融入句法結構和摘要信息的文本蘊含識別模型
2023-10-21 03:05:40鐘茂生羅賢增王明文
計算機技術與發展 2023年10期
鐘茂生,孫 磊,羅賢增,王明文
(江西師范大學 計算機信息工程學院,江西 南昌 330200)
0 引 言
文本蘊含(Recognizing Textual Entailment,RTE)定義為一對文本之間的有向推理關系,其中前提句記作P(Premise),假設句記作H(Hypothetical)。如果人們依據自己的常識認為H的語義能夠由P的語義推理得出的話,那么稱P蘊含H,記作P→H[1]。文本蘊含識別任務的目的是判斷這兩個文本之間的語義關系:蘊含(Entailment)、矛盾(Contradiction)、中立(Neutral)。從另一個角度來看,這是融合語義關系的三分類問題,具體示例如表1所示。

表1 數據示例
近些年來,隨著深度學習的快速發展,以及大規模數據集的發布,越來越多的研究者開始將深度神經網絡應用于文本蘊含關系識別任務中[2-4],并在一些數據集上取得了巨大的提升。在深度學習的方法中,許多研究者都采用長短期記憶網絡(Long Short-Term Memory,LSTM)對句子進行建模,分別得到兩個句子的句向量表征,再通過互注意力機制學習兩個文本之間的交互信息,最后通過分類器判定兩個句子之間的語義關系[5-7],當前的大多數研究也都是基于句向量表征和互注意力機制的方法。雖然這些方法相比之前的傳統方法有著巨大的提升,但是仍面臨一些問題需要解決:
(1)互注意力機制的方法只能捕獲局部交互信息。僅考慮局部交互信息,易弱化句子的整體信息。
(2)未考慮句子的句法信息。大多數方法都注重句子之間的信息交互,忽略了句子的句法結構信息。
針對上述問題,該文提出了融合句法結構和摘要信息的文本蘊含識別模型,并將文本蘊含識別的思想應用于公務員試題中,主要貢獻如下:
(1)在句子交互基礎之上,兼顧句子的全局信息。將互注意力機制和自注意力機制相結合,從局部交互信息和全局信息出發,推測句子之間的語義關系。
(2)融入句子的句法信息。捕捉句法結構這一重要特征,并融入句子表示。
(3)將該模型應用于公務員試題答題中。首先,從公務員試題的選擇題中整理出符合語義關系的語句對,構建出八千余組數據;然后,將該模型遷移至這些數據上進行實驗,嘗試利用文本蘊含識別的思想。
1 相關工作
2015年,Bowman等人[8]發布了大規模的文本蘊含識別數據集SNLI,SNLI數據集一共包含570k個文本對,其中訓練集550k,驗證集10k,測試集10k,一共包含蘊含(Entailment)、矛盾(Contradiction)和中立(Neutral)三種語義關系標簽。
隨著大規模語料庫的出現,越來越多的研究者開始將深度學習應用于文本蘊含識別研究領域。Chen等人[9]將LSTM和Attention機制相結合,在SNLI數據集上達到了88.6%的準確度,并且,時至今日該研究仍被應用于文本匹配、問答任務等多個領域。Kim等人[10]引入了DenseNet的思想,利用LSTM搭建5層RNN網絡,同時將上一層的參數拼接到下一層,然后使用AutoEnconder進行降維,在公共數據集上達到了當時的最優性能。Sainz等人[11]將事件抽取和文本蘊含任務相結合,使得模型在文本蘊含識別任務上的性能得到一定程度的提升。Bauer等人[12]將外部知識融入文本蘊含識別任務中,實驗結果表明,在跨領域數據集中引入外部知識,能夠顯著提高模型性能。
近些年來,也有部分研究者開始關注中文文本蘊含識別領域的研究。2018年,CCL2018發布了包含11萬條數據的中文數據集CNLI。2020年,Hu等人[13]構建了第一個非翻譯的、使用原生漢語的大型中文文本蘊含數據集(OCNLI),OCNLI數據集包含5萬余訓練數據,3千條驗證數據及3千條測試數據,數據來源于政府公報、新聞、文學、電視談話節目等多個領域。
譚詠梅等人[14]將句子的字符特征、句法特征、語義特征等提取出來,使用貝葉斯邏輯回歸模型進行蘊含識別得到初步結果,然后使用規則集合進行過濾,得到最終的蘊含結果,但是傳統的機器學習方法需要人工篩選大量特征,所以又提出了基于神經網絡的方法[15],該方法使用CNN與LSTM分別對句子進行建模,自動提取相關特征,然后使用全連接層進行分類。于東等人[16]將文本蘊含識別的三分類擴展為七分類的蘊含類型識別和蘊含語塊邊界類型識別,在ESIM[8]和BERT[17]模型上分別達到了69.19%和62.09%的準確率。王偉等人[18]認為現有推理模型的訓練時間較久,提出了輕量級的文本蘊含模型,在保持識別準確率的同時,相對于其他主流文本蘊含模型,推理速度提升了一倍。
目前,大多數方法都是采用互注意力機制實現句子之間的交互,這種方法弱化了句子的全局信息,并且沒有考慮句子的句法結構信息。鑒于上述情況,該文提出融合句法結構和摘要信息的文本蘊含識別模型,該模型能夠抽取出文本的主要信息,并在編碼過程中融入句子的句法信息,在實現句子之間局部信息交互的基礎之上,獲取句子全局信息,從而更準確地識別兩個句子的語義關系。最后,將該模型應用于公務員試題答題中,嘗試解決實際問題。
2 模型架構
本節描述了融入句法結構和摘要信息的文本蘊含識別模型,如圖1所示。
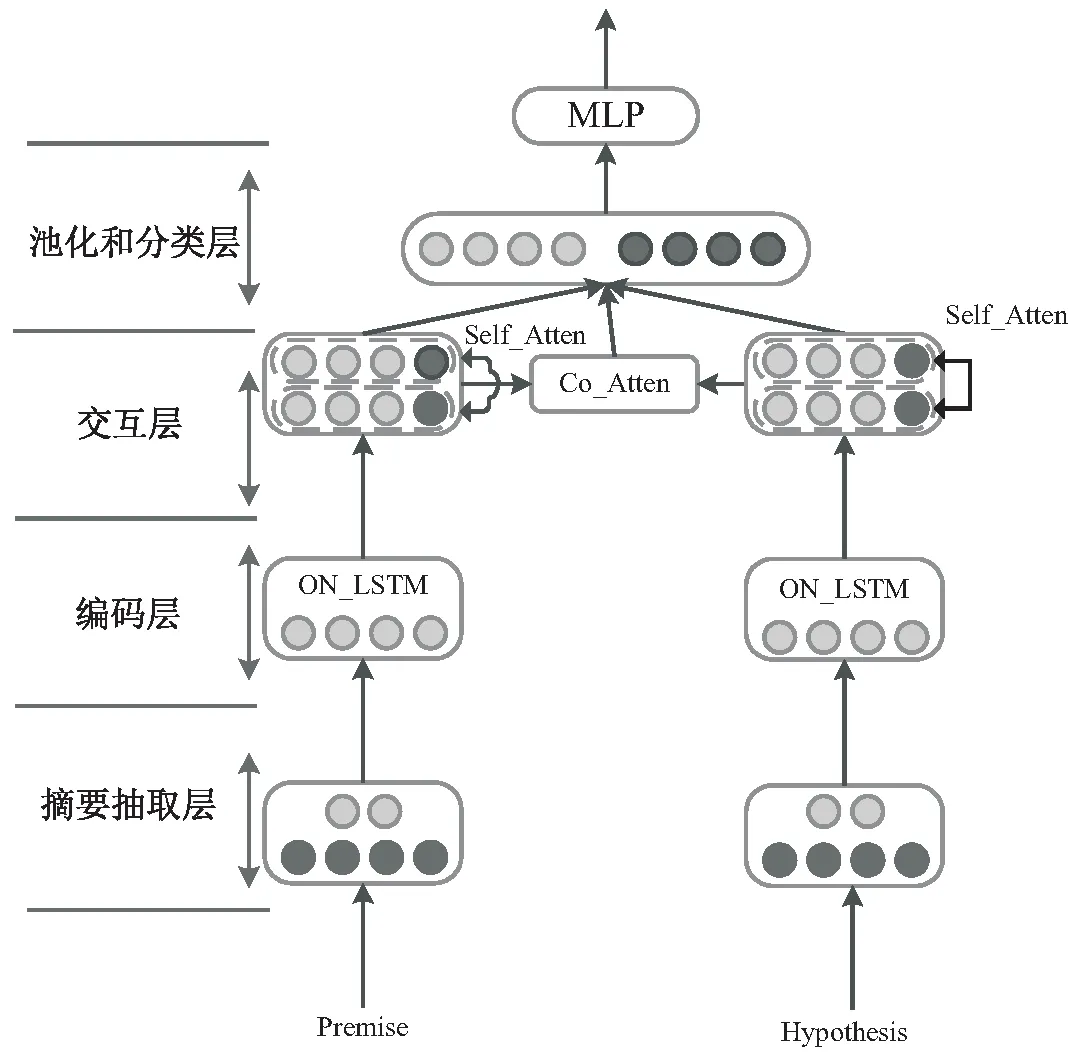
圖1 模型圖
該模型共分為4部分:
(1)摘要抽取層。該層僅應用于公務員試題中,主要是利用TextRank[19]算法,抽取出前提句的主要信息,以解決公務員試題題目冗長、答案簡短導致的句子長度不對稱問題。
(2)編碼層。這一部分主要是將前提句和假設句輸入到ONLSTM[20]網絡中,得到融合句法結構和上下文信息的特征表示。
(3)交互層。該層主要是利用互注意力機制和自注意力機制,分別捕獲句間的交互信息和句子的全局信息。
(4)池化和分類層。利用池化操作,將交互信息和全局信息轉化為固定維度的特征表示,然后將其輸入到全連接層中,得到最終的分類結果。
2.1 摘要抽取層
在公務員試題中,前提句(題目)實際上是一段長文本,如果對前提句這樣的長文本進行建模,部分與答案無關的句子信息反而會成為建模過程中的噪聲,導致主要信息被掩埋,從而影響最終的結果。因此,引入TextRank算法,既能從題目中抽取出主要信息,也能最大程度避免信息的損失。
TextRank算法是將一段文本構建為一個加權圖,文本中的句子視為網絡中的節點,根據節點權重的大小對句子進行排序,從而生成文本的摘要。計算每個句子的權重,首先需要計算句子Si和Sj之間的相似度,如果Si和Sj相似,則認為句子之間存在一條無向有權邊,相似度的計算是由句間的內容重疊率得出,TextRank算法計算相似度的公式如公式(1)所示:
(1)
上述相似度計算方法,依賴于兩個句子包含相同詞語的個數,兩個句子包含相同詞語的個數越多,則相似度越高,這種計算方法僅考慮了詞語的共現,沒有考慮句子本身的句意。因此,將句子轉化為向量化表示,通過余弦相似度計算兩個句子之間的相似度。首先對前提句進行分詞,然后使用Word2Vec[20-21]獲取每個詞語的詞向量,再對這些詞向量加和求平均,以此得到每個句子的句向量S,最后計算每個句子之間的余弦相似度,以此作為句子相似度的衡量標準:
Similarity(Si,Sj)=cos(Si,Sj)
(2)
得到句子相似度之后,以句子作為節點,句間相似度作為邊,利用權重公式得出每個句子的權重,權重計算公式如下:
(3)
其中,WS(Vi)是節點Vi的權重;d為阻尼系數,一般取0.85,表示某一節點跳轉到另一節點的概率;wij是兩個句子之間的相似度Similarity(Si,Sj);In(Vi)表示指向節點Vi的節點集合;Out(Vi)是節點Vi指向的節點集合。
利用TextRank算法,抽取出權重排名前2的句子作為前提句,關于句子抽取數量對實驗結果的影響,該文也會在實驗環節進行實驗分析。
表2中展示的是原始的公務員試題,其中,前提句表示試題的題目,假設句是試題的答案,在標簽列中,“蘊含”是正確答案的語句對,“矛盾”是錯誤答案的語句對,并且,兩條數據的前提句均相同。

表2 試題示例(抽取前)
在接下來的表3中,展示了對試題題目進行摘要抽取后的試題示例。

表3 試題示例(抽取后)
2.2 編碼層
該部分主要作用是將前提句和假設句分別進行建模,并在建模過程中,融入句子的句法信息。
句法是指短語和句子的結構方式,表現為詞語在句子中的排列方式及其相互關系。在處理句子信息時,句法信息是一條極其重要的規則化信息,一些完全相同的詞語根據不同的排列形式進行組合,可能得到語義完全不同的句子,如:“我站在他身后”和“他站在我身后”,就是詞語完全相同,但是語義相反的一對句子。Shen等人[20]提出了ONLSTM(Ordered Neurons LSTM),它能夠在邏輯上將不同的神經元劃分到不同的層級中,從而將句子的層級結構融入到LSTM中,使得模型具有更強大的表示能力。
(4)
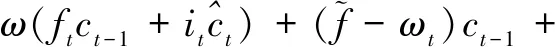
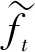
[x1,x1+x2,…,x1+x2+…+xn]
(5)
[x1+x2+…+xn,…,xn+xn-1,xn]
(6)
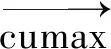
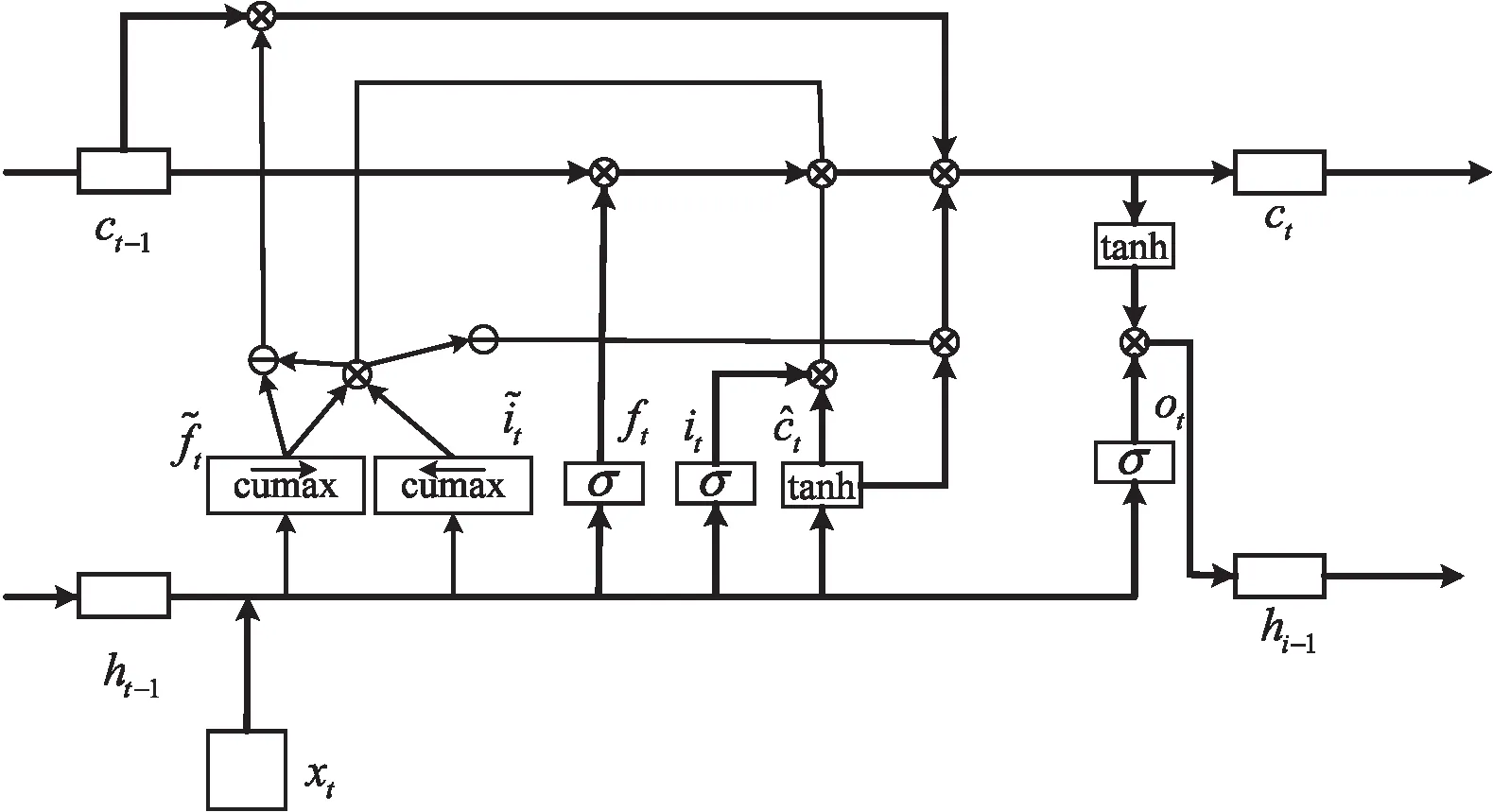
圖2 ONLSTM結構
2.3 交互層
判斷文本蘊含關系的大部分方法都是利用互注意力機制捕獲句子之間的交互信息,將交互信息作為句子分類的重要標準,但是這種方法并沒有充分考慮句子的全局信息。因此,該文在利用互注意力實現句子交互的同時,使用自注意力機制獲取句子的全局信息,以此兼顧句間的交互信息和句子本身的全局信息。
2.3.1 自注意力
在對句子建模時,句子中的一個詞語往往不是獨立的,它的語義和上下文息息相關,所以,在處理單個詞語的同時,也要重點關注它的上下文信息,以及和它本身關聯性較高的詞語,而自注意力機制能夠將句子內部的每個詞語相互匹配,并將更多的注意力聚焦在重點信息上,從而更有效地捕獲句子的全局信息。
Up=softmax(Ws1tanh(Ws2P))
(7)
Uh=softmax(Ws1tanh (Ws2H))
(8)
在上述公式中,使用兩層前向神經網絡計算self-Attention矩陣U,其中P和H是經過ONLSTM得到的向量表征,Ws1和Ws2是需要學習的參數。
Ps=UpPT
(9)
Hs=UhHT
(10)
其中,Ps和Hs是經過self-Attention矩陣加權后得到的向量,表示句子中每個詞語之間的依賴關系。
(11)
(12)
公式(11)(12)的主要作用對信息進行增強,其中減法運算能夠突出兩個序列信息之間的差異程度,⊙表示點乘運算,能夠突出兩個序列信息之間的相同程度。
2.3.2 互注意力
互注意力機制的關注對象是兩個不同的序列,根據序列中詞語的權重,重點關注權重高的部分,降低對權重較低部分的關注度。在文本蘊含識別這一任務中,互注意力機制能夠捕獲前提句和假設句之間不同詞語的依賴關系。
該部分的主要工作是在對句子建模后,利用互注意力機制獲取句子間的交互信息,然后,使用和公式(11)(12)相同的方法對交互信息進行增強。
eij=PTH
(13)
公式(13)是計算前提句和假設句中詞語之間相關性矩陣eij。
(14)
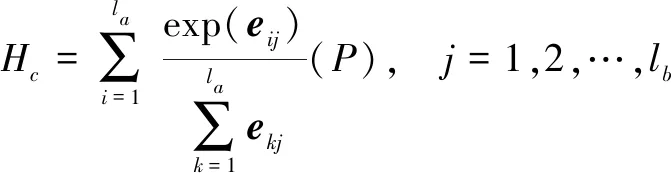
(15)
再將eij按照兩個維度進行歸一化,分別和P、H進行計算,得到交互后的向量表示Pc和Hc。
(16)
(17)
公式(16)(17)和2.3.1小節的方法相同,用以突出兩個向量之間的差異程度和對齊程度。
2.4 池化和分類層
此模塊的主要作用是將自注意力模塊和互注意力模塊的輸出融合,以此作為判斷語義關系的依據。
(18)
(19)
其中,公式(18)(19)是將互注意力和自注意力模塊的輸出向量分別進行最大池化和平均池化,以此將信息壓縮成固定維度的向量。
(20)
上述公式表示分別將互注意力模塊與自注意力模塊的池化向量進行拼接。
y=F(O)
(21)
F為兩層全連接層,使用tanh激活函數,通過softmax函數預測最終的語義蘊含結果。
在上述整個模型中,將交叉熵損失函數(Cross Entropy)定義為損失函數,公式如下:
(22)
其中,N表示樣本個數,yi表示語義關系標簽(0,1),Pi表示每種語義關系標簽的概率。
3 實驗設計與結果分析
3.1 數據集
首先在SNLI和CNLI數據集上驗證模型的有效性,然后將模型和文本蘊含識別的思想遷移至公務員試題中進行實驗。接下來,將具體介紹公務員試題收集和處理過程。
在公務員試題中,包含主旨概括、意圖判斷和細節理解等多種題型,該文經過多次篩選,最終選取了主旨概括和意圖判斷類型試題,這是因為這兩種類型試題的答案大多都是對題目本身的概括或總結,是一種自然的語義蘊含語句對。滿足語義蘊含條件的同時,還需要滿足語義矛盾的語句對,因此,在將這些試題爬取后,又對這些試題進行了再次篩選,從5 127條試題中篩選出4 199條試題,在這一輪的篩選中,將這些答案和題目組成語義矛盾的語句對。最終,從公務員試題中構建了8 398組數據的語義蘊含和語義矛盾的語句對,并將其命名為:CSEQ(Civil Service Examination Questions),具體細節如表4所示。
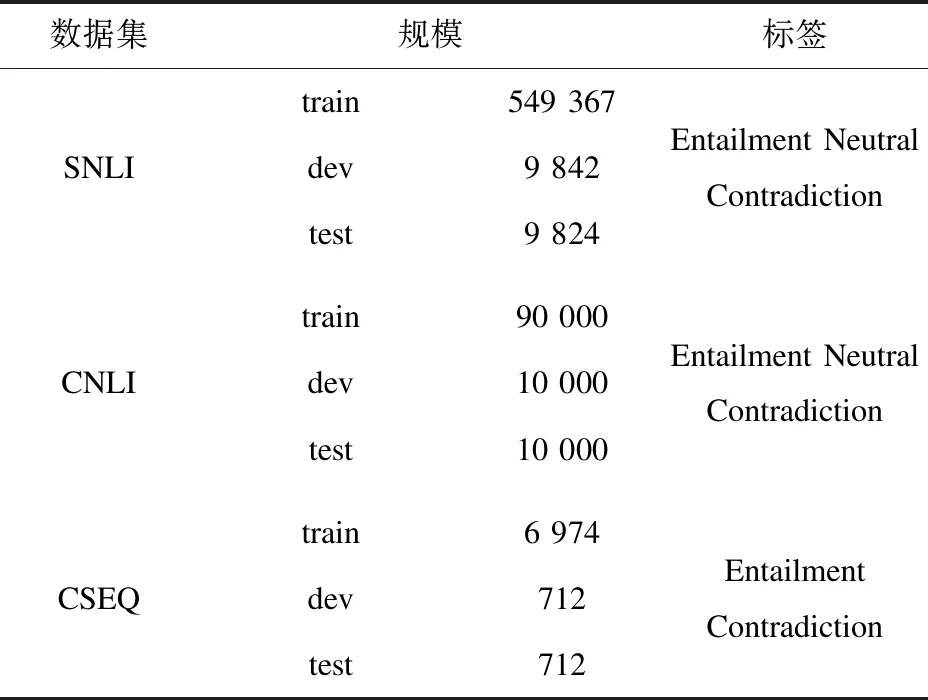
表4 3種數據集規模
在CSEQ數據集中,僅有“Entailment”和“Contradiction”標簽,這是由于,CSEQ來源于該文收集和整理的公務員試題,其受限于試題本身僅有正確和錯誤答案的限制,因而并未設置“Neutral”標簽。
3.2 參數設置
模型的損失函數為交叉熵損失函數,使用反向傳播算法更新模型參數,BatchSize設置為32,為防止模型過擬合,采用Dropout策略,Dropout Rate設置為0.5,學習率設置為0.000 05。模型在SNLI數據集上的實驗,使用預訓練好的300維Glove詞向量[22],在中文數據集上的實驗,使用預訓練好的300維的Word2Vec詞向量[20]。
3.3 評價指標
準確率是文本蘊含識別任務的通用評價指標,即所有樣例中被預測正確的比例,具體計算公式如公式(23)所示:
(23)
其中,TP表示將正類預測為正類數,TN表示將負類預測為負類數,FP表示將負類預測為正類數,FN表示將正類預測為負類數。
3.4 實驗結果與分析
選取了多個實驗對比模型,以此分析文中模型的性能。
在基于SNLI數據集(英文)的實驗中,對比了多個基準模型:
①BiMPM[23]:使用BiLSTM在兩個方向上對前提句P和假設句H進行匹配,最后使用全連接層進行分類。
②ESIM[8]:利用BiLSTM對前提句和假設句進行編碼,利用互注意力機制交互,再通過另一個BiLSTM將信息融合。
③KIM[24]:采用BiLSTM+Atten的方法,同時將WordNet作為外部知識引入,以此提升詞向量的質量。
④DMAN[25]:利用強化學習來整合不同樣本的標注意見不統一的情況,從而提升模型的穩定性。
⑤EFL[26]:該模型利用二分類數據預訓練roBERTalarge模型,然后將其應用于文本蘊含識別任務中,取得了當前最好的性能。實驗結果如表5所示。
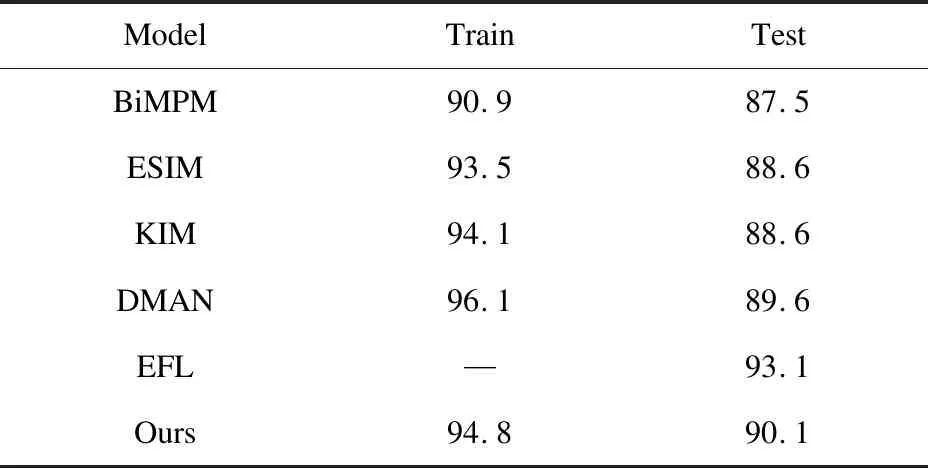
表5 實驗結果(SNLI)
從表5可以看出:(1)與模型BiMPM相比,文中模型具有一定的優勢,這是因為BiMPM注重捕捉兩個句子之間的交互特征,忽略了句子的全局信息,而文中模型在捕捉交互特征的同時,也捕獲了句子的全局信息;(2)與模型ESIM、KIM和DMAN對比,文中模型表現更佳,這是因為這三種模型雖然分別采用了信息融合、引入外部知識和強化學習的方法,但是忽略了句子本身的句法信息,然而,在語義理解這一類型的任務中,句法信息是更加重要的特征;(3)模型EFL的性能更佳,這是因為該方法使用二分類數據預訓練roBERTaLarge模型,其主要優勢源于二分類預訓練語料庫,而文中模型專注于文本蘊含識別這一任務。
在基于CNLI數據集(中文)展開的實驗中,由于KIM引入WordNet作為外部知識、DMAN建立在標簽意見不統一的基礎之上以及EFL使用大規模的英文語料庫預訓練roBERTaLarge模型,所以該文并未對以上三種模型進行復現,而是額外增添了中文領域的文本蘊含識別模型作為基準模型:
①混合注意力模型[27]:利用混合注意力獲取詞語和句子級別的語義信息,根據融合后的語義信息獲取最終的分類結果;
②SRL-Attention[28]:將語義角色和自注意力機制融合,以此提升模型性能。CNLI數據集上的實驗結果如表6所示。
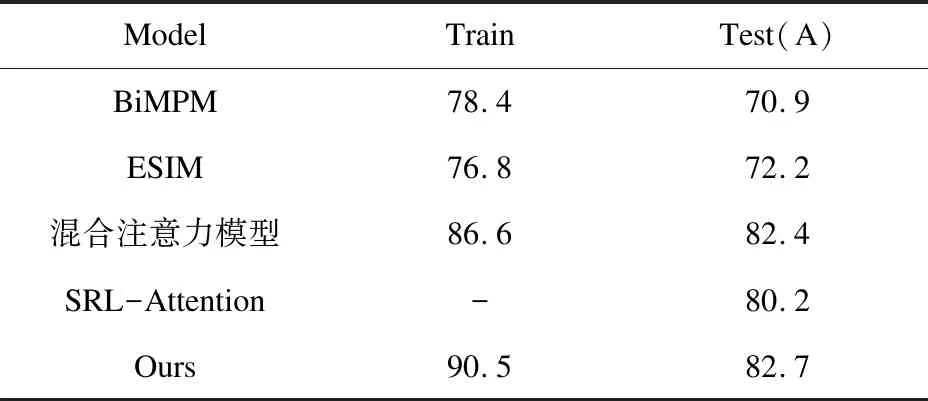
表6 實驗結果(CNLI)
從表6可以看出,BiMPM和ESIM在中文數據上的表現稍遜一籌,這可能由于這兩種模型在SNLI數據集的基礎之上進行實驗,由于SNLI數據集龐大且存在中英文語義鴻溝的問題,所有這兩種模型的表現并不理想,SRL-Attention模型由于并未公布測試集準確率,因此以“-”代替。
從表7可以看出,文中模型在性能上優于對比的多個基準模型,這是因為前兩種模型都是將句子之間的交互信息作為主要判別標準,與此相比,文中模型能夠在捕捉句子交互特征的同時,利用自注意力機制捕捉句子的全局信息;相對于“混合注意力模型”,文中模型表現更佳,這可能由于文中模型融入了句子的句法結構。
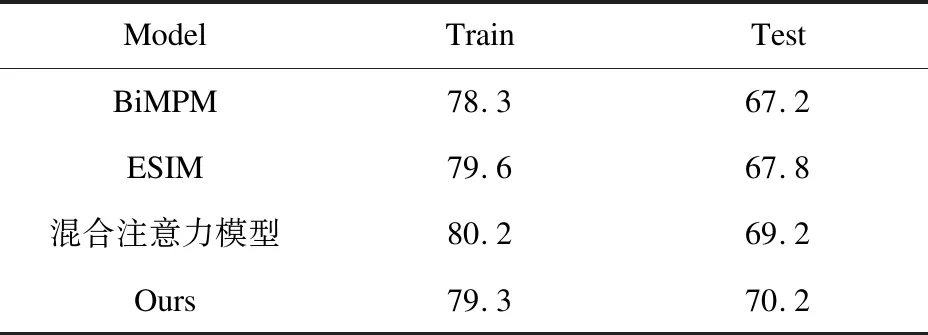
表7 實驗結果(CSEQ)
3.5 消融實驗
在多個數據集上進行了消融實驗,以研究各模塊對模型性能的影響。實驗結果如表8、表9所示。
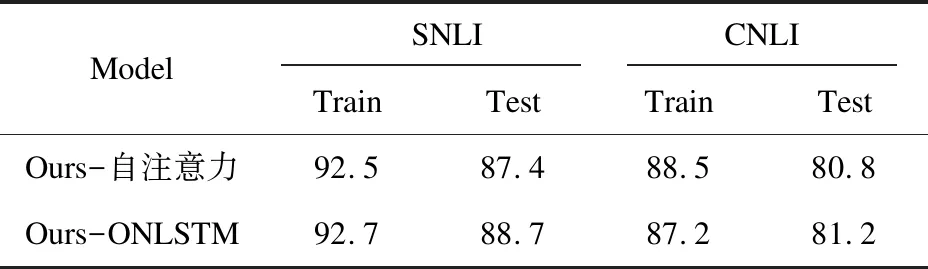
表8 消融實驗
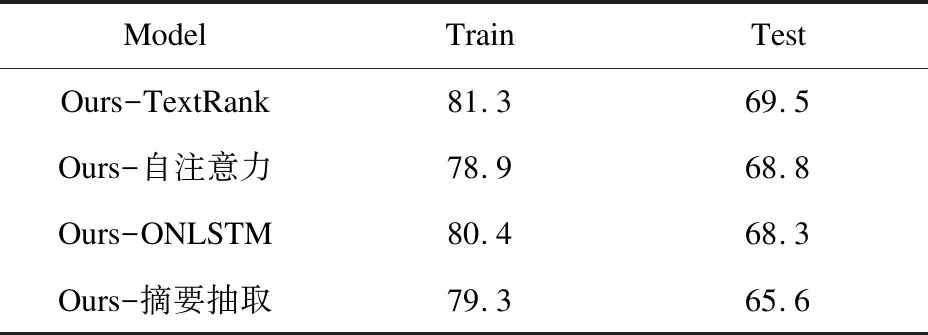
表9 消融實驗(CSEQ)
綜合表8、表9的實驗結果,可以看出:
(1)Ours-TextRank:使用詞向量代替詞語的共現程度,能夠抽取出更加準確的語句,從而使準確率提升了0.7百分點;
(2)Ours-自注意力:移除自注意力機制之后,SNLI數據集上的準確率下降了2.7百分點,CNLI和CSEQ數據集上分別下降了1.9百分點和1.4百分點,說明句子的全局信息能夠為語義關系的推測,提供更多的理論依據;
(3)Ours-ONLSTM:去除ONLSTM后,使用普通的LSTM對句子進行建模,模型的性能分別下降了1.4、1.5和1.9百分點,這說明在句子級別的任務中,句子的句法結構是一個重要的特征;
(4)Ours-摘要抽取:如果不利用文本摘要的方法處理前提句,這一任務則從句子—句子級別轉換為段落—句子級別的任務,這背離文本蘊含識別任務的初衷,且公務員試題中,題目內有大量和答案無關的句子,這會帶來大量的噪音以及前提句和假設句長度不對稱的問題,因此,在去除前提句處理模塊后,模型的性能下降了4.6百分點。
為了探究摘要抽取的句子數量對模型的影響,針對不同句子數量分別進行了實驗,實驗結果如表10所示。
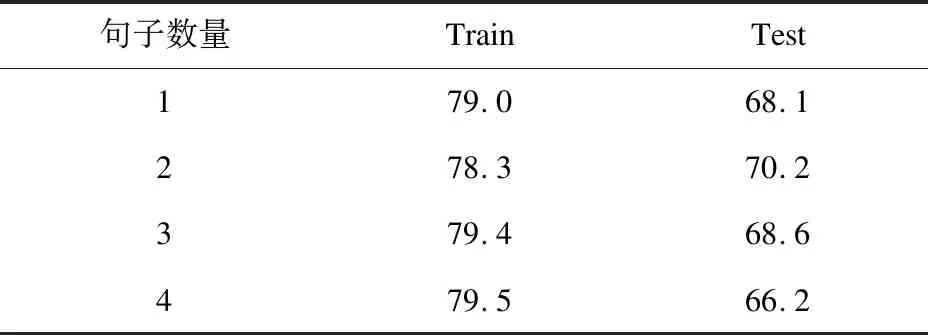
表10 實驗結果(抽取不同數量句子)
從表10可以看出,在抽取的句子數量為2時,準確率最高,在抽取1個句子和3個句子的情況下,準確率分別下降了2.1和1.6百分點,在抽取4個句子的情況下,則下降了4.0百分點。通過上述實驗數據可以發現,如果抽取的句子數量過少,會導致信息的缺失,而句子數量過多,也會帶來額外的噪音,導致準確率的下降。
4 結束語
該文提出了融合句法結構和摘要信息的文本蘊含識別模型,該模型利用摘要抽取算法抽取出前提句的主要信息,并在建模階段融合了句子的句法結構信息,同時兼顧句子的全局信息和局部交互信息,并將該模型和文本蘊含識別的思想應用于公務員試題答題。實驗結果表明,該模型在英文和中文數據集上的表現優于多個基準模型。
該文仍有一些工作需要改進。在構建的數據集中僅有“蘊含”和“矛盾”標簽的語句對,缺乏“中立”標簽的語句對,這需要進一步標注工作;在下一步的工作中,也將考慮融入外部知識,以更好地判別句子語義關系。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
