高低維特征引導的實時語義分割網絡
2023-10-21 07:09:02虞資興瞿紹軍何鑫王卓
計算機應用 2023年10期
虞資興,瞿紹軍*,何鑫,王卓
高低維特征引導的實時語義分割網絡
虞資興1,瞿紹軍1*,何鑫2,王卓1
(1.湖南師范大學 信息科學與工程學院,長沙 410081; 2.湖南華諾星空電子技術有限公司,長沙 410221)( ? 通信作者電子郵箱qshj@hunnu.edu.cn)
多數語義分割網絡利用雙線性插值將高級特征圖的分辨率恢復至與低級特征圖一樣的分辨率再進行融合操作,導致部分高級語義信息在空間上無法與低級特征圖對齊,進而造成語義信息的丟失。針對以上問題,改進雙邊分割網絡(BiSeNet),并基于此提出一種高低維特征引導的實時語義分割網絡(HLFGNet)。首先,提出高低維特征引導模塊(HLFGM)來通過低級特征圖的空間位置信息引導高級語義信息在上采樣過程中的位移;同時,利用高級特征圖來獲取強特征表達,并結合注意力機制來消除低級特征圖中冗余的邊緣細節信息以及減少像素誤分類的情況。其次,引入改進后的金字塔池化引導模塊(PPGM)來獲取全局上下文信息并加強不同尺度局部上下文信息的有效融合。在Cityscapes驗證集和CamVid測試集上的實驗結果表明,HLFGNet的平均交并比(mIoU)分別為76.67%與70.90%,每秒傳輸幀數分別為75.0、96.2;而相較于BiSeNet,HLFGNet的mIoU分別提高了1.76和3.40個百分點。可見,HLFGNet能夠較為準確地識別場景信息,并能滿足實時性要求。
實時語義分割;上采樣;注意力機制;金字塔池化;上下文信息
0 引言
語義分割(semantic segmentation)是計算機視覺領域的研究熱點之一,它的主要價值是能夠將圖像分割成幾組具有某種特定語義的像素區域,并識別每個區域的類別,最終獲得幾幅具有像素語義標注的圖像。因此語義分割在室內導航、地理信息系統、自動駕駛、虛擬增強現實系統和場景理解等領域有著重要的應用價值[1]。傳統語義分割利用圖像灰度、空間紋理、顏色和幾何形狀等低級特征將圖像分割成不同部分,主要有基于閾值的分割方法[2]、基于邊緣的分割方法[3]、基于區域的分割方法[4-5]和基于圖的分割方法[6]等。雖然這些方法分割速度快,但需要人為設計特征提取器,同時對復雜場景的分割效果不佳。基于深度學習的語義分割方法表現出強大的特征提取能力,Long等[7]提出全卷積網絡(Fully Convolutional Network, FCN),將卷積神經網(Convolutional Neural Network, CNN)[8]中的全連接層替換為全卷積層以實現像素級的密集預測,使用反卷積對特征圖上采樣,并提出跳躍連接充分融合全局語義信息和局部位置信息,實現精確分割[9],為語義分割的快速發展奠定了基礎。
盡管FCN模型強大且普適,但它固有的空間不變性導致它沒有考慮有用的全局上下文信息;同時,隨著圖像不斷的下采樣操作,分辨率不斷縮小,導致部分像素丟失,嚴重影響了最終的分割精準性。針對前者,金字塔場景解析網絡(Pyramid Scene Parsing Network, PSPNet)[10]使用金字塔池化(Pyramid Pooling)模塊抽取多尺度的上下文信息,以解決物體多尺度的問題從而提升精度;DeepLab-v2[11]提出了一種新的空洞卷積(Atrous Convolution),以抽取多尺度上下文信息。針對后者,Ronneberger等[12]提出了一種編碼器?解碼器的網絡模型U-Net,U-Net由收縮路徑和擴展路徑組成:收縮路徑利用下采樣捕捉上下文信息,提取特征;擴展路徑是一個解碼器,使用上采樣操作還原原始圖像的位置信息,逐步恢復物體細節和圖像分辨率。Yu等[13]利用雙分支結構設計了雙邊分割網絡(Bilateral Segmentation Network, BiSeNet),主要思想是用一個帶有小步長的空間路徑保留空間位置信息,生成低級的高分辨率的特征圖;再用輕量特征提取網絡結合全局池化操作,合并不同層(level)的中間特征與全局池化的輸出,得到高級的低分辨率的語義信息,最后將兩者融合得到高級的高分辨率特征圖。但是,上述方法并沒有考慮多尺度特征融合過程中語義信息丟失的問題。語義流網絡(Semantic Flow Network, SFNet)[14]將光流法的思想應用在特征對齊中,提出了流對齊模塊以加強特征表示;但是它的計算成本太高,導致網絡并不適用于實時應用。
針對語義分割模型在多尺度特征融合過程中出現語義信息丟失、細節信息冗余的問題,提出一種高低維特征引導的實時語義分割網絡(High-Low dimensional Feature Guided real-time semantic segmentation Network, HLFGNet)。
本文的主要工作如下:
1)提出高低維特征引導模塊(High-Low dimensional Feature Guided Module, HLFGM),解決BiSeNet在合并不同level的中間特征時,由于特征圖尺寸不同出現的語義信息丟失問題。
2)提出金字塔池化引導模塊(Pyramid Pooling Guided Module, PPGM)。改進金字塔池化模塊(Pyramid Pooling Module,PPM),利用原始特征圖引導不同尺度的池化特征圖,加強不同尺度局部信息的有效融合,增強全局上下文信息提取能力。
在公開數據集Cityscapes[15]和CamVid[16]上的實驗結果顯示,HLFGNet具有較好的分割效果。
1 相關工作
1.1 基于卷積神經網絡的語義分割
DeepLab-v1使用空洞卷積[17]解決編碼過程中因為信號不斷被下采樣導致細節丟失的問題;使用全連接條件隨機場(Fully-connected Conditional Random Field)提高模型捕獲結構信息的能力,從而擴大感受野和捕捉邊緣細節,但并未注意多尺度信息。DeepLab-v2[11]提出空洞空間金字塔池化(Atrous Spatial Pyramid Pooling, ASPP)模塊,在給定的特征層上使用不同擴展率(dilation rate)的空洞卷積,可以有效地重采樣。通過構建不同感受野的卷積核獲取多尺度物體信息,解決不同檢測目標大小差異的問題。隨著空洞率的增大,卷積核的有效參數越來越少,最終會退化成1×1的卷積核。DeepLab-v3[18]將ASPP模塊中尺寸為3×3、膨脹率=24的空洞卷積替換成一個普通的1×1卷積,以保留濾波器中間部分的有效權重;最后的特征圖通過16倍雙線性插值上采樣變為與輸入圖像相同大小的分辨率,但這種方法無法獲得分割目標的細節。DeepLab-v3+[19]在DeepLab-v3的基礎上引入解碼網絡以恢復丟失的邊界信息,提高了物體邊界分割的準確度。PSPNet[10]采用4路并行的不同尺度自適應平均池化,分別獲取不同尺度劃分下的局部上下文信息后在通道上合并,提高全局信息的獲取能力。
1.2 實時語義分割
實時語義分割算法需要一種快速生成高質量預測的方法,即推理速度要達到30 frame/s。現階段的算法主要通過裁剪或限定圖像大小降低計算復雜度,或通過分解卷積提高實時性。用于實時語義分割的深度神經網絡架構——高效神經網絡(Efficient neural Network, ENet)[20]通過早期下采樣策略,裁剪模型通道,減少運算和降低內存占用,但裁剪會丟失細節信息;圖像級聯網絡(Image Cascade Network, ICNet)[21]使用圖像級聯加速語義分割方法;BiSeNet[13]利用一條淺層分支獲取空間細節,另一條分支獲取深層的語義信息,再將兩條分支融合輸出;BiSeNet V2[22]去掉了舊版本中耗時的跨層連接,深化細節路徑以編碼更多細節,設計了基于深度卷積的輕量級語義路徑組件;Fan等[23]重新設計網絡架構,將空間邊界信息的學習集成到低層級部分,同時設計短期密集連接(Short-Term Dense Concatenate, STDC)模塊,融合連續若干個不同感受野的卷積核以彌補語義分支感受野的不足,有效提取語義邊界區域特征;Peng等[24]提出一種高效的實時語義分割模型PP-LiteSeg,在解碼器的部分逐步減少特征通道并恢復分辨率,保證深層階段語義信息的完整,同時減少淺層階段的冗余計算。
1.3 注意力機制
注意力可以有效地捕獲不同位置(像素)之間的長程相關性,所有位置的加權和得到每個位置的特征;因此,每個位置(像素)都可以獲得全局視野,并且不降低特征映射(分辨率降低)。壓縮激勵網絡(Squeeze-and-Excitation Network, SENet)[25]通過全局平均池化(Global Average Pooling, GAP)和全連接層獲得通道注意圖;卷積塊注意模塊(Convolutional Block Attention Module, CBAM)[26]將GAP和全局最大池化結合1×1卷積操作,得到一個帶有注意力的特征圖。雙重注意網絡(Dual Attention Network, DANet)[27]提出整合局部信息和全局信息以捕捉上下文信息,再由注意力機制獲得特征表達。雙邊注意力網絡(Bilateral Attention Network, BANet)[28]利用通道相關系數注意模塊學習通道映射之間的正負依賴關系,并利用所有通道映射的加權和更新每個通道映射。全局上下文注意力模塊(Global Context Attention Module, GCAM)[29]由注意力細化模塊分別對平均池化和最大池化后的特征進行通道加權,重新調整特征權重,得到與它們大小對應的權重圖,再由元素加法操作融合特征,以極少的計算量獲得更加豐富的全局上下文信息,最后利用3×3卷積進一步增強特征的表達能力。注意力網絡(ATTention Network, ATTNet)[30]提出空間?條形注意力模塊,采用1×和×1的條形池化核提取特征,避免傳統池化核帶來的無關信息和額外參數計算,從而有效捕獲局部區域的長距離依賴關系。基于注意力感知的全卷積網絡CANet(Context Attention Network)[31]提出空洞空間金字塔注意力模塊,在空洞空間金字塔中嵌入像素相似注意力模塊,增強像素之間的聯系,解決像素丟失的問題。輕量級注意力引導的非對稱網絡(Lightweight Attention-guided Asymmetric Network, LAANet)[32]提出注意力引導的擴展金字塔池化(Attention-guided Dilated Pyramid Pooling, ADPP)模塊和注意力引導的特征融合上采樣(Attention-guided Feature Fusion Upsampling, AFFU)模塊,分別用于聚合多尺度上下文信息和融合不同層的特征。殘差高效學習和注意期望融合網絡(Residual Efficient Learning and Attention Expected fusion Network, RELAXNet)[33]將注意力機制引入編碼器和解碼器之間的跳躍連接中,促進高層特征和低層特征的合理融合。
1.4 特征融合
特征融合模塊(Feature Fusion Module, FFM)常用于語義分割,加強特征表示。除了逐元素求和外,研究人員還提出了以下幾種方法。在BiSeNet中,FFM采用element-wise mul方法融合自空間和上下文分支的特征。為了增強具有高級上下文的特征,深層特征聚合網絡(Deep Feature Aggregation Network, DFANet)[34]提出了一個具有多次連接結構的語義分割模塊,最大化多尺度的感受野。為了解決錯位問題,SFNet和特征對齊分割網絡(feature-Aligned Segmentation network, AlignSeg)[35]首先通過CNN卷積學習變換偏移量,其次利用變換偏移量引導低級特征和高級特征的融合。特征金字塔聚合網絡(Feature Pyramid Aggregation Network, FPANet)[36]利用可學習的向量進行加權以平衡兩個特征的級聯,再使用一個1×1卷積和三個不同速率的空洞卷積組成金字塔特征融合模塊。
2 高低維特征引導的實時語義分割網絡
BiSeNet是一個端到端的實時語義分割網絡,通過雙分支結構獲取高分辨率的高級特征圖。本文借鑒該思想,改進該網絡結構,設計了基于高低維特征引導的實時語義分割網絡(HLFGNet)。
2.1 網絡整體結構
本文網絡的整體結構如圖1所示,由一個提取高級語義特征的語義分支(Semantic Branch)、一個提取空間細節信息的細節分支(Detail Branch)和FFM構成。注意力細化模塊(Attention Refinement Module, ARM)和FFM模塊為BiSeNet中的兩個模塊,后文不再介紹。

圖1 高低維特征引導的實時語義分割網絡
在語義分支中,主干網絡采用在ImageNet上預先訓練并去掉最后全連接層的殘差網絡ResNet-18(Residual Network-18)[37],即圖1中的第1個卷積(Conv)池化操作和后續的4個殘差(Res)塊,它的詳細結構如表1所示。

表1 ResNet-18的詳細結構
注:“7×7”表示卷積核大小為7×7,“64”為卷積核數(輸出通道數),“stride=2”表示步長為2,Maxpool表示最大池化,“×2”表示輸入數據將會執行該矩陣結構2次,后續結構以此類推。
每個Res(=1,2,3,4)都包含一個基本結構(包含殘差(residual)結構),具體結構如表1中Res塊的矩陣所示。首先,Res3塊經過ARM得到Out3,Res4塊經過PPGM獲取具有全局上下文信息的Out4,此時特征映射的大小減小到原始圖像的1/32。其次,Out3與Out4經過HLFGM得到原始圖像1/16大小的特征圖,該特征圖再和Res2塊一起作為輸入,經過HLFGM得到語義分支的最終輸出,此時特征映射的大小為原始圖像的1/8。
在細節分支中,原始圖像經過4個淺層的Stage得到原始圖像1/8大小的特征圖,它的詳細結構如表2所示。其中,Conv2d代表Conv+BN(Batch Normalization)+ReLU(Rectified Linear Unit)組合操作。
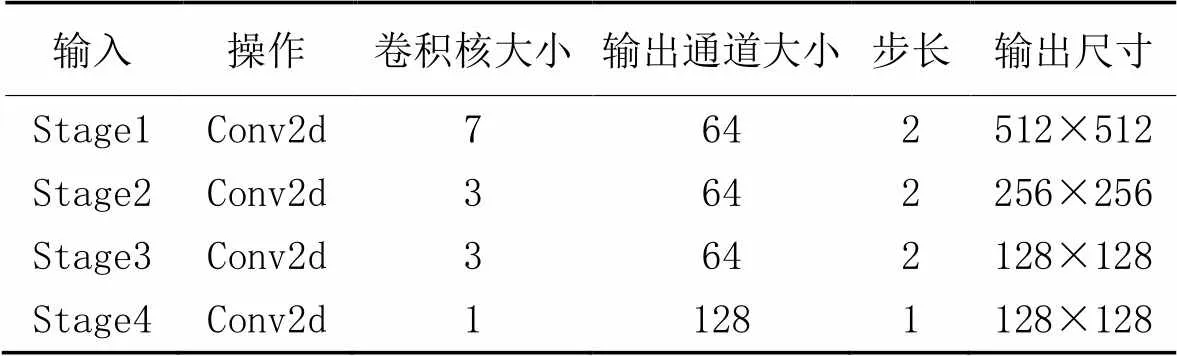
表2 細節分支的詳細結構
最后將兩個分支的輸出經過FFM融合,再經過上采樣恢復成最終的預測分割圖。
2.2 高低維特征引導模塊
語義分割的最終目的是獲得一幅高分辨率的高級語義特征圖。但是在卷積網絡中,圖像通過不斷的下采樣操作擴大感受野和獲取語義特征,降低了圖像的分辨率,導致空間細節信息丟失。一些網絡利用空洞卷積加強特征提取,同時保持高分辨率,但空洞卷積需要耗費較多的計算力,導致推理速度變慢;另外一些網絡將高級語義特征圖雙線性插值上采樣后再與對應分辨率的低級特征圖融合,逐步將分辨率恢復至原圖大小,但高層特征在經過padding、卷積等操作后和低層特征之間的精確位置對應關系已經丟失,而簡單的雙線性插值并不能解決該問題。SFNet[14]提出同一張圖像任意分辨率的兩個特征圖之間的關系,可以用一個特征圖到另一個特征圖的每個像素的“運動”表示,借助該運動關系引導高級特征圖的擴張可以有效減少語義信息的丟失。根據這一思想,結合SENet[25]中的通道注意力機制,提出高低維特征引導模塊(HLFGM),利用低級特征圖中的空間位置信息引導高級語義信息在上采樣過程中的位移,同時利用高級特征圖中的強特征表達消除低級特征圖中冗余的細節特征。HLFGM的詳細結構如圖2所示,計算方法如下:
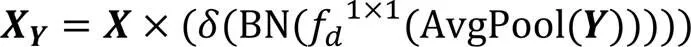

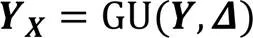
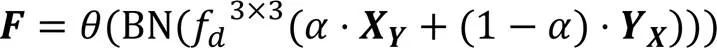
其中:,為低級特征圖;,為高級特征圖;×為矩陣的乘法;δ為Sigmoid激活函數;BN為批標準化操作;為標準的卷積操作,即圖2中的Conv1,卷積核大小為1×1,采樣步長為1,d為空洞率,默認為1,不做任何填充,卷積操作不改變特征圖的尺寸;AvgPool為順著空間維度平均池化;,用來指導低級特征圖上采樣的位移圖;為標準的卷積操作,即圖2中的Conv3,卷積核大小為3×3,采樣步長為1,在特征圖外側進行尺度為1的全1填充;Cat表示級聯拼接操作;Up為雙線性插值操作;GU為指導上采樣的對齊操作;為ReLU激活函數;為權重系數,值為0.7。
圖3(a)和圖3(c)分別為經過HLFGM得到的8倍和16倍下采樣可視化圖,圖3(b)和圖3(d)為未經過HLFGM得到的8倍和16倍下采樣可視化圖。對比圖3(a)和圖3(b)可以看出,前者獲取的細節信息和語義信息更加豐富,如第1行圖中車的輪廓、第3行圖中左側樹的輪廓和右側建筑的細節,而第2行圖中后者丟失遠處路桿特征;對比圖3(c)和圖3(d)可以看出,后者的整體效果較為模糊,細節信息丟失嚴重,而且第3行圖中的街邊和左側車底輪廓出現重影。另外圖3(b)和圖3(d)的第1行圖都出現了較為明顯的條狀紋理。

圖3 高層特征圖的可視化對比
2.3 金字塔池化引導模塊
全局上下文信息和子區域上下文信息有助于區分各種類別。大感受野可以提升大尺寸目標的分割效果,對網絡的性能具有重要意義。隨著卷積層越來越多,感受野也隨之變大,但Zhou等[38]證明CNN的經驗感受野遠小于理論感受野。BiSeNet使用GAP解決這一問題。雖然GAP廣泛應用于圖像分類中,并且它的計算量和內存消耗量低,但是對于復雜場景的圖像,GAP不足以覆蓋必要的信息,而且直接將圖像信息融合形成單個向量的形式可能會失去空間關系并導致歧義,影響最終的分割效果。因此本文采用改進的金字塔池化引導模塊(PPGM)獲取全局上下文信息,擴大感受野。PPGM的詳細結構如圖4所示,計算方法如下:
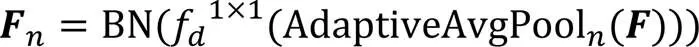
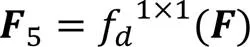
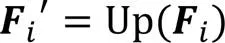


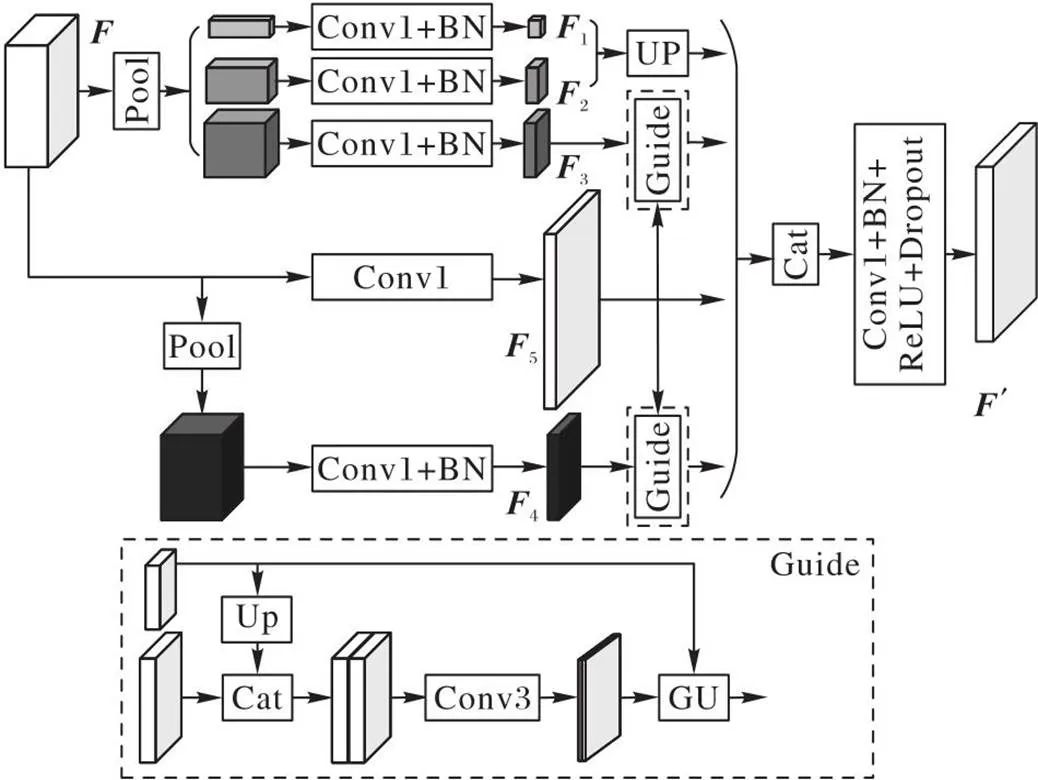
圖4 金字塔池化引導模塊
3 實驗與結果分析
3.1 實驗數據集
Cityscapes[15]是一個街道場景語義分割數據集,每一張圖像從行駛中的汽車的角度拍攝,從全世界50個不同的城市街道場景中收集5 000張高質量的像素級標注圖,其中訓練集、驗證集和測試集的圖像數分別為2 975、500和1 525張。5 000張圖像標注的類別有33類,本文訓練中只關心其中的19類。大類包括地面、建筑、人、天空、自然、背景、道路標志和車輛,小類將大類類別再細分(如車輛分為小汽車、公交等)。圖像分辨率大小均為2 048×1 024像素的RGB通道的彩色圖像,數據集還提供了20 000張粗略標注的圖像用于訓練弱監督分類網絡的性能。
CamVid[16]是來自劍橋的道路與駕駛場景圖像分割數據集,圖像數據自視頻幀提取,原始分辨率大小為960×720像素,包括32個類別。分為367張訓練圖像、100張驗證圖像和233張測試圖像。
3.2 評估指標
在分割評價方面,采用平均交并比(mean Intersection over Union, mIoU)和每秒傳輸幀數,即幀率作為評價指標。mIoU為圖像像素每個類的交并比(Intersection over Union, IoU)值累加后的平均值,如式(10)所示:
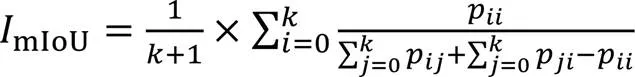
3.3 實驗細節
本文深度學習框架為PyTorch1.4,訓練時將圖像大小調整為1 024×1 024像素作為網絡輸入,損失函數采用交叉熵損失函數,驗證時圖像輸入大小為1 024×2 048像素。在兩塊Tesla-T4 GPU上訓練,在一塊Tesla-T4上測試模型。在訓練過程中,采用帶動量的隨機梯度下降法(Stochastic Gradient Descent, SGD)用于模型訓練,學習率下降公式為:

3.4 實驗分析和比較
為了驗證所HLFGM和PPGM的有效性,驗證HLFGNet的改進效果,使用3.1.3節的參數和配置,采用ResNet-18作為網絡主干,在Cityscapes數據集上展開消融和對比實驗,結果如表3所示。
表3分別為HLFGM和UP(采用雙線性插值上采樣的方式)的對比,以及PPGM和AVG(采用全局平局池化操作的方式)、PPM的對比。將AVG改為PPM后,網絡的參數量降低,這是因為AVG中卷積操作多,而PPM中池化和上采樣操作多。相較于UP+AVG,HLFGM+AVG的mIoU僅提升0.19個百分點;相較于UP+PPM,HLFGM+PPM的mIoU提升0.80個百分點,說明在使用PPM的情況下使用HLFGM,網絡提升顯著。此外,相較于UP+AVG,UP+PPM的mIoU僅提升0.30個百分點;而相較于HLFGM+AVG,HLFGM+PPM的mIoU提升了0.91個百分點,說明在使用HLFGM的情況下使用PPM,網絡提升顯著。根據上述4組對比,可以發現HLFGM和PPM有相互促進的作用,進一步說明HLFGM能有效引導高級特征圖的上采樣,并且它的提升效果也與高級特征圖所含信息的豐富性有關。相較于UP+PPM,UP+PPGM的mIoU提升1.04個百分點;相較于HLFGM+PPM,HLFGM+PPGM的mIoU提升0.66個百分點。因此相較于PPM,PPGM對網絡提升的效果更佳。最終HLFGNet采用HLFGM+PPGM的方式,相較于采用UP+AVG的BiSeNet,mIoU提高了1.76個百分點,參數量減少了0.82 MB,推理速度僅降低了8 frame/s,模型的綜合性能達到最佳。
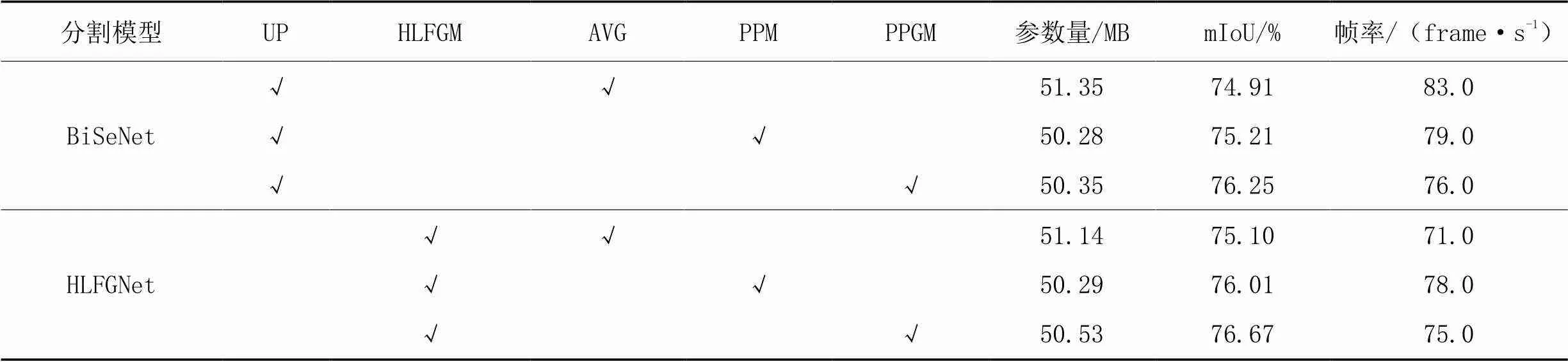
表3 在Cityscapes 驗證集上驗證不同設置下的性能

表4 權重系數實驗結果
相較于HLFGM,PPGM只使用了低級特征圖引導高級特征圖的路徑,同時為了驗證Guide操作(圖4)對不同尺度特征圖的有效性,展開了對比實驗,如表5所示。可以看到,PPGM-1~PPGM-4的參數量都為50.53 MB,這是由于每個Guide操作只使用2個卷積核,因此增加多個Guide操作并不會增加過多的參數量。從表5還可以看出,隨著逐漸增加對不同尺度特征圖的Guide操作,推理速度逐漸降低。PPGM-2和PPGM-3的mIoU提升效果較為明顯,為使速度和精度達到最佳平衡,最終選取PPGM-3,即只對3×3和6×6這兩個尺度的特征圖進行Guide操作,相較于PPM,mIoU提升0.66個百分點,速度下降3.0 frame/s。
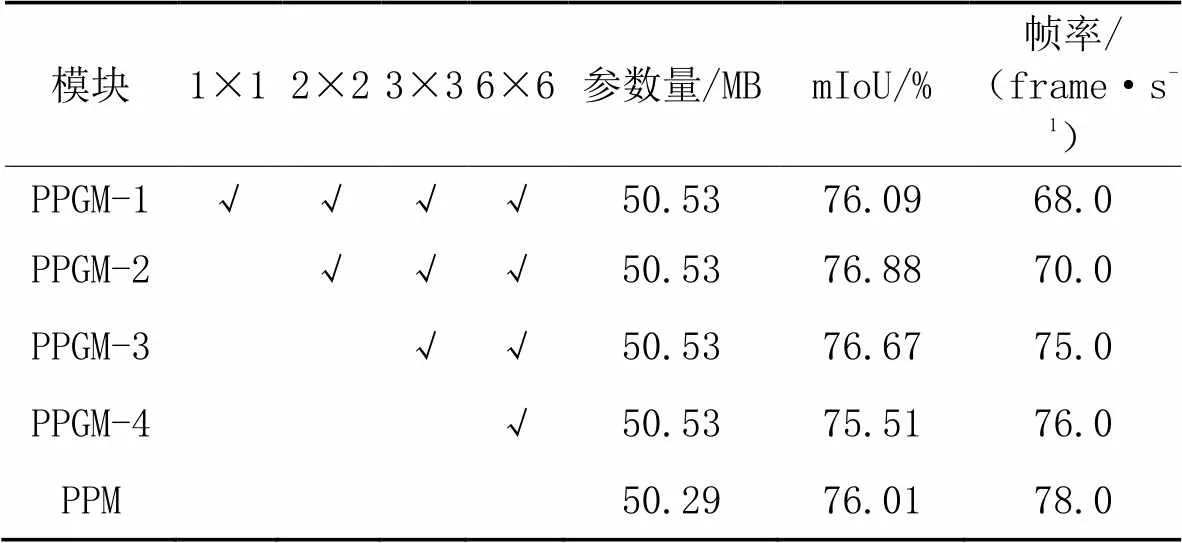
表5 對不同尺度特征圖進行Guide操作的對比實驗結果
注:PPGM-代表對不同尺度的特征圖進行Guide操作,代表經過降維后的不同尺度特征圖,“√”表示對該尺度特征圖進行Guide操作。
表6為不同網絡在Cityscapes數據集上的對比結果,對比網絡包括ICNet[21]、DFANet-A[34]、BiSeNet[13]、BiSeNet V2[22]和邊界感知的實時語義分割網絡(Boundary-Aware real-time Semantic segmentation Network, BASeNet)[39]、快速的實時語義分割網絡(FasterSeg)[40]、STDC2(Short-Term Dense Concatenate)-Seg75[23]和STDC2-Seg75*[23](“*”表示未使用預訓練模型)。

表6 不同網絡在Cityscapes數據集上的實驗結果對比
從表6可以看出,HLFGNet在測試集上的mIoU為75.4%,只比STDC2-Seg75低1.40個百分點,但HLFGNet的參數量比STDC2-Seg75少11.14 MB且幀率提高了26.1 frame/s。HLFGNet的幀率為75.0 frame/s,低于BiSeNet、BiSeNet V2和FasterSeg。但是,HLFGNet在測試集上的mIoU有著明顯的優勢,分別提升了0.9、2.5和3.9個百分點。在參數量上,HLFGNet也優于BiSeNet。相較于BiSeNet V2-L和STDC2-Seg75*,無論是速度、參數量還是mIoU,HLFGNet都有優勢。由此可見,本文提出的HLFGNet在精度和推理速度上取得了較好的平衡,能夠在保證精度較高的同時提高推理速度。
表7為FasterSeg、BiSeNet、HLFGNet在Cityscapes測試集上19種分類的結果。相較于FasterSeg,HLFGNet在所有分類上都有明顯優勢;相較于BiSeNet,HLFGNet在大部分的分類都有優勢,特別是車類,如motorcycle、bus、train,這3類的準確率得到了提升,提升了1.83~5.11個百分點。
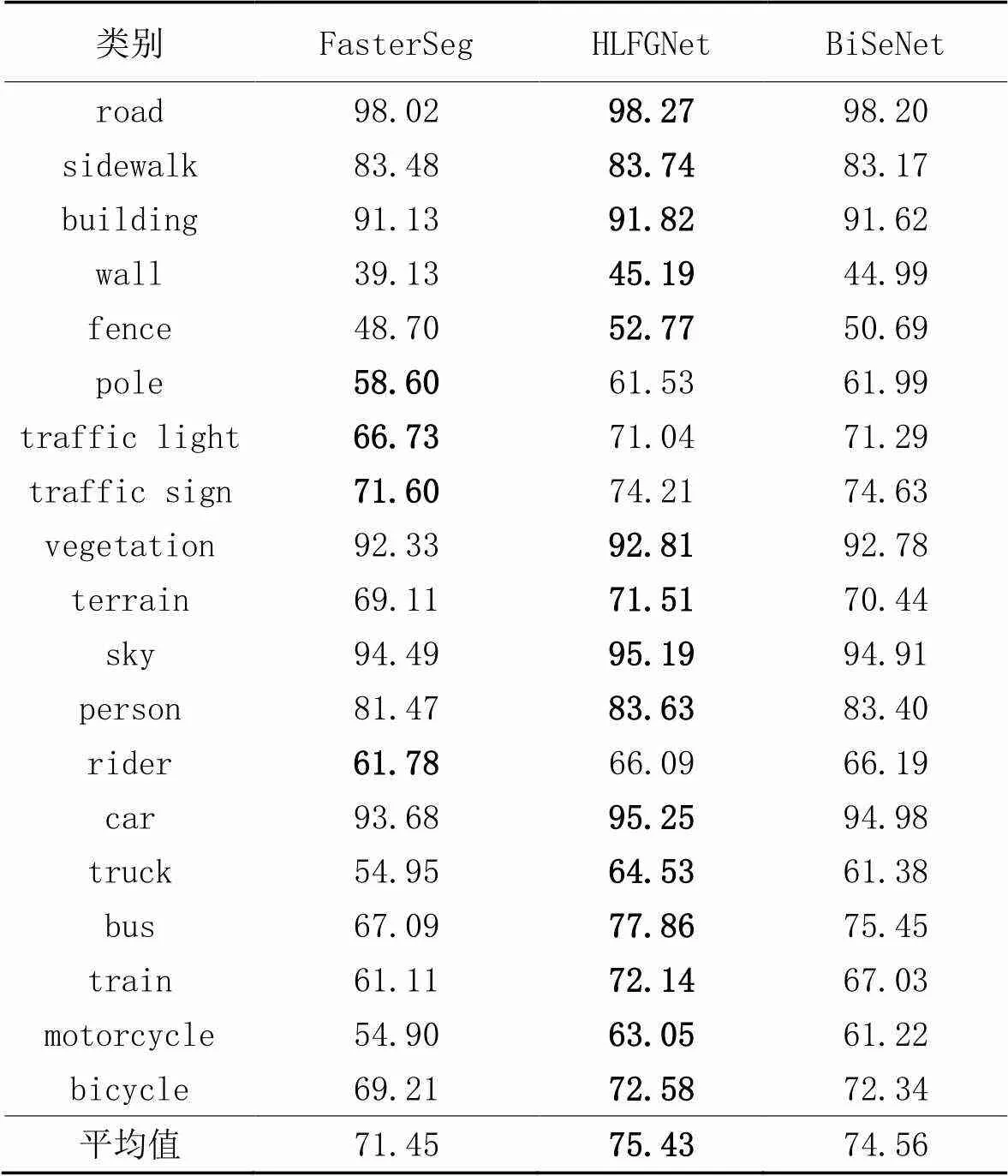
表7 Cityscapes測試集上各個類別的準確率 單位:%
為了驗證HLFGNet的泛化性,本文在CamVid數據集上展開實驗。將訓練集和驗證集一起用于訓練,測試集用于評估。訓練和評估的輸入分辨率和輸出分辨率都為720×960像素。訓練參數設置與在Cityscapes數據集上基本保持一致。實驗結果如表8所示,HLFGNet在CamVid測試集上能夠達到70.90%的mIoU,推理速度為96.2 frame/s,相較于BiSeNet V2,mIoU提高了0.10個百分點,且推理速度提升14.3 frame/s。雖然HLFGNet的推理速度低于BiSeNet,但mIoU提升了3.40個百分點。另外,相較于SegNet、ICNet和ENet[20],無論在mIoU上還是在速度上都有優勢。由此可見,HLFGNet在CamVid數據集上也獲得了良好的性能。
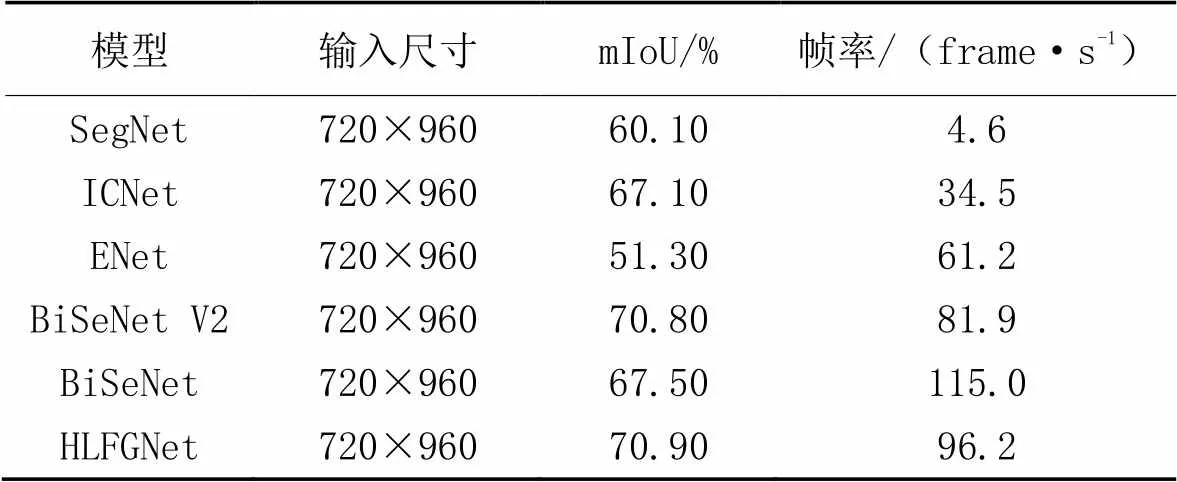
表8 不同模型在CamVid測試集上的對比分析
3.5 實驗定性分析
圖5直觀地展示了BiSeNet和HLFGNet在Cityscapes數據集上的可視化語義分割效果對比。從第1行圖像的虛線標記框可以看出,對于自行車和汽車交疊部分和人腳與自行車的交疊部分,BiSeNet無法得到正確的分割邊界;而HLFGNet通過利用HLFGM加強低級細節信息,有效增強像素之間的語義邊界關系,準確地區分和分割了交疊部分。并且在第1行圖像的實線框中,HLFGNet分割的人型輪廓相較于BiSeNet模型更細致。在第2行圖像中,BiSeNet無法識別道路兩邊的欄桿,而HLFGNet雖然對于道路左側的欄桿無法得到準確的分類,但是能夠利用獲取的細節信息較好地分割欄桿的輪廓細節。第3行圖像的虛線標記框中,可以看出對于遠距離路燈桿HLFGNet的識別能力更強;實線框中,BiSeNet分割的建筑物和路燈有部分像素點缺失;點線框中汽車和背景出現了融合的情況。在第4行圖像的虛線框中,BiSeNet并未識別出左側人物,右邊重合的兩人也丟失了大致輪廓細節;而HLFGNet不僅識別并分割了左側人物,同時右側兩人重合后的區域邊緣信息相對完整。在實線框中,BiSeNet分割出的柱體有部分像素錯誤分類,這是由于缺乏多尺度信息,而HLFGNet使用改進后的PPGM獲取多尺度信息,因此柱體語義分類完整。
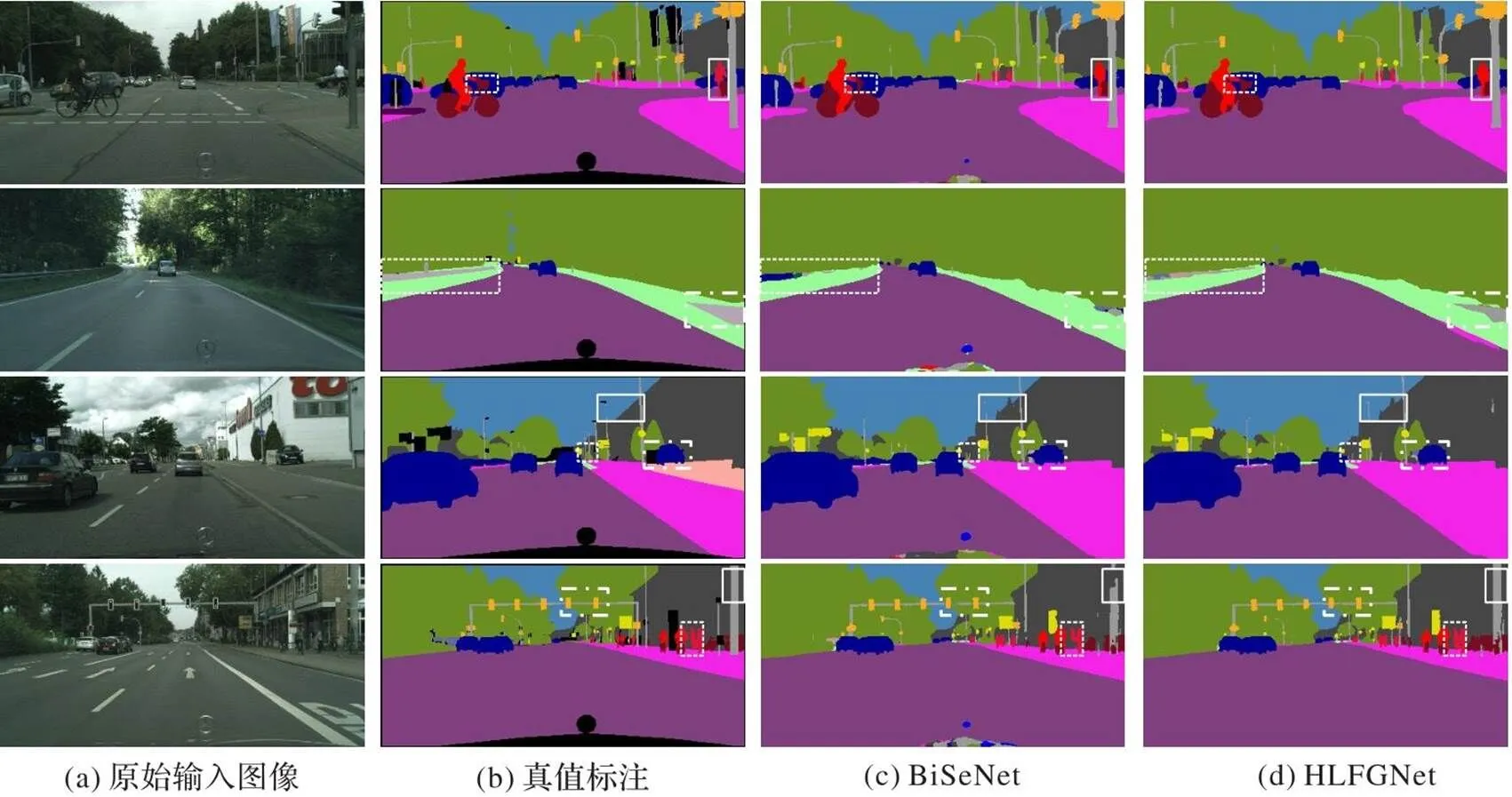
圖5 語義分割實驗效果的可視化對比
綜上所述,HLFGNet相較于BiSeNet能夠更好地識別出不同類別之間的語義輪廓,減少交叉劃分的錯誤現象。同時HLGFM模塊減少語義信息的丟失并且增強了細節信息使物體的邊緣信息更加完整。
4 結語
為保證語義分割網絡在精度和速度之間達到良好平衡,本文提出一種改進的實時語義分割網絡(HLFGNet)。為減少多級特征圖在融合過程中出現語義信息丟失的現象,提出了高低維特征引導模塊,該模塊利用低級特征圖的空間位置信息指導高級特征圖在上采樣過程中的語義信息對齊,同時結合注意力機制,利用高級特征圖獲取到的強特征引導低級特征圖去除冗余的細節特征;另外引入金字塔池化模塊,并對它加以改進,使不同尺度的局部上下文信息能更好地融合,提高整體分割效果。為驗證HLFGNet的有效性,在相同的環境配置下,分別在Cityscapes和CamVid數據集上展開實驗,實驗結果表明,HLFGNet能夠在精度和推理速度之間取得較好的平衡,相較于其他網絡,表現出了良好的性能。但HLFGNet還存在一定不足,語義分支采用的特征提取骨干網絡為ResNet-18,該網絡更適用于分類場景,所以在提取特征圖的多尺度信息和全局上下文信息方面表現有所不足。因此在后續的研究中,需要考慮如何設計更適用于語義分割的特征提取網絡。
[1] 羅會蘭,張云. 基于深度網絡的圖像語義分割綜述[J]. 電子學報, 2019, 47(10):2211-2220.(LUO H L, ZHANG Y. A survey of image semantic segmentation based on deep network[J]. Acta Electronica Sinica, 2019, 47(10): 2211-2220.)
[2] 張新明,李振云,鄭穎. 融合Fisher準則和勢函數的多閾值圖像分割[J]. 計算機應用, 2012, 32(10):2843-2847.(ZHANG X M, LI Z Y, ZHENG Y. Multi-threshold image segmentation based on combining Fisher criterion and potential function[J]. Journal of Computer Applications, 2012, 32(10): 2843-2847.)
[3] 柳萍,陽愛民. 一種基于區域的彩色圖像分割方法[J]. 計算機工程與應用, 2007, 43(6):37-39, 64.(LIU P, YANG A M. A method of region-based color image segmentation[J]. Computer Engineering and Applications, 2007, 43(6): 37-39, 64.)
[4] 李翠錦,瞿中. 基于深度學習的圖像邊緣檢測算法綜述[J]. 計算機應用, 2020, 40(11):3280-3288.(LI C J, QU Z. Review of image edge detection algorithms based on deep learning[J]. Journal of Computer Applications, 2020, 40(11): 3280-3288.)
[5] 宋杰,于裕,駱起峰. 基于RCF的跨層融合特征的邊緣檢測[J]. 計算機應用, 2020, 40(7):2053-2058.(SONG J, YU Y, LUO Q F. Cross-layer fusion feature based on richer convolutional features for edge detection[J]. Journal of Computer Applications, 2020, 40(7): 2053-2058.)
[6] 瞿紹軍. 基于最優化理論的圖像分割方法研究[D]. 長沙:湖南師范大學, 2018:32-66.(QU S J. Research on image segmentation based on optimization theory[D]. Changsha: Hunan Normal University, 2018: 32-66.)
[7] LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 3431-3440.
[8] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017, 60(6): 84-90.
[9] 張鑫,姚慶安,趙健,等. 全卷積神經網絡圖像語義分割方法綜述[J]. 計算機工程與應用, 2022, 58(8):45-57.(ZHANG X, YAO Q A, ZHAO J, et al. Image semantic segmentation based on fully convolutional neural network[J]. Computer Engineering and Applications, 2022, 58(8): 45-57.)
[10] ZHAO H, SHI J, QI X, et al. Pyramid scene parsing network[C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 6230-6239.
[11] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848.
[12] RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation[C]// Proceedings of the 2015 International Conference on Medical Image Computing and Computer-Assisted Intervention, LNCS 9351. Cham: Springer, 2015: 234-241.
[13] YU C, WANG J, PENG C, et al. BiSeNet: bilateral segmentation network for real-time semantic segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11217. Cham: Springer, 2018: 334-349.
[14] LI X, YOU A, ZHU Z, et al. Semantic flow for fast and accurate scene parsing[C]// Proceedings of the 2020 European Conference on Computer Vision, LNCS 12346. Cham: Springer, 2020: 775-793.
[15] CORDTS M, OMRAN M, RAMOS S, et al. The Cityscapes dataset for semantic urban scene understanding[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 3213-3223.
[16] BROSTOW G J, SHOTTON J, FAUQUEUR J, et al. Segmentation and recognition using structure from motion point clouds[C]// Proceedings of 2008 the European Conference on Computer Vision, LNCS 5302. Berlin: Springer, 2008: 44-57.
[17] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[EB/OL]. (2016-06-07) [2022-10-01].https://arxiv.org/pdf/1412.7062.pdf.
[18] CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[EB/OL]. (2017-12-05) [2022-10-24].https://arxiv.org/pdf/1706.05587.pdf.
[19] CHEN L C, ZHU Y, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 801-818.
[20] PASZKE A, CHAURASIA A, KIM S, et al. ENet: a deep neural network architecture for real-time semantic segmentation[EB/OL]. (2016-06-07) [2022-04-10].https://arxiv.org/pdf/1606.02147.pdf.
[21] ZHAO H, QI X, SHEN X, et al. ICNet for real-time semantic segmentation on high-resolution images[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11207. Cham: Springer 2018: 418-434.
[22] YU C, GAO C, WANG J, et al. BiSeNet V2: bilateral network with guided aggregation for real-time semantic segmentation[J]. International Journal of Computer Vision, 2021, 129(11): 3051-3068.
[23] FAN M, LAI S, HUANG J, et al. Rethinking BiSeNet for real-time semantic segmentation[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 9711-9720.
[24] PENG J, LIU Y, TANG S, et al. PP-LiteSeg: a superior real-time semantic segmentation model[EB/OL]. (2022-04-06) [2022-08-06].https://arxiv.org/pdf/2204.02681.pdf.
[25] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018:7132-7141.
[26] WOO S, PARK J, LEE J Y, et al. CBAM: convolutional block attention module[C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 3-19.
[27] FU J, LIU J, TIAN H, et al. Dual attention network for scene segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 3141-3149.
[28] WANG D, LI N, ZHOU Y, et al. Bilateral attention network for semantic segmentation[J]. IET Image Processing, 2021, 15(8): 1607-1616.
[29] 文凱,唐偉偉,熊俊臣. 基于注意力機制和有效分解卷積的實時分割算法[J]. 計算機應用, 2022, 42(9):2659-266.(WEN K, TANG W W, XIONG J C. Real-time segmentation algorithm based on attention mechanism and effective factorized convolution[J]. Journal of Computer Applications, 2022, 42(9): 2659-266.)
[30] 吳瓊,瞿紹軍. 融合注意力機制的端到端的街道場景語義分割[J]. 小型微型計算機系統, 2023, 44(7):1514-1520.(WU Q, QU S J. End-to-end semantic segmentation of street scene with attention mechanism[J]. Journal of Chinese Computer Systems, 2023, 44(7): 1514-1520.)
[31] 歐陽柳,賀禧,瞿紹軍. 全卷積注意力機制神經網絡的圖像語義分割 [J]. 計算機科學與探索, 2022, 16(5):1136-1145.(OU Y L, HE X, QU S J. Fully convolutional neural network with attention module for semantic segmentation[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16(5): 1136-1145.)
[32] ZHANG X, DU B, WU Z, et al. LAANet: lightweight attention-guided asymmetric network for real-time semantic segmentation[J]. Neural Computing and Applications, 2022, 34(5): 3573-3587.
[33] LIU J, XU X, SHI Y, et al. RELAXNet: residual efficient learning and attention expected fusion network for real-time semantic segmentation[J]. Neurocomputing, 2022, 474: 115-127.
[34] LI H, XIONG P, FAN H, et al. DFANet: deep feature aggregation for real-time semantic segmentation[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 9514-9523.
[35] HUANG Z, WEI Y, WANG X, et al. AlignSeg: feature-aligned segmentation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 44(1): 550-557.
[36] WU Y, JIANG J, HUANG Z, et al. FPANet: feature pyramid aggregation network for real-time semantic segmentation[J]. Applied Intelligence, 2022, 52(3): 3319-3336.
[37] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[38] ZHOU B, KHOSLA A, LAPEDRIZA A, et al. Object detectors emerge in deep scene CNNs[EB/OL]. (2015-04-15) [2022-05-12].https://arxiv.org/pdf/1412.6856.pdf.
[39] 霍占強,賈海洋,喬應旭,等. 邊界感知的實時語義分割網絡[J]. 計算機工程與應用, 2022, 58(17):165-173.(HUO Z Q, JIA H Y, QIAO Y X, et al. Boundary-aware real-time semantic segmentation network[J]. Computer Engineering and Applications, 2022, 58(17): 165-173.)
[40] CHEN W, GONG X, LIU X, et al. FasterSeg: searching for faster real-time semantic segmentation[EB/OL]. (2020-01-16) [2022-06-14].https://arxiv.org/pdf/1912.10917.pdf.
High-low dimensional feature guided real-time semantic segmentation network
YU Zixing1, QU Shaojun1*, HE Xin2, WANG Zhuo1
(1,,410081,;2,410221,)
Most semantic segmentation networks use bilinear interpolation to restore the resolution of the high-level feature map to the same resolution as the low-level feature map and then perform fusion operation, which causes that part of high-level semantic information cannot be spatially aligned with the low-level feature map, resulting in the loss of semantic information. To solve the problem, based on the improvement of Bilateral Segmentation Network (BiSeNet), a High-Low dimensional Feature Guided real-time semantic segmentation Network (HLFGNet) was proposed. First, High-Low dimensional Feature Guided Module (HLFGM) was proposed to guide the displacement of high-level semantic information during the upsampling process through the spatial position information of the low-level feature map. At the same time, the strong feature representations were obtained by the high-level feature maps, and by combining with the attention mechanism, the redundant edge detail information in the low-level feature map was eliminated and the pixel misclassification was reduced. Then, the improved Pyramid Pooling Guided Module (PPGM) was introduced to obtain global contextual information and strengthen the effective fusion of local contextual information at different scales. Experimental results on Cityscapes validation set and CamVid test set show that HLFGNet has the mean Intersection over Union (mIoU) of 76.67% and 70.90% respectively, the frames per second reached 75.0 and 96.2 respectively. In comparison with BiSeNet, HLFGNet has the mIoU increased by 1.76 and 3.40 percentage points respectively. It can be seen that HLFGNet can accurately identify the scene information and meet the real-time requirements.
real-time semantic segmentation; upsampling; attention mechanism; pyramid pooling; contextual information
This work is partially supported by National Natural Science Foundation of China (12071126).
YU Zixing, born in 1997, M. S. candidate. His research interests include computer vision, deep learning.
QU Shaojun, born in 1979, Ph. D., senior experimentalist. His research interests include image segmentation, computer vision, deep learning.
HE Xin, born in 1987, Ph. D. His research interests include deep learning, radar-vision fusion.
WANG Zhuo, born in 2000, M. S. candidate. Her research interests include computer vision, deep learning.
1001-9081(2023)10-3077-09
10.11772/j.issn.1001-9081.2022091438
2022?09?29;
2022?12?06;
國家自然科學基金資助項目(12071126)。
虞資興(1997—),男,湖南株洲人,碩士研究生,CCF會員,主要研究方向:計算機視覺、深度學習; 瞿紹軍(1979—),男,湖南永順人,正高級實驗師,博士,CCF會員,主要研究方向:圖像分割、計算機視覺、深度學習; 何鑫(1987—),男,湖南邵陽人,博士,主要研究方向:深度學習、雷達視覺融合; 王卓(2000—),女,湖南邵陽人,碩士研究生,CCF會員,主要研究方向:計算機視覺、深度學習。
TP391.4
A
2022?12?12。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
