科研興趣空間挖掘與多任務推薦研究
——基于異質信息網絡表示學習
2023-11-21 09:48:50崔鴻飛馮子函張靖雨
情報學報 2023年10期
崔鴻飛,馮子函,張靖雨
(1. 北京科技大學經濟管理學院,北京 100083;2. 北京航空航天大學經濟管理學院,北京 100191;3. 愛丁堡大學商學院,愛丁堡 EH8 9JU)
0 引 言
隨著科研進程的不斷推進與發展,研究人員間的科研活動日趨復雜化、多樣化,獲得一項科研成果往往需要不同研究方向的研究者密切合作[1],以及從不同研究主題中獲取新的靈感[2]。然而,由于各領域研究者不斷增多,潛在的合作者變得越來越多,隨著學術問題的研究日趨深入,研究者所面臨的知識爆炸問題也日趨嚴重。在這種情況下,研究者難以在有限的時間中,對自己領域內外的潛在合作者和研究靈感進行全面了解。
與此同時,隨著信息技術的發展,互聯網上涌現了許多優秀的科研文獻數據庫,如美國科學信息研究所創建的多學科核心期刊文獻數據庫Web of Science (www.webofknowledge.com)、美國國立醫學圖書館國家生物技術信息中心的醫學文獻數據庫PubMed(http://www.ncbi.nl.nih.gov/pubmed)等,收錄了其關注的各個領域的大量研究成果。這些成果主要以論文形式展示,囊括了作者的合作關系、作者對關鍵詞的選擇等大量科研行為。合理利用這些科研行為信息,個性化地提供潛在合作者和研究靈感的推薦列表以供篩選,對研究者來說,不僅可以有效地節約時間,更可以使其科學研究道路更具有方向性。
對科研論文中的科研行為信息進行挖掘,一種比較常見的做法是將大量論文中蘊含的科研關系抽象成同質(homogeneous)[1,3-4]或異質(heterogeneous)信息網絡(information network)[5-7],各種科研主體(如作者、關鍵詞等)被抽象為網絡中的節點,對象間的各種聯系(如合著關系)被抽象成網絡中的邊。這種網絡化處理方法已經被廣泛應用于科研關系分析及推薦任務的研究中,并在數據整合、數據挖掘、科研合作關系理解、科研個性化推薦研究等方面做出了重要貢獻(詳見下文“相關研究”)。然而,這類研究往往具有兩個特點:其一,現有研究往往更關注科研共著關系(或科研合作者推薦),忽略了科研興趣方向推薦任務的研究;其二,現有研究往往基于同質信息網絡,忽略了作者與機構之間的從屬關系、作者與文章關鍵詞之間的學科領域與科研興趣關系當中蘊含的巨大信息量。在最新的一些研究中,已經有學者開始關注并分析異質信息網絡[5-7],但這些研究引入異質性的普遍目標依然是科研合作者推薦任務,或者即使涉及關鍵詞推薦,也缺乏對關鍵詞推薦正確率的量化分析。而完全從異質性視角出發,分析作者與關鍵詞之間的關系,并為科研人員提供有效的關鍵詞推薦列表,激發科研人員的研究靈感,是非常重要且至今尚缺乏深入研究的主題。
在關鍵詞推薦和合作者推薦的雙任務推薦背景下,本研究希望探討與同質信息網絡表示的視角相比,基于異質信息網絡的節點表示與推薦方法是否更加適用。為此,本研究基于PubMed 文獻數據庫,選擇當前研究熱點之一,即生命組學及醫學相關的機器學習、深度學習領域,分析科研工作者之間以及科研工作者與領域關鍵詞之間的關系,同時解決合作者推薦與研究興趣推薦兩大任務。基于該領域2010—2021 年發表的13 萬篇論文,本研究濾除僅出現1 次的作者與關鍵詞,篩選出1.1 萬篇適合進行科研合作者及關鍵詞預測的文獻,從異質性視角將文獻抽象成為包含作者、機構、關鍵詞、論文多種主體的“科研異質信息網絡”,并使用異質信息網絡表示學習算法metapath2vec 進行網絡節點嵌入,生成一個同時對作者與關鍵詞進行語義化向量表示、充分體現作者研究興趣的異質科研興趣空間,進而基于該異質科研興趣空間同時完成科研合作者與科研關鍵詞推薦兩種任務,在兩種任務中均獲得更優的表現。此外,本研究的關注點不僅在于推薦任務,還對網絡分析過程中生成的異質科研興趣空間中蘊含的豐富語義信息開展進一步挖掘和研究,以證明該興趣空間對表示科研人員潛在研究方向的有效性,并在科研領域交叉與關聯的理解中提供啟發性方向。
1 相關研究
1.1 基于經典網絡視角的科研推薦研究
“科研推薦”是存在于兩個科研主體(如作者、關鍵詞、機構、期刊等)間的推薦任務的統稱,其背后包含了各種具體的推薦任務,如本研究主要關注的科研合作者推薦、科研關鍵詞推薦等。在網絡視角下,科研推薦的本質是一種鏈接預測(link prediction),當模型預測兩個科研主體在網絡中有大概率產生聯系時,其中一個科研主體就會被推薦給與之匹配的另一個科研主體。
現有關于“科研推薦”的研究主要集中于科研合作者推薦,“科研網絡”是執行這一推薦任務的主要載體。比如,張金柱等[1]構建了作者-關鍵詞二分網絡,并使用基于路徑組合的網絡指標與邏輯回歸進行了科研合著預測;劉萍等[8]、關盼盼[9]以社交網絡理論為基礎,在作者關系的研究中引入隱含狄利克雷分布(latent Dirichlet allocation,LDA)來刻畫作者的研究興趣,進而實現科研合作者的推薦;余傳明等[3]、Yan 等[10]、呂偉民等[11]、秦紅武等[12]在作者合著網絡的分析中應用了鏈接預測的特征指標,如Adamic-Adar index(AA)、common neighbors(CN)、Katz indices(Katz)等,其中,呂偉民等[11]、秦紅武等[12]分別將極端隨機樹、k-means 算法與這些指標結合,余傳明等[3]將基于路徑的與基于鄰居的網絡特征指標彼此間融合,以“特征融合”為基本思路完成科研合作推薦的任務。
上述研究的共同特點是基于網絡結構指標特征,結合統計學習理論建立模型,實現對網絡鏈接關系進行預測的目標。這種方式非常依賴于模型開發者對網絡的理解和對特征的選擇經驗,同時對于大規模數據集,這種傳統的網絡分析方法對計算力的要求非常高。隨著深度學習領域研究的創新與突破,網絡表示學習逐漸在科研推薦任務中得到越來越廣泛的應用,這種方法直接通過模型訓練從原始數據中自動提取特征,避免了對模型開發者經驗的過度依賴;同時,在大規模網絡的計算方面,往往可以比傳統網絡分析方法具有更優的速度,因此,在科研推薦研究中逐漸開始扮演重要角色。
1.2 基于網絡表示學習的科研推薦研究
網絡表示學習(network representation learning)是表示學習(representation learning)方法的一個重要分支。相關實驗已經證明,將網絡表示學習算法應用于鏈路預測等下游任務中,其表現往往優于一些基于指標計算的傳統算法,在SDNE(structural deep network embedding)[13]與node2vec[14]等研究中皆可體現。隨著深度學習技術的不斷發展,這種以數據隱式特征提取為思路的研究方法,被廣泛應用于科研行為數據的分析中。
在這些基于網絡表示學習的科研推薦研究工作中,學者們往往先構建以推薦主體為節點的科研網絡,再利用各種網絡表示學習方法對網絡主體進行向量化表示。例如,張金柱等[1]使用網絡表示學習算法在合著網絡中對作者向量進行表示學習以完成科研合作預測任務;余傳明等[4]將不同網絡表示學習算法下的作者向量表示進行了加權平均融合,并基于此構建科研合作推薦模型;張鑫等[15]將網絡表示學習算法生成的作者節點嵌入與基于作者主題模型生成的作者主題向量表征進行線性特征融合,用于作者合作預測。上述研究的相似點在于它們的同質性視角:在這些研究中,被進行表示學習的網絡都是科研合作網絡,或稱“共著網絡”,其本質是一種僅包含作者節點,并以作者合作關系為邊的同質信息網絡。因此,上述研究中所利用的網絡表示學習算法都屬于同質信息網絡嵌入方法,如Deep-Walk、node2vec、LINE (large-scale information network embedding)、SDNE 等。
事實上,在科研關系預測問題中,同質的作者合作關系僅是豐富科研行為信息中的冰山一角。一個直觀的靈感是,如果把作者與研究機構的從屬關系、作者對關鍵詞的選取關系等信息融入網絡進行挖掘,在科研關系預測中可能會獲得更好的效果。隨著網絡表示學習方法的不斷發展,異質信息網絡表示學習方法越來越成熟,學者們對科研網絡的構建與分析,自然而然地轉向了異質信息網絡表示學習方法。劉云楓等[5]在網絡構建時引入作者、關鍵詞、機構、論文、出版物多種主體,提出了一種基于不同元路徑的多關系映射方法以獲取表示學習的語料庫;王鑫[7]在異質信息網絡構建的基礎上,提出了一種基于屬性網絡表示和主題感知的學術合作者推薦(topic-aware academic collaborator recommendation based on attributed network representation learning,TACR-ANRL)算法。這些研究通過在網絡中引入異質信息,對作者向量給出了更精準的表示,從而獲得了更優的合作者推薦結果。在本研究關注的另一個重要推薦任務即關鍵詞推薦方面,相關研究非常缺乏。其中一項優秀的先驅性研究來自林原等[16],該研究將作者、地址、關鍵詞3 種信息用于構建科研異質信息網絡,利用node2vec 方法進行網絡嵌入后,為科研工作者推薦了合作者、機構與關鍵詞。在這項研究中,雖然科研網絡為異質信息網絡,但圖嵌入算法依然為同質信息網絡表示學習算法,這種方式是否能充分發揮異質信息網絡的異質性優勢,有待進一步討論。同時,這項研究并未設計相關指標對合作者與關鍵詞的推薦正確率進行評估。這些方面非常值得進一步探索。已有很多網絡表示學習算法,如經典的以隨機游走為基礎的metapath2vec[17]和在其基礎上從不同角度改進的spacey[18]、 JUST[19]、 BHIN2vec (balanced heterogeneous information network to vector)[20]、HHNE(hyperbolic heterogeneous information network embedding model)[21]等,以矩陣分解為基礎的PME(projected metric embedding model)[22]、 EOE (embedding of embedding)[23]等,以及近年來不斷涌現的深度學習方法GATNE(general attributed multiplex heterogeneous network embedding)[24]、 MAGNN (metapath aggregated graph neural network)[25]、HGT(heterogeneous graph transformer)[26]等,這些算法均能夠應用于異質信息網絡表示學習,其中部分算法被證明在一些作者合作網絡的鏈路預測任務中可以獲得良好效果[17,27-28]。基于這些算法,本課題組的一項預研究工作[29]驗證了基于metapath2vec 的網絡表示學習方法,所得到的作者與其所發表過的關鍵詞之間的平均距離顯著低于該作者與隨機選擇的關鍵詞之間的距離,這為本研究的雙目標推薦系統提供了充分的可行性依據。
此外,盡管網絡表示學習的方法有效地提升了科研推薦任務的效果,但對科研主體嵌入表示結果的解釋和分析研究仍較為缺乏。從向量空間中深入分析同質或異質科研主體之間的位置和聚集關系,尤其是關鍵詞空間或關鍵詞相關的作者空間的分析,會為理解科研工作者視角下的領域定位、領域之間相關性與領域差異,提供豐富的可解釋性資源。因此,本研究不但在異質信息網絡構建、網絡表示學習算法使用、推薦模型構建與評估等各方面進行了更深一步的探索,而且完成了科研合作者與科研興趣推薦的任務,并對嵌入的向量空間進行了全局與個體視角的深入可視化分析。這些工作將為現有的科研推薦研究工作提供新的分析角度,研究結論也將為科研人員理解領域交叉、尋找新的研究方向提供靈感。
2 研究思路和方法
2.1 研究思路
本研究的整體思路如圖1 所示。本研究聚焦于生命組學及醫學相關的機器學習、深度學習大領域,收集了2010—2021 年發表的13 萬篇科研論文,并根據數據記錄質量、作者出現次數等標準(詳見3.1 節),從中篩選出1.1 萬篇,構成適合進行科研合作者及關鍵詞推薦的科研數據集。基于作者、機構、關鍵詞、論文信息,為了說明異質視角處理科研關鍵詞及合作者推薦任務時相較于傳統同質視角的效果差異,本研究構建了基于科研行為的異質信息網絡(簡稱“異質科研行為信息網絡”),并使用經典的異質信息網絡表示學習算法metapath2vec學習這些科研主體在異質信息網絡所抽象的科研行為背后的語義信息,得到作者、機構、關鍵詞、論文4 種科研主體的向量表示。根據metapath2vec 算法的特性,上述4 種向量可以在同一個空間進行分析,本研究稱之為“異質科研興趣空間”,在此空間中,距離的遠近表示同質或異質主體之間的相關程度,利用這種特性,分別計算不同科研主體的向量表示之間的相似度,并基于該相似度完成科研推薦任務;同時,針對該情景定義相應的評價指標,對推薦結果的正確率進行評價。
本研究的推薦任務包括科研合作者推薦和關鍵詞推薦。考慮到推薦任務的一致性,本研究選取了現有研究中同時涉及這兩項任務的林原等[16]的研究作為對比基線方法,該方法采用同質信息網絡表示學習方法對異質信息網絡進行分析,在合作者與科研關鍵詞方面均給出了參考性的推薦結果。進一步將該結果的正確率指標化(詳見2.5 節),并將其與本研究的推薦結果進行比較。此外,本研究的數據集規模較為龐大(訓練集共3.9 萬個節點),考慮到基線方法原始選取的同質信息網絡表示學習方法node2vec 在大型數據集上所需內存極大,運行時間長,在實際應用中的計算效率受限,本研究采用速度更快、更適合大型數據集[30],且正確率表現不亞于node2vec[17-18,31-32]的方法LINE 作為替代,用于分析在異質信息網絡的節點表示方面,異質信息網絡表示學習算法相較于同質信息網絡表示學習算法的特性。
2.2 異質科研行為信息網絡的建立與嵌入
2.2.1 異質科研行為信息網絡的建立
本研究構建的異質科研行為信息網絡GHeter,包含的節點種類集合為TV={A,K,P,O},A、K、P、O分別代表作者(author)、關鍵詞(keyword)、論文(paper)、機構(organization)4 種網絡節點;包含的邊種類集合為TE={(O,A),(A,P),(P,K)},(O,A)、(A,P)、(P,K)分別代表作者相對于機構的從屬關系、作者相對于論文的發表關系、論文相對于關鍵詞的包含關系3 種邊。異質科研行為信息網絡中節點與邊的具體抽象方式如圖2a 所示。
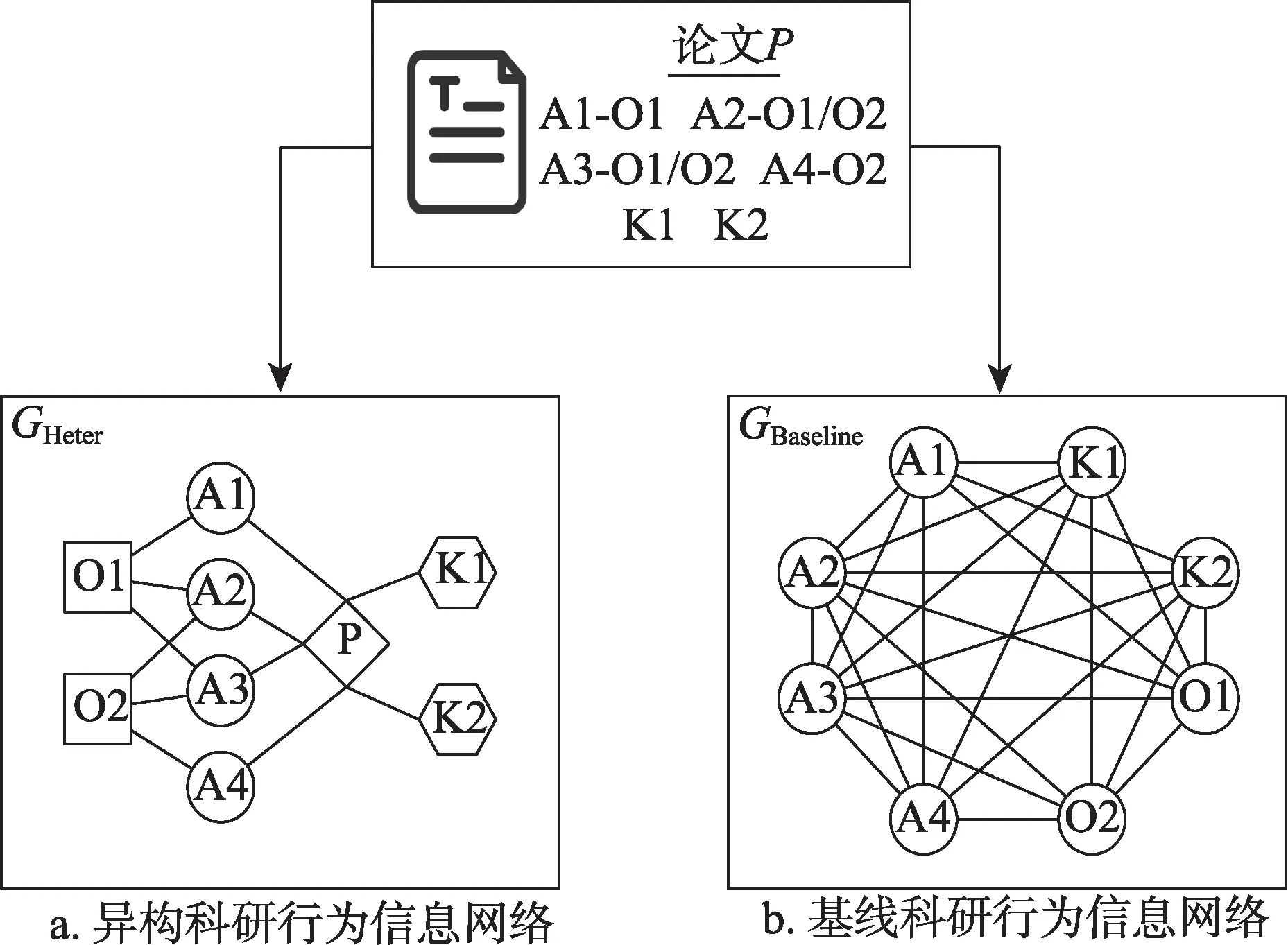
圖2 科研行為信息網絡構建方法
值得注意的是,該網絡為無向網絡,且作者A與機構O節點間通過邊(O,A)直接相連;本研究在作者A與關鍵詞K這兩類節點間引入了論文P,并使用邊(A,P)和(P,K)相連兩者。一方面,相比于將作者A與關鍵詞K通過邊(A,K)直接相連,這種做法能夠顯著減少邊的條數;另一方面,能更好地還原關鍵詞與作者在現實語義上的聯系。
2.2.2 異質信息網絡表示學習與元路徑
本研究選擇了一種基于網絡結構的異質信息網絡表示學習算法——metapath2vec,用于盡量完整地表征網絡結構。該算法在異質信息網絡中使用元路徑引導的隨機游走策略來捕獲不同類型節點和關系的結構以及語義相關性,然后利用針對異質節點的skip-gram 模型執行網絡嵌入。該模型在提出時已經被證明當其用于一個計算機領域會議論文科研數據集時,可以有效地挖掘會議之間的聯系,并能在一定程度上反映作者之間的研究方向關聯(雖然該研究并未展示其在作者合作關系與關鍵詞興趣方面的挖掘效果)。
在metapath2vec 算法中,采樣時的隨機游走需要根據指定的元路徑(meta-path) 進行[17],其中“元路徑”
被定義在一種固定的R=R1?R2?… ?Rl-1復合關系上,用于拓展網絡節點之間的語義關聯。本研究參考了一種常被應用于科研主題數據集如DBIS(database and information system)[33]、AMiner[34]等的有效元路徑方案,并結合異質科研行為信息網絡中的節點和節點間的語義關系,定義了元路徑“OA-P-K-P-A-O”用于指導算法采樣時的隨機游走。該條元路徑包含了網絡中的所有類型節點,在隨機游走過程中能夠直接采樣作者對關鍵詞的使用關系(體現在A-P-K與K-P-A)。此外,還包括作者與機構的從屬關系(體現在O-A與A-O)、作者與作者因關鍵詞興趣而產生的關聯(體現在A-P-K-P-A)等各類聯系。使用這樣的元路徑能夠將更多的語義融合于算法生成的嵌入向量中,從而在下游任務中實現更可靠的關鍵詞與合作者推薦。
2.3 基線方法中的科研行為網絡建立與嵌入
基于林原等[16]研究中的網絡構建方式與網絡表示學習思維,本研究將相同的科研行為數據建立成為基線科研行為網絡GBaseline。在該網絡中,節點種類依舊包括作者(A)、機構(O)、關鍵詞(K),邊則刻畫了作者間的合作關系(author-author,AA)、作者相對于機構的從屬關系(author-organization,A-O)、作者相對于關鍵詞的使用關系(author-keyword,A-K)、機構間的合作關系(organization-organization,O-O) 以及機構相對于關鍵詞的使用關系(organization-keyword,O-K)。基線科研行為網絡中節點與邊的具體抽象方式見圖2b。
根據基線算法的原設計,本研究采用同質信息網絡表示學習方法對基線科研行為網絡GBaseline中的節點進行嵌入表示。考慮到對大型數據集的適配,本研究使用同質信息網絡表示學習方法LINE 替代原基線算法設計中的node2vec(詳見2.1 節),用于探索利用基于同質的方法處理異質信息網絡時會發生的現象。LINE 算法使用KL (Kullback-Leibler)散度作為損失函數,計算節點相似度在向量表示下的概率分布與實際網絡中的經驗分布之間的差異,并經過優化獲得每個節點的低維向量表示。
2.4 科研主體間的相似度計算方法
得到作者、關鍵詞等科研主體的向量表示后,本研究通過向量間的相似度來表征不同科研對象間的“距離”,相似度越高,表示兩個對象在異質科研興趣空間中的距離越近,越可能存在潛在的關聯。本研究選擇余弦相似度作為向量間的相似度的度量。向量X=(X1,X2,…,Xn)與向量Y=(Y1,Y2,…,Yn)間的相似度sim (X,Y)的計算公式為
其中,向量X與向量Y可以是同類型的科研主體,如作者向量Ai與作者向量Aj;也可以是不同類型的科研主體,如作者向量Ai與關鍵詞向量Kj。具體的科研主體類型由推薦任務本身的需求決定。
2.5 推薦模型及其評價指標
本研究是雙任務目標,即可以同時完成科研關鍵詞推薦和科研合作者推薦。為了在推薦任務中充分為用戶提供新信息,本研究以科研主體間的相似度為標準,在篩除用戶已經使用過的關鍵詞或已經合作過的作者后,再進行top-n推薦。在科研關鍵詞推薦任務中,本研究為作者推薦其在異質科研興趣空間中最接近(即向量相似度最大)的且未使用過的n個關鍵詞。類似地,在科研合作者推薦任務中,與被推薦作者向量相似度最大的n個未合作過的作者將被推薦。
在評價指標方面,由于科研推薦任務與很多其他領域(如電影推薦等)的推薦任務有相通之處,本研究參考了電影推薦場景中衡量推薦效果的指標[35],利用“用戶命中率(hit user proportion,HUP)”來描述在未來一段時間(即測試集時間范圍)內使用了模型推薦的關鍵詞或合作者的作者比例,計算公式為
其中,U表示測試集中的作者總數;Ii表示第i名作者在測試集中是否使用了模型推薦的關鍵詞或合作者,若使用過,則Ii= 1,否則,Ii= 0。HUP 指標能夠描述推薦列表在現實中將為多大比例的作者提供幫助,HUP 值越大,表示推薦的效果越好。
3 實驗與分析
3.1 數據獲取與預處理
本研究使用的數據集來自生物醫學和健康科學領域的PubMed(https://pubmed.ncbi.nlm.nih.gov/)數據庫,它是當今國際最權威的醫學文獻數據庫之一Medline 的免費檢索工具,由美國國立醫學圖書館開發,也是生物醫學及健康領域使用最廣泛的互聯網文獻檢索工具。近年來,深度學習方法發展迅猛,在生物與醫學領域也產生了深刻的影響。同時,PubMed 還有一套非常全面且規范的主題詞表(medical subject headings,MeSH),其將論文中可能出現的各種科研概念的書寫形式進行了嚴格的控制和規范,并對每一篇論文進行了主題詞標注,可以認為,PubMed 數據庫中的MeSH 主題詞比作者在撰寫論文時標注的關鍵詞更加全面、規范和準確,因此,采用MeSH 主題詞作為關鍵詞的代表。本研究下載了2010 年1 月1 日至2021 年2 月28 日發表的所有深度學習、機器學習相關的主題論文,檢索式為“(deep learning) OR (machine learning) OR (neural network)”,共下載131691 篇。
由于文化原因和語言習慣,英文姓名往往存在著大量重名。為了明確區分同名作者,避免在研究中將不同的科研實體混淆,本研究使用作者所屬機構字段對作者姓名進行了消歧處理[29]。簡而言之,若兩篇論文中某兩名作者所留姓名相同且其所屬的若干機構中存在相同所屬機構,則這兩名作者將被視為同一個作者,并使用相同的作者ID 進行標識。
鑒于各文獻所屬期刊的記錄習慣不同,為了按照統一的時間字段劃分數據集,本研究選取相關文獻數最多的時間字段,即PubMed 收錄時間,作為劃分訓練集與測試集的標準。共有108477 篇論文擁有此字段,其中2010—2019 年發表的論文77467篇,2020 年及以后發表的論文31010 篇。訓練集為構建異質科研行為信息網絡和后續分析科研興趣空間的基礎。由于關鍵詞推薦是本研究的重要目標之一,在進行數據清洗過程中,本研究將沒有關鍵詞字段的論文直接剔除。同時,由于僅出現一次的作者節點和關鍵詞節點在網絡中無法起到鏈接不同論文的作用,也無法用于推薦正確率的測試,無法提供額外的語義信息,因此,本研究對作者與關鍵詞的累計出現次數進行了篩選,將所有只出現一次的作者與關鍵詞剔除。清洗后的訓練集剩余10670 篇論文。在測試集中,為了充分測試為已有論文發表的研究者推薦關鍵詞或合作者的效果,本研究僅保留在訓練集中出現過的作者和與其相關的機構、關鍵詞、論文數據,清洗后的測試集剩余485 篇論文,其與清洗后的訓練集共同組成適合進行科研推薦研究的高質量數據集。最終數據集情況如表1所示。
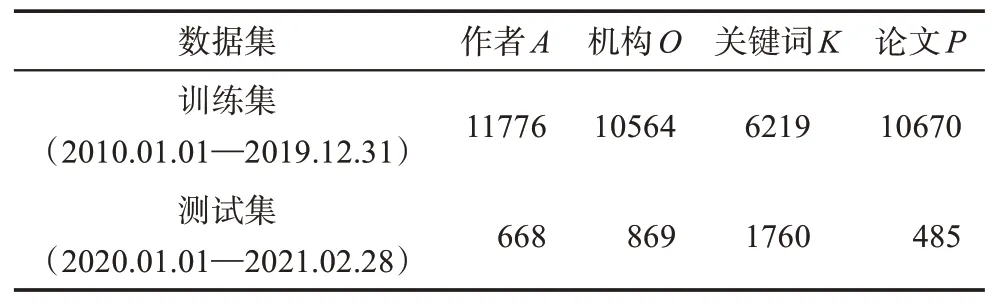
表1 數據集情況
3.2 推薦模型評價
為評價本研究方法的推薦效果,從兩個角度對模型進行評價。從定量角度,基于上述以2020 年1月1 日為界的訓練集和測試集,利用訓練集的數據進行表示學習,并在測試集中驗證推薦效果,通過與基線方法的效果進行比較分析,來說明本研究方法的優勢和可靠性。從定性角度,在推薦結果中隨機選取了一些案例,對照測試集中的真實數據,用于對模型效果進行更形象和具體的說明。
3.2.1 定量評價指標
基于預處理后的訓練集,分別采用本研究方法(詳見2.2 節)與基線方法(詳見2.3 節)構建異質科研行為信息網絡GHeter與基線科研行為網絡GBaseline,并分別進行節點嵌入表示,最終得到兩個不同的向量空間。本研究分別基于這兩個向量空間,按照向量相似度指標從高到低排序,進行合作者與關鍵詞的top-n推薦(詳見2.4 節),并剔除訓練集中已經與被推薦作者產生過聯系的推薦對象,對兩種方法分別計算用戶命中率(HUP)(詳見2.5節)。科研合作者與關鍵詞推薦的top-10、top-20、top-50 和top-100 推薦結果如表2 所示。由于本研究方法使用的metapath2vec 與基線方法使用的LINE 在嵌入表示時均具有一定的隨機性,為避免因單次實驗結果的浮動而導致對比不公平,本研究將實驗重復5 次,表2 所示為所有實驗結果的平均值。
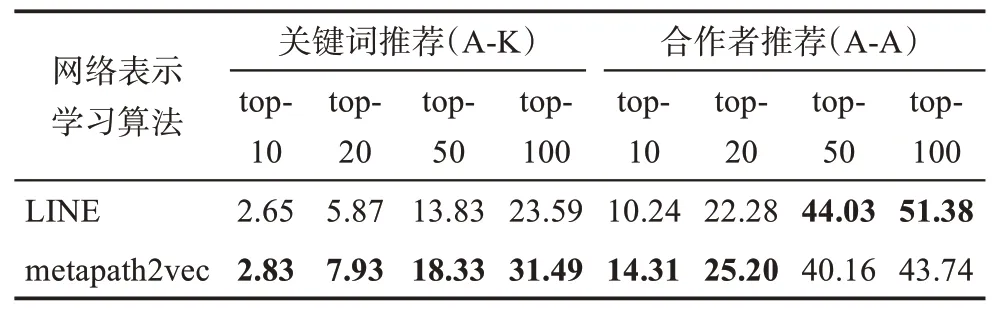
表2 推薦模型的HUP對比 %
結果表明,在關鍵詞推薦任務中,本研究方法在所有推薦級別的用戶命中率均高于基線方法,尤其是在top-20 以上的推薦級別,本研究方法的效果有非常明顯的優勢,均有約1/3 的提升。在進行top-100 推薦時,本研究方法的用戶命中率可達31.49%;而由于本研究方法僅推薦了用戶沒有使用過的關鍵詞,這意味著瀏覽本研究方法的推薦列表將為近1/3 的用戶提供新的靈感。
在合作者推薦任務中,本研究方法并非在所有情況下都優于基線方法。在進行top-10 與top-20 級別推薦時,本研究方法表現優于基線方法,分別改善39.75%和13.11%;而在進行top-50 與top-100 級別推薦時,用戶命中率較基線方法略低,分別下降8.79%和14.87%。盡管如此,依然可以看到,本研究方法傾向于把對用戶信息量最大的結果集中在頭部,在選取較小的推薦數量時,即可展現出較為優越的推薦效果,這種情況在top-10 級別時現得尤其明顯,提升近40%。
由表2 可以看到,與基線方法相比,本研究方法在合作者推薦方面能獲得同樣理想的結果,并且更傾向于把有效結果集中在頭部推薦結果中;在關鍵詞推薦方面,本研究方法則具備極大的優勢,改善效果十分明顯。值得深思的是,在本研究方法構建的異質科研行為信息網絡中,作者節點A與關鍵詞節點K并沒有直接相連;反而在基線方法的科研行為網絡構建中,作者節點與關鍵詞節點被直接連接。相較于兩種節點直接相連的基線方法,沒有直接相連的異質科研行為信息網絡在進行嵌入表示后所得到的作者向量A與其關鍵詞向量K之間相似度更高。其中的主要區別是,在基線方法中,雖然目標網絡是異質信息網絡,但網絡嵌入方法是基于同質的方法,導致異質節點被當作同質節點進行嵌入表示,失去了異質節點之間本來的語義信息;而本研究充分考慮到這一點,通過異質信息網絡嵌入方法充分挖掘異質科研主體之間的語義相關性,在為作者推薦關鍵詞這種異質性推薦任務中,獲得了非常明顯的優勢。
此外,為了衡量推薦模型的穩定性,本研究還計算了5 次重復實驗中HUP 值的方差,結果如表3所示。可以看到,本研究方法中的模型在兩種推薦任務的各個推薦級別中,方差均小于基線方法,尤其在合作者推薦方面更為明顯,可以認為基于異質信息網絡嵌入表示的推薦模型具有更優的穩定性。
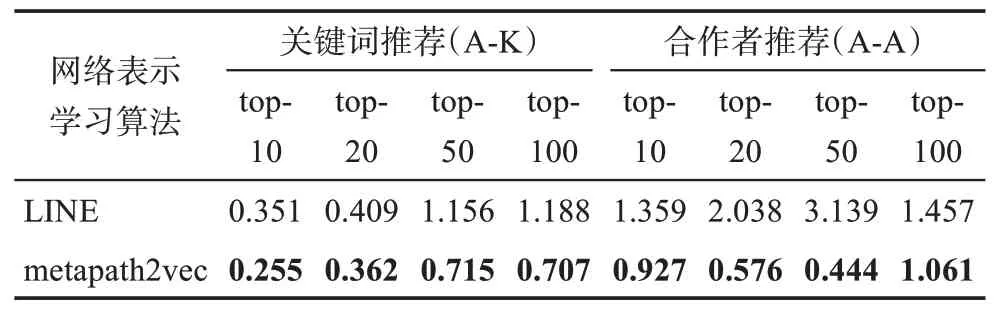
表3 推薦模型的穩定性對比 %
3.2.2 定性推薦案例
在真實的合作者推薦任務中,對于推薦清單中的潛在合作者,科研人員需要從論文、學術關系方面對被推薦者進行了解,并通過郵件、會議等渠道進行充分溝通,才會真正產生合作意向,因此,合作者推薦的清單宜少而精(如10 人)。因此,選取了3 個有代表性的top-10 合作者推薦案例,用于說明本研究方法的推薦效果,如表4 所示。
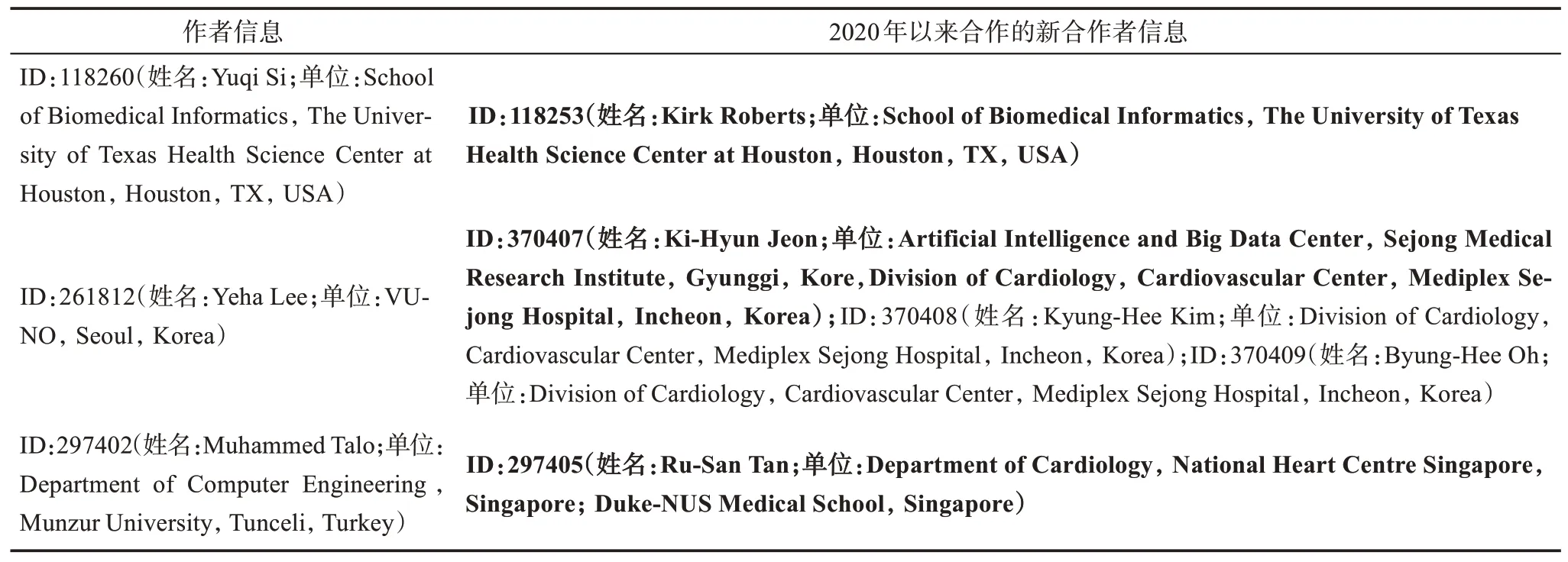
表4 合作者推薦結果舉例
表4 展示了相同單位、相同國家不同單位、不同國家不同單位3 種合作者推薦的情況。對于一些研究方向較為集中的單位,同一領域的研究者通常人數較多,相互之間學術交流較為充分,學者之間的表示向量往往更加相似,因此,在top-10 合作者推薦時,更容易推薦本單位的研究者。例如,美國德克薩斯大學健康科學中心生物醫學信息學院的Yuqi Si,被預測成功的是來自他同單位的合作者Kirk Roberts,這也是他在測試集中的唯一新合作者。Kirk Roberts 曾與同單位的另一學者Hua Xu 以共同通信作者的方式合作發表文章,而Yuqi Si 則曾經參與過Hua Xu 的其他文章工作。此后,以Yuqi Si 為第一作者、Kirk Roberts 為通信作者的方式展開了合作。此外,本研究方法也會對不同單位的研究人員進行有效的推薦。例如,來自韓國VUNO 公司的Yeha Lee,2020 年以來共有3 位新合作者,均來自韓國世宗醫院,其中Ki-Hyun Jeon 被本研究算法預測成功。雖然以前從未合作過,但他們有一個共同的合作者,來自韓國世宗醫院的Joon-Myoung Kwon。來自不同國家的研究者也會被推薦,如Muhammed Talo 來自土耳其Munzur 大學的計算機工程系,其測試集中的唯一新合作者被本研究方法預測成功,新合作者是新加坡國家心臟中心的Ru-San Tan。這兩位研究者雖然以前從未合作過,但他們都各自與對方單位的其他研究人員進行過合作。可以看到,在本研究模型對潛在合作者的推薦過程中,有效抓取了作者以往合作關系網絡中蘊含的信息。
在關鍵詞推薦任務中,目標是為科研工作者提供潛在的興趣方向。在此場景下,科研人員往往通過自身的研究經驗和適度的相關文獻查詢,即可從推薦的關鍵詞列表中提取自己真正感興趣的主題。因此,用戶對關鍵詞推薦列表的信息處理成本較低,可以推薦較多關鍵詞(如50 或100 個)供用戶參考。
表5 展示了隨機選取的3 個top-50 關鍵詞推薦案例。Robert Whelan 來自愛爾蘭都柏林圣三一大學,本研究方法為其推薦成功的關鍵詞為“沖動行為/生理學”,這個關鍵詞在其訓練集數據中并沒有字面上非常貼近的表述,3 個比較接近的關鍵詞為“前額葉皮層/診斷成像/生理病理學”“延遲貼現/生理學”和“新紋狀體/診斷成像和生理病理學”,因為大腦前額葉皮層受損會導致沖動控制能力降低,紋狀體也和沖動行為的可能性成正相關,而延遲折扣則是研究沖動行為的重要視角之一。這說明本研究模型可以從醫學語義方面對關鍵詞進行理解并推薦。同時,推薦列表中的一部分其他關鍵詞也與Robert Whelan 在測試集中使用的新關鍵詞高度相關,如“神經網絡/診斷成像/生理學/生理病理學”“功能神經成像/方法”“心理/生理學理論”等,分別與作者實際的“神經網絡/診斷成像/生理學”“功能神經成像”“心理/生理學”等非常接近。另外,兩位研究者獲得的關鍵詞推薦列表也有類似現象。例如,美國斯坦福大學計算機科學系的Jure Leskovec,除推薦了與實際使用“RNA 序列分析”“RNA/遺傳學”等高度相關的關鍵詞“序列分析”“RNA/方法”“外顯子”以外,還推薦了與骨關節炎在醫學上高度相關的“樹突狀細胞/免疫學”“T淋巴細胞亞群/免疫學”等,而這些在訓練集上并無直接關聯的關鍵詞,應是綜合研究者的合作關系與關鍵詞使用綜合推薦的結果;日本大阪大學醫學研究生院眼科的Atsuya Miki,在命中“青光眼、開角/診斷成像/生理病理”等關鍵詞之外,還推薦了大量直接包含“青光眼”的關鍵詞,這些應是通過與訓練集中的“眼內壓/生理學”和“房角鏡檢查”在醫學語義上的相關性進行推薦的。由此可見,在本研究方法的關鍵詞推薦過程中,確實能基于醫學語義相關性進行有效的推薦。

表5 關鍵詞推薦舉例
3.3 異質向量空間的語義分析
上述實驗結果證明,本研究方法具有更好的推薦效果,其核心在于使用異質信息網絡表示學習算法metapath2vec 生成的異質向量空間(異質科研興趣空間),這個空間可以同時表示作者之間、關鍵詞之間以及作者與關鍵詞之間富含語義相關性的豐富信息。為了呈現這種語義相關性,本研究重新使用全部數據集,刨除沒有關鍵詞字段的論文以及僅出現一次的作者節點和關鍵詞節點后,構建異質科研興趣空間,并對其中包含的關鍵詞向量與作者向量分別進行可視化與語義分析。本研究使用t-SNE(t-distributed stochastic neighbor embedding) 算法,將關鍵詞向量與作者向量同時映射到二維平面,并結合關鍵詞與作者的特點,進行可視化及相關討論。
3.3.1 關鍵詞向量空間
本研究涉及的所有關鍵詞在異質科研興趣空間中的低維分布如圖3 所示。可以看到,盡管各關鍵詞向量廣泛分散于整個向量空間中,其局部依然展示了非常明顯的聚集現象。語義相近或邏輯相關的關鍵詞會聚集分布在近似的區域,即關鍵詞向量具有“語義聚集”的特點。例如,在圖3 中,空間第二象限框出的幾個關鍵詞均傾向于與“空氣污染(air pollution)”話題相關,這個區域除該關鍵詞本身,還包括“空氣污染物/分析(air pollutants/analysis)”“顆粒物(particulate matter)”“二氧化氮(nitrogen dioxide) ”“氣溶膠/分析(aerosols/analysis) ”以及“氣象學(meteorology)”等。有趣的是,“早產/化學誘導(premature birth/chemically induced) ” 和“環境暴露(environmental exposure)”等關鍵詞也在此區域內。事實上,環境暴露主要是指以各種形式接觸環境中的污染物,而空氣污染是最普遍、影響最廣泛的暴露因素之一。近年來,隨著國內外科學界對空氣污染的關注,在空氣污染暴露與妊娠結局相關性方面,涌現了越來越多的研究,其中包括空氣中各類污染物對早產的影響。在關鍵詞空間的其他區域,也存在著這樣表面看似不相關,卻在科學研究中聯系密切的關鍵詞語義聚集現象。比如,空間最右側框出的“農作物育種”區域,盡管大部分關鍵詞都和農作物種子的分類與培育直接相關,如“種子/分類(seeds/classification) ”和“發芽(germination)”等,但同時也存在著“高光譜成像(hyperspectral imaging)”這樣表面上無關,但在科研語義上高度相關的關鍵詞,這是因為高光譜成像可以在分析種子活性、活力、潛在缺陷、凈度等問題上發揮巨大作用。

圖3 關鍵詞空間
為了進一步研究局部區域中關鍵詞遠近分布的細節特性,本研究選取了圖3 右上側作為示例區域并進行局部放大,研究各個關鍵詞向量的詞義和位置(圖4a)。該區域明顯與遺傳發育相關,除了包括“大腦皮層/細胞學/生長發育(cerebral cortex/cytology/growth & development) ”“哺乳動物胚胎(embryo, mammalian)”這種細胞發育和分化研究中常見的目標細胞類型,還有研究細胞發育與分化時所使用的常見手段,如“基因表達/生理學(gene expression/physiology)”“發育中的基因表達/生理學(gene expression regulation, developmental/physiology)”,也包含了各種蛋白質的遺傳代謝問題,如“轉錄因子/遺傳學/代謝(transcription factors/genetics/metabolism) ”“鈣黏蛋白/遺傳學/代謝(cadherins/genetics/metabolism) ”“同源結構域蛋白質/遺傳學/代謝(homeodomain proteins/genetics/metabolism)”這種蛋白質大類,以及“分化抑制蛋白2/遺傳學/代謝(inhibitor of differentiation protain 2/genetics/metabolism) ”“EphA7 受體/遺傳學/代謝(receptor, EphA7/ genetics/metabolism)”等特定蛋白質。值得注意的是,與遺傳代謝相關的各種蛋白質研究形成了極為密集的聚集現象(圖4b)。與其聚集在一起的是“LIM 同源結構域蛋白(LIM-homeodomain proteins) ”,雖然該主題詞不帶“genetics/metabolism”,但其與同區域的幾種蛋白質都在各種腫瘤演化及進展中扮演了非常重要的角色,這一現象更體現了關鍵詞在科研興趣空間中“語義聚集”的特點。可以看出,雖然局部區域內部的關鍵詞表面上并非十分相似,但從研究興趣、科研問題和研究手段上來看,它們之間有著密不可分的聯系。這種聯系若由研究人員挖掘,則需要大量的時間用于文獻調研和分析,而本研究方法可以自動地發現這些潛在的關聯,在充分節約時間的基礎之上,為研究人員提供更多的靈感,甚至可以讓不熟悉某個領域的新研究者,通過科研興趣空間中特定關鍵詞的局部分布,快速了解整個相關小領域。
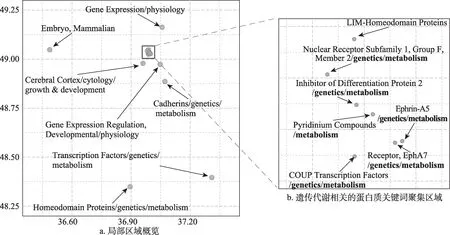
圖4 遺傳發育相關關鍵詞區域示意
3.3.2 作者向量空間
與研究關鍵詞向量空間類似,本研究對科研興趣空間中的作者向量進行可視化分析。為了體現科研興趣視角下的作者向量間關系,考慮到作者文章中包含的關鍵詞能夠在一定程度上反映作者的研究興趣與研究方向,選取了一些整體熱度較高的關鍵詞,并以“是否使用過某關鍵詞”為標準對作者向量空間中的點進行標注,“使用過”為深灰色,反之為淺灰色(圖5、圖6),進而對這些區域進行研究。

圖5 相關主題的作者分布區域差異示例
可以看到,在人類主題相關的研究中(圖5),研究“成年人(adult)”主題的作者主要分布于第二象限,并少量分布于第三象限。相對來說,“青年人(young adult)”作為成年人的子群體,該主題相關的作者分布范圍也是研究“成年人”作者分布范圍的子集,有所不同的是,“青年人”主題的作者分布更偏重于第二象限,而第三象限分布非常少。有趣的是,“中年人(middle aged)”雖然也是成年人的子群體,該主題的研究者分布范圍卻與“成年人”主題研究者形成了交錯趨勢,更偏重于第三象限,且在區域下側明顯聚集了更多的作者,這可能是由于研究“中年人”的作者從興趣上還有一部分傾向于細胞老化的研究話題。
圖6 展示了相同主題下的作者分布與作者研究側重點之間存在的聯系。其中,圖6a 與圖6b 的研究主題均包含“計算機輔助的圖像處理(image processing, computer-assisted)”,兩者唯一的區別為是否具有副主題詞“方法(methods) ”(圖6b),這一微小差異卻使兩個關鍵詞的使用者產生了巨大的差異(分別分布在第二象限與第三象限)。類似地,圖6c 與圖6d 的研究主題均為“核磁共振成像(magnetic resonance imaging) ”,但由于副主題詞“方法(methods)”的存在,兩個關鍵詞的研究者也分別分布于兩個不同的象限區域。可以看到,“計算機輔助的圖像處理”作者的分布范圍,大部分在“核磁共振成像”作者分布的區域子集中,除此之外,僅在第四象限與第三象限下部有小簇聚集,與“核磁共振成像”區域有明顯區別(圖6a、圖6c),這說明目前大部分計算機輔助的圖像處理研究都應用在核磁共振成像數據中。對比圖6b 與圖6d 可以發現,核磁共振成像的方法學研究者分布在第三象限的部分明顯與計算機輔助圖像處理的方法學研究者分布區域重疊。根據上述結果可知,在作者向量空間中,醫學圖像處理領域的方法驅動研究者傾向于分布在第三象限,即使這些研究者的研究主題不同(如一部分研究者研究核磁共振成像,另一部分研究者研究其他種類的圖像處理),他們也可能因各種圖像處理方法學研究的模型理論相關性而聚集在一起。這充分說明了在科研興趣空間中,作者向量分布的語義學意義。
4 結 語
本研究將科研行為數據抽象成具有4 類節點、3類邊的異質信息網絡,使用異質信息網絡表示學習算法metapath2vec 對其進行了嵌入表示,再通過余弦相似度計算向量間的相似度,據此構建了基于異質信息網絡表示學習算法的科研關鍵詞推薦與科研合作者推薦模型。與基線方法的對比結果,驗證了本研究構建的模型在完成科研關鍵詞與科研合作者推薦任務中均具有良好的效果和穩定性,尤其在科研關鍵詞推薦任務方面有著非常強的優勢,這主要得益于本研究更關注科研行為網絡本身的“異質”特性,并使用了相應的異質信息網絡表示算法對其進行處理,合理地挖掘了不同種類節點之間的語義信息。同時,通過對異質信息網絡表示學習算法生成的異質科研興趣空間中作者與關鍵詞的向量進行可視化分析,本研究發現各主體向量表示具有非常明確和合理的語義聚集特點,這些語義特點往往需要研究者耗費大量時間進行文獻閱讀與總結,但本研究方法能夠自動挖掘和發現它們,有助于從研究興趣視角更為快速、深入與準確地理解領域中各個子領域的特點與關聯。
需要說明的是,本研究尚有一些可以改進的方面。比如,作為一項探索性工作,本研究傾向于闡述在雙任務目標的前提下,異質信息網絡表示學習算法相較于同質信息網絡表示學習算法在處理異質信息網絡方面的優勢。本研究使用的metapath2vec僅是眾多異質信息網絡表示算法的典型代表,還有更新的方法值得嘗試。在后續研究中可以對異質信息網絡表示學習算法做進一步改進,構建更適合科研推薦任務的模型,從而進一步提升推薦效果。此外,本研究僅考慮了作者、論文、關鍵詞、機構4種較為基礎的科研主體及其之間的關系,未來可考慮引入更多樣的科研主體(如文獻出版物、發表時間等),以進一步豐富對科研行為的研究與探索。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
兒童故事畫報(2019年5期)2019-05-26 14:26:14
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
