
基于改進(jìn)的稀疏描述和降維人臉識(shí)別方法
2023-12-02 06:47:46程鴻芳
綿陽(yáng)師范學(xué)院學(xué)報(bào) 2023年11期
關(guān)鍵詞:數(shù)據(jù)庫(kù)方法
程鴻芳,祝 軍
(1.蕪湖職業(yè)技術(shù)學(xué)院,安徽蕪湖 241000;2.安徽工程大學(xué),安徽蕪湖 241000)
0 引言
稀疏描述是計(jì)算機(jī)視覺(jué)、人臉識(shí)別、模式識(shí)別等研究領(lǐng)域的一種新的研究手段.稀疏描述人臉識(shí)別是用訓(xùn)練樣本的稀疏的線(xiàn)性組合近似表示測(cè)試樣本,并進(jìn)行分類(lèi)和完成識(shí)別,是壓縮感知理論的核心內(nèi)容之一[1].將維數(shù)較高的圖像降成低維數(shù),可以避免“維數(shù)災(zāi)難”[2].目前比較流行的算法有常規(guī)降維法、線(xiàn)性判別分析(LDA)和主成分分析(PCA)[3]等.
劉子淵等[4]提出利用快速稀疏描述與協(xié)同描述分類(lèi)方法融合進(jìn)行人臉識(shí)別,Naseem等[5]提出線(xiàn)性回歸分類(lèi)法進(jìn)行人臉識(shí)別,簡(jiǎn)彩任等[6]提出利用主成分分析和核主成分分析完成降維圖像,陳麗霞等[7]提出融合稀疏描述和半監(jiān)督降維完成人臉識(shí)別,蔣科輝等[8]提出基于局部約束字典學(xué)習(xí)的非線(xiàn)性降維人臉識(shí)別方法.
以上各學(xué)者從不同的角度提出了不同的人臉識(shí)別的方法,最終達(dá)到識(shí)別的效果各異.本文將稀疏描述和常規(guī)降維兩者結(jié)合,能夠很好地表達(dá)每個(gè)測(cè)試樣本.稀疏描述得出的測(cè)試樣本的維數(shù)與原樣本向量維數(shù)相同,而常規(guī)降維方法得到的樣本向量維數(shù)降低.常規(guī)降維方法通過(guò)變換軸,得出每個(gè)訓(xùn)練樣本和測(cè)試樣本的特征,然后使用分類(lèi)器對(duì)測(cè)試樣本進(jìn)行分類(lèi)[4].將兩者結(jié)合,能取得較低分類(lèi)錯(cuò)誤率[5].
1 改進(jìn)的常規(guī)降維方法
改進(jìn)的常規(guī)降維方法又稱(chēng)為基于描述和降維的人臉識(shí)別方法(Routine reduction dimensionality face recognition,簡(jiǎn)寫(xiě)為RRDFR),RRDFR不僅可以使訓(xùn)練樣本進(jìn)行降維,而且能夠很好地表達(dá)測(cè)試樣本.方法如下:第一步,利用稀疏的線(xiàn)性組合全體訓(xùn)練樣本得到測(cè)試樣本,獲得相應(yīng)的表達(dá)系數(shù);第二步,獲得降維需要的投影軸;第三步,利用投影軸將所有的樣本變換到新的低維空間,并利用基于描述的方法進(jìn)行分類(lèi).根據(jù)以上步驟,將RRDFR設(shè)計(jì)了兩個(gè)算法,分別稱(chēng)為算法1和算法2.
2 RRDFR算法
假設(shè)測(cè)試樣本y,第i個(gè)訓(xùn)練樣本xi(i=1,2,...N),所有的樣本均為列向量.
2.1 算法1
第一步:利用線(xiàn)性組合確定測(cè)試樣本,獲得相應(yīng)的表達(dá)系數(shù).根據(jù)該組合確定一個(gè)和測(cè)試樣本間差異最小的訓(xùn)練樣本.
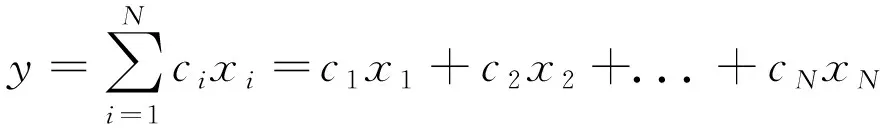
第二步:利用投影軸進(jìn)行降維.令w1,w2,...wd表示前d個(gè)投影軸(利用常規(guī)降維方法得出).該步驟利用xi'=WTxi(i=1,2,...,N)得到每個(gè)訓(xùn)練樣本的特征,其中W=[w1,w2,...wd].通過(guò)y'=WTy獲得測(cè)試樣本的特征.y'和xi'都是d維向量.
第三步:計(jì)算測(cè)試樣本特征y'和第j類(lèi)樣本特征的偏差.計(jì)算公式為
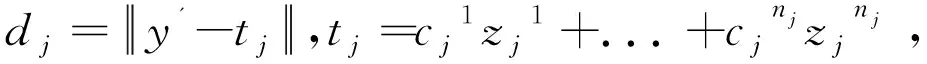
2.2 算法2
算法2在算法1的基礎(chǔ)上,首先選取能夠“最佳”表示測(cè)試樣本的較少訓(xùn)練樣本,然后利用這些“最佳”訓(xùn)練樣本進(jìn)行最后的分類(lèi),算法2的主要步驟如下所示.
第一步:同算法1中的步驟1.
第三步:利用RRDFR得到投影軸,通過(guò)投影軸獲取測(cè)試樣本和”最佳”訓(xùn)練樣本的特征.特征抽取方法和算法1中的步驟2相同.
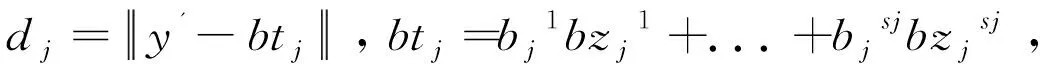
3 合理性分析
RRDFR與常規(guī)的基于描述的人臉識(shí)別方法都會(huì)產(chǎn)生相似的表達(dá)誤差,證明如下:
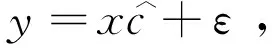
4 RRDFR和DR+RM方法的比較
RRDFR不同于常規(guī)降維方法加基于描述的方法(DR+RM).首先,在人臉識(shí)別中,噪聲會(huì)影響識(shí)別的正確率.該方法對(duì)噪聲具有較強(qiáng)魯棒性.所以該方法非常適合基于圖像的識(shí)別應(yīng)用.其次,在樣本維數(shù)較低時(shí),RRDFR在分類(lèi)性能上大大優(yōu)于DR+RM方法.相對(duì)于低維樣本,基于描述的方法更適合應(yīng)用于高維樣本.假設(shè)訓(xùn)練樣本是非常低維的數(shù)據(jù)并且訓(xùn)練樣本的數(shù)量比樣本向量的維數(shù)大得多,則通常基于描述的方法能夠用訓(xùn)練樣本準(zhǔn)確、零誤差地表示測(cè)試樣本.但是在在利用訓(xùn)練樣本表示測(cè)試樣本時(shí),真正來(lái)自測(cè)試樣本類(lèi)的訓(xùn)練樣本可能無(wú)法發(fā)揮主導(dǎo)作用.基于描述的方法難以對(duì)測(cè)試樣本得出正確分類(lèi).
5 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)將用Python3.9驗(yàn)證文中算法.在驗(yàn)證過(guò)程中分別使用ORL、Yale、AR三個(gè)免費(fèi)人臉圖像庫(kù).同時(shí)分別選擇有遮擋的數(shù)據(jù)集和無(wú)遮擋的數(shù)據(jù)集進(jìn)行實(shí)驗(yàn).其中ORL人臉數(shù)據(jù)庫(kù)中人臉基本沒(méi)有光照、遮擋干擾.Yale人臉數(shù)據(jù)庫(kù)中人臉表情、臉部細(xì)節(jié)、時(shí)期不同.AR人臉數(shù)據(jù)庫(kù)中人臉圖像,表情、姿態(tài)、光照、遮擋不一.如圖1、圖2、圖3所示:

圖1 ORL人臉庫(kù)部分圖像Fig.1 Partial image of ORL face library

圖2 Yale人臉庫(kù)部分圖像Fig.2 Partial image of Yale face library

圖3 AR人臉庫(kù)部分圖像Fig.3 Partial image of AR face library
5.1 γ取值
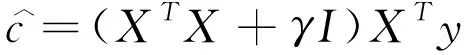
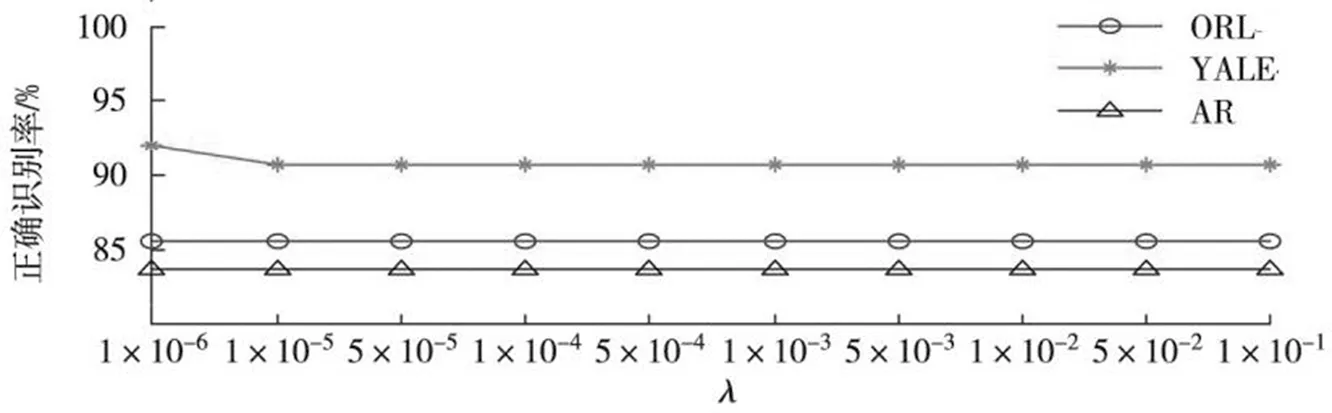
圖4 不同數(shù)據(jù)庫(kù)中λ值對(duì)識(shí)別率的影響Fig.4 The influence of λ value on recognition rate in different databases
5.2 變換軸的個(gè)數(shù)對(duì)算法的影響
算法中利用常規(guī)降維方法得出變換軸的個(gè)數(shù).利用xi'=WTy(i=1,2,...,N)得到每個(gè)訓(xùn)練樣本的特征,其中W=[w1,w2,...wd],w1,w2,...wd表示d個(gè)投影軸.圖5顯示了在AR人臉庫(kù)中隨著變換軸數(shù)量的變化,分類(lèi)精度也隨之變化.實(shí)驗(yàn)中,每個(gè)人前4張圖片作為訓(xùn)練樣本,剩下的為測(cè)試樣本.結(jié)果表明,改進(jìn)后的性能明顯優(yōu)于常規(guī)的LDA(PCA).
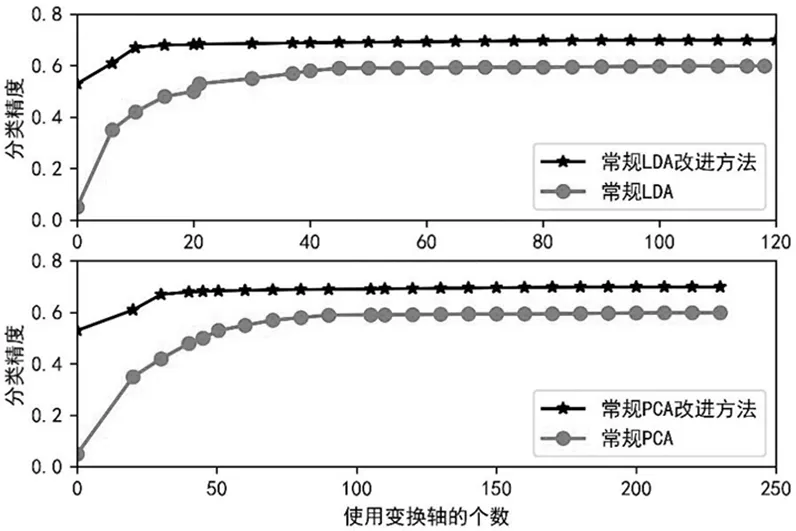
圖5 分類(lèi)正確率Fig.5 Classification accuracy rate
5.2 ORL人臉庫(kù)中的實(shí)驗(yàn)
ORL人臉數(shù)據(jù)庫(kù)共有40個(gè)人不同表情、不同穿戴的圖像,每人10幅共400幅圖像.ORL人臉數(shù)據(jù)庫(kù)中原始圖像大小112×92,實(shí)驗(yàn)中采用下采樣至32×32大小,每類(lèi)隨機(jī)選取2,4,6,8幅作為訓(xùn)練樣本,其余的作為測(cè)試樣本.首先歸一化處理每一幅圖,部分圖像如圖4所示.實(shí)驗(yàn)分成兩類(lèi)進(jìn)行.一組將LDA、RRDFR1(基于LDA)、RRDFR2(基于LDA)進(jìn)行實(shí)驗(yàn),一組將PCA、RRDFR1(基于PCA)、RRDFR2(基于PCA)進(jìn)行實(shí)驗(yàn),測(cè)試結(jié)果如表1所示.降維處理人臉圖像,將高維的人臉圖像降為不同的低維度數(shù)據(jù),在不同維數(shù)下,測(cè)試得出不同的分類(lèi)正確率,如圖6和圖7所示.

圖6 ORL數(shù)據(jù)庫(kù)中LDA、RRDFR1、RRDFR2在不同維數(shù)的識(shí)別率比較Fig.6 Comparison of recognition rates of LDA,RRDFR1 and RRDFR2 in different dimensions in ORL database圖7 ORL 數(shù)據(jù)庫(kù)中PCA、RRDFR1、RRDFR2在不同維數(shù)的識(shí)別率比較Fig.7 Comparison of recognition rates of PCA, RRDFR1, RRDFR2 in different dimensions in ORL database
在圖6中分別表示了采用LDA、RRDFR1(基于LDA)、RRDFR2(基于LDA)算法將ORL人臉圖像降到從10到100不同的低緯度的準(zhǔn)確性.在圖7中分別表示了采用PCA、RRDFR1(基于PCA)、RRDFR2(基于PCA)算法將ORL人臉圖像降到從10到100不同的低維度的準(zhǔn)確性.從圖6和圖7所示的ORL數(shù)據(jù)庫(kù)中三種降維算法對(duì)不同維數(shù)的識(shí)別準(zhǔn)確率比較結(jié)果中可以看出,相比常規(guī)LDA和PCA算法而言RRDFR算法的識(shí)別率要優(yōu).
5.3 Yale人臉庫(kù)中的實(shí)驗(yàn)
Yale人臉數(shù)據(jù)庫(kù)共有15個(gè)人不同光照、不同臉部表情的圖像,每人11幅共165幅圖像.Yale人臉數(shù)據(jù)庫(kù)中原始圖像大小100×100,實(shí)驗(yàn)中采用采樣至48×48大小,每類(lèi)隨機(jī)選取2,4,6,8幅作為訓(xùn)練樣本,其余的作為測(cè)試樣本.首先歸一化處理每一幅圖.實(shí)驗(yàn)分成兩類(lèi)進(jìn)行.一組將LDA、RRDFR1(基于LDA)、RRDFR2(基于LDA)進(jìn)行實(shí)驗(yàn),一組將PCA、RRDFR1(基于PCA)、RRDFR2(基于PCA)進(jìn)行實(shí)驗(yàn),測(cè)試結(jié)果如表2所示.在不同維數(shù)下,測(cè)試得出不同的分類(lèi)正確率,如圖8和圖9所示.
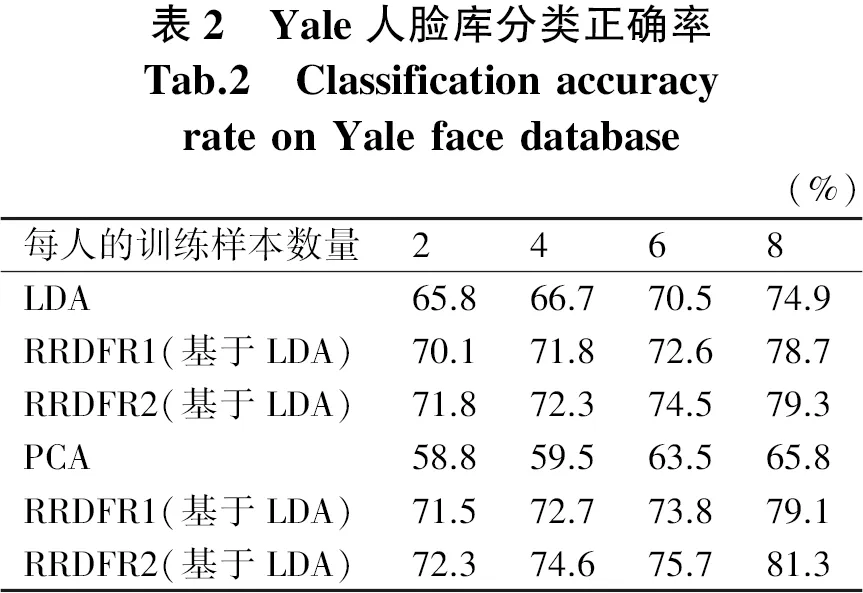
在圖8中分別表示了采用LDA、RRDFR1(基于LDA)、RRDFR2(基于LDA)算法將ORL人臉圖像降到從10到100不同的低緯度的準(zhǔn)確性.在圖9中分別表示了采用這PCA、RRDFR1(基于PCA)、RRDFR2(基于PCA)算法將ORL人臉圖像降到從10到100不同的低維度的準(zhǔn)確性.從圖8和圖9所示的Yale數(shù)據(jù)庫(kù)中三種降維算法對(duì)不同維數(shù)的識(shí)別準(zhǔn)確率比較結(jié)果中可以看出,相比常規(guī)LDA和PCA算法而言RRDFR算法的識(shí)別率要優(yōu).
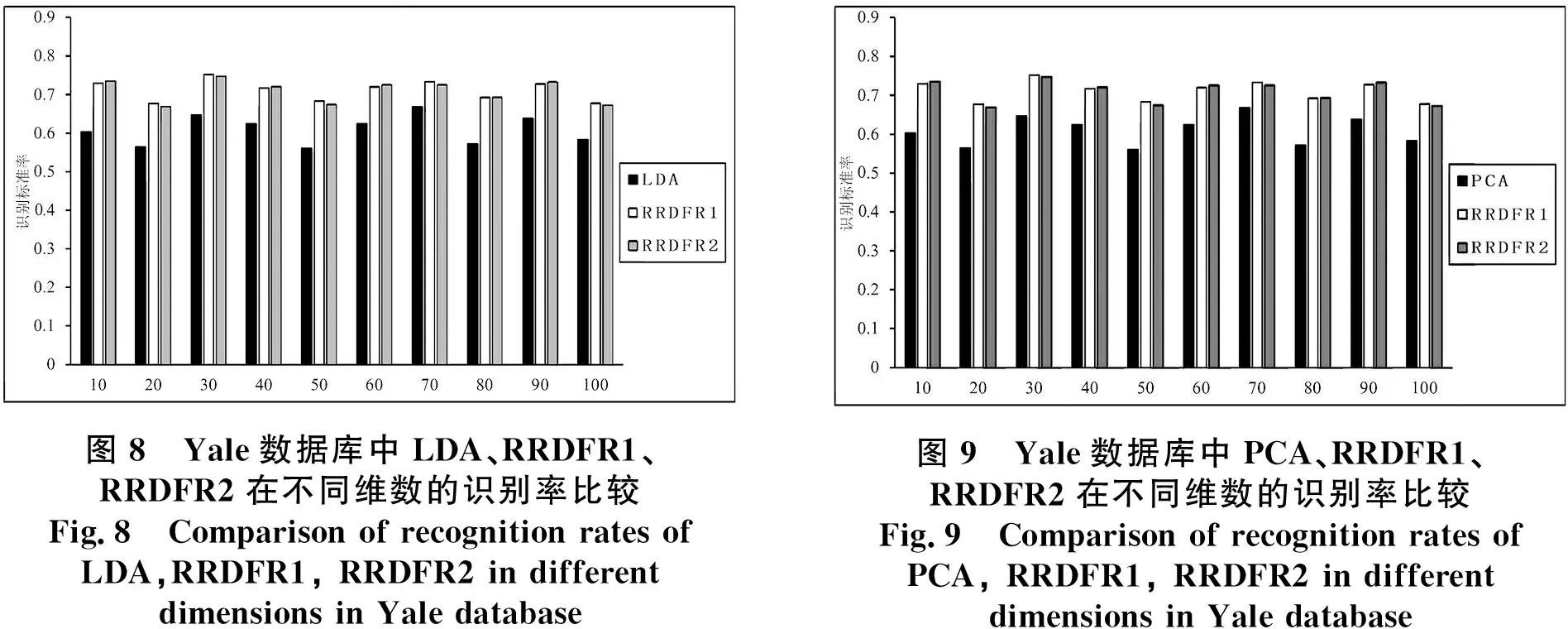
圖8 Yale數(shù)據(jù)庫(kù)中LDA、RRDFR1、RRDFR2在不同維數(shù)的識(shí)別率比較Fig.8 Comparison of recognition rates of LDA,RRDFR1, RRDFR2 in different dimensions in Yale database圖9 Yale數(shù)據(jù)庫(kù)中PCA、RRDFR1、RRDFR2在不同維數(shù)的識(shí)別率比較Fig.9 Comparison of recognition rates ofPCA, RRDFR1, RRDFR2 in differentdimensions in Yale database
5.4 AR人臉庫(kù)中的實(shí)驗(yàn)
AR人臉數(shù)據(jù)庫(kù)共有100個(gè)人不同光照、不同臉部表情、不同遮罩的圖像,每人26幅共2 600幅圖像.AR人臉數(shù)據(jù)庫(kù)中原始圖像大小120×165,實(shí)驗(yàn)中采用采樣至48×48大小,每類(lèi)隨機(jī)選取4,6,8,12幅作為訓(xùn)練樣本,其余的作為測(cè)試樣本.首先歸一化處理每一幅圖.實(shí)驗(yàn)分成兩類(lèi)進(jìn)行.一組將LDA、RRDFR1(基于LDA)、RRDFR2(基于LDA)進(jìn)行實(shí)驗(yàn),一組將PCA、RRDFR1(基于PCA)、RRDFR2(基于PCA)進(jìn)行實(shí)驗(yàn),測(cè)試結(jié)果如表3所示.在不同維數(shù)下,測(cè)試得出不同的分類(lèi)正確率,如圖10和圖11所示.
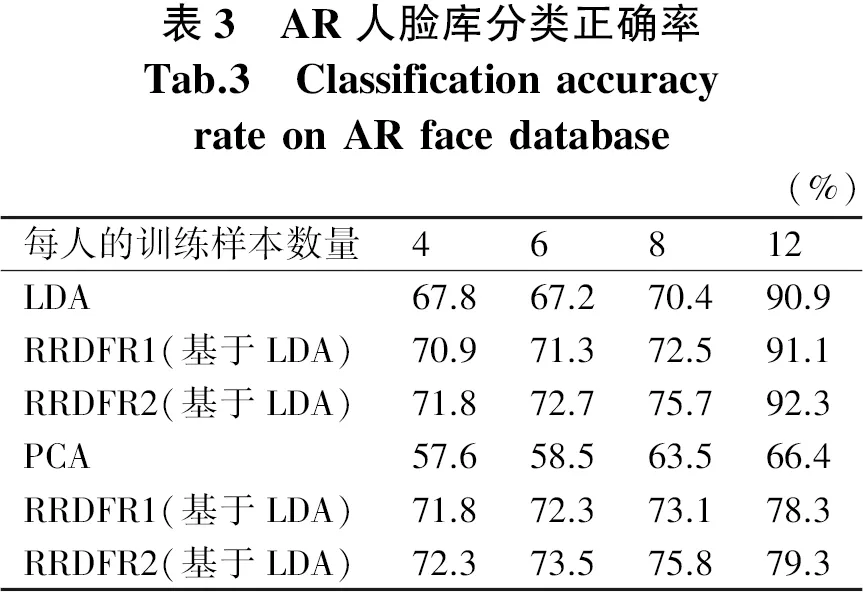
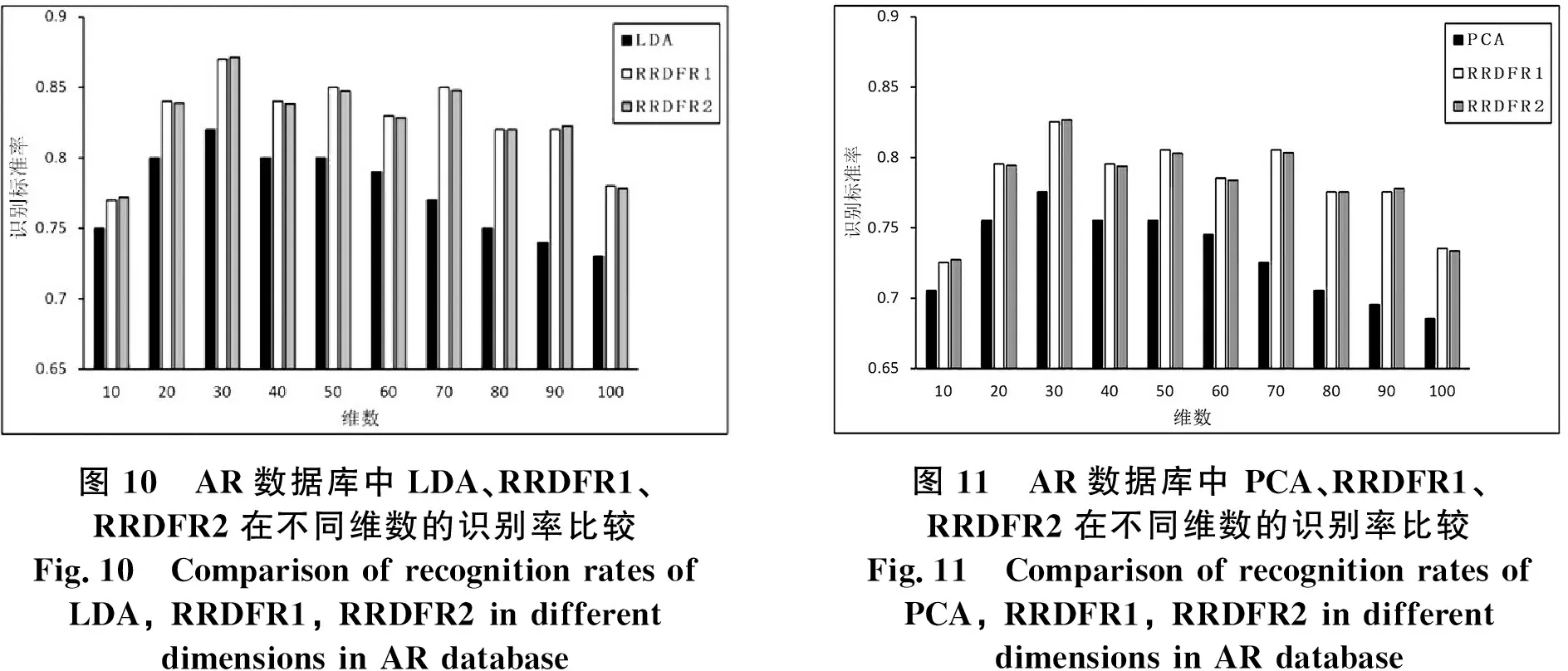
圖10 AR數(shù)據(jù)庫(kù)中LDA、RRDFR1、RRDFR2在不同維數(shù)的識(shí)別率比較Fig.10 Comparison of recognition rates of LDA, RRDFR1, RRDFR2 in different dimensions in AR database圖11 AR數(shù)據(jù)庫(kù)中 PCA、RRDFR1、RRDFR2在不同維數(shù)的識(shí)別率比較Fig.11 Comparison of recognition rates of PCA, RRDFR1, RRDFR2 in different dimensions in AR database
在圖10中分別表示了采用這LDA、RRDFR1(基于LDA)、RRDFR2(基于LDA)算法將ORL人臉圖像降到從10到100不同的低緯度的準(zhǔn)確性.在圖11中分別表示了采用PCA、RRDFR1(基于PCA)、RRDFR2(基于PCA)算法將ORL人臉圖像降到從10到100不同的低維度的準(zhǔn)確性.從圖10和圖11所示的AR數(shù)據(jù)庫(kù)中三種降維算法對(duì)不同維數(shù)的識(shí)別準(zhǔn)確率比較結(jié)果中可以看出,相比LDA和PCA算法而言RRDFR算法的識(shí)別率要優(yōu).
6 結(jié)論
RRDFR同時(shí)具有常規(guī)降維方法和基于描述的分類(lèi)這兩類(lèi)方法的優(yōu)點(diǎn).該方法可以使每一個(gè)測(cè)試樣本都能夠被全部或部分訓(xùn)練樣本的線(xiàn)性組合很好地表達(dá),而且當(dāng)RRDFR方法將樣本變換到另一個(gè)低維空間時(shí),該方法仍能像普通降維方法那樣具有統(tǒng)計(jì)上的一些屬性.
猜你喜歡
兒童故事畫(huà)報(bào)(2019年5期)2019-05-26 14:26:14
財(cái)經(jīng)(2017年15期)2017-07-03 22:40:49
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
意林原創(chuàng)版(2016年10期)2016-11-25 10:28:30
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
