基于改進YOLO v4和ICNet的番茄串檢測模型
2023-11-23 04:37:50劉建航何鑒恒陳海華王曉政翟海濱
農業機械學報 2023年10期
劉建航 何鑒恒 陳海華 王曉政 翟海濱
(1.中國石油大學(華東)海洋與空間信息學院, 青島 266555; 2.中國科學院計算技術研究所, 北京 100094;3.國家計算機網絡應急技術處理協調中心, 北京 100029)
0 引言
我國農作物采摘主要以手工為主,采摘工作季節性強、勞動強度大、成本高[1]。隨著人工智能和農業機械相互結合,使農作物采摘智能化成為可能,采摘機器人在提高采摘率、推動現代化農業發展等方面具有重要意義[2]。
番茄作為中國種植的主要經濟作物,其采收方式分為粒收與串收,串收有著較高的采摘效率,并且串收番茄更容易保存和運輸。快速且精確地采摘番茄串是目前串型番茄采摘機器人的重點研究內容。番茄串檢測以及番茄莖定位主要通過計算機視覺實現。因此,視覺感知系統的性能直接影響番茄串的采摘率[3]。文獻[4]采用顏色分量運算和彩色空間轉換實現圖像閾值分割和目標特征提取,同時對末端執行器進行了設計,實現了串型番茄的采摘,但采摘時間較長,成熟番茄串果實識別成功率為90%。文獻[5]借鑒AdaBoost學習算法在人臉識別中的成功應用[6-7],提出了基于Haar-like特征及其編碼和AdaBoost學習算法的番茄識別方法。實驗結果表明,單幅圖像的處理時間為15 s,正確識別率為93%。文獻[8]提出使用Mask R-CNN模型對果園中重疊綠色蘋果進行識別和分割,將殘差網絡與密集連接卷積網絡相結合作為骨干網絡提取特征,對120幅蘋果圖像進行檢測,結果表明,平均檢測準確率為97.31%,但由于數據集太少,仍需增加樣本集和豐富樣本多樣性以更具說服力。文獻[9]使用雙目視覺技術對番茄進行識別,根據番茄顏色特征用擬合曲線對番茄分割,并通過雙目視覺測量原理計算出番茄的三維坐標,測量誤差低于4%,但仍有待進一步優化提升檢測精度。文獻[10]提出一種番茄果實串采摘點識別方法,該方法對垂直向下的番茄果實串采摘點識別效果較好,但不能對其他姿態的番茄果實進行識別。文獻[11]提出了一種基于改進型YOLO的復雜環境下番茄果實快速識別方法,能夠提取多特征信息,模型對番茄檢測精度為97.13%。
綜上,國內外研究人員針對番茄串的識別和定位問題提出的研究方法尚未達到理想的精度和工業級實時性的要求,對多樣的特征變化魯棒性不足。因此,難以滿足實際需求。為進一步提高農作物的識別率和采摘率,本文以番茄為研究對象,提出一種視覺感知模型,模型包括檢測和語義分割2個模塊,即番茄串檢測和番茄莖分割。采用一種基于深度卷積結構的主干網絡,取代殘差塊結構中的普通卷積運算,降低主干網絡的計算量,從而獲得更為緊湊的主干特征提取網絡,通過K-means++聚類算法獲得先驗框,并改進DIoU距離計算公式,獲得更為緊湊的輕量級檢測模型(DC-YOLO v4),在實現模型參數稀疏性的同時提高識別精度。將MobileNetv2作為ICNet分割模型的主干網絡,以有效減少計算量,達到實時分割效果。
1 材料與方法
1.1 圖像采集
番茄數據集、番茄莖數據集采集于黃河三角洲農業高新技術示范園區的設施農業測試驗證平臺(山東省廣饒縣)。通過Intel RealSense D435型深度相機采集番茄樣本,圖像分辨率為 4 032像素×3 024像素,如圖1a所示,相機安裝在末端執行器上方5 cm處,通過圖1b所示的方式,在移動端遙控機器人進行番茄樣本采樣,模擬番茄采摘機器人的實際工作場景。

圖1 采摘機器人采集番茄樣本Fig.1 Picking robot collects tomato samples
采摘機器人的主要結構如圖2所示,包括機械臂、可移動裝置、機器人控制系統、深度相機和末端執行器5部分。默認狀態下,末端執行器的安裝位置距地面10 cm。

圖2 采摘機器人主要結構Fig.2 Main structure of picking robot1.末端執行器 2.深度相機 3.機械臂 4.機器人控制系統 5.可移動裝置
番茄植株種植在桁架上,行距約0.4 m,高約2 m,為保證數據集樣本的多樣性,分別采集不同光照強度、不同果實數量、不同拍攝角度的番茄串樣本共2 000幅,番茄莖樣本圖像1 000幅。采集的部分番茄樣本如圖3所示。
1.2 番茄檢測網絡
1.2.1YOLO目標檢測網絡
番茄采摘機器人的視覺感知模型包括目標檢測和語義分割兩部分[12]。針對番茄檢測模型,本文借鑒YOLO系列的模型結構[13],其突出特點是快速和精確。與Two-Stage(如Faster R-CNN)使用Region proposal區域建議特征提取方式不同,YOLO的工作原理[14]如下:①對輸入圖像的全局區域進行訓練。②利用主干特征提取網絡完成番茄樣本的特征初次提取。③融合加強特征提取網絡,增大感受野的同時反復提取特征信息。④采用Bounding box預測方式,預測目標類別、置信度和預測框。
YOLO系列網絡模型中,YOLO v1存在網絡模型檢測精度差、目標定位不準確等問題[15];YOLO v2中加入了錨框和批量歸一化,并通過更改網絡模型結構等操作提升了訓練模型性能,但不適用于檢測目標重疊的情況[16];YOLO v3中引入了多尺度融合訓練、殘差結構、改變網絡模型結構等操作,使得訓練模型性能得到了極大提升,但其主干網絡深度達53層且采取了多尺度融合,導致檢測速度慢[17];YOLO v4本質上繼承了YOLO v3的結構,主干網絡更改為CSPDarkNet53優化特征提取性能,采用Mish激活函數使梯度下降過程更為平滑,相較于ReLU、Sigmod等激活函數,Mish在處理負值時不會完全截斷,保證了特征信息流動[18],同時加入了更多目前流行的技巧(如Mosaic數據增強、標簽平滑、CIOU等)。但實際上,在檢測精度和速度方面并沒有明顯提升,未達到工業級番茄檢測的要求。
1.2.2改進的YOLO v4網絡模型
在剖析YOLO v4網絡結構的基礎上,設計了一個基于深度卷積結構的主干網絡,用于對番茄串圖像的初步特征提取。深度卷積結構如圖4所示。
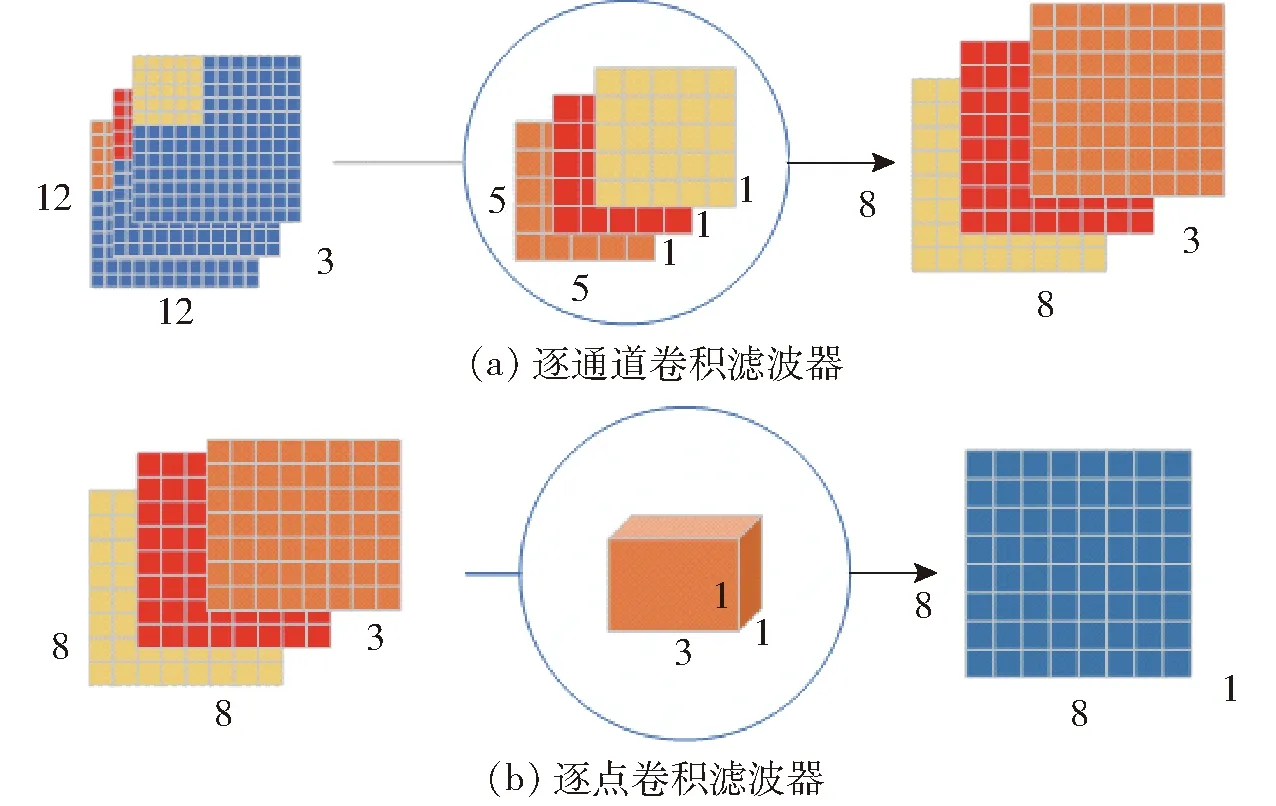
圖4 深度卷積結構Fig.4 Depth convolution structure
番茄檢測模塊由DarkNetBN_Mish模塊、主干網絡、空間金字塔池化(Spatial pyramid pooling,SPP)、像素聚合網絡(Pixel aggregation network,PANet)和YOLO Head構成。如圖5所示,將深度卷積結構替換主干網絡中Resblock_body的普通卷積,降低主干網絡的計算量。
圖5 改進后的Resblock_bodyFig.5 Improved Resblock_body
基于深度卷積結構的主干網絡提取輸入圖像的特征信息,并將特征信息通過卷積傳遞到DarkNetConv2D_BN_Mish模塊中,對輸入圖像進行歸一化和非線性操作,SPP和PANet負責對特征信息加強提取。深度卷積結構處理3個通道的特征信息,最后,通過卷積核尺寸為1×1×3的卷積核將 3個通道的屬性進行融合,傳遞給加強特征提取網絡。相較于普通卷積,深度卷積結構產生的網絡參數少,有效解決了深度學習網絡重復學習特征信息造成計算量大的問題,提高了運算速度。網絡模型的參數如表1所示。可以看出DC-YOLO v4在參數量、處理速度、模型內存占用量等方面均優于一些主流模型的主干網絡。
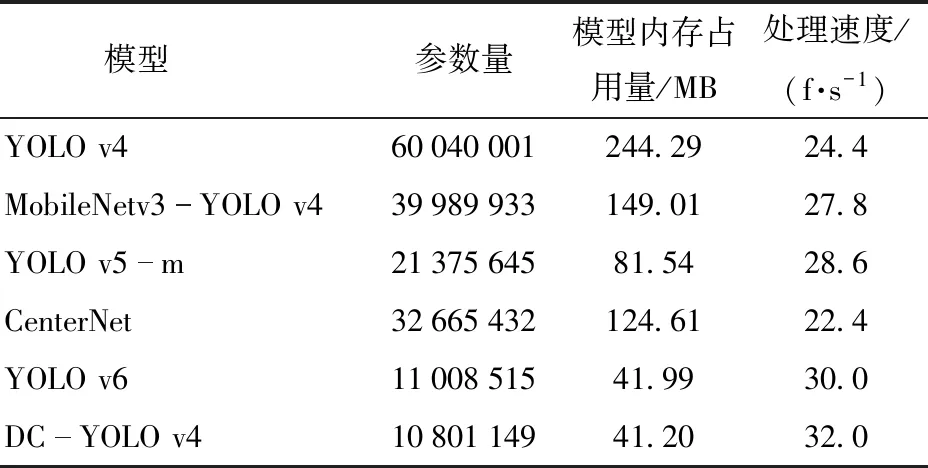
表1 不同網絡模型的主干網絡參數Tab.1 Backbone network parameters of different network models
YOLO v4使用K-means設計先驗框尺寸,但是它存在預先人為確定k個初始聚類中心的缺點,導致生成的先驗框不穩定,難以反映真實框尺寸情況。之后提出的K-means++針對這一問題,進行了一系列改進,不再預先人為確定初始聚類中心,具體實現流程如圖6所示。
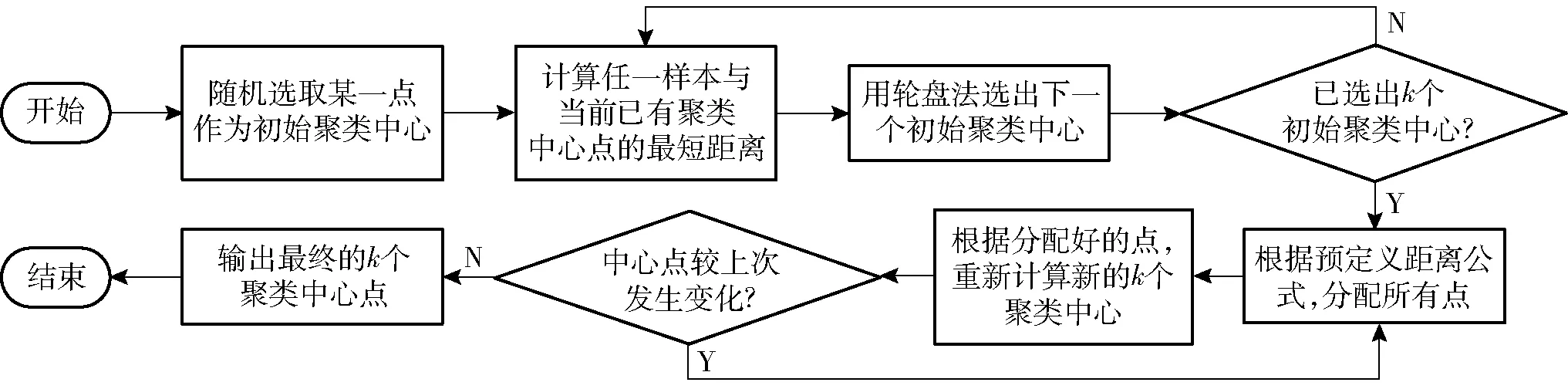
圖6 K-means++算法流程圖Fig.6 K-means++ algorithm flow chart
本文采用改進的交并比(GIoU)計算公式,通過引入檢測框寬高的比例因子vs,避免GIoU在某些情況下退化成IoU的問題,改進的GIoU表達式為
(1)
其中
(2)
式中wgt、hgt——真實框的寬、高
wbb、hbb——預測框的寬、高
C——兩框最小外接矩形的面積
A∪B——兩框并集的面積
并將式(1)作為K-means++的距離計算公式,提高了網絡預測精度。
在網絡訓練前對數據集進行了聚類處理,共得到9種尺寸的Anchor box,如圖7所示,其尺寸分別為(18,20),(28,34),(40,45),(59,50),(45,69),(75,79),(126,55),(55,138),(266,295)。相較于K-means聚類結果,采用K-means++得到的錨框擬合程度更好,便于模型的訓練。

圖7 9種尺寸的聚類中心分布圖Fig.7 Distribution of cluster centers of nine sizes
1.3 番茄莖分割網絡
1.3.1ICNet語義分割網絡
番茄串檢測問題大部分采用傳統圖像處理與機器學習相結合的方式,會受到圖像本身噪聲等多種因素的制約,為了解決番茄串檢測中的局限性,本文將基于深度學習的語義分割算法應用于番茄串分割領域。ICNet網絡模型[19]是基于高分辨率圖像的實時語義分割網絡。它利用處理低分辨率圖像的效率以及高分辨率圖像的高質量。思路是使低分辨率圖像先通過全語義感知網絡來取得大概的語義預測圖,然后提出級聯特征融合單元和級聯標簽指導策略整合中等和高分辨率特征,這逐漸提煉了粗糙的語義預測圖。ICNet的網絡架構如圖8所示。它使用PSPNet的金字塔池化模塊融合多尺度上下文信息,并將網絡結構劃分為3個分支,分別為低分辨率、中分辨率和高分辨率。配合ResNet50使用3個分支進行特征融合形式的訓練,前2個分支增加輔助訓練,增加模型收斂。對于每個輸出特征,在訓練時會以真實標簽的1/16、1/8、1/4來指導各分支訓練,使得梯度優化更加平滑,隨著每個分支學習能力的增強,預測沒有被某一分支主導。
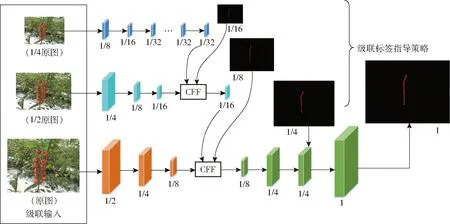
圖8 ICNet網絡結構Fig.8 ICNet network structure
分支1將原圖下采樣到1/4尺寸,然后經過連續3次下采樣降維到原圖的1/32,使用空洞卷積層擴展感受野的同時不縮小尺寸,最終輸出1/32原圖的特征圖。分支1的卷積層數多但特征圖尺寸小,速度快,且第2個分支與第1個分支共享前3層卷積的權值。
分支2將1/2尺寸的原圖作為輸入,經過卷積后降維到1/8原圖,得到1/16尺寸的特征圖,再將第1個分支中由低分辨率圖像提取出的特征圖通過級聯特征融合單元得到最終輸出。
分支3以原圖像為輸入,經3次卷積后得到原圖1/8尺寸的特征圖,再將處理后的輸出和分支2的輸出通過CFF融合。分支3的圖像分辨率大,但卷積層數少,耗時較少。
ICNet的損失函數是通過構建多分支loss實現,損失函數表達式為
(3)
式中τ——分支數量,取3
xt、yt——分支的特征圖尺寸
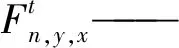
n′——相關的真實標簽
λt——每個分支的損失權重
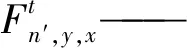
通常,高分辨率分支權重λ3設置為1,中分辨率和低分辨率分支的權重λ2和λ1分別設置為0.4和0.16。
1.3.2改進的ICNet語義分割網絡
在一些經典的深度學習語義分割算法中,主要采用VGG系列或者ResNet系列作為主干特征提取網絡,雖然二者都能夠提取圖像的深層信息,但是對于部署到嵌入式設備上而言,其網絡模型的參數量過大,分割速度慢。因此,采用MobileNetv2替換ResNet,取消傳統的卷積計算,采用深度卷積以及1×1的逐點卷積來提取圖像特征,可以成倍減少卷積層的時間復雜度和空間復雜度。同時還引入了倒殘差結構,先升維后降維,增強梯度的傳播,顯著減少推理期所需的內存占用量。倒殘差結構如圖9所示。
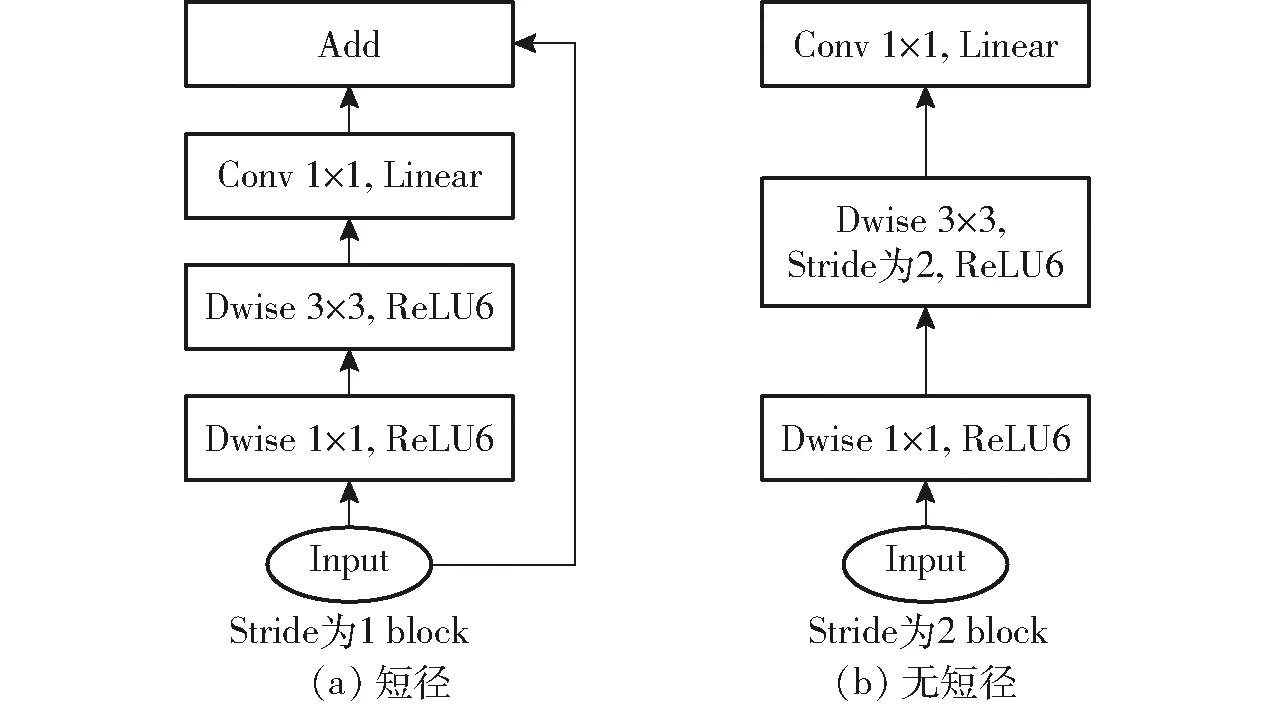
圖9 倒殘差結構Fig.9 Inverted residuals
在殘差結構中,首先通過1×1卷積實現降維,再通過3×3卷積提取通道特征,最后使用1×1卷積實現升維。但在倒殘差結構中,先通過1×1卷積實現升維,再通過3×3的逐通道卷積提取特征,最后使用1×1卷積實現降維。調換了降維和升維的順序,并將3×3的標準卷積換為逐通道卷積,呈兩頭小、中間大的菱形結構。其次,改變了之前所采用的激活函數。殘差結構中通常采用ReLU激活函數,但是,在倒殘差結構中,采用ReLU6 作為激活函數,最后1個卷積使用的是線性激活函數。用ReLU6替換ReLU,目的是為了保證在嵌入式設備低精度也能保有很好的數值分辨率。如果對ReLU的輸出值不加限制,那么輸出范圍就是零到正無窮, 無法精確描述其數值,這將帶來精度損失。ReLU6激活函數如圖10所示。最后1個卷積使用線性激活,則是線性瓶頸結構的內容。瓶頸結構是指將高維空間映射到低維空間,縮減通道數;膨脹層則相反,其將低維空間映射到高維空間,增加通道數。沙漏型結構和梭型結構,都可看做是1個膨脹層和1個瓶頸結構的組合。瓶頸結構和膨脹層本質上體現的都是1×1卷積。線性瓶頸結構是末層卷積使用線性激活的瓶頸結構。ReLU容易導致逐通道卷積部分的卷積核失活,即卷積核內數值大部分為零,這是因為在變換過程中,需要將低維信息映射到高維空間,再經ReLU重新映射回低維空間。若輸出的維度相對較高,則變換過程中信息損失較小;若輸出的維度相對較低,則變換過程中信息損失很大。因此,末層采用線性激活來避免這一問題。
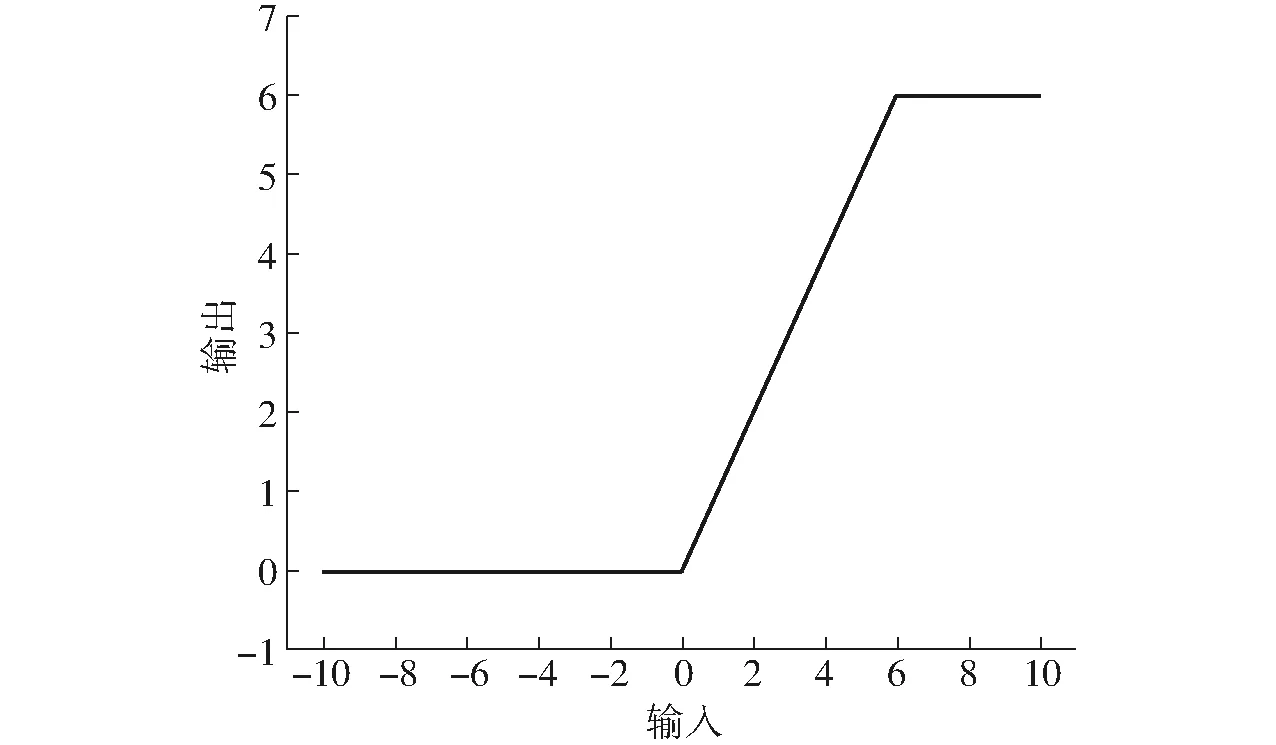
圖10 ReLU6激活函數Fig.10 ReLU6 activation function
2 網絡模型訓練與評價指標
2.1 驗證平臺
主機操作系統為Ubuntu 16.04,中央處理器為Intel Core i9-10920X GPU@ 3.50 GHz,運行內存32 GB,顯卡為Nvidia Quadro P2200(5 GB/戴爾)。神經網絡在Anaconda 3虛擬環境下訓練,采用Pytorch 1.2.0深度學習框架,配置安裝Python 3.8編程環境、GPU并行計算架構Cuda 10.0和神經網絡GPU加速庫Cudnn 10.0。
2.2 番茄檢測網絡模型訓練
采用PASCAL VOC 2007數據集的預訓練權重訓練,訓練圖像分辨率為416像素×416像素,每個批次處理8幅圖像,總迭代次數為1 000,前450次采用凍結訓練加快訓練速度,訓練學習率為0.001,每迭代100次,學習率降低0.1,后550次的解凍訓練學習率為0.000 1。可以看出前200次迭代中網絡快速擬合,200次迭代之后損失函數基本穩定,番茄檢測網絡開始收斂。圖11反映了損失函數的變化趨勢。

圖11 目標檢測模型訓練曲線Fig.11 Target detection model training curves
2.3 番茄串語義分割網絡模型訓練
采用PASCAL VOC 2007數據集的預訓練權重訓練,輸入圖像分辨率為512像素×512像素,格式為JPG,對應的標簽圖像格式為PNG,類別數為2,下采樣倍數為16,每個批次處理8幅圖像,總迭代次數為500,前100次為凍結訓練,學習率為0.000 5,后400次的解凍訓練學習率為0.000 005。由圖12可以分析出,在前100次迭代中網絡快速擬合,100次迭代后損失函數基本穩定,番茄串語義分割檢測網絡開始收斂。

圖12 語義分割模型訓練曲線Fig.12 Semantic segmentation model training curves
2.4 評價標準
為了客觀分析DC-YOLO v4對番茄數據集以及ICNet模型對番茄串數據集的語義分割性能,本文引入平均交并比(mIoU)、準確率(Precision)、召回率(Recall)、平均精度均值(mAP)、綜合評價指標(F1值)、類別平均像素準確率(mPA)和檢測時間(Time)等評價指標。本文的目的是快速準確識別番茄并分割番茄莖,因此把平均交并比、平均精度均值和檢測時間作為主要評價指標。利用IoU閾值為0.5的平均精度來測定番茄識別模型的準確性。此度量標準用于測量目標檢測器的精度,因為它平衡了精度和召回率。
3 結果分析
3.1 番茄檢測效果
本文設計的檢測模塊借鑒了YOLO系列的架構,融合了深度卷積結構,因此有必要與傳統的YOLO系列算法的番茄識別性能進行對比分析。同時,使用批量為8、尺寸為416像素×416像素的圖像,對經過訓練的MobileNet-YOLO v4、YOLOX、YOLO v5-m、YOLO v6進行測試和比較,在測試模型中獲得的結果存在差異,測試結果如圖13所示。DC-YOLO v4模型對番茄和番茄串的識別正確率高于YOLO v4模型,YOLO v4模型深度圖中存在大量噪點,導致其識別精度不足,誤檢率高。MobileNet-YOLO v4檢測模型在實際應用中,對番茄串的識別不敏感,且在深度圖中,DC-YOLO v4模型的番茄串輪廓更為光滑。YOLOX模型[20]是由曠視科技在2021年提出的全新檢測模型,DC-YOLO v4模型與YOLOX模型在實際測試中,并無明顯區別。YOLO v5-m模型的檢測速度快,但喪失了一定的識別準確度,雖然能夠獲取圖像的高級特征,但這些特征具有平移不變性[21],不利于對目標信息的區域采樣。

圖13 不同檢測模型測試效果Fig.13 Test results of different test models
為論證本研究提出的DC-YOLO v4模型的有效性,又與YOLO v5模型系列中最為主流的YOLO v5-m、YOLO v6以及CenterNet檢測模型比較。YOLO v6模型是美團視覺智能部研發的一款目標檢測框架,致力于工業應用。CenterNet模型[22]是無錨框目標檢測器,由于沒有復雜的Anchor操作,檢測速度優于Two-Stage及預錨框系列,算法性能良好,對小目標檢測具有優勢[23]。CenterNet模型只通過FCN(全卷積)的方法實現了對于目標的檢測與分類,即使沒有Anchor與NMS等操作,它在高效的同時精度也較好。可以將其結構進行簡單修改就可以應用到農業場景下的番茄目標檢測之中。
表2展示了不同網絡模型對番茄串和番茄的檢測性能,DC-YOLO v4模型的mAP最大,對于番茄和番茄串的識別準確率及召回率最高,單幅圖像預測時DC-YOLO v4模型比YOLO v4模型的mAP高2.04個百分點。比MobileNet v3-YOLO v4模型的mAP高1.08個百分點。原因是卷積層較多,計算量大,檢測速度偏慢,神經網絡層數過深,因此檢測精度較低。與DC-YOLO v4模型相比,CenterNet模型難以對紋理特征進行有效提取,mAP低于DC-YOLO v4模型2.34個百分點,并且檢測時間差,不滿足工業條件下的實時性要求。
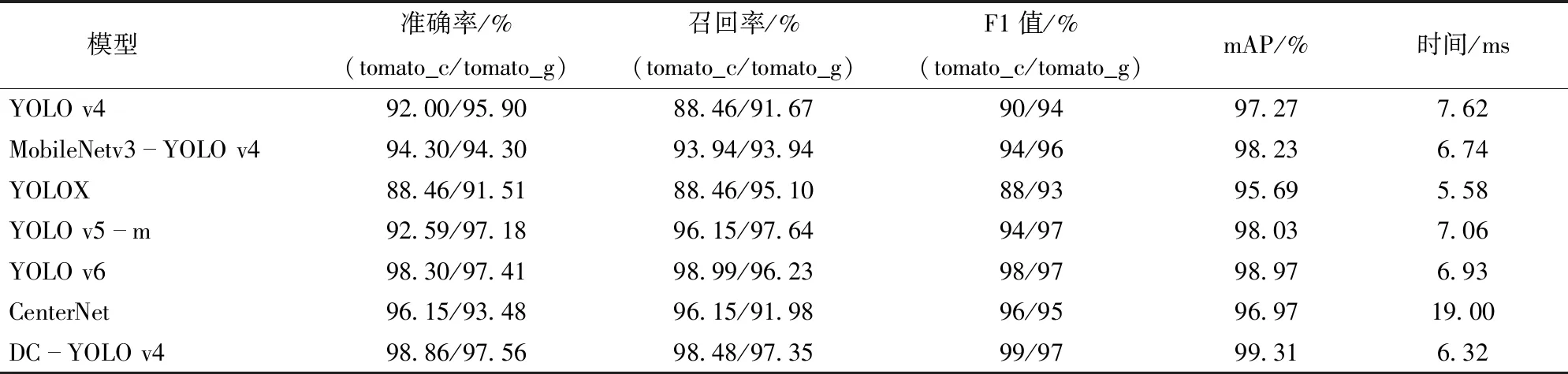
表2 不同識別模型性能比較Tab.2 Performance comparison of different recognition models
另外,DC-YOLO v4模型的召回率稍低于YOLO v5-m模型與YOLO v6模型,原因是YOLO v5-m模型的Backbone是基于CSPNet搭建的,而YOLO v6模型的Backbone則是引入了RepVGG結構[24],二者的主干檢測網絡較為復雜,對于單番茄果實的特征提取能力強。相對于YOLOX模型,雖然DC-YOLO v4模型的檢測時間增加0.74 ms,實時性略低于YOLOX模型,但是檢測精度提高3.62個百分點。可以看出,DC-YOLO v4模型能同時兼顧實時性和準確性,滿足工業條件下采摘機器人的需求。
3.2 番茄莖分割效果
為了更好地展現改進的ICNet模型性能提升的直觀效果,本研究還選取目前有代表性的主流語義分割網絡DeepLab_v3+[25]、U-Net[26]和PSPNet[27]進行實際測試實驗。對比實驗結果如 圖14 所示,相較于ICNet,改進后的ICNet能夠完整分割出番茄莖,較好地保存逐像素點含有的位置信息和語義信息,U-Net只能捕捉大致外形,且包含大量噪點,PSPNet缺少分割細節,不能很好地表征目標特征,DeepLab_v3+在實際測試中,效果與改進后的ICNet無明顯差異。根據本研究提出的量化指標,結合表3可以得出,改進的ICNet網絡與其他網絡相比分割性能有了一定的提高,本文提出的改進ICNet網絡mIoU和mPA分別為81.63%和91.87%,相較于ICNet模型,mIoU和mPA分別提升2.19個百分點和1.47個百分點;相較于DeepLab_v3+模型,mIoU和mPA分別提升7.04個百分點和3.51個百分點;相較于U-Net模型,mIoU和mPA分別提升7.74個百分點和4.88個百分點;相較于PSPNet模型,mIoU和mPA分別提升9.71個百分點和4.66個百分點。結果表明,改進ICNet網絡相較于其他網絡在番茄莖分割上更有優勢。

表3 不同分割模型性能比較Tab.3 Performance comparison of different segmentation models

圖14 不同分割模型測試效果Fig.14 Test results of different segmentation models
3.3 溫室中視覺感知模型驗證
為了驗證本文提出的農作物采摘視覺感知模型在實際應用場景下的性能,將模型部署到山東中科智能農業機械裝備創新技術中心自主研發的番茄采摘機器人系統中進行采摘實驗。如圖15所示,采摘機器人核心組成部件包括眾為創造xARM型六軸機械臂、Intel RealSense D435型深度相機、可移動吊軌以及工控機。

圖15 吊軌采摘機器人Fig.15 Rail picking robot
在實際應用中,當完成檢測任務后,控制系統會給機械臂發送一個前移指令,末端執行器帶動RealSense D435型深度相機向番茄莖大概方位移動,拉近感受視野,使ICNet能夠實時分割出視頻流數據中的番茄莖。如圖16所示,彩色圖中的藍色掩膜為ICNet模型在視頻流中的分割效果,為了滿足工程級的實時性要求,采用霍夫變換將其轉換為二值圖進行處理,加快系統的處理速度。

圖16 實際場景中的分割效果Fig.16 Segmentation effect in real scene
本文共進行了80次采摘實驗,由于吊軌采摘機器人每次僅能采摘一串紅色番茄,故只統計了紅色番茄串的采摘成功率,最終的平均采摘成功率為84.8%。RealSense D435型深度相機檢測到番茄串后,會計算并返回感興趣區域的的中心點,控制系統驅動末端執行器移動到中心點前的10 cm處,經過ICNet模型處理后,得到分割番茄莖,末端執行器會根據計算得到的采摘點進行采摘,最后將采摘的番茄串放入收納籃中,完成上述采摘流程平均用時6 s。影響工作時間的主要原因是番茄莖與背景顏色相近,對于番茄莖的形狀特征提取能力差,同時枝葉的遮擋也增加了番茄莖提取的難度。
4 結論
(1)番茄和番茄串測試集上的實驗結果表明,檢測模塊對番茄的識別準確率為98.86%,召回率為98.48%,F1值為99%,對番茄串的識別準確率為97.56%,召回率為97.35%,F1值為97%,模型平均精度為99.31%,模型平均識別單幅圖像需要6.32 ms。相比于本研究中選用的一些目標檢測對比模型,在性能上有明顯的提升,DC-YOLO v4模型的mAP相比于YOLO v4、MobileNet v3-YOLO v4、YOLOX、YOLO v5-m、CenterNet、YOLO v6模型提高2.04、1.08、3.62、1.28、2.34、0.34個百分點。
(2)番茄莖測試集上的實驗結果表明,改進的ICNet分割模型對番茄莖的平均召回率為91.87%,mIoU為81.63%,mPA為91.87%,模型平均分割單幅圖像需要8.21 ms,改進的ICNet模型的mPA相比于ICNet、DeepLab_v3+、U-Net和PSPNet分別提升1.47、3.51、4.88、4.66個百分點。
(3)將檢測模型部署到番茄采摘機器人上,在溫室環境下對番茄串進行采摘論證,與人工檢驗進行對比,結果表明,機器人的準確采摘率為84.8%,平均完成一次采摘動作用時6 s。本文的研究結果可以為復雜溫室環境下的其他農作物采摘提供技術支撐。
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代語文(2016年21期)2016-05-25 13:13:44
現代企業(2015年9期)2015-02-28 18:56:50
大連民族大學學報(2015年2期)2015-02-27 08:28:11
