基于多核支持向量機(jī)的句子分類算法
2023-11-29 04:20:50肖開研
肖開研,廉 潔
(上海師范大學(xué) 信息與機(jī)電工程學(xué)院,上海 201418)
0 引 言
句子分類是一種對評(píng)價(jià)、意見、情感等各種文本進(jìn)行分類的任務(wù),是當(dāng)下自然語言處理領(lǐng)域熱門的研究方向之一.句子分類算法在情感分析、信息過濾、智能聊天等方面[1-2]有著廣泛的應(yīng)用,對輿情了解、政策制定、企業(yè)營銷決策等都起著重要的作用.
目前,句子分類算法主要包括基于深度學(xué)習(xí)的分類算法和傳統(tǒng)分類算法.基于深度學(xué)習(xí)的分類算法包括卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural networks,CNN)[3]、長短期記憶網(wǎng)絡(luò)(long short-term memory,LSTM)[4]和BERT(bidirectional encoder representations from transformer)模型[5]等.其中,基于CNN 的句子分類算法在實(shí)驗(yàn)中取得了優(yōu)異表現(xiàn),但是,即使是簡單的CNN 也要求在訓(xùn)練前精確設(shè)計(jì)網(wǎng)絡(luò)的結(jié)構(gòu),并設(shè)置相應(yīng)的超參數(shù),導(dǎo)致該算法對實(shí)踐者要求較高[3];LSTM 的門控機(jī)制可處理長期依賴、梯度消失等問題,但是由于缺乏對文本的并行處理能力導(dǎo)致訓(xùn)練耗時(shí)過長[4];BERT 模型采用Transformer 作為編碼器[6],擁有對文本的強(qiáng)大編碼能力,卻因參數(shù)量過大無法在普通設(shè)備上訓(xùn)練、加載[7].可見,深度學(xué)習(xí)模型不僅對硬件要求較高,且其存在著參數(shù)量大、容易過擬合等問題.
傳統(tǒng)分類算法包括樸素貝葉斯分類器(naive Bayes classifier)[8]和支持向量機(jī)(support vector machine,SVM)[9]等.早期的分類算法通過詞袋(bag of words,BOW)模型[10]、TF-IDF(term frequency–inverse document frequency)[11]模型構(gòu)造基于詞頻的文本特征,忽略了文本間的結(jié)構(gòu)關(guān)聯(lián),導(dǎo)致分類效果不佳[12].但隨著Word2Vec[13]、GloVe(global vectors for word representation)[14]、FastText[15]等詞向量模型的提出,使詞向量的表達(dá)包含了上下文信息,有效解決了早期詞向量存在的維度高、稀疏且缺少關(guān)聯(lián)等問題.BERT 模型生成的詞向量表示不僅包含上下文信息,并且能有效提取單詞在特定語境下的含義.利用這些詞向量表示,對文本中的單詞進(jìn)行簡單的加權(quán)求和,可以輕松得到文本的向量表示,傳統(tǒng)的支持向量機(jī)算法可以在這些文本表示上進(jìn)行訓(xùn)練.支持向量機(jī)在全局上將句子分類問題轉(zhuǎn)化為二次規(guī)劃問題,不用大量的標(biāo)記樣本就能訓(xùn)練出分類性能較好的模型,因此,結(jié)合詞向量和支持向量機(jī)對文本進(jìn)行分類不僅可以利用到詞向量語義信息豐富和SVM 易訓(xùn)練的優(yōu)點(diǎn),而且能有效避免深度學(xué)習(xí)算法中存在的結(jié)構(gòu)復(fù)雜、參數(shù)量大、容易過擬合等問題.然而目前基于支持向量機(jī)的句子分類算法只利用了單一的詞向量模型,即用單一核函數(shù)映射、提取文本的向量特征表示,因此存在對文本信息提取不全面、映射能力差的問題[16].
如今,多核學(xué)習(xí)(multi-kernel learning,MKL)在多個(gè)領(lǐng)域都得到了成功的推廣,各種理論和應(yīng)用也證明了多核學(xué)習(xí)相較于單核學(xué)習(xí)的優(yōu)越性能[17].為了探析多核學(xué)習(xí)在句子分類中的應(yīng)用效果,本文采用4 種主流的詞向量表示模型: Word2Vec、GloVe、FastText 和BERT,將多核支持向量機(jī)應(yīng)用于句子分類,并設(shè)計(jì)了新的核函數(shù)系數(shù)尋優(yōu)方法,以更加準(zhǔn)確地提取文本特征,從而提升句子分類的準(zhǔn)確率.
1 相關(guān)工作
1.1 詞向量表示模型
1.1.1 Word2Vec 模型
Word2Vec[13,18]是一種使用神經(jīng)網(wǎng)絡(luò)概率語言模型來訓(xùn)練詞向量的方法,其包含通過上下文預(yù)測目標(biāo)單詞的CBOW(continues bag of words)模型和通過目標(biāo)單詞預(yù)測上下文的Skip-gram 模型.Word2Vec 采用了層次softmax(hierarchical softmax)和負(fù)采樣(negative sampling)等優(yōu)化技巧,將單詞轉(zhuǎn)化為詞向量,同時(shí)所得詞向量在空間的余弦距離的大小代表了單詞之間語義和語法關(guān)系的相似度.
1.1.2 GloVe 模型
GloVe[14]是基于全局詞頻統(tǒng)計(jì)的詞向量模型.GloVe 模型先計(jì)算詞共現(xiàn)矩陣,再利用詞向量與詞共現(xiàn)矩陣之間的近似關(guān)系構(gòu)建損失函數(shù),最后通過學(xué)習(xí)得到較低維度的詞向量表示.GloVe 模型中詞與詞之間的相似性也可以通過詞向量間的距離大小來衡量,而且相較于Word2Vec,GloVe 模型包含了文本的全局信息,對多義詞的處理能力更強(qiáng).
1.1.3 FastText 模型
FastText[15]是將整個(gè)文本作為特征輸入來預(yù)測文本類別的模型.其中FastText 通過n-grams 方法字符級(jí)別地表示一個(gè)單詞,這樣不僅對低頻詞生成的詞向量效果更好,而且對于語料庫之外的單詞可以通過疊加字符向量來構(gòu)建相對應(yīng)的詞向量.
1.1.4 BERT 模型
BERT[5]通過雙向Transformer 編碼器構(gòu)造基于上下文的詞向量.與Word2Vec 不同的是,BERT根據(jù)上下文變化,動(dòng)態(tài)地生成詞向量,即重復(fù)單詞會(huì)因上下文不同而產(chǎn)生不同的詞向量,這讓BERT 可以捕捉單詞在特定語境中的含義,使其在自然語言處理任務(wù)中表現(xiàn)優(yōu)異.
1.2 支持向量機(jī)
文獻(xiàn)[9]基于統(tǒng)計(jì)學(xué)習(xí)理論首次提出了支持向量機(jī)(SVM)算法.SVM 算法基于VC 維(vapnikchervonenkis dimension)理論和結(jié)構(gòu)風(fēng)險(xiǎn)最小原理,通過構(gòu)造最大超平面對樣本進(jìn)行分類.早期,線性SVM 難以對線性不可分樣本進(jìn)行分類[19].后來,核函數(shù)的使用將線性SVM 推廣至非線性SVM,使SVM 的適用范圍和分類準(zhǔn)確性均得到明顯提升.相對于線性SVM 而言,非線性SVM 通過核函數(shù)將低維特征空間里的線性不可分樣本,映射到更高維甚至無限維的特征空間中,并在高維空間中計(jì)算最大超平面對樣本進(jìn)行分類.
近期,很多基于SVM 的不同變體被提出,例如,Sun 等[20]提出的基于Fenchel-Legendre 共軛變換的稀疏半監(jiān)督學(xué)習(xí)框架,為稀疏多視圖SVM 提供了有效的訓(xùn)練方法;Ji 等[21]提出了一種基于正則化函數(shù)最小化的多任務(wù)多類別SVM,讓多任務(wù)多類別學(xué)習(xí)能有效提取不同類別、不同任務(wù)間的內(nèi)在聯(lián)系;Sun 等[22]利用多視圖正則化項(xiàng)對廣義特征值最接近SVM 進(jìn)行優(yōu)化,將復(fù)雜的優(yōu)化問題轉(zhuǎn)化為廣義特征值問題.此外,有關(guān)切線空間本征流行正則化技術(shù)的引入[23],包含局部主成分分析所得的局部切空間表示和使相鄰切線空間相關(guān)的聯(lián)系,讓SVM 可以有效考慮切空間本征流行正則化,以解決半監(jiān)督學(xué)習(xí)問題.
1.3 多核支持向量機(jī)
核函數(shù)的出現(xiàn)讓許多問題可由線性推廣至非線性情況[22,24],同時(shí),基于單核學(xué)習(xí)的SVM 已經(jīng)在許多領(lǐng)域得到成功應(yīng)用.但是當(dāng)樣本數(shù)量龐大[25]、樣本數(shù)據(jù)在高維特征空間非平坦分布[26]或樣本特征所含信息具有異構(gòu)性時(shí)[27],采用單核方法對所有樣本以相同的方式進(jìn)行映射的效果并不理想.針對單核學(xué)習(xí)的不足,眾多研究[25-27]聚焦于多核學(xué)習(xí),以此來提高決策函數(shù)的可解釋性,獲得更優(yōu)的分類效果.多核學(xué)習(xí)主要分為核融合、多尺度核、無限核等方法.本文聚焦于核融合方法,主要思想是將不同特性的核函數(shù)進(jìn)行組合來獲得更優(yōu)的映射性能.然而在實(shí)現(xiàn)多核融合時(shí),每個(gè)核函數(shù)系數(shù)的設(shè)置直接影響最后的融合效果.因此核系數(shù)的尋優(yōu)方法至關(guān)重要,當(dāng)系數(shù)數(shù)量較少時(shí)常用網(wǎng)格搜索(grid search,GS)[28]、隨機(jī)搜索(randomized search,RS)[29]等方法.通常,核系數(shù)的可行域?yàn)閇0,1]且求和為1.GS 在可行域中設(shè)置一定步長進(jìn)行網(wǎng)格搜索,步長較短會(huì)導(dǎo)致訓(xùn)練非常耗時(shí),步長較長則會(huì)導(dǎo)致核融合效果差.RS 在可行域中隨機(jī)采樣,該方法的效果和GS 類似,需要設(shè)置較大的采樣次數(shù)才能獲得較好的模型效果.針對這些問題,本文提出的基于參數(shù)空間分割與廣度優(yōu)先搜索的系數(shù)尋優(yōu)方法,在訓(xùn)練次數(shù)較少的情況下也能獲得較好的分類效果.
2 模型構(gòu)建
本文基于多核SVM,提出了新的系數(shù)尋優(yōu)方法實(shí)現(xiàn)多核融合,將融合所得的混合核嵌入傳統(tǒng)SVM,從而實(shí)現(xiàn)句子分類.
2.1 模型框
基于多核SVM 的句子分類算法框架如圖1 所示.該算法主要分為兩個(gè)階段: 訓(xùn)練階段和測試階段.在訓(xùn)練階段,首先對輸入文本進(jìn)行文本預(yù)處理,包括分詞、去除停用詞、提取詞干、還原詞形、轉(zhuǎn)化為小寫;隨后,分別選用Word2Vec、GloVe、FastText 以及BERT 詞向量表示模型,將訓(xùn)練集文本中的單詞表示為詞向量,并將句子中所有單詞的詞向量相加后求均值,作為句子的向量表示;之后將句子向量利用核函數(shù)進(jìn)行映射,從而得到核矩陣,再按照尋優(yōu)所得的核函數(shù)系數(shù),將這4 種詞向量表示模型所得的核矩陣線性組合,從而得到混合核,實(shí)現(xiàn)訓(xùn)練集文本的多核學(xué)習(xí);最后,采用支持向量機(jī)方法訓(xùn)練出分類器.在測試階段,對測試集文本同樣進(jìn)行文本預(yù)處理、特征提取、核融合后,導(dǎo)入訓(xùn)練所得的SVM 分類器,從而實(shí)現(xiàn)句子分類.

圖1 模型框架Fig.1 Model framework
2.2 多核支持向量機(jī)
假設(shè)某一數(shù)據(jù)集中含有n個(gè)樣本,每個(gè)樣本有M種詞向量表示,表示第i個(gè)樣本的第m個(gè)詞向量表示,其樣本的類標(biāo)簽為yi {1,-1}.多核SVM 主要解決了優(yōu)化問題
式(1)中:W()m、φ()m、βm分別表示第m個(gè)詞向量表示的超平面法向量、核函數(shù)和核函數(shù)系數(shù);ξi、C分別表示第i個(gè)樣本的損失值和懲罰因子.與傳統(tǒng)SVM 的思想一致,可將多核SVM 優(yōu)化問題轉(zhuǎn)化為對偶形式
約束條件
在實(shí)驗(yàn)中,本文利用Word2Vec、GloVe、FastText 以及BERT 這4 種詞向量表示模型來計(jì)算4 種核函數(shù),然后進(jìn)行核融合,具體細(xì)節(jié)詳見圖2.由圖2 所示的熱力圖及其圖例可知,不同詞向量表示模型所提取的特征不同(熱力圖中顏色越藍(lán)的點(diǎn)代表該點(diǎn)數(shù)值越接近–0.20,顏色越紅的點(diǎn)代表該點(diǎn)數(shù)值越接近0.20).
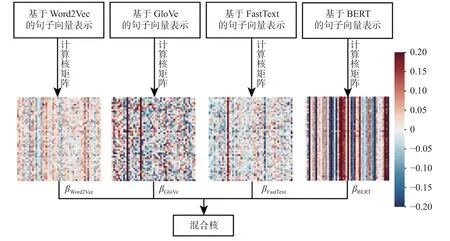
圖2 多核融合過程Fig.2 Illustration of multi-kernel fusing
2.3 核函數(shù)系數(shù)尋優(yōu)方法
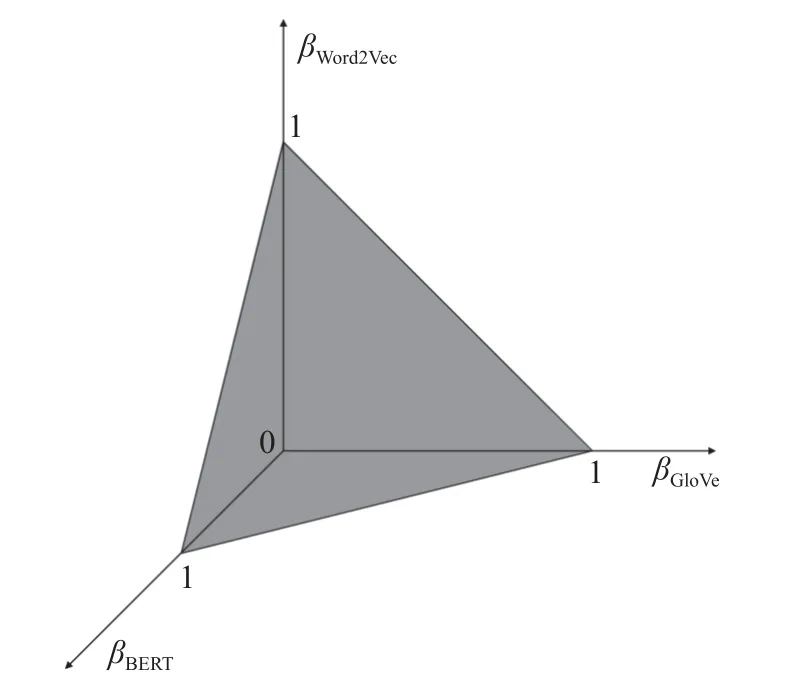
圖3 參數(shù)空間Fig.3 Parameter space
在目標(biāo)函數(shù)不可導(dǎo)的情況下,假設(shè)目標(biāo)函數(shù)存在多個(gè)局部最優(yōu)解,且當(dāng)βWord2Vec、βGloVe與βBERT變化無限小時(shí),目標(biāo)函數(shù)連續(xù).本文提出的系數(shù)尋優(yōu)方法具體步驟如下.
步驟一: 參數(shù)空間為三棱錐體,不斷連接參數(shù)空間中的最長邊中點(diǎn)與其不相鄰的2 個(gè)頂點(diǎn)將參數(shù)空間分割為 2s個(gè)三棱錐體區(qū)域.
步驟二:(βWord2Vec,βGloVe,βBERT)依次取值為每個(gè)區(qū)域的重心坐標(biāo)值并進(jìn)行 2s次訓(xùn)練.
步驟三: 對步驟二所得的 2s個(gè)訓(xùn)練結(jié)果進(jìn)行排序,選擇分類效果最優(yōu)的h個(gè)區(qū)域作為新的參數(shù)空間.
步驟四: 重復(fù)步驟一、步驟二、步驟三,達(dá)到預(yù)設(shè)的參數(shù)空間分割次數(shù),不斷逼近βWord2Vec、βGloVe和βBERT的局部最優(yōu)值.
以上步驟中涉及的s為預(yù)設(shè)的分割次數(shù),其分割方式如圖4 所示,其中深色區(qū)域?yàn)橄乱惠嗊M(jìn)行分割的區(qū)域.該分割方式通過參數(shù)空間的分割,快速逼近目標(biāo)函數(shù)的多個(gè)局部最優(yōu)解,最終選取驗(yàn)證集上訓(xùn)練效果最佳的局部最優(yōu)解作為核函數(shù)系數(shù).
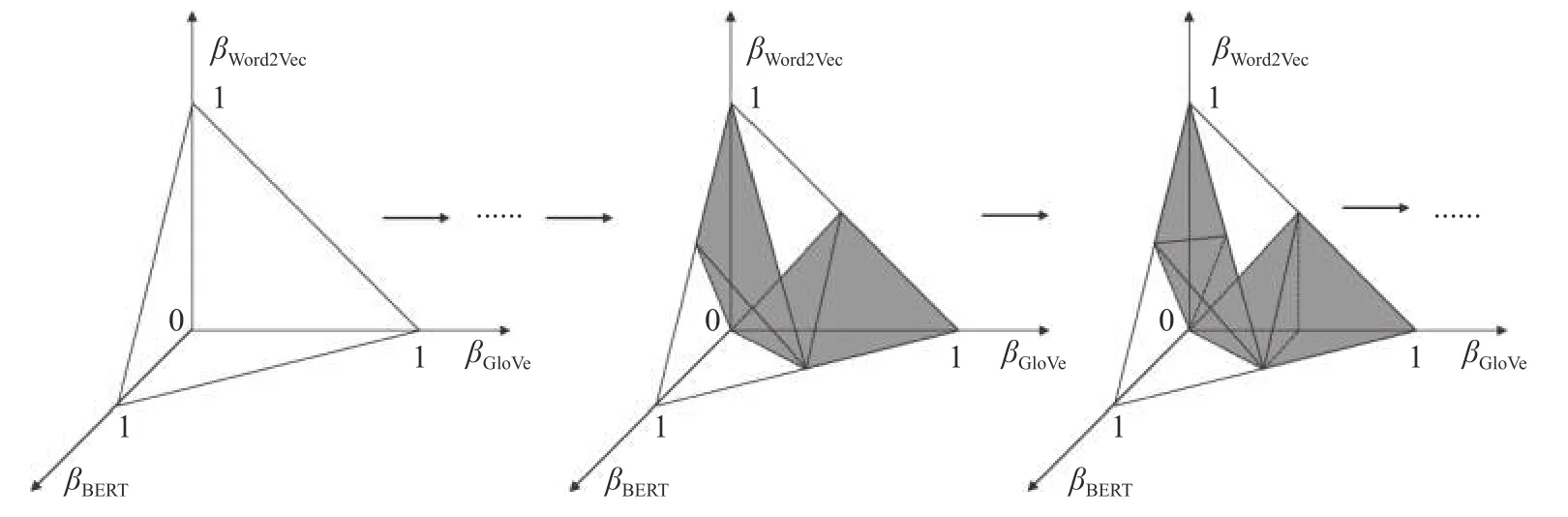
圖4 參數(shù)空間分割Fig.4 Parameter space segmentation
3 對比實(shí)驗(yàn)
3.1 實(shí)驗(yàn)數(shù)據(jù)
為了檢驗(yàn)本文所提出模型的分類性能,采用以下數(shù)據(jù)集進(jìn)行實(shí)驗(yàn).
● SST(Stanford sentiment treebank)-1 數(shù)據(jù)集: 斯坦福大學(xué)情感分類語料庫數(shù)據(jù)集,包含 very positive、positive、neutral、negative 和very negative 這5 個(gè)類別標(biāo)簽.①http://nlp.stanford.edu/sentiment/
● SST-2: 在SST-1 基礎(chǔ)上僅保留了positive 和negative 這2 個(gè)類別標(biāo)簽.
● Subj(subjectivity): 主觀性數(shù)據(jù)集,包含subjective 和objective 這2 個(gè)類別標(biāo)簽.②https://www.cs.cornell.edu/people/pabo/movie-review-data/
● TREC(text retrieval conference): 問題數(shù)據(jù)集,包含abbreviation、entity、description、human、location 和numeric 這6 個(gè)類別標(biāo)簽.③http://cogcomp.cs.illinois.edu/Data/QA/QC/
● CR(customer review): 顧客產(chǎn)品評(píng)價(jià)數(shù)據(jù)集,包含positive和negative 這2 個(gè)類別標(biāo)簽.④https://huggingface.co/datasets/SetFit/CR
● MPQA(multi-perspective question answering): MPQA 意見極性檢測子任務(wù)數(shù)據(jù)集,包含2 個(gè)類別標(biāo)簽.⑤https://www.mpqa.cs.pitt.edu/
● CT(coronavirus tweets): Covid-19 情感分類數(shù)據(jù)集,包含positive、neutral 和negative 這3 個(gè)類別標(biāo)簽.⑥https://www.kaggle.com/datasets/datatattle/covid-19-nlp-text-classification
數(shù)據(jù)集詳細(xì)信息匯總于表1,其中,詞庫大小是指數(shù)據(jù)集中共有多少個(gè)不同的單詞,平均句長是指數(shù)據(jù)集中每個(gè)句子平均單詞個(gè)數(shù).數(shù)據(jù)集中部分?jǐn)?shù)據(jù)集已預(yù)劃分訓(xùn)練集、驗(yàn)證集、測試集,對于未預(yù)劃分的數(shù)據(jù)集采用十折交叉驗(yàn)證(cross-validation,CV),按照0.8∶0.1∶0.1 的比例隨機(jī)劃分訓(xùn)練集、驗(yàn)證集、測試集.
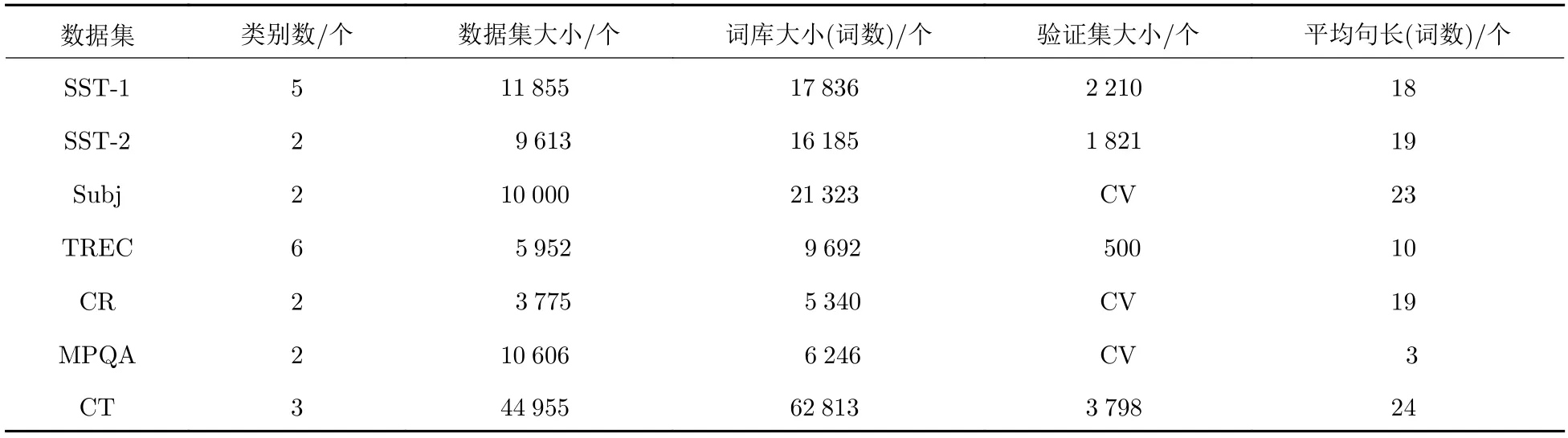
表1 標(biāo)記數(shù)據(jù)集統(tǒng)計(jì)匯總Tab.1 Summary statistics of the datasets after tokenization
3.2 超參數(shù)設(shè)置
實(shí)驗(yàn)使用預(yù)訓(xùn)練的谷歌Word2Vec 詞向量文件、斯坦福GloVe 詞向量文件、臉書FastText 詞向量文件(此3 種詞向量維度為300),以及BERT 的詞向量(其維度為768)對文本進(jìn)行映射.若文本中存在不屬于Word2Vec、GloVe、FastText 詞向量文件中的單詞,則采用隨機(jī)函數(shù)生成300 個(gè)處于[–0.25,0.25]的隨機(jī)數(shù)組成其詞向量.實(shí)驗(yàn)選用高斯核函數(shù)
其中,高斯核函數(shù)的參數(shù)γ和SVM 的懲罰因子C的尋優(yōu)空間分別為[1,0.1,0.01,0.001]、[0.1,1,10,100,1 000].GS 設(shè)置步長為 0 .1,在系數(shù)尋優(yōu)空間中總共可以采樣 84 個(gè)樣本點(diǎn).為了公平比較GS 和RS,RS 方法在系數(shù)尋優(yōu)空間中同樣隨機(jī)采樣 84 個(gè)樣本點(diǎn).在本文提出的尋優(yōu)系數(shù)方法中,將樣本空間分割為 32 個(gè)區(qū)域,選取訓(xùn)練效果最好的兩個(gè)區(qū)域進(jìn)行二次分割;二次分割中每塊區(qū)域分割為16塊區(qū)域,共選取 64 個(gè)樣本點(diǎn)進(jìn)行 64 次訓(xùn)練.
3.3 實(shí)驗(yàn)結(jié)果
本文共選取了6 種文本表示模型進(jìn)行對比實(shí)驗(yàn),包括經(jīng)典的BOW、TF-IDF 算法,以及基于Word2Vec、GloVe、FastText 和BERT 的詞向量的文本表示算法,并對比了3 種核函數(shù)系數(shù)尋優(yōu)方法.實(shí)驗(yàn)使用準(zhǔn)確率作為分類器的分類性能評(píng)估指標(biāo),結(jié)果如表2 所示,其中,MKL 表示通過Word2Vec、GloVe、FastText 和BERT 進(jìn)行多核學(xué)習(xí).表2 中數(shù)據(jù)為10 次實(shí)驗(yàn)結(jié)果的均值.
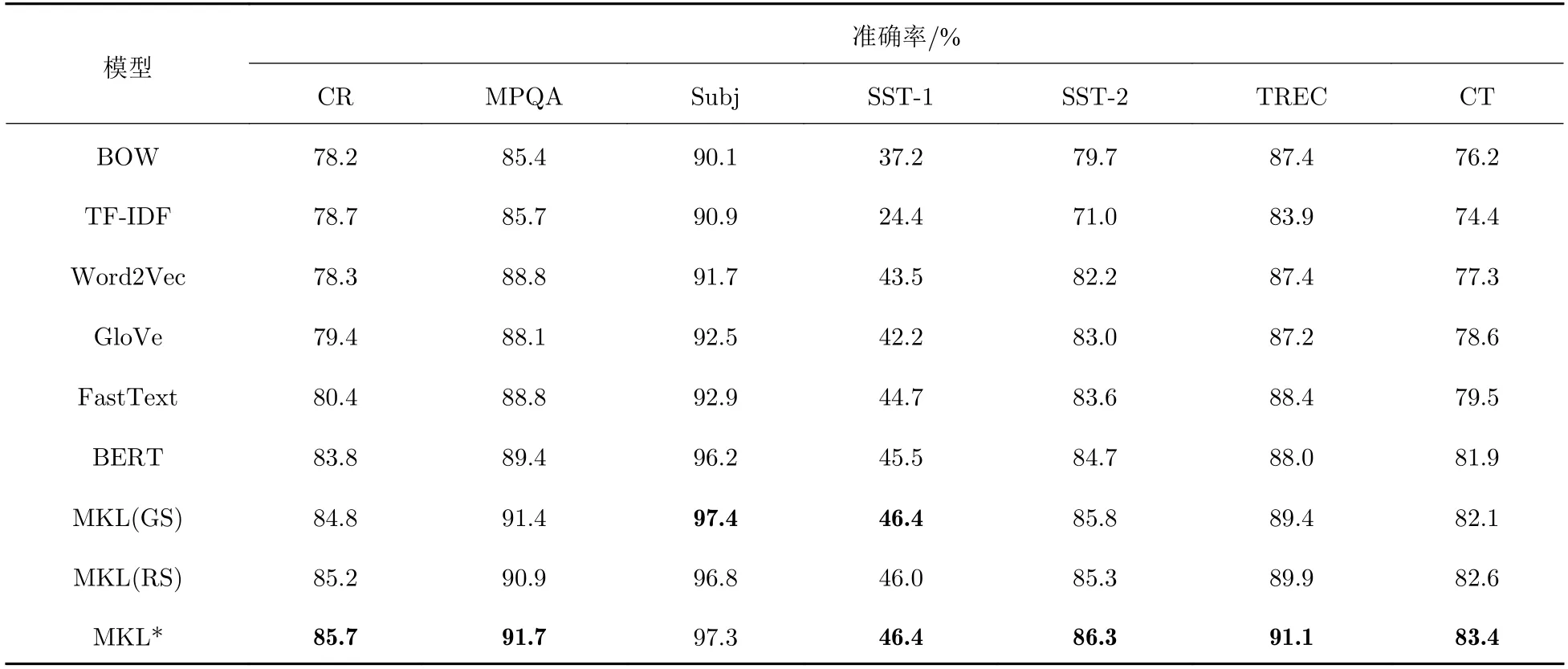
表2 模型分類準(zhǔn)確率對比結(jié)果Tab.2 Comparison of model classification accuracies
實(shí)驗(yàn)結(jié)果表明,多核學(xué)習(xí)相較于早期詞向量模型BOW、TF-IDF 提升幅度明顯,在數(shù)據(jù)集SST-1、CR 上分別提升了9.2%、7%.在所有數(shù)據(jù)集中,基于多核支持向量機(jī)模型的分類準(zhǔn)確率,相較于單核學(xué)習(xí)中的最好結(jié)果都有一定提升,其中在數(shù)據(jù)集TREC 上準(zhǔn)確率提升了2.7%,提升幅度最大.尋優(yōu)方法中,GS 和RS 訓(xùn)練效果相近,RS 在參數(shù)空間隨機(jī)采樣,返回的參數(shù)相比于GS 精度更高;但在訓(xùn)練次數(shù)少的情況下,隨機(jī)采樣導(dǎo)致了訓(xùn)練結(jié)果波動(dòng)較大,而本文提出的方法通過空間分割的方式不斷逼近核系數(shù)局部最優(yōu)值,即使訓(xùn)練次數(shù)少于GS 和RS,也取得了更好且更穩(wěn)定的分類結(jié)果.單核學(xué)習(xí)和多核學(xué)習(xí)在數(shù)據(jù)集SST-2 上的ROC(receiver operating characteristic)曲線如圖5 所示,其中,縱軸是真陽性率(true positive rate,TPR),橫軸是假陽性率(false positive rate,FPR).從其圖像和AUC值(ROC 曲線下面積,area under the curve,AUC)可以看出多核學(xué)習(xí)模型的分類能力更強(qiáng).
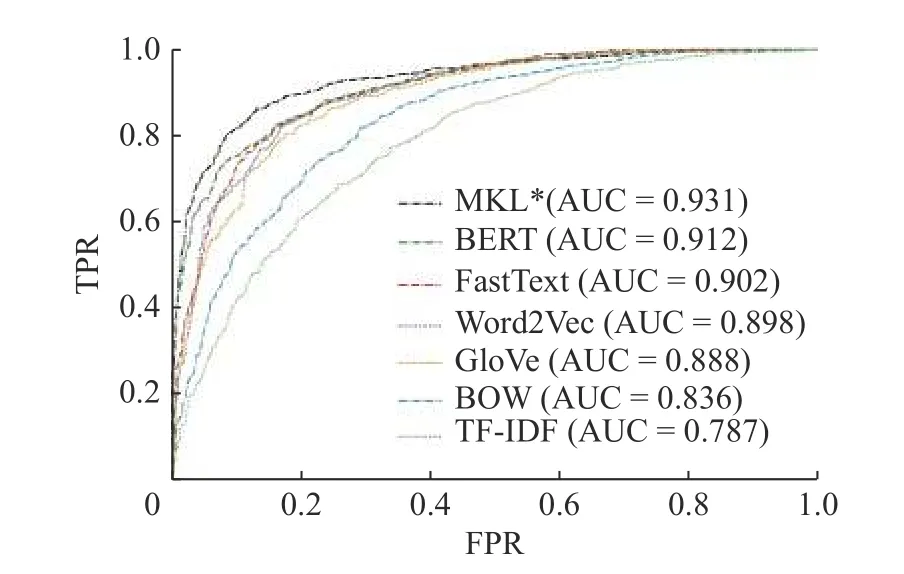
圖5 SST-2 數(shù)據(jù)集上MKL*與單核學(xué)習(xí)的ROC 曲線Fig.5 ROC curve of MKL* and single-kernel learning on SST-2 dataset
此外,當(dāng)γ和C的尋優(yōu)范圍分別為[1,0.1,0.01,0.001]、[0.1,1,10,100,1000]時(shí),3 種核系數(shù)尋優(yōu)方法訓(xùn)練次數(shù)和訓(xùn)練耗時(shí)如表3 所示.從表3 中可以看出,參數(shù)空間分割的尋優(yōu)方法得益于訓(xùn)練次數(shù)少,從而使訓(xùn)練耗時(shí)大幅度降低.

表3 參數(shù)尋優(yōu)方法訓(xùn)練耗時(shí)對比Tab.3 Comparison of training times for parameter optimization methods
4 結(jié)束語
在句子分類任務(wù)中,過去的研究側(cè)重于單核學(xué)習(xí),主要是改進(jìn)句子分類算法中的詞向量表示模型,這類方法往往被其運(yùn)用的詞向量表示模型的缺陷所約束.本文首次將多核學(xué)習(xí)運(yùn)用到句子分類任務(wù)中,多核學(xué)習(xí)的思想融合了不同詞向量表示模型的優(yōu)點(diǎn),讓句子分類結(jié)果更加精確.此外,針對傳統(tǒng)系數(shù)尋優(yōu)方法的不足,本文提出了一種基于參數(shù)空間分割的系數(shù)尋優(yōu)方法.在系數(shù)尋優(yōu)過程中,該方法有效減少了訓(xùn)練次數(shù)和訓(xùn)練結(jié)果的隨機(jī)性,并獲得了更優(yōu)的分類準(zhǔn)確率.
目前,本文實(shí)驗(yàn)采用了4 種詞向量表示模型進(jìn)行多核學(xué)習(xí),導(dǎo)致多核學(xué)習(xí)的潛力沒有完全開發(fā).當(dāng)今還有許多優(yōu)秀的文本表示模型,如ALBERT(a lite BERT)、ELMo(embeddings from language models)、GPT2(generative pre-trained transformer 2)和GPT3 模型等,都可以獲得文本的向量表示.考慮到本文所提出的系數(shù)尋優(yōu)方法能自然地?cái)U(kuò)展至高維空間中,因此,下一步工作將采用更多的模型進(jìn)行多核學(xué)習(xí),進(jìn)一步提升句子分類準(zhǔn)確率.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
