基于雙重注意力機制的云計算負載預測模型
2023-11-18 03:32:08王恩旭王曉紅張冬雯
計算機工程 2023年11期
王恩旭,王曉紅,張 坤,張冬雯
(河北科技大學 信息科學與工程學院,石家莊 050018)
0 概述
近年來,隨著云計算的興起和信息技術的快速發展,云計算[1]的應用逐漸進入人們的視野。但隨著用戶量的不斷增加,越來越多的云計算數據中心存在能源消耗過高的問題,因此降低服務器集群的能耗成為云計算技術發展的重要研究方向[2]。CPU和內存等資源的消耗是服務器的主要能耗來源,分析CPU 和內存等資源的負載模式和特點對于提高資源利用率和降低能耗具有重要意義[3]。服務器資源分配不均勻,會造成數據中心服務器資源的浪費,是服務器集群能耗過大的主要因素之一。目前解決數據中心資源利用率不平橫問題已經成為云計算發展的挑戰[4]。提高服務器資源的利用率和合理的資源分配可以有效地緩解資源浪費和能耗高的問題。如果可以對數據中心資源使用量做出預測,就可提前對資源進行分配和管理,即可有效地提高服務器資源的利用率和降低數據中心能耗[5]。
負載預測[6]是關于集群資源管理的關鍵技術,在服務器正常運行的前提下,每隔一定時間對各臺服務器進行CPU 和內存等資源信息的數據采集,通過對云數據中心所采集的歷史數據進行分析,掌握負載數據的走勢和變化規律,從而進行下一個周期負載值的預測。通過負載預測可以合理地分配云數據中心的資源,達到提高資源利用率和降低能耗的效果[7]。因此,針對于降低數據中心的能耗和提高服務器的資源利用率,負載預測技術具有很高的研究價值。
云計算資源的負載預測是一個典型的時間序列預測問題,建立準確的時序預測模型是負載預測研究工作的重點。基于深度學習的長短期記憶(Long Short-Term Memory,LSTM)網絡是當前比較流行的時序預測模型,但對于云計算服務器各個特征的時序數據,每個特征和每個時間節點信息對于預測結果的影響可能各不相同。LSTM 網絡將所有信息以相同的重視程度進行預測,并無法區分每個特征和時間節點的重要程度。而且,當前很多對負載預測的研究大多只針對服務器某個特征的時序情況進行預測,單一特征無法全面地反映當前服務器的負載情況。
針對于以上問題,本文基于負載預測模型引入雙重注意力機制的思想,搭建雙重注意力機制網絡模型,自適應地提高網絡對各階段時序信息的注意程度,動態挖掘服務器各特征之間的潛在相關性,并且使用CRITIC 客觀賦權法對CPU 利用率和內存利用率等特征進行加權求和,以確定服務器獲得負載值的時序數據。通過對服務器負載值進行預測,以更加全面準確地體現服務器下一時刻的負載狀態。
1 相關工作
云計算資源的負載預測是一個典型的時序預測問題,利用歷史負載數據建立時序預測模型,對未來的趨勢與走向進行分析和預測。本文將目前流行的負載預測研究分為基于機器學習的預測方法和基于神經網絡的預測方法兩大類。
基于機器學習的負載預測方法可變參數較少更容易把握最優參數,在訓練數據集較少時更具有優勢。由于云計算環境的動態性和復雜性,文獻[8]提出一種基于支持向量回歸的多步提前CPU 負載預測方法,并且結合卡爾曼平滑技術進一步減小預測誤差。為捕捉到復雜的非線性特征,文獻[9]提出一種改進的線性回歸方法來預測主機的CPU 使用率,但前提是主機負載變化趨勢在短期內必須為線性的。文獻[10]提出一種將小波分解和ARIMA 相結合的混合方法進行時序預測,通過SavitzkyGolay 濾波進行平滑,再根據小波分解將平滑的時間序列分解為多個分量,分別針對趨勢和分量的統計特征建立ARIMA 模型,但這種方法對數據的穩定性有更高的要求。文獻[11]提出一種基于二次指數平滑的Stacking 集成預測模型對彈性云服務器進行預測,但是該模型需要進行多次構造,并且實現復雜。為了提高模型精度,文獻[12]提出將負載信息分解為線性部分和非線性部分的思想,并將ARIMA 模型和CART 模型相結合進行預測,使得模型的最終預測值比傳統模型預測值更加精確。
基于神經網絡的負載預測方法對預測非線性和噪聲水平高的數據更具有優勢,更適用于數據集較為龐大的數據。針對云資源時間序列的負載預測問題,文獻[13]使用循環神經網絡(Recurrent Neural Network,RNN)預測云主機CPU 利用率,證明了RNN 優于傳統方法,但是使用結果表面隨著預測的步長增加,網絡預測的準確性會逐漸下降。文獻[14]嘗試使用LSTM 對云服務器的負載進行預測,并使用RMSE、MSE 和MAE 3 個指標對預測精度進行衡量,獲得了較好的效果,確定了LSTM 模型用于負載預測的可行性。文獻[15]提出基于概率預測和改進的多層LSTM 的云資源預測模型,為了減少模型的過擬合現象,通過改進似然函數隨機丟棄中間輸出,取得了不錯的效果。文獻[16]提出一種基于遺傳算法的神經網絡負載預測方法,有效提高了網絡模型的收斂速度和預測精度。文獻[17]提出一種基于ARIMA 和LSTM 的組合預測模型對云平臺資源進行預測,并利用CRITIC 將兩個模型的預測結果進行加權組合。實驗結果表明,該方法優于單一的預測模型,但存在梯度消失的問題。文獻[18]針對主機負載中復雜的噪聲變化,提出一種由一維卷積神經網絡和LSTM 組成的混合預測方法,用于在多個連續時間步預測云服務器上的CPU 利用率,有效緩解了噪聲對負載預測影響。文獻[19]提出一種基于深度循環神經網絡編碼器-解碼器的多步在線預測模型,該模型可以對主機的負載進行多步預測,且具有一定的穩定性,但其只考慮了服務器CPU 利用率這一個維度的信息,并沒有考慮如內存或網絡等其他維度信息。文獻[20]將殘差連接與LSTM 網絡相結合,提出一種新的CPU 負載預測模型,并且使用阿里巴巴Cluster-trace-v2018 數據集進行實驗,說明了殘差連接和注意力機制網絡相結合的有效性。文獻[21]通過綜合考慮預測精度和預測時間兩方面因素,提出一種基于GRU 與LSTM 的組合預測模型,結合LSTM 預測精度高與門控循環單元(Gate Recurrent Unit,GRU)預測時間短的優點,對云計算資源負載進行高效預測,但在多個特征維度和時間序列內在關聯性的捕獲上并不敏感。文獻[22]提出一種基于iForest-BiLSTM-Attention 的負載預測方法,該方法結合注意力機制與雙向長短期記憶網絡,計算隱層狀態和注意力權值,對負載數據進行預測,但未考慮到特征維度信息對預測的影響,只是單一維度對注意力權重進行加權。文獻[23]設計并實現一個基于注意力的GRU 負載預測模型,并與沒有注意力機制的GRU 進行對比實驗,驗證了注意力機制可以有效提高預測的準確度,但該模型只考慮了時序注意力,對特征注意力權重的捕獲并不敏感。
針對大多研究對特征維度和時間序列內在關聯性的捕獲不敏感問題,本文在負載預測中引入了雙重注意力機制的思路,加強了各階段時序信息和各特征之間的潛在相關性,評估出各時序信息和特征信息的重要程度。雙重注意力機制網絡模型可以動態地捕獲時序信息和特征信息的權重關系,不僅提高了單步和多步預測的精確度,同時也提高了預測結果的穩定性。
2 負載預測模型
2.1 負載值計算
本文提出使用客觀賦權法求得服務器CPU 使用率、內存使用率和磁盤I/O 等特征的權重,進而計算出服務器負載值的時序數據。受CRITIC 方法的啟發[24],針對對比度的考量,標準差可以反映各項特征的變異程度;相關系數可以體現出各項特征的沖突性,如果兩個特征之間具有較強的正相關,說明兩個特征沖突性較低;如果具有較強的負相關,則說明兩個特征沖突性較高。通過負載值的數據可以有效了解當前各個云計算數據中心服務器的負載情況,進而預測出下一個時間單位的負載情況,并提前進行相應的操作和處理,達到合理分配數據中心資源的效果,同時可以有效提高資源利用率和降低能耗。
假設數據中心中n個主機收集到的特征數據分別為X={X1,X2,…,Xi,…,Xn},其中,Xi為第i臺服務器特征向量集合Xi={C1,C2,…,Cj,…,Cm},Xi定期從服務器收集特征信息,如CPU 使用率、內存使用率、磁盤I/O 使用率等信息。其中每個Cj均具有T個歷史數據,用于預測T+1 時刻的數據,即Cj={cj,1,cj,2,…,cj,t,…,cj,T}。求取負載值權重方法如下:
其中:Ij為信息量,表示第j個特征對服務器的負載影響程度;σj表示第j個特征的標準差;rkj表示第k個特征與第j個特征之間的相關系數。Ij值越大,第j個特征對服務器負載的影響程度就越大,該特征重要性也就越大。因此,第j個特征的客觀權重ωj的計算公式如下:
通過ωj數據即可求取數據中心每臺服務器負載值的時序數據。負載值時序數據計算公式如下:
其中:L為數據中心某臺服務器負載值時間序列數據。每個L具有T個歷史數據,即L={l1,l2,…,lt,…,lT},lt為服務器某一時刻的負載值,通過負載值的時序數據即可預測T+1 時刻的負載值。
2.2 雙重注意力機制網絡模型
注意力機制的本質是對數據加入相應的權重,提高某些數據信息在訓練過程中的重要性,LSTM神經網絡在訓練過程中忽略了時序數據每個時間節點的重要性和每個特征的重要性,只是對信息進行了無差別的壓縮。注意力機制可以自適應地給數據分配注意力權重,突出重要信息對預測結果的影響。本文將雙重注意力機制的思想運用于負載預測中,使數據在訓練過程中自適應地對重要信息增加權重,提高了負載預測網絡單步預測和多步預測的準確性。雙重注意力機制網絡模型如圖1所示。
模型訓練集數據首先進入特征注意力機制模塊,自適應地計算出每個特征對應的權值,并將特征權值與原始數據融合。再將加權后的數據傳入LSTM 中進行學習,隨后傳入到時序注意力機制模塊,以自適應的方式獲取LSTM 網絡層輸出數據的時間權重,數據在時間維度上進行加權,提高了網絡對每個時間步的關注程度。最后將時序注意力機制的輸出使用Flatten 函數進行數據降維,得到[d1,d2,…,dk×T]輸入到全連接層。y1、y2和y3分別為多步預測數據結果。
2.2.1 特征注意力機制
特征注意力機制的目的是輸入數據在進入LSTM 神經網絡之前,將模型的輸入特征自適應地動態分配注意力權重,挖掘某些特征對預測結果的重要性。通過特征注意力機制的方式使模型增大重要特征的訓練權重,從而減小甚至忽略對預測結果影響小的特征重視程度。傳統的相關性分析法會導致特征關聯信息丟失,而特征注意力機制可以有效緩解特征關聯信息丟失問題。特征注意力機制網絡模型如圖2 所示。
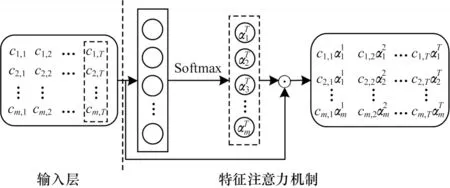
圖2 特征注意力機制網絡模型Fig.2 Network model of characteristic attention mechanism
如圖2 特征注意力機制部分所示,以第T個時間步為例,將單時間步的m個特征CT={c1,T,c2,T,…,cm,T}輸入到由m個神經元組成的單層神經網絡計算得出特征注意力機制的權重向量αT:
本文通過自適應的方式獲取時序數據的特征屬性,將各項特征的權重系數與輸入數據相融合,以提升重要特征對訓練模型的影響,提高了預測模型的準確性。
2.2.2 時序注意力機制
時序注意力機制將接收到的LSTM 隱藏層時序歷史數據信息自適應地分配權重,以區分不同時刻對預測結果的影響。同時,時序注意力機制提取各歷史數據時刻的信息,提高了網絡對于多步預測的準確性。時序注意力機制網絡模型如圖3所示。
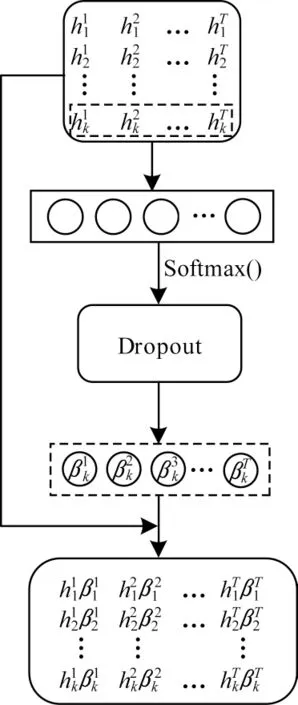
圖3 時序注意力機制網絡模型Fig.3 Network model of temporal attention mechanism
以第k個神經元的輸出為例,時序注意力機制的輸入為LSTM 網絡隱藏層狀態再由k個神經元組成的單層神經網絡計算得出時序注意力機制的權重向量βT:
在獲取到數據矩陣h′=[h′1,h′2,…,h′k]后,輸入到全連接層中。
2.3 模型評價指標
為了量化負載值預測的準確性,本文提出的負載預測模型在進行測試時使用以下評價指標:MAE、平均絕對值百分比誤差(Mean Absolute Percentage Error,MAPE)、MSE、均方根誤差(Root Mean Square Error,RMSE)和決定系數(R2)。其中,MAPE 的值越高說明預測準確度越精確,其他指標反之。
其中:n為測試集的總個數為測試集的預測值;yi為測試集的實際值;yˉ為測試集的平均值。
3 實驗結果與分析
3.1 實驗數據集
為了驗證本文提出的雙重注意力機制負載預測網絡的效果,使用阿里巴巴2018 年公開的數據集Cluster-trace-v2018[25]對網絡行實驗。Clustertrace-v2018 記錄了8 天4 000 多臺服務器各個特征的歷史數據,其中包括CPU 使用率、內存使用率、網絡帶寬的輸入輸出和磁盤使用率,采集頻率約為每次10 s。本文使用其中一臺服務器8 天的歷史數據,為保證時序數據的連續性,對不連續的時間數據進行裁剪,最后網絡的實驗數據裁剪為42 000 條。其中,取前60%作為實驗的訓練集,取20%的作為實驗的驗證集,取后20%作為實驗的測試集。數據集時序數據如圖4 所示。
3.2 數據標準化處理
將數據進行標準化處理可以提高網絡的擬合速度,同時能夠提高網絡預測的準確性和穩定性。本文采用z-score(zero-mean normalization)標準化方法對服務器各項特征進行處理,如式(12)所示:
其中:xt為各項特征在t時刻的值為t時刻的數據標準化結果;μ為實驗數據所有時刻的均值;σ為數據所有時刻的標準差。
3.3 負載值計算與分析
將數據集的歷史數據使用CRITIC 客觀求權法求取服務器各項特征的權重,獲得服務器各個時刻負載值的歷史數據。求得各項特征的信息量如表1所示。
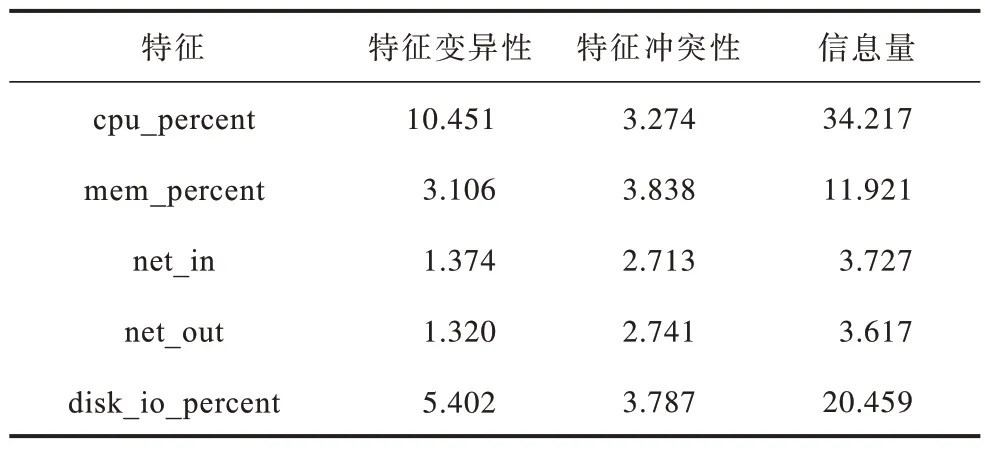
表1 各項特征的信息量Table 1 Information amount of each characteristics
特征變異性為標準差,標準差越大則體現出該特征的變異性越高,權重就會越大。特征沖突性為相關系數,特征之間相關性越強則沖突性較低,權重越小。通過求得標準差和相關系數,確定特征的信息量,進而確定各項特征的權重。各項特征權重如圖5 所示。
相比于其他特征,CPU 使用率的權重更大,同時說明CPU 使用率的波動對服務器的負載有著更大的影響。網絡的輸入輸出只占有5%和4.9%,相比其他特征對服務器負載影響較小。通過求得的特征權重計算出服務器的負載值,輸入到網絡中進行預測。
3.4 負載預測實驗過程與分析
3.4.1 實驗過程
本文使用雙重注意力機制網絡對服務器未來時刻進行預測。首先獲取數據集總服務器每個時刻的特征歷史數據,之后對數據集數據進行裁剪,裁剪的目的是保證時序數據的連續性。將裁剪好的數據進行標準化處理后,通過各個特征加權計算出服務器的負載值,然后將各個特征連同負載值輸入到網絡中進行訓練。當網絡訓練完成后,使用測試集數據對網絡進行評價,評估網絡負載預測的準確性。最后通過一段時間的歷史數據來預測下一時刻或多個時刻的服務器負載值。
3.4.2 實驗環境
本文使用Python3.7 版本進行實驗,軟硬件實驗環境如表2 所示。

表2 實驗環境Table 2 Experimental environment
3.4.3 網絡預測結果
本文提出的雙重注意力機制網絡預測模型為多步預測網絡,本文截取測試集數據5 000 個時間單位的多步預測結果和真實值的比較。由于選擇預測的時間節點過長會與真實值偏差過大,本文分別選取未來第1 個、第4 個和第10 個時間節點的預測結果進行對比,如圖6 所示。其中,圖6(a)~圖6(c)分別表示預測未來第1 個、第4 個和第10 個時間節點的真實值與預測值對比,可以看出本文的網絡模型對于單步或多步預測的真實值與預測值吻合度較高。
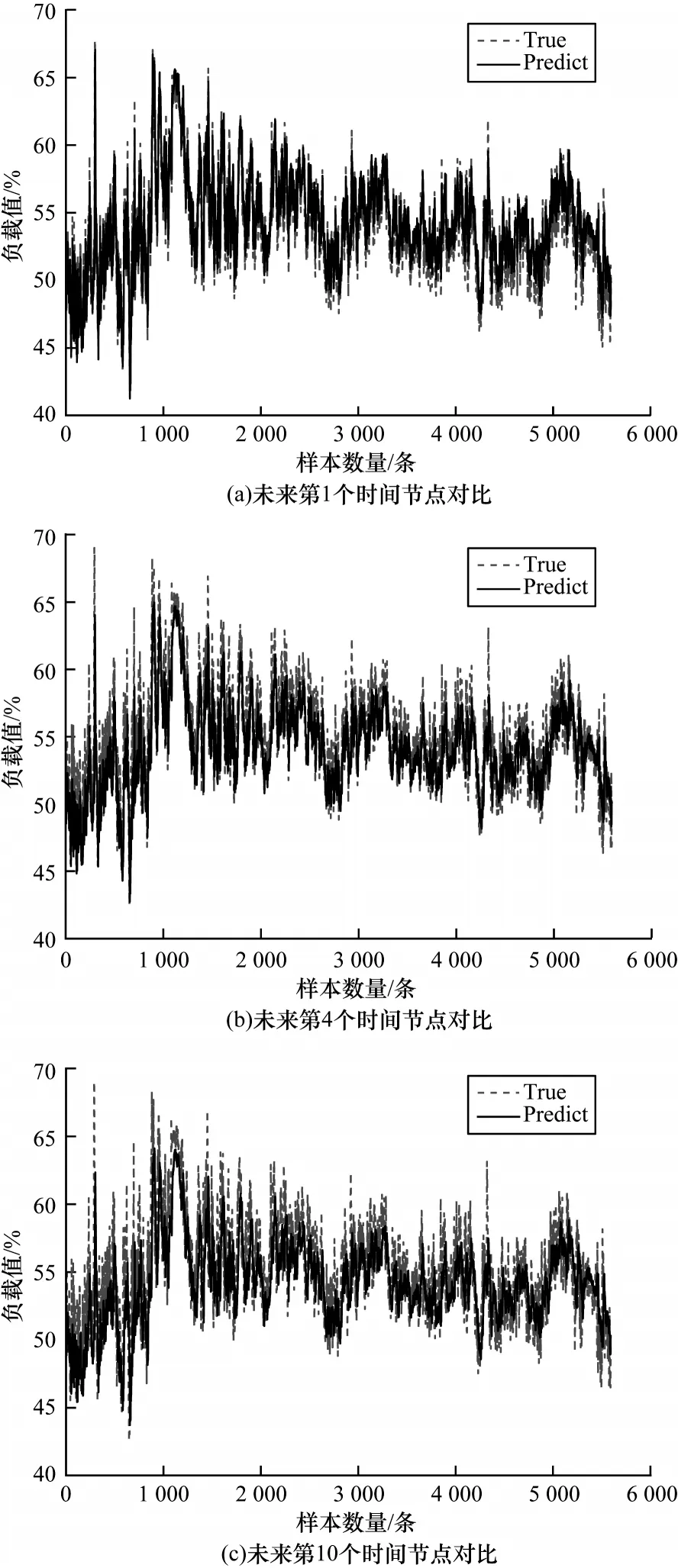
圖6 真實值和預測值對比Fig.6 Comparison of real value and predicted value
在網絡訓練結束后,獲取自適應訓練得到的特征注意力機制權重和時序注意力機制權重,如圖7所示。圖7(a)為特征注意力機制各個特征自適應得出的訓練權重,可以看出CPU 使用率、網絡的輸入和磁盤I/O 對預測結果影響相對較小,網絡輸出和服務器負載值對預測結果影響較大。說明特征注意力機制在訓練過程中自適應地降低了網絡輸入和磁盤I/O 這兩個特征的重要程度,有效地提高了網絡預測的準確性。圖7(b)為時序注意力機制各個步長的權重,通過網絡自適應獲取到時間步長權重可以看出,距離預測結果越近的時間步對于預測結果的準確性影響越大,反之相對較遠的時間步對結果的影響偏小。時序注意力機制通過加大后幾步時間步的權重,從而提高預測結果的準確性。
3.4.4 對比實驗
為了驗證本文所提出的雙重注意力機制負載預測模型(DA-LSTM)單步預測和多步預測的精確度,使用雙重注意力機制網絡與LSTM 網絡、RNN 網絡、GRU 網絡以及單一的加入時序注意力機制(TALSTM)或特征注意力機制(CA-LSTM)網絡分別進行對比,以MAE、MSE、R2和MAPE 評價指標作為衡量標準,結果如表3 所示。
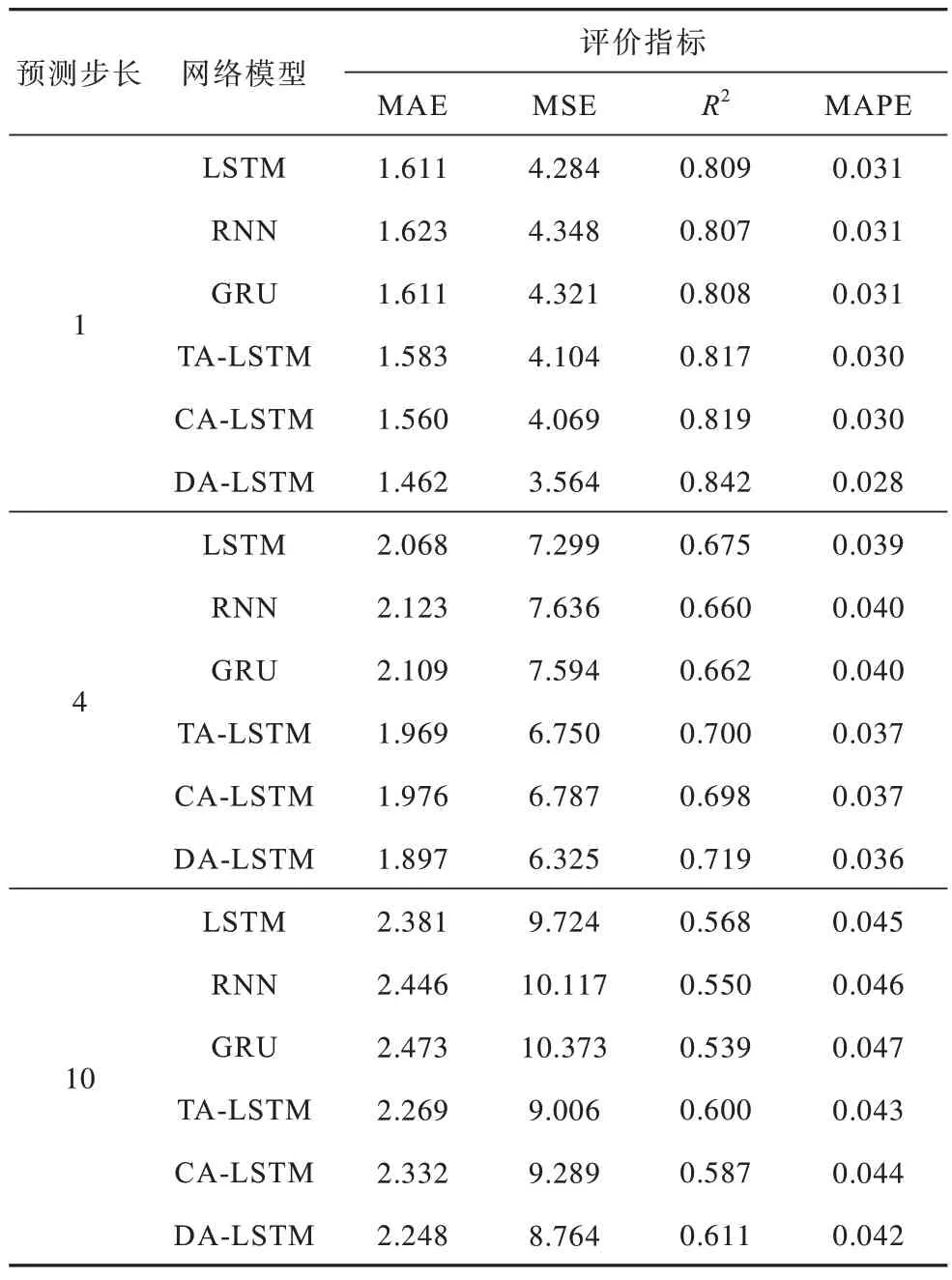
表3 模型評價標準Table 3 Model evaluation criteria
從表3 可以看出,針對服務器的負載預測問題,引入了注意力機制后的TA-LSTM 和CA-LSTM 模型,均具有比傳統預測模型RNN、LSTM 和GRU 較好的預測效果。進而說明,通過時序注意力機制的時間權重提取和特征注意力機制對各項特征的權重提取可以有效地對數據的時序信息和特征信息進行挖掘,提升負載預測的準確性。本文提出的雙重注意力機制網絡在單步預測中相較于LSTM 網絡,MAE 和MES 分別下降了9.2%和16.8%。對于多步預測,其相較于LSTM 網絡在預測第4 步和預測第10 步的MSE 分別下降了13.3%和9.8%,提升效果明顯。綜上所述,針對服務器的負載預測問題,加入特征注意力機制和時序注意力機制可以有效提升網絡單步預測和多步預測的準確性。
本文將雙重注意力機制網絡與其他網絡的預測結果進行對比,通過對比模型預測負載值與真實值的偏離程度,可以得到各個網絡預測的準確性,如圖8 所示。由圖8 可以看出,本文提出的雙重注意力機制網絡模型相較于LSTM、GRU 和RNN 等單一的預測模型,雙重注意力機制網絡預測結果更接近于真實值。與單一加入時序注意力機制或特征注意力機制相比,雙重注意力機制在預測結果與真實值的偏差范圍更加穩定。

圖8 各模型的預測結果Fig.8 Prediction results of each models
同時本文還分別與文獻[21]提出的GRU-LSTM組合模型、文獻[22]提出的BiLSTM-Attention 注意力機制模型和文獻[23]提出的GRU-Attention 注意力機制模型進行了對比實驗,預測結果與真實值的對比如圖9 所示,模型預測的評價指標如表4 所示。
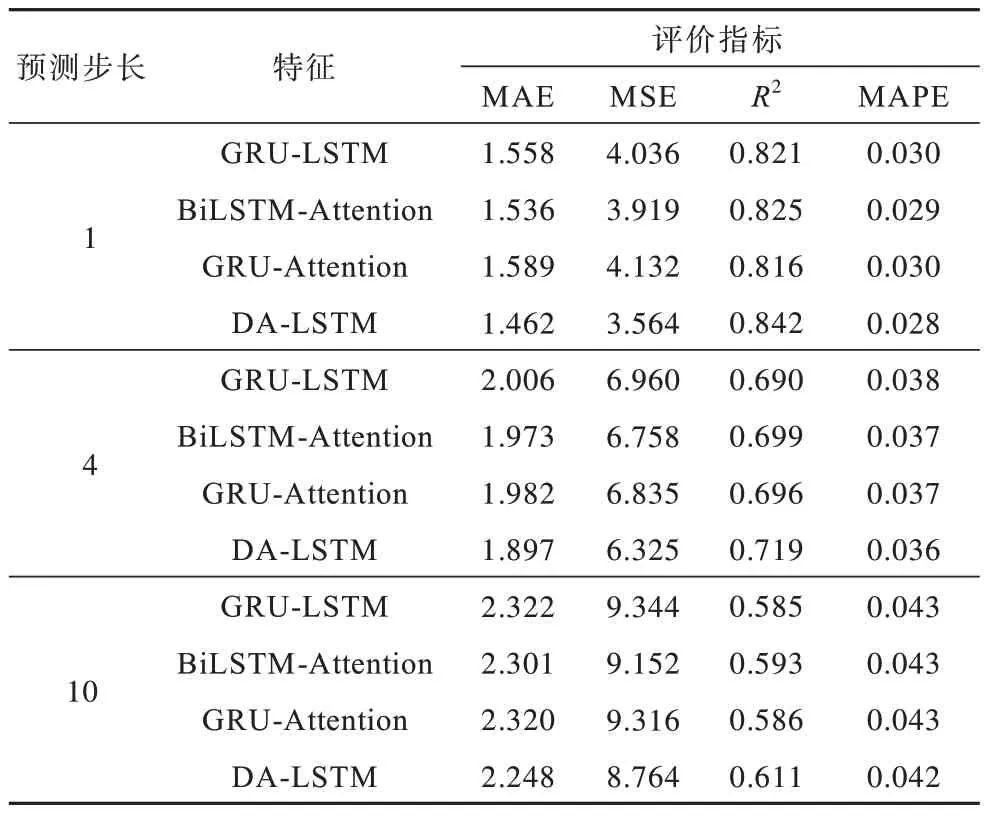
表4 各模型評價標準對比Table 4 Comparison evaluation criteria of each models
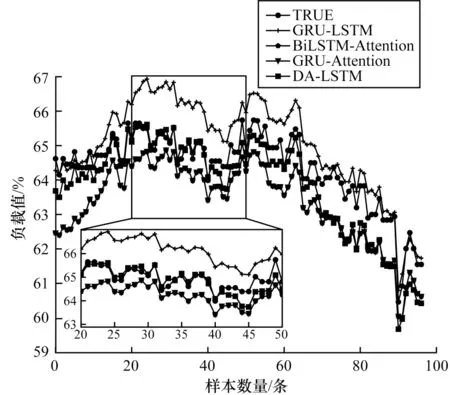
圖9 各模型預測結果對比Fig.9 Comparison of prediction results of each models
從 圖9 和 表4 可以看出,GRU-LSTM 組合模型為提高模型的訓練速度,在LSTM 的基礎上與GRU 進行組合,BiLSTM-Attention 將注意力機制融合到BiLSTM 中,增強了時序數據的訓練權重,GRU-Attention 組合模型將GRU 與注意力機制融合,得到了較好的效果。但以上模型均沒有考慮特征權重對模型預測的影響,本文提出的雙重注意力機制模型在訓練時自適應地對時序信息和特征信息進行捕獲,預測結果更接近于真實值。與其他3 個組合模型相比,本文模型MEA 分別降低了6.5%、5.0%和8.6%,MSE 分別降低了13.2%、9.9%和15.9%,充分說明本文模型具有更好的準確性。
4 結束語
針對服務器單一特征無法準確體現服務器的負載情況,本文提出使用客觀賦權法對CPU 利用率和內存利用率等特征進行加權求和計算出服務器當前的負載值。通過對負載值的預測可以更加有效地了解服務器下一時刻的負載情況,通過引入特征注意力機制和時序注意力機制,提高網絡對負載信息的時序信息和特征信息的重視程度。實驗結果表明,本文所提出的雙重注意力機制網絡能夠有效地提高網絡單步預測和多步預測的準確性。但由于本文模型引入了注意力機制,增加了網絡的訓練時間,減緩了模型的擬合速度,下一步將對模型的結構進行優化,以達到減少訓練時間、提高網絡模型訓練速度的目的。另外,可以尋找模型的最優參數,提高網絡預測的準確性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
文苑(2018年21期)2018-11-09 01:23:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛生(2015年9期)2015-11-10 03:11:12
中國衛生(2014年3期)2014-11-12 13:18:12
