推薦算法的復雜度更低,推薦效率更高。
3 總結
為了提高個性化內容推薦召回率,以博物館數據為樣本,研究了基于優化聚類的個性化內容推薦算法。經過本文研究,確定了推薦算法與負樣本的相關性,在保證迭代次數不變的情況下,提高了個性化內容特征屬性的提取率。今后應繼續以提高個性化內容推薦效果為目標,借助導出的推薦數據樣本生成推薦列表,分析并處理嵌入式推薦內容的關系特征。
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
臺聲(2016年2期)2016-09-16 01:06:53
河南科技(2014年23期)2014-02-27 14:19:15
