應用改進狼群算法優化模糊聚類實現點云數據的區域分割
2023-11-23 10:56:20張佳琦王建民
科學技術與工程 2023年30期
張佳琦,王建民
(太原理工大學礦業工程學院,太原 030024)
通過三維掃描技術可以獲取幾何體的點云模型數據,其作為一種重要的三維空間數據源,在對被測物體的細節表現方面發揮著無可比擬的重要作用[1],已經在逆向工程[2]、三維建模[3]等領域得到廣泛應用。而點云數據的三維重建是其應用的基礎,在數據處理過程中若直接進行三維重建會增加計算機處理的時間、空間的復雜度[4],因此可以利用逆向重建技術[5]對點云數據進行一系列處理,主要包括點云數據的分割、特征提取、匹配和曲面重建等,而在該過程中點云數據的區域分割是后續曲面重構的基礎與關鍵。目前,常用的點云自動分割方法可歸納為4類[6]:基于邊、基于面、基于聚類和混合分割方法。基于邊的方法對噪聲敏感,計算精度低,會造成區域之間連通;基于面的方法對種子點和閾值的選取要求較高,直接影響到分割結果的好壞;混合方法在唯一性和魯棒性等方面有一定優勢,但其涉及算法較多,實現較為復雜。近年來,基于聚類的分割方法由于實現簡單、尋優速度快且性能良好等優點,逐漸被應用于點云數據分割。基于聚類的方法是將數據點空間近鄰、屬性相同或相似的點歸為一類(該方法對于曲面特征變化較明顯的點云數據尤為適用),其中模糊C均值(fuzzyC-means,FCM)算法[7]目前已經成功應用于點云、圖像分割等領域[8-10]。但是在實際應用中,FCM算法對初始值敏感且易于陷入局部最優,致使點云分割效果不佳,因此,許多學者引入群智能優化算法來改善初始聚類中心的選擇,主要有基于遺傳算法、改進的粒子群算法、人工蜂群算法與FCM算法相結合的分割算法[11-13],取得了良好的聚類效果,但這些算法中均存在尋優速度慢、對參數敏感、易“早熟”等問題[14]。
狼群算法作為一種新興的群體智能優化算法,具有敏感參數少、收斂速度快、精度高等優點[15],已在圖像處理[16]、路徑規劃[17]、生產調度[18]等領域廣泛應用。但是,在實際情況中狼群算法仍存在“早熟”、運算復雜、參數較多等缺點,為此基于狼群算法提出了改進的優化算法[19-21],主要有3個方面:①為了使得初始解更好的分布在解空間,對種群初始化進行改進;②引入自適應步長因子,以減少算法對參數敏感的同時提高算法的收斂速度;③引入擾動策略、交互策略使得算法更好地進行全局尋優,并跳出局部最優解。改進后的狼群算法能夠減小參數的敏感性并獲得全局最優的近似解,但是單純一種改進策略效果有限。
為此,現采用佳點集、自適應步長、交互策略和高斯擾動機制等方法對狼群算法進行綜合改進。并將改進后算法融入FCM算法中,提出一種基于曲率約束的改進狼群算法與FCM相結合的混合算法(IWPAFCM),提升FCM算法對點云分割的準確性,并利用仿真實驗測試算法性能。
1 模糊C-均值聚類算法原理
模糊C-均值聚類算法[7]是一種散亂數據分類算法,通過最小化目標函數將數據集劃分為多個聚類,數據集中的元素對于每個聚類都有一個隸屬度值,代表其歸屬于某個聚類的程度,定義隸屬度在[0,1]內取值。
己知l維歐氏空間中的數據集S={s1,s2,…,sj,…,sn}?Rl,樣本sj的特征向量sj=(sj1,sj2,…,sjl)T∈Rl。將數據集S劃分為c(2≤c≤n)個子集,即聚類數為c,c個子集聚類中心為C={C1,C2…,Cc}。通過極小化目標函數實現最佳聚類,目標函數一般定義為
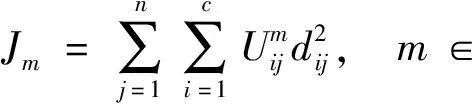
(1)
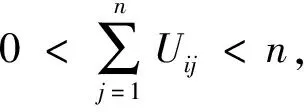
(2)
(3)
利用FCM算法實現對點云數據的區域分割,有兩個關鍵問題需要考慮。首先,FCM算法對于初始聚類中心選擇過于敏感,容易陷入局部最優,因此利用具有全局尋優能力的改進狼群算法來解決這一問題。其次,單純利用傳統FCM算法的歐式距離(以點云坐標為粒子點的距離)對三維點云進行區域劃分時,點云的微分幾何信息,如曲面、法向量等不能被充分利用,為此引入曲率約束的點距離[22]對歐式距離進行替換,從而獲得理想的點云分割結果。
2 改進狼群算法
狼群算法受到自然界中狼群捕食行為的啟發,將狼群按不同的分工劃分為頭狼、探狼和猛狼,抽象出游走、召喚、圍攻3種智能行為,根據“勝者為王”和“強者生存”規則更新頭狼、保持狼群多樣性[23]。
在基本狼群算法中,探狼通過式(4)進行位置更新,也即執行游走行為來尋找當前最優解作為頭狼;猛狼通過式(5)向頭狼奔襲(召喚行為),在該過程中若其適應度值優于頭狼則更新頭狼狀態并發起召喚行為,否則,繼續朝頭狼奔襲。
當兩種人工狼之間的距離小于判定距離時,狼群按照式(6)執行圍攻行為,并根據適應度值判斷是否更新頭狼。然后淘汰部分適應度值較小的狼,并隨機生成新的人工狼。當滿足精度要求或達到最大迭代次數時輸出最優解,否則回到游走行為。人工狼位置更新公式為
(4)
(5)
(6)
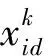
狼群算法具有全局尋優能力強、精度高等優點,但在實際應用中,還是會有一些缺點,如種群多樣性隨迭代更新而下降、后期收斂速度慢、易陷入局部最優等[15],因此利用佳點集、自適應步長、交互策略和高斯擾動機制等方法對算法進行相應的改進。
2.1 佳點集初始化和自適應步長
(1)基本狼群算法以隨機方式初始化種群,可能導致狼群在解空間分布不均勻,尋優結果不理想。佳點集方法的精度不受其維數影響,產生的初始種群均勻性和多樣性更好[24]。一定程度上可以避免陷入局部最優,加快算法收斂速度。在狼群算法“強者生存”更新機制中,同樣以佳點集方式初始化原本隨機生成的人工狼。步驟總結如下。
步驟1根據歐式空間的維數s,找到滿足(p-3)/2≥s的最小素數p。
步驟2設Gs是S維歐式空間的單位立方體,對Gs中的點r=(r1,r2,…,rs),取rk=2cos(2πk/p),1≤k≤s,則將p代入可求得佳點r。
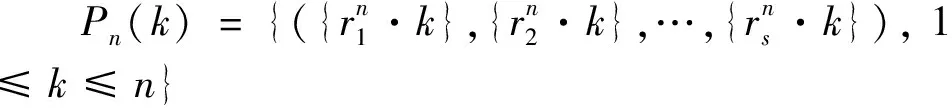
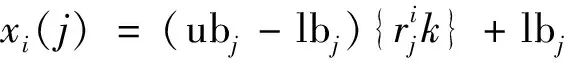
(2)基本狼群算法在3種智能行為中,采用固定步長對解空間進行探索,當步長設定過大時不利于尋找全局最優解,步長過小時又會增加算法的收斂時間,本文研究引入文獻[20]提出的自適應步長來對尋優與收斂時間進行平衡。自適應步長定義為
(7)
式(7)中:rand為[0,1]間的隨機數;xi為當前人工狼i位置;XLead為當前頭狼位置。
(3)基本狼群算法中判定距離的設定同樣影響算法的收斂速度和尋優精度,即設定過小時猛狼多次被頭狼召喚卻難以進入圍攻行為,設定過大時人工狼難以找到獵物位置;故本文研究取消初始判定距離,以頭狼更新或最大召喚次數作為進入圍攻行為的條件[21],很好地提高了WPA算法運行效率。
2.2 交互策略
在WPA算法的游走、召喚行為中,探狼、猛狼群體內部缺少必要的交流,會出現對解空間重復搜索或探索不到的情況,導致尋優時間長,甚至不收斂,因此為了增加人工狼群體內部的交互性以及提高尋優能力,引入交互策略[25],即
vi,d=xi,d+φi,d(xbest,d-xi,d)+φi,d(xj,d-xk,d)
(8)
式(8)中:φi,d為[0,1]的隨機數;φi,d為[-1,1]的隨機數;xbest,d為頭狼位置;xk,d,xj,d為隨機的人工狼k、j在d維空間位置,且k≠i≠j。式(8)的前半段確保了頭狼的領導能力,后半段增加了人工狼之間的交互,很好地提高了算法全局與局部尋優的能力。
2.3 高斯擾動機制
基本狼群算法在陷入局部最優時難以跳出局部最優點[15],因此引入高斯擾動來解決這一問題。位置更新公式為
(9)
(10)
以求解適應度最小值為例,IWPA算法步驟如下。
步驟1初始化人工狼數目N,最大迭代次數kmax,最大游走次數ymax,召喚次數t,更新比例因子β。以佳點集方法對種群進行初始化,確定每個人工狼的適應度值,排序取最小值位置作為頭狼位置。
步驟2選取排序后適應度較小的Snum匹人工狼作為探狼,按照更新后的游走步長執行游走,之后按式(8)尋找新獵物,從h+1個獵物中尋找最優獵物,直到頭狼位置更新或者達到最大游走次數時執行步驟3。
步驟3頭狼發起召喚,召集猛狼向其位置靠近,選取當前猛狼、召喚后位置、進行一次式(8)后位置三者中的最小適應度位置作為新的猛狼位置,過程中若適應度小于頭狼則更新頭狼位置,并以當前頭狼位置發起召喚行為,直到猛狼達到最大召喚次數或頭狼被更新時執行步驟4。
步驟4按自適應圍攻步長計算參與圍攻行為人工狼的新位置,若適應度值小于頭狼則更新頭狼位置。
步驟5對當前所有人工狼排序,淘汰適應度值較差的部分人工狼,并以佳點集生成新的人工狼,若其適應度值小于當前頭狼則更新頭狼狀態。
步驟6以高斯擾動機制對頭狼位置進行更新。
步驟7判斷算法是否達到規定精度或最大迭代次數,滿足其中一點則算法結束,輸出結果,否則,執行步驟2。
2.4 算法性能測試
為了充分驗證本文算法的尋優性能,通過3個標準測試函數在固定維數30維情況下對所提算法(IWPA)的尋優性能進行測試,函數描述如表1所示。

表1 3個標準測試函數
表1中f1和f2為單模態函數,可以用來測試算法的尋優精度,f3為多模態函數,一般尋優算法很難找到全局的最優解,用來測試算法在有多個局部最優解情況下跳出局部最優解和尋找全局最優解的能力。函數分別運行20次,迭代次數設為1 000次,計算出平均值、標準差、最優和最差值,并和算法MWPA[19]、MACWPA[20]、WPA[23]和FA[26]進行對比,計算結果如表2所示,迭代曲線如圖1所示。
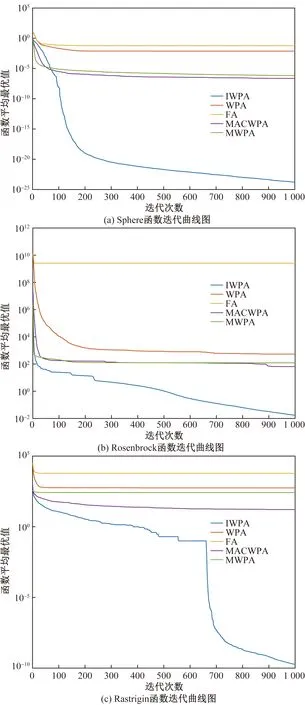
圖1 各算法迭代曲線
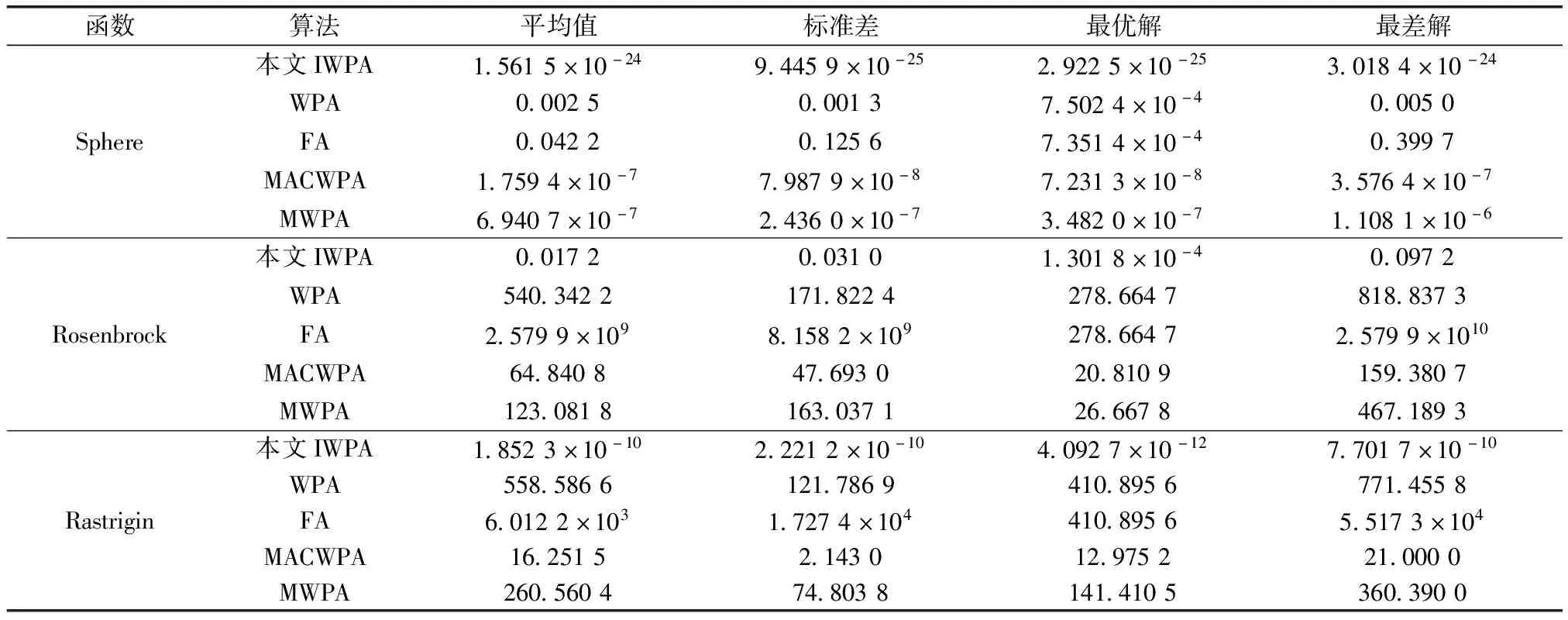
表2 5種算法在3個測試函數下計算結果對比
通過表2中數據可以看出,對于所有的標準測試函數,在規定的迭代次數情況下本文算法在尋優精度和穩定性方面都明顯優于對比算法,尤其是在多模態函數中,本文算法的尋優精度達到了1×10-10,表現出了極佳的尋優能力。通過迭代圖可以看出,對于兩個單模態函數,本文算法隨著迭代的進行并沒有出現明顯的停滯現象,表明如果繼續迭代本文算法甚至可能找到函數的最優解,而對于多模態函數,本文算法在迭代后期有著明顯跳出局部最優值的能力,表現出了本文算法在多模態函數中的優勢。這主要是由于IWPA引入自適應步長,使參與尋優的人工狼能根據算法迭代自動調整靠近頭狼的步長,同時以頭狼更新和最大召喚次數作為進入圍攻行為的條件,加快了算法的尋優速度,而通過佳點集、交互策略和高斯擾動機制,使得算法擁有加深全局搜索能力,跳出局部最優,改善了全局尋優的精度。通過以上測試充分證明了所提算法在單模態和多模態函數尋優中的優勢,也為進一步與FCM算法結合,解決其對初值敏感和易于陷入局部最優的問題提供了充分的依據。
3 基于曲率約束的IWPAFCM聚類算法
應用改進狼群算法優化FCM聚類算法對點云進行區域分割,可有效改善FCM算法陷入局部極小值的情況。而為了實現理想的點云分割效果,充分利用點云的特征信息,本文研究利用曲率約束的點距離替換傳統FCM算法的歐式距離。下面對點云特征向量的估算,點距離的計算,適應度函數的選擇等關鍵問題進行說明。
3.1 點云特征矢量的估算
利用法矢量、曲率構成的7維特征向量表示點云粒子,以此來實現對特征變化明顯的物體表面的細分割。

(11)
應用自適應鄰域主成分分析法[27]對法向量求解,該方法易于實現、穩定性強;對于曲率估算可通過對某點鄰域內的25~30個點進行局部擬合,構造局部鄰域內的二次曲面[28],將擬合出的二次曲面的曲率近似作為該點的主曲率,進而可求得高斯曲率、平均曲率。
3.2 點距離
傳統歐氏距離對點云數據分割不能很好地反映曲面的特征變化,即使特征變化明顯,在給定距離閾值范圍,還是會被分割到同一區域,在某些特定需求條件下不能得到理想的分割效果[22]。為此利用點云法矢和曲率來計算兩點之間的距離,實現對點云模型的細分割。
定義2點距離。設點云數據P中的任意兩個點pi和pj,分別表示為:pi=(ai,bi,ci,Ki,Hi,ki1,ki2),pj=(aj,bj,cj,Kj,Hj,kj1,kj2),則pi和pj的距離可表示為
D(pi,pj)=DN(pi,pj)+φDQ(pi,pj)
(12)
式(12)中:DN(pi,pj)為法向距離;DQ(pi,pj)為曲率約束;φ為約束調整參數;DN(pi,pj) 和DQ(pi,pj)分別由式(13)和式(14)計算。
(13)
(14)
整理式(12)、式(13)和式(14),調整參數得
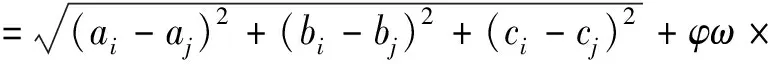
(15)
式中:λ為φ、ω合并后的調整參數,當點云曲面信息豐富,需要細分出更細節區域時,應適當增大λ取值。以式(15)計算求得的距離D(pi,pj)來替換傳統FCM算法的歐式距離dij。
3.3 適應度函數
模糊聚類取得較優的聚類結果時,目標函數取極小值;而狼群算法為尋優算法,可根據情況求得目標函數的極大值或極小值,以模糊聚類的目標函數作為改進狼群算法的適應度函數,適應度函數為
f(Xi)=Jm
(16)
在IWPA-FCM算法中,種群中任意一個人工狼Xi的位置狀態,都可以用一個c×l列的一維行向量表示,即:Xi=(c11,c12,…,c1d,…,ci1,ci2,…,cid,…,cc1,cc2,…,ccl),其中l為樣本維數,c為聚類數。則種群中第i個聚類中心可表示為 (ci1,ci2,…,cil)。IWPAFCM 聚類算法的基本步驟如下。
步驟1根據輸入點云數據計算出每個點的特征向量并進行歸一化處理[29]。
步驟2初始化狼群算法的基本參數[23],取模糊加權指數m=2。
步驟3利用改進狼群算法來初始化種群、更新求解最優適應度值,并輸出最優聚類中心。
步驟4以改進狼群算法求得的最優聚類中心作為FCM的初始值進行迭代,最終求得全局最優解。
IWPAFCM聚類算法的點云分割流程圖如圖2所示。

圖2 改進狼群算法優化聚類中心的點云分割流程
為了對以上過程有更詳細的描述,以取最小值為例給出IWPAFCM聚類算法的主循環偽代碼,在主循環之前是一些基礎計算與賦值,包括利用點云X計算法矢量V和高斯曲率K、平均曲率H和主曲率K1和K2,然后歸一化V、K、H、K1、K2組成新的解空間,并在解空間中利用佳點集初始化狼群位置,之后由式(1)~式(3)和式(12)計算每只狼對應適應度值并排序確定頭狼、探狼和猛狼的位置和適應度,然后代入主循環進行計算,主循環偽代碼如下。

算法:IWPAFCM聚類算法
----------------------------------------------------------
輸入:點云X、迭代次數imax、游走次數Tmax、游走方向數h、探狼數量Snum、猛狼數量Mnum、召喚最大次數Wmax
輸出:聚類中心(頭狼位置)
%主循環
for iter=1:imax
%探狼游走
fori=1:Tmax
forj= 1:Snum
forn=1:h
根據式(4)和式(7)得到h個新獵物
end for
根據式(8)獲得交互獵物V
form=1:h+1
計算獲得的h+1個獵物的適應度
end for
更新探狼位置
end for
選出當前最優探狼,位置為X,適應度Y
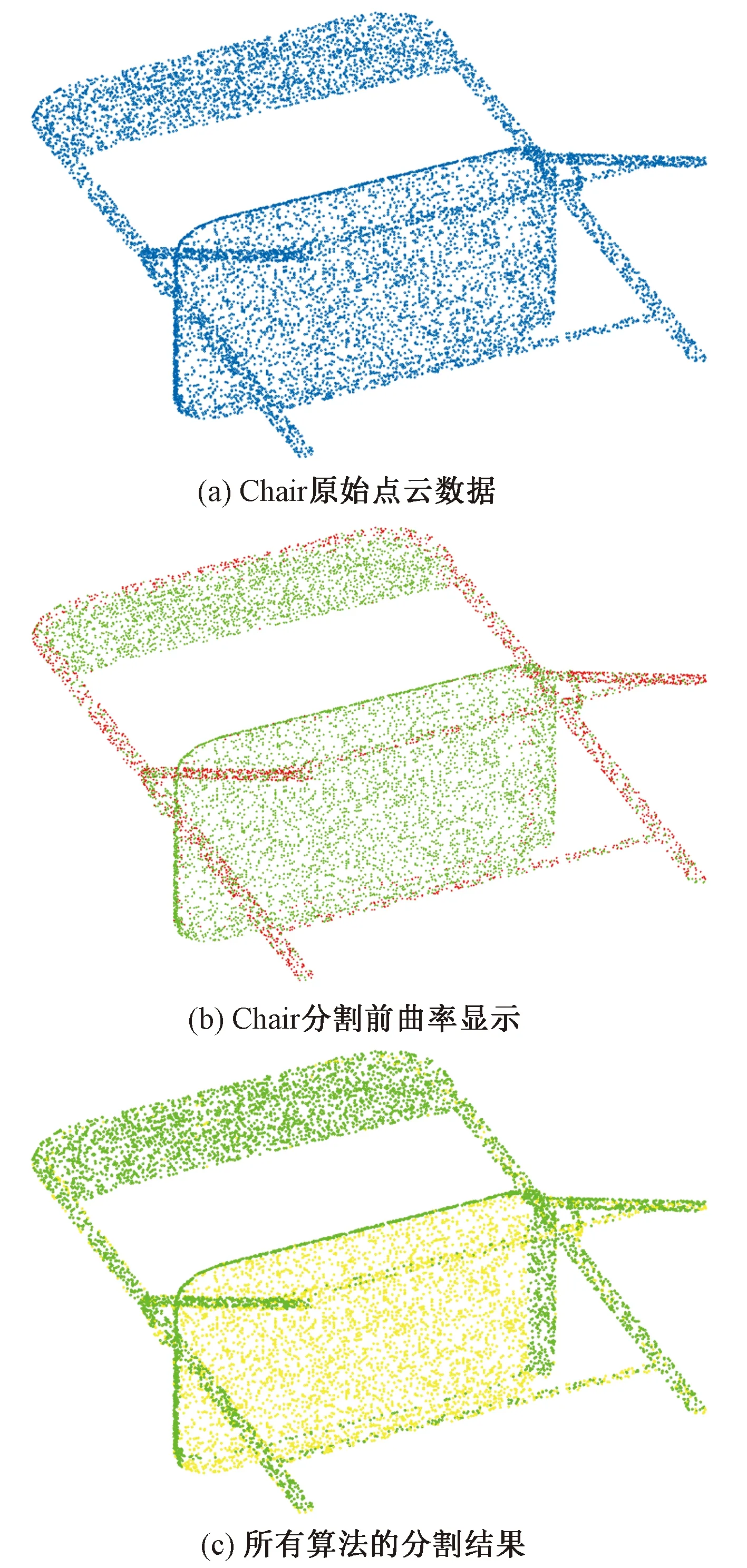
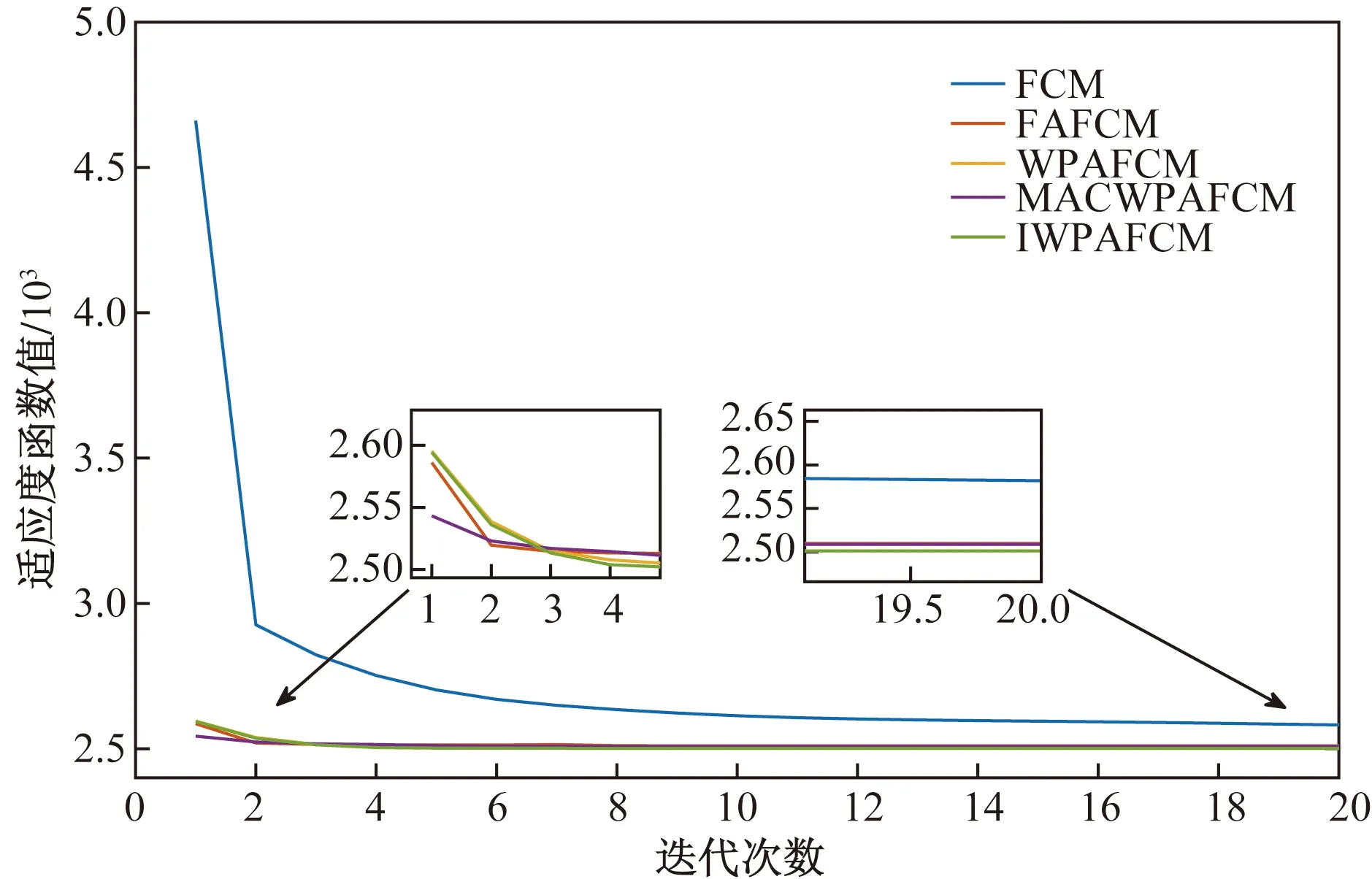
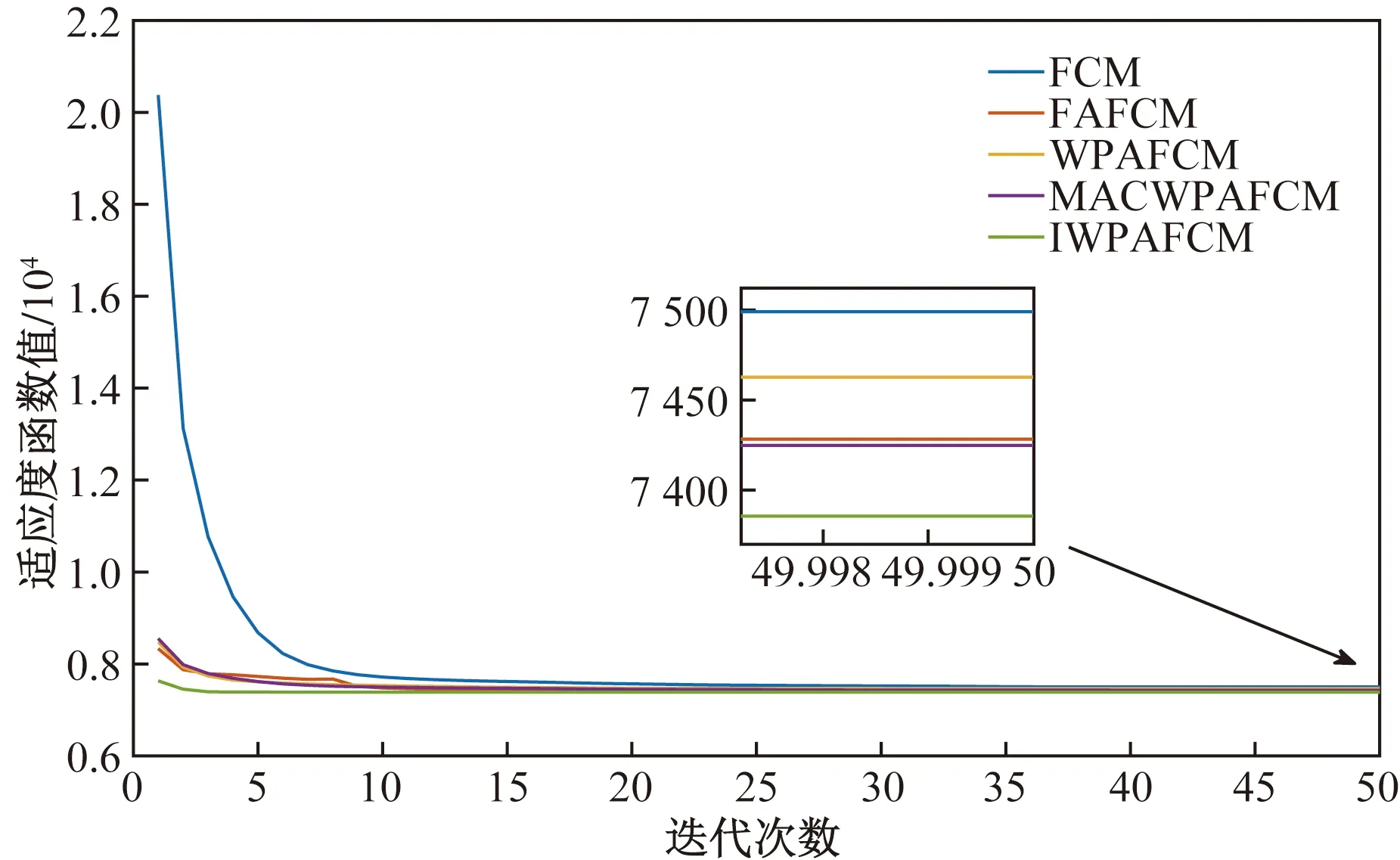
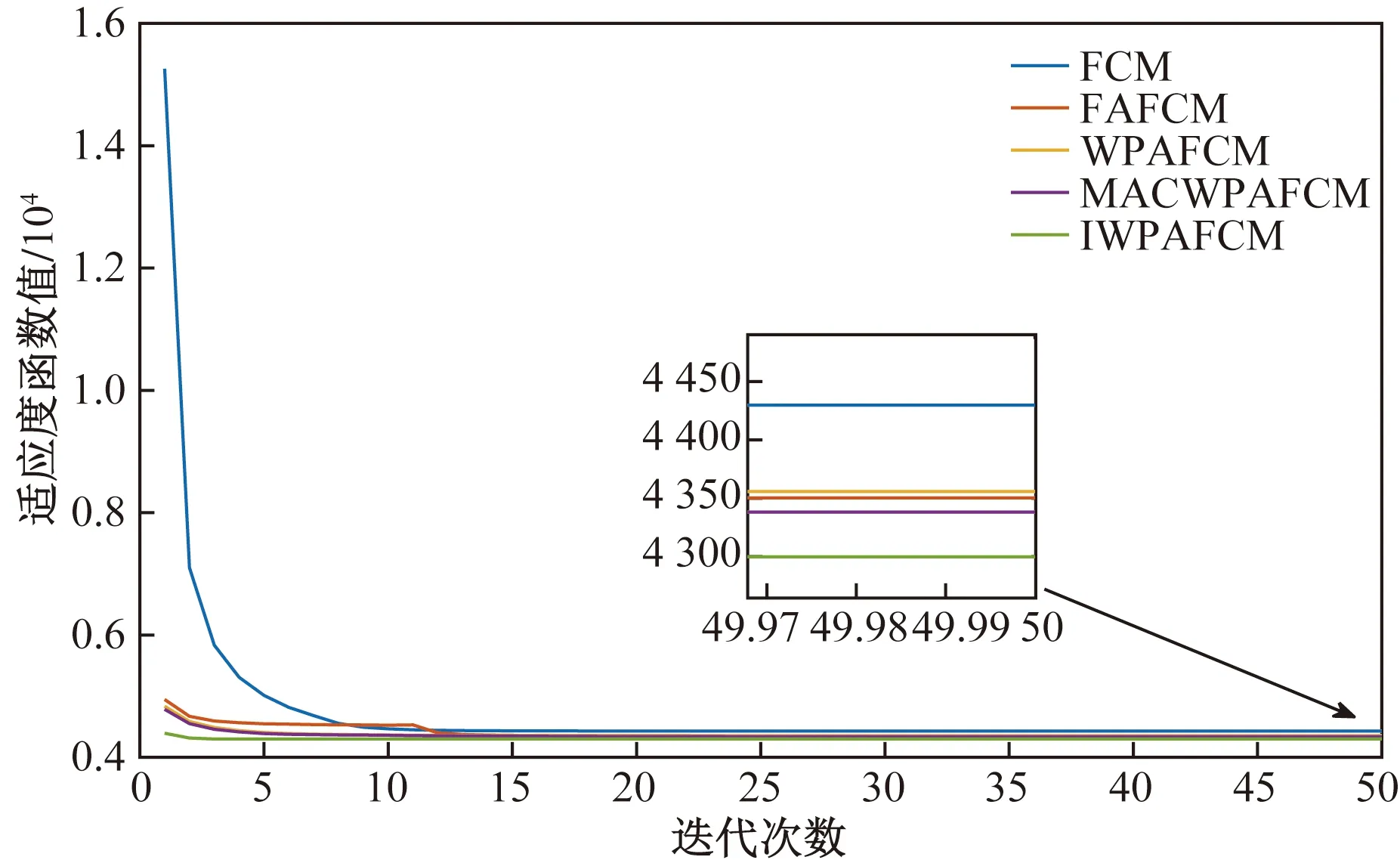
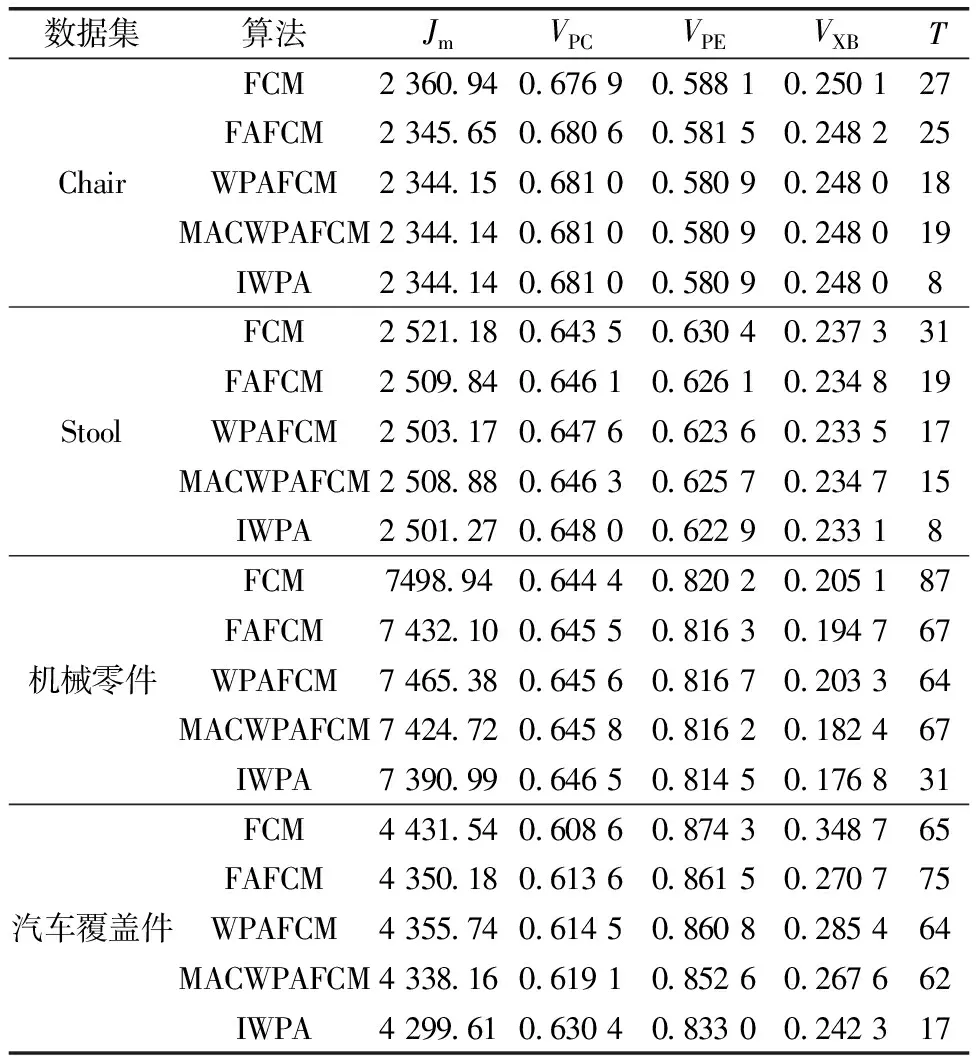
IfY Ylead=Y; Xlead=X; break; %跳出進入召喚行為 end if end for%結束游走 %召喚行為 fori=1:Mnum flag_exit = 0;%判斷頭狼是否替換 wgt=0;%召喚次數 while flag_exit==0 由式(5)和式(7)計算奔襲后位置 由式(8)計算交互位置 分別計算新位置適應度 選取三者最優位置X和最優Y wgt= wgt+1; ifY Ylead=Y; Xlead=X; wgt=Wmax; end if %圍攻行為 if wgt==Wmax 由(6)和式(7)計算圍攻后位置 選取當前最優位置X和最優Y ifY Ylead=Y; Xlead=X; flag_exit = 1; break end if end if%結束圍攻 end while end for%結束召喚 佳點集更新狼群 %高斯擾動機制 由式(9)和式(10)計算和更新頭狼 end for%結束迭代 在基本WPA算法上主要進行了步長調整、改變圍攻條件、增加交互行為和高斯擾動機制等,此處對改進后的算法復雜度進行分析。算法的計算量通常根據迭代次數乘以每次迭代的計算量進行評估,所以對照偽代碼,取一次迭代過程的計算量為例來簡要說明算法的計算量,假設一次迭代過程中游走和召喚行為只執行一次,取探狼和猛狼數量同為Snum。 WPA算法計算量為:游走行為中加法hSnum次,乘法2hSnum次;召喚行為中加法3Snum,乘法2Snum;圍攻行為中加法2Snum,乘法2Snum。IWPA算法的計算量為:游走行為中加法Snum(h+5)次,乘法2Snum(h+1.5),召喚行為中加法2Snum,乘法3Snum。 通過一次迭代計算量可以看出,IWPA 算法的計算量大于WPA。在實際應用過程中,本文研究中IWPA采用頭狼更新或達到最大召喚次數進入圍攻行為,WPA則以頭狼更新或進入圍攻距離作為進入圍攻行為的條件,而圍攻距離參數的設定會影響WPA算法的運行時間,設定過小猛狼很難進入圍攻行為,算法計算量會增大;過大計算量小但不利于尋優。IWPA則利用自適應步長、交互行為和最大圍攻次數配合,雖然增加了一定的算法運行時間,但保證了算法優秀的尋優性能和避免早熟的能力。 為了驗證算法的有效性,應用MATLAB2018a對上述算法加以實現,以ModelNet40公開數據集[30]中Chair、Stool點云模型和實測點云機械零件、汽車覆蓋件點云模型為例進行點云數據的區域分割,并與基本FCM算法、基于算法MACWPA[20]、WPA[23]、FA[26]優化的模糊聚類算法分割效果進行對比,取30次實驗中出現次數最多的分割效果作為該算法分割效果,當分割效果相同時,以得到該分割效果的次數(成功率)進行比較。 對于點云數目較少的Chair和Stool點云模型,點數都為10 000,如圖3和圖4所示,圖3(a)為Chair原始點云;圖3(b)為Chair分割前曲率顯示;對于Chair點云模型,5種算法都取得了較好的點云模型分割效果,如圖3(c)所示,都很好地將椅子腿和椅子座面進行了分割,但是對于成功率,基本FCM、FAFCM成功率分別為56.6%、93.3%,WPAFCM、MACWPAFCM和本文算法的成功率都為100%;圖4(a)為Stool原始點云;圖4(b)為Stool分割前曲率顯示;對于Stool點云模型,5種算法同樣都取得了較好的點云模型分割效果,都很好地將凳子腿和凳子座面進行了分割,基本FCM、FAFCM、WPAFCM、MACWPAFCM和本文算法成功率分別為36.7%、83.3%、96.7%、93.3%和100%。綜上可以看出對于兩種公開數據集點云模型,本文算法點云聚類分割效果好且結果穩定,成功率都達到了100%。 圖3 Chair點云數據區域分割 對于實測點云,如圖5和圖6所示,圖5(a)為機械零件原始點云,點數為140 282;圖5(b)為機械零件分割前數據點的曲率顯示,同一曲面會包含少量曲率屬性不同的點;圖5(c)為基本FCM算法和WPAFCM算法分割結果,可明顯看到在模型前側對于邊界分割的效果不理想,成功率分別為46.7%和53.3%;圖5(d)為本文算法、MACWPAFCM和FAFCM算法分割結果,用8種不同顏色來表示類型不同的面,可以看到邊界清晰,準確表達了點云分割結果,成功率分別為93.3%、73.3%和63.3%。圖6(a)為汽車覆蓋件原始點云,點數為147 197;圖6(b)為汽車覆蓋件分割前數據點的曲率顯示,同一曲面會包含少量曲率屬性不同的點;圖6(c)為基本FCM、WPAFCM算法和FAFCM算法分割結果,可明顯看到在粉紫色類中包含有藍色類的點,分割效果不理想,其成功率分別為36.7%、56.7%和63.3%;圖6(d)為本文算法和MACWPAFCM分割結果,用8種不同顏色來表示分割結果,可以看到邊界清晰,準確表達了點云分割結果,其成功率分別為100%和53.3%。綜上可以看出對于兩種實測點云模型本文算法點云聚類分割效果好且結果穩定。 圖5 機械零件點云數據區域分割 為了客觀、科學地評價點云分割的結果,利用聚類性能評價指標劃分系數VPC、劃分熵VPE和緊湊度與分離度的比值VXB來評價算法性能與聚類效果。各指標表達式為 (17) (18) (19) 式中:VPC、VPE僅與隸屬度矩陣uij有關,VPC越大表示聚類結果最有效,VPE則相反[31];VXB與數據的幾何結構有關,是類內緊湊度與類間分離度的比值,因此VXB越小表示聚類結果越有效[32]。 分別用FCM、FAFCM、WPAFCM、MACWPAFCM和IWPAFCM算法在4種數據集上進行聚類分析,求得其各自的適應度函數值以及聚類性能指標VPC、VPE和VXB,并統計其達到收斂精度(1×10-6)時的迭代次數T。種群規模取15,各算法分別運行30次,MACWPAFCM、WPAFCM、FAFCM算法參數設定參考文獻[20,23,29],求得各項指標的平均值,對比結果如表3所示,迭代過程圖如圖7~圖10所示(對于ModelNet40數據集取20次迭代,實測數據集取50次迭代結果進行對比,因為在20、50次迭代之后兩類數據集收斂所需迭代次數較多的FCM算法也接近收斂,數值不再有太大變化)。 圖8 Stool模型的聚類迭代過程 圖9 機械零件的聚類迭代過程 圖10 汽車覆蓋件的聚類迭代過程 表3 各項指標的實驗結果比較 根據評價準則,VPC越大越好,Jm、VPE、VXB越小越好,由表3可以看出對于各類數據集,本文算法較其他4種算法在適應度函數值Jm和VPC、VPE、VXB聚類指標值上均為最優,在迭代次數上本文算法明顯減少。其中FCM算法在各項指標中均為最差值。 對于Chair數據集,本文算法較FAFCM和FCM算法,在VPC指標上平均提高0.4%~4.1%,在適應度函數值Jm上平均減少0.2%~1.68%,在VPE指標上平均減少0.6%~7.2%,在VXB指標上平均減少0.2%~2.1%,WPAFCM和MACWPAFCM算法與本文算法取得了相同的指標值,但本文算法在迭代次數上較其他4種算法平均迭代減少了10~19次;對于Stool數據集,本文算法在VPC指標上平均提高0.4%~4.5%,在在適應度函數值Jm上平均減少0.2%~1.99%,在VPE指標上平均減少0.7%~7.5%,在VXB指標上平均減少0.4%~4.2%,在迭代次數上平均減少7~23次;綜上可知對于點云數較少的兩種ModelNet40數據集,本文算法在VPC指標上平均提高0.4%~4.3%,適應度函數值Jm平均減少0.2%~1.84%,在VPE指標上平均減少0.65%~7.35%,在VXB指標上平均減少0.3%~3.15%,平均迭代次數減少8~21次。因為點云數較少,對比算法同樣可以取得較好的各項指標,所以單純從數據上感覺提升不是很高,但在此基礎上本文算法仍在指標上略有提高的同時,迭代次數明顯減少。 對于機械零件,本文算法在VPC指標上平均提高0.7%~2.1%,在適應度函數值Jm上平均減少4.06%~10.75%,在VPE指標上平均減少1.7%~5.7%,在VXB指標上平均減少5.6%~28.3%,在迭代次數上平均減少33~56次;對于汽車覆蓋件,本文算法在VPC指標上平均提高11.3%~21.8%,在適應度函數值Jm上平均減少3.85%~13.19%,在VPE指標上平均減少1.96%~4.13%,在VXB指標上平均減少2.53%~10.64%,在迭代次數上平均減少45~58次;綜上可知對于點云數較多的兩種實測點云數據,本文算法在VPC指標上平均提高6%~11.95%,適應度函數值Jm平均減少3.95%~11.97%,在VPE指標上平均減少1.83%~4.92%,在VXB指標上平均減少4.06%~19.47%,平均迭代次數減少39~57次。 從圖7~圖10同樣可以看出,本文算法較其他4種算法,不僅收斂速度快,收斂所需迭代次數少,而且獲得了較優的適應度函數值。因為IWPAFCM算法在初始種群分布、搜索能力方面做出了改進,可以快速高效地獲得聚類過程中較優的聚類中心,因此提高了聚類性能,減少了迭代次數,也獲得了更好的綜合評價指標。 為提高聚類性能、解決標準FCM算法對初始值敏感的問題,本文提出一種基于曲率約束的改進狼群算法優化模糊聚類的混合算法IWPAFCM。在該算法中,首先利用佳點集將人工狼種群均勻分布到解空間中,生成分布均勻、范圍廣、全局尋優能力強的初始種群;然后引入自適應步長因子,對尋優與收斂速度進行平衡;進一步采用交互策略,增強了狼群的全局探索能力;最后采用高斯擾動對頭狼進行變異處理,使得算法能夠跳出局部最優。曲率約束點距離的引入,使得IWPAFCM不僅保證了良好的全局與局部尋優能力,而且能夠穩定地得到良好的點云分割效果。 為驗證算法有效性,利用兩種ModelNet40公開數據集和兩種實測點云模型進行仿真實驗。結果表明,在兩種ModelNet40公開數據集上,IWPAFCM算法相比4種對比算法中效果最差的FCM算法,在VPC指標上平均提高4.3%,適應度函數值Jm平均減少1.84%,在VPE指標上平均減少7.35%,在VXB指標上平均減少3.15%,平均迭代次數減少21次;相比4種算法中效果最好的MACWPAFCM算法在VPC指標上平均提高0.4%,適應度函數值Jm平均減少0.2%,在VPE指標上平均減少0.65%,在VXB指標上平均減少0.3%,平均迭代次數減少8次。在兩種實測點云數據集上,相比4種對比算法中效果最差的FCM算法,本文算法在VPC指標上平均提高11.95%,適應度函數值Jm平均減少11.97%,在VPE指標上平均減少4.92%,在VXB指標上平均減少19.7%,平均迭代次數減少57次。相比4種算法中效果最好的MACWPAFCM算法在VPC指標上平均提高6%,適應度函數值Jm平均減少3.95%,在VPE指標上平均減少1.83%,在VXB指標上平均減少4.06%,平均迭代次數減少39次。表明本文算法能夠準確找到初始聚類中心,獲得了良好的點云分割效果,減少了迭代次數,提升了聚類性能。4 實驗結果與分析
4.1 定性分析

4.2 定量分析
5 結論
