海洋底質類型圖矢量化智能制作技術研究
2023-11-28 10:08:10王風帆孔敏余佳韓璐遙
海洋信息技術與應用 2023年4期
關鍵詞:方法
王風帆,孔敏,余佳,韓璐遙
(國家海洋信息中心,天津 300171)
海洋底質類型圖是開展海洋環境研究的基礎圖件之一,常用于海洋工程、沉積環境研究等領域[1-2]。傳統底質制圖方法依賴于制圖人員的專業知識,主觀性強且效率不高[3]。隨著計算機技術的發展,空間插值技術的引入大大提高了底質類型圖制作的效率。張立華等[4]和王濤等[5]引入了Voronoi圖生成技術;楊康等[3]利用反距離加權和克里金法進行網格點粒級組分插值,然后采用柵格疊合法計算底質類型。Jerosch[6]改進了柵格疊合法,利用協同克里金法引入地形信息,并證明該方法適用于不含礫石的謝帕德分類。Lark等[7]直接利用協同克里金法進行底質類型預測,但只針對簡化的福克分類(含礫),且實現過程復雜,對統計學知識要求較高。由于克里金法對數據在空間平穩性和統計分布上的要求較高,限制了其在底質類型圖制作中的應用。劉付程等[8-9]和袁瑋等[10]提出了一種基于概率測度的底質類型制圖法,降低了對數據的要求,且能夠對插值結果的不確定性進行評價,但對空間統計相關知識要求較高。上述海洋底質類型圖制作方法均需要準確的沉積物組分信息,無法應用于組分信息缺失的場景,且其目標產品均為網格或位圖數據,不利于后續圖件修改工作的開展。
本文針對傳統底質類型圖制作中存在的問題,基于隨機森林算法分類功能,研究海洋底質類型網格數據智能制作方法,設計了底質類型分布矢量圖的制作與平滑流程,能夠獲取準確的底質類型分布矢量數據,使底質類型邊界光滑美觀,最終利用渤海區域底質數據進行應用試驗,結果與柵格疊合法進行對比分析,證明了該方法的有效性。
1 數據情況
本文選用渤海區域歷史調查獲取的表層沉積物樣品粒度數據,共790 站,包含經度、緯度、各組分比例(礫石、砂、粉砂、黏土)信息,數據完整且較為規范(組分比例之和為100%±1%)[11],可精準確定底質類型并用于后期方法驗證。站位數空間分布如圖1所示。
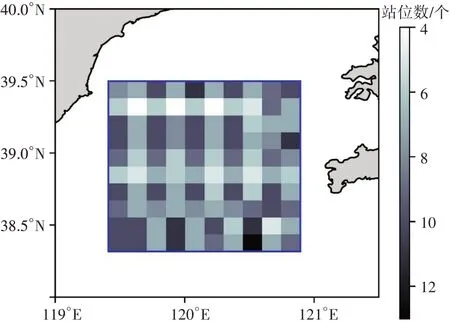
圖1 底質數據站位數空間分布圖
依據福克分類法[7],將數據劃分為11 種底質類型。從數量上看(圖2),以砂質粉砂、粉砂質砂、泥質砂和粉砂為主,黏土、礫質泥質砂、含礫泥、礫質砂十分稀少。
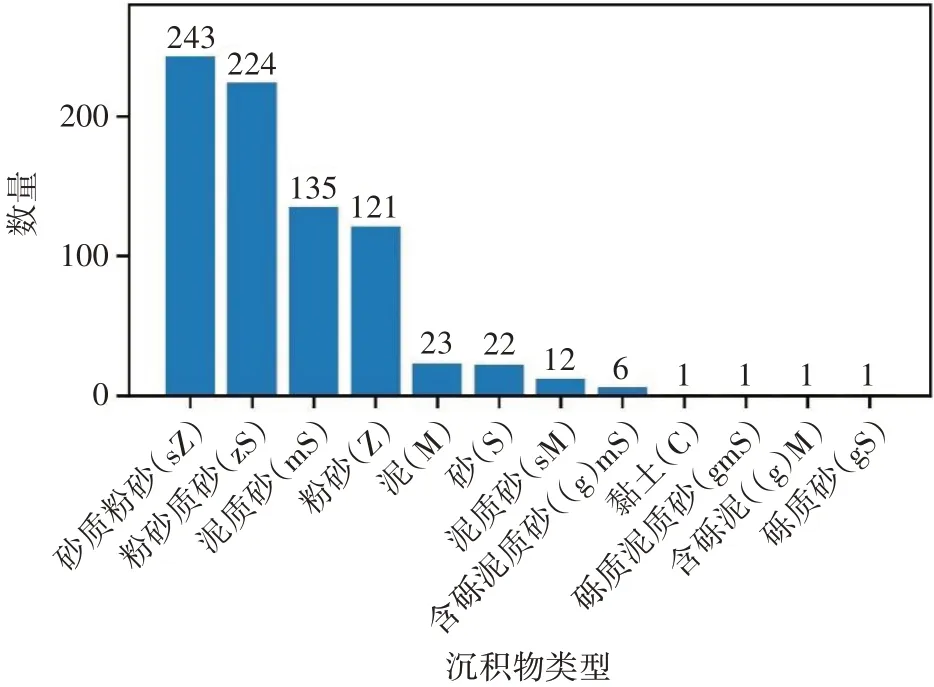
圖2 底質類型站位數量分布圖
2 技術方法
2.1 隨機森林算法
考慮到海洋底質歷史數據中,沉積物組分信息經常存在缺失的情況,因此對于一些缺少詳細數據的區域只能利用已知的底質類型直接成圖。而底質類型屬于離散數據,大部分插值方法不適用該場景,因此本文利用機器學習隨機森林算法的分類功能,通過學習底質數據的空間自相關性來預測未采樣位置的底質類型。
2.1.1 算法原理
隨機森林算法是指為增強決策樹的多樣性而在決策樹構建過程中對樣本和特征進行隨機化選擇的集成化學習方法(圖3),即具有隨機化決策樹的Bagging 集成,屬于非參數統計方法與決策樹算法的結合[12]。隨機森林算法不需要先驗假設,可以充分利用輸入信息,能夠處理樣本不平衡問題且不容易出現過擬合,具有較高的運算速度和穩健性,易于操作和使用,因而在數據分類中廣泛應用。
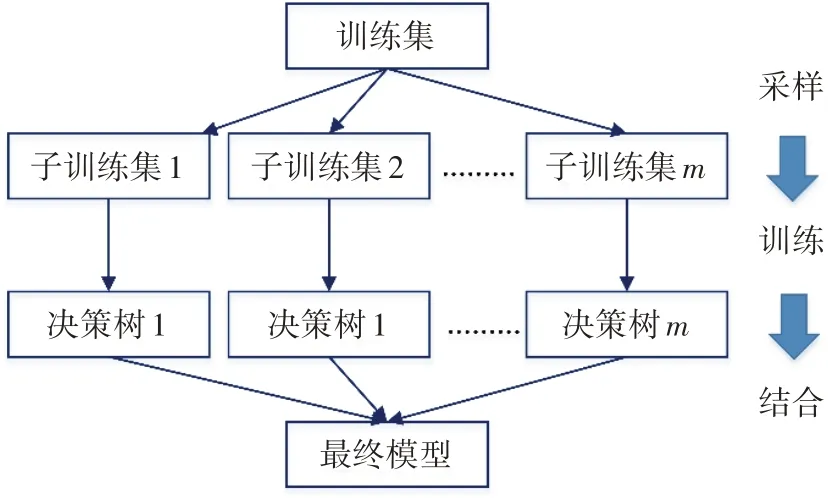
圖3 隨機森林算法原理圖
隨機森林算法首先對具有K個特征的訓練數據集進行有放回隨機采樣,形成m個子訓練集,針對每個子訓練集隨機抽取k個特征(k≤K)來建立m個決策樹,然后在測試或實際分類時,采用投票作為結合策略,以決策樹預測最多(票數最高)的類別作為最終結果。這種通過隨機抽取部分樣本來生成決策樹的方法稱為Bagging 集成。決策樹建立需要確定分裂方法,常用的是不純度度量法,包括Gini 系數法、信息增益法、增益比率法等。這里采用應用最廣泛的Gini 系數,其公式為:
式中:pl為輸入樣本屬于第l個類別(共L個類別)的概率。Gini系數越小代表樣本純度越高。
2.1.2 模型評估指標
評估分類模型性能的指標有準確率、精準率、召回率和F1 值等[13]。其中,準確率是常用的模型評價指標:
式中:TP為真正類,指一個正類實例被預測為正類;TN為真負類,指一個負類被預測為負類;FP為假正類,指一個負類被預測為正類;FN為假負類,指一個正類被預測為負類。
在數據不均衡的情況下,準確率對模型性能的反映存在很大缺陷,因此需要從不同角度去評價分類效果。
精準率Pre為真正類與預測為正類的數量之比。
召回率Rec為真正類與實際為正類的數量之比。
F1 值是精準率與召回率的結合,能夠對模型進行整體評價。
考慮到本文數據中各底質類型數量并不均衡,雖然算法構建過程中采取了一定措施,但為了進一步減小數據不均衡帶來的影響,最終采用F1 值作為建模過程中的評價指標。
2.1.3 類型編碼
將輸入數據中的經度和緯度作為特征變量,底質類型為標簽變量。底質類型為字符型數據,算法無法識別,需要將其轉換為離散化數值[12](表1)。
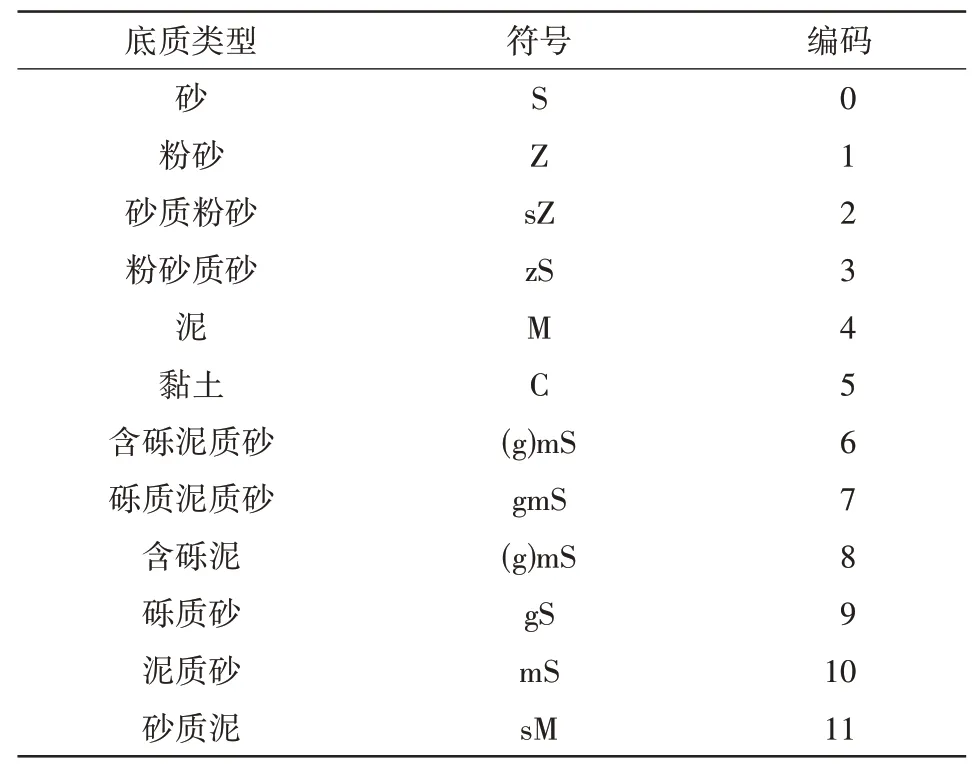
表1 底質類型編碼
將數據輸入模型進行訓練,決策樹數量設置為100,完成后將成圖網格點處坐標輸入模型,以預測坐標點處的坐標類型編碼,然后利用表1進行反編碼,即可獲取底質類型的網格數據。根據數據空間分布范圍,設置網格步長為0.6'。
2.2 矢量圖制作
獲取網格數據后,便可進行底質類型圖的制作。底質類型圖不同于等值線及等值線填充圖,其以多邊形面為主體,內部的底質類型一致。常規作圖法采用網格填充或者最近鄰插值方式,但在網格步長較大時會產生明顯的鋸齒狀邊界。而等值線生成法雖然能夠產生光滑的邊界,但由于其將輸入編碼作為連續數值,最終會產生連續疊加的“厚”邊界甚至不正確的面要素,需要后期進行手工編輯修正,增加了工作量[14]。
為了改善這一問題,本文利用ArcGIS 的矢量數據操作功能[15-16],提出了一種底質類型邊界平滑方法。具體如下:
采用最近鄰插值獲取底質類型面要素,利用Data Management Tools -> Feature -> Feature to Point 功能提取面要素的代表點,并利用Spatial Analyst Tools -> Extraction -> Extract Values to Points功能將底質類型信息添加到代表點中。
將面要素轉換為線要素(邊界線),利用Cartography Tools -> Generalization -> Smooth Line功能對邊界線進行光滑。這里平滑算法選用Peak,容差為1°。
利用Data Management Tools -> Feature ->Feature to Polygon 將邊界線與研究區多邊形結合生成具有光滑邊界的面要素。
利用Analysis Tools -> Overlay -> Spatial Join功能,將代表點的底質類型信息賦給面要素。
最終,對面要素進行顏色填充等操作,完成底質類型圖的編制。總體技術路線如圖4所示。
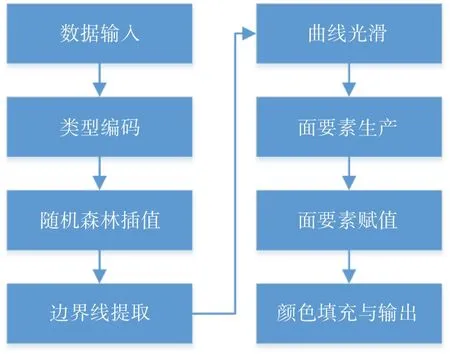
圖4 技術路線圖
3 試驗與分析
為了測試模型的有效性,需要將數據集劃分成兩個部分,分別用于模型構建與測試。考慮到含礫泥質砂等5 種沉積物數量過少(<10),無法開展測試,因此將其剔除,然后按6∶4 的比例將數據集劃分為訓練集與測試集,利用訓練集建立底質類型空間預測模型,并利用測試集對模型進行評估。分析評估結果(表2)發現,模型總體加權平均F1 值為60%,其中對泥質砂的預測性能較好,F1 值達到了71%,但對砂和砂質泥的預測性能很差,F1 值為0%。這里影響模型性能的因素主要有兩個,一個是樣本數量,另一個則是樣本的分布情況。樣本數量越少,算法挖掘其規律的效果就越差;而分布零散,會導致某一種沉積物的分布區內沒有樣本用于模型建立,也會影響測試結果。因此除了量化分析結果外,還需要通過繪制底質類型圖并與已有方法制作的圖件相比較進行驗證分析。

表2 隨機森林模型測試結果
將渤海沉積物粒度數據按照本文建立的智能制圖方法進行網格化與圖件制作,即假設研究區內底質數據僅有底質類型信息,沉積物組分信息缺失,在該情形下制作獲取底質類型圖(圖5(a))。為了分析圖件的有效性,需對比底質數據中沉積物組分信息完整的場景,即采用柵格疊合法制作底質類型圖進行比較(圖5(b))。面要素顏色填充均依據國家標準《海洋要素圖示圖例及符號》(GB/T 32067-2015)[16]。
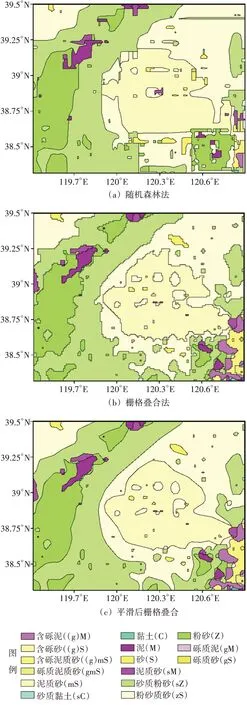
圖5 不同方法制作的底質分類圖
首先,隨機森林與柵格疊合的制圖結果十分接近,整體趨勢基本一致。柵格疊合的結果可靠性較高,但也是基于詳細的組分信息,在許多收集的海洋底質類型圖等資料中并不包含這些信息,因此隨機森林方法在一定情形下作為常規制圖法的補充是比較可靠的。
其次,柵格疊合比隨機森林結果多出3 個底質類型,砂質黏土(sC)、礫質泥(gM)和含礫砂((g)S),這是由于柵格疊合是基于組分進行插值,疊合后需要重新進行類型劃分。沉積物的空間分布具有一定的漸變性特征,不同底質類型之間的邊界具有模糊性(不確定性)[10],因此出現這種現象是合理的。但這些類型占比非常小,對結果影響不是很大,因此隨機森林結果可用性還是很高的。
最后,柵格疊合法產生的底質類型邊界由于最近鄰插值呈鋸齒狀,一般為了消除這種現象需要設計更小的網格間距,會加大計算量。而本文提出的邊界平滑方法可以解決這個問題,并能夠獲取易于編輯的矢量數據,有利于后期的圖件修改。此外,該平滑方法也可應用于柵格疊合法邊界平滑,效果明顯(圖5(c))。
4 結語
本文針對底質類型數據,提出基于隨機森林算法的底質類型圖網格制作方法,并利用ArcGIS的矢量數據操作功能構建底質類型邊界平滑方法,開發了底質類型矢量圖智能制作技術,最終利用渤海沉積物粒度數據進行應用試驗,并與柵格疊合技術進行了對比,得出結論如下:
(1)本文提出的底質類型智能預測方法能夠對未采樣位置的底質類型進行有效預測。
(2)利用本文提出的底質類型邊界平滑方法可以獲得平滑的底質類型邊界,制作出的圖件較為美觀。
(3)本文提出的底質類型矢量圖智能制作方法,是對傳統底質類型圖制作方法的補充與改進,能夠有效提高圖件制作效率,有利于后續研究工作的開展。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
