技術機會發現領域專利挖掘方法研究述評
2023-11-21 09:48:52韋婷婷馮丹鈺宋世領張建桃
情報學報 2023年10期
韋婷婷,馮丹鈺,宋世領,張建桃
(華南農業大學數學與信息學院,廣州 510642)
0 引 言
隨著新一輪科技革命的到來,各國企業面臨著急需加大自主創新、提供具有競爭性和差異化的產品、主動適應全球競爭格局等關鍵問題。技術機會發現(technology opportunities discovery,TOD),又稱為技術機會分析(technology opportunities analysis,TOA),可通過專利挖掘方法發現新的技術動向,推斷該領域可能出現的技術形態或技術發展點,從而幫助研究人員識別、推導和評估新技術理念,對于企業技術創新、產業發展具有重要的戰略意義[1-2]。
早期的技術機會發現相關研究通常采用德爾菲法、層次分析法和情景規劃等定性分析方法,分析結果受專家的經驗和領域知識的影響較大[1]。隨后的研究將文獻計量、專利分析與專家意見相結合進行定量分析,發現可獲得更客觀的結果,但輸出的領域技術機會粒度較大[3]。隨著人工智能技術的發展,技術機會發現的方法也經歷了一系列變革,近年來的相關研究將自然語言處理與機器學習、復雜網絡分析等方法相結合進行定量分析,以期在降低專家依賴的影響的同時得到更具細粒度的分析結果。
圖1 為技術機會發現方法的一般流程。首先,選取數據源并進行數據預處理;其次,根據IPC(international patent classification) 共現關系或專利引用關系構建技術網絡,或根據技術功效屬性的層次等級(高/低,強/弱)構建技術形態矩陣,建立技術知識的結構化表示;最后,通過挖掘專利技術集群或技術形態矩陣識別潛在的技術機會。
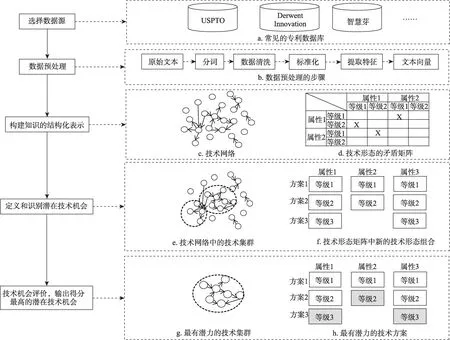
圖1 技術機會發現方法流程圖
目前技術機會發現研究領域已引起國內外學界的廣泛關注,積累了大量研究成果,因此,對其分析方法進行梳理顯得十分必要。然而,只有少數學者從特定角度對技術機會發現方法進行綜述。例如,伊惠芳等[4]基于技術創新要素,從知識基礎以及創新的環境、方式和類型4 個維度總結相關研究;任海英等[3]根據不同的主體指向性,將技術機會分為領域技術機會和研發機會兩大類;蘇娜平等[5]總結了目前技術機會分析的主要方法,如基于專利地圖的方法、基于形態學分析的方法和基于科技關聯的方法等,并指出目前技術機會發現方法的局限性在于數據源相對單一、多為靜態分析以及缺乏完善的技術機會評價體系;Lee[6]指出,目前TOA 的研究熱點包括從專利文本中提取技術信息、基于TOA 尋找新的技術靈感和目標技術領域推薦。
盡管國內外圍繞技術機會發現的研究范圍、研究對象和研究方法進行了大量的梳理,然而隨著人工智能技術的不斷發展及其在各個領域的滲透,技術機會發現的方法手段也在發生變化。因此,亟須梳理目前最新的應用進展,尤其是深度學習與自然語言處理相結合的專利挖掘方法在技術機會發現中的重要應用,從技術前沿追蹤視角對近年來國內外技術機會發現領域的研究方法進行總結,幫助研究人員厘清分析方法與研究內容的適配關系,為該領域開展后續相關研究和實踐的技術選型提供參考依據。
1 技術機會發現中的專利挖掘方法
由于以專利文獻作為技術機會發現的數據基石,技術機會發現的相關研究通常采用專利挖掘與分析方法。本文根據技術機會發現領域包含的各子任務所需的底層共性分析方法,將專利挖掘在技術機會發現領域的應用分為5 個方面:專利知識表示、專利相似度計算、專利聚類、技術主題識別和鏈路預測。下文將詳細闡述這些方法的應用研究現狀。
1.1 專利知識表示
專利知識表示是指將專利知識單元進行編碼,以便于計算機的識別與處理。表1 總結了現有文獻中常見的模型及其代表性研究。
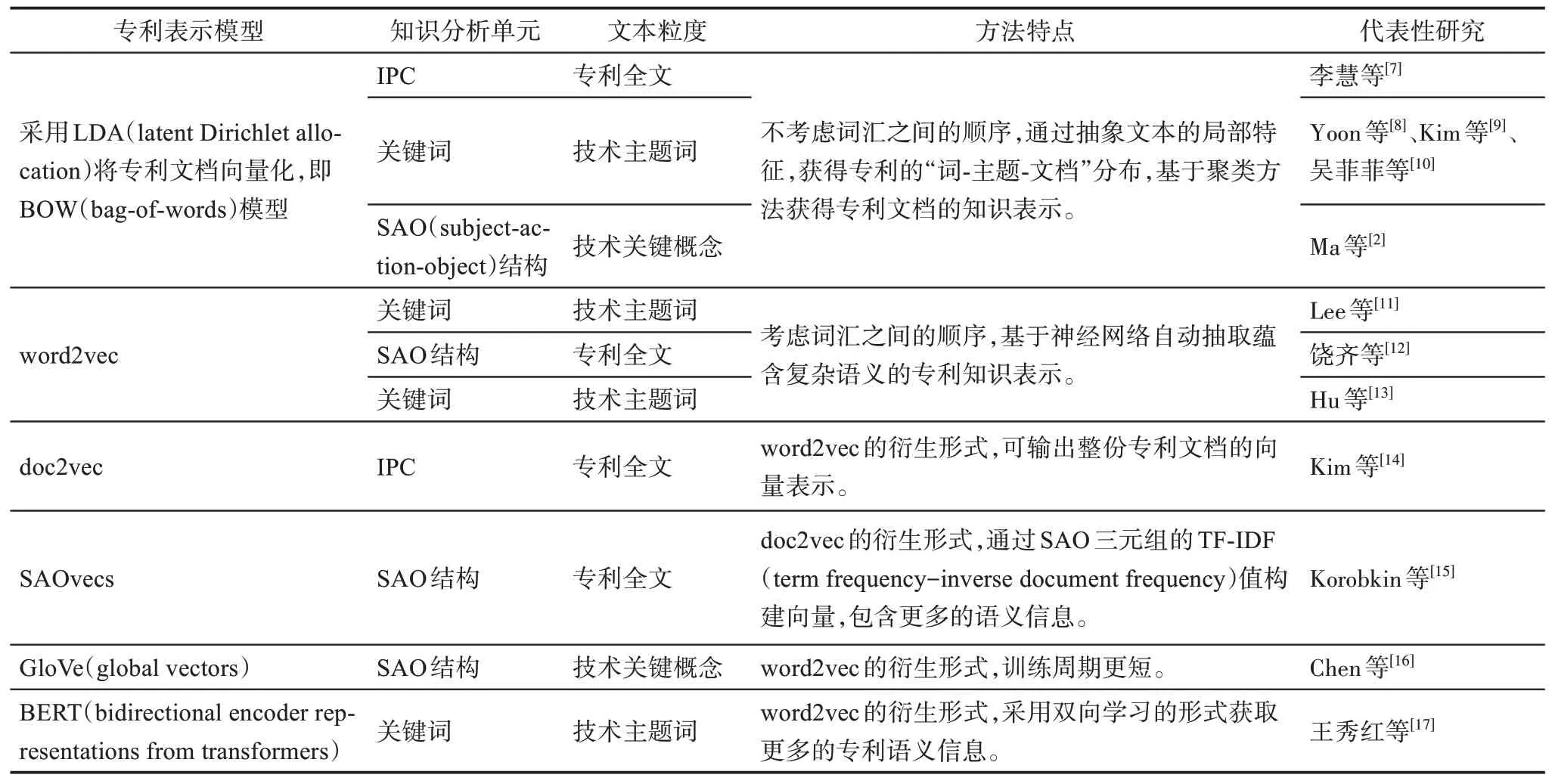
表1 專利知識表示部分代表性模型
專利知識表示模型可劃分為離散式表示模型和分布式表示模型兩類[18]。早期研究通常采用離散式表示模型,即基于專利中術語的出現頻率獲得專利的知識表示向量。詞袋模型(BOW)是一種經典的離散式表示模型,其通常與潛在狄利克雷分布(LDA)算法結合使用,直接輸出文本向量表示和主題詞概率分布,再進行后續的分析。李慧等[7]采用LDA 算法從專利樣本中獲取技術主題,再結合IPC 共現和共類關系構建技術網絡,通過將主題詞概率分布與IPC 分類號的各級含義對比驗證,可以更準確地表示領域內的核心技術。Kim 等[9]將專利中術語的TF-IDF 矩陣輸入LDA 模型,用輸出的每份專利主題分布向量表示其技術類別。Ma 等[2]采用LDA 獲得了各技術主題內關鍵術語分布,通過分析關鍵術語之間的SAO 結構,將句子結構信息視為技術關聯的表示,探索技術主題之間的潛在聯系。離散式表示模型是將專利的局部對象(詞或短語)作為特征進行抽象以表示專利的含義。
分布式表示模型則是將詞的語義分布式地存儲在各個維度中,彌補了離散式模型并未考慮上下文單詞之間的相互關聯關系且不適用于表征長文本的缺點。在自然語言處理領域,代表性的分布式表示模型有word2vec[19]、doc2vec[20]、GloVe[21]和BERT[22]模型,這些模型也都被引入專利文本表示當中。
在word2vec 模型的應用方面,Lee 等[11]采用包含輸入層、隱藏層和輸出層的三層神經網絡獲得專利的word2vec 詞向量,并基于詞向量的相似度建立產品地圖,將產品地圖視為專利產品的知識表示。Zhu 等[23]采用圖卷積網絡(graph convolutional network,GCN)獲得了專利文本的關鍵詞向量表示,解決了先前基于詞向量的方法不能表示專利與技術領域之間語義關系的問題。饒齊等[12]直接采用開源工具獲得專利的word2vec 詞向量,比較了word2vec詞向量與基于詞袋模型的詞向量在中文專利SAO 結構抽取任務中的表現,并驗證了將詞向量用于關系抽取的可行性。
doc2vec 模型在word2vec 模型的基礎上增加一個段落ID(identifier)特征向量,可用于獲得整份專利文檔的向量化表示。Kim 等[14]采用dco2vec 模型獲得了每個技術領域的專利文檔向量,從專利全文本的視角研究分屬不同技術領域的一對IPC 分類號之間的語義相似性。Kim 等[24]利用專利文本的SAO 結構和詞向量更新,通過doc2vec 模型得到句向量,此步驟提高了SAO 結構中單詞間的余弦相似度,可以更好地反映專利的技術要素和上下文語義。Korobkin 等[15]基于詞頻、上下文語義和句子結構信息學習專利的SAOvecs 向量,提升了后續執行專利聚類、識別核心技術和熱點技術的準確性。
GloVe 和BERT 也屬于word2vec 的衍生模型。GloVe 可獲得比傳統的word2vec 模型更充分的全局信息。Chen 等[16]采用GloVe 模型,基于全局詞共現生成專利向量,在語義信息抽取任務中能以更短的訓練周期取得比word2vec 模型更好的效果。BERT模型則通過雙向的學習方式更深度地學習詞匯的上下文,僅需采用具體任務的數據集對通用BERT 模型的最后一層進行微調,就能夠被應用于很多實際任務[25]。林原等[26]通過微調使BERT 模型能夠包含更多的領域知識,獲得更能精確表達語義的文本表示。王秀紅等[17]采用BERT 模型獲得了專利文本的詞向量、文本向量和位置向量,再將通過BERT 訓練的向量與采用LDA 獲得的專利主題向量拼接,最終獲取了包含豐富語法和語義信息的專利知識表示。
在專利文本表示的對象中,專利的知識單元包括專利的IPC 分類號、關鍵詞和SAO 結構。其中,IPC 分類號和關鍵詞所包含的語義信息較弱,無法準確表示專利之間的關系[7,27];而SAO 結構是“主語-謂語-賓語”形式的三元組,在專利技術信息的表示上更具細粒度。因此,以IPC 分類號和關鍵詞作為基礎知識單元的通常是那些僅考慮結構化數據和詞頻概率分布的任務,如基于LDA 的專利聚類和主題識別[2];SAO 結構常被應用于考慮語義關系、對深度和精準度有要求的專利文本挖掘任務中[28]。
總體而言,在表示方法層面,分布式表示模型所取得的性能優勢使其已逐漸取代離散式模型成為目前主流的專利文本表示方法;在分析對象方面,現有研究很少將整篇專利文檔向量化,一般僅提取文檔中可以有效表示技術知識的部分,如關鍵詞或專業術語等[8-9]。
1.2 專利相似度計算
基于專利文本進行相似度計算能夠獲取技術間相似程度,可用于展示技術發展的脈絡、現狀和趨勢,為技術機會發現提供分析基礎。該環節的一般流程:先將專利轉化為詞、短語或句子的表示向量,再采用一些度量指標計算專利之間的相似度。
在專利文本表示方面,如1.1 節所提方法,專利相似度計算中主要采用了詞袋表示法、主題表示法和分布式表示法。其中,基于詞袋表示的方法僅利用簡單的文本統計信息計算技術之間的相似度;基于主題表示的方法考慮了詞共現信息,包含一定的語義;基于分布式表示的方法則是在融合了更多文本語義特征的基礎上進行相似度計算[29]。
在相似度的度量方法上,經典的方法是余弦相似度計算法。例如,專利A和專利B之間余弦相似度的計算公式為
其中,fAi表示專利A的向量的第i個元素;fBi表示專利B的向量的第i個元素。兩個向量之間夾角的余弦值越接近1,則兩份專利的相似度越高。
另一種常用的專利相似度度量指標是Jaccard 指數,即將兩份專利中相同關鍵詞的數量除以兩份文本的關鍵詞總和得出的值,計算公式為
其中,NA1B1表示同時存在于向量A→和向量B→中的元素;NA1B0表示存在于向量A→但不存在于向量B→中的元素;NA0B1表示不存在于向量A→但存在于向量B→中的元素。Jaccard 指數的取值范圍是0~1,值越大,相似度越高[30]。
在實際應用中,Song 等[1]利用專利關鍵詞向量之間的余弦值表示對應兩項技術的相似度,通過識別出與目標技術專利相似術語最多的其他領域專利文檔,找到改進目標技術的解決思路以及潛在的技術融合機會。Arts 等[30]通過計算專利關鍵詞之間的Jaccard 值測度專利所代表的技術之間的相似性,為從業者評估專利新穎性、尋找技術機會提供幫助。劉俊婉等[31]將Jaccard 指數作為相似度指標,用于測度專利技術主題詞共現的強度,以發現新興主題產生關聯的機會。Lee 等[11]基于具有相似技術基礎的產品彼此靠近的假設,根據word2vec 詞向量之間的余弦距離建立了“專利-產品”網絡,基于此確定目前公司有能力進入的新產品領域,即潛在的技術機會。席笑文等[32]將word2vec 詞向量與LDA 主題向量拼接,通過拼接向量之間的余弦相似度測度專利權人之間技術產出的相似性,以幫助技術主體識別潛在的競爭關系或合作機會。Zhang 等[33]基于余弦相似度計算尋找關聯的LDA 主題向量,結合專利發布時間軸獲取區塊鏈領域中各項子技術演變的軌跡,發現了當前的熱點主題、突破性主題和空白主題,其中熱點主題被視為最有前景的技術機會,突破性主題被視為有潛力的技術機會。
總之,現有研究采取的相似度度量指標比較固定,但是在技術挖掘層面根據其具體應用選擇不同的方法模型,其中詞向量與LDA 模型相結合的挖掘方法呈流行趨勢。
1.3 專利聚類
專利聚類的核心思想是將高維的原始文本數據投射到低維空間,使相似的數據樣本盡可能地集中,而不相似的樣本則盡可能地分散。專利聚類的結果常被用于識別該領域的關鍵技術集群、構建技術網絡、識別離群專利等,對于把握技術發展的態勢具有重要意義,為技術機會發現提供直觀的分析依據。
根據專利知識的使用,專利聚類方法可以分為基于IPC 代碼的聚類、基于專利主題的聚類以及基于功能信息的聚類[34]等幾大類。常用的聚類算法包括主成分分析(principal components analysis,PCA)、k均值聚類算法(k-means clustering algorithm,kmeans)和LDA 模型。此外,還有LDA 的變形模型,如標簽化的多重混合狄利克雷模型(labeled Dirichlet multi mixture model,LDMM) 的半監督聚類模型。表2 總結了現有文獻中常用的聚類算法及其應用領域。
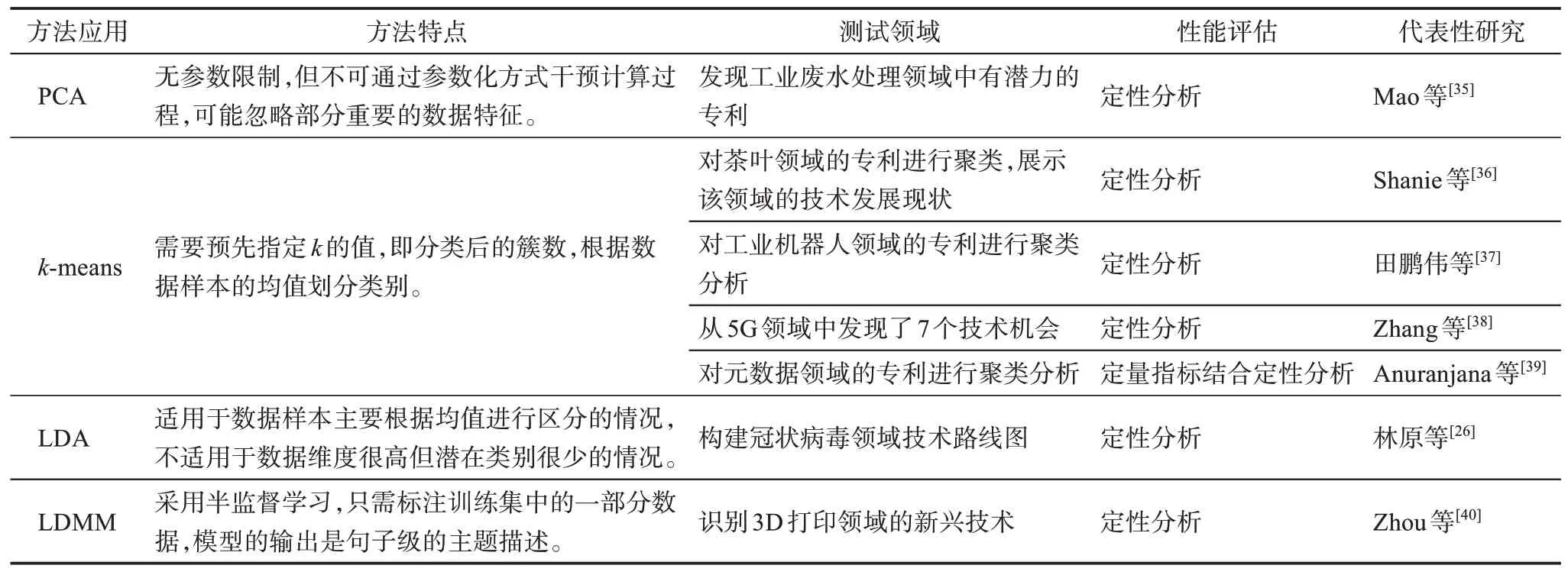
表2 常見的聚類算法
各聚類算法中,PCA 的特點是不需要輸入參數,使用較為簡便;k-means 需要預先設定集群的類別[38];LDA 則基于主題的分布劃分集群,例如,李慧等[7]采用LDA 獲得特定IPC 碼類別下的專利主題詞聚類,綜合專利文本的結構化特征和非結構化特征對該領域中的核心技術演化軌跡和趨勢進行分析。LDMM 采用半監督方式學習數據特征,Zhou等[40]采用LDMM 獲得了專利的句子級表示,解決了有監督模型泛化能力不強和無監督學習模型不精確的問題,能夠更好地識別新興技術。除了應用算法,有些研究采取更直接的聚類方式,如Arts 等[30]根據專利關鍵詞的共現程度判斷技術之間的相似度,以此作為技術聚類的依據。此外,由于聚類結果呈現的是數據集中的專利被劃分到不同的技術集群,因此,集群間的空隙、異常專利或離群專利也可被視為技術機會的表示[41]。目前已有一些研究采取了通過離群計算的方式進行技術機會分析。例如,Jeon 等[42]計算每份專利的局部離群因子(local outlier factor,LOF)值,從而得到專利的新穎度,識別出有潛力的新專利;Wang 等[43]則通過計算專利的LOF 值來尋找相似的專利集合。
目前,基于專利文本的聚類算法其測試領域較為多樣化,但由于缺乏統一標準的公開測試集,聚類結果的性能評估通常以定性分析為主。因此,無法公平地對聚類算法進行統一評估,只能根據具體應用領域的需求特點選擇更適配的專利聚類算法。未來可以從定量和定性相結合評估的角度針對性地提出技術機會發現中專利聚類的統一模型框架,從而提升技術機會發現領域其分析結果的可靠性。
1.4 技術主題識別
技術主題一般是指某技術領域的關鍵技術或子領域的關鍵技術[44]。主題識別旨在獲取技術領域中核心或熱門的技術主題,進而幫助把握技術發展態勢和發掘技術機會。
技術主題識別的經典方法是LDA 模型。LDA模型是一種基于概率和統計方法的主題模型,能夠從文本中提取出潛在的主題[45],是由“詞-主題-文檔”構成的三層貝葉斯概率模型。表3 列舉了技術機會發現領域中LDA 的部分應用實例。
從方法本身而言,LDA 可以根據詞頻最高的詞組得出潛在的主題,但沒有考慮語義和詞頻以外的信息。因此,部分文獻采用統計學方法對LDA 進行優化。比如,呂璐成等[46]將非負矩陣分解模型與LDA 結合,把主題識別任務轉換為解決約束最優化的統計學問題,提升了動態識別專利主題的模型性能。此外,考慮到專利的主題詞有時并不是獨立的詞匯,而是由2~3 個詞匯組成的短語。馬建紅等[27]通過雙向長短時記憶網絡-條件隨機場模型抽取出專利短語后,采用經廣義波利亞甕模型(generalized Pólya urn)引入先驗知識后的LDA 模型進行主題短語抽取。該方法既解決了基于短語的主題模型常出現的稀疏性問題,又具備比傳統主題模型更高的可讀性和判別性。
除了上述兩種從LDA 的性能上提升主題識別準確度的做法之外,有文獻將LDA 的結果與其他方法的結果相結合,以期在后續任務中取得更好的效果。例如,王秀紅等[17]將通過BERT 獲得的語義特征向量與采用LDA 獲得的主題特征向量結合,彌補了單一LDA 模型缺乏上下文語義信息的局限性,在后續的專利聚類任務中取得了更具準確性和細粒度的結果。Kim 等[49]將LDA 與網絡分析方法結合,通過鏈路預測從主題關鍵詞網絡中尋找技術機會。該方法實現了對LDA 輸出的技術主題之間關系的挖掘,能更好地輔助技術機會發現。
在主題分析對象上,LDA 的分析對象通常為專利的部分文本,如摘要或權利聲明,或者專利的引用網絡。基于純文本(摘要或權利聲明)的主題識別主要利用文本內元素的共現信息;基于所有權人關系網絡和引用關系網絡的相關研究兼顧了專利文本的內部語義和每份專利文本與外部世界的信息交互。在進行主題識別時,若有多個分析對象,則根據需要對這些對象設置一定的權重比例。例如,Ma 等[2]根據經驗將標題和摘要的權重設置為2∶1,其在后續研究中還將探索不同權重比例對識別結果的影響。
在實際應用中,Kim 等[9]將LDA 主題詞分布與引用網絡結合,通過可視化3D 打印領域中各技術集群內專利間的繼承關系監測技術發展的軌跡,發現技術開發機會。該方法基于LDA 主題分布確定專利所屬的技術主題集群。Choi 等[50]將技術主題的類型設置為主導型、新興型、飽和型和下降型4類,采用LDA 分析物流領域專利的摘要,發現與數據庫和傳感器子相關的通常為新興型主題,這意味著數據獲取和數據分析可能是物流領域未來的技術熱點,即有潛力的技術開發機會。此外,該項研究證明了當無法用某幾個美國專利分類(United States patent classification,USPC)中子類的主題詞完全覆蓋該領域的專利主題時,可用LDA 主題模型的結果進行補充,以開展更全面的領域技術發展現狀分析。韓芳等[51]采用LDA 識別出太陽能光伏領域中12 個擁有突破性創新潛力的技術主題,即有前景的技術開發方向。該方法具有比基于共詞分析或向量空間模型的主題識別方法更低的算法復雜度。
技術主題識別的結果還可以通過可視化的方式呈現,可視化工具諸如LDAvis[33]、Gephi 軟件[32]和t-SNE 算法[7,52]可被用于直觀展示技術主題識別的結果。但是,主題模型的可視化往往僅能展示技術的動態演化過程,無法識別和預測技術的突變和融合。
總體而言,技術主題識別容易受所提取的術語和特征選擇技術的影響,難以取得較好的性能。改進的方向之一是優化專利文本的向量表示,比如,劉小玲等[53]在構建文本向量時將專利的文本內容、引用關系和分類號信息3 個屬性進行了融合,提升了專利向量表示的準確性。除了增強專利知識,未來可以從聯合模型的層面考慮,利用模型之間相互知識補充的原理將有利于主題的精準識別,這類方法在技術機會發現領域尚處于初始探索階段,具有很大的改善空間。
1.5 鏈路預測
在技術機會發現領域,實施鏈路預測的目的主要是預測技術發展的趨勢,找到潛在的技術機會。鏈路預測的數據基礎是技術網絡,即先構建一個以節點代表技術、以邊代表技術之間關聯關系的網絡,再通過已知的技術網絡拓撲結構如技術節點和鏈接的特征,預測網絡中尚未連接的兩個技術節點之間產生鏈接的可能性[54]。圖2 為在技術網絡中開展靜態鏈路預測的示意圖。鏈路預測的方法可以劃分為基于相似度、基于社會網絡分析和基于機器學習三大類。表4 總結了技術機會發現領域常用的鏈路預測方法。
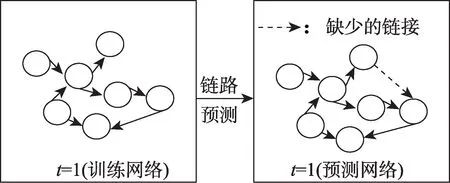
圖2 靜態鏈路預測示意圖
基于相似度的鏈路預測通常采用Jaccard 指標、Adamic-Adar (AA) 指標、共同鄰居算法(common neighbors,CN)、優先依附算法(preferential attachment,PA)等相似度指標或算法預測可能出現的鏈接。Seo[55]將上述4 種方法結合用于鏈路預測,減少了計算過程中的信息丟失。Han 等[56]采用局部隨機游走(local random walk,LRW) 算法獲得技術節點的特征向量,與上述4 種方法相比,LRW 算法準確度更高。
基于社會網絡分析的鏈路預測通常采用邊緣中介中心性、度中心性、接近中心性等指標,根據技術網絡的結構特征進行預測。比如,Park 等[58]采用基于邊緣中介中心性的方法預測可能出現的跨領域知識流,用經過技術節點的最短路徑數量刻畫該節點在技術網絡中的重要性。
上述兩類方法皆是對技術網絡的全局或局部特征展開定量分析,不能充分挖掘網絡的深層信息。基于機器學習的方法能夠更好地獲取技術網絡中節點和連邊的屬性和結構信息。涉及機器學習的方法包括基于統計的機器學習模型,如決策樹(DT)、隨機森林(RF)、支持向量機(SVM)和k-近鄰算法(k-nearest neighbor,kNN)等[62];還包含基于深度學習的模型,如長短時記憶網絡(long short term memory networks,LSTM)、圖卷積網絡(GCN)。Yoon 等[54]采用基于SVM 的鏈路預測模型,預測專利網絡中可能出現的新節點;Cho 等[57]采用基于DT方法預測可能出現的IPC 共現;Kim 等[14]采用基于RF 的方法預測可能出現的技術融合。基于深度學習的方法在獲取足夠特征信息的同時能夠降低對專家領域知識的依賴度[25]。Nakai 等[63]采用LSTM 預測專利網絡中引文規模增長的趨勢;Qi 等[61]采用GCN 將復雜的專家-機構網絡簡化為圖的形式,預測專家合作關系;Zhu 等[23]采用GCN 獲得專利文本的低維知識表示,結合兩個能反映專利與技術領域的語義親密度的指標——技術特征向量和強度坐標,來預測技術融合。
鏈路預測的應用主要有以下幾個拓展方向。首先,需度量技術主體的內在能力是否足以實現該技術機會。例如,Seo[55]通過基于LDA 的鏈路預測發現技術主題網絡中近期可能出現的新鏈接,然后采用關聯規則分析生成技術主題之間有方向和權重的鏈接,找到與企業的能力相匹配的技術機會。其次,許多模型僅考慮生成的鏈路方向,沒有保留網絡的拓撲結構信息。Chen 等[64]采用PageRank 計算節點的影響得分,捕捉網絡的全局結構信息,然后采用非對稱鏈路聚類計算協同系數得分,獲得網絡的局部結構信息,最后在非負矩陣分解模型中聯合優化這兩個參數,使模型同時保留局部和全局信息。此外,除了從技術的角度挖掘有潛力的技術機會,鏈路預測還可在合作網絡中挖掘潛在的合作者關系。比如,Qi 等[61]采用基于GCN 的鏈路預測識別論文和專利作者所屬機構的合作網絡中缺失的鏈接,以此作為潛在的合作機會。
目前,在鏈路預測的相關研究中,基于圖卷積網絡(GCN)的方法能夠更全面、更深層次地挖掘技術網絡所隱含的信息,極大地提升了預測性能,這將成為一個重要趨勢。
2 結果與討論
本文通過系統性回顧相關文獻,總結了專利知識表示、專利相似度計算、專利聚類、技術主題識別和鏈路預測5 類技術機會發現中的底層共性分析方法的應用現狀。圖3 是上述方法在技術機會發現領域應用的結構圖,將5 類方法與相關業務結合,以期能夠從全局的視角展示各類方法與技術機會發現流程中各階段任務的適配性。
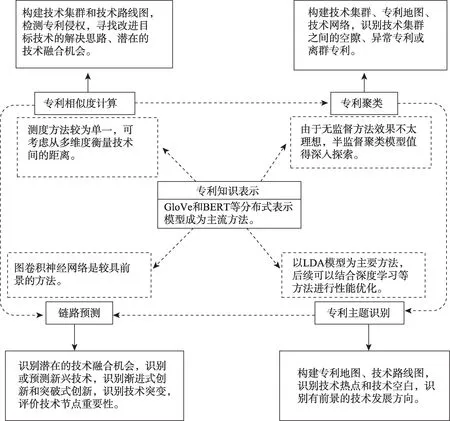
圖3 專利挖掘方法在TOD領域的應用結構圖
(1)專利知識表示具有關鍵性作用
在技術機會發現方法的一般流程中,專利知識表示主要應用于數據預處理和構建知識的結構化表示,是后續分析的基礎數據。因此,選擇何種類型的專利知識以及如何準確地將知識進行表示,對技術機會發現的有效性具有關鍵性作用。目前沿用的分布式表示模型是通用領域中的文本表示方法,但是針對領域術語較多、語義復雜的專利文本表示尚未發現相關研究。未來研究可以集中于普通文本和專利文本的具體差異和聯系,深入探索更好的專利文本表示模型。
(2)技術機會定義決定方法選擇
從圖3 可以看出,盡管專利相似度計算方法、專利聚類方法、技術主題識別方法和鏈路預測方法均可以達到技術機會發現的目的,但是各研究根據技術機會內涵的不同定義而選擇不同的底層分析方法。上述4 種類型挖掘方法的應用場景各自具有相應的側重點。
專利相似度計算通常用于技術機會發現領域的各個子任務,它在尋找相似技術解決方案上具有一定優勢。例如,專利相似度計算通過識別其他領域中與目標專利相似度最大的專利,可以找到改進目標技術的解決方案以及發現目標技術與其他領域的技術發生融合的機會。除了傳統的余弦相似度計算之外,目前有些研究利用深度學習模型進行專利之間的自動距離測量,但是需要一定量的標注數據。
專利聚類方法的主要目的是自動發現技術集群,在大規模數據場景下,該方法相比于專利相似度計算方法更為靈活,但是其效果易受數據樣本不均衡的影響。根據聚類輸出結果,可以將專利數量龐大的技術集群視為當前的技術熱點,將集群之間的空隙視為有待開發的技術空白區域,將明顯獨立于集群的專利視為可能發生技術突變的異常或離群專利。該方法可用于基于離群點檢測的技術機會發現上。但是,目前的聚類手段仍是傳統的機器學習方法為主,雖然無監督的方式避免了數據標注的問題,但是技術集群中也包含了大量噪聲數據,不利于技術機會的發現。
專利主題識別方法基于專利之間主題的關聯度構建技術集群,它將與大量技術主題有關聯的目標主題視為技術熱點,找尋有前景的技術開發或融合方向。目前的方法以LDA 模型為主,該方法的底層思想是從詞共現角度識別專利技術主題,對于領域術語多樣復雜的專利文本而言,其效果仍有待提升。盡管有將LDA 與其他深度學習模型結合使用的相關研究工作,但是目前仍處于探索階段,在其他子任務的適用性方面還有待考究。
相比于前幾類方法,鏈路預測方法更貼近面向未來的技術預測這個內涵。其通過預測技術網絡中缺失或即將出現的鏈接,識別潛在的技術融合機會,也能識別可通過歷史數據預測到的漸進式創新,找到目標技術的改進機會。此類方法也可通過預測技術網絡中空白區域新出現的鏈接和節點,識別可能的技術突變和突破式創新,尋找將在目標技術領域引起重大變革的技術機會。此外,部分文獻將通過鏈路預測獲得的邊的權重與關聯規則分析或綜合評價指標結合,評價技術機會的前景和可行性。從現有研究工作來看,圖神經網絡方法逐漸引起相關研究人員的關注,將成為具前景的熱門方法之一。
綜上所述,在進行技術機會分析時,往往需要根據通用流程中各個步驟的具體業務,選擇合適的方法。其中,預處理階段的方法最為模式化,通常采用專利知識表示的模型,輸出專利文本向量。知識結構化表示的建模方法較為豐富,主要用于構建技術網絡或技術路線圖,此類方法的輸出對技術機會發現的結果影響較大。現有文獻對技術機會的定義各不相同,包括但不限于技術熱點、技術空白、跨領域的技術融合等,因此,可應用于技術機會識別階段的方法及其應用形式也最為多樣。專利相似度計算方法可用于找尋與目標技術相關的改進和融合機會,專利聚類方法和專利主題識別方法可用于找尋技術熱點和技術集群之間的空隙,鏈路預測方法可用于識別和預測技術融合,也有文獻選用兩種以上的方法構建混合模型,以達到更優的識別效果。目前,適用于技術機會評價階段的方法主要是基于鏈路預測的權重計算或評價指標,形式較為單一且未能形成規范的評價體系。有效的評價方法將能夠反過來促進專利挖掘方法的進一步改善。未來有前景的研究方向包括優化專利的知識表示、探索效果更好的技術機會識別模型,以及在技術機會的評價階段應用更多樣的方法。
3 面臨的挑戰
總結現有文獻,目前在技術機會發現領域有關專利挖掘方法的應用主要存在以下幾個有待解決的問題。
(1)專利全文本分析方法有待挖掘。鮮少文獻采用整份專利文本作為研究對象,大部分文獻僅采用專利的標題和摘要作為語義分析對象。部分專利挖掘任務相關的研究考慮到了權利要求書中權利要求人之間的關系[65],但受限于算法效率和硬件算力,對于專利其他部分,如屬于長文本的說明書,開展分析的難度依然較大。
(2)用于分析的文本知識結構較單一。現有研究的知識分析單元包括IPC 分類號、關鍵詞、SAO結構等。其中,SAO 結構的提取需要預先設置技術關鍵詞,即需要充足的領域知識作為支撐,但仍可能忽略有價值的技術知識。基于IPC 分類號和關鍵詞的文本分析所包含的技術信息較為寬泛,難以識別出具體的技術機會。目前,大部分文獻僅基于專利文本結構的某一類技術要素展開分析,未來的拓展方向之一是基于混合的文本知識結構展開分析。值得注意的是,有時將兩類知識分析單元關聯起來的做法可能使分析結果變得模糊和不準確[54]。
(3)技術主題識別方法具主觀性。技術機會的表征主要由技術主題關鍵詞構成,然而在現有的主流方法中,關鍵詞的提取高度依賴于專業領域詞典,并且在提煉技術機會的過程中需要人工定義技術主題的具體名稱和內涵,主觀成分較大。缺乏客觀及普適性的挖掘方法將難以保證結果的可靠性。
(4)檢驗技術機會的方法有待完善。現有文獻對技術機會的檢驗過程常常是不充分的,模型的輸出結果并不一定就是技術機會,因此,需要設計諸如專利被引量、被引量增長率、專利與相關聚類集群相連的節點數等驗證指標[66]作為補充。
4 改進思路
基于技術機會發現的流程、各類方法的應用現狀及當前研究所面臨的挑戰,本文提出了一些應用創新方面的切入點,如圖4 所示。
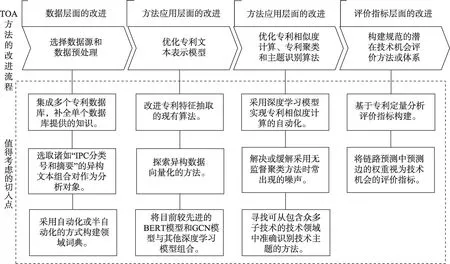
圖4 專利挖掘方法應用創新的思路圖
(1)數據層面的改進。數據層面的改進主要是選用內涵信息更豐富的專利對象。涉及多源異構專利數據的研究是近年的熱點,主要通過集成多個專利數據庫并選取不同結構的文本分析對象,從而實現較為全面、深入的分析。此外,鑒于專利主題識別對領域詞典的高度依賴,領域詞典的自動化或半自動化構建將是未來發展趨勢之一。
(2)方法應用層面的改進。方法應用層面的改進主要是對算法本身進行優化,探索組合模型在不同應用場景中的適用性,以及尋找能解決現有問題的新方法。比如,提出可將異構數據向量化的新方法,探索更新穎的文本表示模型,探索BERT、GCN 及其衍生模型與傳統機器學習模型組合后在專利特征抽取、專利相似度計算、專利主題識別、鏈路預測等任務中的適用性。此外,可從無監督聚類方法角度,嘗試緩解或消除噪聲,以實現不需要主題詞表的專利聚類,尋找可以快速處理大規模復雜數據的新方法。
(3)評價指標層面的改進。評價指標層面的改進主要是提出具有實踐價值的技術機會評價體系。可根據現有研究中常見的社會網絡分析指標、文獻計量指標、專利質量評價指標等,構建一套較完整的技術機會評價體系;還可采用GCN 模型預測技術關系,以被預測邊的權重作為技術機會的評價指標[61]。
5 結 語
本文對技術機會發現領域中的專利挖掘方法應用進行了文獻綜述,總結了該領域底層共性的專利挖掘方法在整個技術機會發現方法流程中的研究現狀,構建了研究方法和該領域研究子任務的適配結構圖,提出該領域面臨的方法上的挑戰,并提出了幾點改進思路。
在人工智能、大數據技術背景下,未來希望研究者們可以共同豐富專利挖掘對象的內涵,優化專利特征抽取算法,實現大規模領域專利數據集的規范化構建,探索先進的文本表示模型和圖卷積網絡模型與其他模型組合后在各類專利挖掘任務中的表現,從而能夠更好地借鑒目前前沿的深度學習思想,對技術機會發現領域提出針對性的改進方法,并完善技術機會發現定性和定量相結合的統一評價體系,增強技術機會發現結果的有效性和可靠性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
