面向路側(cè)視角目標檢測的輕量級YOLOv7-R算法*
2023-11-09 03:56:14張小俊奚敬哲史延雷袁安錄
汽車工程 2023年10期
張小俊,奚敬哲,,史延雷,袁安錄
(1.河北工業(yè)大學機械工程學院,天津 300401;2.中國汽車技術(shù)研究中心汽車工程研究院,天津 300300)
前言
得益于新一代互聯(lián)網(wǎng)的飛速發(fā)展,自動駕駛技術(shù)已經(jīng)成為汽車產(chǎn)業(yè)未來發(fā)展的主要組成部分,但當前該領(lǐng)域研究通常聚焦于單車視角提升檢測精度與效率,而對匹配路側(cè)視角圖像信息特點的目標檢測模型的研究相對較少,且忽略了道路與車輛的協(xié)同性。而路側(cè)感知系統(tǒng)可用“上帝視角”的大范圍感知能力來彌補單車系統(tǒng)的感知盲區(qū),降低事故概率,提高道路交通效率。視覺傳感器又因其成本較雷達傳感器低廉,且能夠準確表達目標紋理特征的特點,在感知任務(wù)中扮演重要角色。因此在車輛網(wǎng)聯(lián)領(lǐng)域中,如何將各類交通參與者的檢測任務(wù)完成于路側(cè)單元(road side unit,RSU)較低算力的邊緣計算平臺已成為自動駕駛技術(shù)賦能的必要條件。
目前在目標檢測算法方面,傳統(tǒng)方法因?qū)崿F(xiàn)手段復(fù)雜、計算過程低效等原因已較少采用。在深度學習中,目標檢測算法分為R-CNN[1]系列雙階段算法和YOLO[2]、SSD[3]系列單階段算法。雙階段算法先定位再識別,所以精度上優(yōu)于單階段,但參數(shù)量和實時性較差,不能滿足RSU 低計算資源及高實時性的需求。與R-CNN 算法相比,SSD 算法有更快的推理速度,但其檢測精度存在一定的局限性,而YOLO系列算法相對其他算法在檢測速度上有很大提升,同時兼顧了準確度,適合作為路側(cè)感知場景中的檢測方法。
與其他檢測算法相比,YOLO 系列算法會一直利用深度學習最新成果來不斷地進行優(yōu)化更新。Wu 等[4]在YOLOv5s 的基礎(chǔ)上,提出了YOLOv5-Ghost,調(diào)整了原有的網(wǎng)絡(luò)結(jié)構(gòu),網(wǎng)絡(luò)參數(shù)大大減少,推理速度有所提高,但檢測精度下降3%。Liu 等[5]通過引入通道注意力模塊和集成DIOU 損失函數(shù),提高了對自動駕駛系統(tǒng)中小目標的檢測性能。Zhou等[6]在YOLOv5 的Backbone 中用混合使用深度卷積,同時利用Focal Loss函數(shù)提升算法的檢測精度。
雖然將上述算法移植到路側(cè)視角下目標檢測的過程中針對車輛等交通目標的特點已經(jīng)做了一定的優(yōu)化,但是檢測能力仍舊存在不足。吉林大學的張舜然[7]將MobilNetv3 結(jié)構(gòu)融入到Y(jié)OLOv4 網(wǎng)絡(luò),并加入注意力優(yōu)化與卷積計算優(yōu)化,使檢測精度達到90%,但模型參數(shù)量沒有下降很多,也沒有考慮交通環(huán)境中目標與目標之間的遮擋問題,若被遮擋目標的特征提取不充分就會導致算法在檢測時出現(xiàn)遺漏;山東大學的皮任東[8]采用了路側(cè)激光雷達與YOLOv5 結(jié)合的方法,算法mAP 值提高了4.48%,但也存在參數(shù)量龐大的問題。還有很多路側(cè)感知算法雖然降低了網(wǎng)絡(luò)參數(shù)量,適合部署在移動端,但忽略了同類目標在路側(cè)視角下因其遠近關(guān)系所呈現(xiàn)出多種尺度大小的問題,使模型學習困難,導致精度下降。
本文將ELAN 高效網(wǎng)絡(luò)融入到EfficientNetv2-s[9]結(jié)構(gòu)中,構(gòu)成新的EfficientNetv2-e 輕量化檢測網(wǎng)絡(luò),更換掉YOLOv7[10]算法的Backbone;在預(yù)處理階段適當?shù)貏h除輸入圖像中的部分信息,來增強對被遮擋目標的學習能力;根據(jù)路測感知信息有著背景信息不變的特點,將SE(squeeze-and-excitation)[11]通道注意力機制更換為CA(coordinate attention)[12]坐標注意力機制,解決被測目標的多尺度問題;再引入Focal-EIoU Loss[13]損失函數(shù),增加算法收斂速率,由此提出一種輕量級YOLOv7-R 算法。實驗表明,本文算法的綜合性能相較于對比算法更優(yōu)。
1 YOLOv7-R算法
1.1 YOLOv7算法
為了保證RSU 系統(tǒng)檢測的實時性,本文預(yù)選擇YOLO 系列算法為模型基礎(chǔ)。YOLO 系列算法,以其結(jié)構(gòu)精簡、性能高效、容易部署等優(yōu)點,被廣泛應(yīng)用于工業(yè)開發(fā),其中YOLOv7 是目前YOLO 系列較為先進的算法,十分適用于路側(cè)視角下的交通目標檢測。
YOLOv7 采用擴展高效網(wǎng)絡(luò)架構(gòu)(E-ELAN)[14]、基于級聯(lián)模型[15]、重參數(shù)化卷積[16]等策略,兼顧了檢測精度與檢測速度。如圖1所示,YOLOv7的網(wǎng)絡(luò)結(jié)構(gòu)包括3 部分:Input、Backbone 和Head。Input 端同傳統(tǒng)YOLO 一樣,采用了自適應(yīng)錨框設(shè)計,解決了不同數(shù)據(jù)集之間相同目標大小不同的問題,為被檢測圖像提供了合適的預(yù)選框。Backbone 部分由幾組Conv卷積層、ELAN 架構(gòu)和MPConv 組成。Conv模塊由卷積、批量歸一化、SiLU 激活函數(shù)[17]組成,用來提取圖像特征;ELAN 網(wǎng)絡(luò)架構(gòu)有兩條分支,第一條分支是通過一個1×1的卷積使通道數(shù)變化,第二條分支先通過一個1×1 的卷積,改變通道數(shù),再通過4 個3×3 的卷積,做特征提取,最后把得到的特征堆疊到一起得到最終的特征提取結(jié)果;MPConv 在Conv 層的基礎(chǔ)上增添了最大池化層,構(gòu)成兩個分支,最大池化可以增大感受野,減少輸入特征的數(shù)據(jù)量,Conv 用作特征提取,再通過Concat 操作將兩個分支提取到的特征進行堆疊,增強網(wǎng)絡(luò)的學習能力。還使用了SPP模塊,其作用是通過MaxPool增大感受野,使算法適應(yīng)不同的分辨率圖像,便于識別區(qū)分大小不同的目標;CSP 模塊將輸入分為兩部分,一個部分采用標準卷積,另外一個部分采用SPP 處理,最后把這兩個部分Concat 在一起,可以減少一半的計算量,且速度變得更快,精度變得更高。Head 部分由路徑聚合特征金字塔網(wǎng)絡(luò)(PAFPN)構(gòu)成,通過創(chuàng)造由底向上的路徑來讓底層特征更容易傳遞到輸出層,以便不同尺度特征的高效融合,再通過RepVGG Block(Rep)結(jié)構(gòu)調(diào)整PAFPN 輸出特征圖的通道數(shù),最后經(jīng)過1×1 卷積進行置信度、類別和錨框的預(yù)測。

圖1 YOLOv7網(wǎng)絡(luò)結(jié)構(gòu)
1.2 主干網(wǎng)絡(luò)改進
盡管YOLOv7 性能優(yōu)異,在自動駕駛?cè)蝿?wù)中表現(xiàn)優(yōu)秀,但是從模型大小上,其在資源較少的移動端上部署并沒有那么順利,YOLOv7 模型參數(shù)計算量如式(1)所示:
式中:Cin、Cout為輸入、輸出通道數(shù);d表示卷積的深度;k表示卷積核大小。從式(1)中可以看出,當模型的通道數(shù)C擴大n倍時,模型參數(shù)量J將擴大n2倍;若將模型的深度d擴大n倍時,參數(shù)量J也擴大n倍。
YOLOv7 主干網(wǎng)絡(luò)的通道數(shù)C設(shè)置較大,由式(1)可得,其模型復(fù)雜度較高。為了使模型復(fù)雜度降低,使算法更適合完成RSU 的檢測任務(wù),受到文獻[9]啟發(fā),本文使用EfficientNetv2-e 主干網(wǎng)絡(luò)替換YOLOv7 的Backbone。EfficientNetv2-s 是一種 輕量級網(wǎng)絡(luò),采用漸進式學習策略,通過縮減網(wǎng)絡(luò)通道數(shù)C,擴增深度d的方式,實現(xiàn)了網(wǎng)絡(luò)復(fù)雜度和特征提取精準度的折中。EfficientNetv2-s 中多使用深度可分離卷積(depthwise separable convolution,DSC),運算過程如圖2所示。

圖2 深度可分離卷積結(jié)構(gòu)
深度可分離卷積是逐層卷積和逐點卷積的結(jié)合,深度卷積首先對每個輸入通道分別執(zhí)行逐層卷積,然后通過點卷積(1×1 卷積)將輸出通道混合。即在一個標準的卷積中將輸入同時進行濾波和組合操作,但DSC將這個操作進行拆分,第一步將輸入進行濾波操作,第二步再將其進行組合操作。這種將標準卷積進行分解的操作方法可以有效地減少運算代價和網(wǎng)絡(luò)模型的尺寸。相較于普通卷積,DSC 的參數(shù)更少,參數(shù)量下降比為
參數(shù)量下降必然導致模型的學習性能受損,為彌補模型的這一缺點,將YOLOv7 主干網(wǎng)絡(luò)中的ELAN 高效網(wǎng)絡(luò)架構(gòu)融入到EfficientNetv2-s(圖3(a))主干網(wǎng)絡(luò)中,稱為EfficientNetv2-e 架構(gòu)。ELAN在不破壞原有梯度的情況下,通過控制最短和最長的梯度路徑,網(wǎng)絡(luò)能夠?qū)W習到更多樣、更準確的特征信息,具有更強的魯棒性。改進后YOLOv7-R 的主干網(wǎng)絡(luò)如圖3(b)所示。

圖3 主干網(wǎng)絡(luò)改進
1.3 注意力機制優(yōu)化
注意力機制是一種仿生物視覺機制。將人眼以“高分辨率”關(guān)注某個特定區(qū)域的習慣用在深度學習之中,讓模型去學習圖像中哪里是更重要的特征信息。一般來說,將該機制用于輕量網(wǎng)絡(luò)上時,通道注意力會比較明顯地改善網(wǎng)絡(luò)的性能,這是因為通道注意力使輕量網(wǎng)絡(luò)更關(guān)注圖像中重要的語義信息,而丟棄部分不重要的信息,由此削弱噪聲對輸入圖像特征提取的不良影響,增加模型的檢測精度。
同樣,EfficientNetv2 使用SE 通道注意力機制來增強模型性能,然而,它只考慮了建模輸入數(shù)據(jù)的通道關(guān)系,從每個通道的角度提取感興趣的區(qū)域,忽略了位置信息,不能精確地定位對象。這就可能會產(chǎn)生因相同目標呈現(xiàn)多尺度而導致模型漏檢的問題。因此本文采用CA 坐標注意力機制來替換SENet,CA注意力機制網(wǎng)絡(luò)結(jié)構(gòu)如圖4 所示,其中XAvg Pool 和YAvg Pool 是沿著兩軸做平均池化提取寬高方向上的特征信息,并通過Concat操作來拼接得到的特征,接著做卷積來獲得長程依賴關(guān)系,再進行歸一化,得到每個維度的全局信息,然后沿著X軸和Y軸做split操作,再進行Conv和Re LU激活,最后將得到的信息重新加權(quán),完成坐標注意力的施加。
不同于SE 注意力,CA 注意力機制把通道注意力分解成兩個方向進行特征編碼,其優(yōu)點是沿一個方向獲得長程依賴,沿另一個方向保留精確的位置信息,形成具有方向感知和位置信息的特征圖,以提高在特征提取過程中更關(guān)注感興趣區(qū)域的能力,使得算法能夠關(guān)注大范圍的目標位置信息忽略無效重復(fù)的背景語義信息,又不會帶來計算量的增加,足夠靈活和輕量,有助于模型通過位置信息更好地定位和識別多尺度目標。引入CA 注意力機制后的EfficientNetv2-e網(wǎng)絡(luò)中MBConv和Fused-MBConv 的結(jié)構(gòu)如圖5所示。
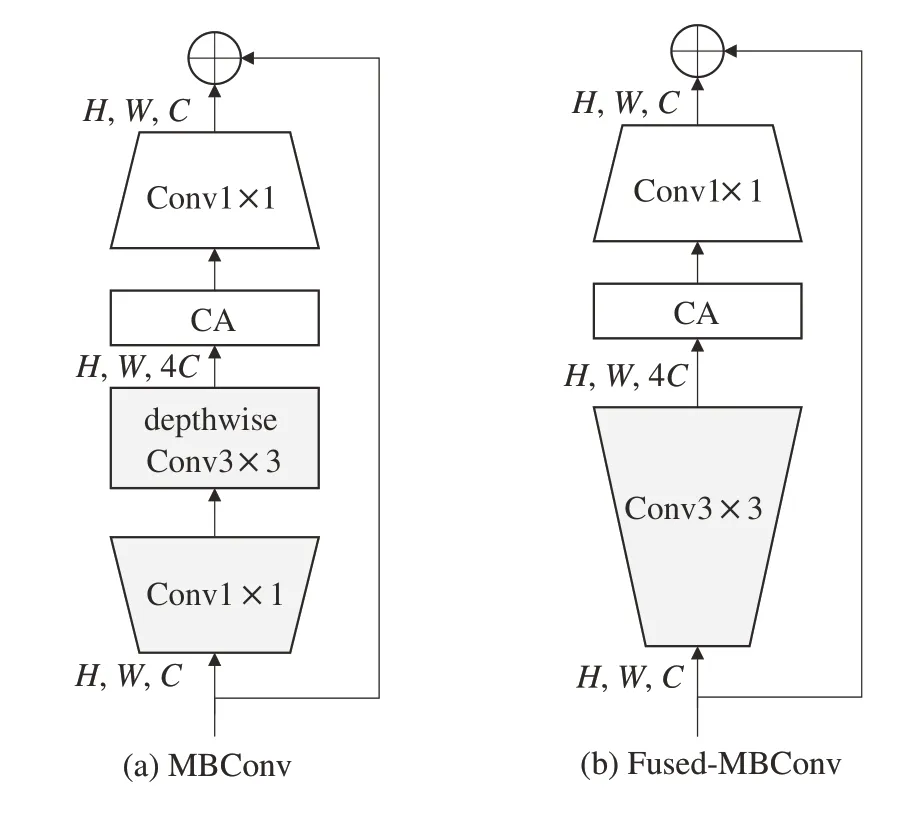
圖5 MBConv和Fused-MBConv結(jié)構(gòu)
1.4 損失函數(shù)優(yōu)化
深度學習中損失函數(shù)的選取很大程度影響訓練所得的算法性能。YOLOv7 的訓練方式分為帶auxiliary head 訓練與不帶auxiliary head 訓練兩種方式,帶auxiliary head 的訓練方式中,aux-head loss 和lead-head loss 兩者之間的比例不能過大,不過它們的損失函數(shù)相同,整體和YOLOv5 系列保持一致,分為3 部分:坐標損失、置信度損失和分類損失。后兩部分使用BCEWithLogits loss[18],坐標損失則默認采用CIoU loss[19]。CIoU loss計算公式如下:
式中:A為預(yù)測框;B為真實框;IoU為A和B的交并比,即A與B交集部分與并集部分面積之比,IoU越大,說明預(yù)測框越接近真實框,但當預(yù)測框與真實框沒有重疊部分時,或兩者完全重合時,IoU不能給出優(yōu)劣評價;b為預(yù)測框的中心點;bgt為真實框的中心點;ρ表示歐式距離計算;C為能夠包含預(yù)測框和真實框的最小閉包區(qū)域的對角線距離;參數(shù)a用于調(diào)節(jié)平衡比例;參數(shù)v用來描述預(yù)測框與真實框的寬高比的一致性,當中心點重合時,可通過v來衡量預(yù)測框和真實框的接近程度。
YOLOv7 的CIoU loss 考慮了重疊面積、中心點距離及寬高比,使得預(yù)測框的回歸更加穩(wěn)定,但它還不夠完美。因為其公式中使用參數(shù)v寬高比比例來衡量與真實框的寬高接近程度,并不是寬和高的真實值,所以有時會阻礙模型的優(yōu)化;而w和h其中一個值增大時,另一個值必然減小,它們不能保持同增同減,這也會導致?lián)p失函數(shù)收斂過慢以及回歸框定位的不精確。為了提高算法性能和檢測精度,本文采用Focal-EIoUloss 來替代CIoUloss,F(xiàn)ocal-EIoUloss的計算公式如下:
式中LIoU、Ldis、Lasp分別表示重疊面積損失、中心點距離損失及寬高比損失,邊界框回歸的EIoU 損失如圖6所示。

圖6 邊界框回歸的EIOU損失
EIoU loss 相較于CIoU loss 所做出的改進是將損失函數(shù)拆分為重疊面積損失、中心點距離損失及寬高比損失3 部分,并且對CIoU loss 中的a和v進行了修改,Cw和Ch為可包含真實框、預(yù)測框的最小框的寬度和高度,EIoU loss 利用和直接計算包圍框?qū)捀叩恼鎸嵵担@樣便解決了CIoU loss 使用寬高比比例所造成的阻礙優(yōu)化問題,還能解決訓練過程中的發(fā)散問題。此外,考慮到預(yù)測框的回歸中存在訓練樣本不平衡的問題,即在輸入圖像中回歸誤差小的優(yōu)質(zhì)錨框的數(shù)量遠少于誤差大的低質(zhì)量數(shù)量,質(zhì)量較差的樣本會產(chǎn)生過大的梯度影響參數(shù)的優(yōu)化,又借鑒了解決正負樣本不平衡的Focal loss[20],將偏差大的地方設(shè)置更大的梯度優(yōu)化,以便于關(guān)注對難樣本的檢測,降低質(zhì)量差的樣本對算法性能的影響。通過整合EIoU 損失函數(shù)和Focal 損失函數(shù),得到最終的Focal-EIoU loss 的表達式,如式(9)所示。當EIoU loss 很小時,F(xiàn)ocal-EIoU Loss 也會很小,雖然這會抑制高質(zhì)量樣本對模型訓練的影響,但數(shù)據(jù)表明,這種抑制效果對RSU 感知系統(tǒng)所需的背景不變數(shù)據(jù)集的影響是微弱的。
2 實驗設(shè)計
2.1 實驗配置和評價指標
實驗環(huán)境為Ubuntu20.04 操作系統(tǒng),處理器型號為i7-10700K,顯卡是RTX3090,顯存為12 GB,采用的深度學習環(huán)境為pytorch1.11,編程語言為python3.8,安 裝CUDA11.3、CUDnn8.0.4 以 及OpenCV4.6.0.6等擴展包。本文算法與對比算法的實驗結(jié)論均在此實驗環(huán)境中得出。
YOLOv7 的訓練方式分為正常訓練及auxiliary head 訓練,auxiliary head 訓練生成兩組不同的軟標簽,即粗標簽和細標簽,細標簽與lead head引導標簽分配器生成的軟標簽相同,粗標簽則通過放寬更多的網(wǎng)格作為正樣本的約束而成,但在路側(cè)感知數(shù)據(jù)集中粗標簽的附加權(quán)重接近于細標簽的附加權(quán)重,就會導致在最終預(yù)測時產(chǎn)生不良的先驗,所以本文采用不帶auxiliary head 的訓練策略。為了準確評估YOLOv7-R 算法在路側(cè)感知圖像上的檢測性能,按照COCO 數(shù)據(jù)集的標準,實驗評價指標采用總體樣本平均精確度mAP,即算法對數(shù)據(jù)集中各類目標檢測精度的平均值,每個類別使用準確率(precision,P)和召回率(recall,R)作為x軸和y軸,可繪制一條曲線,該曲線與兩軸圍成圖形的面積則為AP值。APsmall表示像素面積小于32×32 目標的AP值,APmedium表示像素面積大于32×32 小于96×96 目標的AP值,用來專門評判算法對多尺度檢測中的小目標檢測精度。推理速度指標采用FPS,即網(wǎng)絡(luò)每秒傳輸幀數(shù),單位是f/s(幀/秒)。具體公式如下,其中TP為真正例,F(xiàn)P為假正例,F(xiàn)N為假反例。
2.2 實驗數(shù)據(jù)
本文選擇的數(shù)據(jù)集為清華大學智能產(chǎn)業(yè)研究院(AIR)在2022 年2 月份發(fā)布的DAIR-V2X-I 中開源的7 058 張圖片。DAIR-V2X 是全球首個車路協(xié)同圖像數(shù)據(jù)集,開創(chuàng)了行業(yè)先河。數(shù)據(jù)來自北京市高級別自動駕駛示范區(qū)10 km 城市道路、10 km 高速公路及28 個路口,涵蓋晴天、雨天、霧天、白天、夜晚等豐富場景。DAIR-V2X-I 即為RSU 捕捉到的圖像數(shù)據(jù)集,由Car(乘用車)、Truck(貨車)、Van(面包車)、Bus(公交車)、Pedestrian(行人)、Cyclist(自行車)、Tricyclist(三輪車)、motorcyclist(摩托車)、Barrowlist(手推車)、TrafficCone(交通錐桶)這10 類組成,數(shù)據(jù)類別實例如圖7 所示。由于DAIR-V2X-I 中的三輪車的類別數(shù)量為0,并且手推車的類別數(shù)量僅為128,占比很小,所以真實類別可計為8 類。又因為這些數(shù)據(jù)中序號相近的圖片多為相鄰時刻的圖片,所以要隨機打亂再劃分數(shù)據(jù)集。但是數(shù)據(jù)集中各種目標的樣本數(shù)量差距較大,訓練效果差,必須要對樣本數(shù)量少的類別數(shù)據(jù)進行增強處理。
2.3 數(shù)據(jù)增強策略
因為數(shù)據(jù)類別的嚴重不平衡,數(shù)據(jù)增強策略不可或缺。YOLOv7 輸入端使用了Mosaic 數(shù)據(jù)增強,拼接4 張圖片訓練,主要作用是豐富背景。而由于DAIR-V2X-I 數(shù)據(jù)集具有背景信息不變性的特點,并不需要豐富背景,遂即舍棄Mosaic數(shù)據(jù)增強,進而轉(zhuǎn)為外部針對遮擋物體的GridMask[21]數(shù)據(jù)增強,參數(shù)設(shè)置分別為1/3、0.1、0.1、0.1,效果如圖8(b)所示。該方法對數(shù)據(jù)中的信息進行有序的刪除,以模擬對交通目標的部分遮擋,還不會造成擦除部分的不均勻。倘若模型對GridMask 處理后的圖片進行訓練,模型就能夠有效提高對被遮擋目標的檢測性能。

圖8 數(shù)據(jù)增強效果
對于數(shù)據(jù)量較少的種類,使用Multiplicative-Noise 隨機噪聲,在圖片中加入噪點,不改變太多背景信息的情況下進行數(shù)據(jù)增廣,增加圖片數(shù)量的同時,還可模仿雨雪天氣的路側(cè)情況;還使用Random-Gamma 隨機灰度系數(shù)變化,改變圖片的對比度,模仿夜間、傍晚時刻的路側(cè)情況,提高模型的泛化能力。最終將所得圖片以0.8∶0.1∶0.1 比例進行隨機打亂劃分,得到訓練集8 469 張圖片,驗證集和測試集各有1 059張圖片。
3 實驗及結(jié)果分析
在訓練參數(shù)的處理上,設(shè)置訓練epochs為300;訓練BatchSize為32;訓練動量Momentum為0.937;選擇學習率動態(tài)變化設(shè)置,lr0為0.01,weight_decay設(shè)置為0.000 5;優(yōu)化函數(shù)采用Adam。圖9(a)為訓練所得YOLOv7 與YOLOv7-R 的mAP@0.5 函數(shù)曲線,圖9(b)為訓練得到的mAP@0.5:0.95函數(shù)曲線,縱坐標代表mAP值,橫坐標代表迭代次數(shù)。對比兩條曲線可知在訓練迭代超過20 次之后,YOLOv7-R算法的mAP曲線始終高于YOLOv7 算法,說明本文的YOLOv7-R有更好的檢測精度。

圖9 YOLOv7與YOLOv7-R的mAP值對比
3.1 損失函數(shù)收斂性驗證
在與上述同一實驗條件下,對YOLOv7 與本文算法的損失函數(shù)進行分析試驗。兩種Loss函數(shù)的曲線變化如圖10 所示。其中,兩條曲線分別為坐標損失使用CIoU Loss 與使用Focal-EIoU Loss 時的平均損失值的情況。

圖10 損失函數(shù)迭代對比
從圖10 可以看出,持續(xù)的訓練學習,F(xiàn)ocal-EIoU Loss 和CIoU Loss 最終都到達收斂狀態(tài)。但是Focal-EIoU 方法的收斂速率和損失值相較于CIoU方法更優(yōu),穩(wěn)定性也有所提升。所以,使用Focal-EIoU 作為YOLOv7-R 的損失函數(shù),對檢測性能提升有著積極作用。
3.2 消融實驗
為清晰地了解本文所提出的改進措施對路側(cè)視角下目標檢測算法性能的影響,設(shè)計了一組消融實驗,在基線算法YOLOv7的基礎(chǔ)上添加和修改各個模塊,對比分析了:(1)原YOLOv7模型;(2)在YOLOv7基礎(chǔ)上更換EfficientNetv2-e 作為Backbone;(3)在(2)基礎(chǔ)上更改SE 注意力機制為CA 注意力機制;(4)在YOLOv7 基礎(chǔ)上將損失函數(shù)CIoU loss 改為Focal EIoU loss;(5)同時更換加入CA注意力機制的EfficientNetv2-e 和Focal EIoU loss 函數(shù)的本文算法。在相同的實驗條件下,在本文數(shù)據(jù)集上進行實驗,輸入數(shù)據(jù)大小為1920×1080。具體實驗結(jié)果見表1。

表1 消融實驗結(jié)果
由表1 可知,在除參數(shù)量之外的所有指標里,本文最終算法均為最優(yōu)。將YOLOv7 模型的Backbone更換為EfficientNetv2-e可以使其減少53.7%的參數(shù)量,增加23.7%的檢測效率,但這也使得模型精度有所降低;CA 注意力機制及Focal-EIoU Loss 都提高了模型的檢測精度。對比模型(3)和本文算法可知,更換Focal-EIoU Loss 后的模型(3)的mAP@0.5:0.95 值提高了4.3%,所以可知Focal-EIoU Loss 非常有利于模型在該數(shù)據(jù)集上精度的提升,在進行算法優(yōu)化時使用該方法是必要的。除此之外,由模型(2)和(3)可知,CA 坐標注意力機制對模型多尺度小目標的精度提升也是顯著的,APsmall與APmedium分別提高了2%和5.7%。最后可得本文算法與YOLOv7 算法在DAIR-V2X-I 數(shù)據(jù)集上相比,在參數(shù)量降低52.3%的同時mAP@0.5提高了3%,mAP@0.5:0.95提高了4.8%,且檢測速度增加了24.6%,驗證了YOLOv7-R 模型在路側(cè)單元感知數(shù)據(jù)集上的可行性,完全可作為車路協(xié)同產(chǎn)業(yè)中可以落地的模型基礎(chǔ)。
為了進一步驗證YOLOv7-R 面向被遮擋目標檢測任務(wù)的有效性,從DAIR-V2X-I 數(shù)據(jù)集中篩選部分有遮擋的圖像,進行目標檢測,圖11 可視化了有遮擋目標的圖像經(jīng)過本文算法YOLOv7-R 與原YOLOv7 算法的目標檢測結(jié)果,原圖中使用虛線標記紅框中的目標為未被YOLOv7 檢測到的被遮擋目標。

圖11 遮擋目標的檢測效果實例
從圖11 中可以看出,本文模型對被遮擋的目標的敏感程度要優(yōu)于YOLOv7算法,漏檢目標如第1個場景中公交車面前被遮擋的行人、第2 個場景中對向車道被遮擋的車輛以及第3 個場景中斑馬線上行駛的自行車目標。上述表明了本文模型在遮擋目標檢測中的巨大優(yōu)勢。其原因在于輸入數(shù)據(jù)經(jīng)過GridMask 增強后,模型對被遮擋目標的學習能力提高,最終實現(xiàn)檢測性能的提升。
3.3 對比實驗
為進一步表明本文算法的有效性,使用本文的YOLOv7-R 算法分別與 SSD、EfficientDet[21]、YOLOv4[23]、YOLOv5-m、YOLOv5-s、YOLOv7、YOLOX-s[24]及最新的SOTA 算法YOLOv8 在本文數(shù)據(jù)集上進行了對比實驗驗證,因為雙階段目標檢測算法的參數(shù)量和檢測效率都不符合路側(cè)感知系統(tǒng)的部署條件,所以本文沒有談及。對比實驗結(jié)果如表2所示。
由表2 可知,YOLOv5-s 因為其極簡的網(wǎng)絡(luò)結(jié)構(gòu),所以具有較小的參數(shù)量,雖然本文算法在參數(shù)量上的表現(xiàn)不及YOLOv5-s 與YOLOX-s,但檢測精度與檢測效率為本次實驗中的最優(yōu),比YOLOv5-s 的mAP@0.5高9%,比YOLOX-s的mAP@0.5高8.2%。實驗結(jié)果表明,YOLOv7-R 在兼顧精度與速度的條件下,優(yōu)化了參數(shù)量與模型大小,具有更好的性價比,也體現(xiàn)了YOLOv7-R 在路側(cè)視角圖像檢測上的優(yōu)勢。
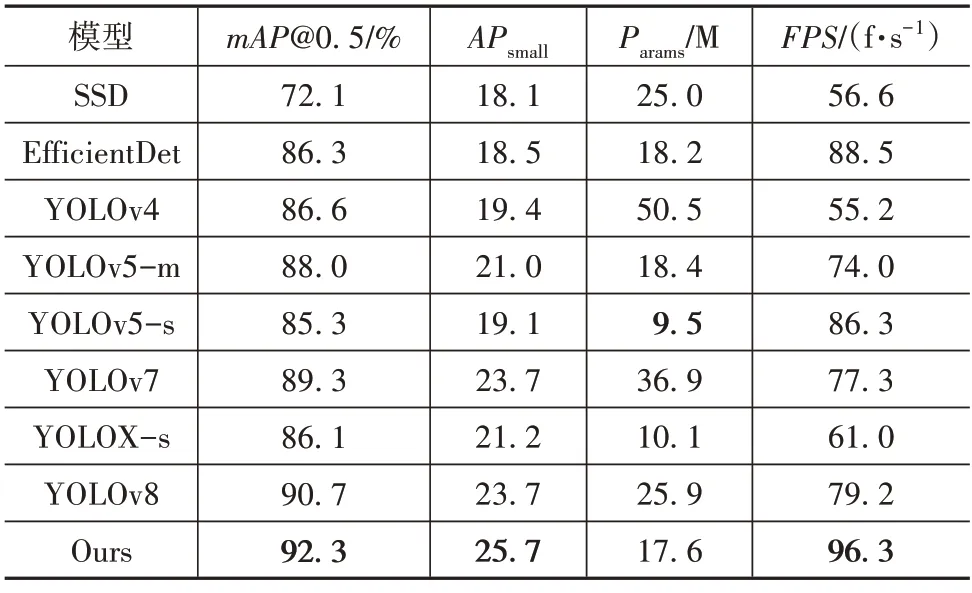
表2 不同算法對比
3.4 本文算法檢測效果
為了更直觀地感受YOLOv7-R 算法的檢測性能,在天津市津塘公路的路口采集了一些路側(cè)視角圖像進行測試,檢測效果如圖12 所示。在a 組檢測圖片中,可以看到待檢測圖片為擁堵時段的路口,屬于復(fù)雜場景,YOLOv7-R 算法能夠?qū)⒏鹘煌繕藴蚀_地檢測出來。在b 組檢測圖片中,從原圖可以看到車輛正處于低光照條件下,屬于夜間場景,YOLOv7-R 也能準確地將待檢測目標測出。在第3組檢測圖片中,圖12(c)為YOLOv7 算法的檢測結(jié)果,圖12(d)為YOLOv7-R 的檢測結(jié)果,可以看到當應(yīng)對存在遮擋目標的情況時,YOLOv7 算法漏檢了道路中央被車輛所擋住的行人,這就可能帶來安全隱患,而如圖12(d)所示本文算法則是精準地檢測出了他們。最后一組檢測圖片為目標多尺度的檢測效果圖,因相同目標的尺寸不一,導致YOLOv7 算法漏檢了遠處的小目標車輛,而圖12(f)中的本文算法將待測目標準確測出。上述檢測效果表明,本文算法能夠?qū)崿F(xiàn)對路側(cè)視角下的道路交通目標的準確檢測,且在漏檢率、遮擋目標分辨率上的表現(xiàn)均優(yōu)于基線算法,更適合部署在RSU設(shè)備當中。

圖12 檢測效果對比
4 結(jié)論
為了實現(xiàn)V2X(vehicle to everything)中RSU 感知系統(tǒng)的實時檢測應(yīng)用,本文提出了一種基于YOLOv7 改進的目標檢測算法YOLOv7-R。針對在算力較低的RSU 上部署模型困難的問題,文中更換了YOLOv7的Backbone,引入了添加ELAN 高效網(wǎng)絡(luò)架構(gòu)的EfficientNetv2-s 網(wǎng)絡(luò),以簡化卷積來實現(xiàn)模型的輕量化;針對被側(cè)目標呈多尺度、可能導致模型漏檢問題,本文使用CA坐標注意力機制代替主干網(wǎng)絡(luò)中的SE 注意力機制,通過捕捉目標的方向信息與位置信息,降低模型的漏檢率;針對模型輕量化所帶來的精度損失,修改原有的損失函數(shù)為更精確的Focal-EIoU loss,減小低質(zhì)量樣本對算法性能的影響,提升模型的檢測精度;針對數(shù)據(jù)集中的被測目標重疊問題,采用GridMask 數(shù)據(jù)增強策略,進一步提升模型的檢測性能。實驗結(jié)果表明,在有效地提升檢測速度及精度的前提下,還減小了模型的大小,以更小的參數(shù)量實現(xiàn)了對于目標數(shù)據(jù)集更高精度的檢測。
雖然本文算法能夠?qū)崿F(xiàn)對RSU 檢測場景中的部分交通目標較為準確的識別,但還有進一步提升的空間。DAIR-V2X-I數(shù)據(jù)集只有8類交通目標,而實際中的交通參與者類別會更多,后續(xù)研究將不斷擴充數(shù)據(jù)集中的類別,以提高算法的泛化能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
