基于雙視圖特征融合的糖尿病視網(wǎng)膜病變分級
2023-11-29 04:20:42姜璐璐孫司琦鄒海東陸麗娜
華東師范大學學報(自然科學版) 2023年6期
姜璐璐,孫司琦,鄒海東,陸麗娜,馮 瑞,
(1.復旦大學 工程與應用技術研究院,上海 200433;2.上海市眼科疾病精準診療工程技術研究中心,上海 200080;3.復旦大學 計算機科學技術學院 上海市智能信息處理重點實驗室,上海 200433;4.復旦大學 上海市智能視覺計算協(xié)同創(chuàng)新中心,上海 200433;5.上海交通大學附屬第一人民醫(yī)院,上海 200080;6.上海市眼病防治中心,上海 200040)
0 引 言
糖尿病視網(wǎng)膜病變(diabetic retinopathy,DR)是糖尿病的重要并發(fā)癥之一.我國DR 患病率高達15%~ 43%,DR 是成年人致盲的首要原因[1].對DR 患者進行早期篩查、診斷和治療能有效防止其視覺受損及失明.因此,DR 大規(guī)模篩查一直是防盲治盲的重要任務之一.
彩色眼底照相是一種簡單且高效的DR 篩查手段.在社區(qū)篩查中,常使用雙視圖拍攝法對同一只眼睛從2 個不同視角進行拍攝,得到以視盤為中心和以黃斑為中心的2 張圖像,如圖1 所示.由于基層操作人員技術能力有限、老年人瞳孔較小配合度較低等原因,導致從社區(qū)篩查采集到的圖像往往質量較差,存在周邊區(qū)域不可讀、眼底結構不清晰等問題.而雙視圖的眼底圖像對中既有相同區(qū)域,也有不同區(qū)域的互補信息,其相互結合能夠獲得較單視圖更為完整的信息,可以有效解決單視角下圖像遮擋和視場受限等問題.
隨著糖尿病人群的增多和眼科醫(yī)師的相對缺乏,傳統(tǒng)的人工DR 篩查方法已不能有效應對 DR 患病率和致盲率持續(xù)增高的雙重挑戰(zhàn).近年來隨著人工智能(artificial intelligence,AI)的飛速發(fā)展,基于彩色眼底圖像的AI 輔助診斷算法在DR 篩查中展現(xiàn)出了良好的靈敏度和特異度,不僅緩解了眼科醫(yī)師和閱片醫(yī)師的負擔,也在一定程度上彌補了眼科醫(yī)療資源分布不均的不足.
然而,現(xiàn)有的DR 分級算法普遍存在兩個問題: 第一,由于眼底病灶在圖中占比率極小,普通的DR 分級模型使用圖像級標簽進行訓練,準確度低且診斷結果可解釋性差;第二,目前大多數(shù)模型基于單張圖像訓練,不能有效利用彩色眼底照相中多個視圖的信息.
針對以上問題,本文提出了一種基于雙視圖特征融合的DR 分級算法: 首先,將自注意力機制引入DR 分級,以減小圖中背景無關特征的影響,同時增強重要特征對分類結果的影響;其次,提出了一種跨視圖注意力模塊,挖掘雙視圖圖像對之間的語義聯(lián)系,提高DR 分級的準確性.
1 相關工作
1.1 雙視圖融合技術
在基于醫(yī)學影像進行診斷與疾病分級時,醫(yī)師通常會綜合多個視角拍攝的影像作出更加可靠的決策.一般而言,雙視圖融合技術可以分為數(shù)據(jù)層融合、特征層融合和決策層融合這3 種類型.其中,特征層融合即對原始數(shù)據(jù)進行特征提取后,在特征級別進行融合.目前,已有大量研究通過構建卷積神經(jīng)網(wǎng)絡(convolutional neural network,CNN)進行雙視圖醫(yī)學影像分析,這些方法可以分為全局特征融合方法和區(qū)域特征融合方法這兩類[2].
(1)全局特征融合方法是指融合各視圖CNN 分支全局池化后的特征.以乳腺X 線攝像為例,基于矢狀面的CC(craniocaudal)視圖和中側面的MLO(mediolateral oblique)視圖,Wu 等[3]討論了在單一網(wǎng)絡中組合各視圖卷積分支的多種方法,從而得到使乳腺癌分類準確率最高的組合方法.CT(computed tomography)肺部影像中也有類似應用,如Wang 等[4]提出了一種雙視圖CNN,用于從CT 圖像中的軸向、冠狀面和矢狀面視圖分割肺結節(jié).然而,全局特征融合的方法不能關注到圖像的細節(jié)特征,也忽視了視圖之間的潛在聯(lián)系.
(2)區(qū)域特征融合方法是將圖像分成不同區(qū)域,挖掘不同區(qū)域之間的聯(lián)系.Wang 等[5]提出了一種基于區(qū)域的3 步方法: 第一步,從乳腺X 線攝像的每個視圖中提取大量感興趣區(qū)域(region of interest,ROI);第二步,使用基于注意力驅動的CNN 從每個ROI 中提取單視圖的特征;第三步,通過一個基于長短期記憶網(wǎng)絡(long short-term memory,LSTM)的融合模型將各視圖的特征與其他臨床特征相結合.然而,區(qū)域特征融合方法的局限性在于需要對圖像劃分區(qū)域并進行圖像配準,配準的精度直接影響融合效果.
為避免上述問題的出現(xiàn),本文提出了雙視圖特征融合方法: 無須圖像配準,在模型卷積部分的中間層融合雙視圖特征,挖掘視圖間的語義聯(lián)系,從而提高模型性能.
1.2 注意力機制
近年來,注意力機制廣泛應用于計算機視覺領域的研究,其形式與人類的視覺注意力相似.人類視覺通過快速瀏覽圖像的全局信息,且關注圖像中的重要區(qū)域并忽略不相關的部分,從而獲取更多細節(jié)信息.
在醫(yī)學圖像分析領域,注意力機制的重要性更加直觀.醫(yī)學診斷的重點是觀察小的局部異常區(qū)域,而大部分正常圖像部分則不那么重要.特別地,注意力機制在DR 輔助診斷算法中有著大量的應用.Wang 等[6]提出了一種Zoom-in 網(wǎng)絡,可以同時進行DR 分級和生成病變區(qū)域的注意力圖,該網(wǎng)絡由3 個部分組成: 用于提取特征并輸出診斷結果的主干網(wǎng)絡、用圖像級別的監(jiān)督學習生成注意力圖的注意力網(wǎng)絡,以及模擬臨床醫(yī)師檢查時放大操作的檢查網(wǎng)絡.Lin 等[7]提出的基于抗噪聲檢測和基于注意力融合的框架,可以進行5 類DR 分級: 首先,利用CNN 提取特征,將特征輸入到中心樣本檢測器中以生成病變圖;然后,把病變圖和原始圖像送入所提出的注意力融合網(wǎng)絡.該網(wǎng)絡可以學習原始圖像和病變圖的權重,減少了無關信息的影響.Zhao 等[8]提出用具有注意力機制的雙線性注意力網(wǎng)絡進行DR 分級: 首先,將ResNet 中提取的特征輸入注意力網(wǎng)絡,可更加關注到?jīng)Q定分級的關鍵性區(qū)域;然后,采用雙線性策略訓練兩個注意力網(wǎng)絡,并進行更細粒度的分類.
自注意力機制在Tansformer[9]中被提出,是注意力機制的改進與優(yōu)化,并在自然語言處理領域迅速得以進展.2018 年,Wang 等[10]提出了一種新型Non-local 網(wǎng)絡,將自注意力機制首次引入計算機視覺領域,在視頻理解和目標檢測任務上取得了卓越的效果.最近,各種深度自注意力網(wǎng)絡(視覺Transformer)[11-13]的出現(xiàn),更展現(xiàn)了自注意力機制的巨大潛力.
值得注意的是,在以上方法中,注意力圖是從單視圖中推斷出來,不能應用于雙視圖眼底圖像的DR 分級場景中.而本文提出的跨視圖注意力機制是結合應用場景對自注意力機制的一種創(chuàng)新性改進,能夠使模型更適應下游任務.
2 算法介紹
2.1 模型架構
本文提出的基于雙視圖特征融合的DR 分級模型架構如圖2 所示,其由3 個主要部分組成: 特征提取部分、特征融合部分和特征分類部分.圖2 中,C 是concatenation 運算,S1,S2為輸出特征.

圖2 模型架構Fig.2 Model framework
(1)特征提取部分: 主干網(wǎng)絡從成對的眼底圖像中提取特征表示.在本文研究中,為節(jié)省計算資源,提取眼底圖像對的特征使用了共享的主干網(wǎng)絡,采用去除完全連接層的ResNets[14]作為主干網(wǎng)絡,并加載模型在ImageNet 上預先訓練好的參數(shù).
(2)特征融合部分: 首先,單視圖經(jīng)過自注意力模塊過濾掉單張圖像內(nèi)的無關信息,提取重要信息,同時跨視圖注意力則捕獲所提取的圖像對特征表示的像素之間的空間相關性;之后,將增強后的特征全局池化進行拼接.
(3)特征分類部分: 使用全連接層得到DR 分級結果.
給定眼底圖像對{I1,I2},I1和I2分別表示眼底圖像對視圖1 和視圖2 的圖像.I1和I2經(jīng)過主干網(wǎng)絡后,提取的特征分別為F1和F2,且I1,I2RH×W×3,F1,F2Rh×w×c,其中,H和W分別表示輸入圖像對的高度和寬度,h、w、c分別是被提取特征的高度、寬度和通道數(shù).F1和F2經(jīng)過多視圖特征融合模塊后的特征圖為S1和S2,特征通道數(shù)為c1; 經(jīng)過全局池化和拼接后的通道數(shù)為c2.
2.2 雙視圖特征融合
針對眼底病灶微小、普通的DR 分級模型準確度低等問題,本文將自注意力機制引入模型,以降低圖像的噪聲影響,同時增強病灶細節(jié)特征的學習;同時針對雙視圖眼底圖像對存在互補的關系,提出了一種跨視圖注意力模塊,挖掘雙視圖圖像對之間的語義聯(lián)系,以提高DR 分級的準確性.
2.2.1 自注意力模塊
圖3 展示了針對單視圖的自注意力(self-attention,SA)模塊細節(jié),其中,reshape 為重塑操作,用于改變數(shù)組形狀.給定視圖1 和視圖2 利用主干網(wǎng)絡提取的特征F1和F2,首先,將每個視圖的特征轉換為查詢(query,q)特征、鍵(key,k)特征和值(value,v)特征.F1和F2通過1 × 1 卷積變換后的查詢特征、鍵特征、值特征分別為F1q、F1k、F1v和F2q、F2k、F2v,其中,F1q,F1k,F2q,F2kRh×w×c′,F1v,F2vRh×w×c′′,c′和c′′代表特征的通道數(shù),且c′c′′.相應公式為

圖3 針對單視圖的自注意力模塊Fig.3 Self-attention module for single view fundus images
其中,linear 代表參數(shù)為θ的1 × 1 卷積.
然后,將F1q和F1k大小變換到 Rh×w×c′,并通過計算,再使用softmax 函數(shù)歸一化后得到視圖1 空間注意力圖F1_Att. 當用于多標簽分類問題時,使用sigmoid 函數(shù).同理可以得到F2_Att.相應公式為
將F1v大小變換到 Rh×w×c′′,將F1v和F1_Att做矩陣乘法,并將其大小變換到 Rh×w×c.
最后,把得到的F1_self乘上參數(shù)α并和原矩陣F1相加,得到經(jīng)過自注意力機制的最終結果.視圖2 同理.相應公式為
其中,α1和α2是可學習的參數(shù),初始化為0,并在訓練中不斷優(yōu)化.最終得到的和是空間注意力圖與原特征圖的加權融合.
經(jīng)過自注意力模塊后的視圖特征具有單視圖的全局上下文信息,并根據(jù)注意力有側重性地聚合上下文,增強了眼底病灶特征的學習.
2.2.2 跨視圖注意力模塊
受跨模態(tài)特征融合中的跨模態(tài)注意力機制的啟發(fā),本文提出了跨視圖注意力(cross-attention,CA)模塊.圖4 展示了針對雙視圖的跨視圖注意力模塊細節(jié).此模塊中,將視圖1 與視圖2 的特征分別變換為查詢(query)特征、鍵(key)特征和值(value)特征的步驟與自注意力模塊一致,不再贅述.

圖4 針對雙視圖的跨視圖注意力模塊Fig.4 Cross-attention module for dual-view fundus images
相互引導的雙向關系捕捉了眼底圖像對中每個位置之間的重要性.以F1→2為例,每一行表示視圖1 的一個像素點位置與視圖2 所有像素位置之間的關系權重,通過與視圖2 的特征F2v矩陣相乘,大小變換后得到由視圖1 引導的視圖2 加權信息F2_cross,該特征將更多地傾向于關注視圖2 中與視圖1 相關的特征信息.同理,可以得到由視圖2 引導的視圖1 加權信息F1_cross,該特征重點挖掘視圖1 中與視圖2 相關的特征關系.相應公式為
將視圖1 得到的注意力特征與跨視圖注意力特征進行拼接,拼接后的特征既有視圖1 內(nèi)部的重點信息,也融合了與視圖2 相關的特征信息.利用1 × 1 卷積層將連接的特征轉換為輸出特征S1.同理可得到S2.相應公式為
其中,S1,S2Rh×w×c1.
3 實驗結果與分析
3.1 實驗基礎設置
本文采用ResNet-18、ResNet-34、ResNet-50 和ResNet-101 作為主干網(wǎng)絡的特征提取器,參數(shù)從ImageNet 預訓練中初始化.為了適應不同采集相機造成的不同圖像分辨率,首先將所有眼底圖像的尺寸調(diào)整到(512 × 512)像素.為了進行訓練,從調(diào)整后的圖像中隨機裁剪(448 × 448)像素大小的塊,測試時使用中心裁剪.本文使用Pytorch[15]框架,采用SGD(stochastic gradient descent)隨機梯度優(yōu)化器,使用交叉熵損失函數(shù);采用poly 策略動態(tài)調(diào)整學習率,初始學習率設置為0.007,動量因子為0.9,迭代次數(shù)為50 次.
3.2 數(shù)據(jù)集介紹
在本文自建的雙視圖數(shù)據(jù)集DFiD 和公開的數(shù)據(jù)集DeepDR[16]上,采用五折交叉驗證法進行了實驗驗證.數(shù)據(jù)集DFiD 有3 212 對共6 424 張雙視圖眼底圖像;數(shù)據(jù)集DeepDR 包含了400 對共800 張雙視圖眼底圖像.數(shù)據(jù)集的分布如表1 所示,且采用DR 五級標注: DR-0 級表示無DR;DR-1 級表示輕度非增生型DR;DR-2 級表示中度非增生型DR;DR-3 級表示重度非增生型DR;DR-4 級表示增生型DR.
3.3 評價指標
采用二次加權kappa 系數(shù)、調(diào)和平均值(F1)和ROC(receiver operating characteristic)曲線下面積(area under curve,AUC)作為評價指標.二次加權 kappa 可以表示有序多分類問題中不同評估者的評估結果的一致性,它對分級的差異進行懲罰,懲罰幅度與預測值與真實值之間距離的平方相關.F1值是精確度和敏感度的調(diào)和平均值.相應公式為
式(14)—(16)中:P為精確度(precision),即PPV(positive predictive value),陽性預測值,表示真陽性樣本在所有預測陽性樣本中的比例;RTP真陽性率(true positive rate,TPR)又稱敏感度(sensitivity),表示正確識別的陽性比例;NTP表示真陽性(true positive,TP)樣本的數(shù)量;NFP表示假陽性(false positive,FP)樣本的數(shù)量;NFN表示假陰性(false negative,FN)樣本的數(shù)量.
3.4 不同主干網(wǎng)絡與融合策略的實驗對比
本文在自建的雙視圖眼底圖像數(shù)據(jù)集DFiD 上進行了對比實驗,分別對比了不同主干網(wǎng)絡和不同特征融合策略的結果,其中,用于對比的融合策略是全局特征融合方法.實驗結果如表2 所示.
由表2 的結果可知,使用更深的主干網(wǎng)絡作為特征提取器可以獲得更好的分類性能.同樣,在使用本文提出的特征融合方式的情況下,使用ResNet-101 為主干網(wǎng)絡與使用ResNet-18 的主干網(wǎng)絡的結果相比,二次加權kappa、F1、AUC 分別提高了4.9%、2.4%和2.6%.
在使用相同的主干網(wǎng)絡的情況下,本文提出的特征融合策略相比于全局特征融合方法,其結果都更優(yōu)越;在使用最優(yōu)的特征提取器ResNet101 的情況下,本文提出的融合策略比全局特征融合方法的二次加權kappa、F1、AUC 分別提高了6.1%、4.2%和3.0%.這證明了本文提出的雙視圖眼底圖像特征方法能夠顯著地提高分類準確性.
3.5 與公開方法的對比
本文選取兩種公開的與本文方法類似的雙視圖眼底圖像特征融合算法同本文方法進行了實驗對比,實驗結果如表3 所示.其中,AUBNet(attention-based unilateral and bilateral feature weighting and fusion network)[17]是一種基于注意力的單側和雙側特征加權和融合網(wǎng)絡,由特征提取模塊、特征融合模塊和分類模塊組成,利用特征提取模塊進行兩級特征加權和融合來獲得雙眼的特征表征,最后利用分類模塊進行多標簽分類;DCNet(dense correlation network)[18]由主干神經(jīng)網(wǎng)絡、空間相關模塊和分類器組成,空間相關模塊提取眼底圖像對特征之間的密集相關性,并融合相關的特征表示.
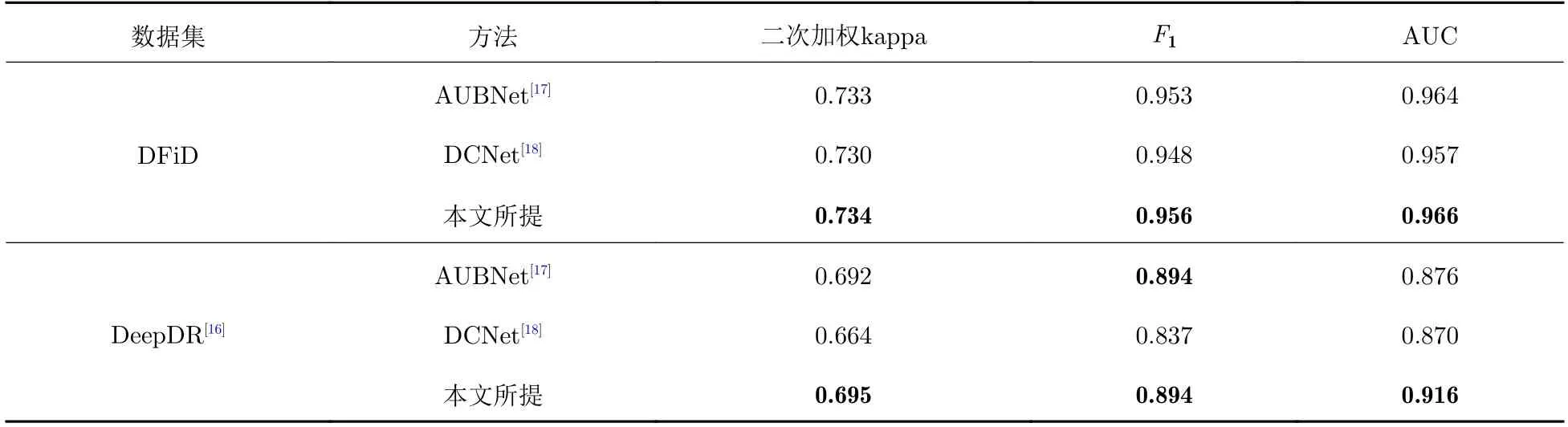
表3 與公開方法的對比Tab.3 Comparison results with public methods
由表3 的結果可以看到,在數(shù)據(jù)集DFiD 上,本文提出的方法各項指標都取得了最優(yōu)表現(xiàn);在數(shù)據(jù)集DeepDR 上,本文提出方法的二次加權kappa 和AUC 值都取得了最優(yōu)表現(xiàn),F1值達到了與AUBNet的F1值相等.由實驗結果可知,本文提出的方法是十分優(yōu)秀的,不僅在內(nèi)部數(shù)據(jù)集上有效,在完全公開的數(shù)據(jù)集上也表現(xiàn)優(yōu)異.這證明本文提出的雙視圖特征融合方法能夠有效地挖掘視圖之間的相關性.
3.6 消融實驗
為了驗證所設計的模塊對提高分類性能的有效性,本文在以ResNet-101 為主干網(wǎng)絡的情況下,分別加入自注意力(SA)模塊和跨視圖注意力(CA)模塊.用于對比的網(wǎng)絡結構包括ResNet-101 主干網(wǎng)絡(提取特征后直接拼接)、加入SA 模塊的網(wǎng)絡、加入CA 模塊的網(wǎng)絡,以及加入SA 模塊和CA 模塊的網(wǎng)絡.實驗結果如表4 所示.

表4 數(shù)據(jù)集DFiD 上的消融實驗結果Tab.4 Ablation results on DFiD dataset
表4 的實驗結果表明,SA 模塊和CA 模塊都能有效地提高DR 分級準確性.自注意力能夠關注到單視圖中關鍵病灶部位,而跨視圖注意力能夠通過雙視圖的關聯(lián)更加可靠且全面地挖掘病灶特征.
此外,本文可視化了測試數(shù)據(jù)集DFiD 中的樣例,結果如圖5 所示.圖5 是使用Grad-CAM(gradient-weighted class activation mapping)[19]得到的可視化結果.此樣例的真實結果為DR-2 級.從圖5(a)和圖5(b)所示的原始圖像對來看,圖5(a)所示的圖像1 圖像清晰,可以明顯看到眼底病灶;而圖5(b)所示的圖像2 圖像質量較差,幾乎看不清細節(jié).在實際應用中也常會出現(xiàn)這種情況,即如果雙視圖中有一方圖像質量較差,對最終的分類結果并沒有幫助,甚至會引入噪聲.圖5(c)顯示了模型不能準確地關注到圖像顯著區(qū)域,特征響應范圍過大.圖5(d)加入SA 模塊和CA 模塊后能夠消除背景以及噪聲信息的干擾,進一步細化了注意力區(qū)域,準確定位到了病灶區(qū)域.實驗結果和可視化結果都證明了本文提出的特征融合方法的有效性.

圖5 可視化結果Fig.5 Visualization results
4 總結
本文提出了一種基于雙視圖特征融合的DR 分級算法,并在自建的數(shù)據(jù)集DFiD 和公開的數(shù)據(jù)集DeepDR上進行了實驗.本文算法主要包括特征提取、特征融合與特征分類,其中特征融合部分,引入了自注意力機制挖掘單視圖病灶區(qū)域的上下文信息,并設計了融合雙視圖特征的跨視圖注意力模塊.實驗結果表明,本文所提出的各模塊可有效地提高DR 的分類性能.最后采用 Grad-CAM 方法對本文模型進行了可視化解釋,為模型推理提供了可見的預測依據(jù).
在后續(xù)研究工作中可部署模型到移動端和PC 端,搭建眼底圖像檢測系統(tǒng),讓用戶在完成眼底照相后,能快速地得到初步篩查的結論,以緩解基層醫(yī)院缺乏眼科醫(yī)師的難題.
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數(shù)理化(高中版.高考數(shù)學)(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
