生成式智能出版:知識生成原理、沿革與啟迪
2023-11-19 22:50:33張新新
編輯之友 2023年11期
【摘要】文章基于人工智能生成知識的視角,分析了智慧驅動型和數據驅動型兩種知識生成的原理,論述了個體生產知識、專業生產知識、大眾生產知識以及人工智能生成知識的沿革歷程,最后提出知識生成格局的變化對出版業、出版本質及出版學研究范圍拓展三個方面的價值思考。
【關鍵詞】AIGC 生成式智能出版 ChatGPT 數字出版 數據科學 微軟小冰
【中圖分類號】G230 【文獻標識碼】A 【文章編號】1003-6687(2023)11-036-09
【DOI】10.13786/j.cnki.cn14-1066/g2.2023.11.005
生成式人工智能技術的出現引起社會各行各業的熱議和思考,在出版業內部,將引發編校印發各環節革新;[1]在出版業外部,將促進出版大數據、智能知識服務、出版領域智能決策機器人、生成式智能出版物以及元宇宙出版等新產品、新業態和新模式的涌現。[2]此外,生成式人工智能技術將推動出版業前端——知識生成方式發生革命性變化,把人類生成知識推至人機協同生成知識的新層面。
一、知識生成原理闡釋:以智慧為中心與以數據為中心
出版是知識生產和表達的產業,知識生產是出版業的前提和基礎。所謂知識,《現代漢語詞典》有兩種解釋:第一種是指人們在社會實踐中所獲得的認識和經驗的總和;第二種是指學術、文化或學問,如知識面、知識分子等。本文以第一種概念為立論之基,探討知識的生成理路。
人類社會發展至今,知識生成包含智慧驅動型和數據驅動型兩種類型。智慧驅動型知識生成方式,是指知識生成是在人的智慧主導下所形成的知識創造。知識生成最初的原動力源于個體,即“個體通過直接的‘實踐經驗積累隱性知識”。[3]隱性知識無法通過文字、語言、圖表或符號來明確表述,也難以進行邏輯說明,往往是人類非語言智力活動的成果,如非正式的、難以表達的經驗、技巧、技能和訣竅等技能類隱性知識,再如直覺、感悟、洞察力、心智模式、團隊默契、企業文化等認識類隱性知識。隱性知識生成以后,大致形成了社會化、外顯化、組合化、內隱化四種知識轉化模式。[4]社會化,強調隱性知識的傳播過程,即通過傳授、觀察、模仿等社會化方式實現個體與個體之間的隱性知識傳播,如出版業中的“傳幫帶”學徒機制,新編輯通過模仿、學習和請教等方式學會老編輯的技巧和經驗。外顯化,是隱性知識轉化為顯性知識的過程。顯性知識是指可以通過文字、圖表、公式等進行完整表述的知識,隱性知識顯性化的呈現方式包括概念、假設、模式、類比或比喻等。組合化,是指顯性知識通過增加、關聯、組合、分類和整理等形式向系統知識轉化的過程。內隱化,是指顯性知識的隱性化過程,即顯性知識體現于隱性知識之中,生成應用性、操作性知識,如“事上練”“干中學”較好地形容了內隱化過程。智慧驅動型的知識生成是目前占據主流地位的知識生成方式,構成了目前出版業所生產和傳播的主流知識。知識轉化之后,則進入知識論證或驗證階段。論證環節是指人們通過預測或實驗,能夠證偽或證明該知識環節決定著知識的合規律性和知識質量。在知識體系構建的過程中,論證環節主要通過知識融合方式實現:為解決知識質量參差不齊、基于不同數據源的知識重復等問題,進行知識融合;對來自不同數據源的知識基于同一框架規范進行異構數據整合、消歧,由實體對齊和實體消歧組成。
數據驅動型知識生成方式,是指基于海量數據的知識生產原料,從中挖掘出新規律、新知識,實現數據、信息走向知識生成的使命。“以數據為關鍵原料的知識生產范式的出現與知識形態的演變,意味著新的認識論或知識觀正在悄然形成。”[3]數據驅動型知識生成方式離不開數據、算法和算力要素的支持。在數據方面,“機器學習的數據是影響創作質量的重要因素,掌握的數據越多,設定的程序越清晰,他們的知識創作會越順利”。[5]相反,數據積累偏少、數據質量不高或需高度創造性寫作的領域,[6]知識智能生成就無法實現。就新聞機器人而言,越是天氣、地震預報及金融、體育等數據繁多、結構化和標準化水平較高(“干凈”數據)的領域,[7]就越容易開發出實用價值突出的自然語言自動生成系統;就生成型預訓練聊天機器人而言,ChatGPT之所以能夠取得突破性進展,極為關鍵的因素是其從網頁、WebText2、圖書、維基百科等渠道搜集而來的3 000億單詞語料,經過數據清理后形成超過1 750億的巨量無標注文本數據;[8]就寫作機器人而言,微軟小冰在出版《陽光失了玻璃窗》詩集之前,就已完成自1920年以來519位詩人的現代詩數據訓練,并借助深度神經網絡等技術,在訓練1萬次之后,具備了創作現代詩歌的能力。
在算法方面,機器人根據語法、句法規則,或者大語言模型,實現半自動或全自動的自然語言生成,形成符合人類認知、需求和價值觀的內容。不過在具體的算法應用方面尚有較大差異,如微軟小冰采用基于規則的系統和機器學習技術,而ChatGPT則基于海量語料庫以及人類的反饋強化學習算法。
在算力方面,算力水平的高低、強弱決定著算法作用的發揮和數據處理能力的大小。通俗理解,算力相當于人的大腦在觀察、感知、決策、控制等方面的反應速度。ChatGPT能夠成為AI發展的里程碑式成果,在知識生成方面實現巨大跨越,離不開超強算力的支撐和加持。ChatGPT使用的GPT3.5模型在微軟云計算服務Azure AI的超算基礎設施上訓練,總算力消耗約為3 640PF-days(按每秒一千萬億次計算,須運行3 640天);[9]而小冰公司與微軟中國聯手推出的人工智能解決方案,則將微軟智能云Azure作為云計算運營平臺,可以提供大規模的計算資源支持。
2021年,Haiko等人從數據科學視角提出了數據智能和分析的知識創造過程模型,將人的智慧和智能化技術進行了有機融合。[10]該模型分為擴大個體知識、分享隱性知識、業務概念(個體通過分享擴充知識以增強業務內容理解能力)、數據理解、數據準備(數據加工、清洗、整合等)、數據建模、評估論證、知識生成(知識網絡化)、模型應用以及部署(新知識、新模型的應用)階段。也有國內學者進一步提煉為“業務理解與概念化、數據準備與建模、知識生成與模型應用”[3]三個階段。由此看來,人類智慧生產知識和數據生成知識的融合趨勢日益明顯,融為一體、合而為一的知識生成新格局正在加速形成。
二、知識生成進階分析:從個體智慧到人工智能
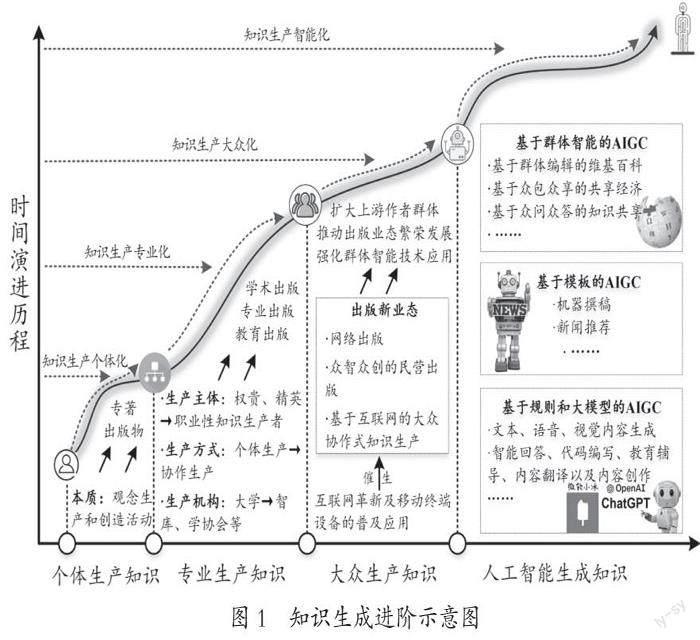
ChatGPT的火出圈,也推動著知識生成從個體生產知識、專業生產知識、大眾生產知識走向人工智能生成知識,進而推動人機協同生成知識新格局的出現,知識生成進階見下頁圖1。
1. 個體生產知識
“人類知識的兩大枝干,它們也許來自某種共同但不為我們所知的根源,這就是感性和理性。”[11]知識是如何產生的?關于這個問題,古今中外先賢們孜孜不倦地追求并試圖給出盡可能合理的答案,由此形成了經驗論和唯理論兩種認知觀。以笛卡爾、斯賓諾莎和萊布尼茨等人為代表的唯理論派認為,知識的源泉是“天賦觀念”,唯有經過演繹和推理所獲得的理性知識,方是可靠的知識,因此崇尚演繹法;而貝克萊、休謨和馬赫等則認為,知識的源泉是經驗感知,知識是對客觀世界的反映,人們通過感官對世界進行觀察歸納和總結,從而形成知識,故崇尚歸納法。
此外,力圖綜合唯理論和經驗論的康德則以感知經驗為基礎,提出先驗想象力的概念,以“靈魂不可或缺的功能”[12]試圖找尋二者之間的平衡點,即想象力是感情和理性的中介,是先天知識的奠基力量。“科學始于問題”是卡爾·波普爾提出的著名觀點,[13]強調的是問題促使人們探索、思考,并通過科學嚴謹的求證過程獲得答案,最終形成有關問題的科學知識。[14]應該說,“科學始于問題”的知識生產方式,圍繞著問題的提出、猜想假設、證偽排除,最終提出新問題,同樣綜合了唯理論和經驗論,并強調實驗法對科學知識發現的重要價值。
個體生產知識本質上是觀念生產和創造活動,是個體基于語言和心智,對陌生事物的概念、屬性、特征、程序、結構、邏輯等進行探索的過程。基于個體生產的知識,推動著社會從蒙昧樸素走向科學理性,對科學和社會發展有著不可磨滅的貢獻。[5]個體生產知識古已有之,是出版和出版業發展的原動力。如孔子以“垂世立教”的思想“書其重者”,選擇重要的學術著作進行整理、刪節、補充、編次和闡述,編訂“六經”,歸納總結了夏商周三代文化,實現了中華文化的傳播與傳承,且孔子之于《論語》的原創性知識生產影響深遠,迄今仍然是出版機構出版和發行的暢銷品牌。個體生產知識對出版業的影響還體現在專著出版這一出版業態上。在學術出版或專業出版領域,專著是學術成果的最主要體現,也是個體生產知識的智慧結晶,是作者圍繞特定選題所進行的系統、專深的知識生產。
2. 專業生產知識
專業生產知識是指由專門的組織或個人負責知識生產,是以知識生產為職業活動的過程。“專業組織所生產的文化形式開始決定著其他個體文化形式的合法性、合理性與發展方向,壟斷著對宇宙、社會、人生以及神的存在等問題的解釋權,影響著人類的終極關懷。”[15]
在我國歷史上,西周時期就已出現專業化的知識生產組織,《禮記·王制》記載:“天子命之教然后為學。小學在公宮南之左,大學在郊。天子曰辟雍,諸侯曰泮宮。”天子的大學叫辟雍,諸侯的大學叫泮宮。春秋戰國時期,諸子百家爭鳴,分別生產、傳播和傳世了各學派的知識和理論。諸子書編纂有個鮮明特點,即采用語錄體,[16]由弟子門人根據老師生前言談內容編輯記錄而成。西漢時期,“興太學”,“以養天下之士”。作為專門傳授知識、研究學問的太學,開創于公元前124年,與西方的雅典大學、亞歷山大里亞大學同為世界上最古老的高等學校。[17]到唐朝初年,太學規模完備,盛極一時。唐朝和宋朝,太學和國子學同時存在,元明清則改設國子學或國子監。
西方出現的第一個培育思想的場所是公元前387年柏拉圖創立的阿加德米學園,被視作“雅典第一個永久性的高等教育機構”。[18]學園生產和教授體操、數學、音樂、法律等各門知識,以培養自由人格和探索萬物本源的能力。中世紀時期,沙龍成為上流社會和文人雅士生產和交流知識的重要場所,知識生產為上流精英和政府權威所壟斷。及至大學出現,符合要求的大學從業者成為職業化的知識生產者,與科研團隊在組織制度下從事知識生產,從而實現了個人知識向專業知識的跨越。而今,大學也不再是唯一的知識生產組織,學會、協會、實驗室、科技公司、創新智庫等越來越成為科研創新主體,擔任著生產和傳播知識的角色。
專業人士生產知識或精英群體生產知識,本質上還是個體生產知識,只不過依托專門化的知識生產組織,在知識探索、生產和傳播途徑上更加科學化、合理化和系統化。而專業組織生產知識或專業機構生產知識,一方面,使知識的生產者、擁有者由權貴階層、精英階層轉變為職業性知識生產者,只要該生產者具有專業組織標準,即可在制度內從事知識的協同生產和傳播;另一方面,個體生產知識模式轉變為協作生產知識模式,知識生產向著群體化、社會化、職業化、建制化、合理化的方向發展,在更大范圍內、更高水平上、更深程度上推動了人類社會的知識生產和傳播水平的提升。
以出版視角來審視,專業生產知識對出版業發展也產生了深刻而久遠的影響。首先,學術出版本身就是對學術成果進行編輯加工,面向學術群體進行傳播,以推動學術研究進步為宗旨。[19]學術出版得以誕生、發展與壯大,離不開專業生產內容模式的出現,得益于大學等專業組織生產和傳播知識的直接推動。其次,專業出版作為面向特定領域的職業群體所開展的法律、醫學、建筑等專業知識生產和傳播的業態,本身也是專業生產知識模式在出版業的體現,是專業生產和傳播知識的發展結果。最后,教育出版是以教材、教輔圖書、數字教育服務為主要產品的出版業態,以社會教育和知識傳播為主要目的。
3. 大眾生產知識
隨著互聯網時代的到來,網絡重構了社會形態,也成為新知識的提供方和沉淀池。為適應互聯網變革,“知識的創造者和應用者都要具有將知識轉化成電腦語言的工具和技巧”,[20]通過鍵盤、屏幕、網絡等新介質,人們在互聯網上生產、分發和共享數據、信息、知識,形成了新的思維方式、工作方式和生活方式。于是,用戶生產知識這一新的知識生產方式應運而生。
用戶生產知識在出版業有幾種典型的業態,在特定的發展階段,這些新業態的出現,進一步推動了出版業的可持續、高質量發展。第一,網絡出版。網絡出版相較于傳統的圖書出版,首先,作者身份由專業群體轉變為大眾網民,出版作者準入門檻降低,作者群體規模擴大;其次,出版的門檻實質性降低了,不像圖書出版需要嚴格的書號配給,網絡出版取得經營許可證后,具體的編號編碼由網絡出版企業自行開展;再次,網民大眾生產網絡文學、小說作品等,通過網絡出版的傳播,進一步發揮了數字出版產品的教誨、審美、倫理等價值,維護了社會和諧穩定。第二,眾智眾創的民營出版。民營文化公司的知識生產方式,較國有出版企業有較大不同:后者主要是借助外部作者的資源,進行知識的二次生產;而前者則大多圍繞特定領域、特定主題、特定知識點,組織包括自身隊伍在內的眾人智慧進行編創,是知識的一次生產,甚至許多出版產品的知識生產完全來自自身,如考研輔導讀物、中小學教輔讀物等。第三,基于互聯網的大眾協作式知識生產。基于互聯網的大眾協作式知識生產,如百度百科、維基百科、豆瓣小組等網絡平臺的知識產品,往往就特定的知識體系、知識點,面向全網征稿,符合一定標準和具備一定水平的網民,可以就相關詞條、相關作品進行內容編創,所完成的知識產品經過審校后可面向整個互聯網進行知識傳播。值得注意的是,這種生產方式,一方面,融匯了大眾集體的智慧,是智慧生產知識的模式;另一方面,也融合了智能化的數字技術,采取知識挖掘、數據驅動知識生成技術,因此是既屬于智慧驅動型也屬于數據驅動型的知識生產模式。
隨著5G技術的普及和推廣,互聯網門檻進一步降低,得益于移動互聯網終端設備的普及與通信寬帶提速降費等,用戶依然是互聯網內容的主要生產者和有力傳播者。[21]基于5G容量增強、海量終端、高速率以及低時延等技術優勢,大眾進行知識生產、制作、下載的高速度、即時化效果將進一步呈現,同時,將進一步面臨生產內容、生產知識的審核、把關等方面的挑戰。
于出版業發展而言,大眾生產知識模式的出現,一方面,擴大了上游的作者群體,使作者的范疇不再局限于專業人士和專業組織,進一步擴展到數量更多、范圍更廣、代表性更強的公民大眾;另一方面,大眾生產知識模式的豐富和發展,推動著大眾出版、民營出版的蓬勃發展,促進了網絡出版業態的繁榮壯大,也進一步強化了眾智眾創的群體智能技術在出版業的廣泛落地和應用。
4. 人工智能生成知識
前述個體生產知識、專業生產知識、大眾生產知識在各自的發展階段對知識生產、傳播和規律探索都起到了積極的推動作用,但是知識生產的主體始終局限于人的范疇。而人工智能生產知識則把知識生產主體由同質的個人、專業群體或專業組織擴展到異質的數據、算法、機器、人工智能。
其實,新型內容生產方式(AIGC)并非新事物,早在第二次人工智能浪潮(1976—2006年)時,專家系統就試圖通過“人機交互界面、知識庫、推理機、解釋器、綜合數據庫、知識獲取”[22]等部件,輸入某個領域的大量專家知識與經驗,模擬人類專家的推理思維,解決需要人類專家處理的復雜知識問題。專家系統依據知識庫,使用推理機所得出的結論,就具備了AIGC的雛形,具有了人工智能生成知識的意味。1976年,耶魯大學開啟了機器模擬人類寫作的先河,研發了全球首套故事寫作機器算法,支持撰寫簡訊等簡單文字內容。[6]
前些年的微軟小冰、新聞機器人、維基百科等都具備了人工智能生成內容的能力,只是ChatGPT優化對話語言模型出現以后,其超強的內容創作、智能回答、代碼編寫、內容翻譯、教育輔導等能力,使得AIGC由專業群體走向公民大眾、由特定行業走向社會的方方面面。維基百科、新聞機器人、微軟小冰、ChatGPT代表著四種不同人工智能生成內容、知識的技術路線。
(1)基于群體智能的AIGC。群體智能源于20世紀90年代人們對蜜蜂、螞蟻、魚、鳥等生物群體的觀察和研究。所謂群體智能,是指數量眾多的無智能或低智能的簡單個體聚集在一起組成群體,利用群體優勢通過相互間的分工合作表現出智能行為特性。[23]
群體智能作為新一代人工智能的重要方向,作為我國人工智能發展的重點領域,已是不爭的事實。在理論層面,繼自組織、間接通信以及群體智能系統的底層機制研究等涌現[24]之后,結構理論與組織方法、激勵機制與涌現機理、學習理論與方法、通用計算范式與模型,成為基于互聯網的群體智能理論體系重點突破的方向所在。在政策層面,國務院印發的《新一代人工智能發展規劃》明確規定了群體智能的基礎理論、關鍵共性技術、服務平臺以及應用場景,指出要開展群體智能的知識獲取與生成關鍵技術研究。在實踐層面,群體智能的應用場景廣泛,幾乎滲透到生活的各個方面,如基于群體編輯的維基百科、基于眾包眾享的共享經濟、基于眾問眾答的知識共享等,甚至包括“基于群智理念的出版流程協同再造”。[25]
維基百科是群體智能生成知識的典型產品,也是前述數據驅動型知識生產方式的經典案例。維基百科“通過大規模群體協作、非線性、去中心化、自下而上的群體智慧方法”,[26]實現了對結構化、半結構化數據源的知識抽取。一方面,抽取的結果形成了形式化的知識,如建筑、法律、醫學等領域本體;另一方面,生成了基于元數據的專題知識庫。這一過程的微觀層面可描述為,用戶以標簽(用戶隱性知識顯性化的結果)作為信息載體參與群體的交流和溝通,通過對信息資源的大量標注進行協作,從而形成群體知識;群體知識在推動個體智能提升的基礎上促進群體智能的涌現,從而再次鞏固群體知識形成的基礎。[27]在技術路線的歸結上,維基百科奉行的是人機物結合的群體智能2.0時代的眾包技術,[28]任務提出者運用互聯網聚集群體智慧,將任務發布在眾包平臺上供參加者選擇,任務提出者和參加者基于眾包平臺進行信息交流。
(2)基于模板的AIGC。就新聞資訊行業而言,機器撰稿、新聞推薦已不是新鮮事物。[29]新聞機器人本身是一種人工智能生成內容、生成知識的技術。國外有代表性的新聞機器人有美聯社的WordSmith、《華盛頓郵報》的Heliograf以及《紐約時報》的Blossom等;國內則有新華社的快筆小新、騰訊的Dreamwriter(夢幻寫手)、第一財經的DT稿王、《南方都市報》的小南、今日頭條的張小明、中國地震臺網的地震信息播報機器人等。
機器人撰稿核心技術主要是自然語言處理、數據挖掘、機器學習、知識圖譜、語音識別及計算機視覺等。作為自然語言生成系統,機器人撰稿的技術路線有模板式、抽取式和生成式三種。[30]抽取式撰稿的技術路線主要應用在文本自動摘要方面,即機器人從海量文本素材中篩選重要信息,進行二次加工,從原始新聞文本內容中快速抽取核心信息,生成文章摘要。生成式撰稿的技術路線則主要體現在基于大語言模型的AIGC,如ChatGPT。基于模板的機器人撰稿技術是迄今最普遍、最成熟的一種技術。其主要技術原理包括:首先,清洗和加工數據,建立海量的語料庫;其次,對海量語料庫進行訓練,形成深度學習模型,并通過語義分析、命名實體識別和情感分析等技術,準確抓取新聞事件的關鍵要素,[31]包括測量新聞性、敘事角度排序、匹配報道角度與數據事實(選擇故事點)等;最后,因事制宜選擇模板,篩選關鍵數據填入語言模板模型,[32]自動生成新聞稿件并基于自然語言進行潤色。早期的新聞機器人所生成的稿件,往往因為模板單一而可讀性不強、模板痕跡嚴重而為人詬病,但經過數十年的發展,各種新聞機器人的語言模板類型不斷豐富、數量不斷增加,基于不同模板生成的新聞適人化、可讀性程度不斷提升,已經達到難以區分是由人類撰寫還是由機器撰寫的程度。如Wordersmith自身擁有100多種報道類型、3億種新聞寫作模板,不同模板的語調、語氣和寫作風格都各有特色。新聞機器人生成的稿件,從枯燥無味、單調呆板變得更加生動、具有人情味,更加符合人類的學習、閱讀、思考和表達習慣。
此外,AI主播等新聞機器人在前述技術基礎之上,還運用了計算機視覺、語音合成等技術,基于真人表情、語音、唇形等特征進行建模,把文字信息轉化為音視頻的形式,實現新聞咨詢的音視頻播報和實時交流互動。
(3)基于規則的AIGC與基于大模型的AIGC。在ChatGPT出現以前,微軟小冰、微軟小娜等聊天機器人在內容、知識生成方面有著不俗的表現,一度是AIGC領域的佼佼者。但前者的到來并成為現象級事件,使得有必要分析和比較這兩種AIGC的技術原理和應用場景差異,以便對AIGC有更進一步的認知和理解。
2014年5月,微軟(亞洲)互聯網工程院正式宣告微軟小冰的誕生。微軟小冰是建立在情感計算框架基礎上,綜合運用算法、大數據和云計算,逐步進行代際升級并向EQ方向發展的完整的人工智能體系。[33]2021年9月,第九代微軟小冰發布,覆蓋中國、日本、印尼等多個國家的6.6億在線用戶、4.5億臺智能設備以及9億內容觀眾,涵蓋金融、地產、汽車、零售等多個垂直領域。
在內容生成方面,微軟小冰可以進行文本內容、語音內容以及視覺內容生成。在詩歌領域,2017年其與湛廬文化合作出版首部AI詩集《陽光失了玻璃窗》,2019年采取人機合作的方式出版首部由AI和人類共同創作的詩集《花是綠水的沉默》;在金融領域,建立國內規模第一的金融文本摘要平臺,為國內40%以上的個人投資者和90%以上的金融機構交易員提供金融知識服務,并構建了基于小冰AI生成的金融知識圖譜;在音樂領域,創作獨一無二的音樂曲目,并自主完成樂器選擇、編曲和歌詞創作,自主發布數十首逼近人類歌手演唱水平的單曲;在有聲讀物領域,構建CCP有聲讀物生產平臺并創造30多個角色化聲音,支持基于AI技術自動生成定制化的兒童有聲讀物,并擁有2 300多小時自主版權的非定制兒童有聲讀物,形成了國內規模較大的有聲讀物知識庫;在繪畫領域,通過學習400多年藝術史上的236位著名畫家的經驗,可在受到創作激勵時,獨立完成100%原創繪畫作品,并于2019年在中央美術學院舉辦個人畫展,于2020年在中信出版社出版繪畫作品集《或然世界:誰是人工智能畫家小冰》。此外,小冰在圖案設計、電臺節目和電視臺節目內容生成方面也都有著杰出的表現。
ChatGPT作為一款火爆2023年度的AI產品,其在智能回答、代碼編寫、教育輔導、內容翻譯以及內容創作方面的應用場景和表現,以及作用于出版業所形成的生成式智能出版場景,如出版大數據與大語言模型、升維發展的智能知識服務、智能決策的出版領域智能機器人、生成式智能出版物、元宇宙出版五類新業態,已有相關研究[1-2]加以介紹,此不贅言。
同樣是人工智能生成內容、生成知識的微軟小冰和ChatGPT,其相互之間的原理、場景和特征對比分析主要有以下幾方面。
在AI設定方面,小冰被設定為對話代理,用于社交平臺為用戶提供情感陪護,其已然成為全球范圍內承載交互量最大的人工智能系統,占全球交互總量60%以上。ChatGPT則優化對話語言模型,運用更為通用的大語言模型,可回答更廣闊范圍內的各種知識問題并執行各種自然語言處理任務。小冰的目標設定和功能設置上更多屬于情感智能的范疇,而ChatGPT則更多屬于認知智能的范疇。前者旨在賦予AI以類似于人的觀察、理解和生成各種情感特征的能力,產生類人情感并進行自然、親切、生動交互;后者則旨在賦予AI具備類似人的學習、理解、語言、推理、決策等高級智能,進行知識學習、邏輯推理、問題求解、形成知識圖譜或進行智能決策等。二者的共同點在于均集多項技能于一身,都具備了通用人工智能的若干屬性。
在算法方面,微軟小冰使用了基于規則的系統以及深度學習技術,即使用了預先定義的規則和規則引擎進行響應和交互,其主要過程包括:一是語義解析,對輸入的文本進行語義解析以理解關鍵信息和意圖;二是規則匹配,基于預定義規則和規則引擎來匹配輸入的語義和模式,如使用固定的模板;三是生成回復,匹配到相應的規則,根據規則的定義生成回復,回復的方式可以是簡單的文本替換,也可以基于模板填充;四是輸出和交互,把生成的回復反饋給用戶,作為對用戶輸入的回應。而ChatGPT則使用了基于人類反饋強化學習算法的Transformer架構以及自注意力機制(self-attention)。GPT是一種基于互聯網可用數據訓練的文本生成深度學習模型,采用了利用人類反饋中強化學習(Reinforcement Learning with Human Feedback,RLHF)算法,主要包括三個步驟:一是預訓練語言模型的訓練階段,旨在形成自然語言理解與生成上下文學習能力、復雜意圖理解能力以及特定受眾文本摘要能力等;二是打分模型訓練階段,旨在通過代碼微調和指令微調來評估模型輸出符合人類表現程度的優劣;三是基于強化學習的語言模型優化階段,旨在優化模型,支持生成思維鏈進行復雜推理,以提高ChatGPT的思考能力。自注意力機制,也是Transformer架構的核心技術之一,通過給予不同位置的元素不同的注意力權重,使得模型可以根據序列中元素之間的相關性加權組合信息。ChatGPT的Transformer架構則使用了多頭注意力機制,在不同的“頭”中分別計算注意力權重,以獲得更多顆細顆粒度的關注信息。[34]多注意力機制的使用,使得ChatGPT具有更卓越的處理長序列和捕捉長距離依賴關系的能力,更好地實現自然語言理解,能夠生成連貫的、高質量的文本內容。
在數據語料庫方面,微軟小冰側重于中文語境,集合了中國近7億用戶的社交數據、新聞和百科知識等,并精練為1 500萬條真實而有趣的語料庫(之后每天凈增 0.7%)。[34]ChatGPT的訓練語料或數據來源則主要是英語、法語等其他語境,大致有兩類:一是前文介紹過的超過1 750億的巨量無標注文本數據;[33]二是有標注文本數據,融入了由40名標注人員主導的、數萬高質量的、符合人類偏好的人工標注數據,“以獲得聽得懂人類語言、自身擁有判斷標準的LLM”。[8]
正是由于上述三方面的不同,微軟小冰和ChatGPT在知識生成方面各有特色:在輸出長度方面,微軟小冰輸出內容的長度和規模較ChatGPT顯得力有不逮,后者可以輸出數萬字的文本內容;在輸出模態方面,微軟小冰可支持輸出文本、圖片、表情符號、音頻、視頻等多種模態的知識,而ChatGPT則主要集中在文本模態領域,所生成的內容以文本為主;在輸出語言性質方面,微軟小冰主要面向中國客戶輸出中文數據、信息和知識,而ChatGPT則更多是基于英語、法語等非中文的語料庫進行內容生成;在適人化方面,由于微軟小冰的強交互性、情感智能定位以及專門針對中文用戶所進行的訓練和優化,其個性化理解和回應用戶需求、偏好的能力較強,具有較好的適人性,而ChatGPT作為通用的大語言模型,個性化和適應性方面則稍遜色;從知識生成的特點來看,微軟小冰所生成的知識在特定領域的內容會更加豐富和準確,而ChatGPT則能夠涵蓋更廣泛的主題和領域,針對用戶提問,生成范圍更廣、更為系統、更為專業的數據和知識。
三、知識生成價值芻議:從出版前端到出版本質
從知識生產的主體和時間節點來看,前述個體生產知識、專業生產知識、大眾生產知識以及人工智能生產知識,皆為知識的第一次生產,即由人類或人工智能所進行的知識的創新和創造;而出版行為、出版活動則屬于知識的第二次生產。那么,從知識生產方式來看出版學,能夠帶來哪些啟迪和思考?
1. 知識生成格局的變革,深刻影響出版業的發展
知識生成格局的變革,從智慧驅動到數據驅動,從人類生產知識到AI生產知識,將在很長一段時間內呈現出人機協作生成知識的新格局。人機協作生成知識格局涵蓋AI生產新聞、AI創作圖書、AI創作音樂、AI創造繪畫、AI生產有聲讀物等AI生成內容的各個領域,對出版業產生全方位的深刻影響。在出版產品方面,一系列的生成式智能出版物將陸續出現,如生成式智能出版物、生成式智能知識服務、出版專業大語言模型等。實踐中,世界頂級的法律、稅務知識服務商律商聯訊(LexisNexis)已于2023年5月推出了面向法律界的生成式智能知識服務平臺——Lexis+AI,具備提供法律內容檢索、法律內容總結以及生成合同、簡報等功能。在出版技術方面,大語言模型技術、基于人類反饋的強化學習算法、自注意力機制等技術將陸續影響和作用于出版業,對出版內部流程和外部產品服務持久賦能。在出版營銷方面,營銷文檔的AI制作、基于AIGC的虛擬客服、出版營銷數據建設等將會出現或不斷強化,在線下營銷、直播營銷、短視頻營銷等基礎上進一步拓展出版營業的版圖,豐富出版營業的內涵。
2. 知識生成方式的變化,并沒有改變出版本質
出版的本質究竟是什么?以實踐視角視之,出版的本質可被解讀為“對作品經過編輯、復制而后予以公開的活動”,筆者認為反映出版實踐的編校印發說固然是沒錯的,但在回答出版的本質是什么這一問題上則顯得力有不逮。以理論視角考察,編輯出版是“文化締構、文化傳播和文化再生產活動”[35]“出版活動的本質是文化選擇”[36]“商業形式的文化建構”[37]等觀點是從文化角度提出的,“出版專業主義核心內涵是信息選擇把關、共識與價值觀表達以及知識和文化的傳播”[38]及“出版本質是一種知識生產”[39]則是從知識的角度提出的。筆者基本贊同出版的本質是知識生產這種說法,至少知識生產作為出版的本質可以適用于專業出版、學術出版、教育出版等業態,但是大眾出版的本質是否為生產知識?抑或生產的是技巧、技能、生活經驗等隱性知識?這一點尚需嚴謹論證。實際上,出版的本質是知識生產,更確切地說,是知識的第二次生產,是知識的建制化生產,是一種深層次、有底蘊的知識生產,是知識的社會化生產與傳播。就此而言,無論是人類還是AI生產的知識,實質上生產的是知識素材、知識原型,而非知識產品、知識成品,出版業生產和傳播的則是知識產品和知識成品。
3. 知識生成范式的轉換,啟迪出版學研究范圍拓新
AI生成知識的出現并不能取代人類生成知識,數據驅動生成知識也不能替代智慧生成知識,恰如機器人新聞中算法和記者的關系,不是替代關系而是耦合關系,[40]二者同樣在新聞業中扮演重要角色。但這意味著知識生成的范式開始由人類智慧生成知識轉變為人機協作生成知識,且這一新的知識生成范式將在很長的歷史時期內存在并發展。就出版學研究而言,知識生產范式和內容供給模式的轉換,[41]給我們最大的啟發在于拓新出版學的研究邊界,基于時間維度展開高新技術對出版業應用的出版未來學研究。[42]就此而言,是否可擴展至出版前端的作者,在作者學方面進行鉆研和探索?長期以來,出版學研究的范圍往往在本體維度的出版經營管理、時間維度的出版史、空間維度的國際出版、技術維度的數字出版以及作為出版后端的閱讀、讀者等,鮮有學者將作者、作者學作為出版學研究的基本范疇和主要領域。把出版學研究領域拓展至前端的作者,一方面,有利于擴大出版學研究范圍,深入分析知識生成的主體、工具、對象等特點,探究知識生成機理與規律;另一方面,在人機寫作生成知識的時代,對作者的研究進一步由研究人類作者延展到研究AI作者,既是提升出版人數字素養與技能的要求,也與當下作為研究熱點的智能出版、智慧出版相吻合。
結語
生成式人工智能技術引發了社會各行各業的熱議和思考,也引起了學術各界的研究和探索。本文在提出智慧驅動型和數據驅動型知識生成原理的基礎上,從知識生成這個維度,對個體生產知識、專業生產知識、大眾生產知識及人工智能生成知識進行了分析和思考,最后提出了人機協同生成知識的新格局對出版業和出版學發展的意義。其實,關于生成式人工智能和出版的關系,還有諸多議題值得深入研究,如生成式人工智能物的可版權性如何、著作權歸屬如何、可行性的法律治理方案如何、分析式智能出版和生成式智能出版的區別與聯系又在哪里等。
參考文獻:
[1] 張新新,丁靖佳.生成式智能出版的技術原理與流程革新[J/OL].[2023-07-16].圖書情報知識,https://kns.cnki.net/kcms2/detail/42.1085.g2.20230716.0031.002.html.
[2] 張新新,黃如花. 生成式智能出版的應用場景、風險挑戰與調治路徑[J/OL].[2023-07-17].圖書情報知識,https://kns.cnki.net/kcms2/detail/42.1085.G2.20230717.1104.003.html.
[3] 郝祥軍,顧小清. AI重塑知識觀:數據科學影響下的知識創造與教育發展[J]. 中國遠程教育,2023(5):13-23.
[4] 王健. 知識萃取——將科研項目隱性知識顯性化[J]. 企業管理,2022(4):102-105.
[5] 吳飛,段竺辰. 從獨思到人機協作——知識創新模式進階論[J]. 浙江學刊,2020(5):94-104.
[6] 吳鋒. 發達國家“算法新聞”的理論緣起、最新進展及行業影響[J]. 編輯之友,2018(5):48-54.
[7] 熊國榮,李賢秀.“機器人記者”對新聞記者就業的沖擊及應對[J]. 編輯之友,2016(11):73-77.
[8] Brown T, Mann B, Ryder N, et al. Language Models are Few-shot Learners[J]. Advances in Neural Information Processing Systems, 2020(33): 1877-1901.
[9] 朱光輝,王喜文. ChatGPT的運行模式、關鍵技術及未來圖景[J]. 新疆師范大學學報(哲學社會科學版),2023(4):113-122.
[10] Haiko V, Cunningham S, Janssen M, et al. Data science as knowledge creation a framework for synergies between data analysts and domain professionals[J]. Technological Forecasting and Social Change, 2011, 173(4): 1-10.
[11] 康德. 純粹理性批判[M]. 鄧曉芒,譯. 北京:人民出版社,2004:21.
[12] 王慶節.“先驗想象力”抑或“超越論形象力”——海德格爾對康德先驗想象力概念的解釋與批判[J].現代哲學,2016(4):58-65.
[13] 邱仁宗. 科學方法與科學動力學——現代科學哲學概述[M]. 北京:高等教育出版社,2006:51.
[14] 袁方,王漢生. 社會研究方法教程(重排本)[M]. 北京:北京大學出版社,2013:28.
[15] 劉魁. 真理、文化權威與知識生產的時代性——兼評福柯對真理話語的微觀權力分析[J]. 南京政治學院學報,2005(3):53-57.
[16] 李明杰. 中國出版史:上冊·古代卷[M]. 長沙:湖南大學出版社,2008:50-51.
[17] 張岱年,方克立. 中國文化概論[M]. 北京:北京師范大學出版社,2004:135.
[18] 賀國慶. 古希臘高等教育探微[J]. 河北大學學報(哲學社會科學版),2003(4):5-8.
[19] 方卿,許潔,等. 出版學基礎[M].武漢:武漢大學出版社,2023:356.
[20] 讓-弗朗索瓦·利奧塔. 后現代狀況:關于知識的報告[M]. 島子,譯. 長沙:湖南美術出版社,1996:35.
[21] 張新新,陳奎蓮. 堅持出版導向,引領5G時代數字出版新變化[J]. 出版發行研究,2020(3):38-44.
[22] 張新新. 智能出版:現代出版技術原理與應用[M]. 北京:人民出版社,2021:40-50.
[23] Rocio·M. T, Maria O. Identification of innovation solvers in open innovation communities using swarm intelligence[J]. Technological Forecasting and Social Change, 2016, 109(2): 15-24.
[24] 王玫,朱云龍,何小賢. 群體智能研究綜述[J]. 計算機工程,2005(22):194-196.
[25] 劉華東,馬維娜,張新新. “出版+人工智能”:智能出版流程再造[J]. 出版廣角,2018(1):14-16.
[26] 肖奎. 維基百科大數據的知識挖掘與管理方法研究[D]. 武漢大學,2014.
[27] 牛明坤. 基于大眾標注的群體知識組織性質與結構研究[D]. 湖南大學,2018.
[28] 趙健,張鑫褆,李佳明,等. 群體智能2.0研究綜述[J]. 計算機工程,2019(12):1-7.
[29] 張新新,劉華東. 出版+人工智能: 未來出版的新模式與新形態——以《新一代人工智能發展規劃》為視角[J]. 科技與出版,2017(12):38-43.
[30] 申屠曉明,甘恬. 機器人寫稿的技術原理及實現方法[J]. 傳媒評論,2017(9):15-19.
[31] 央視新聞:新聞機器人的工作原理與技術解析[EB/OL].[2023-07-14].http://www.uctdm.com/43920.html.
[32] 鄧浩然. 新聞寫作機器人現狀與發展研究——以Xiaomingbot為例[D]. 蘭州大學,2019.
[33] 陸偉晶. 人工智能機器人面臨的倫理困境——以“微軟小冰”為例[J]. 視聽界,2018(4):74-78.
[34] 崔宇紅,白帆,張蕊芯. ChatGPT在高等教育領域的應用、風險及應對[J]. 重慶理工大學學報(社會科學),2023(5):16-25.
[35] 王振鐸. 文化締構編輯觀[J]. 河南大學學報(哲學社會科學版),1988(3):104-114.
[36] 陳少志,張新新. 出版業文化質量的提升向度與路徑探析——基于編輯工作的視角[J]. 中國編輯,2023(7):34-40.
[37] 方卿,丁靖佳. 數字出版三個基本理論問題的思考[J]. 中國出版,2023(10):17-22.
[38] 李楊. 數智時代出版專業主義的核心內涵建構[J]. 編輯之友,2022(7):83-89.
[39] 范軍. 出版本質上是一種知識生產[J]. 出版科學,2022(3):1.
[40] 張超,鐘新. 從比特到人工智能:數字新聞生產的算法轉向[J]. 編輯之友,2017(11):61-66.
[41] 方卿,丁靖佳. 人工智能生成內容(AIGC)的三個出版學議題[J]. 出版科學,2023(2):5-10.
[42] 張新新. 中國特色數字出版學研究對象:研究價值、提煉方法與多維表達[J]. 編輯之友,2020(11):5-11,30.
作者信息:張新新(1984— ),男,江蘇贛榆人,博士,上海理工大學出版印刷與藝術設計學院教授、博士生導師,國家新聞出版署科技與標準重點實驗室學術委員會主任,主要研究方向:數字出版、人工智能、文化管理與服務。
