基于YOLO-RW模型的機器視覺原木端面識別定位
2023-10-12 07:12:56曾小山張小波
森林工程 2023年5期
曾小山,張小波
(江西環境工程職業學院 汽車機電學院,江西 贛州 341002)
0 引言
露天堆放的原木受到存放時間、存儲地點、天氣和光線等多種因素的影響,導致部分原木端面出現了裂縫和霉菌等缺陷。此外,一些原木在采伐時遭受了切割和割傷等情況,給原木端面圖像的采集和檢測帶來了很大的困難,影響了圖像的正確識別效果。
針對上述問題,相關人員進行了一些有益的探索和研究[1-5]。例如,以原木剖面圖為實例,欒新等[1]設計了一種分層分類器,該分類器可以單獨識別目標,成功解決了不規則端面的模式匹配問題。梅振榮[2]則采用最小二乘法橢圓擬合的方案,解決了原木端面的處理和徑級識別問題。林麗華[3]對多尺度小波變換邊緣檢測算法進行了改進,主要針對原木圖像質量進行了優化,優化后的算法在保證原木輪廓邊緣完整性和連續性的同時,大幅提高了原木圖像的質量。霍東旭[5]采用了基于Canny算法的邊緣檢測方法對原木圖像進行處理,通過去除噪聲和計算邊緣振幅,成功地檢測出更多原木端面的邊緣細節,優化后的方法顯著提高了原木端面圖像的清晰度和邊緣識別率。趙亞鳳等[6]采用自適應閾值分割、隨機森林分類器的訓練和預測以及圖像增強算法,成功解決了在有陰影的圖像中進行分割的問題。這種方法不僅能夠有效地進行陰影消除,還可以提高圖像的識別準確率。然而,以上方案的算法復雜度較高,導致原木端面識別的效率不高,同時在圖像信息處理時可能會出現信息不完整的情況,從而可能導致檢測遺漏并降低系統的可靠性。此外,自適應閾值響應滯后等問題也會影響系統的性能。
目前,深度學習技術在圖像處理領域取得了巨大進展,其中基于You Only Look Once(YOLO)模型的目標檢測方法得到了廣泛的應用。本研究提出一種名為YOLO-Raw Wood (YOLO-RW)的新型深度學習模型,專門應用于原木木材材積圖像的端面識別和定位。YOLO-RW模型結合了各個版本的YOLO模型的優缺點,并在數據增強、模型結構和損失函數等方面進行了優化,從而提高了模型的精度和魯棒性。通過試驗,本模型能夠有效地緩解原木端面的裂紋、霉菌、切割痕跡、復雜背景以及陰影等干擾因素,大幅提升了圖像中的原木端面目標識別準確率,為實現原木材積的自動檢測奠定了基礎。
1 YOLO模型介紹
YOLO是一種基于深度學習的目標檢測模型,將目標檢測問題看作是一個回歸問題,通過一個神經網絡直接預測出目標的類別和位置。YOLO算法在物體檢測上具有速度快、檢測效果好等優點,因此在目標檢測領域得到了廣泛應用。YOLO從v1到v7版本進行了多次改進[7],下面將對其進行簡要介紹。
YOLOv1 (You Only Look Once version 1, YOLOv1)由Joseph Redmon等在2015年提出。YOLOv1的核心思想是將目標檢測問題轉化為一個回歸問題,即將物體的位置和類別信息直接預測出來,而不是先進行區域提取,再對提取的區域進行分類和回歸。YOLOv1網絡結構由全卷積神經網絡(Fully Convolutional Networks ,FCN)構成,由輸入層、卷積層、下采樣層、全連接層和輸出層組成。其中,卷積層和下采樣層用于提取特征,全連接層用于將特征映射到輸出層,輸出層負責輸出檢測結果。相比傳統的目標檢測方法,YOLOv1 具有檢測速度快、準確率高的優點,但也存在定位誤差較大、對小目標檢測效果較差等缺點。
YOLOv2(You Only Look Once version2)是2017年提出的目標檢測算法。相比YOLOv1,其解決了召回率和定位精度不足的問題。YOLOv2使用Anchor機制和K-means聚類,提高了召回率,并將淺層特征與深層特征相連,有助于對小尺寸目標的檢測。YOLO9000能夠實時檢測超過9 000種物體,主要基于YOLOv2。其速度更快、精度更高,可以適應多種尺寸的圖像輸入。
YOLOv3 (You Only Look Once version 3)是YOLO系列的第三代目標檢測算法,由Joseph Redmon 等在2018年提出。相較于YOLOv2,YOLOv3在提高檢測準確性的同時,進一步提高了檢測速度,通過卷積模塊、主干網絡、批量歸一化、交叉熵損失函數、預測框調整和多尺度預測等方法,YOLOv3在檢測準確性和速度上都有了顯著提高,成為目標檢測領域的一個重要算法。
YOLOv4(You Only Look Once version4)于2020年由Alexey Bochkovskiy等提出,相較于前一版YOLOv3,其采用CSPNet骨干網絡、多尺度訓練策略、多樣化的數據增強、高斯混合損失函數、預訓練模型、Bag of Freebies和Bag of Specials等技術進行改進,從而在檢測準確率和速度上均有了顯著提升,同時具有更好的泛化能力。
YOLOv5(You Only Look Once version5)由Ultralytics于2020年提出。相較于YOLOv4,YOLOv5采用了輕量級的模型結構,引入了大量的模型優化技術,包括自適應多尺度訓練、優化的anchor boxes、流式數據加載和緩存和NVIDIA Apex混合精度訓練等,從而在檢測準確率、速度和模型大小等方面均有顯著提升,成為目標檢測領域中一種性能優秀的算法。
YOLOv7(You Only Look Once version 7)最大的貢獻是用原始的視覺幾何組(Visual Geometry Group,VGG)網絡代替ResNet[9-10]網絡,在訓練時,使用ResNet-style的多分支模型,在測試時,轉化成VGG-style的單線路模型,主要的方法是在測試時,將訓練時的多分支模型進行合并得到一條單線路模型,即將1× 1卷積、BN(批標準化)與3×3卷積進行合并。而YOLOv6與YOLOv7的發行時間非常接近,這里不過多闡述。
YOLO從v1版本到v7版本進行了大量的更改,其中包括主干網絡的更改、卷積模塊的更改、損失函數的更改和訓練的策略等。然而現有版本的YOLO對于木材端面檢測仍然存在不少問題:低版本的YOLO模型識別率不高,高版本對于訓練樣本數量高,對于僅有較少量樣本的木材端面圖像集難以適用,且高版本的YOLO運行要求也高,一定程度限制其使用范圍。因此,如何選擇合適的結構用于檢測自己特定的數據集并達到良好的識別效果是一個很有挑戰的問題,本研究面向木材端面檢測需求,結合YOLO系列模型的特點,從數據增強、特征融合和損失函數優化等多方面入手,提出一種適用于原木端面檢測的新模型。
2 YOLO-RW改進算法設計
2.1 識別對象分析
本研究木材堆放圖像的采集地點為江西省贛州市上猶縣某國營林場及龍南市某鄉鎮木材檢驗所,復雜原木端面拍攝圖像如圖1所示。由圖1可知,木材端面的輪廓攝影距離近,在光線充分照射的情況下能夠維持基本的顏色和形狀特征,但木材堆積的密集度和木材的保管時間過長會導致木材端面的腐蝕、裂紋等缺陷,從而使木材端面的形狀特征不規則且不完整。

圖1 復雜原木堆積圖像Fig.1 Complex log stacking image
在木材端面徑級識別方法中,傳統的R-G(紅-綠)色差分割方法難以在圖像中含有大量木材端面輪廓的情況下完全分離木材輪廓。雖然支持向量機可以對密集堆放的原木端面進行檢測識別和分類,但是由于正負樣本的限制,無法適應所有環境中的原木輪廓徑級識別。因此,本研究通過數據增強、優化網絡結構等方法,對原木端面圖像進行處理,并通過端到端的整體訓練使神經網絡自適應地學習原木端面輪廓所需要的特征,從而實現在復雜環境下精確識別原木端面輪廓。
2.2 YOLO-RW主干網絡優化
基于對YOLO模型內容的闡述,受數據集中圖像數量較小的限制,原木檢測任務并不適合過于復雜的網絡結構(YOLOv6,YOLOv7等),而早期的YOLO版本(YOLOv1,YOLOv2等)對于目前的深度學習框架性能不佳。因此本研究采用YOLOv3的主干網絡框架并作大量的簡化和改進,模型的整體流程如圖2所示。

圖2 YOLO-RW模型結構Fig.2 YOLO-RW model structure
YOLO-RW由3部分組成:下采樣模塊、融合模塊和預測模塊,其中,下采樣模塊使用3×3的卷積層、批歸一化層、激活函數層和若干組ResNet Block組成,這一模塊將輸入圖像下采樣到52×52大小的特征圖,如圖2右下角所示。接著,下采樣至26×26大小的特征圖與13×13大小的特征圖,再經過融合模塊進行特征融合,該模塊的設計基于注意力特征融合(Attentional Feature Fusion,AFF)[16],將不同維度的特征融合到一起。具體來說,給定2個不同尺寸度的特征圖(x,y),低維度特征圖y經過卷積核為3×3,步長為2的卷積層進行下采樣,再經過一層1×1的卷積層獲得低維特征圖,而高維特征圖x經過一層全局平均池化層獲得全局特征,經過3×3的卷積層與ReLU激活層,最后再經過一層1×1的卷積層獲得高維全局特征圖,將2種特征相加,再經過一層sigmoid層,分別與原特征x、y相乘,得到最終的融合特征,具體流程如圖2左下角所示。之后將得到的3種維度的特征圖分別經過一層3×3的卷積層,得到最終的預測特征,該特征的維度與yolov3中的結果相同,最后根據預測結果得到輸出圖像。
2.3 YOLO-RW損失函數設計
通過對各類損失的研究與試驗,YOLO-RW共有3種損失,置信度損失、分類損失以及定位損失。其中,置信度損失使用二元交叉熵損失,見式(1)。
(1)

分類損失同樣使用二元交叉熵損失,具體損失見式(2)。
(2)

(3)
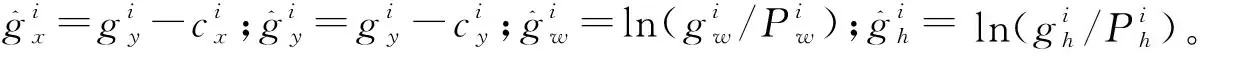
因此,模型的總損失見式(4)。
L(o,c,O,C,l,g)=λ1Lconf(o,c)+λ2Lcla(O,C)。
(4)
式中,λ1、λ2、λ3為損失的權重,用來平衡各個損失,在YOLO-RW中,分別將其設置為1、0.1和0.1。在后面的消融試驗中,將證明上述損失函數組合使得模型具有最佳的檢測效果。
3 試驗
3.1 評價方法
機器視覺目標檢測是一項非常重要的任務,需要在圖像的復雜信息中準確地找到預定的目標,并通過算法獲取目標的大小和位置信息。為了評估算法的優劣,常用的機器視覺技術指標包括精度、召回率、平均精度均值和交并比等。本研究將采用客觀的評估標準來評估原木端面輪廓識別的準確性,并使用上述指標對訓練后的模型進行評估。同時,將尋找適當的閾值[11],通過預測的置信度來篩選最佳目標。這些評估方法將有助于衡量算法性能和提高目標檢測的準確性。
(5)
(6)
(7)
式中:Precision為準確率;Recall為召回率;mAP為平均精度;TP(True Positive)為檢測結果正確,并且結果呈現陽性;FP(False Positive)為檢測結果錯誤,并且結果呈現陽性;FN(False Negative)為檢測結果錯誤,并且結果呈現陰性;μ為閾值;k為樣本數量。
首先,考慮模型的整體性能,通過多次迭代優化,篩選出平均精度(mAP)值最高的模型。接著,需要在迭代出的模型中對閾值這個參數采取足夠的關注度,并適時地對其數值加以改變,這樣做的目的是必須考量準確率、召回率和IoU這三者之間的權值關系,使之能夠自適應地檢測當前環境下的原木端面。對于準確率和召回率,需要在堆積的原木中識別每一根原木的端面,因此應當優先選擇準確率。對于IoU,本研究只需要每一根原木端面的中心點,所以對IoU要求不會特別嚴格。
3.2 原木端面圖像數據集
根據原木端面的物理及形狀等特點,在選擇神經網絡的訓練素材時,需分別考慮4種特征(端面完整、割傷、形狀不規則和有陰影)的原木端面圖像,在林場及木材檢查站拍攝原木堆積場景圖像256張。各個圖像的占比見表1。

表1 各類原木圖像占比Tab.1 The proportion of images of various types of logs
圖像的標注情況如圖3所示,由圖3可以看出,圖像的分辨率各不相同,并且不同的圖像間存在著背景復雜、原木密集和色彩單一等特點。因此,為了能夠全面地提取到不同特點圖像的特征,防止過擬合,需要補充訓練樣本的數據量,因此需對圖像進行圖像數據增強操作。

圖3 數據集樣本標記 Fig.3 Dataset sample labeling
3.3 原木端圖像集的數據增強
數據增強是一種數據預處理技術,通過對原始數據進行各種變換和扭曲,生成更多、更豐富的數據樣本,從而提高模型的泛化能力和魯棒性。對于原木檢測任務而言,存在以下問題。1)數據量遠小于YOLO模型所需的數據量,這會導致模型過擬合。2)檢測目標過于密集,模型訓練容易陷入局部最優解,影響模型精度。3)模型難以泛化。因此,選擇一種合適的數據增強方法顯得非常重要。
本試驗對原木數據集進行了翻轉、調高對比度與飽和度、旋轉、隨機裁剪和縮放等操作,為保證圖像的原始比例,并使得圖像能夠適應網絡的輸入,增強后的圖像進行了等比例的縮放,缺失的位置由黑色像素填充,如圖4所示。
為能夠讓模型提取到復雜圖像分布的特征,對不同的原木圖像進行裁剪與拼接作為一種圖像增強方法,具體選定4張原木圖像,在每一張圖像上隨機裁剪208×208像素大小的子圖,并將裁剪到的4張子圖拼接成1張圖像作為訓練數據,結果如圖5所示。

圖5 原木圖像拼接增強Fig.5 Log image stitching and enhancement
另外,還使用了添加高斯噪聲[11]等簡單的圖像增強方法。最終,將所得到的256原木圖像增強至2 048張圖像。這種增強方法的有效性將在后面的消融試驗中進行驗證。
3.4 模型參數優化試驗
訓練的模型需要對圖片中的原木端面進行檢測、定位及分類,采用mAP值對目標進行性能評價,通過訓練找到mAP值最高的模型,然后仔細分析,當模型的閾值發生改變時,其準確率、召回率和IoU是如何跟隨閾值的變化而變化,以確定模型的最佳閾值。
針對如何找到一個平均精度(mAP)值最高的模型這個問題,最直接的方法就是對模型進行大量的迭代訓練,每一個模型的輸出應當設置好合適的迭代次數,本研究根據實際情況,設置迭代次數為1萬次,并且輸出模型頻率是一個模型/百次迭代,因此可獲得100個訓練模型,然后在這些模型中尋找mAP值最高的那個模型,并把該模型確定為最終模型。試驗結果如圖6所示,由圖6可以看出,當迭代次數達到4 500次時mAP已趨于穩定,不再發生變化,mAP的最大值是87.67%,即為最優模型。

圖6 平均精度曲線Fig.6 Average accuracy curve
在圖7的準確率-召回率曲線圖像中,其曲線在坐標系第一象限占據的區域面積很大,表明該模型對原木端面的識別定位及分類效果較佳。
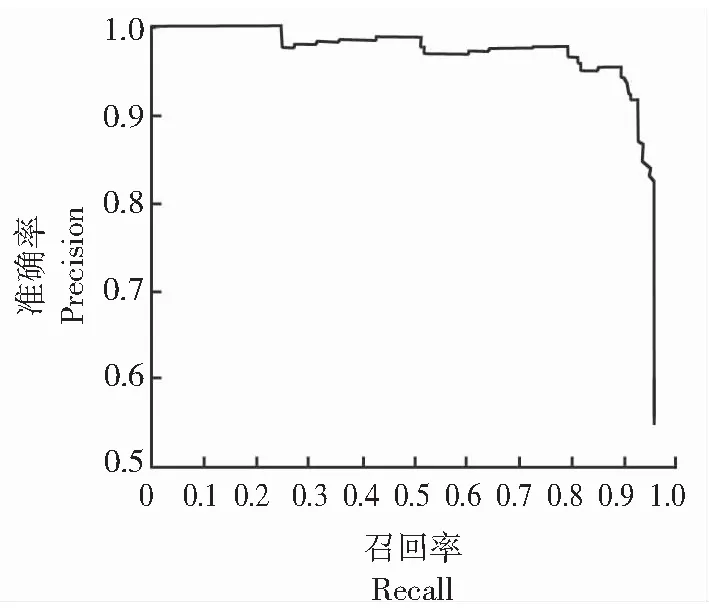
圖7 準確度-召回率曲線Fig.7 Precision recall curve
最優模型選取出來后,考慮到模型實際使用的閾值,采用預設的閾值對其進行篩選。在原木端面識別系統中,設定本研究中模型的優先級由大到小為:準確率、召回率、IoU。另外,為了同時兼顧準確率和召回率,采用F1分數(F1-score,式中用F1-score表示)作為分類的評估衡量指標[13]。
(8)
試驗結果如圖8所示,置信度閾值(Threshold confidence level)是一個小于1的數,圖8中用橫坐標表示,其大小范圍為0~1。Precision、IoU、F1-score及Recall這4個參數的大小也不超過1,用百分數形式表征。 由圖8可知,當閾值等于0.50時,模型的各個指標表現優異,說明此時的模型處于最優狀態。
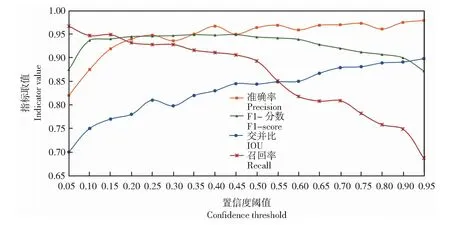
圖8 不同閾值下的準確率、召回率、F1分數和交并比Fig.8 Precision, Recall, F1-score, and IoU under different thresholds
3.5 模型性能分析
選定的模型采用端到端的聯合方式進行了訓練[13]。在訓練的具體參數方面,主要對初始學習率、權重衰減率和動量因子等幾個重要參數進行調整和設定,通過訓練,這些參數的值分別為1×10-3、5×10-4、0.9。圖片像素大小為416×416像素。每個GPU用于處理單個圖像,當模型的精度達到收斂時,模型將停止訓練。需要注意的是,模型需要及時測試比對。模型的最終輸出結果,必須將識別原木端面目標的概率作為重要指標,僅保持概率值為0.8以上的區域。
模型能否準確提取圖像中有價值的數據信息是一個非常重要的環節,為此,基于無監督的K-means聚類算法計算當前數據錨的預訓練數值。并用歐氏距離作為衡量數據對象間相似度的指標。模型訓練共耗時4 h,一共為訓練次數12 000次,其損失值變化情況如圖9所示。

圖9 損失值變化曲線圖Fig.9 Loss variation curve
由圖9可知,模型在初始迭代期間(前1×103次迭代)快速擬合,損失值迅速變小,迭代次數達到4×103次后,損耗值趨于穩定,迭代次數越多并不意味著模型的好壞,反之過多的訓練可能導致過度擬合。
YOLO-RW模型經過12萬次迭代后,對原木端面的檢測效果如圖10所示,可見模型對原木端面存在裂紋、凹凸不平、端面輪廓不規則和圖像背景復雜等情況有很好的識別能力。由于在模型訓練過程中對數據集進行了增強處理,該模型在光線強弱變化較大的應用場景以及其他復雜的場景中也具有很好的適應性。圖10為復雜情景下YOLO-RW的識別效果,由圖10可以看到,在具有復雜背景的情況下(圖10(a)),模型依然能夠準確地識別到原木的位置并進行較為準確的預測。在大量不規則的原木中,模型也可以識別到原木的準確位置,即使在較難識別的區域中(圖10(b)中右下角),模型可以給出預測結果,這種結果可以有效地提高模型的召回率。在更加綜合的圖像中圖(10(c)),模型依然保持著良好的效果,這些結果體現了YOLO-RW強大的識別能力以及泛化能力。

圖10 復雜情況下YOLO-RW識別效果Fig.10 YOLO-RW recognition effect in complex situations
3.6 消融和對比試驗
圖11為所提出的方法與不同檢測方法的結果,為了從多方面體現所提出模型的優越性,選取了YOLOv3、YOLOv5、文獻[14]以及文獻[15]4個模型作為結果對比的基準模型,從圖11中的識別對比結果和圖12給出的各模型召回率可知,YOLOv3檢測到的結果較少,表明其召回率較低,YOLOv5雖然檢測到了非常多的結果,但卻存在許多錯誤的判斷,這是由于YOLOv5在原木檢測任務中模型過于復雜,出現了過擬合,而文獻[15]與文獻[16]在不規則的原木圖像下表現均不佳。由此可證明本研究所提出的YOLO-RW在端面檢測正例的召回率明顯高于其他基準模型。

圖11 不同模型的原木端面檢測對比結果Fig.11 Comparison results of log end face detection for different models

圖12 不同模型召回率對比結果Fig.12 Comparison results of recall rates between different models
此外,為了定量地分析各個模型的檢測結果,使用30張測試樣本,共840個原木端面進行檢測,其中端面完好的原木79個,復雜背景下的原木247個,霉變端面216個,不規則形狀端面298個。各個模型的檢測出的個數結果見表2。由表2中可以看出,YOLOv5在各種端面的檢測中都優于YOLOv3,需要注意的是,雖然YOLOv5檢測出了更多的原木數,但其檢測錯誤的數量也同樣多,這是由于網絡復雜產生的過擬合現象,而本研究所提出的模型在各種端面的檢測任務中都獲得了最理想的結果。
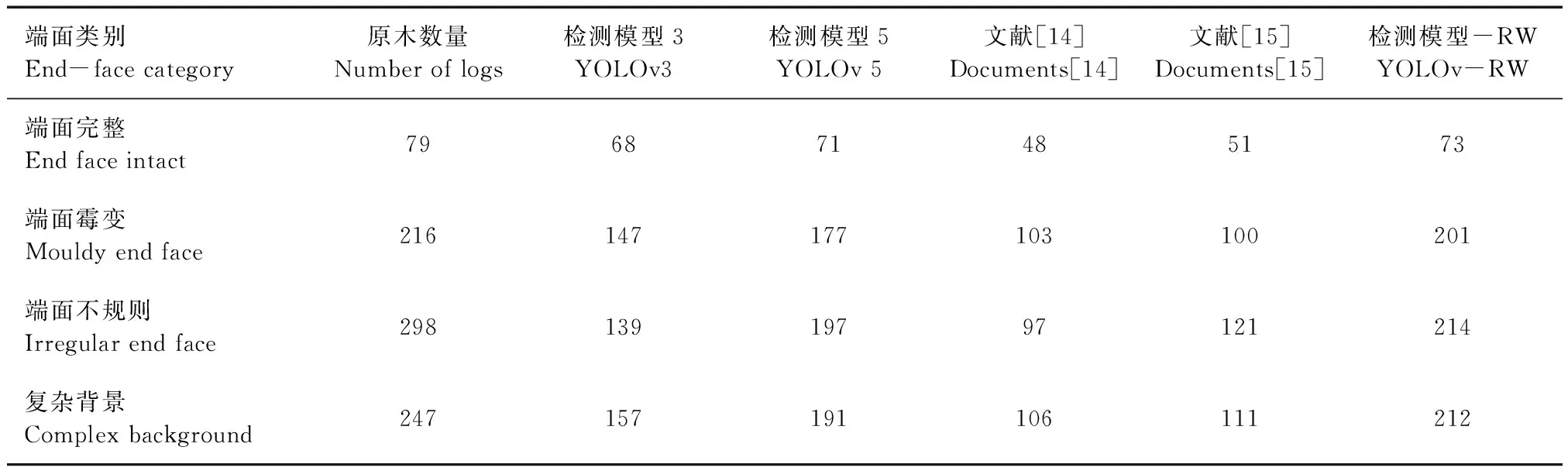
表2 不同模型正確檢測出原木端面數量對比Tab.2 Comparison of correctly detected number of log end faces by different models
為進一步證明研究中所提出的每項優化措施合理性以及優越性,進行了消融試驗,以目前效果最好的YOLOv7作為基準,分別對所提出的融合模塊、損失函數以及數據增強方法進行控制變量,對30張圖的840個原木進行檢測率的分析,其結果見表3。
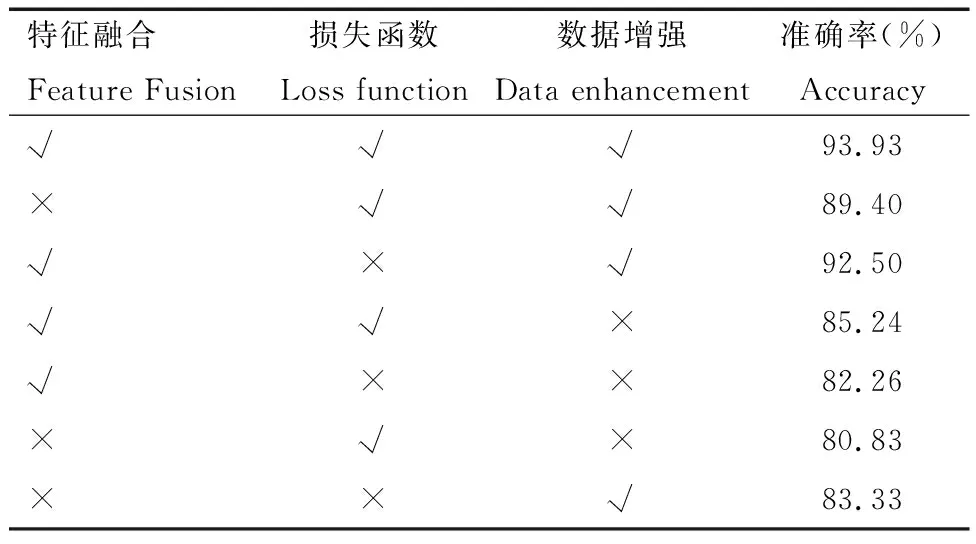
表3 模型優化措施影響檢測率的消融試驗Tab.3 Ablation tests in which model optimization measures affect the detection rate
從表3中可以看出,同時使用本研究所提出的方法時檢測效率最高,其中損失函數對結果的影響較小,其次是特征融合,而數據增強產生的影響較大。
4 結論
原木木材端面識別與定位是木材材積檢測系統中最關鍵的步驟之一,原木木材由于存放場地、存放時間等因素,原木端面會存在伐痕、開裂、凹凸不平和陰影等缺陷,從而導致原木木材材積的智能檢測可靠性和穩定性不高。為此,本研究提出一種專門應用于原木木材材積圖像的識別YOLO-RW模型,該模型綜合分析了各個版本的YOLO模型的優缺點,并通過數據增強、特征融合和損失函數等方面進行優化,從而得到了適合原木檢測的端到端新模型。與其他原木檢測基準模型相比,本研究提出的方法具有更高的精度和魯棒性。最后,采用mAP值對目標進行性能評估,通過訓練找到mAP值最高的模型,確定模型的最優閾值。試驗表明該模型的檢測精度高、速度快,在復雜環境下可靠性和穩定性均表現優異。然而,YOLO-RW模型仍存在不足,具體為模型需要耗費大量的計算資源,這導致系統功耗和系統穩定性難以兼顧,對此,將對模型做進一步研究和驗證,降低模型的復雜度,以期減少其對系統資源的消耗,提升模型的穩定性和可應用性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
