
面向農業學者領域的本體構建及可視化研究
2023-10-19 05:20:48陳寶發
江蘇農業科學 2023年18期
陳寶發, 任 妮
(1.江蘇大學科技信息研究所,江蘇鎮江 212013; 2.江蘇省農業科學院信息中心,江蘇南京 210014)
農業作為國家的第一產業,是國民經濟中一個重要的產業部門,支撐著國民經濟的建設和發展,農業學者則是一個國家農業發展水平的重要推動力,在農業科技的生產創造、傳播和應用等方面發揮著不可替代的作用。然而農業學者的專業領域與科研成果卻散落在互聯網的各個角落,并沒有完善的一體化組織系統,不利于農業科研和生產活動的知識回顧與創新。隨著學術信息化建設的不斷進步,互聯網上公開的學者信息也在不斷完善,人們不僅對搜索不同類型的學術信息感興趣,如論文、期刊、作者等信息,對基于語義的信息搜索需求也日益增長,如結構化的學者簡介、學術成果的主題分類等。現有的學術信息檢索工具,如中國知網、百度學術和科研之友等平臺大多只是對學術成果的簡單羅列,而缺少基于文獻細粒度的語義信息;對學者信息的展示往往缺少簡介信息,或是未能將簡介信息結構化、立體化地組織起來,最終導致不能建立起統一的學術網絡。本體(ontology)這一概念源自哲學領域,是對客觀世界本質及其規律的抽象表示,20世紀90年代以來,其概念逐漸被引入人工智能、知識工程、圖書情報等領域。Perez等認為,本體可以用于在計算機領域表示知識,包含類、關系、公理、函數和實例5種要素[1],能夠規范特定范圍的基本概念、屬性、概念間的關系以及屬性和關系的約束規則[2]。在學術檢索系統中運用本體來表示知識,可以統一學者信息的組織形式,且在學者和學者之間、學者和研究成果之間建立起語義關聯,為基于語義的檢索需求提供支撐。近年來,國內外學者在生物醫學[3]、人文歷史[4]、商業智能[5]、農業[6]等領域開展了大量本體構建研究。在學術領域,Tang等擴展FOAF本體,針對機器學習領域提出基于條件隨機場算法的科研人員檔案抽取方法[7]。馬翠嫦等提出一種網絡學術文檔細粒度聚合本體構建的方法,可以為網絡文獻聚合單元的細粒度組織提供參考[8]。鄭楊等研究現有的學者檢索工具,并對學者智能目錄體系的構建提出建議[9]。然而當前的研究大多僅針對特定的學科領域建立本體模型,鮮有對農業領域學者和科研成果進行本體化組織,且未能將學者信息和學術成果信息在語義關聯的基礎上進行有機結合。因此,本研究對長三角地區農業學者的簡介信息進行分析與處理,從文本數據中抽象出概念體系,提出農業學者的本體設計模式,并與學術文獻的組織體系相結合,通過實證研究完成面向農業學者及文獻細粒度的本體構建,形成可以復用至其他學科領域的學術本體模型,進而為領域學者知識圖譜的構建提供模式層框架。
1 本體構建方法及流程
學者本體構建是以相關學者的工作實踐經歷為基礎,結合學者現有的學術成果,形成客觀明確的知識表示規范體系,并以結構化的形式,通過本體描述語言和可視化工具最終實現學者本體的建模工作。
在本體構建方面,目前較經典的方法有骨架法、METHONTOLOGY法[10]、七步法[11]等,這些方法通常來源于具體的本體開發項目。但這些方法尚不符合軟件工程的生命周期演進思想,也缺乏本體的質量評估過程[12],導致不能滿足知識圖譜不斷更新的需求。因此,本研究根據農業學者信息的屬性特征,以網站數據庫Wikidata和Schema等關于研究人員的本體定義為參考,并加入實例填充、驗證評估與優化迭代環節,進而確定農業學者本體的構建流程(圖1)。

(1)確定本體的領域和范圍。構建本體的第一步首先是確定本體的應用領域和覆蓋范圍。本研究構建的學者本體是面向長三角地區的農業學者簡介信息,并結合這些學者所發表的文獻信息,以實現學者信息的結構化和語義化組織,進而為后續構建知識圖譜定義知識體系。
(2)構建本體框架。該階段的主要目標是對已獲取的領域內信息進行分析總結,抽象出領域內的核心概念,定義類和類的結構,并確定類的對象屬性和數據屬性,從而形成一個完整的本體結構模型。本研究參考Wikidata等的本體類[13-14],結合長三角地區農業學者的信息和文獻信息,定義相關的核心類以及屬性,最終完成農業學者信息的本體框架。
(3)本體形式化和可視化。本體框架構建完成后,為了使計算機可以理解和存儲本體,應該使用形式化的語言實現該本體,如RDF、OWL等本體描述語言,以增強本體的語義表達能力,此外還可以使用Protégé等工具實現本體的可視化呈現。
(4)創建實例。實例是領域本體中最小的概念,也是體現領域知識的重要組成部分。為了實現領域本體的知識服務功能,本研究基于設計完成的農業學者領域本體,采用深度學習的方法對獲取到的長三角地區農業學者主頁信息進行實體抽取,包括學者數據獲取、實體標注、模型訓練、實體抽取等步驟,并通過Neo4j圖數據庫存儲學者實體數據。
(5)本體驗證與評估。當本體初步構建完成后,須要對本體進行評估,以保證其能夠對農業學者的信息結構體系進行充分有效的描述,并能夠識別出本體中存在的冗余部分,從而進一步完善本體的概念和屬性。
(6)本體優化迭代更新。隨著時間的推移,領域內的知識結構可能會出現新的變化。所以,本體構建也是動態變化的過程,在出現新的領域知識類別時,應該重新對領域本體的結構框架進行分析與調整,從而實現本體的更新迭代,以滿足其在新環境中的適用性。
2 農業學者本體構建
本研究所構建農業學者本體的目標是根據農業學者的學術生涯,抽象出能夠完整描述學者信息的核心概念,再結合學者的學術成果信息建立可以復用的領域學者本體模型。本研究根據上述提出的構建流程,首先確定農業學者本體的領域和范圍,再定義本體的類和屬性,建立本體框架,并使用OWL語言和Protégé工具實現本體的保存與管理,最后對本體質量進行評估。
2.1 確定本體的領域和范圍
本研究構建的本體為后期建立農業學者知識圖譜提供模式層架構,并以此建立面向長三角地區農業從業人員的知識服務平臺。因此,該領域本體的覆蓋范圍為長三角地區的農業學者信息和文獻信息。為了該目標,需要從學者主頁、百科網頁等渠道獲取長三角地區農業學者的簡介信息,并從簡介信息中抽象出可以描述學者的核心類和屬性信息,如學者類、機構類、職位類等,屬性信息有畢業院校、工作單位、研究方向等。此外,還需要將篇名、關鍵詞、研究方法等文獻屬性嵌入學者本體。最終實現由學者相關概念和文獻描述信息構成的農業學者領域本體。
2.2 構建本體框架
2.2.1 定義類和類的結構 目前有3種常用類的定義方法,分別是自頂向下、自底向上和二者結合定義[13]。其中,使用最多的方法是自頂向下構建,該方法首先從頂層的抽象概念入手,再逐漸細化;自底向上的方法則是從具體類別著手,同時對概念逐漸歸類抽象,以形成完整的結構;二者結合定義可以先找到明確的具體概念,同時再對其進行泛華和細化。本研究的學者本體采用自頂向下的構建方法,遵循從抽象到一般,再到具體概念的3層結構。根據對獲取的長三角農業學者文本信息進行分析,可以將該本體的最頂層抽象類定義為參與者類、對象類和事件類,將這些抽象概念進一步具體化,可以定義為5個一級子類(核心類)和8個二級子類(圖2)。

本研究構建的本體中最頂層的抽象概念是參與者類、對象類和事件類,具備一定的通用性。而根據農業學者本體的個性化需求,可以將上述3種抽象概念細化為學者類、機構類、職稱類、研究方向類、文獻類5種核心類。本研究針對農業學者的本體構建,所以將學者定義為核心類,其實體可以具體為長三角地區的農業學者。
在該本體中,對象類分為機構類、職稱類、研究方向類3個核心類。其中,機構類主要描述學者的畢業院校和所在單位,所以可以分為學校、科研院所、企業3個子類;職稱是區別科學技術人員的等級稱號,在農業學者本體中創建職稱核心類可以豐富學者的描述信息,包含高級、中級、初級職稱3個子類;研究方向是學者的重要標簽,能夠體現該學者當前或歷史時期的主要成果所在領域,所以將研究方向類確定為該本體的核心類。
事件類是由參與者類的實體執行的主動行為,在該本體中可以總結為農業學者在特定時間、單位和期刊發表論文的行為,所以將文獻類定義為本體的核心類,即事件類的一級子類。文獻類通過外部特征和內部特征描述文獻的關鍵信息,并基于文本細粒度分析得出文獻的主題分類,能夠更加細致地刻畫學者的研究領域。此外,根據文獻發表的渠道不同,文獻類包含會議論文和期刊論文2個子類。
2.2.2 定義類的屬性 在本體框架中定義類和類的結構后,應該定義組成類的不同屬性以及類與類之間的關系,以完善類的內部數據結構,從而保證類的獨特性。本體中類的屬性包括對象屬性和數據屬性。其中對象屬性表示類與類之間的關系,其屬性值必須為另一個類;數據屬性則表示類的實例對象所具備的特征,屬性值為數據類型且只存在于類本身。通過參考Wikidata中researcher類的屬性定義以及數據源中學者簡介信息的共性描述,最終確定5個對象屬性和7個數據屬性(表1)。
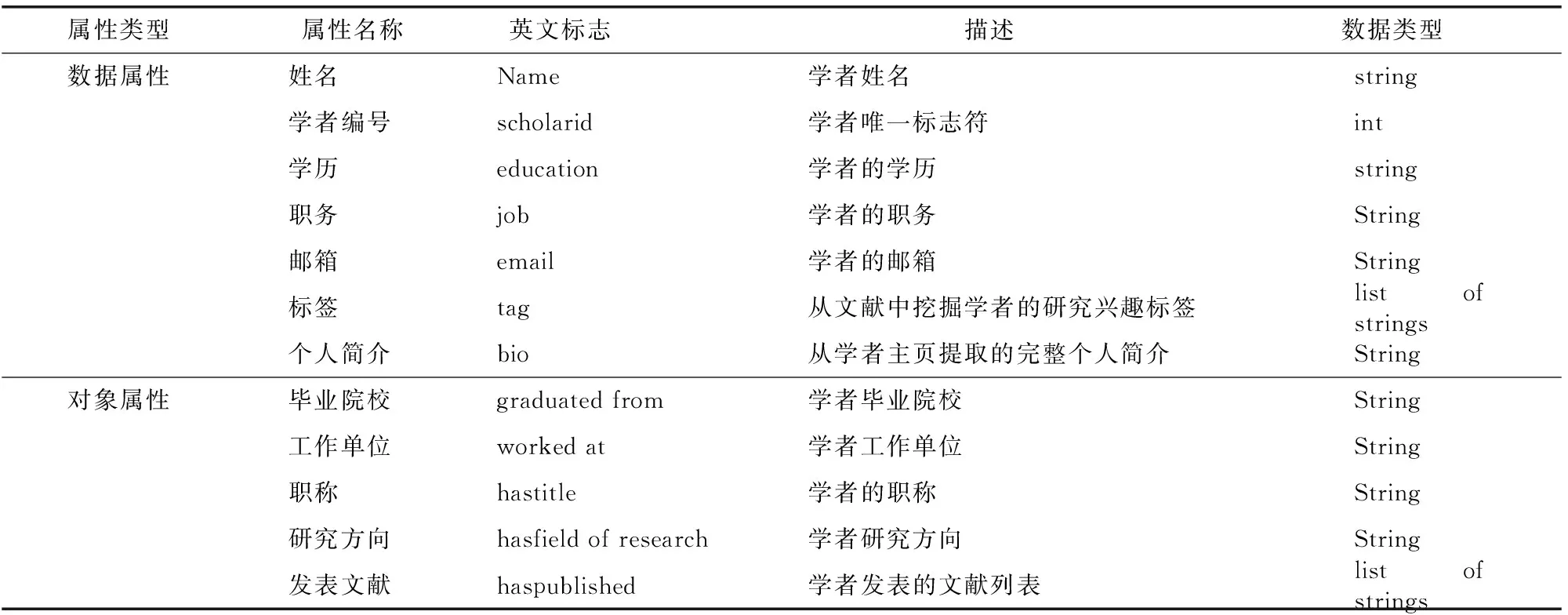
表1 農業學者本體屬性
在該本體中,以學者類為中心建立類的對象屬性和數據屬性,對象屬性表示學者類與其他類之間的關系,包括畢業院校、工作單位、職稱、研究方向和發表文獻,其定義域為學者類,值域分別為機構類、職稱類、研究方向類和文獻類。數據屬性包括學者姓名、編號、學歷、職務、郵箱、標簽以及個人簡介,其中學者標簽描述是對學者文獻進行文本細粒度分析得出的興趣領域,能夠總結學者科研成果的方向,有利于建立基于標簽的學者推薦系統。
此外,本研究還對文獻類的數據屬性進行定義。通過復用都柏林核心元素集(dublin core element set,DC)關于信息資源的元數據構成,并從農業學者本體構建的實際需求出發,最終定義文獻類的16個數據屬性(表2)。包括文獻編號(PaperID)、題名(PaperTitle)、作者編號(AuthorID)、作者(Author)、所屬單位(Organ)、文獻來源(Source)、關鍵詞(Keywords)、摘要(Abstract)、發表時間(Pubtime)、發表年份(Year)、卷(Volume)、期(Issue)、開始頁碼(Page_start)、結束頁碼(Page_end)、DOI碼(DOI)、研究主題(ResearchTopic)。其中,文獻編號是用于描述文獻的唯一標志,是文獻數據庫的主鍵;作者編號是與學者數據進行關聯的標志符,因為文獻存在多個作者,所以數據類型為列表;研究主題是基于文獻內容的特征詞提取得出的文獻主題分布。

表2 文獻類數據屬性
最后,綜合農業學者的對象屬性和數據屬性,并通過“發表文獻”屬性將學者類與文獻類進行關聯,進而形成完整的農業學者本體框架(圖3)。

2.3 本體的形式化與可視化表示
在明確定義農業學者本體類和屬性的基礎上,為實現本體在計算機中的存儲、更新與復用,應該使用統一的本體描述語言對本體進行形式化描述。OWL是W3C Web本體工作組設計的一種知識表示語言,與其他描述語言相比(如XML、RDF),其優勢是表示知識便于被計算機所理解和應用,且擁有更豐富的推理方法和詞匯表。所以,本研究采用OWL語言對農業學者本體進行形式化表示,并使用Protégé工具實現本體的可視化。
首先對農業學者本體中的類使用OWL語言進行描述,代碼示例見圖4。在OWL中使用Class來表示類,如創建學者類,將其英文標簽設置為“Scholar”,中文標簽設置為“學者”,并繼承FOAF詞表[15]中的人物類(foaf:Person),以實現語義層次的知識共享。
對象屬性在OWL中以ObjectProperty表示,用于創建類與類之間的關系。 如使用OWL語言創建對象屬性“發表文獻(hasPublished)”,設置其定義域(domain)為學者類,值域(range)為文獻類,并與文獻類的作者屬性(hasAuthor)形成相對關系(inverseOf),代碼見圖5。

數據屬性在OWL中以DataProperty表示,用于展示類的實例屬性值,如創建文獻類的“摘要(Abstract)”屬性,其定義域(domain)設置為文獻類,并以range標簽設置數據類型為字符串(string),代碼見圖6。

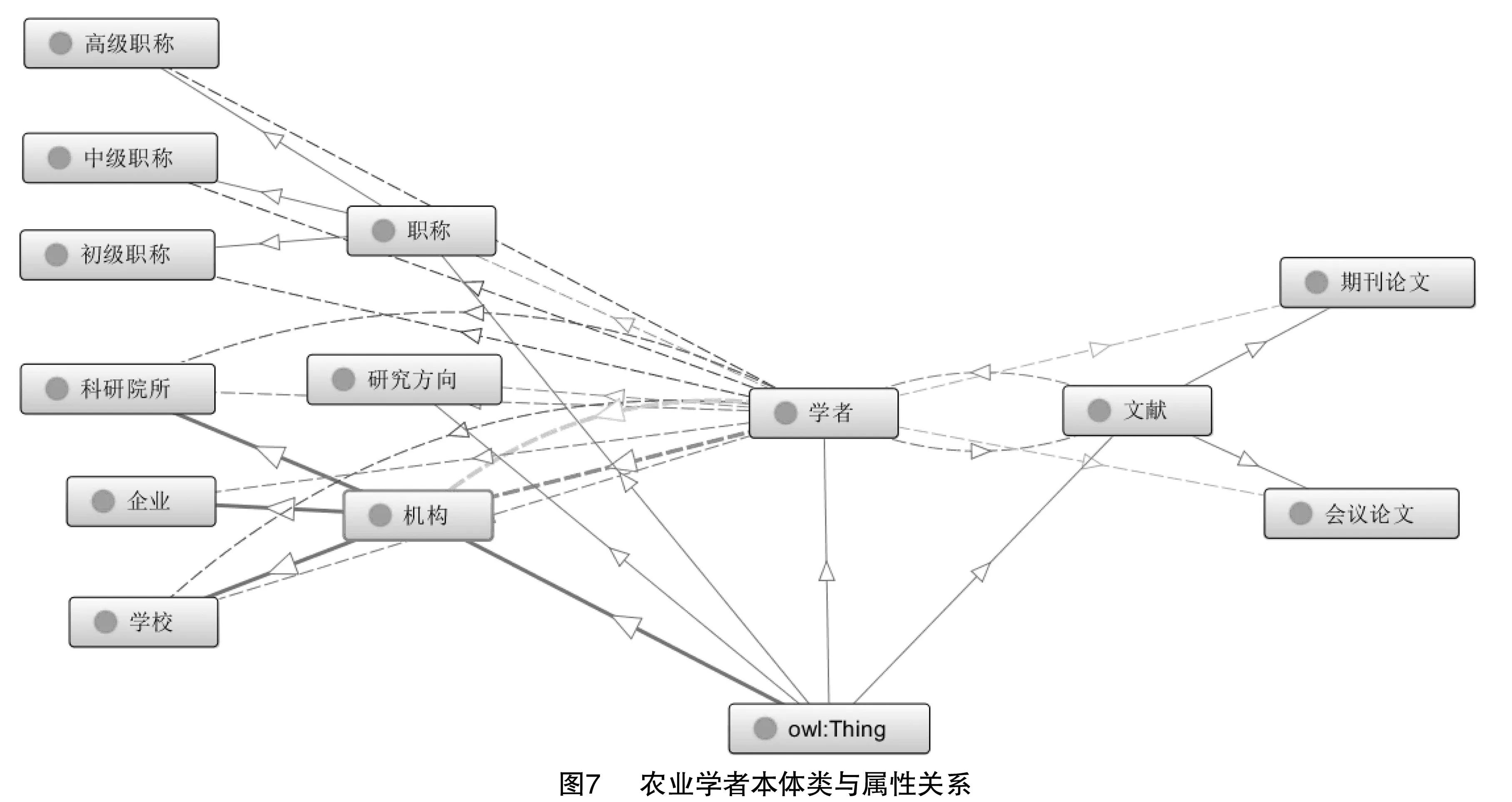
將使用OWL語言編輯完成的農業學者本體文件導入Protégé軟件,利用OntoGraph功能進行本體的可視化展示。由圖7可知,實線部分為類的層級結構關系,其中學者、文獻、職稱、機構和研究方向均為超類“Thing”的子類;虛線為屬性關系,展示學者與其他類的對象屬性,其中文獻和學者定義了相對關系。
3 實體抽取
3.1 數據獲取
本研究通過scrapy爬蟲框架,從農業科學院官網、農科機構知識庫聯盟等渠道獲取長三角地區江蘇省、浙江省、安徽省、上海市農業科學院的專家學者信息為數據源,剔除部分缺失無效信息,共得到學者信息1 022條。此外,以作者和機構為檢索詞,對知網上的相關學者論文進行檢索,共下載學者文獻數據52 000條。
由于數據源的學者信息來源多樣,多數為非結構化文本數據,且篇幅差異較大,所以本研究對學者的簡介信息進行相應的刪減,使篇幅保持在300字以內,以便于后續實體抽取任務的開展。下載的文獻數據為CSV格式,通過python腳本將其轉化為json格式,并去除存在的換行符、空格等特殊符號。
3.2 實體標注
根據定義的學者本體,本研究通過阿里云NLP自學習平臺對學者文本信息進行標注,標注的實體主要包括單位、二級單位、研究領域、教育、姓名、職稱、時間、職務、郵箱共9類實體。為了將數據輸入訓練模型,需要對學者的文本數據進行標簽化處理,本研究采用BMEO標注法對上述已標注實體進行標簽轉換(表3)。

表3 學者文本標注示例
將標注完成的數據按照8 ∶ 2的比例構建訓練集和測試集,并輸入模型進行訓練。
3.3 命名實體識別模型構建
本研究采用BiLSTM-CRF模型進行命名實體識別研究,模型結構見圖8。該模型主要包括Embedding層、BiLSTM雙向循環神經網絡、CRF層3個部分。
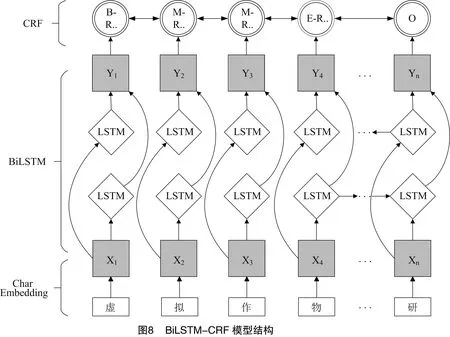
Embedding層主要將學者的文本信息進行字符級別的編碼,通過Word2Vec的連續詞袋(CBOW)模型可以預測每個字符的出現概率,使句子表示為字符級特征向量,再將字符向量輸入到BiLSTM模型中。
長短期記憶網絡(long-short term memory,LSTM)是基于RNN模型(循環神經網絡)進行的變體,相較于傳統的RNN模型,引入記憶單元(memory cell)和門的控制結構[15]。LSTM通過遺忘門決定上一時刻的記憶單元有多少保留到當前時刻,通過輸入門決定當前時刻網絡的輸入有多少保存到單元狀態,通過輸出門控制單元狀態有多少輸出到LSTM的當前輸出值,可以解決原始RNN模型無法處理長距離依賴關系的問題。而BiLSTM通過雙向循環結構可以解決LSTM模型只能從前往后傳遞信息的問題,從而可以使模型結合正反2個方向的信息,最終輸出數據標簽的分布概率。
條件隨機場(conditional random field,CRF)是一種條件概率分布模型,可以考慮上下文標簽的依賴關系,對BiLSTM輸出的標簽概率進行一定的約束,以保證最終的預測結果是有效的。其原理是設x=(x1,x2,…,xn),y=(y1,y2,…,yn)均為線性鏈表示的隨機變量序列,在給定隨機變量序列x的條件下,隨機變量y的條件概率分布P(y|x)構成條件隨機場。當隨機變量取值為x的條件下,隨機變量為y的條件概率有如下公式。
(1)
(2)
式中:tk、sl表示特征函數,一般情況下,tk、sl的取值為1或0,即滿足特征條件時為1,不滿足則為0;λk、μl分別表示tk、sl所對應的權值;Z(x)表示規范化因子,來保證P(y|x)的概率分布。
在訓練時通過最大擬然估計求得最大概率,預測時利用維特比(Viterbi)算法進行解碼,預測出最大概率的標簽序列。
3.4 試驗結果
本研究采用準確率(P)、召回率(R)、F1值3個指標作為模型的評價標準。其計算公式分別為
(3)
(4)
(5)
式中:準確率(P)表示模型識別到的正確實體占識別總實體的比例;召回率(R)表示識別正確實體占原數據總實體的比例;F1值表示調和平均數,綜合正確率和召回率,用于綜合反映模型整體的效果。
由表4可知,此模型在訓練集上的命名實體識別準確率、召回率、F1值較高,分別達到87.03%、83.99%、85.49%,而在測試集上的效果有一定的折損。比較表4和表5可知,單一的LSTM模型實體抽取效果較差,準確率、召回率和F1值均有所下降,召回率下降較多,說明在整個數據集中識別到的正確實體數較少。而BiLSTM-CRF模型的F1值比LSTM模型高4.19百分點。可見,加入前后文信息并使用CRF層對BiLSTM輸出序列進行約束后,模型的命名實體識別效果有明顯提升。

表4 BiLSTM-CRF模型訓練結果

表5 BiLSTM-CRF和LSTM模型對比試驗
3.5 實體存儲及可視化
本研究使用Neo4j圖數據庫對學者實體和文獻數據進行存儲和關系構建以及可視化展示。Neo4j可以通過Cypher語言進行數據庫的操作,也可以通過交互式界面訪問圖譜數據,可以輕易地表示出半結構化的數據和數據間的關系。在獲取抽取的實體后,導出為json格式文件,使用腳本語言自動寫入Neo4j圖數據庫進行可視化存儲,并與文獻數據進行關聯(圖9)。最終構建10多萬實體和40多萬組關系。

4 本體驗證與評估
本體的評價指標主要包括完整性、清晰性、一致性、可擴展性和兼容性[16]。本研究以長三角地區農業專家學者信息為數據源,基于上述所構建的學者本體,通過BiLSTM-CRF模型對農業學者信息進行實體抽取和填充,并基于農業學者實例結合上述指標對該本體模型進行評估,以確保其能夠滿足知識服務平臺的建設需求。
由圖10可知,以“王才林”為學者實例,根據學者主頁的簡介信息進行實體抽取,對本體屬性進行填充,并通過“發表文獻”這一屬性關聯相關文獻,添加所屬單位、關鍵詞、摘要、文獻來源、文獻編號等屬性信息,最終實現以“王才林”為核心的農業學者語義網絡。

從農業學者本體的實例示意來看,在完整性方面,該本體參考Wikidata的researcher類對研究人員的描述以及都柏林核心集對信息資源的元數據定義,覆蓋面較完善,但是考慮到數據源存在缺失的可能性,所以在學者類中缺少對科研項目的定義,在后續增加可靠的數據源后,應對本體進行更新補充。在清晰性方面,農業學者本體擁有3類抽象概念、5個一級核心類以及8個二級子類,其概念和屬性關系定義明確。從本體實例來看,學者信息能夠準確地填充進本體類和屬性中,避免了歧義,進而確保農業學者本體的清晰性。在一致性方面,該本體從3類抽象概念出發,自頂向下逐漸細化,形成邏輯一致的層次結構。在可擴展性方面,本研究構建的農業學者本體以OWL語言進行本體描述,其語法靈活,能夠對新出現的概念方便地進行描述,擴展性更好,還可以關聯豐富的詞匯表資源。在兼容性方面,農業學者本體內部可以實現學者與文獻資源的映射,并在構建過程中聲明與FOAF本體Person類的繼承關系,從而保證該本體與其他信息組織資源的兼容與互操作。
5 結語
本研究以長三角地區農業學者為對象,優化傳統的本體構建方法,提出農業學者本體構建方法和流程。在厘清學者相關概念體系以及學術文獻關鍵屬性的基礎上,完成本體框架模型的設計。運用Protégé工具完成類和屬性的定義,建立農業學者領域本體,并實現本體的形式化與可視化表示,最后以長三角地區農業學者為例,采用深度學習算法對學者簡介信息進行實體抽取,完成本體實例的填充,大大減少了本體建模的人工依賴性,并利用Neo4j圖數據庫進行實體和關系的存儲以及可視化展示,還利用農業學者實例開展本體的驗證與評估。但由于學者信息數據源的復雜多樣且沒有統一的內容形式,以及隨著時代的進步發展,農業學者信息的核心屬性存在變化的可能,所以在后續的研究與應用中,該本體的內容覆蓋上還存在優化的空間。
在后續的研究中,將進一步完善農業學者本體的概念體系和屬性結構,在應用層面,該學者本體將作為知識圖譜的模式層,進一步結合深度學習算法實現專家興趣預測、農業學者畫像等應用,進而建立基于知識圖譜的面向農業從業人員的知識服務平臺。
猜你喜歡
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
今日農業(2021年14期)2021-11-25 23:57:29
中華手工(2017年2期)2017-06-06 23:00:31
山東青年(2016年1期)2016-02-28 14:25:25
中外會展(2014年4期)2014-11-27 07:46:46
當代修辭學(2014年3期)2014-01-21 02:30:44
公務員文萃(2013年5期)2013-03-11 16:08:37
海外英語(2006年11期)2006-11-30 05:16:56
