基于Dlib的面部疲勞檢測模型
2023-12-06 11:33:50宋佳堯安姝潔張涔嘉
軟件工程 2023年12期
宋佳堯, 尉 斌, 安姝潔, 張涔嘉, 楊 瑋
(天津商業大學信息工程學院, 天津 300134)
0 引言(Introduction)
目前,對于疲勞狀態的主要測量方法分為生理特征、視覺特征和語音特征等類型[1]。其中,基于生理特征[2]的疲勞檢測大多情況下會使用侵入式的傳感器,高昂的價格及侵入式設備可能引起佩戴者的不適,是影響其普及推廣的兩大因素;基于語音特征[3]的疲勞檢測只適用于采用標準呼叫應答的場景且語音標記樣本數據較為稀缺;基于視覺特征[4]的疲勞檢測具有非接觸性、可直接根據人的面部關鍵點坐標的變化(如頭部位置的偏移、眼睛閉合時長、打哈欠等)反映其疲勞狀態等優勢,成為目前研究的主流方法。在駕駛環境、云自習室等情境下,基于面部視覺特征的疲勞狀態檢測,可以幫助人們對駕駛員的疲勞狀態、學生注意力不集中的狀態發出預警。
1 基于面部特征的疲勞檢測(Fatigue detection based on facial features)
目前,應用較為廣泛的基于面部特征的疲勞檢測度量參數有PERCLOS(眼睛閉合時間占單位時間的百分率)參數和PMOT(張嘴時間占單位時間的百分率)參數。PERCLOS是卡內基梅隆研究所提出的度量疲勞的物理量[5]。美國聯邦公路管理局開展了在駕駛情境下,對PERCLOS、眨眼頻率、打哈欠等9種疲勞參數進行相關性分析研究,得出PERCLOS參數與疲勞駕駛狀態相關性最高的結論[6]。
PERCLOS參數表示閉眼時長在單位時間內所占的百分比,使用閉眼幀數與單位時間內視頻總幀數n的比值表示,其計算公式如下:
(1)
根據參考文獻[7],將眼瞼遮住瞳孔的面積達到80%,判定為閉眼的P80標準對疲勞狀態的檢測是最準確的。
PMOT參數的計算公式如公式(2)所示,它用來表示張嘴時長在單位時間內所占的百分比,使用張嘴幀數與單位時間內視頻總幀數m的比值表示。
(2)
值得注意的是,單獨使用PMOT參數,有時會造成打哈欠的張嘴和說話張嘴的誤報,實際進行疲勞檢測時,可以結合眨眼頻率和頭部姿態參數進行閾值的確定。
2 模型設計(Design of the model)
Dlib是一種開源的、跨平臺的工具包,包含諸如圖像處理、機器學習和深度學習等眾多模塊。對比TensorFlow和PyTorch兩大框架,Dlib模型在圖像處理和特征點定位方面的通用性更強,具有更大的優越性。因此,Dlib模型在人臉檢測領域的應用也非常廣泛。本文設計的Dlib面部疲勞狀態檢測模型,由人臉檢測器、關鍵點定位器、特征計算器和狀態預測器四個模塊構成,面部疲勞狀態檢測模型框架如圖1所示。其中,人臉檢測器的任務是讀取視頻,并通過dlib.get_forntal_face_detector函數捕獲視頻流中的人臉,將人臉框發送給關鍵點定位器。關鍵點定位器的任務是通過dlib.shape_predictor函數獲取人臉的68個關鍵點的坐標,并將坐標向量傳遞給特征計算器。特征計算器的任務是分別對眼部特征、嘴部特征和頭部姿態進行計算,并將結果實時發送給狀態預測器。狀態預測器的任務是對疲勞狀態進行判定,不依賴于單一參數,而是結合眼部、嘴部和頭部姿態進行綜合度量。例如,人在打瞌睡時,除了會閉眼,頭部也會下垂;打哈欠時,除了嘴部的張開角度比說話時大,還會出現閉眼的情況。

圖1 面部疲勞狀態檢測模型框架Fig.1 Framework of facial fatigue state detection model
Dlib庫提供了dlib.get_forntal_face_detector函數,基于這個函數可以構造人臉檢測器,人臉檢測器采用HOG算法(Histogram of Oriented Gradient,方向梯度直方圖)、線性分類器、金字塔圖像結構和滑動窗口檢測等技術,Dlib模型中的HOG算法主要用于捕獲輪廓信息,首先對圖像進行灰度化處理,其次進行Gamma壓縮和歸一化圖像,以減少戶外光照對圖像的影響;其檢測效果如圖2所示。在本文的模型設計中,人臉檢測器可以針對攝像頭進行實時的人臉捕獲。

圖2 人臉檢測器效果Fig.2 Face detector effect
面部關鍵點定位器是基于Dlib庫中的dlib.shape_predictor函數構造的,該函數對面部的68個關鍵點(編號從1~68)進行標注。從圖3可以看出,左眼的關鍵點編號是37~42,右眼的關鍵點編號是43~48,嘴部的關鍵點編號是49~68。圖2和圖3中使用的測試圖片來自于WIDER FACE公開數據集。

圖3 關鍵點定位器效果Fig.3 Key locator effect
3 實現原理(Implementation principle)
3.1 對瞌睡狀態的判定
是否發生了疲勞狀態下的瞌睡行為主要通過“閉眼+頭部姿態變化”綜合判定。
在Dlib庫中,眼睛的位置是通過六個關鍵點進行標注的(圖4)。因此,眼睛縱橫比的計算方法如下[8]:
(3)

圖4 計算縱橫比的眼部關鍵點Fig.4 Key points for calculating eye aspect ratios
頭部姿態估計主要是獲得臉部朝向的角度信息,一般可以用旋轉矩陣、旋轉向量、四元數或歐拉角表示[9]。歐拉角的可讀性更好,使用較為廣泛,常用的三個歐拉角度是俯仰角Pitch、搖頭Yaw和滾轉角Roll。
為減少誤報,提高模型判定的準確率,要對正常狀態下的眨眼和疲勞時的閉眼進行區分,正常狀態下眨眼的閉眼時間極短,而疲勞時閉眼時間相對較長。正常狀態下眨眼時,眼睛縱橫比只在瞬時(1~3幀)處于0值,因此在判斷眼睛縱橫比的基礎上,還要檢測閉眼的持續時長[10]。
持續時長可通過計數器統計。在眼睛縱橫比小于0.2時,認為當前幀處于閉眼狀態,計數器加1。一旦計數器的值大于閾值,則結合頭部當前的姿態進行判定。例如,計數器的值大于48且頭部俯仰角Pitch大于15°,則判定為瞌睡行為。
3.2 對打哈欠狀態的判定
是否發生了疲勞狀態下的打哈欠行為,主要通過嘴部的張開角度和持續時間判定。在Dlib庫中,嘴部的外部輪廓對應12個關鍵點,如圖3中的編號49~60,內部輪廓對應8個關鍵點,如圖3中的編號61~68。
類似眼睛縱橫比的計算方法,選取嘴部外部輪廓的6個關鍵點(關鍵點的位置如圖5所示),進行嘴部縱橫比的計算,具體計算方法如公式(4)所示:
(4)
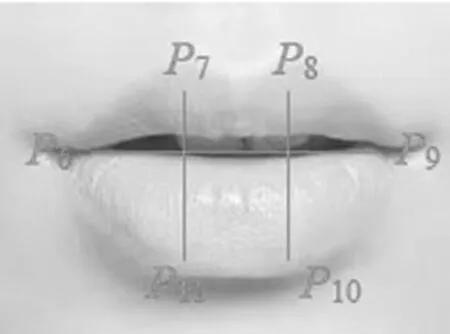
圖5 計算縱橫比的嘴部關鍵點Fig.5 Key points for calculating mouth aspect ratios
一般情況下,人們在安靜、說話、唱歌等不同狀態時,嘴部的縱橫比對應不同的數值。例如,安靜時的嘴部是閉合的,正常說話和交談時嘴部是半張開狀態的,而在打哈欠時,會把嘴張大且持續一定的時間。
為減少誤報,提高模型判定的準確率,要對正常狀態下的說話和疲勞時的張嘴打哈欠行為進行區分,人在正常說話時,他的嘴巴張開和閉合是非常頻繁的,而打哈欠時,嘴部縱橫比數值大且持續時間長(大于4 s)。持續時間的計算與“3.1”小節的計算方法類似,可通過計數器統計。在嘴部縱橫比大于0.3時,認為當前幀處于張嘴狀態,計數器加1。當計數器的值大于96,則判定為打哈欠。
4 模型測試(Model testing)
實驗環境為OpenCV3.4.9.3+Dlib-19.17.99,開發環境為Python3.7.3,Harr分類器選用haarcascade_frontalface_alt.xml。眼睛縱橫比的閾值為0.2,嘴部縱橫比的閾值為0.3。
本文使用YawDD數據集作為測試數據集,YawDD數據集是一個公開的視頻數據集,共收集了90名汽車駕駛員的駕駛視頻,其中女性駕駛員為43名,男性駕駛員為47名。視頻總數有351條,其中內后視鏡角度的視頻合計320條(女性駕駛員為156條,男性駕駛員為164條);儀表板角度的視頻合計29條(女性駕駛員為13條,男性駕駛員為16條)。部分視頻中,駕駛員佩戴了普通眼鏡或太陽眼鏡。圖6展示了YawDD數據集中有代表性的視頻數據,分為男性戴普通眼鏡、男性戴太陽眼鏡、男性未戴眼鏡、女性戴普通眼鏡、女性戴太陽眼鏡、女性未戴眼鏡六種類型。

(a)男性戴普通眼鏡
針對上述六種類型的視頻數據,模型在測試時均成功捕獲到駕駛員打哈欠的狀態,并實時預警提示信息,如圖7所示。

(a)男性戴普通眼鏡
觀察模型測試過程,發現佩戴普通眼鏡或太陽眼鏡,均未影響模型對眼部關鍵點的定位,但在佩戴太陽眼鏡時,有時會因光線照射角度的不同影響對眼部關鍵點坐標的實時跟蹤,進而產生計算延遲,對疲勞狀態的檢測造成了一定影響。模型在YawDD數據集中測試統計結果如表1所示,平均查全率約為94.2%,平均準確率約為93.3%。

表1 測試統計結果
以下針對查全率低于100%的情況進行分析。從表1的數據來看,存在漏報導致查全率低的情況主要集中在男性戴太陽眼鏡、女性戴普通眼鏡和女性戴太陽眼鏡三種情況。但通過對模型的檢測發現,是否佩戴眼鏡不是影響測試的重要因素,駕駛員的肢體移動、手勢變化才是影響測試的主要因素。如圖8所示,女性駕駛員在打哈欠的同時,用右手捂住了嘴巴,導致模型無法跟蹤嘴部關鍵點坐標而產生了漏報。這些情況也為下一步對模型進行優化提供了方向。

圖8 漏報舉例Fig.8 Misreporting examples
5 結論(Conclusion)
疲勞檢測在日常學習、生活的很多方面都有著廣泛的應用。例如,隨著我國汽車保有量的不斷攀升,疲勞駕駛引發的交通事故數量也逐年升高。在疲勞駕駛行為導致交通事故前,駕駛員往往會有明顯的先前疲勞特征,因此對疲勞駕駛狀態進行檢測并做出相應的預警,對于保障交通運輸安全至關重要。本文提出的基于Dlib的模型通過人臉檢測器、關鍵點定位器、特征計算器和狀態預測器四個模塊,能夠快速有效地識別出人物打哈欠、瞌睡等疲勞狀態。通過實驗結果可知,模型能夠滿足實時性、魯棒性和準確率的要求。
猜你喜歡
汽車實用技術(2022年14期)2022-07-30 06:13:42
汽車實用技術(2022年4期)2022-03-07 06:07:20
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
公民與法治(2016年4期)2016-05-17 04:09:26
中國衛生(2014年2期)2014-11-12 13:00:16
語文知識(2014年7期)2014-02-28 22:00:26
