SMViT:用于新冠肺炎診斷的輕量化孿生網絡模型
2023-10-29 04:21:08馬自萍譚力刀馬金林
計算機與生活 2023年10期
關鍵詞:模型
馬自萍,譚力刀,馬金林,陳 勇
1.北方民族大學 數學與信息科學學院,銀川 750021
2.北方民族大學 計算機科學與工程學院,銀川 750021
3.寧夏醫科大學總醫院 放射介入科,銀川 750004
由于新冠病毒的傳播速度極快,對全人類的生命健康帶來了嚴重的危害。因此,快速精確地診斷出新冠肺炎對患者治療與切斷病毒傳播鏈具有重要意義。研究表明,新冠肺炎患者在患病期間幾乎都會出現肺部性狀的改變[1-2]。手動標記影像數據不僅對檢查人員的臨床經驗要求較高,而且費力耗時,而基于深度學習的智能影像診斷技術具有診斷速度快、靈敏度高的優點[3]。
用于新冠肺炎診斷的經典深度網絡主要有[4-9]:VGGNet、ResNet、DenseNet、InceptionNet、CapsNet 和EfficientNet 等網絡。VGGNet 使用小核卷積與小核池化來保證少量參數下獲取更多細節特征,一些學者將VGGNet 作為主干網絡用于新冠肺炎診斷取得了不錯的效果[4]。ResNet 采用殘差連接的結構將淺層特征與深層特征直接相連,有效地緩解了梯度消失、梯度彌散和網絡退化的問題[5]。DenseNet中任意層之間都有直接的連接,利用所有層的特征來預測結果以提升網絡的魯棒性[6]。InceptionNet 采用多尺度的多分支卷積層來提取不同尺度的特征,使用1×1的卷積與全局平均池化來使網絡參數減少的同時提高運算速度[7]。CapsNet通過將capsule嵌套在其他層中來減小網絡深度,每個capsule 可以檢測圖像中的一類特定實體,通過動態路由機制向父層反饋檢測到的實體。基于CapsNet架構的新冠肺炎診斷網絡由于其深度較淺,對設備算力要求不高[8]。EfficientNet由B0~B7共8個不同尺度的子網絡構成,通過交替使用3×3與5×5的卷積層來提取特征,并使用組合縮放系數來同時調整網絡的寬度與深度,實現了較高的新冠肺炎診斷準確度[9]。
由于常規病毒性肺炎與新冠肺炎的影像特征差別很小,基礎網絡往往難以準確地進行分類。因此,研究者提出了一些多模型結合的方法。Ozkaya等[10]提出了一種多模型深層特征融合和排列的新冠肺炎檢測方法(deep features fusion and ranking technique,DFFRT)。類似地,Rahimzadeh等[11]提出基于Xception[12]和ResNet的級聯神經網絡。這類網絡雖然實現了精度的提升,但靈敏度不足。為此,Togacar 等[13]結合MobileNetV2[14]和SqueezeNet[15]構造級聯網絡,并且借助支持向量機(support vector machine,SVM)[16]對有效特征進行組合,提升了模型的靈敏度。
多模型結合的方法雖然在一定程度上提升了模型的診斷性能,但是大多數新冠肺炎數據集的樣本數量十分有限,而常規架構下的深度學習網絡會由于訓練數據不足導致網絡泛化能力較弱,難以在小樣本數據集上取得良好的效果。因此,Zheng等提出了DeCoVNet[17]模型,該模型通過與弱監督方法[18]結合,采用數據增強技術有效緩解了數據集過小帶來的過擬合問題,但是該模型容易導致較高的假陰性率。為此,Narin 等[19]巧妙地使用結合遷移學習的二進制Resnet模型(binary classification of transfer learning Resnet,BTLResnet)來解決數據量少和訓練時間不足的問題,改善了假陰性問題。與BTLResnet模型不同,Wang 等[20]提出了基于DenseNet121 的新冠肺炎分類和預后分析方法,該方法使用雙步遷移策略來解決新冠肺炎數據集樣本數量不足的問題,在數據集較小的情況下取得了較高的診斷準確率。與此類似的是,Chowdhury等[21]提出基于EfficientNet的集成網絡(efficient COVID-19 detection network,ECOVNet)。該網絡使用在ImageNet 上預訓練的權重進行遷移,通過集成預測的方法來降低模型的泛化誤差,提高了在新冠肺炎X-ray圖像小數據集的診斷準確率。
綜上所述,基于遷移學習的方法解決了數據集樣本不足的問題,然而,簡單的遷移學習技術對源域數據與目標域數據的相似度要求較高,復雜的遷移學習技術在不同任務上需要使用不同的遷移策略,可移植性差。為此,He 等提出一種自監督預訓練框架(masked autoencoder,MAE)[22],通過在原圖像上隨機掩蓋一定比例的像素塊作為模型的輸入數據,使用原圖像作為標簽來訓練模型。受此啟發,本文構建了MAE 策略下的ViT(vision transformer)模型以緩解復雜的遷移學習技術的可移植性差問題。
目前,在許多視覺任務中ViT模型展現了其全局的優越性,與卷積神經網絡(convolutional neural network,CNN)相比,性能有了顯著的提升[23]。但是,ViT 模型的多頭自注意力機制會對全局的特征表示進行學習,這導致其參數量顯著增加。為此,本文采用循環子結構的方法對模型進行輕量化,通過在單個子網絡上循環更新梯度來避免訓練時產生過大的計算圖。對由多個結構相同的編碼器塊構成的ViT模型,該方法可明顯降低其參數量。
1 本文方法
1.1 輕量化策略
本文提出了循環子結構輕量化策略,其網絡訓練流程如圖1 所示。設一個神經網絡A由結構相同的子網絡A1,A2,…,An構成,子網絡Ak的輸出為子網絡Ak+1的輸入,網絡A的總參數量為子網絡A1參數量的n倍。設神經網絡B僅由子網絡B1構成,B1與A1結構相同,因此網絡B的總參數量為子網絡A1參數量。通過公式推導證明,在網絡A與網絡B有相同輸入、標簽、網絡參數的情況下,將子網絡B1復用n次后,每一輪訓練將會得到相同的結果。該策略對由多個具有相同結構的子網絡構成的復雜網絡具有輕量化效果。
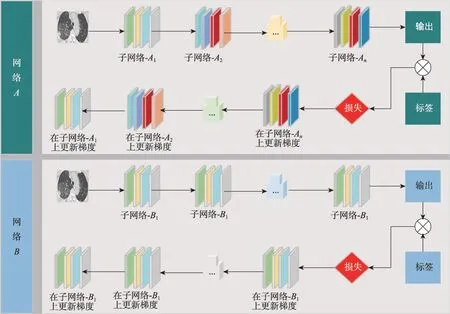
圖1 網絡A 與網絡B 的訓練流程Fig.1 Training process of network A and network B
理論證明如下:將神經網絡表示為函數的形式,設子網絡A1為函數output=f1(input),子網絡A2為函數output=f2(input),子網絡Ak為函數output=fk(input),子網絡B1為函數output=g(input),其中input為網絡的輸入,output為網絡的輸出。設神經網絡中采用sigmoid作為激活函數,并將一個子網絡分為輸入層、隱含層與輸出層。由神經網絡的定義可知,f1(input),f2(input),…,fn(input),g(input)的形式均可表示為:
其中,W為神經網絡中輸出層與前一層各連接的權重,b為偏置項,X為隱含層的輸出。由式(1)易知,表示神經網絡的函數在定義域內無窮次可導。因此,任意表示神經網絡的函數均可利用泰勒公式將其表示為一個多項式函數。若將所有的子網絡函數均按泰勒公式展開到固定的階數,則函數f1(input),f2(input),…,fn(input),g(input)均可表示為同階的多項式函數:
網絡A可表示為:
網絡B可表示為:
其中,函數g()復合了n次。設多項式函數g()的第m階為omxm,多項式函數fn()的第m階為pnmxm。
通過歸納假設法可以證明,當n=1時:
若令om=p1m,則式(3)與式(4)相等。當n=k時:
若令om(k-1)m+(k-1)=pkm p(k-1)m...p2m p1m,則式(3)與式(4)相等。當n=k+1時:
若令om km+k=p(k+1)m pkm...p2m p1m,則式(3)與式(4)相等,即可以通過將單個子網絡復用n次來達到與由n個子網絡構成的復雜網絡相等的效果。
1.2 輕量化的孿生架構網絡
本文提出輕量化的SMViT(siamese masked vision transformer)網絡模型,其結構如圖2所示。從圖2可以看出,輕量化SMViT 模型的編碼器通過將一個編碼器子塊循環使用來取得與原本由多個編碼器子塊堆疊構成的編碼器相同的效果,有效減少了網絡參數量與訓練模型所需顯存。在SMViT的預訓練網絡中,編碼器負責提取高維特征表示,解碼器則通過與未掩碼圖像計算MSE(mean square error)損失來細粒度地還原圖像,從而有效地增強了模型的潛在特征表示能力。MSE損失公式為:
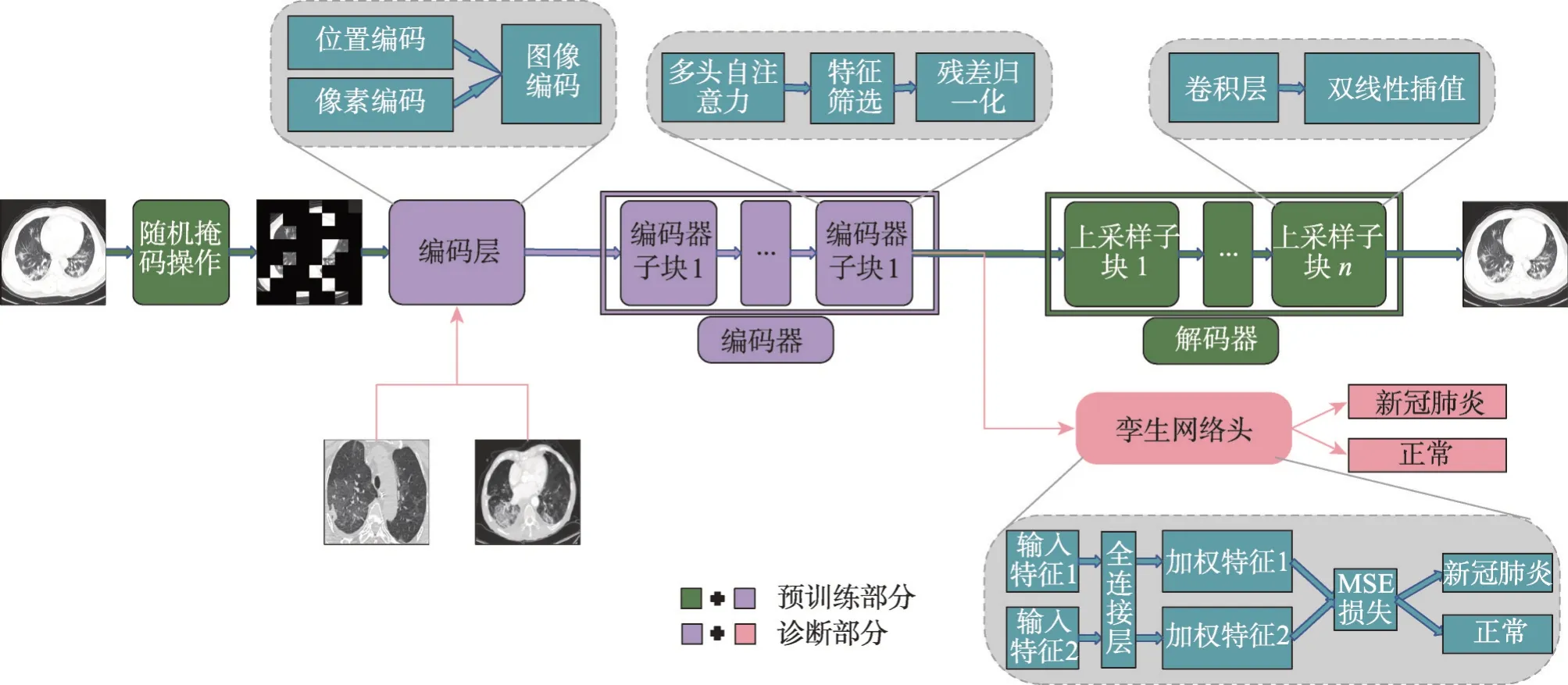
圖2 SMViT網絡結構圖Fig.2 Structure of SMViT
最后,搭建一個孿生網絡頭用于新冠肺炎的診斷。
1.3 孿生網絡頭
孿生網絡的核心思想是利用神經網絡將兩個輸入樣本映射到新的空間中進行表示,通過對兩個樣本在新空間的表示計算損失,來評價兩個輸入的相似度[24]。由于孿生網絡具有權值共享的特性,這樣可以保證兩個不同樣本的輸出在同一域內[25]。近年來,孿生網絡已成為各種視覺表示學習模型中的常見結構,它將最大化兩幅同一類別圖像之間的相似性,并最小化兩幅不同類別圖像之間的相似性。孿生神經網絡可以將分類問題轉化為模板匹配的問題,進而具備較強的小樣本學習能力,且不易被錯誤樣本干擾[26]。
因此,在ViT的編碼器上添加一個由全連接層與MSE損失構成的孿生網絡頭,其結構如圖2所示。其中,編碼器與解碼器負責掩碼自監督預訓練,預訓練完成后再訓練由編碼器與孿生網絡頭組成的診斷網絡,此時,編碼器梯度將不再更新。由于肺部圖像中不同區域對是否被判定為新冠肺炎的貢獻度不同,在孿生網絡頭中,全連接層將對輸入樣本的特征圖進行加權。然后計算兩個樣本加權后的MSE損失來判定兩個樣本是否屬于同一類別。嵌入了孿生網絡頭后,輕量化的SMViT 能更好地分辨出新冠肺炎患者的肺部圖像,進而在小樣本數據集上具備良好的泛化能力。
1.4 算法流程
SMViT模型的訓練流程圖如圖3所示,具體流程如下:
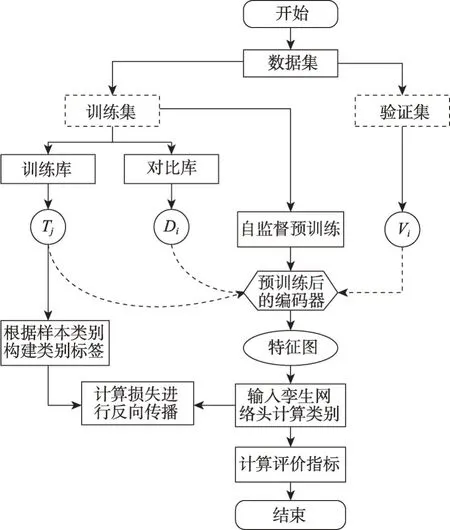
圖3 SMViT訓練流程圖Fig.3 Flow chart of SMViT
(1)把所有樣本分為訓練集與驗證集后,將所有訓練集中的數據輸入ViT 中進行掩碼自監督預訓練。預訓練完成后隨機從訓練集中選取部分樣本作為對比庫。
(2)分別遍歷對比庫與訓練集中剩余的所有樣本,每次從對比庫中選出一個樣本Di,從訓練集中挑選出一個樣本Tj;將Di與Tj分別輸入編碼器中計算特征圖。
(3)然后將特征圖輸入孿生網絡頭計算差異,并根據樣本所屬類別構建的標簽進行損失計算,最終使得同類樣本差異最小,異類樣本差異最大。
(4)利用模型進行驗證時,首先分別遍歷驗證集與對比庫中所有樣本,每次從驗證集中選出一個樣本Vi,從對比庫中挑選出一個已知類別的樣本Di,計算Vi與Di的特征圖;其次輸入孿生網絡頭進行判斷,若兩個樣本屬于同一類別,則該類別得分加1,反之,則不加分;最后計算所有類別的得分率,得分率最大者作為該輸入樣本的類別。
1.5 數據集與評價指標
現有的新冠肺炎數據集有X-ray圖像與CT圖像兩類。本文使用的X-ray圖像數據集包括COVID-19 radiography database 數據集[27]與Pranavraikokte 數據集[28],CT 圖像數據集包括COVID19-CT 數據集[29]與SARS-CoV-2 CT-scan 數據集[30]。COVID-19 radiography database 數據集包含3 616 例新冠肺炎陽性、6 012 例肺部陰影(非COVID 肺部感染)和10 192 例正常的X-ray 圖像。Pranavraikokte 數據集包含137例新冠肺炎陽性病例、90 例正常和90 例病毒性肺炎病例的X-ray圖像。COVID19-CT數據集包含216名新冠肺炎患者的349 幅和397 幅正常的CT 圖像。SARS-CoV-2 CT-scan數據集包括1 262例COVID-19陽性患者的CT 圖像和1 230 例COVID-19 陰性患者的CT圖像。本文實驗中對所有數據集均按7∶3的比例劃分訓練集與驗證集。
由于數據集樣本內部存在類別不均衡的問題,為了對模型性能進行更客觀的評價,本文采用準確率(accuracy,ACC)、特異度(specificity,SPE)、靈敏度(sensitivity,SEN)和F1分數來評價模型性能。其中,SPE的計算公式為:
其中,TP、TN、FP、FN分別表示真正例、真反例、假正例、假反例。F1-Measure的計算公式為:
其中,P與R分別表示查準率和查全率,其計算公式分別為:
1.6 實驗環境
本文的實驗環境均基于Pytorch 框架,使用Titan V 12 GB 顯卡。初始學習率為0.000 3,batchsize 為32,epoch為100,使用Adam優化策略。
2 實驗結果與分析
2.1 新冠肺炎診斷結果與分析
本實驗驗證了SMViT 模型在新冠肺炎X-ray 圖像、CT 圖像數據集上的診斷性能,并給出了實驗分析。測試集一共包含4個數據集,本文方法在各數據集上的“損失-輪次”與“準確率-輪次”折線圖如圖4所示。從圖4可以看出,損失值隨輪次增加逐漸趨于穩定,準確率上升趨勢在訓練后期仍然增長平穩,表明本文方法具有較穩定的收斂性能。
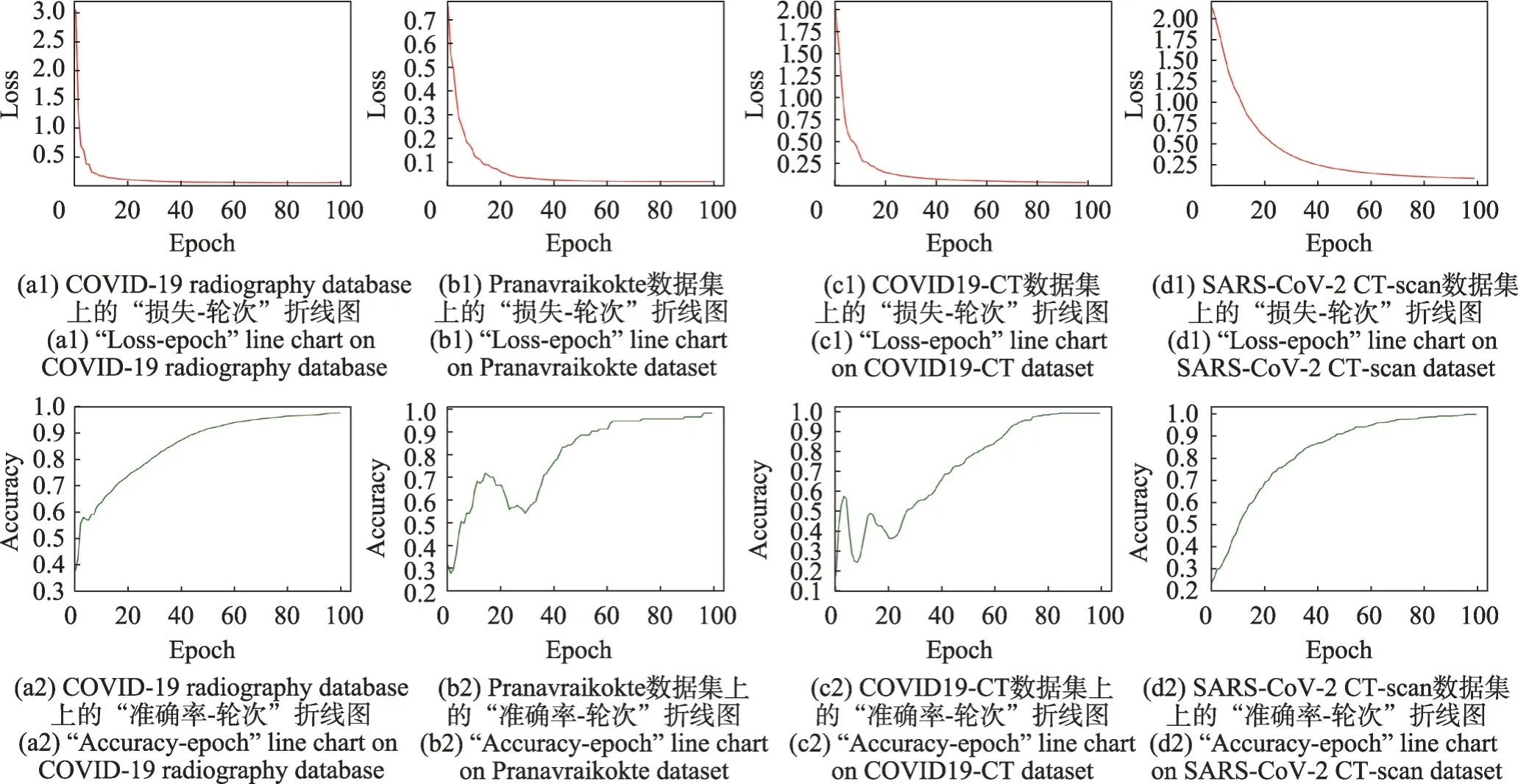
圖4 不同數據集下輪次對精度和損失的影響Fig.4 Effect of epoch on accuracy and loss under different datasets
在兩個X-ray 圖像數據集上比較了SMViT 與對比模型的診斷性能,實驗結果如表1 所示。可以看出,在兩個數據集上,對于ACC、SPE、SEN和F1 分數而言,SMViT模型取得了最好的診斷性能,與對比模型相比,最多提高了7.0%、6.7%、7.3%和6.0%,與MFViT 相比,分別提高了0.9%~1.4%、0.8%~4.6%、0.4%~0.8%和0.8%~2.8%,表明SMViT 在X-ray 圖像上的診斷性能具有明顯的優勢。此外,為了比較模型在推斷時的計算效率,在兩個X-ray圖像數據集上計算了單幅圖像的平均推斷耗時。SMViT的推斷耗時略高于MobileNetV2+SqueezeNet,但是明顯低于其他對比模型。因此,本文模型在推斷速度上仍然具有一定的優勢。
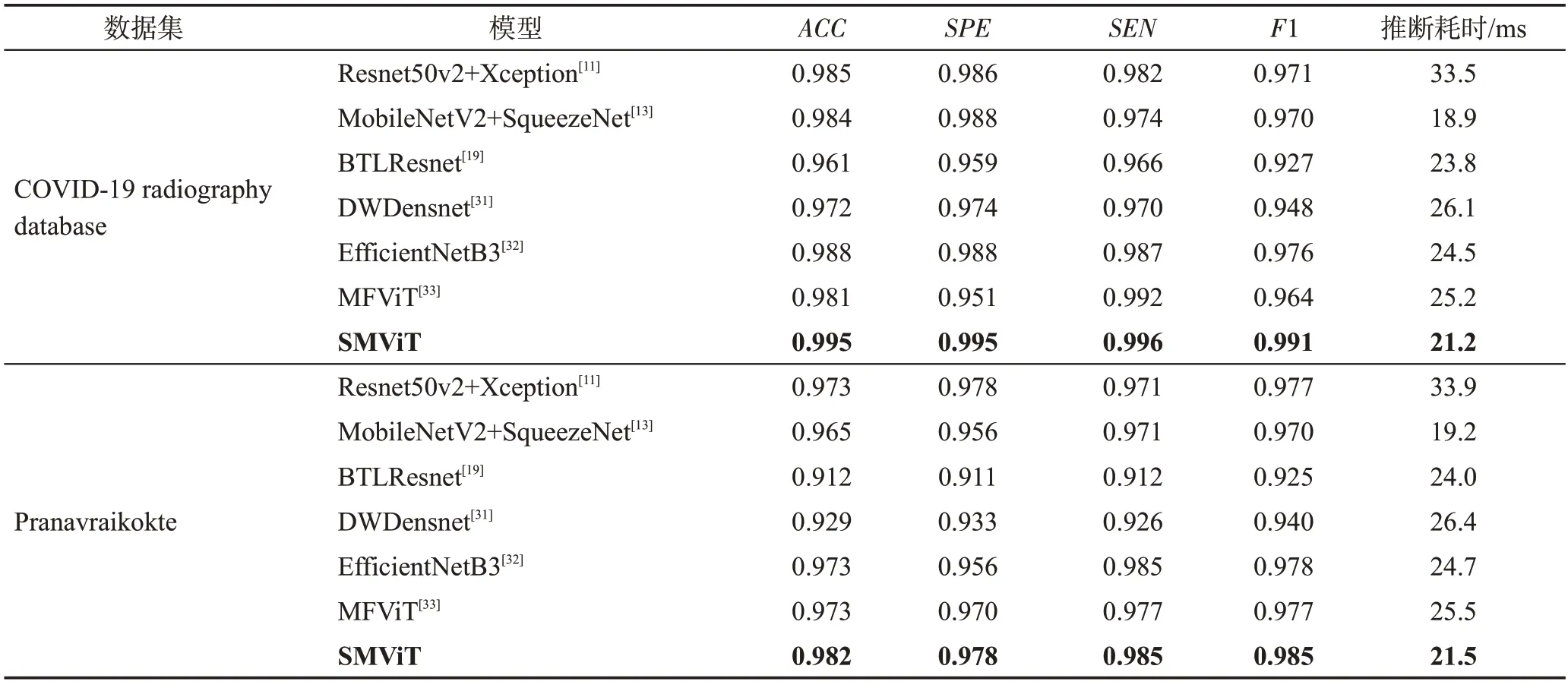
表1 不同方法在X-ray圖像上的性能對比Table 1 Performance comparison of different methods on X-ray images
在兩個CT 圖像數據集上比較了SMViT 與對比模型的診斷性能,實驗結果如表2 所示。可以看出,SMViT的ACC、SPE、SEN和F1分數具有最高的取值,與最具競爭力的Trans-CNN Net相比,分別提高了0.9%~2.1%、1.2%~2.1%、0.7%~2.0%和1.0%~2.1%,表明SMViT 在CT 圖像上的診斷性能具有明顯優勢。從推斷耗時來看,SMViT的推斷耗時與DeCoVNet2D相當,略高于COVID-FACT,但低于其他對比模型。其原因是COVID-FACT也采用了輕量化策略。與其他非輕量化的模型相比,SMViT在CT圖像上的推斷速度仍然具有顯著的優勢。
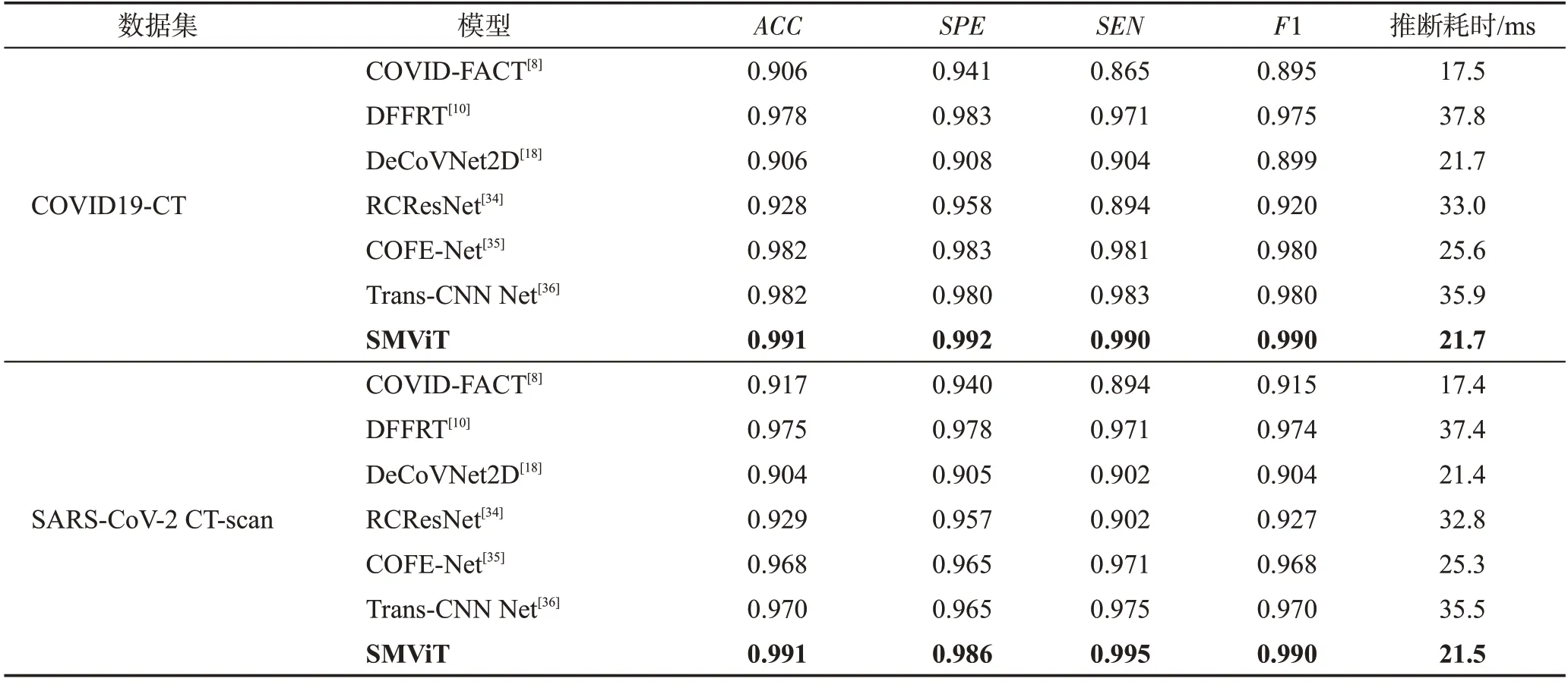
表2 不同方法在CT圖像上的性能對比Table 2 Performance comparison of different methods on CT images
2.2 消融實驗
為了驗證孿生網絡與ViT結合的有效性,分別設計了四組消融實驗,在包含X-ray 圖像與CT 圖像的四個數據集上的實驗結果如表3所示。
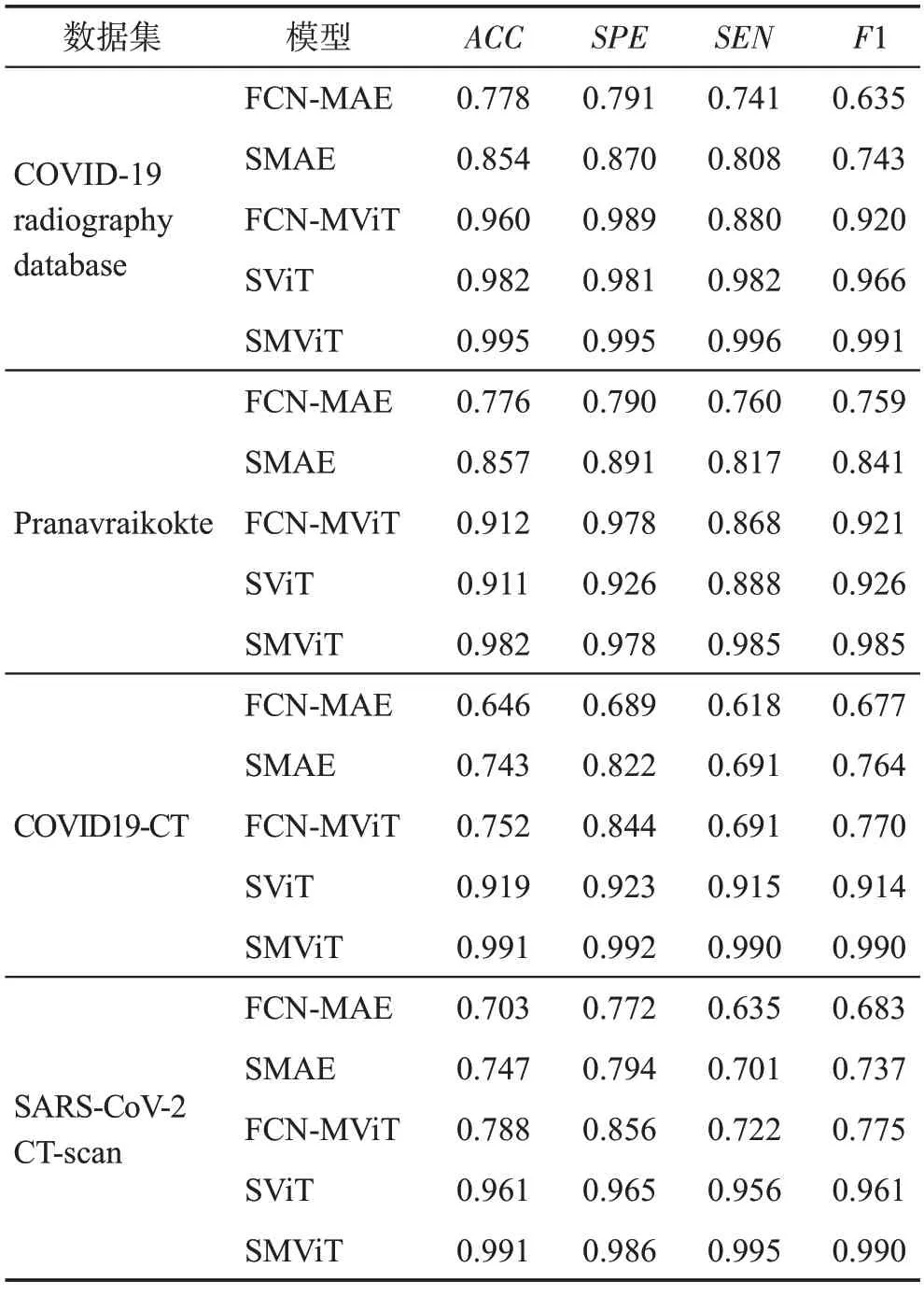
表3 消融實驗結果Table 3 Ablation experimental results
第一組實驗驗證孿生網絡架構是否比全連接網絡架構更有效。將ViT 與主流的用于分類的全連接網絡進行組合(fully connected network-masked vision transformer,FCN-MViT),其訓練流程與SMViT 保持一致。對比表3 中COVID19-CT 數據集與Pranavraikokte數據集上的實驗結果可以看出,FCN-MViT的性能不如SMViT,對于相對復雜的CT圖像病例的診斷效果較差。這表明FCN-MViT 在小數據集上的分辨能力不足,而基于孿生網絡與ViT 結合的SMViT,在小數據集上表現出了優越的性能。因此,采用孿生網絡架構比采用全連接網絡架構性能更好。
第二組實驗檢驗基于ViT 的自監督預訓練模型是否比基于卷積自編碼器的自監督預訓練模型更有效。使用圖像處理領域非常流行的卷積自編碼器來代替ViT 進行掩碼自監督預訓練(siamese masked autoencoder,SMAE)。對比表3 中SMAE 與SMViT的實驗結果,可以看出SMAE的性能明顯不如SMViT,這表明SMAE在圖像特征提取能力上略遜一籌。因此,雖然SMViT與SMAE模型均采用孿生網絡架構,但基于ViT 的自監督預訓練模型比基于卷積自編碼器的自監督預訓練模型更有效。
第三組實驗驗證卷積自編碼器與全連接網絡架構是否會是更有效的結合方式:使用卷積自編碼器進行掩碼自監督預訓練,采用全連接網絡架構進行分類(fully connected network-masked autoencoder,FCNMAE)。從表3 可以看出,FCN-MAE 不僅不能在小數據集上取得良好的結果,而且其總體性能遠低于SMViT。這進一步驗證了采用孿生網絡架構的模型在小數據集上能取得更好的效果,而采用卷積自編碼器與全連接網絡架構相結合的架構則會帶來更糟糕的結果。
第四組實驗驗證掩碼自監督預訓練策略能否比非掩碼自監督預訓練策略提取到更有效的特征表示,進而提升診斷精度。實驗中,使用與SMViT結構完全相同的網絡,采用非掩碼自監督預訓練策略(siamese vision transformer,SViT)。從表3 可以看出,在不同的數據集上SViT 的診斷準確率比SMViT低1.3%~7.2%。這表明與非掩碼自監督預訓練策略相比,掩碼自監督預訓練策略能提取到更有效的特征表示。
綜上所述,采用非孿生網絡架構的神經網絡在小數據集上的性能不佳;采用卷積自編碼器進行預訓練會導致模型特征提取能力不足,與采用ViT進行預訓練的模型相比其性能略顯不足;采用卷積自編碼器與全連接網絡架構的模型會帶來更糟糕的結果;而采用孿生網絡架構的ViT模型能夠在數據集樣本不足的情況下取得最好的效果。因此,孿生網絡對ViT模型在新冠肺炎診斷中具有重要的提升效果,進而驗證了此種架構的有效性。此外,與非掩碼自監督預訓練策略相比,掩碼自監督預訓練策略能提取到更有效的特征表示,對模型診斷性能的貢獻更高。
2.3 單類網絡下的輕量化可行性分析
在1.1 節已經證明由多個具有相同結構的子網絡構成的復合網絡,可以通過在單個子網絡上循環更新梯度來取得完全相同的結果。但為了進一步驗證該方法的可行性,設計了一個采用全連接層構建的具有多個相同結構子網絡的復合網絡,其結構如圖5所示。
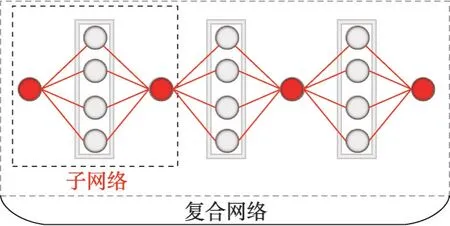
圖5 全連接構建的復合網絡Fig.5 Composite network constructed by full connection
設定相同輸入、標簽、初始參數,在單個子網絡復用三次與三個子網絡使用一次的模式下,驗證輸出與損失是否一致來判斷該策略的可行性,實驗結果如圖6所示。從圖6可以看出,兩種模式下每個輪次的輸出與損失完全一致,這表明該策略是可行的。
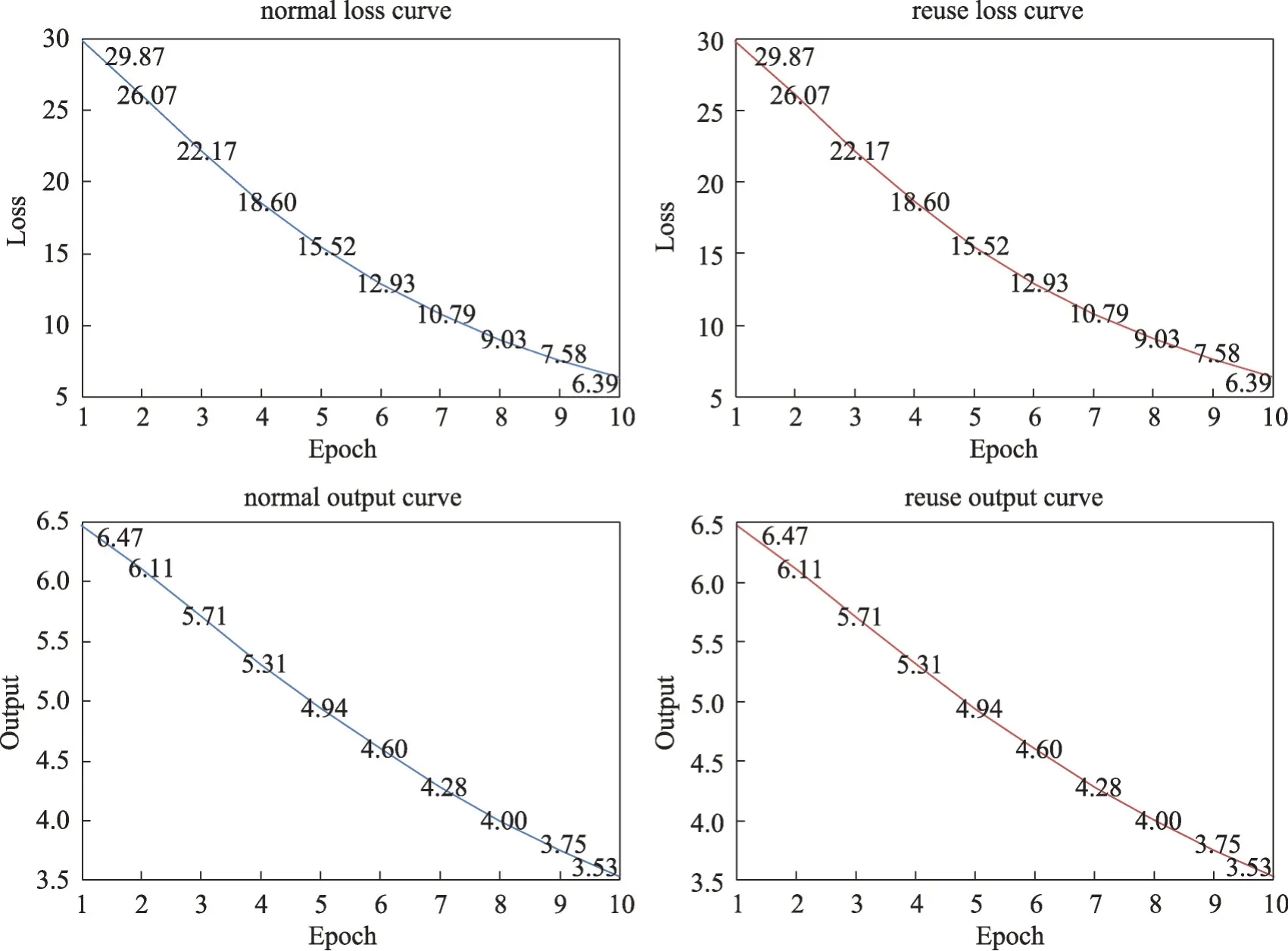
圖6 單類網絡下兩種方法的損失與輸出結果曲線Fig.6 Loss and result curves of two methods under simple network
2.4 復合網絡下的輕量化可行性分析
在保證相同輸入、標簽、初始參數的情況下,仍然通過檢查單個子網絡復用三次與三個子網絡使用一次兩種模式下,每個輪次的輸出與損失是否一致來檢驗該方法在復合網絡下的可行性,實驗結果如圖7 所示。從圖7 可以看出,兩種模式下,每個輪次的輸出與損失仍然完全一致,這表明該方法在復合網絡下仍然可行。
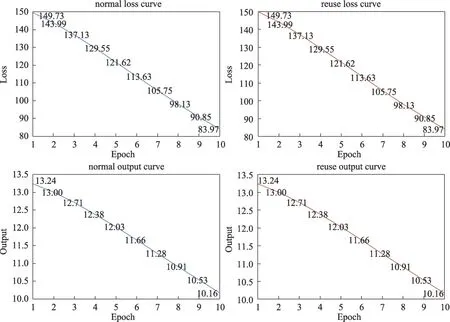
圖7 多類網絡下兩種方法的損失與輸出結果曲線Fig.7 Loss and result curves of two methods under multiple networks
設計了一個由全連接層、卷積層共同構建的具有多個相同結構子網絡的復合網絡,其結構如圖8所示。從圖8可以看出,該復合網絡具有三個結構完全相同的子網絡,每個子網絡的數據由全連接層輸入,通過reshape改變張量形狀,再輸入卷積層,然后通過reshape 再次改變張量形狀后輸入到全連接層,最后將全連接層的輸出作為下一個子網絡的輸入。
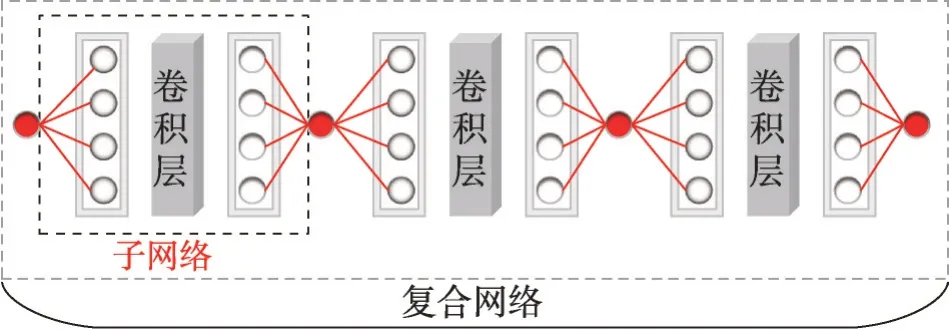
圖8 多類網絡構建的復合網絡Fig.8 Composite network constructed by multiple networks
2.5 輕量化結果與分析
由于ViT 的編碼器是由多個結構相同編碼器塊組合而成,屬于由多個相同結構的子網絡構成的復雜網絡,可以通過循環單個編碼器塊來達到與使用多個編碼器塊一樣的效果,并減小ViT的參數量。為了驗證SMViT 的輕量化效果,在不同編碼器塊數量下進行了對比。不同編碼器塊所占顯存與參數量如表4所示。在batchsize相同的情況下,循環單個編碼器塊的SMViT與擁有9個編碼器塊的ViT相比,所占顯存可減少74.07%,網絡參數量可減少88.88%。因此,基于循環子結構的SMViT 能明顯減少其參數量與顯存占用。
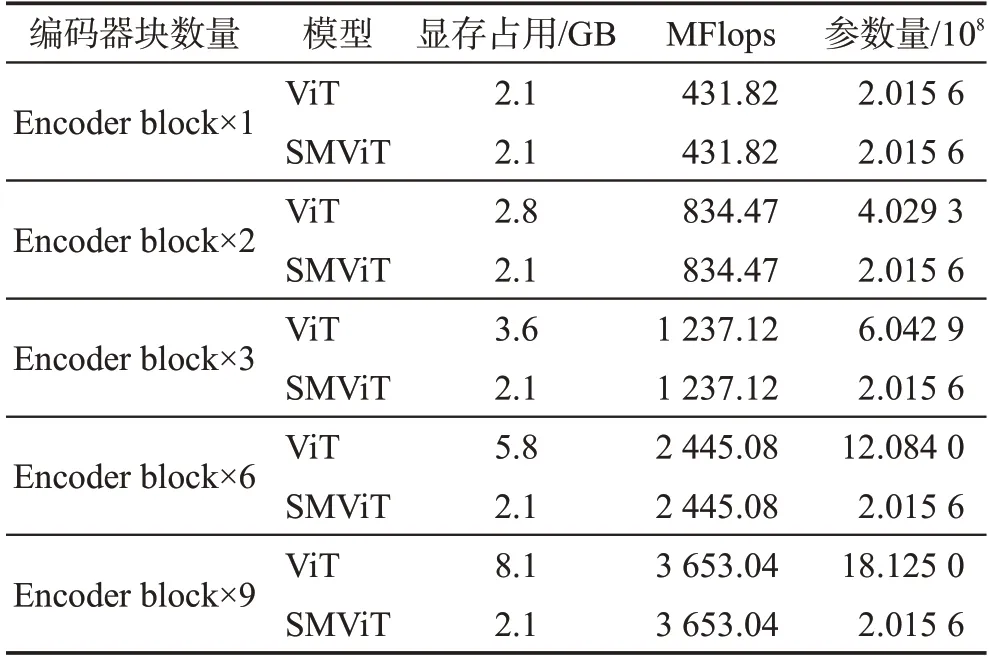
表4 不同方法的資源使用量Table 4 Resource usage of different methods
3 結束語
本文提出了一種輕量化的孿生ViT模型SMViT,并應用于新冠肺炎診斷。首先,使用非對稱的輕量級ViT 進行掩碼自監督預訓練來使模型學到更有效的潛在特征表示;其次,在ViT 的基礎上添加孿生網絡架構來搭建SMViT;最后,通過循環子結構的方法對模型進行輕量化。實驗結果表明:在X-ray數據集上,本文模型的ACC、SPE、SEN與F1 分數,比最具競爭力的ViT 架構模型提高了1.42%、4.62%、0.40%和2.80%;在CT圖像數據集上,相應指標最大可提高2.16%、2.17%、2.05%和2.06%。在X-ray 圖像與CT圖像上的實驗結果均表明SMViT的診斷性能明顯優于對比模型,表現出了優越的性能。此外,在數據集樣本量不足的情況下,SMViT 仍然具有良好的泛化能力。在基于循環子結構的輕量化策略下,SMViT能明顯減少參數量與顯存占用。
由于SMViT 采用了孿生網絡架構,在解決多分類問題時訓練耗時較高,未來的研究將對此進行優化。另外,對不具有結構相同子網絡的復合網絡如何進行輕量化仍然有待進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
