Python數(shù)據(jù)可視化的優(yōu)勢(shì)
——以《三國(guó)演義》為例
2023-11-29 09:47:22李文娟
中國(guó)教育技術(shù)裝備 2023年19期
關(guān)鍵詞:可視化
李文娟
甘肅省定西市安定區(qū)教育局 甘肅定西 743000
0 引言
在數(shù)據(jù)科學(xué)、人工智能、大數(shù)據(jù)分析等迅猛發(fā)展的當(dāng)前,數(shù)據(jù)可視化的方法不勝枚舉,數(shù)據(jù)可視化的目的主要是直觀展示信息的分析結(jié)果和構(gòu)思,使大量抽象的數(shù)據(jù)具象顯示。國(guó)外常用的數(shù)據(jù)可視化工具有Visual Eyes、Google Trends、Many Eyes、Grasshopper、WebGL 等,國(guó)內(nèi)常見的數(shù)據(jù)分析工具有Excel 數(shù)據(jù)圖表分析、SPSS 在線(軟件)數(shù)據(jù)分析、CiteSpace 可視化文獻(xiàn)分析、Python 第三方庫(kù)數(shù)據(jù)可視化等。本文以Python 語(yǔ)言數(shù)據(jù)可視化的過程為例,展現(xiàn)Python 強(qiáng)大的數(shù)據(jù)分析及可視化功能。
1 大數(shù)據(jù)時(shí)代數(shù)據(jù)可視化成為發(fā)展趨勢(shì)
1.1 大數(shù)據(jù)的時(shí)代背景
奧地利科學(xué)家維克托·邁爾-舍恩伯格是最早洞見大數(shù)據(jù)時(shí)代發(fā)展趨勢(shì)的數(shù)據(jù)科學(xué)家之一,2012年他在《大數(shù)據(jù)時(shí)代》中前瞻性地指出,大數(shù)據(jù)帶來(lái)的信息風(fēng)暴正在變革我們的生活、工作和思維方式。國(guó)際互聯(lián)網(wǎng)數(shù)據(jù)中心預(yù)測(cè),2025年全球每年產(chǎn)生的數(shù)據(jù)將達(dá)到175ZB,如果把175ZB 全部存在DVD 光盤中,那么DVD 疊加起來(lái)的高度可以繞地球222 圈。在如此海量的數(shù)據(jù)中,如何快速便捷地展現(xiàn)和發(fā)掘其中的價(jià)值,是一個(gè)巨大的挑戰(zhàn)。大數(shù)據(jù)時(shí)代信息量暴增,高效地獲取數(shù)據(jù)成為人們最關(guān)注的問題,也將成為未來(lái)研究的趨勢(shì)。
1.2 數(shù)據(jù)可視化的發(fā)展歷程
數(shù)據(jù)可視化的發(fā)展可追溯至20世紀(jì)50年代計(jì)算機(jī)圖形學(xué)的早期。在中國(guó)知網(wǎng)學(xué)術(shù)平臺(tái)上,以“數(shù)據(jù)可視化”為主題詞檢索發(fā)現(xiàn),最早在1993年有一篇數(shù)據(jù)可視化的研究報(bào)告,文中提到1986年美國(guó)提出科學(xué)計(jì)算可視化的概念,在國(guó)際上引起廣泛重視。從20世紀(jì)90年代開始,國(guó)內(nèi)一些高校和研究所相繼開展了可視化技術(shù)的研究[1]。根據(jù)知網(wǎng)發(fā)文年度趨勢(shì)表可知,從1993年至今,有關(guān)數(shù)據(jù)可視化的文獻(xiàn)數(shù)量逐年增多,尤其從2012年開始增長(zhǎng)速度加快,在2020年達(dá)到峰值,至今研究熱度一直未減。
1.3 數(shù)據(jù)可視化的典型工具
表1 中簡(jiǎn)述了當(dāng)前常用的6 種數(shù)據(jù)可視化工具,它們?cè)诟髯缘膽?yīng)用領(lǐng)域有獨(dú)特的功能優(yōu)勢(shì),Visual Eyes 常用于可視化教學(xué);Google Trends 應(yīng)用于全球新聞等各類信息的可視化;Many Eyes 用于展現(xiàn)在線的可視化社區(qū)信息;Grasshopper 在建筑信息可視化方面更占優(yōu)勢(shì);WebGL 是一個(gè)不需要組件加載的網(wǎng)絡(luò)三維可視化技術(shù);Cite Space 在論文熱點(diǎn)研究可視化方面功能強(qiáng)大。相較這些技術(shù)手段,Python 的應(yīng)用領(lǐng)域更為廣泛,發(fā)展前景更好。
2 Python數(shù)據(jù)可視化的優(yōu)勢(shì)
2.1 Python是一門功能強(qiáng)大及應(yīng)用廣泛的編程語(yǔ)言
Python 是Guido van Rossum 在1990年開發(fā)的一個(gè)輕語(yǔ)法、弱類型的高級(jí)編程語(yǔ)言軟件,它擁有強(qiáng)大的第三方庫(kù),最大的優(yōu)勢(shì)是比其他語(yǔ)言更簡(jiǎn)單易學(xué),功能強(qiáng)大,數(shù)據(jù)結(jié)構(gòu)高效,能快速實(shí)現(xiàn)面向?qū)ο蟮木幊獭3藬?shù)據(jù)可視化功能,該語(yǔ)言也廣泛支持應(yīng)用程序的開發(fā),在詞云、數(shù)據(jù)可視化、數(shù)據(jù)倉(cāng)庫(kù)與數(shù)據(jù)挖掘、仿真系統(tǒng)等方面都有很多應(yīng)用。在云端、網(wǎng)站、游戲開發(fā)、機(jī)器人、航天飛機(jī)控制、物聯(lián)網(wǎng)終端等領(lǐng)域,Python 應(yīng)用無(wú)處不在[8]。此外,Python 還可以利用第三方庫(kù)爬取網(wǎng)絡(luò)、網(wǎng)頁(yè)以及網(wǎng)站內(nèi)容,從而快速地收集所需要的信息。近年來(lái),Python 在人工智能領(lǐng)域扮演著重要的角色,有很多典型的應(yīng)用案例,例如:谷歌的無(wú)人駕駛、谷歌的AlphaGo 項(xiàng)目、微軟的小冰、蘋果的Siri、IBM的Watson 等[9]。
2.2 Python 具有豐富的第三方庫(kù)
Python 有標(biāo)準(zhǔn)庫(kù)和第三方庫(kù)兩類,標(biāo)準(zhǔn)庫(kù)Python 安裝自帶,可供使用者隨意使用,第三方庫(kù)則需要另外下載或者在線安裝。強(qiáng)大的標(biāo)準(zhǔn)庫(kù)是基礎(chǔ),豐富的第三方庫(kù)是強(qiáng)化,隨著應(yīng)用領(lǐng)域的拓展,強(qiáng)大的第三方庫(kù)使用途徑越來(lái)越廣泛,在高中信息技術(shù)教材中,涉及的第三方庫(kù)較多,每一個(gè)庫(kù)都有一個(gè)典型的應(yīng)用特例,下面通過表2 對(duì)這些庫(kù)進(jìn)行匯總介紹。

表2 Python 第三方庫(kù)介紹
2.3 Python數(shù)據(jù)可視化的過程有章可循
通過查閱大量文獻(xiàn),發(fā)現(xiàn)利用Python 實(shí)現(xiàn)數(shù)據(jù)可視化的過程都有固定的模式。如戴瑗、鄭傳行基于Python,在爬取及分析南京二手房數(shù)據(jù)時(shí),對(duì)數(shù)據(jù)進(jìn)行采集、清洗,再對(duì)清洗后的數(shù)據(jù)進(jìn)行可視化分析。翟高粵基于Python 的數(shù)據(jù)分析過程包含需求分析、數(shù)據(jù)獲取、數(shù)據(jù)預(yù)處理、分析建模、模型評(píng)價(jià)與優(yōu)化、部署等步驟。陳都、徐峰的創(chuàng)傷流行病學(xué)可視化研究包括數(shù)據(jù)導(dǎo)入、數(shù)據(jù)清洗、統(tǒng)計(jì)分析、數(shù)據(jù)可視化以及模型建立等步驟。錢貝貝、陳志波基于Python 爬蟲的音樂數(shù)據(jù)可視化分析過程包含數(shù)據(jù)采集、數(shù)據(jù)預(yù)處理、數(shù)據(jù)分析和可視化展示等步驟,研究隱藏在這些海量數(shù)據(jù)背后的規(guī)律。本文將借鑒高中信息技術(shù)教材中數(shù)據(jù)處理的過程進(jìn)行數(shù)據(jù)可視化研究,按照數(shù)據(jù)采集、數(shù)據(jù)整理、數(shù)據(jù)分析與數(shù)據(jù)可視化四個(gè)步驟,展示Python數(shù)據(jù)可視化的過程。
3 Python數(shù)據(jù)可視化的過程
基于《三國(guó)演義》小說(shuō)文本,利用Python 實(shí)現(xiàn)文本和數(shù)值數(shù)據(jù)可視化。首先用詞云將文本數(shù)據(jù)可視化,主要利用jieba 庫(kù)分詞統(tǒng)計(jì)、imageio庫(kù)導(dǎo)入圖像、WordCloud 庫(kù)生成詞云功能;其次用圖表將數(shù)值數(shù)據(jù)可視化,在第一步的基礎(chǔ)上,采集jieba 分詞統(tǒng)計(jì)出來(lái)的高頻人物詞,利用CSV 文件處理,利用pandas 庫(kù)中的函數(shù)read_csv()讀取,利用NumPy 庫(kù)指定生成柱狀圖的列數(shù),利用Matplotlib 庫(kù)中pyplot 函數(shù)繪制柱狀圖。
Requests 庫(kù)和Beautiful Soup 庫(kù)在《普通高中教科書·信息技術(shù)必修1 數(shù)據(jù)與計(jì)算》教材中沒作介紹,教材涉及的相關(guān)內(nèi)容主要是網(wǎng)絡(luò)爬取數(shù)據(jù)這一內(nèi)容的拓展,向?qū)W生展示爬蟲爬取數(shù)據(jù)的原理與過程,本文將不再贅述。
3.1 用詞云將數(shù)據(jù)可視化
3.1.1 數(shù)據(jù)采集與整理
數(shù)據(jù)采集主要是明確數(shù)據(jù)需求、確定數(shù)據(jù)來(lái)源、選擇數(shù)據(jù)采集的方法。選擇處理的對(duì)象是《三國(guó)演義》小說(shuō)文本,通過網(wǎng)絡(luò)采集的方法,下載獲取文件;數(shù)據(jù)整理是相對(duì)煩瑣的一步,主要通過Word文檔整拼寫檢查及文檔校對(duì)功能校正文字,然后整理成txt 文件,放在指定文件夾中。
3.1.2 數(shù)據(jù)分析與可視化
數(shù)據(jù)分析與數(shù)據(jù)可視化既緊密聯(lián)系又相互融合,此處使用結(jié)構(gòu)分析法,將分析的結(jié)果以詞云的形式生動(dòng)、直觀地呈現(xiàn)出來(lái)。首先使用jieba 庫(kù)進(jìn)行前20 個(gè)高頻詞統(tǒng)計(jì),具體過程如圖1所示,從圖中可知在《三國(guó)演義》中曹操、孔明、劉備等詞語(yǔ)出現(xiàn)頻率很高,大概可以得出小說(shuō)主要圍繞這些人物展開故事。
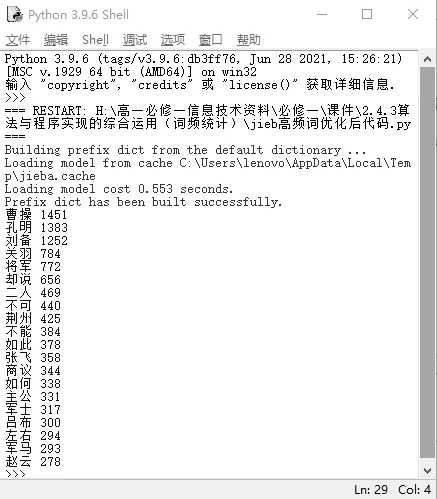
圖1 《三國(guó)演義》前20 個(gè)高頻詞統(tǒng)計(jì)
具體代碼如下:


print(items[i][0],items[i][1]) #輸出詞和出現(xiàn)次數(shù)
其次在jieba 分詞的基礎(chǔ)上應(yīng)用imageio 庫(kù)和Wordcloud 庫(kù)生成詞云,具體如圖2所示,通過文字大小決定詞語(yǔ)頻率,詞云可以將小說(shuō)出現(xiàn)頻率較高的主要詞語(yǔ)直觀呈現(xiàn)出來(lái)。

圖2 《三國(guó)演義》詞云
具體代碼如下:


3.2 用圖表將數(shù)據(jù)可視化
3.2.1 數(shù)據(jù)采集與整理
此處的數(shù)據(jù)采集基于以上網(wǎng)絡(luò)采集的文本,具體步驟是根據(jù)上面jieba 分詞統(tǒng)計(jì)的高頻詞,刪除與人物無(wú)關(guān)的高頻詞匯,只保留人物詞匯,將詞匯與頻次統(tǒng)計(jì)整理在數(shù)據(jù)表格文件中并保存為csv 文件,放在指定文件夾中。
3.2.2 數(shù)據(jù)分析與可視化
為清晰顯示每個(gè)高頻人物詞出現(xiàn)的數(shù)量,選擇對(duì)比分析法,生成柱狀圖,從而直觀地展示小說(shuō)中出現(xiàn)頻率較高的七位人物的頻次差距,從圖3 得出頻率較高的七位三國(guó)人物是曹操、孔明、劉備、關(guān)羽、張飛、呂布、趙云,出現(xiàn)頻次分別為1 451、1 383、1 252、784、358、300、278。
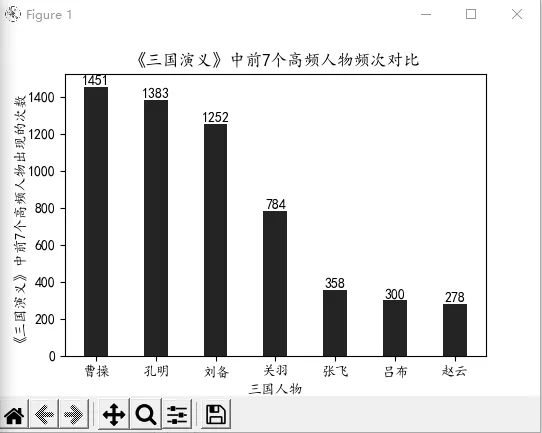
圖3 《三國(guó)演義》前七位高頻人物出現(xiàn)的頻次
具體代碼如下:


4 結(jié)論
Python作為眾多數(shù)據(jù)可視化呈現(xiàn)的工具之一,有簡(jiǎn)潔實(shí)用等多種優(yōu)勢(shì),作為三大主力編程語(yǔ)言榜首的Python,除了應(yīng)用領(lǐng)域廣泛外,相較其他數(shù)據(jù)可視化軟件或語(yǔ)言,既能用圖表實(shí)現(xiàn)數(shù)值數(shù)據(jù)可視化,也能生成詞云實(shí)現(xiàn)文本數(shù)據(jù)可視化,這是Python實(shí)現(xiàn)數(shù)據(jù)可視化或者數(shù)據(jù)分析的獨(dú)特優(yōu)勢(shì),也是本文探索的價(jià)值所在,Python 的前景優(yōu)勢(shì)可歸納為以下三點(diǎn)。
4.1 Python 應(yīng)用領(lǐng)域廣泛
在爬蟲、數(shù)據(jù)分析、機(jī)器學(xué)習(xí)等模塊,Python具有巨大的潛力,強(qiáng)大的第三方庫(kù)賦予Python 更多的應(yīng)用領(lǐng)域,其中pandas、NumPy、 SciPy 等用于數(shù)據(jù)分析,Matplotlib 用于作圖,sklearn 用于機(jī)器學(xué)習(xí),PyBrain 用于神經(jīng)網(wǎng)絡(luò),PyGame 用于多媒體開發(fā)和游戲軟件開發(fā),webpy 用于搭建Web 框架等。
4.2 學(xué)會(huì)Python 就業(yè)前景良好
Python 入門簡(jiǎn)單易學(xué),從事Python 開發(fā),工作機(jī)會(huì)很多,未來(lái)發(fā)展空間也很大,在數(shù)據(jù)科學(xué)、人工智能、網(wǎng)絡(luò)爬蟲、游戲開發(fā)和桌面應(yīng)用開發(fā)等方面,相關(guān)職位種類逐漸增多,如Python 數(shù)據(jù)分析師、人工智能工程師、爬蟲開發(fā)工程師、游戲軟件開發(fā)工程師等。
4.3 Python 用戶體驗(yàn)更好
未來(lái)Python 將會(huì)在功能應(yīng)用方面更快更高更強(qiáng),Python 本身就是一個(gè)很實(shí)用的編程軟件,其標(biāo)準(zhǔn)庫(kù)和第三方庫(kù)非常強(qiáng)大,任何方向的技術(shù)編程都能找到相應(yīng)的支持庫(kù),眾多開發(fā)公司將它作為開發(fā)語(yǔ)言。近幾年P(guān)yPy 解釋器在不斷加快Python 的運(yùn)行速度,相信再過幾年P(guān)ython 在運(yùn)行速度和開發(fā)效率方面將有很大的提升。
猜你喜歡
江蘇安全生產(chǎn)(2022年7期)2022-08-24 02:11:52
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2022年3期)2022-08-22 00:32:50
北京測(cè)繪(2022年6期)2022-08-01 09:19:06
選煤技術(shù)(2022年2期)2022-06-06 09:13:12
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
北京測(cè)繪(2021年7期)2021-07-28 07:01:18
海洋信息技術(shù)與應(yīng)用(2020年1期)2020-06-11 12:43:56
山東農(nóng)業(yè)工程學(xué)院學(xué)報(bào)(2019年11期)2020-01-19 02:49:22
傳媒評(píng)論(2019年4期)2019-07-13 05:49:14
