基于隨機失活層優化深度置信網絡算法的刀具磨損預測
2023-10-21 03:37:04□陳莉
裝備機械 2023年3期
關鍵詞:深度
□ 陳 莉
新鄉職業技術學院 現代設計與工程學院 河南新鄉 453006
1 研究背景
隨著工業加工技術的不斷進步,提升自動化控制精度成為眾多研究人員的關注重點[1]。在加工過程中,鍛錘與工件表面會在數控加工中心運行階段發生接觸,從而造成磨損的問題。鍛錘表面的磨損狀態會對工件的加工質量與鍛床性能造成直接作用,尤其是在進行精加工時,需要達到更高的精度控制要求[2-3]。但是到目前為止,鍛錘材料并不能完全滿足實際使用性能要求,對于切削鍛錘耐磨性的研究也受到較大的限制[4-5]。
進行刀具磨損預測時,庫祥臣等[6]以反向傳播神經網絡構建預測模型,從傳感器信號頻譜內采集波形參數組成輸入特征,再以隨機方式對樣本實施訓練。畢長波等[7]主要研究通過遺傳算法在全局范圍內搜索反向傳播神經網絡權值的過程,由此確定最優性能的網絡,但神經網絡只能實現淺層學習的分析功能,此時樣本數據內包含與預測結果存在緊密關聯的輸入特征,才可以獲得優異的模型性能,這并不滿足深度挖掘的要求。王國峰等[8]研究通過深度學習方法從樣本中提取趨勢性特征,以粒子濾波修正的方法來提升模型的魯棒能力。Keyvanrad等[9]利用深度置信網絡測試分辨手寫數字,并對詞匯進行預測試驗。Mannepalli等[10]采用深度置信網絡方法準確提取輸入語音信號的有效頻譜信號,在情感識別方面表現出優異的綜合性能。
筆者在前人研究的基礎上,應用隨機失活層優化深度置信網絡算法,對數控刀具磨損狀態進行預測,并與其它算法進行對比分析。
2 隨機失活層優化深度置信網絡算法
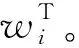
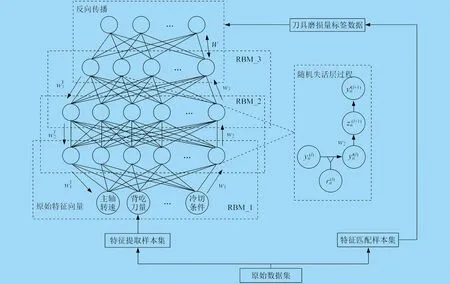
圖1 深度置信網絡整體架構
基于深度置信網絡進行分析時,需要對大量參數進行校準,傳統方法通常是選擇網絡組合方法,從而實現網絡集成功能的綜合分析。但進行多模型訓練測試需要耗費大量時間,因此采用隨機失活層函數優化深度置信網絡訓練過程,這樣不必按照常規循環方式中通過重復學習的過程來達到固定神經元的效果,不必對特征檢測器的作用進行限制,從而防止模型對局部特征產生依賴,有效減緩過擬合程度,并由此完成正則化功能。
調節環節面對受限波爾茲曼機的訓練方式,在訓練開始前,先利用隨機概率向量對工作節點激活狀態進行分析。
(1)
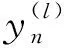
判斷屏蔽節點已轉為靜默狀態,則循環不再進行學習,集成被判定激活的節點,得到神經網絡訓練架構,再對訓練步驟進行如下重復處理:
(2)
(3)
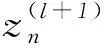
3 試驗驗證
3.1 感知數據獲取
當刀具停止回轉后,形成隨機分布的刀具位置會對檢測結果造成明顯影響。對此,設計一種能夠隔離測試儀器和機臺的雙鏡頭視覺測試方法,利用相機來抓取磨損圖像。
3.2 刀具磨損狀態識別
端銑切削加工時,采用硬質合金四齒立銑刀,以45號鋼作為加工材料,由此在數控加工中心上進行加工。
將刀具后刀面磨損程度0.4 mm作為磨鈍判斷指標,最終測試得到12組數據,部分見表1。
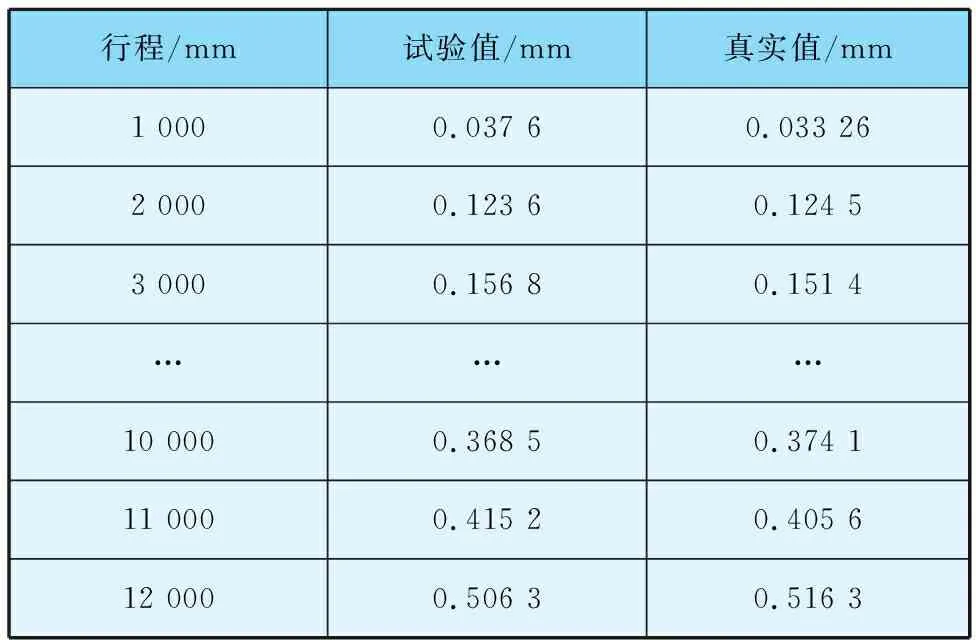
表1 測試數據
3.3 預測模型框架搭建
采集得到200組樣本,再以7∶3將樣本分為訓練樣本與測試樣本。控制學習率為0.02,將單次訓練的樣本數控制為32,共進行50次層間迭代。將隨機失活層概率設置為0.08,包含七個輸入層與一個輸出層。樣本數據采集見表2,受限玻爾茲曼機迭代過程如圖2所示。
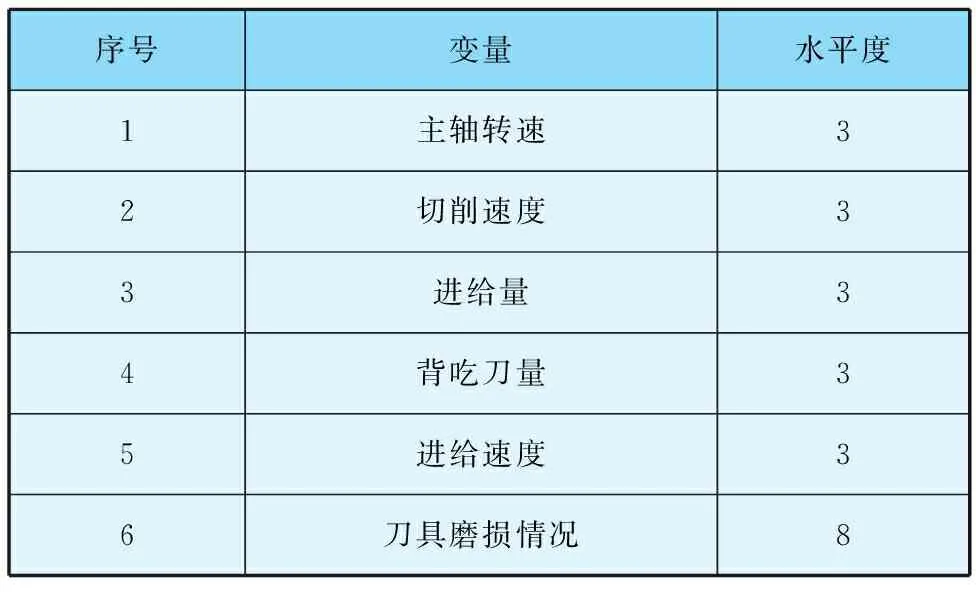
表2 樣本數據采集
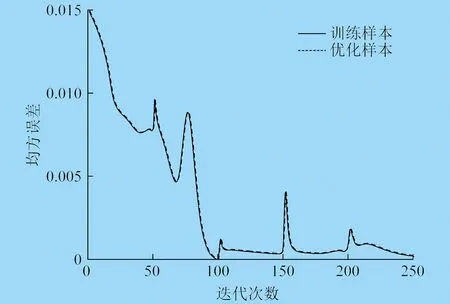
圖2 受限波爾茲曼機迭代過程
由圖2可知,各層受限波爾茲曼機都需要在初期訓練階段重新學習,此時會引起重構誤差方式突變,最終逐漸達到穩定狀態。
3.4 結果分析
采用不同算法進行對比測試,預測精度對比如圖3所示。由圖3對比可知,深度反向傳播網絡缺乏良好的泛化能力,支持向量機則花費最長的預測時間。對于生產過程而言,可以忽略模型的訓練時間,但是不同預測時間會引起刀具置換判斷結果的較大差異。
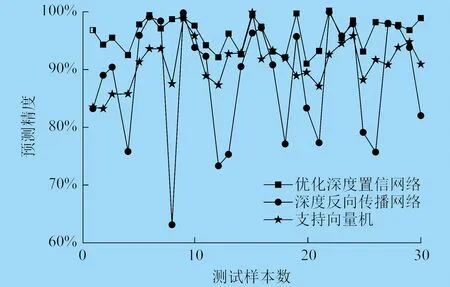
圖3 算法預測精度對比
相比較深度反向傳播網絡和支持向量機,樣本選擇過程對深度置信網絡的預測精度有直接影響。當測試集數據超出訓練集范圍時,將會明顯影響預測精度,與深度置信網絡特性相符。加入隨機失活層后,有助于提升模型學習性能。
由于深度置信網絡進行特征提取時能夠重構得到更優權值,因此在促進網絡預測性能提升的情況下能夠更快完成特征匹配收斂過程。算法誤差比較見表3。由表3可知,經過隨機失活層優化的深度置信網絡表現出更穩定與更準確的預測結果。
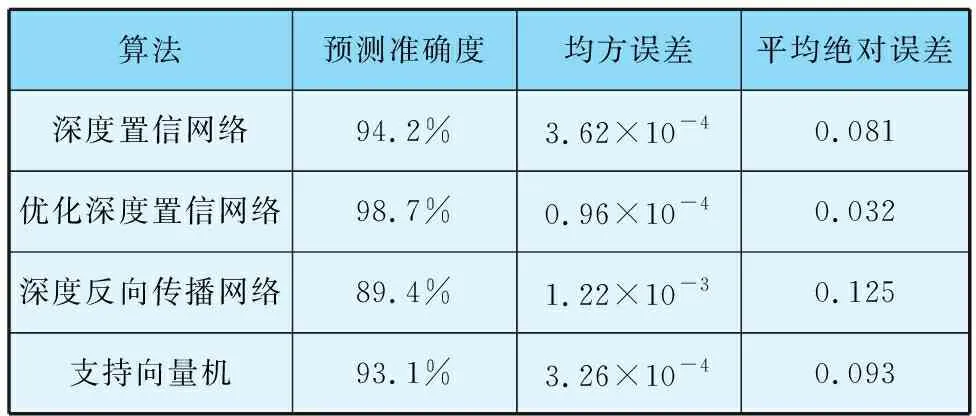
表3 算法誤差比較
4 結束語
為了提高數控刀具加工精度,應用隨機失活層優化深度置信網絡算法,進行刀具磨損狀態預測,并開展試驗分析,得到研究結果。
各層受限波爾茲曼機都需要在初期訓練階段重新學習,此時會引起重構誤差方式突變,最終逐漸達到穩定狀態。
相比深度反向傳播網絡和支持向量機,加入隨機失活層后,深度置信網絡有助于提升模型學習性能,表現出更穩定與更準確的預測結果。
猜你喜歡
中學生數理化·七年級數學人教版(2022年6期)2022-06-05 06:50:50
快樂學習報·教育周刊(2022年16期)2022-05-01 21:25:05
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
新聞傳播(2016年10期)2016-09-26 12:14:59
新聞傳播(2015年10期)2015-07-18 11:05:40
交通建設與管理(2015年15期)2015-03-20 15:18:57
