基于時空聚類的多源異構時序數據集成方法
2023-10-21 06:10:40胡才亮楊慧芳
電子設計工程 2023年20期
陳 超,胡才亮,崔 鈺,謝 芳,楊慧芳,王 健
(安徽明生恒卓科技有限公司,安徽合肥 230000)
數據集成是統計學的一個分支,現階段相關領域學者對于數據集成的研究已經取得了一定進展,使得數據集成技術逐漸完善,然而,數據時空分布不均與數據混亂情況下的數據集成效果依然較差。尤其是工業信息、通信信息等各行各業所產生的龐大信息量通常都較為混亂,數據呈現無序性和多源性,因此,對多源異構的數據集成便成為了該領域的研究重點之一。
針對此問題,一些學者進行了相關研究。文獻[1]提出了分布式數據集成方法,建立一種分布式環境下高性能數據工具,通過大數流式計算框架實現多源異構數據的集成,但該方式太過依賴于數據工具,不適用于普及使用。文獻[2]提出了基于多目標優化技術的多源異構數據集成方法,通過建立多目標群交叉優化算法處理不平衡數據集,過濾大部分多源異構數據,以此完成數據集成,但該方式過濾掉太多數據,已無法滿足統計學中對多源異構數據的集成要求。
多源異構的數據集成通常以時間序列形式呈現,數據量較大且集成難度增加,而利用傳統方法進行多源異構時序數據集成出現執行和抽取時間較長、篩選準確率較低的問題,因此該文提出了基于時空聚類的多源異構時序數據集成方法。
1 多源異構時序數據協同處理
在進行數據集成時,需要將時序不同步的混亂數據進行同步處理,該文通過三種方式匯集時序數據,分別為濾除、插值以及混合式時序數據[3-4]。多源異構時序數據匯集過程如圖1 所示。
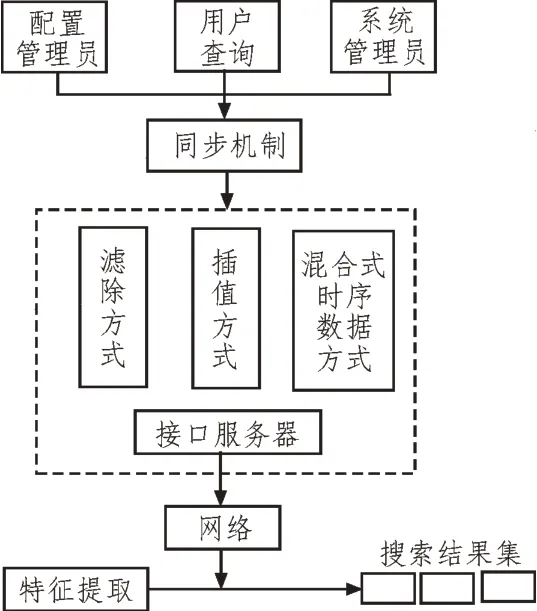
圖1 數據匯集過程
在濾除處理過程中,選取最大的監測數據間隔作為時序,如果時序數據出現遺漏,則選取離時間節點最近的時序數據來代替[5-6]。與濾除處理方式相反,插值過程中采用最小監測數據作為時序數據,通過采集最近點的多源異構時序數據的平均值來填補缺失數據[7]。
混合時序數據匯集時間根據信息集匯聚的內容而定,通常把信息集中的時序數據之一視為新的時間或重定義新的時序。各個時序數據之間以新的匯集順序為依據,生成監測時序數據[8-9]。
完成數據匯集后對多源異構時序數據進行協同處理。在對時序數據源進行整理后,針對時序數據的字段增加三個基礎特性,包括時序數據標志、起始日期、時間間隔。同步處理后根據同步機制將時序數據錄入虛擬數據庫[10-11]。
通過分析數據匯聚層協調程度進行時序數據同步,時序數據的同步對于數據匯聚的協同程度影響很大,當匯聚的數據都是時序數據時,時序數據同步機制便開始運行,從數據匯聚層開始收集時序數據中的所有時序數據,如時序數據的名字、日期、大小、采樣間隔、時序數據的去向等及其同步方法,以此實現數據同步[12-13]。
2 多源異構時序數據集成
實現多源異構時序數據協同處理后對數據進行集成,集成流程如圖2 所示。
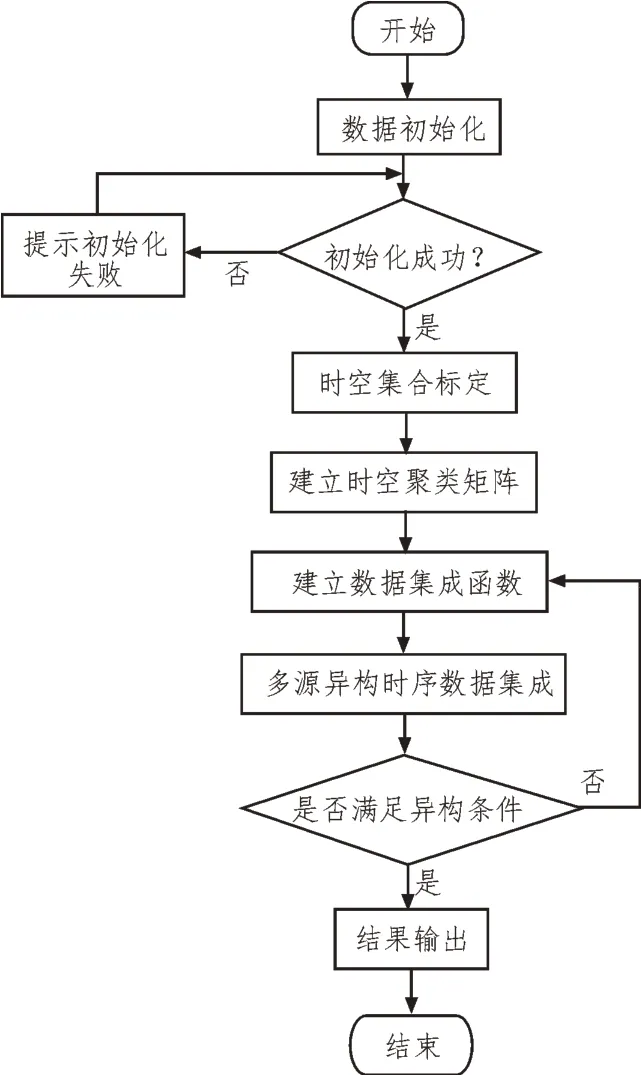
圖2 基于時空聚類的多源異構時序數據集成流程
根據圖2 可知,多源異構時序數據集成主要通過時空集合標定、建立時空聚類矩陣、建立數據集成函數、多源異構時序數據集成來實現。
2.1 時空集合標定
時空聚類以時空數據庫為基礎,時空數據庫具備存儲大量信息的能力,能夠更好地對多源異構時序數據進行整合與分析,在執行數據儲存指令時,時空集合可提取現有多源異構時序數據的處理條件信息,以此為基礎,完善多源異構時序數據[14-15]。時空集合P計算公式如式(1)所示:
式中,Wn表示多源異構時序數據向量最小值;Wm表示最大多源異構時序數據向量最大值。
2.2 時空聚類矩陣
在時空集合標定結果已知的情況下,建立時空聚類矩陣,在時空聚類矩陣中,多源異構時序數據分為橫向與縱向兩種形式。在針對橫向多源異構時序數據進行判定過程中,采用時空聚類算法中的最近鄰分析算法,其表達式為:
式中,R表示最近鄰分析結果;dobs表示在觀測過程中節點與最近鄰點之間的平均距離;dexp表示不同狀態下的節點期望值。
由于最近鄰算法只考慮到橫向數據中的點對點情況,因此,對縱向多源異構時序數據進行分析時,需要引入時空聚類算法中的莫蘭指數E(·),通過計算莫蘭指數的期望值I實現對縱向多源異構時序的判定:
式中,n為縱向排列數量。時空聚類矩陣可作為精準的信息判別條件,通過時空聚類矩陣描述時空數據庫中的存儲能力,當時空數據庫的數據量達到目標值時,即可認為時空聚類矩陣進入飽和狀態。
2.3 數據集成函數
數據集成函數是以時空聚類矩陣為基礎建立的多源異構時序數據查詢限定條件,由于時空聚類算法的應用性很強,隨著數據信息量的增加,集成函數的極限值覆蓋面積也會不斷增加,直到能夠滿足多源異構時序數據的傳輸需求。數據集成函數D可表示為:
式中,Xn代表多源異構時序數據最小參量,Xm代表多源異構時序數據最大參量,且將信息參量混亂狀態的傳輸情況考慮在內,Xn與Xm的差值越大,數據集成函數性能越優。
2.4 多源異構時序數據集成
多源異構時序數據集成就是利用時空聚類算法轉換所有數據,數據集成主要分為兩個過程,分別是數據分離與數據集成。通過數據集成的層次結構來選擇集成的方式[16]。將每一條多源異構時序數據信息看作一個類,根據時空聚類算法規則集成越來越大的類,直到滿足預設條件。通過時空聚類算法中的統計量G來判斷多源異構時序數據期望,表達式為:
式中,E(G)為G統計量的期望值;wi為多源異構時序數據權重。
根據相似度的測量對時序聚類結果進行分組,比較數據庫中的時間序列相似度,在同一個簇中相似度高的數據列為一組而不同簇中的信息數據相差較大。多源異構時序的集成是為了在不同時間域的同一個屬性時間序列數據庫中挖掘數據信息。無論是數據分離還是數據集成,用戶都可以根據自己的要求來設計多源異構時序數據的分離和集成要求,從而更好地實現多源異構時序數據集成。
3 實驗研究
為了研究該文提出的基于時空聚類的多源異構時序數據集成方法的實際應用效果,設計了相關實驗。選用傳統的基于多目標優化的多源異構數據集成方法和基于數據挖掘的多源異構時序數據集成方法與該文的集成方法進行對比。實驗環境如圖3 所示。
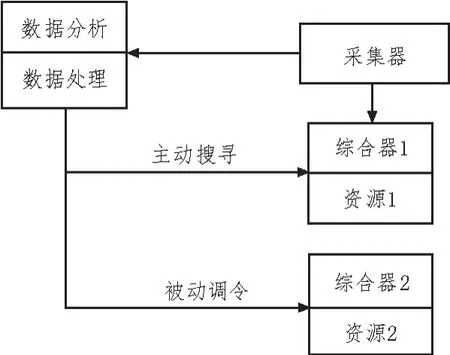
圖3 實驗環境
系統接口與數據庫順利連接后就會讀取存儲空間內的數據,采用自動抽取方式提煉圖層要素,在后臺完成數據執行和抽取,抽取過程不會顯示詳細的圖形數據,抽取結果會直接輸入到數據庫內部。三種方法的數據執行時間和篩選時間實驗結果分別如表1 和表2 所示。

表1 執行時間實驗結果
根據表1 與表2 可知,該文提出的基于時空聚類的多源異構時序數據集成方法所用的數據執行和抽取時間都低于傳統方法。由于用戶具有多樣性要求,因此需要抽取不同數據,該文提出的集成方法在數據抽取過程中,只針對數據庫的部分數據進行提取,通過抽查分析解決這一問題,這樣既能很好地存儲相關數據,又能提高執行和抽取速度。
系統接口與數據庫順利連接后,需要重新獲取數據庫內部的空間數據,通過定義分析進行數據篩選,篩選準確率實驗結果如圖4 所示。
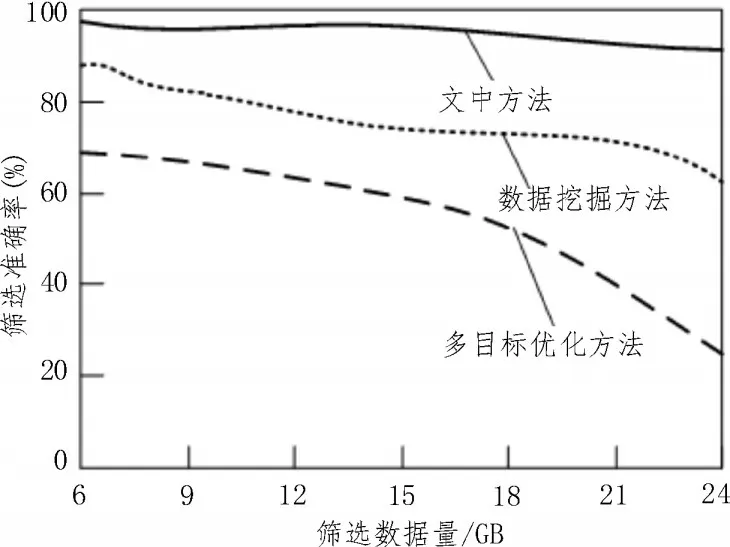
圖4 篩選準確率實驗結果
分析圖4 可知,隨著數據量的增加,篩選結果準確率開始呈現下降趨勢,但是該文提出的集成方法的準確率始終保持較高水平,原因是該文的集成方法在篩選過程中會將數據轉為shapefile 格式,采用時空聚類算法包含的時空數據庫存放多源異構數據,并對其進行數據集成處理,通過數據命名確保篩選結果的正確性,而傳統方法多采用盲目篩選的方式,篩選結果難以達到用戶要求。
順利完成篩選后對數據進行集成,實驗結果如圖5 所示。
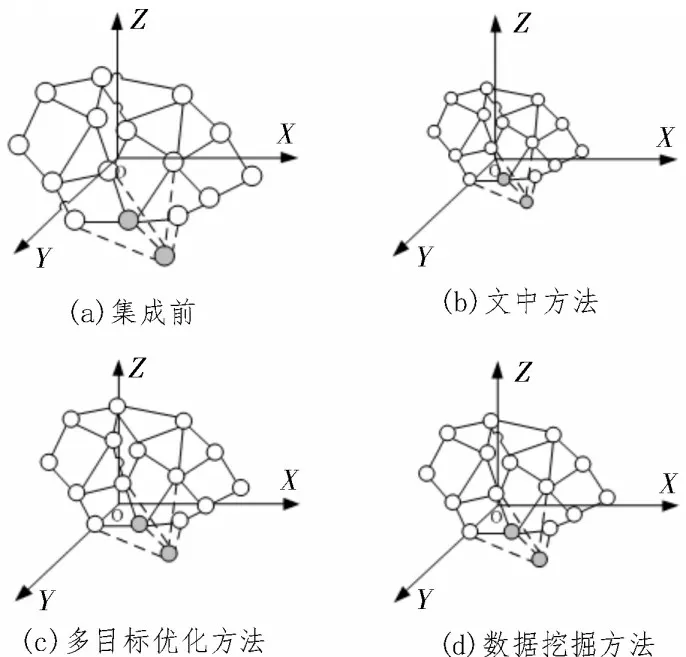
圖5 數據集成實驗結果
觀察圖5 可知,該文提出的集成方法的集成效果更加好,原因是該文方法在對數據進行處理時,能夠很好地實現空間坐標轉換,提高了集成效率,確保集成效果更好,而傳統方法在集成過程中容易受到外界因素的影響,集成效果相對較差。
4 結束語
數據集成是解決大量數據信息存儲與分析的方法之一,對于多源異構時序數據信息的集成需要加入具有針對性的算法來實現。該文通過時空聚類算法建立時空聚類矩陣,從而完成多源異構時序數據的集成。實驗表明,所提出的基于時空聚類的多源異構時序數據集成解決了傳統方式存在的不足,以此保障多源異構時序數據集成的速度與質量。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
