基于知識圖譜的問答系統設計
2023-11-30 22:03:40秦麗娟
無線互聯科技 2023年18期
基金項目:2019年度江蘇省高校哲學社會科學研究專題項目;項目編號:2019SJB154。
作者簡介:秦麗娟(1983— ),女,江蘇南京人,講師,碩士;研究方向:教育信息化。
摘要:隨著網絡數據的爆發式增長,知識泛濫和知識過載問題日益凸顯。傳統的問答系統通常采用簡單的關鍵詞匹配模式,往往無法準確理解用戶的真實意圖,難以提供準確的答案。為解決這一問題,文章設計了一種基于知識圖譜的智能問答系統。首先,通過本體層構建、數據爬取、數據存儲等步驟構建知識圖譜。其次,分別采用BERT+BiLSTM+CR模型和BERT+TextCNN模型進行命名實體識別和用戶意圖識別。最后,使用Flask封裝后臺API,以便提供更加靈活和個性化的服務。
關鍵詞:知識圖譜;問答系統;用戶意圖
中圖分類號:TP391.3? 文獻標志碼:A
0? 引言
Web3.0時代充斥著巨量信息,導致知識泛濫和知識過載等問題[1]。傳統的問答系統通常采取簡單的關鍵詞匹配模式,然后羅列一大堆數據供用戶查看,用戶往往很難辨別這些數據的準確性[2]。近年來,知識圖譜的理論研究取得了迅猛的發展,特別是在知識圖譜中的信息抽取環節方面,為構建問答系統的初期特征抽取任務提供了極大的幫助[3]。這種方法不僅顯著減少了人工干預的需求,還提高了問答系統的準確率和效率。OpenAI的ChatGPT引起了人工智能界的廣泛關注,給問答系統和搜索引擎帶來了一種全新的形態,即基于深度學習的形態。與傳統方法相比,這些方法通過深度學習技術來提高問答系統的準確性、召回率和效率,并能從復雜的知識結構中高度概括和挖掘所需信息,使得問答平臺能更有效地獲取知識,為各個領域的發展提供服務。本文旨在探討如何利用Web3.0時代豐富的數據資源和現代人工智能技術,構建一種基于知識圖譜的智能問答系統模型。
1? 相關技術
1.1? BERT模型
BERT(Bidirectional Encoder Representations from Transformers)模型是由Google于2018年提出的。它的主要目的是利用大量的未標注數據來學習一種通用的語言表示方法。與其他的基于深度學習的自然語言處理技術相比,BERT具有許多優點。首先,它可以適應各種類型的任務,因為它的訓練方法可以學習到語言的各種特征,從而在不同的應用場景中都可以得到良好的效果。其次,BERT也易于微調,這使得它在面對特定任務時可以快速適應并進行優化。此外,BERT可以充分利用大規模的未標注數據,讓模型學習到更多的語言特征,并在后續的微調過程中更好地適應任務。因此,BERT在自然語言處理領域受到了廣泛的關注,被認為是最強的預訓練語言模型之一。
1.2? DBNet網絡
DBNet在圖像分割任務中具有較高的準確性和魯棒性,被廣泛應用于計算機視覺領域。系統使用DBNet網絡進行文本檢測任務。DBNet網絡結構主要由3個模塊構成,分別是FPN、FCN和DB操作。FPN結構為了獲取多尺度的特征,分為自底向上的卷積操作與自頂向下的上采樣。首先,根據卷積公式獲取原圖大小比例的1/2、1/4、1/8、1/16、1/32的特征圖;其次,自頂向下采樣2次,之后同樣進行自底向上的操作;最后,對每層輸出結果進行采樣,變成1/4大小的特征圖。FCN模塊是將特征圖經過卷積核轉置卷積獲取概率圖P和閾值圖T、Z最后對2張圖進行DB(可微二值化)方法得到二值圖。
1.3? 長短時記憶網絡
LSTM(Long Short-Term Memory)是一種特殊的循環神經網絡,由Hochreiter等人提出。它將記憶單元添加到隱藏層的神經單元中,由此來控制時間序列中的記憶信息。LSTM是循環神經網絡(Recurrent Neural Networks,RNN)的一個變種。RNN的內部狀態可以表現動態時序行為,也稱為記憶信息。與RNN不同,LSTM改變了RNN的記憶單元,使其包括了一個“處理器”cell,它可以決定要保留哪些信息。一個cell由輸入門、遺忘門和輸出門組成。信息在進入LSTM網絡后,cell會根據規則判斷該信息是否有用,只有符合算法要求的信息才會被保留,而不符合要求的信息將通過遺忘門被丟棄。
2? 總體設計方案
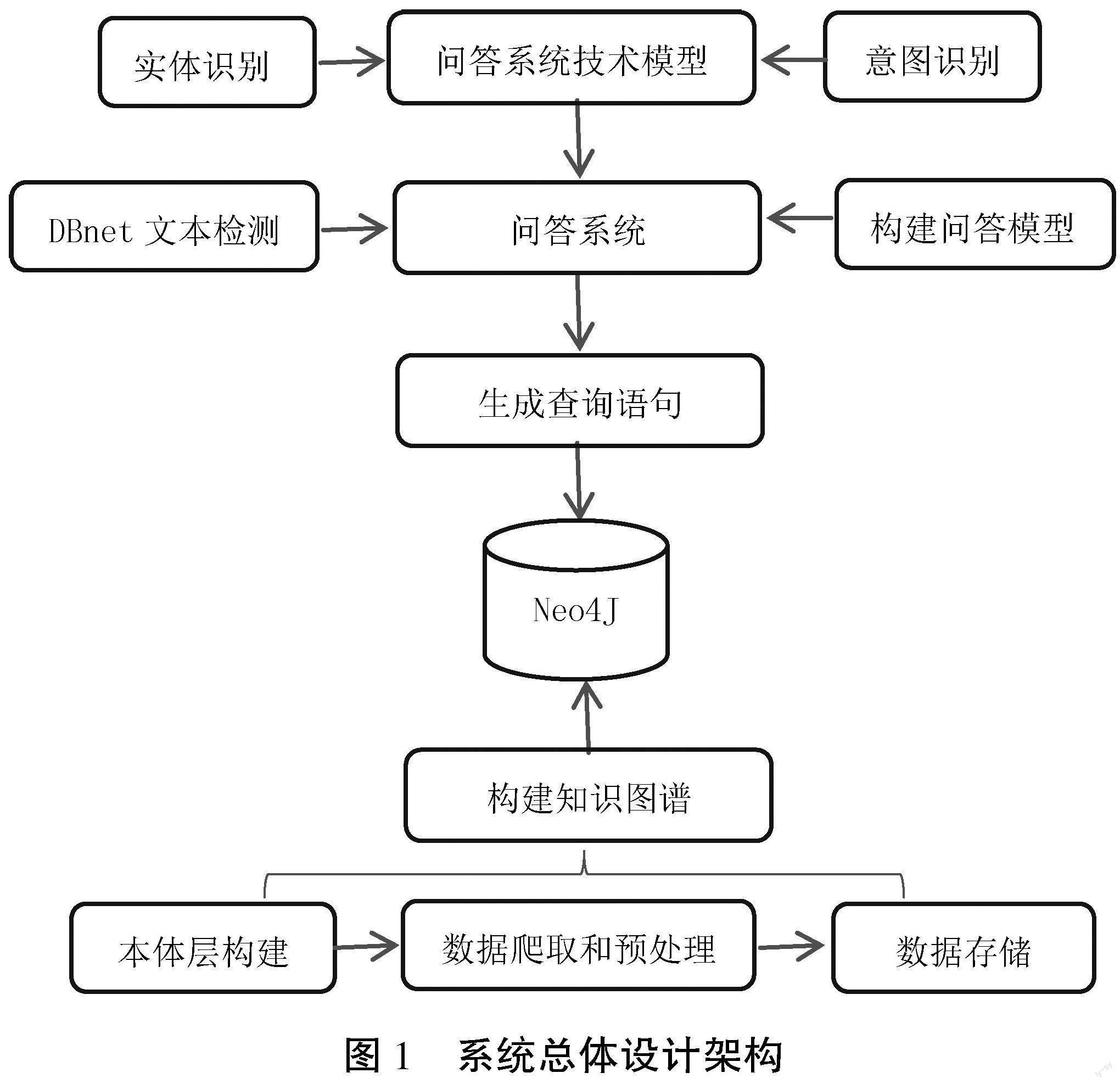
系統主要分為3個主要任務,即知識圖譜的構建工作、問答系統相關技術模型的設計以及問答系統的設計,具體如圖1所示。
問答系統相關技術模型的設計訓練主要分為命名實體識別和用戶提問意圖識別。問答系統整體使用Flask封裝后臺API,用戶的需求為輸入,然后判斷為文本還是圖片,如果是圖片則使用DBnet識別圖片內容,如果是文本則通過NLP的BERT+BiLSTM+CRF構建提問實體,之后用CNN進行分類來識別意圖,最后構建查詢語句,將數據返回給用戶。
3? 知識圖譜的構建
3.1? 基本流程
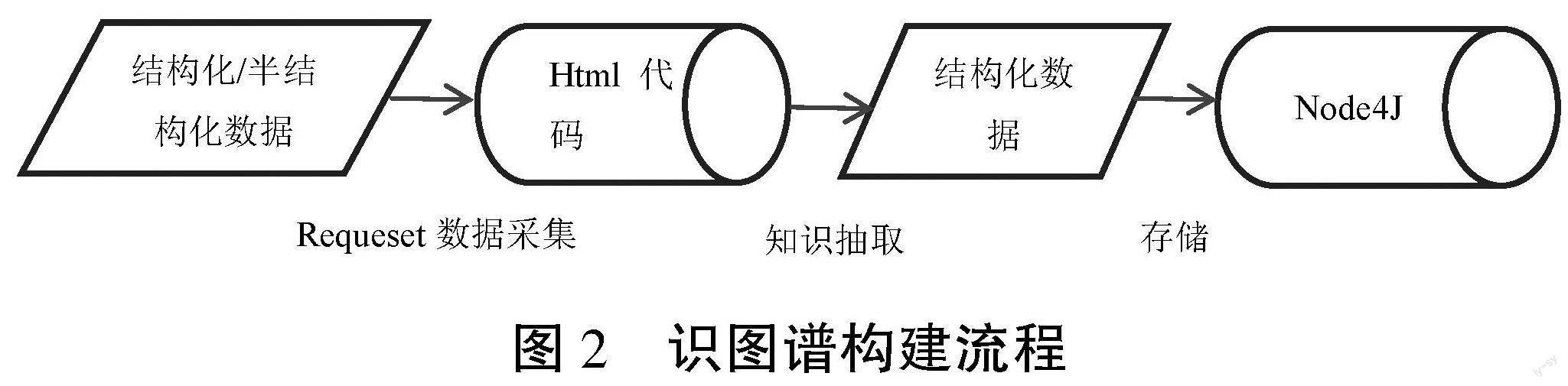
知識圖譜的構建相關流程,如圖2所示。首先,通過爬蟲行采集結構化或半結構化數據;其次,通過中間數據庫進行存儲;再次,進行知識抽取,將數據轉為知識圖譜的結構化數據;最后,存儲進Node4J數據庫。
3.2? 本體層構建
在知識圖譜中,本體層是一種用于描述實體、屬性、概念以及它們之間關系的結構化資源模型。本體層可以看做是整個知識圖譜中最核心的一層,通過對相關實體和概念的分類、定義和關聯規范,能夠為下層數據集成提供更加明確的語義表示和分層約束。在已經建立好本體層之后,只要將需要被存儲/表達的實體映射到本體層上,就可以很方便地繼承/獲取其相關屬性信息或者推理出新的事實或知識。將知識隱式編碼到本體層的方式,可以使得知識圖譜更加具有可理解性、自解釋性和可維護性,并且便于進行知識推理、查詢和分析。
3.3? 數據爬取和預處理
系統主要通過request、Selenium和XPath相結合來爬取網站。具體爬取過程為:首先,進入網站找到相應數據對應的URL地址,分析URL地址之間跳轉的關系;其次,在網站中定位所需要的元素;最后,編寫爬蟲代碼依次爬取每個URL的數據。網頁中存在著部分缺失值,需要對提取到的數據進行清洗和預處理,去除無用的標簽、特殊字符或者HTML實體,使數據更加規范和易于處理。
3.4? 數據存儲
數據預先只存儲在本地磁盤中,不易于系統后臺進行查詢工作,需要將其導入數據庫,知識圖譜主要具有實體、關系、屬性3個主要元素,而圖數據庫的點、邊、點的相應值正好與其一一對應。圖數據庫具有天然的優勢存儲知識圖譜,且其和結構化數據庫一樣提供了類SQL的查詢語言,因此將數據存儲進圖數據庫。Noe4J是一個開源的數據庫,易于使用,所以選擇其作為后臺知識庫。
4? 問答系統相關技術模型設計
4.1? 基于BERT-BiLSTM-CRF模型的命名實體識別
實體抽取即從非結構化文本中識別出實體信息,最早期采取字典和規則的方法,但過分依賴專家人工,費時費力,難以適應數據改變,后來被最大熵模型,支持向量機,條件隨機場的機器學習方法所替代。近年來,深度學習也不斷走入NLP的視野,CNN、RNN都開始被用于實體識別。基于RNN在解決長距離依賴問題的過程中出現的梯度消失和梯度爆炸,專家們引入了門控機制,創造了LSTM的新模型來解決長期依賴問題,由此也衍生出了BiLSTM來解決雙向的語義依賴問題。系統使用BERT-BiLSTM-CRF模型,該模型是一種結合了BERT、BiLSTM和CRF的序列標注模型,用于解決命名實體識別(NER)任務。該模型的核心思想是利用BERT模型的語義表示能力、BiLSTM模型的上下文信息捕捉能力和CRF模型的標簽約束能力,從而提升NER任務的性能。
首先,系統選擇使用BERT動態語言模型作為詞嵌入層。BERT模型包含多層雙向Transformer語言模型,并大量使用Attention機制,在編碼過程中考慮每個詞的上下文信息。與CNN和RNN不同,BERT模型只包含前饋神經網絡和自注意力機制,通過Transformer網絡的Encoder部分解決了RNN長距離依賴問題。BERT的輸入向量包括3部分:詞分隔、句子分隔和位置分隔。
其次,經過BERT詞嵌入層后,這些向量將會進入特征提取層,去除掉那些無關緊要的特征,獲取能夠典型代表這一向量的特征,同時也減少了向量的維度,方便后續的處理。系統采用BiLSTM作為特征層。LSTM根據前文描述,解決了RNN可能出現的梯度消失、梯度爆炸等問題,且由于中文文本前后文的關系性,系統使用兩層LSTM進行雙向提取,最后將結果連接到CRF標注層。
最后,特征提取完成后,需要獲取每一個字符的BIO標注。前文講述的CRF是一種基于概率圖模型的序列標注方法,且CRF利用了輸出的全局概率分布來建模,同時將原本單獨考慮的每個標注之間的相互作用融合在一起,具有極強的建模能力,所以選擇CRF作為特征分類層。CRF將會最終輸出類似B-DIEASE、I-DIEASE、O等標注類型,用于后續直接讀取獲得識別出來的實體。
4.2? 基于BERT+TextCNN模型的用戶意圖識別
識別出實體后,還需要判斷用戶對于實體需要具體哪一屬性或者關系的識別。由于定義了本體層,意圖識別可以轉化為機器學習的分類和NLP方向的情感識別問題,KNN、SVM、樸素貝葉斯是最常見的機器學習方法。隨著技術的發展出現了TextCNN、RNN等模型處理此類任務。BERT作為預處理語言模型,在NLP領域受到廣泛的關注,相較于LSTM,Transformer可以更好地處理長距離依賴,并且其本身就是基于注意力機制,因此系統采用BERT+CNN進行意圖抽取的任務。BERT+TextCNN模型從特征提取層、特征分類層和數據增強層面綜合應用了BERT和TextCNN的特點,能夠充分利用語義表示和卷積神經網絡特征提取的優勢,同時通過數據增強來提升模型的魯棒性和泛化能力。
首先,利用BERT模型作為特征提取器,學習文本的語義表示。BERT模型通過無監督預訓練,在大規模語料上學習到了豐富的上下文相關的詞向量表示,能夠捕捉詞語和句子之間的語義關系。這些語義表示作為輸入,提供了豐富的語義信息,用于后續的特征提取和分類。
其次,利用TextCNN模型進行特征提取和分類。TextCNN模型通過卷積和池化操作提取文本的局部和整體特征。卷積操作利用不同尺寸的濾波器對文本進行卷積,捕捉不同長度的局部特征。池化操作則提取出每個特征維度上的最重要特征。這樣TextCNN模型能夠有效地提取文本的特征,將其輸入到分類器中進行分類。
最后,采用各種數據增強技術來提升模型的魯棒性和泛化能力。例如,可以使用數據增強方法如隨機替換、隨機插入、隨機刪除等,對輸入文本進行擾動,生成新的訓練樣本。這樣可以增加模型對不同變體的文本的適應能力,提升模型的泛化能力。
5? 系統架構
系統參考MVC架構分為3個部分:前端顯示層、邏輯處理層和數據訪問層。前端顯示層向最終用戶提供易于使用的界面,使用了BootStrap和Jquery框架來簡化前端界面的開發。邏輯處理層主要響應前臺發送的異步請求,然后返回相應的數據供前端顯示給終端用戶。其主要工作是調用模型獲取模型的結果,再進入數據訪問層獲取數據。Flask可以更容易地實現一個輕量、靈活、易擴展的 Web 應用,并且能夠快速進行迭代和部署,所以系統選擇Flask將后臺封裝。數據訪問層通過第三方的PYNEO包來對Neo4J數據庫進行訪問,其使用方式與JDBC類似,用戶只需要編寫數據庫連接的參數和相應的CQL語句即可完成查詢。
6? 結語
筆者通過介紹知識圖譜和問答系統的設計和實現過程,展示了如何利用現代技術手段構建高效的知識管理和問答系統。通過這些技術手段,可以更好地管理和利用知識資源,提高用戶獲取信息的效率和準確性。在未來的工作中,筆者將進一步優化和改進該系統,如增強知識圖譜的構建效率和準確性,提高問答系統的智能水平和服務質量。此外,筆者還將探索更多的應用場景,如智能客服、智能推薦等,以更好地發揮新技術的實際價值。
參考文獻
[1]杜睿山,張軼楠,田楓,等.基于知識圖譜的智能問答系統研究[J].計算機技術與發展,2021(11):189-194.
[2]王天彬,黃瑞陽,張建朋,等.融合機器閱讀理解的知識圖譜問答系統設計與實現[J].信息工程大學學報,2021(6):709-715.
[3]趙浩宇,陳登建,曾楨,等.基于知識圖譜的中國近代史知識問答系統構建研究[J].數字圖書館論壇,2022(6):31-38.
[4]盧經緯,郭超,戴星原,等.問答ChatGPT之后:超大預訓練模型的機遇和挑戰[J].自動化學報,2023(4):705-717.
(編輯? 姚? 鑫)
Design of knowledge graph based Q&A system design
Qin? Lijuan
(Jiangsu Second Normal University, Nanjing 210013, China)
Abstract: With the explosive growth of online data, the problem of knowledge flooding and knowledge overload is increasingly prominent. Traditional Q&A systems usually use a simple keyword matching model, which often fails to accurately understand the real intention of users and makes it difficult to provide accurate answers. To solve this problem, the article designs an intelligent Q&A system based on knowledge graphs. Firstly, the knowledge graph is constructed through the steps of ontology layer construction, data crawling and data storage. Secondly, BERT+BiLSTM+CR model and BERT+TextCNN model are used for named entity recognition and user intention recognition, respectively. Finally, the backend API is wrapped using Flask in order to provide more flexible and personalized services.
Key words: knowledge graph; Q&A system; user intention
