基于改進深度卷積神經網絡的軸承故障診斷
2023-10-16 15:31:54張彩華張英杰李明陸碧良李蒲德
計算技術與自動化 2023年3期
關鍵詞:故障診斷
張彩華 張英杰 李明 陸碧良 李蒲德

關鍵詞:風電機組;軸承;故障診斷;深度卷積神經網絡
滾動軸承已成為旋轉機械和設備中使用最頻繁和最核心的部件之一,廣泛應用于風帶電、航空航天、交通運輸等工業領域。由于工作環境是一個復雜的高載荷、非線性、強耦合、不穩定的系統,滾動軸承容易發生故障。因此,有必要研究數據驅動的滾動軸承智能故障診斷方法。
從相關文獻中可以看出,振動分析理論完善了工業系統的早期故障診斷方法,如油液分析、超聲波探傷、噪聲分析等。如Yin等利用傅里葉變換的相關理論,將時域信號轉換為頻域信號來描述設備的運行狀態,然后從振動信號的頻譜上對機械設備進行對比分析和研究。Cong等利用奇異值分解(SVD)提取模擬信號的相關特征并進行分析。仿真結果表明,該方法對單一軟故障和災難性多重故障都有較好的識別性能。Qian等提出了一種利用a穩定參數分布估計和人工神經網絡(ANN)技術實現軸承故障定位智能診斷的軸承診斷方法。曾蕓等利用小波包分解軸承故障信號特征后輸入到徑向基神經網絡(RBF)中有效地對軸承故障進行智能分類。
實際上,時頻域特征方法可以使用較少的參數,實現更高效、準確的故障分類。然而,基于時域特征的特征選擇通常需要專家知識的參與,不能充分利用振動數據的隱藏信息。
近年來,卷積神經網絡(CNN)在模式識別、計算機視覺等領域得到了廣泛的應用,并取得了巨大的成功。CNN不需要人工提取特征,可以自動地從給定的信號和圖像中挖掘和提取特征,從而降低了特征提取的難度。此外,它還可以通過抑制模型可能出現的過擬合現象來提高模型預測的準確性。因此涌現了許多基于CNN的智能故障診斷方法。Yuan等提出了一種基于快速傅里葉變換(FFT)和卷積神經網絡(CNN)的滾動軸承故障診斷方法。丁承君等通過變分模態分解獲取不同頻率的限帶本征模態分量,再利用卷積神經網絡提取各模態數據特征,最后通過全連接分類在變工況下完成軸承故障分類。Lu等提出了一種多通道輸入連續卷積神經網絡支持向量機(CNN-SVM)早期故障診斷模型。Chen等提出了一種基于多個小波變換的一維卷積遞歸神經網絡。雖然這些方法在滾動軸承數據集上取得了較好的診斷效果,但仍存在缺點:需要將時間序列信號通過FFT或小波變換轉換成更明顯的高維特征進行模型訓練,不能直接挖掘代表性特征。
本文提出了一種基于改進深度卷積神經網絡的直接時間序列特征提取方法用于滾動軸承故障診斷。旨在解決以下兩個問題:一是特征學習方法具有自動化的特點,基于時域特征的特征選擇通常需要專家知識的參與,該方法可以實現端到端的智能學習,無需人工參與。另一個問題與直接時間序列特征提取有關,傳統的CNN通過FFT或小波變換將時間序列信號轉換為更明顯的高維特征進行模型訓練,無法直接挖掘代表性特征。本文使用一種新型一維卷積神經網絡直接提取原始振動信號的特征,最后通過分類器實現智能故障診斷,實現端到端的智能故障診斷過程,同時也避免了特征轉換的代價。
1相關工作
滾動軸承是現代工業生產中最常用的機械部件之一。一般通過設計智能診斷方法對滾動軸承進行故障診斷,在本節中,簡要描述了滾動軸承故障診斷的發展歷史,以及卷積神經網絡的基本概念和框架。
1.1滾動軸承故障診斷
隨著現代工業日益復雜化和規模化,利用傳感器獲取的海量數據來識別不同故障狀態,需要設計準確、高效的數據驅動故障診斷方法。近年來,機器學習和模式識別技術在數據驅動故障診斷中得到了廣泛的應用,因為工業過程或機器中的不同故障本質上可以被視為不同的類別。常用的方法包括支持向量機(SVM)、隨機森林、BP神經網絡等。然而,基于機器學習的數據一驅動方法仍然存在不可忽視的缺點,它需要人類先驗知識的參與。因此,基于深度學習的卷積神經網絡故障診斷方法得到了發展,但早期的卷積神經網絡主要集中在圖像處理上,一維時間序列振動信號不能直接輸入卷積神經網絡進行智能故障診斷。因此,通過FFT或小波變換將振動信號轉換成圖像或頻譜信號受到了人們的關注,并取得了良好的故障診斷效果。然而,使用圖像或頻譜信號進行模型訓練無法獲得底層數據信息,且容易受到環境干擾的影響。故有必要開發一種基于原始振動信號直接時間序列特征提取的智能故障診斷模型。
1.2卷積神經網絡
卷積層:卷積運算部分是CNN中最重要的運算模塊之一。通常使用多個卷積核對輸入數據進行卷積運算,并對卷積后的輸出進行處理。與不同的卷積核進行卷積后可以輸出一個feature map,即從輸入信號中提取的不同的特征。由于卷積運算在同一輸入信號上實現了權值共享、部分連接和CNN權值共享的特性,因此與全連接層相比,卷積層可以提取更豐富的特征,使用更少的參數,使得最終訓練出來的模型具有更強的泛化能力。卷積運算公式如下:
其中x代表輸入的第i個數據,w為該卷積層中第k個卷積核參數,b為對應的偏置參數,g為第k個卷積核提取第i個樣本的特征。
最大池化層:池化層有時也稱為采樣層,主要分為下采樣層和上采樣層。經過卷積運算后,得到很多不同的特征映射。雖然學習了許多不同的特征,但會導致向下一層傳遞的維數迅速增加。池化的主要作用是在盡量保留原有顯著特征的情況下,降低特征圖的輸出維數,既減少了參數的數量,加快了模型的訓練速度,又很好地提取了主要特征。最大池化是CNN中最常用的池化方法之一,它會在一定大小的區域內輸出最大值。最大池化的數學表達式為:
其中,y表示當前層的第i個神經元的輸出,max pooling()是一個下采樣函數,該函數是在一定范圍內取最大值的函數,Sscal。是池化的范圍,是池化的步長大小。
全連接層:特征經過卷積層和池化層后,輸入到全連接層。在全連接層中,對具有分類的深層特征信息進行整合,構建提取的特征與樣本類型之間的映射關系。全連接層的最后一層稱為輸出層或分類層。最常用的分類器是Softmax分類器。數學公式可表示為:
2本文模型
基于一維卷積神經網絡IDCNN模型設計了一個有效的智能診斷系統,并引入全局平均池化,增加正則化和Dropout模塊,通過批歸一化等方法優化卷積神經網絡模型結構,研究了不同網絡結構和超參數對滾動軸承故障診斷測試的影響。
2.1改進后的IDCNN
改進后的IDCNN網絡結構如圖1所示。它直接使用原始數據信號進行相關研究,并將數據分割作為模型的輸入,最大限度地利用原始數據集的相關狀態特征,減少了人為影響。本文提出一種使用多種相關訓練技術對傳統CNN進行優化的方法,使其能夠更高效、準確地診斷故障類型。通過使用全局平均池化技術(global average pooling,GAP)代替全連接層部分,減少了模型的訓練參數數量,加快了模型的訓練速度。并使用L2正則化和Dropout技術減少模型的過擬合,從而提高模型的精度。由于該方法在整個故障診斷過程中不需要人工提取特征,因此可以將滾動軸承的原始振動數據直接輸入到改進的CNN中,然后自動進行故障診斷并輸出結果。綜上所述,這是一種“端到端”的算法結構,具有極強的可操作性和優秀的通用性。的數據格式不能直接導入網絡作為輸入層,因此需要對數據進行預處理。
特征提取層主要實現對給定數據集的特征挖掘和提取。通過疊加多個卷積、激活和池化層來構建更深的層。在實驗過程中,發現并不是層數越多越好。超過一定限度后,隨著層數的增加,訓練模型的精度反而會下降。選擇合適的層數既可以節省訓練時間,又可以提高準確率,達到優化神經網絡結構的目的。最后,輸出層對測試數據進行智能診斷,得到精確的診斷結果。
2.3網絡結構和參數細節
IDCNN網絡結構及參數詳情如表1所示。同時引入全局平均池化(GAP)技術,代替了全連接層,對神經網絡模型進行了優化,降低了網絡需要訓練的參數量。總體算法思想是對振動信號進行多層卷積運算后取全局平均值,并將GAP生成的值輸入到Softmax激活函數中,即可得到所需的多類概率分布。
3仿真實驗
該數據集由美國凱斯西儲大學(Case WesternReserve University,CWRU)實驗并發布。圖3是實驗平臺的圖片。由于驅動端采集到的軸承振動信號比風扇端采集到的振動信號受干擾小,因此實驗中采用驅動端加速度傳感器采集到的振動數據。
3.1數據描述
數據集包括4種載荷工況,0hp(1797r7min)、1hp (1772r/min)、2hp (1750r/min)和3hp(1730r/min)滾動軸承振動信號。在每種負載工況下,其數據集包括9種故障類型和1種正常狀態數據。軸承的內圈、外圈和滾動體的故障直徑分別為7mils(約0.18mm)、14mils(約0.36mm)和21mils(約0.53mm),均采用電火花加工完成。單點坑。實驗中采集的數據集根據采樣頻率分為12kHz和48kHz。本文將采樣頻率為12kHz的振動信號數據集作為下一個實驗的數據集。實驗選取4種載荷工況(0hp、1hp、2hp、3hp),每種載荷工況選取10種滾動軸承狀態數據,每種狀態數據按相同數量、相同長度選取作為實驗樣本。表2顯示了0hp負載和12kHz采樣頻率下的9種滾動軸承失效狀態。
3.2實驗結果
從驅動端的12kHz振動數據中分別按照四種負載工況選取10種軸承故障狀態信息。從每種軸承故障類別隨機提取200個樣本,樣本的采樣點數為1024,每種負載下共有2000個樣本,訓練集和測試集劃分比例為7:3,mini-batch的大小設置為128。針對不同負載下的故障樣本進行訓練,后續表中實驗數據的迭代次數均為100,最終的結果為取五次實驗結果的均值。
3.2.1對比實驗
優化器的選擇影響著整個模型的參數更新和收斂的速度,最終影響模型的診斷精度。因此選擇目前最常用的幾種優化器:SGD、Rprop、RM-Sprop、Adagrad、Adam作為對比實驗。整個實驗在Pytorch環境中完成,將優化器中的weight_de-cay設置為0.0001,學習率設置為0.001,以保證參數一致。實驗結果見表3,SGD表現最差,在四種負載下的平均準確率只有26.99%;RMSprop和Adam優化器實驗表現相當。
圖4是以在2hp下進行200次迭代的實驗數據繪制成的優化器的診斷精度對比圖,從該圖中可知RMSprop優化器初始準確率更高,但是在迭代過程中相比于Adam震蕩較為明顯。綜合考慮,選取更適合的Adam算法作為本章模型的優化器。
此外實驗選取了常見的分類模型:邏輯回歸(Logistic Regression,LR)、支持向量機(SupportVector Machine,SVM)以及反向傳播神經網絡(Back Propagation Neural Network, BPNN)作為對比實驗。實驗結果如表4所示。
通過對比分析,機器學習技術受限于人工特征選擇和淺層特征表征學習能力,LR和SVM的診斷精度低于基于深度網絡的BPNN和IDCNN;但BPNN在不同負載下的診斷精度均低于IDCNN模型,最終的四種負載情況下的平均準確精度僅為92.44%,而IDCNN模型明顯優于對比方法,最終的平均準確率達到了100%,這充分說明IDCNN模型在軸承故障診斷中特征提取以及分類能力的優異性。
3.2.2消融實驗
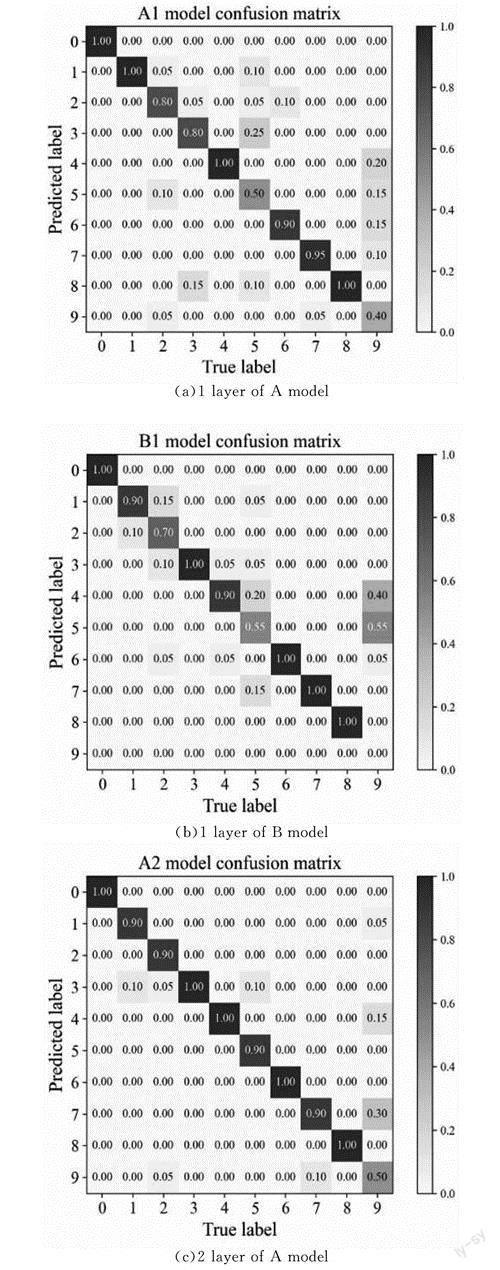
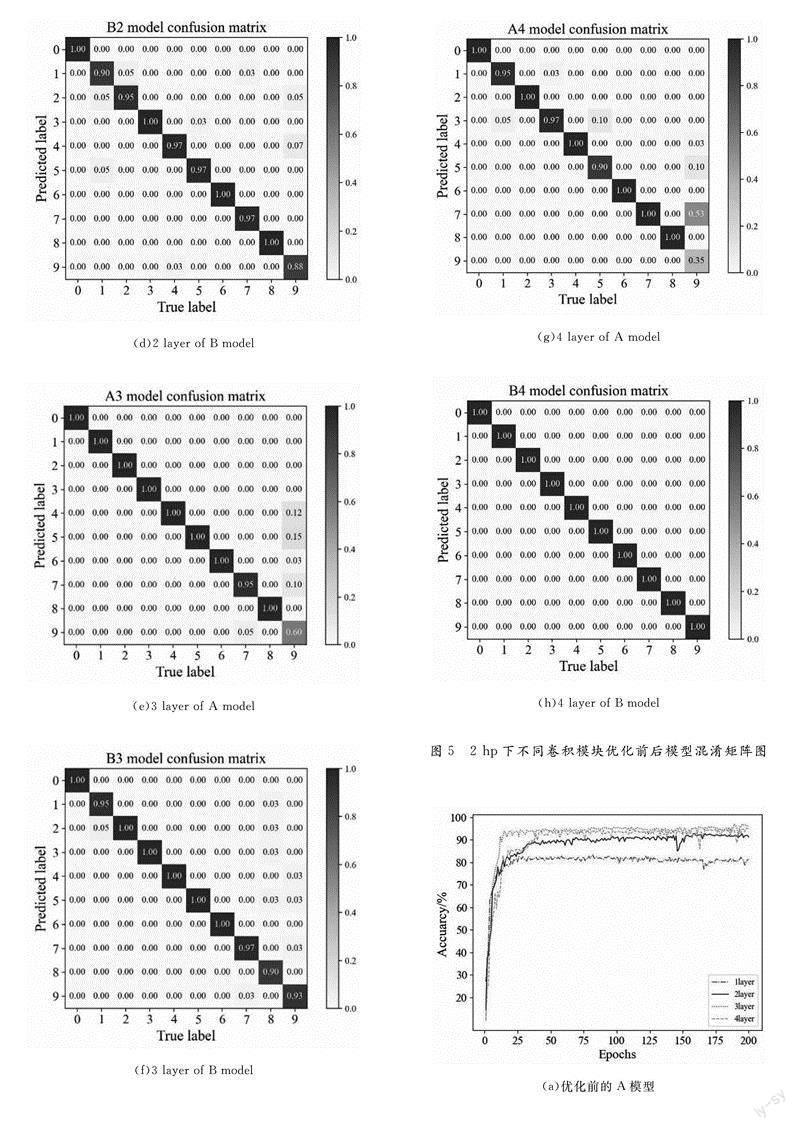
在深度學習中模型網絡層數的增加代表著其學習特征能力的增強,能避免欠擬合的出現,能更好地完成相應的任務,然而這也會造成訓練資源的增加,甚至出現過擬合的現象。因此在故障診斷中,模型的層數的選擇和診斷精度應當根據實際需要保持平衡,以達到既能實現高精度診斷的目標,又能保證模型結構簡單、訓練時間較短的目的。考慮到CNN的模型結構對特征提取能力有較大的影響,因此從不同網絡模塊是否增加批量歸一化、Dropout以及全局平均池化GAP兩種角度探討了模型中特征提取器對軸承故障診斷的具體影響,而分類器的結構則保持不變。不同卷積模塊下的故障診斷性能具體結果見表5。其中A模型去除特征提取器中的批量歸一化、GAP以及Dropout代表優化前的模型,而B模型則是優化后的完整的特征提取器。
從結果得知,卷積模塊對模型診斷精度影響最大,模型只有1組卷積模塊時,優化前的A模型平均診斷精度只有78.24%,優化后的B模型平均診斷精度只有72.39%,卷積模塊增加1組后兩個模型的平均診斷精度分別上升了12.00%和20.87%。隨著卷積模塊的增加,診斷精度也逐漸提高。值得注意的是:在有3組卷積模塊時,A模型的平均診斷精度就達到了最高92.10%,而B模型則是在有4組卷積模塊時才達到最高100.00%。優化后的B模型受益于批量歸一化、Dropout以及GAP技術,一方面提高了診斷精度,另一方面防止過擬合的發生。
圖5和圖6分別展示了在2hp負載時不同卷積模塊下、模型優化前后的混淆矩陣圖和準確率對比圖。從圖6中的準確率對比圖可以看出優化后的B模型收斂更快更穩定。
4結論
針對滾動軸承系統故障的智能診斷問題,提出了基于IDCNN的故障診斷算法,它是一種“端到端”診斷方法,直接對原始振動信號數據進行處理,提取相鄰時間點之間的信息特征,無需對原始數據進行任何人工特征提取和信號處理操作。它可以擺脫傳統方法對人工特征提取的依賴,突破了傳統方法依賴專家經驗的局限性。最后在CWRU數據集上進行了對比實驗和消融實驗。對比實驗主要包括優化器對比實驗,從不同優化器的表現中選擇了Adam作為模型優化器;進一步與經典算法進行對比,實驗結果表明了IDCNN模型的優越性。消融實驗則從模型的卷積模塊角度設計了不同層數的卷積模型,從實驗結果表明在有四組卷積模塊時表現最佳,并且在實驗中驗證了批量歸一化、Dropout以及GAP優化技術對模型準確率有明顯的提升作用。
猜你喜歡
一重技術(2021年5期)2022-01-18 05:42:10
水泵技術(2021年3期)2021-08-14 02:09:20
裝備制造技術(2020年3期)2020-12-25 05:22:30
制造技術與機床(2018年11期)2018-11-23 01:07:42
電子制作(2018年10期)2018-08-04 03:24:46
制造技術與機床(2017年10期)2017-11-28 05:20:43
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
振動工程學報(2014年2期)2014-03-01 01:15:22
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
振動、測試與診斷(2014年4期)2014-03-01 01:14:00
