結合向量化方法與掩碼機制的術語干預翻譯模型
2023-11-18 03:32:16張金鵬段湘煜
計算機工程 2023年11期
張金鵬,段湘煜
(蘇州大學 計算機科學與技術學院,江蘇 蘇州 215000)
0 概述
神經機器翻譯(Neural Machine Translation,NMT)是自然語言處理領域的一項重要且具有挑戰性的任務[1]。隨著信息技術的不斷發展,電商、醫藥、新能源等領域涌現出大量行業術語[2-4],錯誤的術語翻譯可能會嚴重影響用戶體驗,這便要求機器翻譯系統具備更高的準確性與可控性。在統計翻譯年代,基于短語的機器翻譯系統[5]可以對系統輸出進行良好的控制,實現對指定單詞的強制翻譯[6],然而這種強制干預不適用于神經機器翻譯。
2022 年,WANG 等[7]借助向量化方法將詞典知識顯式地融入模型控制術語翻譯。雖然向量化方法為術語干預提供了新的范式,但其只考慮了如何將術語信息與句子信息融合,并沒有強調模型對術語信息的關注。在向量化方法中,目標術語的翻譯主要依據兩部分信息:一是源端句子信息,包含源端術語及其上下文;二是人為給定的術語約束,包含正確的術語翻譯。本文建立一種結合向量化方法與掩碼機制的術語干預機器翻譯模型,在訓練階段借助掩碼機制對源端術語加以屏蔽,以增強編碼器與解碼器對約束信息的關注,同時在推理階段借助掩碼機制優化術語干預輸出層的概率分布,最終達到提升術語翻譯準確率的目的。
1 相關工作
目前,主流的術語干預方法可以分為兩類:一類是對傳統的束搜索加以改進,引入強制解碼策略;另一類是使用數據增強方法調整模型輸入。
1.1 基于強制解碼的術語干預方法
網格束搜索(GBS)[8]是典型的基于強制解碼的術語干預方法,相較于傳統束搜索,網格束搜索為術語額外增加一個維度,用于標記已經生成的術語單詞數量,從而將束搜索拓展為網格的形式。假設術語單詞數為C,GBS 將維護C+1 組用于存儲滿足不同術語單詞數的候選譯文,最后從第C+1 組(術語全部生成)的候選譯文中選取得分最高的句子作為解碼輸出。由于網格束搜索增加了額外的維度,解碼復雜度隨術語單詞數量線性增長。為了克服上述問題,POST 等[9]提出使用動態束分配(DBA)的策略改進GBS。不同于GBS,DBA 控制解碼過程中波束的總量不變,并采用動態分配的策略將波束分配給C+1 組,保證解碼復雜度與術語單詞數無關。HU 等[10]進一步提出借助向量數組優化的動態束分配策略(VDBA),使DBA 能夠以批處理方式運行,優化了解碼效率。雖然此類方法通過對束搜索加以改進,確保指定術語出現在譯文中,但其愈發繁瑣的解碼過程使其明顯慢于傳統束搜索解碼。
1.2 基于數據增強的術語干預方法
目前,工業界采用的術語干預方法主要基于數據增強技術,原因在于采用數據增強技術無需修改模型結構,只需使用標準的束搜索即可達到一定程度的術語干預效果,且解碼速度快。SONG 等[11]提出使用字符替換的方法(Code-Switching)進行術語干預,具體做法是借助先驗的術語詞典,將源句中的源端術語替換為目標端術語,用于翻譯模型訓練。在推理階段,人們需要提前將源句中的術語替換為指定的翻譯再進行解碼。DINU 等[12]提出保留源端術語并在其右側拼接目標術語的方式進行數據增強。在WMT2021 英中術語翻譯任務中,WANG 等[13]對此類方法做進一步拓展,將源端術語使用特殊標記替換,并在該標記的右側指明源端術語及其翻譯(TermMind)。目前,數據增強方法最主要的缺點在于術語干預的成功率有限,說明只改變訓練數據而不調整模型結構難以到達理想的干預效果。
2 融合向量化方法與掩碼機制的術語干預機器翻譯模型
采用Transformer[14]作為機器翻譯模型的基礎結構(Vanilla),模型由編碼器、解碼器以及輸出層構成,Transformer 借助編碼器與解碼器將具體的單詞或者子詞轉化為向量化表示,并借助輸出層將解碼器的輸出向量轉化為詞表概率。
2.1 基于向量化方法的術語干預機制
基于向量化方法的術語干預機器翻譯模型如圖1 所示。對比傳統的Transformer 模型,基于向量化方法的術語干預模型存在以下改動:1)借助詞嵌入層以及多頭注意力機制將源端術語以及目標端術語向量化(圖1 虛線區域);2)將這些攜帶術語信息的特征向量融入翻譯模型的編碼器與解碼器(分別對應圖1 中編碼器融合術語信息以及解碼器融合術語信息);3)引入額外的輸出概率分布提高術語生成的準確率(對應圖1 中術語干預輸出層)。

圖1 基于向量化方法的術語干預機器翻譯模型Fig.1 Terminology intervention machine translation model based on vectorization method
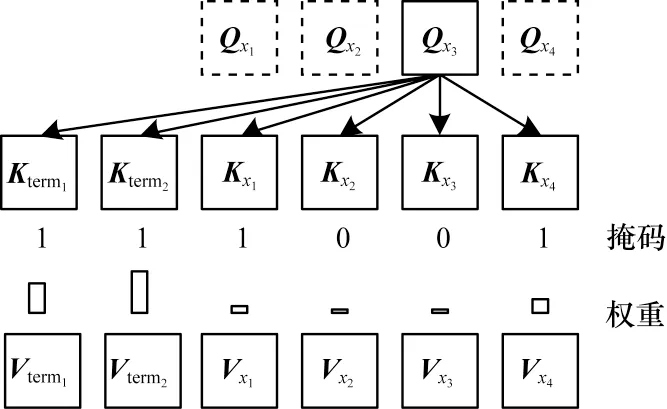
圖2 結合掩碼機制與編碼器的自注意力機制Fig.2 Self-attention mechanism combining mask mechanism and encoder
2.1.1 術語向量化
向量化干預方法首先將源端術語與目標端術語分別轉化為額外的鍵Kterm與值Vterm,以便將術語信息融入編碼器的自注意力機制以及解碼器的編碼器-解碼器注意力機制。使用(S,T)表示一組術語對在經過詞向量層與位置編碼層后得到的向量表示。在通常情況下,源端術語與目標端術語的長度不一致,在形態上不對齊[15]。在這種情況下,將S與T分別作為鍵與值是不可行的,需要額外增加一層多頭注意力使得T與S形態一致,如式(1)所示:
其中:Kterm與Vterm分別表示一組術語的鍵與值,且Kterm與Vterm?Rd×|s|,d與|s|分別表示模型的詞嵌入維度以及該組術語中源端術語所包含的單詞數量,Vterm可以被看作是向量T在源端長度上的重新分配。事實上,由于一組平行句對中包含不止一組術語,因此Kterm與Vterm由N組術語鍵值拼接得到,如式(2)所示:
2.1.2 編碼器融合術語信息的過程
在Transformer 中,編碼器由詞嵌入層以及6 層編碼層構成,編碼層的自注意力機制由多頭注意力網絡構成,用于學習文本的上下文表示。每層的自注意力機制如式(3)所示:
其中:Hout表示自注意力機制的輸出,Hout?Rd×|x|;Henc表示編碼層的輸入,Henc?Rd×|x|,|x|表示編碼層輸入的序列長度。
由于編碼器的每一層都包含不同級別的語義信息[16],因此應確保術語信息融入編碼器的每一層。在編碼端,向量化方法借助自注意力機制融合Kterm與Vterm。在每一層執行自注意力過程前,使用兩層適應網絡將包含術語信息的鍵值與原始輸入Henc拼接,確保編碼器在自注意力過程中可以顯式地融合術語信息,如式(4)所示,以此達到術語干預的目的。
其中:adapt 表示包含兩層線性變換以及ReLU 激活函數的適應網絡,該適應網絡對所有編碼層是通用的;Kunion與Vunion分別表示引入術語干預的鍵與值,Kunion和Vunion?Rd×(|x|+|s|),|s|表示所有源端術語的長度之和。
在編碼層中,融合術語信息的自注意力機制如式(5)所示:
2.1.3 解碼器融合術語信息的過程
將術語信息融入解碼器的方式與編碼器類似,區別為選取編碼器-解碼器注意力機制融合術語信息。在Transformer 中,解碼器由詞嵌入層以及6 層解碼層組成,解碼層由自注意力組件、編碼器-解碼器注意力組件以及前向網絡構成。每一層的編碼器-解碼器注意力機制如式(6)所示:
其中:Henc表示編碼端提供的輸入;Hdec表示解碼端自注意力組件提供的輸入,Hdec?Rd×|y|,|y|表示解碼器輸入的長度。
對于每一層的編碼器-解碼器注意力機制,融合術語信息的鍵值如式(7)所示:
其中:Kunion和Vunion?Rd×(|y|+|s|),與編碼器融合術語信息類似,解碼器借助adapt 將術語特征向量與該注意力機制的原始輸入Henc進行拼接,得到新的鍵Kunion與值Vunion。在融合術語信息后,編碼器-解碼器注意力機制如式(8)所示:
2.1.4 術語干預輸出層
如圖1 所示,向量化方法借助術語干預輸出層進一步提升術語翻譯準確率。在Transformer 中,輸出層用來將解碼器最后一層的輸出轉化為子詞級別的概率。使用hk?Rd×1表示解碼器在k時刻的輸出,使用s與t表示人為給定的術語對,則Transformer 模型的輸出如式(9)所示:
其 中:W?Rd×|υ|表示輸 出嵌入矩陣,|υ|表示詞 表大小。
為了進一步借助術語信息干預文本生成,受控制文本生成[17]的啟發,在輸出層引入額外的概率分布對輸出分布進行調整,如式(10)所示:
其中:wy表示子詞y的詞向量;t表示所有目標術語子詞集合。
在得到Pplug后,使用門控單元控制Pplug的干預力度,門控單元如式(11)所示:
其中:W1和W2?Rd×d;W3?R2d×1。
模型借助3 個可訓練的線性變換生成干預權重g,最終的輸出概率如式(12)所示:
2.2 掩碼機制
掩碼機制被廣泛應用于各項任務中,用于屏蔽無關信息或者對原數據加噪,例如自回歸生成模型在解碼器中借助掩碼操作屏蔽后續文本,在各項任務中對填充符進行處理,以及在掩碼語言模型中直接使用掩碼符號對一定比例的原文本進行替換。此外,ReLU 激活函數以及丟棄機制(Dropout)都被認為是一種掩碼操作。本文在訓練階段借助掩碼機制屏蔽源端術語,增強模型編碼器與解碼器對約束信息的關注;在解碼階段引入掩碼機制,改善輸出層的概率分布,進一步提升術語翻譯準確率。
2.2.1 結合掩碼機制的編碼器
向量化干預方法將術語信息直接拼接到編碼器自注意力機制的鍵值中,當自注意力機制進行查詢操作時,可以顯式地看到兩部分信息,分別是人為給定的術語信息以及源端句子信息,源端句子又可以分為源端術語和源端術語上下文兩部分。
2.2.2 結合掩碼機制的解碼器
掩碼機制融入解碼器的方式與編碼器類似。向量化干預方法將術語信息直接拼接到編碼器-解碼器注意力機制的鍵值中,然后根據解碼端提供的查詢信息對編碼器的鍵值進行注意力操作。為了增強模型解碼器對人為給定的約束信息的關注,如圖3所示,在編碼器-解碼器注意力機制中利用掩碼機制屏蔽源端術語對應的鍵值。

圖3 結合掩碼機制的編碼器-解碼器注意力機制Fig.3 Attention mechanism of encoder-decoder combining mask mechanism
2.2.3 結合掩碼機制的輸出層
在解碼階段,基于向量化方法的干預機制在輸出層中引入額外的概率分布Pplug,然而Pplug是面向所有術語子詞計算的,忽視了每個術語的實際翻譯情況。例如“傳染源”這個術語,經過子詞切分后為“傳染@@源”,術語干預輸出層會額外增大“傳染@@”以及“源”兩個子詞的輸出概率。這一做法并沒有考慮該術語的實際翻譯情況,假設模型在推理階段未解碼出“傳染@@”,此時模型無須增大“源”的輸出概率,否則可能導致模型提前生成“源”。
簡而言之,當術語的第i個子詞未被譯出時,Pplug不應該包括第i+1 個子詞及其之后的子詞。針對該問題,對Pplug進行改進,使用tnext替換式(10)中的t,如式(13)所示,tnext表示每個術語下一個待生成子詞的集合,并非所有未生成的子詞的集合。借助掩碼數組進行維護,將每個術語下一個待生成子詞的掩碼置為1,其余置為0,并根據術語的解碼情況進行更新。
3 實驗與結果分析
3.1 數據集
選擇德英與英中語項進行實驗。對于德英任務,使用WMT2014 德英語料作為訓練集,共包含447 萬句平 行語料,并借助fast-align[18]對 齊,使 用文獻[19]中的500 句包含人工對齊標注的平行語料作為測試集。對于德英訓練集和測試集,也采用文獻[19]中的術語抽取腳本依據對齊標注抽取術語。此外,由于德英測試集與訓練集存在部分重疊,因此將這部分重疊句子從測試集中移除。對于英中翻譯任務,使用語料隨機抽取腳本,從WMT2021 英中數據集中抽取450 萬句平行語料用于訓練,訓練集的術語抽取方法與WMT2014 德英數據集一致。采用WMT2021 英中術語翻譯任務提供的2 000 句包含術語標注的平行語料作為測試集。德英與英中實驗均采用子詞切分方法[20]構建源端與目標端共享的詞表,構建時迭代操作數設置為40 000。
3.2 實驗環境與模型參數
所提翻譯模型的執行根據Fairseq 工具庫[21],所有模型的訓練均在8 張顯存為16 GB 的英偉達P100-PCIe 顯卡上進行。選取編碼器與解碼器的層數均為6,將隱狀態維度為512 的Transformer 模型作為基礎架構,每個多頭注意力機制包含8 個獨立的注意力頭。在訓練階段,德英與英中任務均迭代10 萬步,采用Warm-up 學習策略,學習率的初始值為0.000 7,最大值為0.001,并采用Adam 更新策略,Dropout 的概率設置為0.1。在訓練階段,參考掩碼語言模型的設計[22],借助掩碼機制隨機屏蔽15%的源端術語。
3.3 對比模型選取
對比的術語干預方法主要分為兩類:一是基于強制解碼策略的方法;二是基于數據增強的方法。此外,也與未采用掩碼機制的基于原始向量化方法的Code-Switching 翻譯模型進行比較。為了保證對比公平,所有基線均采用與本文術語干預方法一致的Transformer 結構,并保持一致的學習策略進行訓練,直至收斂。在測試環節,為所有術語干預方法提供相同的術語約束。對比的機器翻譯模型具體描述如下:
1)Vanilla。未采用任何術語干預方法的基線Transformer 翻譯模型。
2)VDBA。在推理階段采用向量化的動態束分配策略,并使用前綴樹對DBA 進行優化,能以批處理方式執行解碼并具有強大的術語干預能力。
3)Code-Switching。將源句中的術語直接替換為目標端術語作為輸入,同時使用指針網絡進一步優化。
4)TermMind。將源句中的術語替換為指定的特殊標記,并將目標端術語與源端術語拼接在特殊標記的右側,在WMT2021 英中術語翻譯任務中排名第一。
5)VecConstNMT。基于向量化方法的術語干預翻譯模型,未引入掩碼機制。
3.4 評價指標
評價指標主要包括:1)BLEU 得分,使用sacreBLEU[23]計算;2)復制成功率(CSR),從單詞級別上計算術語翻譯準確率;3)術語評估矩陣[24],包括正確匹配率(EM)、窗口重疊度量(Window2和Window3)以及偏向術語的翻譯編輯率(TERm)[25-26]。EM 用來衡量在譯文中成功匹配的源端術語占總源端術語的比例,不同于CSR,EM 從短語級別上計算術語生成的比例,是本文最重要的評價指標。窗口重疊度量用來衡量目標術語在譯文中的位置準確率。TERm 計算術語單詞部分的編輯損失。
3.5 模型性能
各模型在WMT2014 德英與WMT2021 英中數據集上的實驗結果如表1 所示。對于術語翻譯準確率,VDBA 具有最高的單詞級別準確率(CSR)和短語級別準確率(EM),但該模型并不能更深層次地融合術語信息,且VDBA 在BLEU 得分以及窗口級別的準確率等指標上表現并不理想。基于術語數據增強的Code-Switching 以及TermMind 具有較高的BLEU 得分,但是術語干預能力較弱,CSR 與EM 低于其他模型。本文提出的結合向量化方法與掩碼機制的干預機器翻譯模型在提升術語翻譯準確率的同時,進一步提升了譯文的整體翻譯質量,與Code-Switching 相比,在WMT2014 德英數據集上EM 指標提升了9.27 個百分點,在WMT2021 英中數據集上EM 指標提升了2.95 個百分點,且sacreBLEU提升了0.8 和0.4 個百分點,Window2、Window3 以及TERm 等指標也有所提升。

表1 各模型在WMT2014 德英與WMT2021 英中數據集上的實驗結果Table 1 Experimental result of various models on the WMT2014 German-English and WMT2021 English-Chinese datasets %
3.6 消融實驗
消融實驗結果如表2 所示,分別移除編碼器、解碼器以及輸出層的掩碼機制以測試其對模型性能的影響。由表2 可以看出:移除編碼器的掩碼機制會顯著降低模型的sacreBLEU;輸出層的掩碼機制減少了Pplug的候選,因此移除后會使sacreBLEU 略有提升,但EM 下降明顯;解碼器掩碼機制對模型性能的影響介于編碼器與輸出層之間。
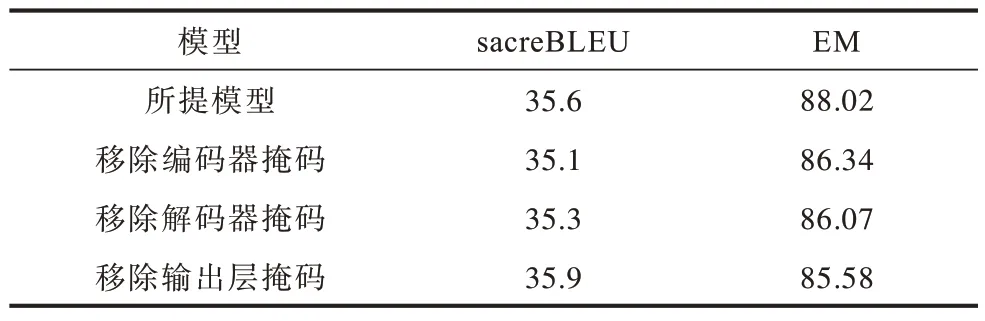
表2 消融實驗結果Table 2 Results of ablation experiments %
3.7 短語級別干預
掩碼機制的引入能大幅度提升模型對于短語級別術語的翻譯能力。按照術語長度將測試集分為4 個子集,表3 對比了VecConstNMT 與所提模型的4 個子集的術語翻譯結果。由表3 可以看出,CSR 與EM 之間存在較大的差距,這一差距隨術語長度的增加而增加。這說明了向量化干預方法雖然可以將術語在單詞級別翻譯出來,但無法保證這些單詞以正確的順序連續譯出,保證術語的完整翻譯。引入掩碼機制可顯著提高長術語的EM 指標值,縮小CSR與EM 之間的差距。
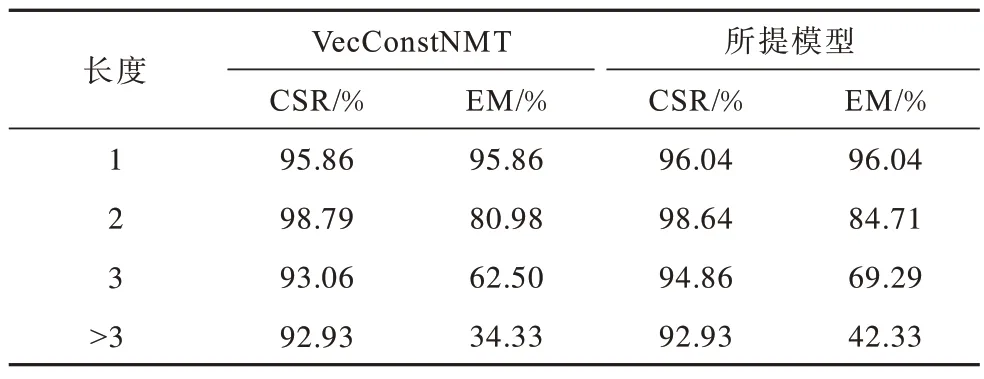
表3 不同長度的術語翻譯結果Table 3 Results of terms with different lengths
3.8 解碼速度
各模型的解碼速度如表4 所示。由表4 可以看出:Vanilla 未使用任何術語干預方法,解碼速度最快;VDBA 在推理階段加以約束,雖然具備最高的術語翻譯準確率,但解碼速度極慢,尤其是批處理解碼,在大部分實際場景中不適用;所提模型只需在輸出層跟蹤每個術語的翻譯進度,因此相比于Vec ConstNMT 模型,解碼速度幾乎不受影響。
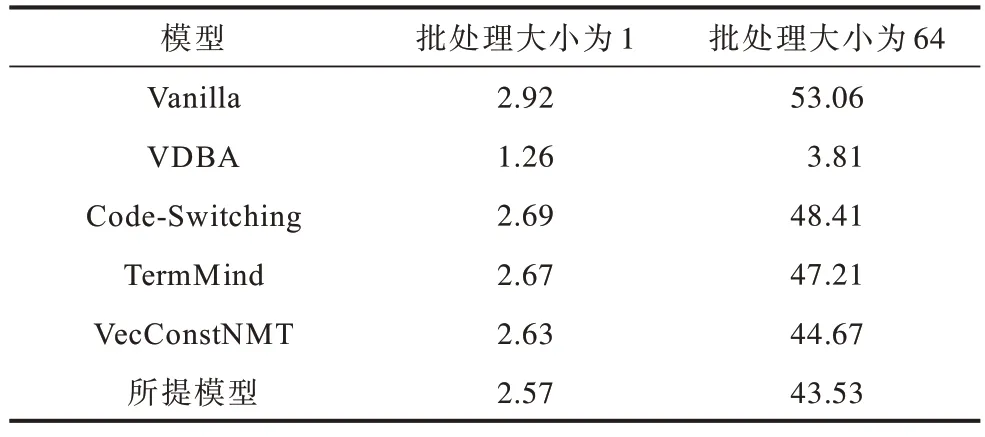
表4 各模型的解碼速度對比Table 4 Comparison of decoding speed of various models 單位:(句?s-1)
4 結束語
目前,基于數據增強與強制解碼的術語干預方法存在目標術語翻譯準確率低以及解碼速度慢的問題,限制了這些方法在實際場景中的應用。受向量化方法的啟發,本文構建基于向量化方法與掩碼機制的術語干預機器翻譯模型,借助掩碼機制增強模型對向量化信息的關注及優化輸出層的概率分布。實驗結果表明,所提模型在保證解碼速度的同時顯著提升了術語翻譯的準確率,并且提高了譯文的整體翻譯質量。術語翻譯任務建立在人為給定的術語翻譯完全正確這一基礎上,但在實際場景中術語對往往存在一對多的情況,并且對于每句句子中的每個術語,通過人工注釋得到最合適的目標翻譯顯然是費時費力的。后續將針對上述問題做進一步研究,根據特定上下文,使模型從候選術語中自動識別并翻譯出正確的目標術語。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年9期)2015-11-10 03:11:12
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國衛生(2014年3期)2014-11-12 13:18:12
