基于特征增強注意力機制的人臉超分辨率算法
2023-11-06 09:38:28許若波李陽
電腦知識與技術 2023年25期
許若波,李陽
(江蘇信息職業技術學院物聯網工程學院(信息安全學院),江蘇無錫 214153)
0 引言
人臉超分辨率技術是指利用計算機信息技術將低分辨率人臉圖像恢復至清晰的高分辨率人臉圖像。人臉超分辨率技術應用在多個領域,例如,它能夠作為基礎任務應用在人臉檢測和人臉識別等領域。近年來,出現了眾多圖像超分辨率算法,分為基于傳統的圖像超分辨率算法與基于深度學習的超分辨率算法,其中基于深度學習技術的超分辨率算法在近幾年得到了快速的發展。例如,Dong 等人[1]提出了使用3層卷積神經網絡恢復低分辨率圖像(SRCNN),與基于傳統的圖像超分辨率算法相比較,SRCNN在客觀評估指標方面獲得了較大的提升;Kim 等人[2]提出了利用更深層次的殘差網絡學習圖像的殘差信息(VDSR) ;Dai 等人[3]提出了一種深度二階注意力網絡(SAN),所提出的二階通道注意力模塊,更加有利于網絡學習特征之間的相關度;Zhang等人[4]提出了一種基于混合高階注意力網絡(MHAN),該算法分為兩個子任務,分別是特征提取和恢復重要細節任務,最終重建出清晰的高分辨率圖像。
本文算法的主要核心是采用深度殘差網絡與特征增強注意力機制相結合的方式自適應增強重要的特征,首先采用特征提取模塊將輸入的人臉圖像轉化為多通道的特征圖像,然后采用特征增強注意力機制模塊選擇性地恢復有用的人臉高頻細節信息,最后采用重建模塊獲取高分辨率人臉圖像。
1 相關知識
在2017 年,Ledig 等人[5]提出了一種生成對抗網絡,獲得了逼真的主觀視覺效果,其中它的生成網絡是由多個殘差塊組成的深度殘差網絡,因此深度殘差網絡在圖像超分辨率重建任務中也獲得了廣泛的應用;近年來也出現了眾多采用注意力機制提升網絡性能的算法,例如Hu 等人[6]提出了一種SENet 結構的注意力機制,可以自適應地重新校準通道特征響應。同時SAN 與MHAN 圖像超分辨率算法在網絡中也加入了注意力機制并獲得了良好的重建效果。因此本文重點采用深度殘差網絡與特征增強注意力機制相結合的方式完成人臉圖像的重建任務,其中特征增強注意力機制可以自適應增強人臉高頻細節信息。
2 基于特征增強注意力機制的人臉超分辨率算法
本文提出的基于特征增強注意力機制的人臉超分辨率網絡結構如圖1所示。該網絡結構分為3個模塊,分別是特征提取模塊、特征增強注意力機制模塊和重建模塊。其中特征提取模塊用于將輸入的人臉圖像轉化為多通道的人臉特征圖像,特征增強注意力機制模塊用于自適應恢復人臉高頻細節信息,重建模塊用于重建高分辨率人臉圖像。

圖1 基于特征增強注意力機制的人臉超分辨率網絡結構
2.1 特征提取模塊
特征提取模塊主要是為了將輸入的彩色圖像轉換為含有多個特征通道的人臉特征圖像,所輸出的人臉特征圖像作為下一步特征增強注意力機制模塊的輸入。
特征提取模塊網絡結構如圖1所示。由單個卷積層和ReLU 激活函數層串聯組成,其中卷積層的卷積核大小為3×3,輸出256個通道特征圖。特征提取模塊的輸出作為特征增強注意力機制模塊的輸入,因此特征提取模塊輸出特征圖操作為:
2.2 特征增強注意力機制模塊
特征增強注意力機制模塊是本文算法的核心模塊,該模塊能夠利用殘差塊提取特征的同時,自適應選擇重要的特征,特征增強注意力機制模塊共包含12個子模塊,每個子模塊均采用了殘差塊與注意力機制相結合的結構,以此來自適應增強人臉圖像的高頻細節信息。
特征增強注意力機制模塊專注于自適應學習特征通道之間的相關性,因此可以增強人臉圖像的高頻細節信息,如圖1所示,該模塊中的子模塊網絡結構由殘差塊和注意力機制組成,其中殘差塊由2對卷積層與ReLU 激活函數層串聯組成,卷積核大小均為3×3,輸出256 個通道特征圖。因此,特征增強注意力機制模塊第1個殘差塊提取特征操作為:
注意力機制能夠自適應地將重要特征進行提純,獲取有用的特征,淡化無用的特征。其網絡結構首先由1個卷積層與1個BN層串聯組成,為了保留重要的特征,將卷積層的卷積核大小設置為1×1,同時為了保證注意力機制在訓練過程中的穩定性,因此加入了BN層;其次設計并行的分支結構,其中一條分支由平均池化層、全連接層、ReLU激活函數層和全連接層組成,另一條分支由最大池化層、全連接層、ReLU 激活函數層和全連接層組成;然后將兩條分支的輸出分別進行加權相乘;最后將加權后的結果相加并輸入至Sigmoid 激活函數層,因此注意力機制輸出重要權重系數操作為:
其中,Conv_BN(·)表示卷積操作和批規范化操作,Avgpool(·)表示平均池化操作,Maxpool(·)表示最大池化操作,它們均表示壓縮輸入特征映射的空間維度,使其具有全局的感受野,壓縮后表示為1×1×C,C表示通道數量,?(·)表示串聯組成的全連接層操作、ReLU激活函數層操作和全連接層操作,第1個全連接層操作表示特征壓縮,提純重要的特征信息,表示為1×1×(C/m),m表示倍數,m設置為16,第2 個全連接層操作將壓縮后的特征數量升至原來的數量,表示為1×1×C,其中a和b表示權重系數,均設置為0.5,SigmoidATTN(·)表示激活函數操作表示生成的自適應權重系數。
生成的自適應權重系數與殘差塊提取的特征進行相乘操作,則可以增強重要的特征,并將結果與進行短跳躍連接操作,因此特征增強操作表示為:
特征增強注意力機制模塊共含有12個子模塊,因此特征增強注意力機制模塊輸出操作為:
其中,l=1表示第1個子模塊,以此類推,經過第12 個子模塊后,則生成最終的特征增強注意力機制特征
2.3 重建模塊
為了進一步將特征增強注意力機制模塊輸出的特征圖像重建成細節豐富的高分辨率圖像,必須設計最終的重建網絡結構。重建模塊能夠進一步提取重要的特征,并將低分辨率空間升至高分辨率空間大小。重建模塊首先由2個串聯的殘差塊組成,與2.2小節使用的殘差塊結構一致,卷積核大小均為3×3,輸出256個通道特征圖,同時進行短跳躍連接操作;其次設計了串聯組成的卷積層和ReLU 激活函數層,其中卷積核大小與輸出通道數量分別為3×3和256;然后設計由單個卷積層、子像素卷積層、卷積層和子像素卷積層串聯組成的結構,起到了上采樣的作用,上采樣倍數為4,最后通過1個輸出通道數量為3的卷積層重建出最終的高分辨率人臉圖像。具體步驟是,首先將特征圖像通過2個殘差塊;其次通過卷積層和ReLU激活函數層;然后通過上采樣操作;最后通過1個卷積層重建出最終的高分辨率人臉圖像。因此重建模塊的輸出操作為:
其中,f REC(·)表示重建網絡表示最終重建的高分辨率人臉圖像。
2.4 損失函數
由于L1損失函數有較好的網絡收斂能力,因此本文算法采用L1損失函數作為網絡的損失函數,基于特征增強注意力機制的人臉超分辨率損失函數為:
其中,ki表示原始的人臉圖像表示最終重建的高分辨率人臉圖像,Loss表示基于特征增強注意力機制的人臉超分辨率損失。
3 實驗與結果分析
3.1 實驗數據集
本文算法采用FEI數據集,FEI數據集包含400張圖像,選用360張作為訓練,40張作為測試,原始圖像大小為260×360 像素,采用雙三次插值法(Bicubic)下采樣4倍形成低分辨率數據集,低分辨率數據集圖像大小為65×90 像素,從而形成對應的高分辨率數據集和低分辨率數據集。
3.2 實驗參數信息
本文算法的實驗硬件主要為NVIDIA GTX 1080Ti顯卡,采用分塊的方式形成訓練集,低分辨率圖像塊大小為48×48像素,為了更快地讓網絡收斂,學習率設置0.000 1,共訓練290 個時期,為了提升網絡的泛化能力,同時使網絡能夠自適應調整學習率,故采用了Adam優化器。
3.3 實驗結果
本文算法采用峰值信噪比(PSNR)和結構相似性(SSIM)作為客觀評估指標,一般情況下,PSNR與SSIM的值越高,說明圖像質量越高。本文算法與多個算法進行比較,其中包括Bicubic、VDSR、SAN 和MHAN 算法,尤其是SAN 和MHAN 算法均使用了注意力機制,因此更能凸顯本文算法的優越性。
本文算法與Bicubic、VDSR、SAN和MHAN算法進行主觀視覺效果比較,如圖2所示,從人類的肉眼明顯可以看出,Bicubic算法雖然可以將低分辨率圖像升至高分辨率圖像空間大小,但是未能恢復細節,重建效果很差,從放大的人臉圖像眼睛區域可以看出,細節屬于完全模糊的狀態;VDSR算法比Bicubic算法恢復的細節更多一些,但是雙眼皮中的褶皺痕跡已經變形,細節信息嚴重丟失;SAN 算法的雙眼皮褶皺痕跡與原始圖像相比,有少量的細節并未恢復,褶皺痕跡不明顯;MHAN 算法與SAN 算法的情況大致相同,同樣是褶皺痕跡的細節信息尚未完全恢復;本文算法的主觀視覺效果最接近于原始圖像,從圖2中可知,本文算法的主觀視覺效果超越了對比算法。

圖2 主觀視覺效果圖
在客觀評估方面,本文算法與其他算法的實驗結果如表1所示,表1列出的實驗結果為40張測試圖像的平均PSNR 和SSIM 值。本文算法的PSNR、SSIM 值均超越了對比算法,尤其超越了使用注意力機制的SAN 與MHAN 算法。因此,本文算法在FEI 數據集上的主觀和客觀效果均表現出出色的重建效果。
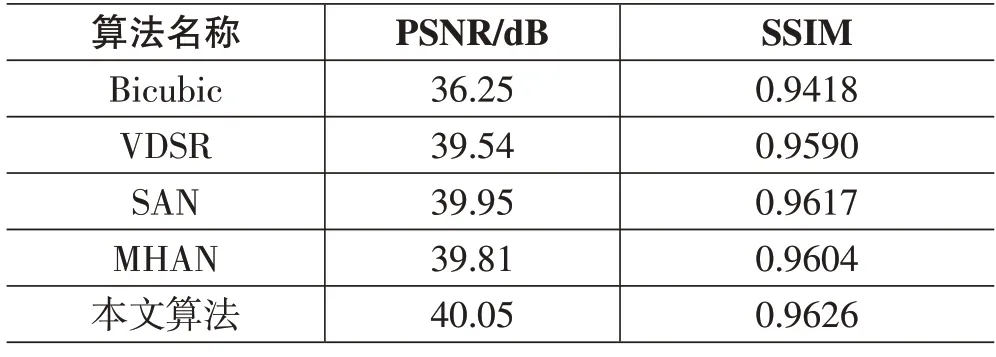
表1 客觀評估實驗結果
4 結論
本文提出了一種基于特征增強注意力機制的人臉超分辨率算法,該算法采用了3個模塊,分別是特征提取模塊、特征增強注意力機制模塊和重建模塊,3個模塊完成不同的重建任務;該算法能夠學習通道特征之間的自適應權重系數,增強重要的特征信息,有利于恢復更多的人臉高頻細節信息,提升網絡的表達能力。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
四川勞動保障(2021年9期)2022-01-18 05:11:08
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2016年9期)2016-11-12 13:28:08
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
