基于半監督判別分析的領域自適應方法研究?
2023-10-20 08:24:42成佳駿
計算機與數字工程 2023年7期
成佳駿 李 波
(1.武漢科技大學計算機科學與技術學院 武漢 430065)(2.武漢科技大學智能信息處理與實時工業系統湖北省重點實驗室 武漢 430065)
1 引言
在計算機視覺領域中,許多機器學習方法被用來做圖像分類任務。比如,線性回歸[1]、邏輯回歸[2]、k近鄰[3]、決策樹[4]、支持向量機[5]。但是,當圖像特征表示過于冗余或質量較差時,其準確性將降低。因此,提取高質量圖像特征非常重要。
特征提取是作為挖掘圖像潛在特征的一種重要方式,不僅有利于對圖像內容的深入理解,而且對于提高圖像分類和識別的準確率也至關重要。有許多經典的特征提取方法。比如,主成分分析(Principal Component Analysis,PCA)[6]、獨立成分分析(Independent Component Analysis,ICA)[7]、線性判 別 分 析(Linear Discriminant Analysis,LDA)[8]等。以上的算法是全局的,無法從中提取局部流形結構信息。為了發現隱藏在高維數據中的非線性結構并挖掘數據的局部幾何結構信息。拉普拉斯特征映射(Laplacian Eigen-maps,LE)[9]、局部線性嵌入(Locality Linear Embedding,LLE)[10]和其他流形學習算法也被提出用于特征提取。此外,深度學習方法也應用于特征提取[11~12]。
然而,以上提出的算法通常需要大量與測試(目標域)樣本具有相同分布的訓練(源域)樣本,并且當標記的訓練樣本不足且具有分布偏差時,算法性能將會受到很大影響。領域自適應(Domain Adaption)問題解決了源域和目標域之間的樣本分布不一致的問題。如何有效地衡量域之間分布差異是領域自適應的關鍵步驟。常用的方法包括基于熵的KL 散度[13]、Bregman 散度[14]、最大均值差異(Maximum Mean Discrepancy,MMD)[15]。Zhuang等[16]通過將KL散度作為域間分布自適應提取深度特征,提出一種自編碼的領域自適應方法。Si等[17]將Bregman 差異添加到子空間學習的目標函數中,提出了轉移子空間學習(Transfer Subspace Learning,TSL)方法。然而,需要密度估計的流程阻礙了KL 和Bregman 散度的適用性。之后,香港大學的Pan等提出遷移成分分析(Transfer Component Analysis,TCA)[18],使用MMD 消除了再生核希爾伯特空間(Reproducing Kernel Hilbert Space,RKHS)中域之間分布差異,減少源域和目標域間的邊緣分布差異。龍明盛等提出了遷移聯合匹配方法(Transfer Joint Matching,TJM)[19],在優化目標中同時進行邊緣分布自適應和源域樣本選擇。隨后,龍明盛等提出的聯合分布自適應方法(Joint Distribution Adaptation,JDA)[20]的目標是同時減少源域和目標域的邊緣分布差異和條件分布差異。王晉東等提出平衡分布自適應(Balanced Distribution Adaptation,BDA)[21]方法來解決JDA 中忽略邊緣分布和條件分布優先考慮的問題,該方法能夠根據特定的數據領域,自適應地調整分布適配過程中邊緣分布和條件分布的重要性。
雖然基于MMD 的領域自適應方法很方便,但是有必要構建一個與樣本大小成正比的分布差異矩陣,增加了計算成本。另外,這些方法都沒有考慮到源域和目標域樣本的標簽信息,沒有保留投影到子空間后樣本數據的流形結構。許多機器學習研究人員發現,未標記數據與少量標記數據結合使用時,可以大大提高學習準確性[22]。因此,基于LDA[8]的半監督判別分析(Semi-supervised Discriminant Analysis,SDA)[23]被提出。SDA 的目的是找到一個投影矩陣W,該投影從標記的數據點推斷出判別結構,以及從標記和未標記的數據點推斷出固有的幾何結構。
為此,本文提出一種基于半監督判別分析和跨域均值差異(Semi-supervised Discriminant Analysis And Cross-domain Mean Measure,SDA-CDMD)的領域自適應方法。首先,用源域和目標域到彼此域均值距離的平方和表示兩個域之間的差異(CDMD)。其次,將SDA 加入到優化目標,保證數據映射到子空間后的局部幾何信息。最后,通過最小化CDMD 并結和SDA 來構造關于投影矩陣W 的目標函數。減少域之間的邊緣分布差異和條件分布差異,促進域之間的知識遷移。與基于KL 散度、Bregman 散度和MMD 的領域自適應算法相比,基于SDA-CDMD 的方法具有計算成本低,所需內存少,知識傳遞效率高,易于推廣和應用的優點。
2 半監督判別分析
半監督判別分析(Semi-supervised Discriminant Analysis,SDA)[23]的目標是學習一個全局的投影變換,使其不僅具有較好的分類判別能力,同時保持數據的局部分布特性。假設樣本數據集X=XS∪XT=[x1,x2,…,xN]∈Rd×N,其中N=n+m。SDA 的目標函數如下所示:
其中,WTXLXTW 是一個正則項。a 是全局散度與正則項之間的平衡參數。正則項的拉普拉斯矩陣為L=D-S。其中,S 表示由X 組成的鄰接矩陣。在本文中,矩陣S定義為
D是一個對角矩陣:其條目是S的列(或行)的總和,表示如下:
Sb和St分別表示樣本X的類間散度矩陣和全局散度矩陣,具體定義如下所示:
Sw表示X 的類內散度矩陣,N(c)和u(c)分別表示X 中包含c類樣本的數量和平均值。由于目標域是沒有標簽的,所以在標簽迭代過程中用偽標簽替代。每次迭代后都需要更新目標域標簽。在式(4)和式(6)中,u 表示樣本數量為n+m 的X 樣本均值。如下所示:
本文中,X 由源域樣本和目標域樣本組成,n和m分別為源域樣本數量和目標域樣本數量。
3 跨域均值差異
為了衡量兩個域之間的分布差異,本文提出了一種新的域之間度量準則:跨域均值差異(Corss-Domain Mean Discrepancy,CDMD)。
假設源域Ds和目標域Dt的樣本數量固定,CDMD通過兩個域之間到彼此域樣本均值點歐式距離的平方和來評估Ds和Dt的分布差異。如圖1 所示,在源域和目標域的原樣本空間中分別有三類樣本點及其均值:xS(1),xS(2),xS(3),uS和xT(1),xT(2),xT(3),uT。從xS(1),xS(2),xS(3)到uT的距離分別為dS(1),dS(2),dS(3)。而從xT(1),xT(2),xT(3)到uS的距離分別為dT(1),dT(2),dT(3)。可以用下式表示這兩域之間的分布差異。
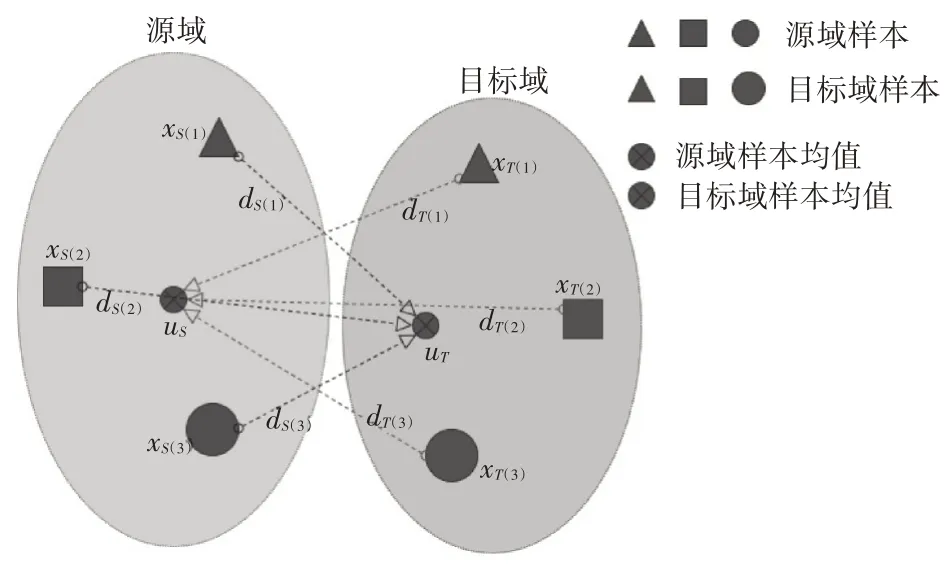
圖1 原始樣本空間
因此,通過CDMD計算Ds和Dt之間的分布差異公式為
圖1和式(9)表明,當樣本數量保持不變時,d2(Ds,Dt)越小,源域樣本點越接近目標域樣本均值點;目標域原本點越接近源域樣本均值點,域之間的分布差異越小。
為了提取最佳的共享特征表示,本節通過學習一個基于CDMD 的最優特征子空間的投影矩陣W。如圖2 所示,通過投影變換zS=WTxS和zT=WTxT,投影后源域和目標域樣本點及其均值變為zS(1),zS(2),zS(3),?S和zT(1),zT(2),zT(3),?T。從zS(1),zS(2),zS(3)到?T的距離分別為d?S(1),d?S(2),d?S(3)。從zT(1),zT(2),zT(3)到?S的距離分別為d?T(1),d?T(2),d?T(3)。本章希望找到一個映射矩陣W使得式(11)成立,進而減少域之間的分布差異。
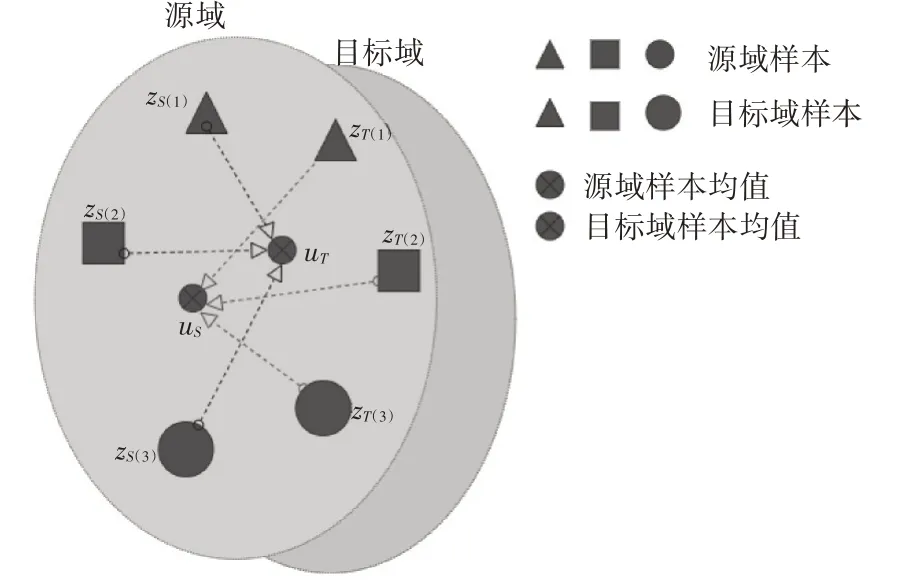
圖2 投影后樣本空間
因此,為了找到最佳的共享特征子空間,通過將低維投影矩陣W 加入到式(9)中,可以得到基于CDMD的優化目標函數如下所示:
其中,u 由式(10)表示,式(13)寫成矩陣形式如下所示:
4 SDA-CDMD算法
在SDA-CDMD 方法中,給定有標簽的源域數據集Xs={(x1,y1),(x2,y2),…,(xn,yn)}∈Rd×n和沒有標簽的目標域數據集XT={x1,x2,…,xm}∈Rd×m。其中n 和m 分別是源域樣本和目標域樣本數量,d 是原始特征空間維度。
4.1 目標函數
SDA-CDMD 算法將SDA 與CDMD 相結合構造出關于投影矩陣W的優化目標函數。另外,在目標函數上添加經典領域自適應方法TCA[18]和JDA[20]使用的正則化項。最終的目標函數為
其中,M=XXT-XuT-XTu+uuT。||W||2 F 是投影矩陣的稀疏約束項,l是平衡參數,||·||2 F是矩陣F-范數的平方運算。參數b 用于權衡SDA 與CDMD 之間的權重。
優化問題(14)的求解可以轉換為拉格朗日乘數法求解廣義特征值的問題。定義L=diag(l1,l1,…,lk)為拉格朗日乘子,式(14)的廣義特征分解為
求解等式(15)得到的前k 個最大特征值對應的特征向量組成的矩陣即為投影矩陣W。
4.2 算法流程
在上述理論的基礎上,本文提出的SDA-CDMD算法步驟見算法1。
算法1 基于SDA-CDMD領域自適應算法步驟
輸入:源域樣本XS和目標域樣本XT,子空間維度k,參數a、b、l,最大迭代次數T。
輸出:投影矩陣W
1)直接訓練源域樣本得到一個分類器f,通過f 得到目標域樣本的偽標簽。初始化矩陣St和Sb。
2)令跌代次數t=1;
3)求解式(15)得到投影矩陣W;
4)由W得到低維數據ZS=WTXS和ZT=WTXT;
5)用{ZS,YS}訓練出一個分類器f,通過f 得到目標域樣本的偽標簽。更新矩陣St和Sb;
6)t=t+1;
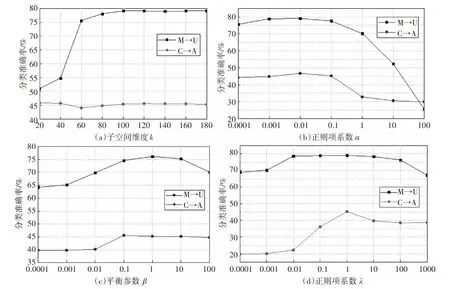
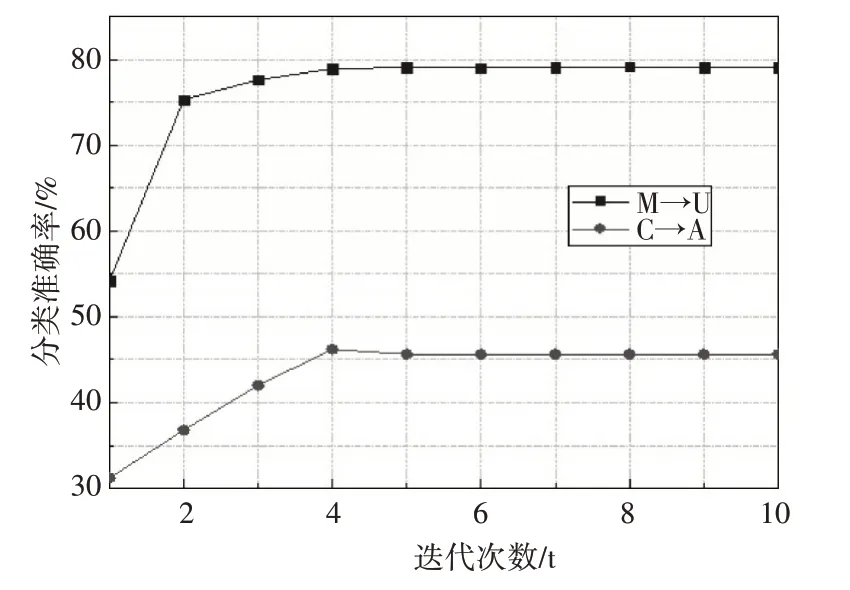
7)如果t 為了對本文提出的方法進行驗證,將本文提出的SDA-CDMD 算法與傳統的領域自適應算法進行實驗結果比較,比較的方法包括GFK[24],TCA[18],TSL[17],JDA[20],TJM[19],BDA[21]。以此對本文所提出算法的有效性和實用性進行評估。 USPS 數據集和MINST 數據集都是手寫數據集,具有手寫的數字0-9 的十個類別。它們的分布不同但是聯系緊密,都具有手寫的數字0-9 的十個類別。在實驗中,構建兩組實驗數據作為域適應問題:U→M(USPS 作為源域,MINST 作為目標域)和M→U(MINST作為源域,USPS作為目標域)。 Office+Caltech 數據集由Gong 等第一次被提出[25],它包含Office和Caltech兩個數據集。有四個域C(Caltech),A(Amazon),W(Webcam)和D(DSLR)。在實驗過程中,兩個不同的域隨機選取分別作為源域和目標域,比如C→A(Caltech 作為源域,Amazon 作為目標域)。一共有12 種域適應問題。 在對比實驗中,設置本文算法的參數:子空間維度k=100,正則項系數a=0.001,最大迭代次數T=10。另外在USPS+MNIST 數據集上設置平衡參數b=1,正則項系數l=0.1。在Office+Caltech 數據集上設置b=0.5,l=1。其它方法的參數使用它們各自文獻的最優參數,選用k-NN 分類器對USPS+MNIST數據集的兩組域適應問題(U→M,M→U)和Office+Caltech 數據集的9 組域適應問題(C→A,C→W,…)使用7種領域自適應方法進行比較,比較結果如表1和表2所示。 表1 USPS+MNIST數據集分類準確率(%) 表2 Office+Caltech數據集分類準確率(%) 從表1和表2的結果分析中我們可以得出以下兩點結論: 第一,BDA、JDA、SDA-CDMD 這些共享特征提取算法的準確率總體上高于TCA、GFK 和TSL。表明同時減少兩個域之間的邊緣分布差異和條件分布差異,更有利于對齊源域與目標域,保留數據的本質屬性。 第二,SDA-CDMD 的平均準確率總體上優于其它幾種傳統的領域自適應算法,這就表明SDA-CDMD 在特征提取過程中充分利用了標簽信息使得類內散度最小化,類間散度最大化,這樣可以充分挖掘數據的局部幾何結構信息。在投影到子空間后保留了樣本的原始幾何結構,同時通過CDMD減少了域之間的分布差異。 根據目標函數(14),SDA-CDMD 算法性能受參數a、b、l 和子空間維度k 的影響。因此,為了測試SDA-CDMD 對參數的敏感性并研究其隨著迭代次數的增加算法的收斂性。我們分別選取USPS+MNIST 數據集的M→U 域適應問題和Office+Caltech 數據集的C→A 域適應問題。對這兩組實驗采用控制變量法找到每個最優的參數結果,圖3分別展示了給定其他三個參數值,變換剩余一個參數值時分類準確率的變化趨勢。 圖3 參數設置 另外,記錄這兩組實驗在每次迭代后的分類準確率,如圖4所示。 圖4 迭代次數分類準確率 通過圖3 和圖4 可以看出:1)隨著迭代次數的增加SDA-CDMD 的精度在4 次迭代后逐漸增強并穩定下來,這說明算法具有很強的收斂性能。2)SDA-CDMD 的精度隨著子空間維度的增加而提高,然后基本保持不變。3)正則化參數a的變化導致分類準確率的波動較大,并且兩組實驗的趨勢不同。總體來說兩組實驗在區間a∈[0.0001,0.01]效果最好。4)平衡參數b 在區間[0.5,1]中,兩組實驗的分類準確率最高。5)隨著正則化參數λ的增加,兩組實驗的分類準確率先升再降。M→U 實驗在λ=0.1 處取得最優值,C→A 實驗在λ=1 處取得最優值。 本文提出的基于半監督判別分析和跨域均值差異的領域自適應(SDA-CDMD)方法,通過三方面實現領域自適應:1)將源域和目標域映射到同一子空間,減少兩個域之間的邊緣分布差異和條件分布差異;2)利用半監督判別分析方法使數據在投影后保持原有的幾何結構信息,同時使得同類樣本更聚集、異類樣本更分散;3)為了有效衡量域之間的分布差異同時提高計算效率,提出一種跨域均值差異的度量準則。在多個數據集上的對比實驗可以看出,SDA-CDMD 算法效果總體上優于其它傳統的領域自適應方法。 本文算法雖然相較于一些傳統算法有一定的改進,但仍有不足之處。如本文算法中分類器僅選用k-NN,后續將嘗試不同的分類方法來提高分類準確率。近年來,隨著深度學習的發展,各種深度學習模型不斷提出,后續會考慮將本文算法和深度學習相結合。5 實驗與數據分析
5.1 數據集描述
5.2 方法比較


5.3 參數設置及收斂性分析
6 結語
猜你喜歡
音樂探索(2022年2期)2022-05-30 21:01:37
小天使·一年級語數英綜合(2019年8期)2019-08-27 02:23:00
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中國特種設備安全(2018年11期)2019-01-08 02:08:32
小學科學(學生版)(2018年7期)2018-08-13 09:33:04
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
鄭州大學學報(醫學版)(2015年2期)2015-02-27 14:50:46
