我國算法知情權(quán)改良路徑研究
2023-10-25 09:05:12劉蓓華珊
中阿科技論壇(中英文) 2023年10期
劉 蓓 華 珊
(長春工業(yè)大學(xué) 吉林,長春 130000)
自人類進入算法時代以來,算法的效能在各情境下決定著決策效率、決策質(zhì)量,對公私主體產(chǎn)生的多維度影響也日益明顯。但與此同時,看似理性的算法所產(chǎn)生的相關(guān)負面性也在不斷擴大。根據(jù)《算法應(yīng)用的用戶感知調(diào)查與分析報告(2021)》[1],發(fā)現(xiàn)目前絕大多數(shù)算法相對人對算法的認知尚不充足,在提升算法透明度方面有較強訴求。超過80%的平臺用戶期待能夠自主選擇推薦算法所依據(jù)的標簽集。而超過50%的平臺用戶對于企業(yè)是否適用算法開展服務(wù),以及使用算法的內(nèi)容、目的并不知悉,期待企業(yè)可以增強信息告知。當對算法結(jié)論存在異議時,76.48%的平臺用戶期望人工介入。在自動化決策的過程中,因算法本身所固有的歧視性、不確定性與黑箱性、權(quán)力與控制性等因素,已經(jīng)引發(fā)了“算法歧視”“算法黑箱”“算法操控”等風險。
為化解算法的負外部性,平衡算法相對人和決策方之間的法益保障,給相對方“賦權(quán)”成為重要的解決方案之一,在立法上“沿用”“改良”“創(chuàng)建”是目前算法治理的三條基本思路。因此,相對方獲取算法相關(guān)信息方面的“賦權(quán)”在立法中總體分為兩種進路:一種是完善改良知情權(quán)。改良“知情權(quán)”,結(jié)合延續(xù)我國現(xiàn)有其他法律制度。另一種是構(gòu)建算法解釋權(quán)。這種“構(gòu)建算法解釋權(quán)”思路成為計算法學(xué)研究熱點。選擇哪條路徑一直在被學(xué)者們反復(fù)詰問。目前學(xué)界對“構(gòu)建算法解釋權(quán)”思路存在一些質(zhì)疑,如算法黑箱限于技術(shù)障礙是否可以打開,解釋程度(限于不同場景)為何,以及如涉及知識產(chǎn)權(quán)和商業(yè)秘密如何解釋等。
在立法上,算法解釋權(quán)作為一種新型權(quán)利,在各國立法上的權(quán)利構(gòu)造與權(quán)利邊界尚未明確,并沒有形成真正獨立的權(quán)利。雖然部分學(xué)者對算法解釋權(quán)持支持態(tài)度,但鑒于立法的保守性與多方實踐因素,各國對算法解釋權(quán)的立法仍普遍呈消極態(tài)度。在我國整體的立法思想上,更傾向于將算法的違法性在既有的法律框架內(nèi)得以證成與救濟,通過已有成熟運行邏輯的權(quán)利對個人信息主體提供保障。因此,接下來將探索算法知情權(quán)改良路徑下的全新構(gòu)建,即構(gòu)建算法知情權(quán)權(quán)利束,將算法解釋權(quán)吸收于算法知情權(quán)之中,以此改良知情權(quán)。
1 算法知情權(quán)改良第一步:吸收“可理解性”
從認識論角度看,依據(jù)“關(guān)系—屬性—實體”這一客觀規(guī)律,事物關(guān)系是真正打開事物實體特性的鑰匙[2]。算法知情權(quán)與算法解釋權(quán)之間具有一定相似性,也存在一定的差異性,這是算法知情權(quán)改良的基礎(chǔ),下面就從二者異同比較出發(fā),以求證算法知情權(quán)吸收解釋權(quán)的可行性。
1.1 算法知情權(quán)和算法解釋權(quán)的相似性
首先,權(quán)利目的相同。算法知情權(quán)和解釋權(quán)的目的都是為了用戶更好地了解算法使用的基本信息,來矯正雙方信息不對稱的情況,避免算法黑箱對算法相對人造成損害。
其次,權(quán)利義務(wù)主體相同。算法知情權(quán)和解釋權(quán)的權(quán)利主體均為受到算法決策不利影響的算法相對人。義務(wù)主體均為算法決策方。
再次,權(quán)利客體相同。所謂權(quán)利客體是一個抽象的范疇,是一種法律所保護的人格或財產(chǎn)利益[3]。算法知情權(quán)和解釋權(quán)的權(quán)利客體均為算法相對人體現(xiàn)為公平、自由、尊嚴的人格利益。
最后,權(quán)利對象相同。權(quán)利對象則是具體的,承載人格或財產(chǎn)利益的載體(物、行為、信息等)。算法知情權(quán)和解釋權(quán)的權(quán)利對象均為當算法相對人的權(quán)益可能或已受到不利影響時,請求算法決策方為或不為其提供決策信息的行為。
1.2 算法知情權(quán)和算法解釋權(quán)的差異性
首先,權(quán)利產(chǎn)生淵源。算法知情權(quán)是立法中既有的權(quán)利,算法解釋權(quán)是從算法知情權(quán)中衍生出的一種新型權(quán)利。
其次,權(quán)利行使時機。目前立法上算法知情權(quán)表面上似乎只屬于“事前”(數(shù)據(jù)采集輸入前)權(quán)利,因為算法知情權(quán)中的“告知”發(fā)生在個人信息處理前,但這并不否認在數(shù)據(jù)處理、數(shù)據(jù)結(jié)果輸出兩個環(huán)節(jié)有知情權(quán)。實質(zhì)上算法知情權(quán)存在于數(shù)據(jù)采集輸入、數(shù)據(jù)處理、數(shù)據(jù)結(jié)果輸出三環(huán)節(jié),貫穿于算法自動化決策的始終。算法解釋權(quán)屬于“事后”權(quán)利(數(shù)據(jù)結(jié)果輸出后),作為一種救濟性的請求權(quán),只能在自動化決策數(shù)據(jù)輸出階段行使。因此,可以認為在行權(quán)時空上,算法知情權(quán)遠遠超出算法解釋權(quán)。
再次,權(quán)利內(nèi)容。算法知情權(quán)告知內(nèi)容更偏向于基礎(chǔ)性內(nèi)容的告知,一般包括個人信息控制者基本情況、處理目的、處理方式等。在我國除此也可能包括算法基本原理和主要運行機制,而算法解釋權(quán)需要向算法相對人解釋自動化決策的內(nèi)部運行邏輯。可見,在我國立法例中,算法知情權(quán)的權(quán)利內(nèi)容范圍可以包含算法解釋權(quán)。
最后,可理解性。從算法相對人的角度來看,算法知情權(quán)傾向聚焦知曉行為,不關(guān)注知曉程度與效果。而算法解釋權(quán)更傾向于對決策的“理解”的程度與效果,算法解釋權(quán)獨立成權(quán)的核心要義在于“可理解性”。
綜上所述,通過比較這兩種權(quán)利的異同,可知“可理解性”是算法解釋權(quán)能否獨立成權(quán)的關(guān)鍵,但由于可理解性出于眾多因素難以實現(xiàn),這成為算法解釋權(quán)在實踐中未能入法的主要原因。在對算法知情權(quán)、算法解釋權(quán)的立法和理論研究剖析中可知,包括中國在內(nèi)的大多數(shù)國家更傾向通過算法知情權(quán)和其他現(xiàn)有法律資源結(jié)合,以解決自動化決策風險問題,因此將算法解釋權(quán)中的“可理解性”吸收進算法知情權(quán),是知情權(quán)改良的第一步。
2 算法知情權(quán)改良第二步:算法知情權(quán)權(quán)利束的階段化建構(gòu)
算法知情權(quán)的權(quán)利束應(yīng)分三個階段進行建構(gòu)。如前所述,我國立法中算法知情權(quán)中的“告知”是在個人信息處理之前,即在數(shù)據(jù)收集輸入環(huán)節(jié)。但是并沒有否認在數(shù)據(jù)處理、數(shù)據(jù)結(jié)果輸出兩個環(huán)節(jié)有知情權(quán)。那么,結(jié)合誠信等原則,實質(zhì)上算法知情權(quán)應(yīng)該存在于數(shù)據(jù)采集輸入、數(shù)據(jù)處理、數(shù)據(jù)結(jié)果輸出三環(huán)節(jié),并貫穿算法自動化決策始終。告知—決定權(quán)、訪問權(quán)、查閱權(quán)、復(fù)制權(quán)、商討權(quán)、人工替代權(quán)、人工干預(yù)權(quán)、人工接管權(quán)等權(quán)利共同構(gòu)成了理論上的算法知情權(quán)權(quán)利束的基本要素。
2.1 自動化決策數(shù)據(jù)采集輸入階段
2.1.1 自動化決策數(shù)據(jù)采集輸入階段“告知—決定”權(quán)行使路徑的權(quán)利束
第一,告知方式。此階段被告知的相對人為不特定人的群體,因此在此階段個人信息的告知方式及告知內(nèi)容必須依據(jù)《中華人民共和國個人信息保護法》(以下簡稱《個人信息保護法》),應(yīng)當以顯著、完整、清晰易懂的方式進行。第二,告知內(nèi)容。是“一般性”告知,分為所收集數(shù)據(jù)的數(shù)據(jù)基本情況告知,以及自動化決策運行規(guī)則基本內(nèi)容的告知。告知的內(nèi)容主要包括個人信息處理者的基本情況、數(shù)據(jù)的處理目的與方式、所處理的個人信息種類及個人信息的保存期限,以及個人信息主體的行權(quán)方式及程序。第三,“告知—決定”的權(quán)利架構(gòu)。很多學(xué)者認為,因“告知—同意”原則是算法知情權(quán)的主要內(nèi)容,進而主張將“知情—同意”原則權(quán)利化。但是,這種觀點似乎忽視了算法相對人拒絕的權(quán)利。因此,在數(shù)據(jù)采集輸入階段構(gòu)建的算法知情權(quán)路徑之一是以“告知—決定”原則為基礎(chǔ),算法相對人可以選擇同意或拒絕該自動化決策,即行使同意權(quán)與拒絕權(quán)。第四,“告知—決定”下級權(quán)利束。如果算法相對人拒絕自動化決策,可以選擇直接退出自動化決策,或行使人工替代權(quán)。因人工替代存在著效率低以及行權(quán)成本高的特性,因此場景化路徑是人工接管權(quán)行權(quán)的前提。人工替代權(quán)作為“告知—選擇”原則中拒絕權(quán)的下級權(quán)利束,其中包括人工干預(yù)權(quán)和人工接管權(quán)。
2.1.2 自動化決策數(shù)據(jù)采集輸入階段訪問權(quán)行使路徑的權(quán)利束
我國《個人信息保護法》在此階段未提及訪問權(quán),訪問權(quán)在立法中出現(xiàn)于數(shù)據(jù)處理階段。在數(shù)據(jù)收集輸入之前尚未開始數(shù)據(jù)收集,因此訪問權(quán)主要是針對平臺的概覽訪問。《個人信息保護法》第二章第十六條規(guī)定,不得因個人不同意處理其個人信息或撤回同意而拒絕對其提供產(chǎn)品、服務(wù)。在《常見類型移動互聯(lián)網(wǎng)應(yīng)用程序必要個人信息范圍規(guī)定》中,也規(guī)定了App不得以用戶不同意提供非必要個人信息為由而拒絕用戶使用其基本功能服務(wù),并劃定了常見類型App的必要個人信息范圍。因此,可以基于這種基本功能服務(wù)設(shè)置無數(shù)據(jù)普適性的瀏覽頁面,以此幫助算法相對人行使訪問權(quán)。無數(shù)據(jù)普適性的瀏覽頁面,是該自動化決策服務(wù)內(nèi)容及程序結(jié)構(gòu)的重要展現(xiàn),且該頁面的使用不會留下數(shù)據(jù)痕跡,更偏向于體驗瀏覽。在訪問權(quán)的權(quán)利結(jié)構(gòu)上,其作為算法知情權(quán)下的二級權(quán)利,同樣下設(shè)決定權(quán)。當算法相對人完成無數(shù)據(jù)普適性的瀏覽頁面的框架性訪問后,仍有權(quán)利選擇同意或拒絕該自動化決策(見圖1)。
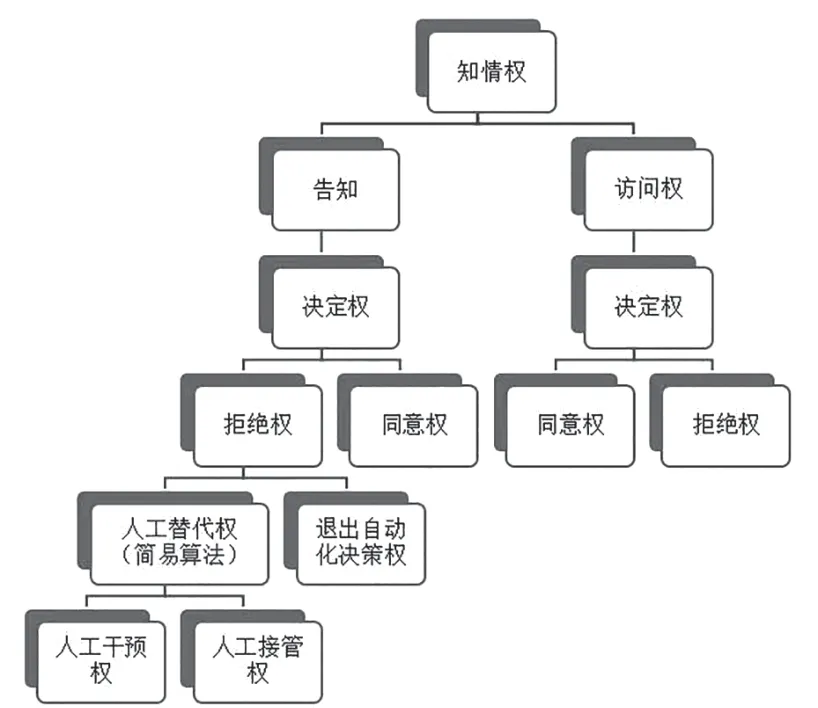
圖1 數(shù)據(jù)采集輸入階段算法知情權(quán)權(quán)利束(圖中兩處拒絕權(quán)下級權(quán)利束一致,為簡明僅列示一處)
2.2 自動化決策數(shù)據(jù)處理階段
2.2.1 自動化決策數(shù)據(jù)處理階段訪問權(quán)行使路徑的權(quán)利束
該階段的訪問權(quán)內(nèi)容與數(shù)據(jù)采集輸入階段不同,該層次的訪問可以排查出具體決策適用的規(guī)則是否包含歧視性、非法性以及個人信息數(shù)據(jù)是否錯誤等問題[4]。第一,包含《個人信息保護法》中所規(guī)定的查閱權(quán)、復(fù)制權(quán)以及決定權(quán)。在算法決策方請求查閱其個人信息時,應(yīng)依據(jù)《個人信息保護法》第二章第十七條提供清晰易懂、語言準確的個人信息資料,而非以二進制代碼的方式提供[5]。所謂復(fù)制權(quán)就是要求算法決策方為算法相對人提供所要求復(fù)制的其個人信息的副本,此種副本應(yīng)該是書面形式的,包括紙介質(zhì)或電子介質(zhì)。查閱權(quán)和復(fù)制權(quán)的行使時間在算法處理分析數(shù)據(jù)過程中具有不特定性,對算法中個人信息的使用產(chǎn)生了一定監(jiān)督的作用。第二,該環(huán)節(jié)的決定權(quán)的結(jié)構(gòu)與數(shù)據(jù)采集輸入階段相同,均包含同意權(quán)與拒絕權(quán),但因該階段已有數(shù)據(jù)的輸入,所以拒絕權(quán)的行使方式也變得多樣化。若算法相對人選擇拒絕自動化決策,此后的權(quán)利行使方式有四種:其一,修改權(quán)、更新權(quán)以及補充權(quán),要求算法決策方對錯誤、過時及殘缺的數(shù)據(jù)進行更正、更新和補充。其二,刪除權(quán),隨之退出自動化決策。其三,直接退出自動化決策權(quán)。其四,人工替代權(quán)。
2.2.2 自動化決策數(shù)據(jù)處理階段“告知—決定”權(quán)行使路徑的權(quán)利束
第一,告知方式。該階段應(yīng)進行收集、積累和處理數(shù)據(jù),因此該階段的告知方式體現(xiàn)出“個體性”。第二,告知內(nèi)容。基于誠信原則對所收集數(shù)據(jù)、自動化決策相關(guān)內(nèi)容的告知,該層次的告知可以幫助檢視決策歧視性、非法性以及個人信息數(shù)據(jù)是否錯誤等問題。但自動化決策相關(guān)內(nèi)容的告知,需算法相對人主動向算法決策方提出而展開。第三,商討權(quán)。因數(shù)據(jù)處理階段的告知具有“個性化”,“告知”可以通過商討權(quán)施展,以商討交流來實現(xiàn)雙方需求調(diào)和。在商討權(quán)下設(shè)決定權(quán)權(quán)利束,不再重復(fù)闡述(見圖2)。

圖2 數(shù)據(jù)處理階段算法知情權(quán)權(quán)利束(圖中兩處拒絕權(quán)下級權(quán)利束一致,為簡明僅列示一處)
2.3 自動化決策數(shù)據(jù)輸出階段
2.3.1 自動化決策數(shù)據(jù)輸出階段“告知—決定”權(quán)行使路徑的權(quán)利束
第一,告知內(nèi)容。在數(shù)據(jù)輸出階段,聚焦在自動化決策結(jié)論等相關(guān)內(nèi)容的告知。此時的算法知情權(quán)構(gòu)建的目的是使算法相對人發(fā)現(xiàn)于己不利的決定,以便提出異議和申請救濟。第二,告知方式。在這個階段,告知依然呈現(xiàn)出個案特點。只有通過這種個性化告知才有利于最大效率地降低決策算法相對人的疑慮。且個性化告知的限度應(yīng)堅持披露最小化原則,告知的內(nèi)容應(yīng)是適當?shù)摹⒈匾模悦庖鹦畔⑦^載與用戶選擇疲勞。雖然這種個性化告知會給企業(yè)等算法決策方帶來一定的負擔并耗費一定的經(jīng)濟成本,但是從長遠來看,這是信息時代高速發(fā)展背景下的大勢所趨,市場本身具有調(diào)整能力,企業(yè)可以通過改變盈利模式的方式來取得相當?shù)慕?jīng)濟收益。第三,“告知—決定”的權(quán)利架構(gòu)。決定權(quán)仍由同意權(quán)和拒絕權(quán)構(gòu)成。當算法決策方向算法相對人履行告知義務(wù)后,算法相對人可以不再作任何回復(fù),對算法自動化決策結(jié)果“默示”同意。同時也可以選擇行使拒絕權(quán)。行使拒絕權(quán)的方式除了在前兩個階段提到過的方式外,還包括傳統(tǒng)維權(quán)方式——尋求司法救濟。
2.3.2 自動化決策數(shù)據(jù)輸出階段訪問權(quán)行使路徑的權(quán)利束
訪問權(quán)權(quán)利束的建立可使算法相對人對算法中的個人信息是否存在錯誤進行判斷,包括查閱權(quán)、復(fù)制權(quán)以及決定權(quán)。與本階段直接行使決定權(quán)不同的是,若算法相對人訪問后同意該自動化決策應(yīng)以“明示”同意向算法決策方反饋(見圖3)。
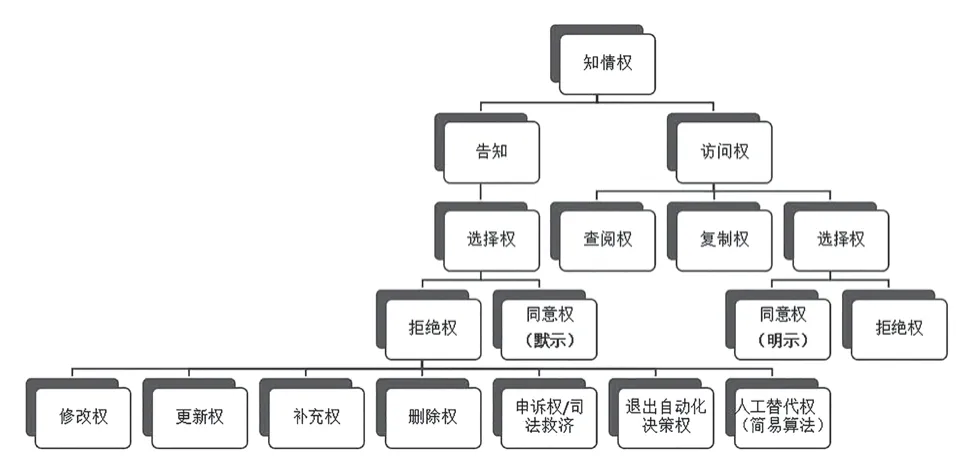
圖3 事后階段算法知情權(quán)權(quán)利束(圖中兩處拒絕權(quán)下級權(quán)利束一致,為簡明僅列示一處)
需要注意的是,本文提出的算法知情權(quán)權(quán)利束是從理論層面建構(gòu)的。鑒于算法決策應(yīng)用場景的多元化,在具體應(yīng)用情境中算法知情權(quán)的構(gòu)建應(yīng)采取場景化路徑[6]。首先,如果沒有對算法知情權(quán)的建構(gòu)進行場景化賦權(quán),不分場景式的“一刀切”,將會導(dǎo)致算法知情權(quán)權(quán)利束喪失彈性與適配性。場景的類型化標準是多種多樣的,如公私之分、平臺等級、行業(yè)區(qū)分、數(shù)據(jù)敏感度等。我國《信息安全技術(shù) 個人信息安全規(guī)范》(GB/T 35273-2020)第5.4條區(qū)分了收集個人信息、個人敏感信息、個人生物識別信息、未成年信息以及間接獲取個人信息的五個情景,這是在保持《個人信息保護法》概要規(guī)定的基礎(chǔ)上,彌補其場景化、精細化不足。其次,算法決策拒絕權(quán)的行使并非在所有場景均可以實現(xiàn)。例如,在自動駕駛的情景下,主張脫離自動駕駛汽車的算法自動化處理,要求避免使用該算法的可能性為零。又如,在大型平臺的推薦服務(wù)中,要求人工替代權(quán)也是強人所難。總之,上文所梳理的是一種理論層面的“階段化”權(quán)利束,具有公式性意義。在實踐中,以上權(quán)利束結(jié)構(gòu)需要結(jié)合具體場景來判定當事人擁有怎樣的“個性化”算法知情權(quán)權(quán)利束,即在具體場景中從理論層面的權(quán)利束中選擇權(quán)利集,形成場景化賦權(quán)。
3 結(jié)語
隨著算法技術(shù)的不斷發(fā)展,算法已經(jīng)成為了算法時代的“基礎(chǔ)語言”,其應(yīng)用場景也在不斷豐富。但看似理性的算法也同時引發(fā)了一系列風險。算法自身的壁壘結(jié)構(gòu),使算法決策方的權(quán)力不斷擴大,改變了算法決策方與算法相對人原有的相對平等的狀態(tài)。本文通過對算法知情權(quán)與算法解釋權(quán)的比較分析,得出了知情權(quán)吸收解釋權(quán)的改良設(shè)計方案的可能性。并進一步推進改良,構(gòu)建了三環(huán)節(jié)的算法知情權(quán)權(quán)利束。因此,可以回答研究初始的疑問:沿用、改良與創(chuàng)建作為目前算法治理的三條基本思路,應(yīng)該選擇哪條路徑?在算法知情權(quán)、解釋權(quán)的立法問題上,沿用現(xiàn)有法律、改良“知情權(quán)”是一條可行的路徑。但是,未來面對其他現(xiàn)實新難題時,“創(chuàng)建”之路可能是最優(yōu)選擇。
