三維坐標(biāo)注意力路徑聚合網(wǎng)絡(luò)的目標(biāo)檢測(cè)算法
2023-12-08 11:49:10涂小妹包曉安金瑜婷張慶琪
計(jì)算機(jī)與生活 2023年12期
涂小妹,包曉安,吳 彪,金瑜婷,4,張慶琪
1.浙江廣廈建設(shè)職業(yè)技術(shù)大學(xué) 建筑工程學(xué)院,浙江 東陽(yáng) 322100
2.浙江理工大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院(人工智能學(xué)院),杭州 310018
3.浙江理工大學(xué) 理學(xué)院,杭州 310018
4.浙江廣廈建設(shè)職業(yè)技術(shù)大學(xué) 信息學(xué)院,浙江 東陽(yáng) 322100
5.山口大學(xué) 東亞研究科,日本 山口753-8514
目標(biāo)檢測(cè)一直以來(lái)是計(jì)算機(jī)視覺(jué)領(lǐng)域的研究熱點(diǎn)之一,其任務(wù)是返回給定圖像中的單個(gè)或多個(gè)特定目標(biāo)的類別與矩形包圍框坐標(biāo)[1-3]。目前兩大主流目標(biāo)檢測(cè)算法:(1)基于候選區(qū)域的雙階段目標(biāo)檢測(cè)算法,以RCNN(region-CNN)為代表,雙階段檢測(cè)算法準(zhǔn)確率高,但是訓(xùn)練和推理階段速度慢,不能滿足實(shí)時(shí)要求[4-5];(2)基于直接回歸的單階段目標(biāo)檢測(cè)算法,以SSD(single shot multi-box detector)和YOLO(you only look once)為代表[6-10],單階段檢測(cè)算法在準(zhǔn)確率和運(yùn)行速度上能達(dá)到一個(gè)均衡,是目前目標(biāo)檢測(cè)中使用較多的一種檢測(cè)框架[11-12]。本文主要以單階段YOLO 系列算法為研究基礎(chǔ),針對(duì)現(xiàn)實(shí)場(chǎng)景中對(duì)目標(biāo)預(yù)測(cè)框定位要求較高的場(chǎng)景,提出了一種檢測(cè)精度較高、定位較準(zhǔn)確的檢測(cè)模型(YOLO-T)。
YOLO系列檢測(cè)框架主要分為主干網(wǎng)絡(luò)、特征融合網(wǎng)絡(luò)、特征解碼網(wǎng)絡(luò)。主干網(wǎng)絡(luò)提取特征,特征融合網(wǎng)絡(luò)融合多層語(yǔ)義特征信息,特征解碼網(wǎng)絡(luò)根據(jù)具體任務(wù)解碼網(wǎng)絡(luò)的輸出。為了充分利用主干網(wǎng)絡(luò)提取的特征,2017年,Lin等人[13]提出了特征金字塔網(wǎng)絡(luò)(feature pyramid networks,F(xiàn)PN),用于構(gòu)建多尺度特征獲取高級(jí)語(yǔ)義信息。FPN 以及基于FPN 的改進(jìn)版[14-18]在單階段檢測(cè)算法上表現(xiàn)出不錯(cuò)的效果。2018年,Liu 等人[14]考慮到網(wǎng)絡(luò)淺層特征信息對(duì)于目標(biāo)分割的重要性,提出了PANet(path aggregation network)網(wǎng)絡(luò),該網(wǎng)絡(luò)從一個(gè)多尺度特征金字塔中捕獲遠(yuǎn)程淺層特征,提高了模型檢測(cè)精度。2020 年,Tan 等人[15]在PANet 的基礎(chǔ)上提出了BiFPN(bi-directional feature pyramid network),該網(wǎng)絡(luò)在每個(gè)層級(jí)添加殘差連接進(jìn)行反復(fù)堆疊來(lái)融合特征。2022 年,Luo 等人[17]提出了通道增強(qiáng)特征金字塔網(wǎng)絡(luò)(channel enhancement feature pyramid network,CE-FPN),該網(wǎng)絡(luò)既實(shí)現(xiàn)了通道增強(qiáng)又實(shí)現(xiàn)了上采樣的亞像素跳躍融合方法。以上這些網(wǎng)絡(luò)模型檢測(cè)準(zhǔn)確率較高,但模型推理速度較慢,參數(shù)量較大,用于YOLO 網(wǎng)絡(luò)會(huì)使其失去實(shí)時(shí)性。于是許多基于YOLO 系列的輕量級(jí)模型應(yīng)運(yùn)而生。2021 年,Hu 等人[19]將YOLOv3-Tiny 網(wǎng)絡(luò)中的卷積層替換為深度分布偏移卷積和移動(dòng)反向瓶頸卷積,并設(shè)計(jì)漸進(jìn)式通道級(jí)剪枝算法在保持檢測(cè)性能的同時(shí)減少了參數(shù)量和計(jì)算成本。2022 年,邱天衡等人[20]基于YOLOv5網(wǎng)絡(luò)提升檢測(cè)精度的同時(shí),使用Ghost 模塊對(duì)網(wǎng)絡(luò)進(jìn)行輕量化,減少模型復(fù)雜度和參數(shù)量。2022年,楊小岡等人[21]在基于改進(jìn)YOLOv5的基礎(chǔ)上,使用深度可分離卷積以及對(duì)網(wǎng)絡(luò)進(jìn)行迭代通道剪枝,以降低模型的參數(shù)量和計(jì)算量。
YOLO 系列網(wǎng)絡(luò)在實(shí)際工業(yè)應(yīng)用中備受青睞,2021 年,Ge 等人[10]提出了YOLOX,在網(wǎng)絡(luò)寬度和深度不斷遞增的過(guò)程中,按照主干特征提取網(wǎng)絡(luò)大小,YOLOX 可以分為S、M、L、X。YOLOX-S 使用的主干特征提取網(wǎng)絡(luò)網(wǎng)絡(luò)最小,模型更輕量化,但在實(shí)際工業(yè)應(yīng)用場(chǎng)景中發(fā)現(xiàn)YOLOX-S 對(duì)目標(biāo)邊界框的回歸不夠準(zhǔn)確,如圖1 所示。YOLOX-M/L/X 模型隨著網(wǎng)絡(luò)寬度和深度的加深,模型具有更好的檢測(cè)和識(shí)別性能,但會(huì)受到硬件條件的制約,難以滿足對(duì)檢測(cè)實(shí)時(shí)性和目標(biāo)框回歸準(zhǔn)確率要求都很高的應(yīng)用場(chǎng)景。針對(duì)這個(gè)問(wèn)題,本文基于YOLOX-S 算法提出了一種檢測(cè)精度較高、定位較準(zhǔn)確的目標(biāo)檢測(cè)算法YOLO-T。

圖1 檢測(cè)框與真實(shí)框的IOUFig.1 IOU of prediction box and ground truth box
(1)在路徑聚合特征金字塔網(wǎng)絡(luò)(path aggregation feature pyramid networks,PAFPN)中,本文提出了采用shortcut 連接方式進(jìn)行跨層特征之間融合,利用TDCA(three-dimensional coordinate attention)對(duì)PAFPN 內(nèi)特征進(jìn)行注意力加權(quán)的方法。該方法不僅能將淺層特征傳遞到特征解碼網(wǎng)絡(luò)中,保留淺層語(yǔ)義信息,又解決了融合淺層特征信息的特征金字塔網(wǎng)絡(luò)存在信息冗余的問(wèn)題。
(2)考慮到坐標(biāo)注意力機(jī)制(coordinate attention,CA)[22]只在X和Y方向進(jìn)行特征聚合,而忽略了通道Z方向的特征加權(quán),本文在CA的基礎(chǔ)上,提出了三維坐標(biāo)注意力(TDCA),其在特征的X、Y和Z三個(gè)方向上進(jìn)行注意力增強(qiáng),有效地將空間坐標(biāo)信息和通道特征信息整合到生成的注意權(quán)重中。
(3)在正負(fù)樣本標(biāo)簽分配策略中,本文沿用了更精準(zhǔn)的SimOTA 采樣策略,但在cost 代價(jià)函數(shù)中,使用了軟標(biāo)簽高質(zhì)量焦點(diǎn)損失(soft label quality focal loss,soft-QFL)和GIOULoss 聯(lián)合作為cost 代價(jià)損失以及網(wǎng)絡(luò)的分類和回歸損失,通過(guò)在目標(biāo)區(qū)域采集高質(zhì)量的樣本來(lái)有效地加速模型收斂。
1 相關(guān)工作
YOLO 系列算法直接對(duì)預(yù)測(cè)的目標(biāo)物體進(jìn)行回歸,在精度要求不高的情況下,速度能達(dá)到實(shí)時(shí)檢測(cè)。經(jīng)過(guò)不斷研究發(fā)展,2021 年,Ge 等人[10]提出了YOLOX,YOLOX 由Backbone、Neck 和Head 等部分組成。Backbone采用CSPDarknet提取圖片的特征信息;Neck 部分采用PAFPN 的特征金字塔結(jié)構(gòu),實(shí)現(xiàn)不同尺寸特征信息的傳遞,解決多尺度問(wèn)題;Head部分采用解耦頭,分別計(jì)算定位、分類和置信度任務(wù),再通過(guò)非極大值抑制(non-maximum suppression,NMS)對(duì)最終檢測(cè)結(jié)果進(jìn)行后處理。2022年,汪斌斌等人[23]基于YOLOX 檢測(cè)模型以及遷移學(xué)習(xí)方法實(shí)現(xiàn)了玉米雄穗的高精度識(shí)別。2022年,楊蜀秦等人[24]提出了基于改進(jìn)YOLOX 的單位面積麥穗檢測(cè)方法,利用采樣框直接實(shí)現(xiàn)了單位面積麥穗計(jì)數(shù)。YOLOX 在實(shí)時(shí)檢測(cè)任務(wù)中有一個(gè)良好的表現(xiàn),但YOLOX 也還有優(yōu)化的空間,如YOLOX 算法的目標(biāo)預(yù)測(cè)框定位不夠準(zhǔn)確,如圖1 所示,檢測(cè)框與目標(biāo)框的IOU 較低。圖1(a)綠色真實(shí)框與帶分類置信度綠色預(yù)測(cè)框的IOU值為0.55,圖1(b)左邊目標(biāo)dog 的綠色真實(shí)框與帶分類置信度藍(lán)色預(yù)測(cè)框的IOU值為0.69,圖1(c)紅色飛機(jī)的綠色真實(shí)框與帶分類置信度紅色預(yù)測(cè)框的IOU值為0.53。
故本文將YOLOX-S 作為研究的基礎(chǔ)網(wǎng)絡(luò),主要改進(jìn)了三方面:(1)在網(wǎng)絡(luò)的Neck 部分,采用shortcut連接方式進(jìn)行跨層特征之間融合,保留淺層語(yǔ)義信息(如邊緣輪廓特征);(2)提出了TDCA注意力算法,并利用TDCA 注意力對(duì)Neck部分的內(nèi)部特征進(jìn)行加權(quán)融合,通過(guò)給特征賦予權(quán)重來(lái)保留有用信息和去除冗余信息;(3)改進(jìn)標(biāo)簽分配策略與損失函數(shù),在計(jì)算SimOTA 的損失矩陣時(shí),采用聯(lián)合soft-QFL 和GIOULoss 的計(jì)算方法,在保證不損失效率的同時(shí)增強(qiáng)了性能。
YOLOX 的Neck 部分是PAFPN,基于PANet[14]創(chuàng)建了自下而上的FPN 增強(qiáng),加速了底層信息的流動(dòng),能快速融合各層語(yǔ)義信息。FPN 是利用圖像金字塔的方式進(jìn)行多尺度變化增強(qiáng),與圖像金字塔不同的是,F(xiàn)PN 是將主干網(wǎng)絡(luò)提取的特征圖壘成金字搭,使用自上而下的方式進(jìn)行特征融合,目的是融合高低層語(yǔ)義信息提高特征的表達(dá)能力,為網(wǎng)絡(luò)的輸出提供更多有效信息。基于FPN 的改進(jìn)還有BiFPN、DRFPN(dual refinement feature pyramid networks)、CE-FPN、Aug-FPN(augmented FPN)等[15-18]。其中BiFPN、CE-FPN 以及Aug-FPN 的結(jié)構(gòu)如圖2 所示,BiFPN[15]在每個(gè)層級(jí)添加殘差連接進(jìn)行反復(fù)堆疊融合特征。CE-FPN[17]實(shí)現(xiàn)了通道增強(qiáng)和上采樣的亞像素跳躍融合方法,減少了由于通道縮減而造成的信息丟失。Aug-FPN[18]通過(guò)一致監(jiān)督縮小特征融合前不同尺度特征之間的語(yǔ)義差距,減少了金字塔最高層特征圖的信息損失。上述通過(guò)反復(fù)自上而下和自下而上的特征融合結(jié)構(gòu)來(lái)提高檢測(cè)精度,但這樣的結(jié)構(gòu)增加了計(jì)算復(fù)雜度,損失了檢測(cè)速度。

圖2 BiFPN、CE-FPN以及Aug-FPN的網(wǎng)絡(luò)結(jié)構(gòu)圖Fig.2 Network structure diagram of BiFPN,CE-FPN and Aug-FPN
本文在改進(jìn)FPN 的同時(shí),還使用深度可分離卷積(depthwise separable convolution)模塊代替主干特征提取網(wǎng)絡(luò)中的基礎(chǔ)卷積結(jié)構(gòu),深度可分離卷積由逐通道卷積(depthwise convolution,DW)和逐點(diǎn)卷積(pointwise convolution,PW)兩部分組成。DW 是一個(gè)卷積核對(duì)應(yīng)特征圖的一個(gè)通道,一個(gè)通道只被一個(gè)卷積核卷積,生成的特征圖通道數(shù)和輸入通道數(shù)一樣。PW 與常規(guī)卷積運(yùn)算類似,卷積核尺寸為1×1×C×N,C為上一層的通道數(shù),N為新特征圖通道數(shù)。因此,在計(jì)算量相同的情況下,Depthwise Separable Convolution 可以將神經(jīng)網(wǎng)絡(luò)層數(shù)做得更深,在實(shí)際工業(yè)應(yīng)用中能輕量化網(wǎng)絡(luò)模型,降低深度學(xué)習(xí)模型對(duì)硬件的要求。
注意力機(jī)制是認(rèn)知科學(xué)領(lǐng)域的學(xué)者發(fā)現(xiàn)人類處理信息時(shí)采用的機(jī)制,后來(lái)把這種機(jī)制引入到卷積神經(jīng)網(wǎng)絡(luò)[25]。SENet(squeeze-and-excitation networks)[26]通過(guò)Squeeze 和Excitation 兩個(gè)模塊得到特征通道的注意力權(quán)值,完成通道特征重標(biāo)定。CBAM(convolutional block attention module)[27]在SENet 的 基礎(chǔ)上使用GAP(global average pooling)和GMP(global max pooling)兩個(gè)池化進(jìn)行Squeeze操作,更充分地提取通道特征。之后,有學(xué)者提出Dual Attention Network[28]、Selfcalibrated Convolutions[29]和Strip pooling[30]等。2021年,周勇等人[31]提出了弱語(yǔ)義注意力的遙感圖像可解釋目標(biāo)檢測(cè),利用弱語(yǔ)義分割網(wǎng)絡(luò)產(chǎn)生強(qiáng)化目標(biāo)特征的注意力權(quán)重值,抑制背景噪聲。2022 年,李飛等人[32]提出了混合域注意力YOLOv4 的輸送帶縱向撕裂多維度檢測(cè),改進(jìn)了輕量級(jí)網(wǎng)絡(luò)MobileNetv3 的特征提取性能。2022年,王玲敏等人[33]提出了一種改進(jìn)YOLOv5的安全帽佩戴檢測(cè)方法,該算法在YOLOv5的主干網(wǎng)絡(luò)中添加CA 注意力機(jī)制,將位置信息嵌入到通道注意力當(dāng)中,使網(wǎng)絡(luò)可以在更大區(qū)域上進(jìn)行注意。本文算法是在CA[22]注意力基礎(chǔ)上提出了TDCA 注意力算法,在CA 的基礎(chǔ)上捕獲了通道感知注意力特征,提高了注意力的信息融合。
2 本文算法
2.1 網(wǎng)絡(luò)整體結(jié)構(gòu)
本文以YOLOX-S 為基礎(chǔ)網(wǎng)絡(luò)提出了改進(jìn)網(wǎng)絡(luò)YOLO-T,使用TPA-FPN(TDCA path aggregation feature pyramid networks)和TDCA 改進(jìn)了網(wǎng)絡(luò)的Neck 部分來(lái)提高網(wǎng)絡(luò)的回歸精度和收斂速度,使用Depthwise Separable Conv 模塊改進(jìn)Backbone 中的卷積結(jié)構(gòu)來(lái)降低網(wǎng)絡(luò)模型的復(fù)雜度,網(wǎng)絡(luò)模型結(jié)構(gòu)如圖3 所示。YOLO-T 在特征融合部分利用Backbone 中不同位置的3個(gè)特征層,分別位于中間層、中下層、底層。中間層保留了較多的淺層特征信息(如輪廓、紋理和顏色等)。中下層保留了一些屬性特征(如某一時(shí)刻目標(biāo)的狀態(tài))。底層則保留了高級(jí)語(yǔ)義信息,高層語(yǔ)義性越強(qiáng),模型的分辨能力也越強(qiáng),但高層語(yǔ)義信息容易丟失小目標(biāo)特征。當(dāng)網(wǎng)絡(luò)輸入大小為640×640 的3通道RGB 圖像時(shí),經(jīng)實(shí)驗(yàn)得出用于特征融合的中間層feat1=(80,80,256)、中下層feat2=(40,40,512)和底層feat3=(20,20,1 024)在保持計(jì)算量的情況下效果最好。在feat1、feat2和feat3特征層輸入Neck部分之前使用TDCA 注意力機(jī)制完成特征重標(biāo)定。Neck 部分采用TPA-FPN,Head部分沿用YOLOX-S的解耦頭結(jié)構(gòu)。
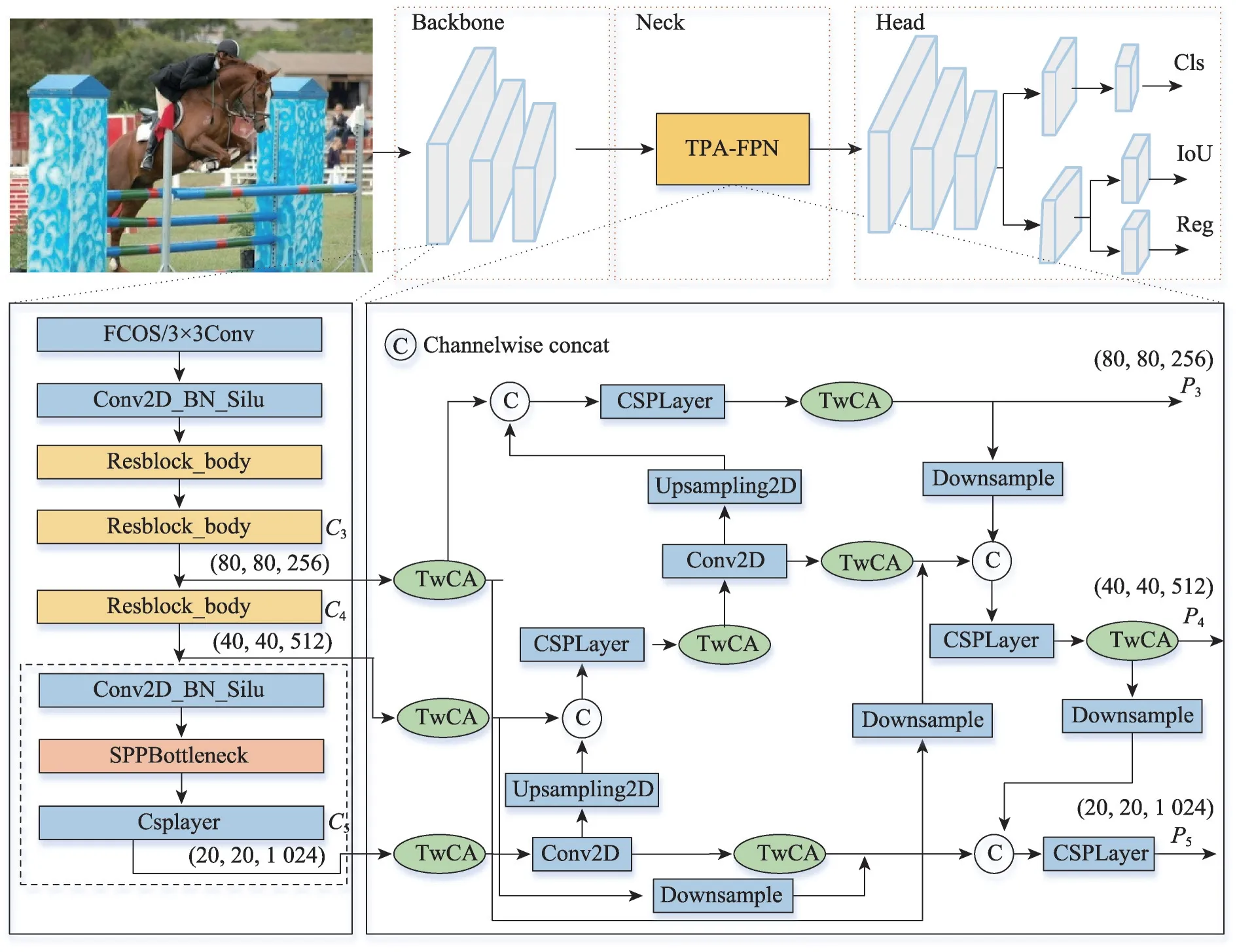
圖3 YOLO-T網(wǎng)絡(luò)結(jié)構(gòu)Fig.3 YOLO-T network structure
2.2 三維坐標(biāo)注意力(TDCA)
注意力機(jī)制通過(guò)權(quán)重重標(biāo)定,給特征圖中的信息賦予不同的權(quán)重,達(dá)到加強(qiáng)有用信息、抑制無(wú)用信息的目的。Hou等人[22]通過(guò)在X和Y兩個(gè)方向上聚合特征的信息,提出了一種為輕量級(jí)網(wǎng)絡(luò)設(shè)計(jì)的協(xié)調(diào)注意力機(jī)制(coordinate attention,CA),CA 模型的加入可以有效提高模型的收斂速度和監(jiān)測(cè)精度。事實(shí)上,在深度卷積神經(jīng)網(wǎng)絡(luò)中,特征圖不僅有X和Y兩個(gè)方向的空間信息,還存在通道Z方向的通道信息,而CA 注意力機(jī)制忽略了Z方向的通道信息。對(duì)于特征圖數(shù)據(jù),分別利用不同的卷積模塊學(xué)習(xí)不同方向的信息權(quán)重,然后通過(guò)可學(xué)習(xí)的加權(quán)融合方式獲取輸入特征圖的權(quán)重,也以此進(jìn)行X、Y和Z方向的信息交流,充分利用X、Y方向的空間信息和Z方向的通道信息,稱為三維坐標(biāo)注意力(TDCA),結(jié)構(gòu)如圖4所示。
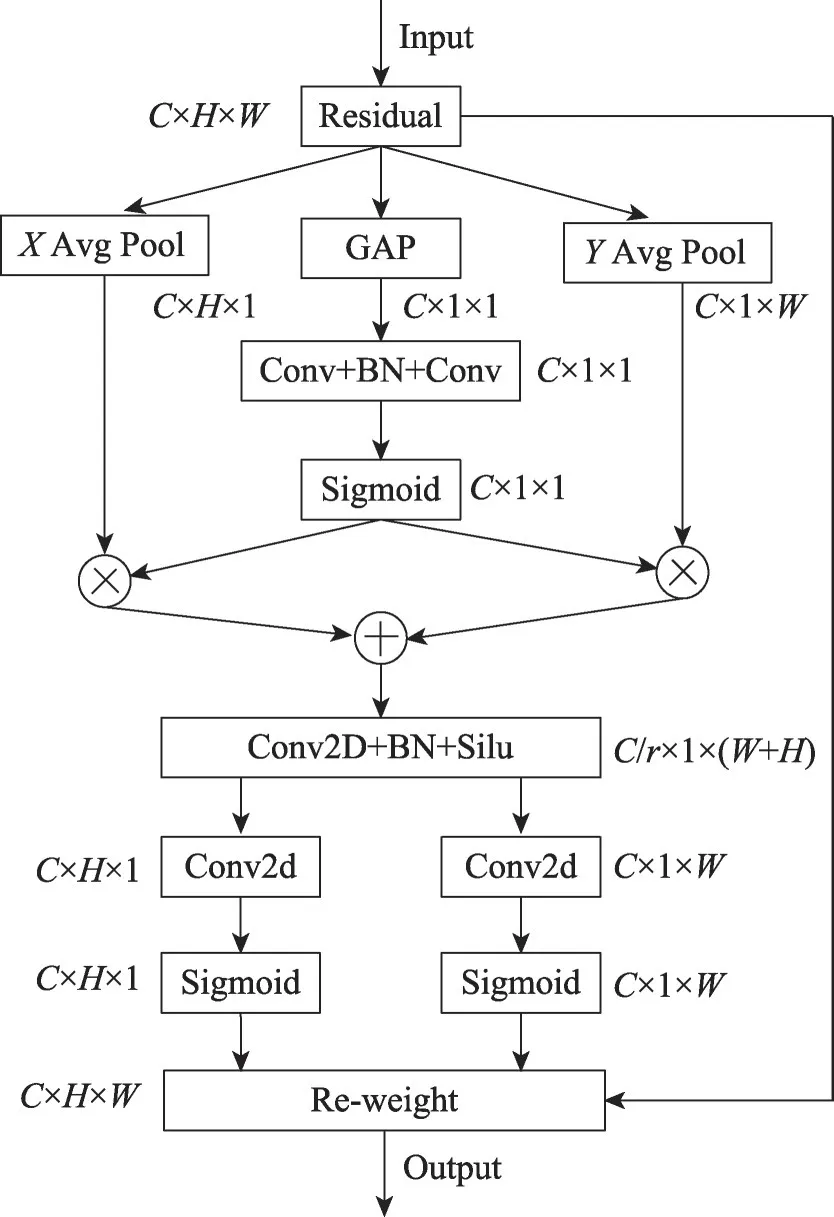
圖4 三維坐標(biāo)注意力TDCAFig.4 3D coordinate attention TDCA
在結(jié)構(gòu)中對(duì)于輸入特征圖F∈R C×H×W,X、Y和Z方向的注意力模塊計(jì)算公式如下所示:
經(jīng)過(guò)X、Y和Z方向的權(quán)重特征提取后,將Z方向的特征分別與X和Y方向的特征融合,公式如下所示:
式中,ZX∈RC×H×1和ZY∈RC×1×W是X與Z方向,Y與Z方向的通道權(quán)重重標(biāo)定,將ZX轉(zhuǎn)置與ZY沿Y方向進(jìn)行Concat,Z∈RC/r×1×(W+H)為ZX和ZY結(jié)合后的結(jié)果特征圖,其中r為通道的系數(shù),取0.5,降低通道數(shù)以減少計(jì)算量。BaseConv2 表示卷積的基本單元,包含卷積層、BN 層和Silu 激活函數(shù)。將Z分割成ZX′和ZY′,分別對(duì)它們進(jìn)行卷積和激活操作,可表示為:
fconv2d為1×1 卷積為恢復(fù)縮放的通道數(shù)操作,最后將得到的兩個(gè)空間解碼權(quán)重圖與輸入特征進(jìn)行點(diǎn)乘,完成特征權(quán)重重標(biāo)定,TDCA輸出公式如下所示:
Fout∈RC×H×W為TDCA 網(wǎng)絡(luò)結(jié)構(gòu)的輸出。通過(guò)X和Y方向捕獲方向感知和位置感知信息,利用Z方向捕獲跨通道信息,使模型更加精準(zhǔn)地定位和識(shí)別感興趣的目標(biāo),能夠更加有針對(duì)性地提取圖像特征,提升圖像識(shí)別效果。表1 是從對(duì)比實(shí)驗(yàn)角度證明TDCA網(wǎng)絡(luò)結(jié)構(gòu)的有效性。
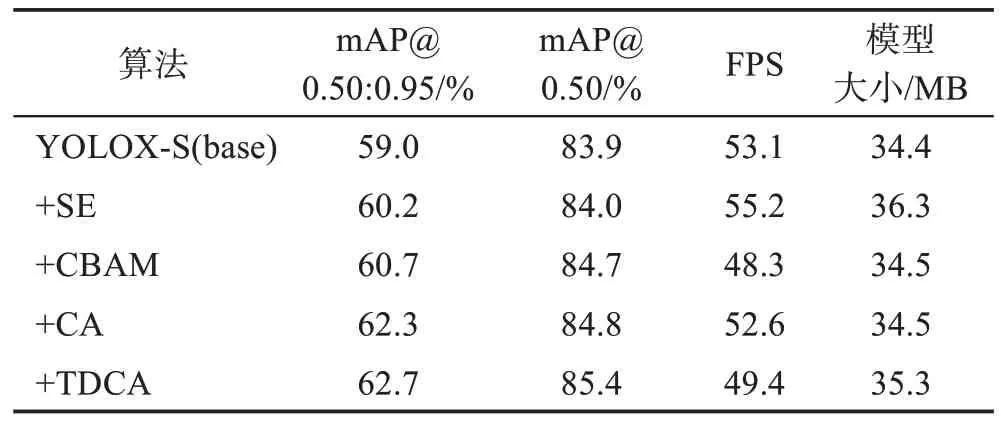
表1 各種注意力機(jī)制與TDCA在YOLOX-S下對(duì)比Table 1 Comparison of various attention mechanisms and TDCA in YOLOX-S
表1 為YOLOX-S 與加入SE、CBAM、CA 以及TDCA 注意力模塊后在PASCAL VOC2007+2012 數(shù)據(jù)集上訓(xùn)練測(cè)試的精度對(duì)比。從表1中可以看出,加入注意力機(jī)制后普遍能夠提升網(wǎng)絡(luò)的精度,而在加入TDCA 后,在mAP@0.50:0.95 指標(biāo)上比最優(yōu)的CA機(jī)制提高了0.4 個(gè)百分點(diǎn),比YOLOX-S 算法提高了3.7 個(gè)百分點(diǎn)。在mAP@0.50 指標(biāo)上,TDCA 相較于最優(yōu)的CA 機(jī)制提高了0.6 個(gè)百分點(diǎn),相比原始算法提高了1.5 個(gè)百分點(diǎn)。對(duì)算法成本進(jìn)行分析,從表1中可以看出,TDCA 與基礎(chǔ)網(wǎng)絡(luò)YOLOX-S 相比檢測(cè)速度和模型大小有所增加,但是與其他注意力機(jī)制相比都相差不大。因此,從3個(gè)方向提取特征注意力信息是對(duì)CA模塊有效的改進(jìn)方向。
相比此前的輕量級(jí)網(wǎng)絡(luò)上的注意力方法,TDCA存在以下優(yōu)勢(shì):首先,它不僅能捕獲跨通道的信息,還能捕獲方向感知和位置感知的信息,這能使模型更加精準(zhǔn)地定位和識(shí)別感興趣的目標(biāo);其次,TDCA靈活且輕量,可以很容易地插入經(jīng)典模塊,如Mobile-NeXt[34]提出的sandglass block;最后,作為一個(gè)預(yù)訓(xùn)練模型,TDCA可以在輕量級(jí)網(wǎng)絡(luò)的基礎(chǔ)上給下游任務(wù)帶來(lái)增益,特別是那些存在密集預(yù)測(cè)的任務(wù)。
2.3 TPA-FPN網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計(jì)
FPN 自頂而下的融合方式極大地利用了高低層特征語(yǔ)義信息,從而提高了特征的表達(dá)能力。因此,基于FPN 的改進(jìn)算法常在融合方式上進(jìn)行創(chuàng)新,例如PANet 網(wǎng)絡(luò)[14]從自頂向下再?gòu)淖缘紫蛏先诤戏绞教岣咛卣魅诤夏芰Γ珺iFPN[15]網(wǎng)絡(luò)利用反復(fù)堆疊的方式進(jìn)行特征融合。上述兩種融合方式能有效地保證特征之間的信息交流,但是特征內(nèi)的信息重要程度卻被忽略了。此外,特征融合過(guò)程中的自頂而下和自底向上的融合方式會(huì)使特征內(nèi)的語(yǔ)義信息被稀釋,從而會(huì)損失特征圖內(nèi)部的一些較重要的信息。本文提出了TPA-FPN 網(wǎng)絡(luò)結(jié)構(gòu),如圖5 所示,在PAFPN 特征融合網(wǎng)絡(luò)中采用shortcut 連接方式進(jìn)行跨層特征融合,保留其淺層語(yǔ)義信息。但是,融合了跨層特征的特征圖信息存在冗余,于是在PAFPN 網(wǎng)絡(luò)結(jié)構(gòu)中加入TDCA網(wǎng)絡(luò)結(jié)構(gòu),對(duì)特征內(nèi)的重要信息進(jìn)行X、Y和Z方向的加權(quán),TDCA 網(wǎng)絡(luò)結(jié)構(gòu)通過(guò)給特征賦予權(quán)重來(lái)保留有效信息和去除冗余信息。
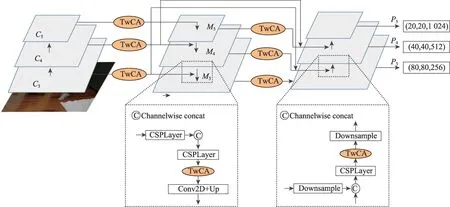
圖5 TPA-FPN網(wǎng)絡(luò)結(jié)構(gòu)Fig.5 TPA-FPN network structure
主干網(wǎng)絡(luò)不同階段的特征圖對(duì)應(yīng)的感受野不同,它們表達(dá)的信息抽象程度也不一樣,在Backbone網(wǎng)絡(luò)中抽取特征豐富的C3、C4、C5三層做特征融合,C3、C4、C5除了在自頂向下過(guò)程中與鄰層特征融合之外,還通過(guò)短連接(shortcut)進(jìn)行跨層級(jí)特征融合,將保留的淺層信息傳遞到間隔層。但以這種方式做信息融合,容易產(chǎn)生信息冗余。解決方法是在特征融合之前以及在自頂向下和自底向上特征融合過(guò)程中,加入TDCA 三維坐標(biāo)注意力網(wǎng)絡(luò),通過(guò)注意力調(diào)節(jié)特征信息的重要程度,提高特征的信息表達(dá)能力,從而保留有用信息和去除冗余信息。最后特征融合網(wǎng)絡(luò)TPA-FPN 輸出尺度大小為80×80×256、40×40×512、20×20×1 024 的特征層P3、P4、P5,作為目標(biāo)檢測(cè)網(wǎng)絡(luò)中分類和回歸特征的依據(jù)。
在TPA-FPN 特征融合網(wǎng)絡(luò)中,不同特征層之間自上向下融合需要對(duì)尺寸較小的特征進(jìn)行上采樣,自下向上的特征融合過(guò)程中需要對(duì)尺寸大的特征進(jìn)行下采樣,本文使用的上采樣方法為雙線性插值法,下采樣方法為普通卷積操作,將下采樣或上采樣后的特征圖與底層特征或高層特征進(jìn)行concat連接。
表2 為在PASCAL VOC2007+2012 數(shù)據(jù)集上訓(xùn)練測(cè)試的精度對(duì)比結(jié)果。以YOLOX-S 網(wǎng)絡(luò)結(jié)構(gòu)為基礎(chǔ),在Neck 部分分別使用FPN、PAFPN 和TPAFPN 作為算法1、算法2 和算法3。在算法3 的基礎(chǔ)上,將主干網(wǎng)絡(luò)結(jié)構(gòu)中的卷積結(jié)構(gòu)替換成Depthwise Separable Conv 模塊降低網(wǎng)絡(luò)模型的復(fù)雜度,作為對(duì)比算法4。
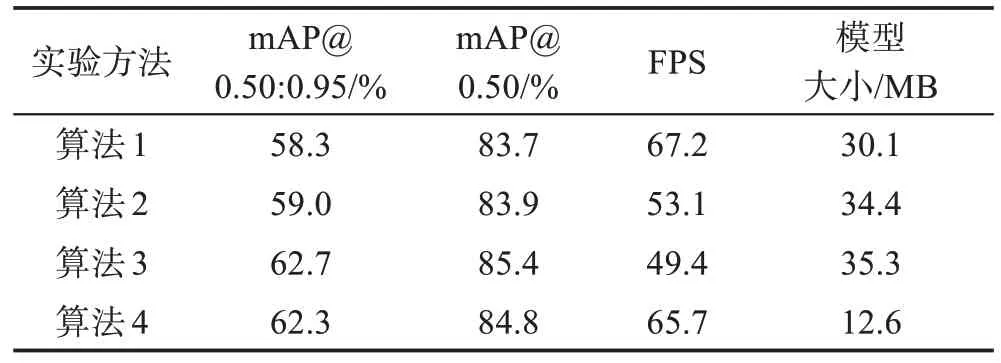
表2 FPN、PAFPN和TPA-FPN在YOLOX-S下對(duì)比Table 2 Comparison of FPN,PAFPN and TPA-FPN in YOLOX-S
由表2 可知,算法3 中的TPA-FPN 在推理速度上略低于FPN 和PAFPN,但在高交并比要求下TPAFPN 比PAFPN 的mAP@0.50:0.95 指標(biāo)提升了3.7 個(gè)百分點(diǎn),mAP@0.50 指標(biāo)提升了1.5 個(gè)百分點(diǎn)。表明跨層級(jí)特征融合和利用TDCA 網(wǎng)絡(luò)結(jié)構(gòu)保留有效信息和去除冗余信息能提高網(wǎng)絡(luò)對(duì)邊界框的回歸精度。算法4使用了Depthwise Separable Conv模塊,雖然在準(zhǔn)確率上有所降低,但能有效地對(duì)網(wǎng)絡(luò)進(jìn)行輕量化,模型大小減少了64.3%,由檢測(cè)速度(FPS)指標(biāo)可知,模型檢測(cè)速度提升了33.0%。模型大小的降低和檢測(cè)速度(FPS)的提升能有效減少在實(shí)際應(yīng)用場(chǎng)景下模型對(duì)硬件的要求。參數(shù)量的降低能有效減少在實(shí)際應(yīng)用場(chǎng)景下模型對(duì)硬件的要求。通過(guò)TPAFPN 結(jié)構(gòu)使特征金字塔網(wǎng)絡(luò)能更好地融合各層語(yǔ)義信息,可以更好地回歸目標(biāo)邊界框,契合高交并比下的工業(yè)目標(biāo)檢測(cè)任務(wù)。
2.4 標(biāo)簽分配策略與損失函數(shù)
目標(biāo)檢測(cè)中預(yù)測(cè)定位的過(guò)程是模型開始訓(xùn)練時(shí)先在圖像的每個(gè)位置生成一系列錨框,網(wǎng)絡(luò)結(jié)構(gòu)按照一定的規(guī)則將錨框分成正負(fù)樣本,但由于圖像中目標(biāo)的數(shù)量有限,這樣生成的錨框大部分都是背景,導(dǎo)致模型訓(xùn)練樣本不均衡。因此,在正負(fù)樣本標(biāo)簽分配策略中,本文沿用YOLOX-S中更精準(zhǔn)的SimOTA采樣策略,但在cost代價(jià)函數(shù)中,本文使用了soft-QFL作為cost 代價(jià)損失和分類損失。考慮到one-hot 標(biāo)簽中0 和1 的絕對(duì)情況下,本文的soft-QFL 分為兩種情況:(1)half soft-QFL將正類別中的1使用IOU的值代替,其他類別的值使用0;(2)soft-QFL 在正類別中的1使用IOU的值代替的情況下,其他類別的值使用(1-IOU(gt,anchor))/C,結(jié)構(gòu)如圖6 所示。在原基礎(chǔ)網(wǎng)絡(luò)中回歸損失函數(shù)使用的是IOULoss,本文針對(duì)IOU 存在當(dāng)錨點(diǎn)與真實(shí)框沒(méi)有相交時(shí),不能反映兩者的距離關(guān)系,使用GIOULoss 作為網(wǎng)絡(luò)的回歸損失。上述改進(jìn)目的是通過(guò)在目標(biāo)區(qū)域采集高質(zhì)量的樣本來(lái)有效地加速模型收斂,從而改善目標(biāo)正負(fù)樣本標(biāo)簽分配不均衡的問(wèn)題。改進(jìn)的SimOTA 采樣策略如式(8)所示,其中ai的值作為樣本的標(biāo)簽,ai的值越大表示此錨點(diǎn)更接近真實(shí)框。
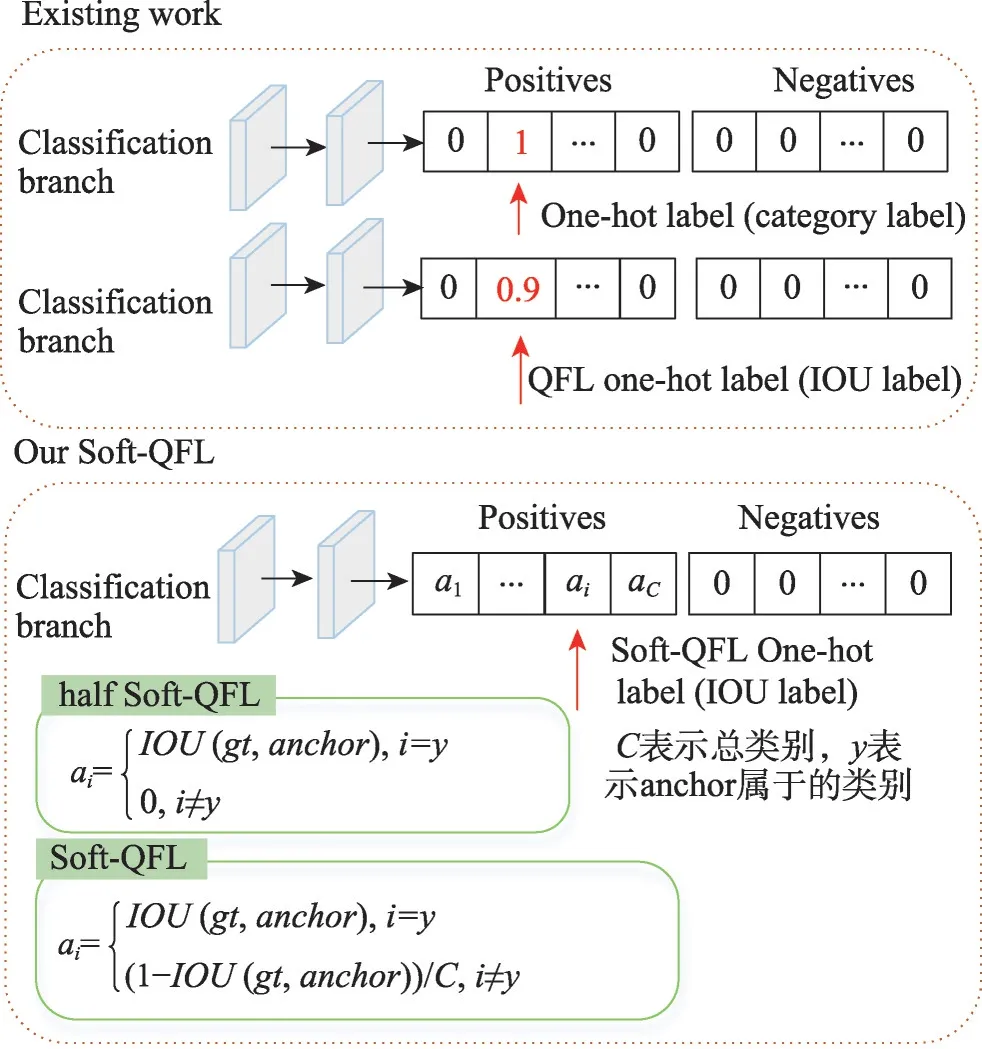
圖6 改進(jìn)的SimOTA采樣策略Fig.6 Improved SimOTA sampling strategy
IOU(gt,anchor)表示目標(biāo)真實(shí)框gt與生成的anchor錨點(diǎn)框之間的IOU 值,C表示總類別。在分類損失中,將one-hot 編碼中的1 替換為ai的值,0 替換為(1-IOU(gt,anchor))/C,這樣更能反映出錨點(diǎn)與真實(shí)樣本的關(guān)系,如式(9)所示:
式中,pi表示預(yù)測(cè)為第i類的概率,β為調(diào)節(jié)參數(shù),實(shí)驗(yàn)取值為2。當(dāng)anchor是難分的正樣本時(shí),ai的值偏低,1-ai的值偏高,而Lcls在逐漸降低的過(guò)程中,網(wǎng)絡(luò)就相當(dāng)于增加了難分正負(fù)樣本的loss權(quán)重,使得網(wǎng)絡(luò)在訓(xùn)練時(shí)不會(huì)花太多時(shí)間在易分的負(fù)樣本上,加快了模型收斂。
利用IOU 指導(dǎo)正負(fù)樣本標(biāo)簽的分配,再與分類置信度損失函數(shù)進(jìn)行聯(lián)合預(yù)測(cè),在速度無(wú)損的情況下能有效地改善正負(fù)樣本不均衡問(wèn)題。表3 中的消融實(shí)驗(yàn)為在PASCAL VOC2007+2012 數(shù)據(jù)集上的精度對(duì)比結(jié)果,基礎(chǔ)網(wǎng)絡(luò)采用YOLOX-S,“√”代表引入模塊,實(shí)驗(yàn)環(huán)境參數(shù)以及網(wǎng)絡(luò)超參數(shù)設(shè)置如3.1 節(jié)所示。
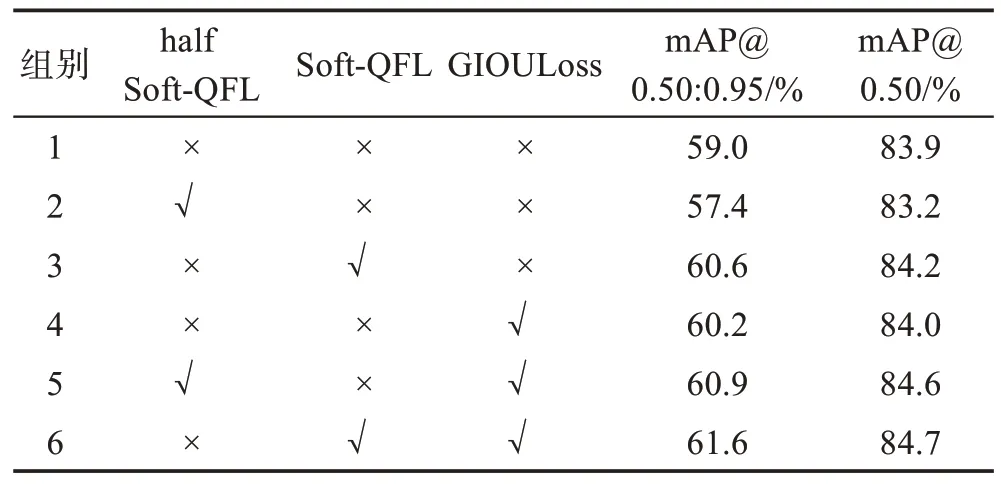
表3 標(biāo)簽分配策略與損失函數(shù)的mAP對(duì)比Table 3 Comparison of mAP of label allocation strategy and loss function
在表3 中對(duì)比1、2 組實(shí)驗(yàn)發(fā)現(xiàn),使用half Soft-QFL 進(jìn)行改進(jìn)的模型在mAP@0.50:0.95 和mAP@0.50 的指標(biāo)上有所下降,而通過(guò)對(duì)比1、2、3 組實(shí)驗(yàn)可以看出,Soft-QFL 的表現(xiàn)比half Soft-QFL 在mAP@0.50:0.95 指標(biāo)上提高了3.2 個(gè)百分點(diǎn),在mAP@0.50指標(biāo)上提高了1.0個(gè)百分點(diǎn)。分析half Soft-QFL可能是使用IOU 指標(biāo)作為正類別的標(biāo)簽反而削弱了損失函數(shù)的表現(xiàn),Soft-QFL 則是在改變正類別時(shí),對(duì)負(fù)類別也進(jìn)行了改進(jìn),并同時(shí)作用于損失函數(shù),從而使模型表現(xiàn)出良好的效果。對(duì)比1、4 組實(shí)驗(yàn),GIOULoss在mAP@0.50:0.95 指標(biāo)上比原算法提高了1.2 個(gè)百分點(diǎn),有一個(gè)較好的效果。通過(guò)5、6 組實(shí)驗(yàn)可以看出,soft-QFL+GIOULoss的表現(xiàn)效果最好。
從結(jié)構(gòu)上分析在基于錨框檢測(cè)的目標(biāo)檢測(cè)算法中,使用Soft-QFL 和GIOULoss聯(lián)合能有效改善網(wǎng)絡(luò)檢測(cè)精度,使網(wǎng)絡(luò)訓(xùn)練更穩(wěn)定,加速網(wǎng)絡(luò)訓(xùn)練收斂速度。
3 實(shí)驗(yàn)結(jié)果及分析
3.1 實(shí)驗(yàn)環(huán)境與參數(shù)設(shè)置
為了公平分析和評(píng)估本文提出的算法性能,實(shí)驗(yàn)測(cè)試環(huán)境配置如下:CPU 為Intel?Xeon?Gold 5218R CPU@2.10 GHz,64 GB 內(nèi) 存,Ubuntu16.04 操作系統(tǒng),2 張GeForce RTX3090 型號(hào)的顯卡。運(yùn)行環(huán)境配置如下:Python 版本為3.7,Pytorch 版本為1.9.0,CUDA 版本為10.2。網(wǎng)絡(luò)運(yùn)行的超參數(shù)設(shè)置如下:網(wǎng)絡(luò)訓(xùn)練分為凍結(jié)訓(xùn)練和解凍訓(xùn)練,凍結(jié)訓(xùn)練50 個(gè)epoch后再進(jìn)行解凍訓(xùn)練,凍結(jié)訓(xùn)練的batch-size設(shè)置為64,解凍訓(xùn)練的batch-size 設(shè)置為32,動(dòng)量參數(shù)為0.937,學(xué)習(xí)率初始值為0.01,最小值為0.000 1,隨著網(wǎng)絡(luò)的訓(xùn)練,學(xué)習(xí)率進(jìn)行余弦退火衰減,解凍階段訓(xùn)練300 個(gè)epoch,并使用Adam 優(yōu)化算法更新網(wǎng)絡(luò)權(quán)重。
超參數(shù)置信度閾值、NMS 閾值的作用是剔除每一類別中的重復(fù)預(yù)測(cè)框,其取值對(duì)模型性能有一定影響。通過(guò)非極大值抑制(NMS)算法,本文設(shè)計(jì)了一組超參數(shù)置信度閾值和NMS 閾值的靈敏度實(shí)驗(yàn)。根據(jù)NMS算法思想,置信度閾值和NMS閾值過(guò)大容易將正確的預(yù)測(cè)框剔除,過(guò)小不能達(dá)到去除重復(fù)框的效果。實(shí)驗(yàn)結(jié)果表示,在置信度閾值取值0.45,NMS閾值取值0.50時(shí),本文算法展現(xiàn)出較好的性能。
算法1非極大值抑制(NMS)算法
3.2 評(píng)價(jià)指標(biāo)
本實(shí)驗(yàn)的評(píng)價(jià)指標(biāo)使用平均檢測(cè)精度(mAP@0.50、mAP@0.50:0.95)和檢測(cè)速度(FPS)作為模型的衡量標(biāo)準(zhǔn),平均檢測(cè)精度能有效地評(píng)估模型的性能,包括識(shí)別準(zhǔn)確率、定位準(zhǔn)確率,檢測(cè)速度能有效地衡量模型的推理性能,是實(shí)際工業(yè)應(yīng)用中的重要指標(biāo)。其中,mAP@0.50 表示IOU 閾值為0.50 時(shí)的mAP;mAP@0.50:0.95 表示步長(zhǎng)為0.05 的IOU 閾值從0.50到0.95 的各個(gè)mAP 的平均值。mAP@0.50 主要體現(xiàn)目標(biāo)檢測(cè)模型的識(shí)別能力,mAP@0.50:0.95 由于IOU 最高取值達(dá)到了0.95,IOU 取值高主要體現(xiàn)目標(biāo)定位效果以及邊界框回歸能力。mAP 的值與模型的性能呈正相關(guān),F(xiàn)PS 表示每秒檢測(cè)圖像的數(shù)量,其值越大表示檢測(cè)速度越快。
mAP表示平均檢測(cè)精度即P-R曲線下方的面積,P-R 曲線是以準(zhǔn)確率(Precision)為縱軸,召回率(Recall)為橫軸的二維曲線。具體計(jì)算公式如式(10)~式(12):
式中,TP表示為真正例樣本數(shù);FP表示為假正例樣本數(shù);FN表示為假反例樣本數(shù)。Precision 表示預(yù)測(cè)樣本中的正樣本數(shù)占所有實(shí)際正樣本數(shù)的比例。Recall 表示預(yù)測(cè)樣本中的正樣本數(shù)占所有預(yù)測(cè)樣本的比例,Precision與Recall呈負(fù)相關(guān)。
3.3 PASCAL VOC2007+2012數(shù)據(jù)集對(duì)比實(shí)驗(yàn)
PASCAL VOC 數(shù)據(jù)集是計(jì)算機(jī)視覺(jué)挑戰(zhàn)賽公開的數(shù)據(jù)集,常被用來(lái)檢驗(yàn)?zāi)繕?biāo)檢測(cè)模型的性能。PASCAL VOC2007+2012 是兩個(gè)年份公開發(fā)布數(shù)據(jù)集的并集,此數(shù)據(jù)集更復(fù)雜,使用該數(shù)據(jù)集對(duì)模型性能進(jìn)行驗(yàn)證可增加數(shù)據(jù)量,同時(shí)也更具說(shuō)明性。該數(shù)據(jù)集包含20 類檢測(cè)目標(biāo),模型的訓(xùn)練集使用PASCAL VOC2007+2012 數(shù)據(jù)集中的train+val 部分,共16 551 張圖像,模型的測(cè)試集使用PASCAL VOC 2007數(shù)據(jù)集中的test部分,共4 952張圖像。
為了驗(yàn)證YOLO-T模型的性能,本實(shí)驗(yàn)將與以下算法做對(duì)比:(1)雙階段目標(biāo)檢測(cè)算法Faster R-CNN[35]、Mask R-CNN[4]和Cascade R-CNN[5];(2)高精度單階段算法RetinaNet[36]和以SSD[6]為基礎(chǔ)改進(jìn)的ASSD(attentive single shot multibox detector)[37]算法;(3)單階段無(wú)錨框算法FCOS(fully convolutional one-stage object detection)[38]和ATSS(adaptive training sample selection)[39]算法;(4)以YOLO系列為基礎(chǔ)的YOLOv3[20]算法以及改進(jìn)的輕量級(jí)算法YOLOv4-mobileNetv2[20]、YOLOv4-ghostNet[20]、YOLOv5-S[20]和YOLOX-S。與以上算法對(duì)比結(jié)果如表4所示。
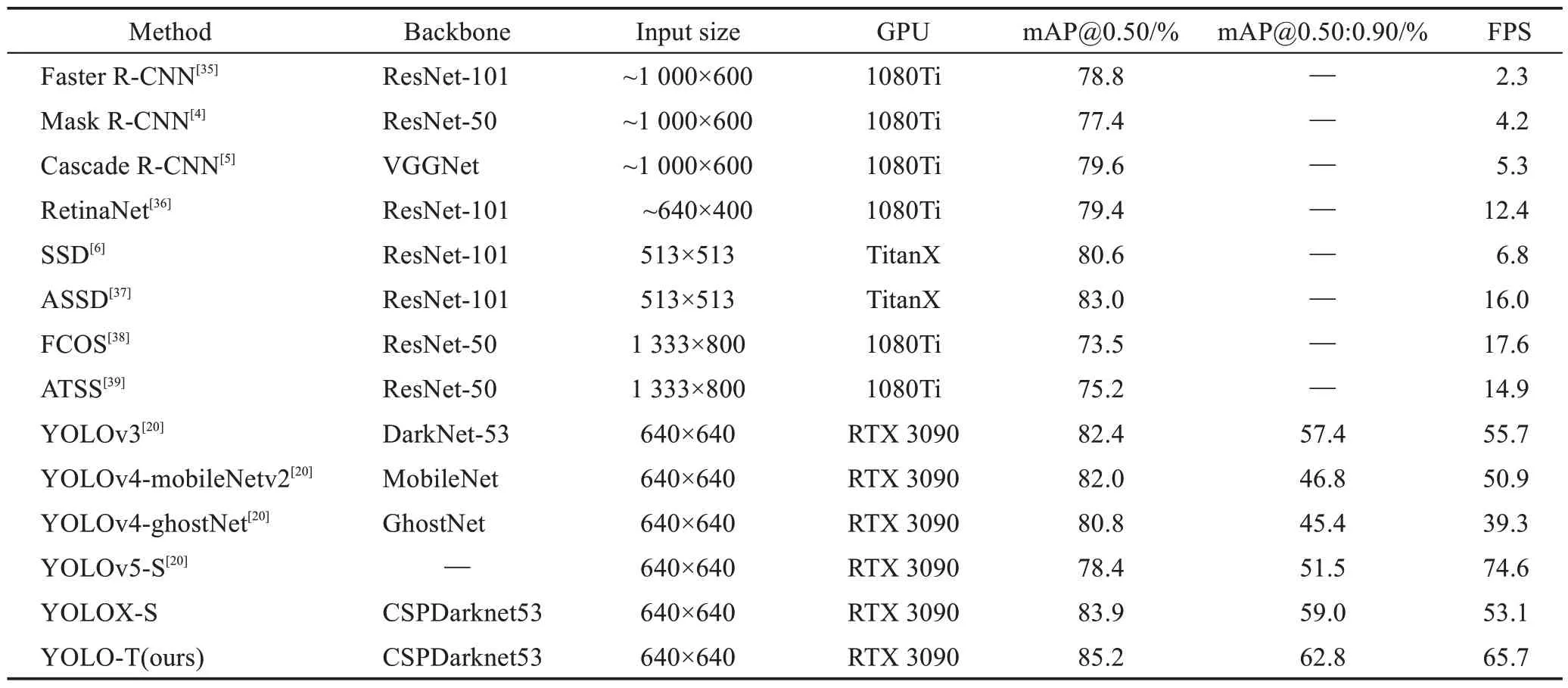
表4 PASCAL VOC2007測(cè)試集上各目標(biāo)檢測(cè)算法對(duì)比實(shí)驗(yàn)Table 4 Comparative experiment of each object detection algorithm on PASCAL VOC2007 test set
由表4 可知,本文提出的YOLO-T 在檢測(cè)精度上有著顯著優(yōu)勢(shì),在PASCAL VOC2007測(cè)試集上mAP@0.50 的精度達(dá)到了85.2%,相較于基礎(chǔ)網(wǎng)絡(luò)YOLOXS 提高了1.3 個(gè)百分點(diǎn),而能體現(xiàn)定位效果和邊界框回歸能力的mAP@0.50:0.90精度達(dá)到了62.8%,相較于基礎(chǔ)網(wǎng)絡(luò)YOLOX-S 提高了3.8 個(gè)百分點(diǎn),說(shuō)明YOLO-T網(wǎng)絡(luò)結(jié)構(gòu)能有效提高預(yù)測(cè)定位的檢測(cè)精度;與雙階段檢測(cè)器相比,mAP@0.50 提高了5.6~7.8 個(gè)百分點(diǎn);與單階段經(jīng)典算法SSD 以及基于SSD 改進(jìn)的ASSD 算法相比有4.6 個(gè)百分點(diǎn)和2.2 個(gè)百分點(diǎn)的提升;與高精度RetinaNet 算法以及單階段無(wú)錨框的FCOS 和ATSS 算法相比,YOLO-T 網(wǎng)絡(luò)結(jié)構(gòu)更展現(xiàn)了其優(yōu)勢(shì),檢測(cè)精度都有大幅度提升;相比于有相同baseline 的輕量化網(wǎng)絡(luò)YOLOv4-mobileNetv2、YOLOv4-ghostNet、YOLOv5-S 和YOLOX-S,雖然檢測(cè)速度不如基礎(chǔ)網(wǎng)絡(luò)YOLOX-S,但是檢測(cè)精度上有著明顯的優(yōu)勢(shì)。總體來(lái)看,在檢測(cè)精度和檢測(cè)速度兼具的條件下,YOLO-T在眾多模型中的表現(xiàn)更加出色。
由于超參數(shù)置信度閾值和NMS閾值的取值對(duì)模型性能有一定影響,本文設(shè)計(jì)了一組超參數(shù)的靈敏度實(shí)驗(yàn)。根據(jù)非極大值抑制(NMS)算法,選取了9組數(shù)據(jù)對(duì)模型的性能進(jìn)行測(cè)試。在取值的過(guò)程中,閾值過(guò)大容易將正確的預(yù)測(cè)框剔除,過(guò)小不能達(dá)到去除重復(fù)框的效果。因此,本文的置信度閾值從0.40到0.50 以0.05 為步長(zhǎng)遞增,NMS 閾值從0.30 到0.50以0.1為步長(zhǎng)遞增,實(shí)驗(yàn)結(jié)果如表5所示。
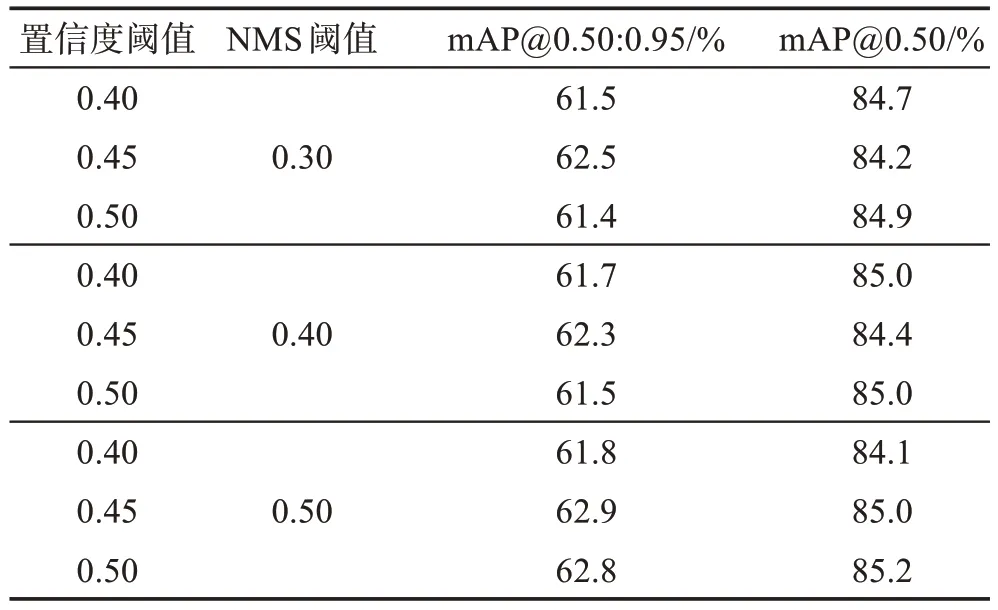
表5 超參數(shù)置信度閾值、NMS閾值的實(shí)驗(yàn)結(jié)果Table 5 Experimental results of hyperparameter confidence threshold and NMS threshold
根據(jù)表5的實(shí)驗(yàn)結(jié)果,不同的超參數(shù)置信度閾值和NMS閾值對(duì)模型性能有一定影響。當(dāng)置信度閾值取0.45,NMS 閾值取0.50 時(shí),模型的mAP@0.50:0.95指標(biāo)最高;當(dāng)置信度閾值取0.50,NMS 閾值取0.50時(shí),模型的mAP@0.50 指標(biāo)最高。綜上實(shí)驗(yàn)結(jié)果,實(shí)驗(yàn)中測(cè)試的超參數(shù)置信度閾值設(shè)為0.45,NMS 閾值為0.50。
本文還對(duì)VOC數(shù)據(jù)集的場(chǎng)景圖像進(jìn)行定性評(píng)價(jià)分析,效果如圖7 所示。圖7 中(a)和(b)為經(jīng)過(guò)CA注意力和TDCA注意力處理后的加權(quán)熱力圖,圖7(a)中從左到右預(yù)測(cè)框與真實(shí)框的IOU 值分別為0.55、0.69 和0.53,圖7(b)中從左到右預(yù)測(cè)框與真實(shí)框的IOU 值分別為0.79、0.99 和0.78。從圖中可以看出,和CA 注意力機(jī)制相比,加入TDCA 后,網(wǎng)絡(luò)對(duì)檢測(cè)目標(biāo)區(qū)域的定位和關(guān)注程度都獲得了提升,證明在Neck部分加入TDCA能更好地融合關(guān)鍵特征信息。

圖7 注意力機(jī)制CA與TDCA的熱力圖對(duì)比Fig.7 Heat map comparison of attention mechanism CA and TDCA
第1 組實(shí)驗(yàn)對(duì)cat 進(jìn)行檢測(cè),目標(biāo)cat 由于衣物的遮擋,將身體和頭部分開了,此時(shí)圖7(a)檢測(cè)器出現(xiàn)定位不準(zhǔn)確,只檢測(cè)到了頭部以下的部分,而圖7(b)檢測(cè)定位較圖7(a)準(zhǔn)確,IOU 提高了0.24。從熱力圖中也可看出,TDCA比CA更能關(guān)注到目標(biāo)的特征。第2 組實(shí)驗(yàn)中兩個(gè)目標(biāo)較聚集,從對(duì)比圖來(lái)看,圖7(b)的模型對(duì)左側(cè)的目標(biāo)定位比圖7(a)模型準(zhǔn)確,IOU提高了0.3。第3組實(shí)驗(yàn)對(duì)較明顯的大目標(biāo)aircraft進(jìn)行檢測(cè),圖7(b)模型定位性能表現(xiàn)得比圖7(a)好,IOU 提高了0.25,但是在小目標(biāo)person 的檢測(cè)上,YOLO-T模型檢測(cè)效果略遜色。但總體來(lái)說(shuō),YOLO-T在目標(biāo)定位上要優(yōu)于基礎(chǔ)網(wǎng)絡(luò),平均IOU 提高了26%,證明網(wǎng)絡(luò)提取到了更加豐富的語(yǔ)義信息,表現(xiàn)出更好的性能。YOLO-T 更適合于定位要求較高的現(xiàn)實(shí)場(chǎng)景。
3.4 消融實(shí)驗(yàn)
本文算法從TDCA、TPA-FPN 和Soft-QFL 三方面對(duì)YOLOX-S 進(jìn)行改進(jìn),為探究各改進(jìn)方法的有效性,在基線網(wǎng)絡(luò)YOLOX-S 的基礎(chǔ)上設(shè)計(jì)了4 組消融實(shí)驗(yàn),實(shí)驗(yàn)數(shù)據(jù)集使用3.3 節(jié)的PASCAL VOC2007+2012 數(shù)據(jù)集,每組實(shí)驗(yàn)所采用的實(shí)驗(yàn)環(huán)境、網(wǎng)絡(luò)超參數(shù)以及訓(xùn)練技巧均相同,實(shí)驗(yàn)結(jié)果如表6 所示。其中,TPA-FPN 代表所提Neck 結(jié)構(gòu),Depthwise Separable Conv 模塊代表修改主干特征提取網(wǎng)絡(luò)中的基礎(chǔ)卷積結(jié)構(gòu),Soft-QFL 代表提出的標(biāo)簽分配策略與損失函數(shù),由于TDCA 結(jié)構(gòu)是融入到TPA-FPN 結(jié)構(gòu)中的,不對(duì)TDCA模塊進(jìn)行消融實(shí)驗(yàn)。
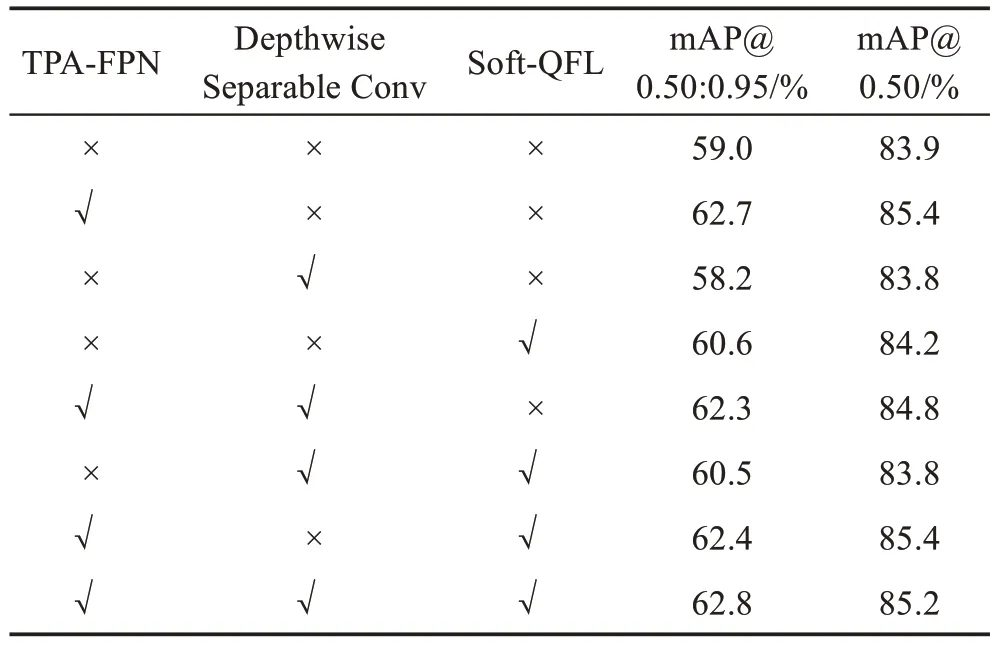
表6 各改進(jìn)模塊在YOLOX-S框架下的消融實(shí)驗(yàn)Table 6 Ablation experiment of each improved module under framework of YOLOX-S
由表6可知,以YOLOX-S為基礎(chǔ),加入TPA-FPN模塊后mAP@0.50:0.95 提升了3.7 個(gè)百分點(diǎn),mAP@0.50 提升了1.5 個(gè)百分點(diǎn),TPA-FPN 網(wǎng)絡(luò)結(jié)構(gòu)融入了TDCA注意力機(jī)制,mAP@0.50:0.95指標(biāo)的提高說(shuō)明模型對(duì)目標(biāo)預(yù)測(cè)框的回歸能力提高了,使預(yù)測(cè)的目標(biāo)框與真實(shí)目標(biāo)框更接近,這對(duì)需要更準(zhǔn)確定位的回歸任務(wù)來(lái)說(shuō),加入TPA-FPN 是非常有效的;其次,使用了Soft-QFL 改進(jìn)標(biāo)簽分配策略以及損失函數(shù),mAP@0.50:0.95 提升了1.6 個(gè)百分點(diǎn),mAP@0.50 提升了0.3 個(gè)百分點(diǎn)。Soft-QFL 通過(guò)改進(jìn)標(biāo)簽分配策略以及損失函數(shù)來(lái)提升網(wǎng)絡(luò)模型的識(shí)別能力,Soft-QFL 在幾乎不消耗網(wǎng)絡(luò)的訓(xùn)練和推理性能的基礎(chǔ)上,提高了網(wǎng)絡(luò)檢測(cè)精度。此外,由于網(wǎng)絡(luò)結(jié)構(gòu)引入了TPA-FPN 模塊,模型的復(fù)雜度增加,網(wǎng)絡(luò)檢測(cè)速度和模型參數(shù)量有所增大。
在YOLO-T 主干網(wǎng)絡(luò)中引入Depthwise Separable Conv 模塊代替普通卷積模塊,由表2 和表6 可知,引入深度可分離卷積模塊mAP@0.50:0.95 和mAP@0.50準(zhǔn)確率只降低了0.8個(gè)百分點(diǎn)和0.1個(gè)百分點(diǎn),但模型的參數(shù)量和網(wǎng)絡(luò)復(fù)雜度減少了64.3%。最終的YOLO-T 網(wǎng)絡(luò)模型達(dá)到了速度和檢測(cè)精度兩方的平衡,并且模型對(duì)目標(biāo)預(yù)測(cè)框的擬合能力進(jìn)一步增強(qiáng),在實(shí)際應(yīng)用中對(duì)硬件的要求更小,能被用于需要定位更加準(zhǔn)確的工業(yè)應(yīng)用場(chǎng)景中。
3.5 COCO數(shù)據(jù)集對(duì)比實(shí)驗(yàn)
為了進(jìn)一步評(píng)估YOLO-T 目標(biāo)檢測(cè)模型的精度和定位效果,本文在類型更多、圖像環(huán)境更加復(fù)雜的COCO 數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)。COCO 數(shù)據(jù)集是由微軟提供的大型目標(biāo)檢測(cè)數(shù)據(jù)集,具有數(shù)據(jù)類別多和目標(biāo)尺寸跨度大等特點(diǎn)。實(shí)驗(yàn)中將COCO2017 數(shù)據(jù)集中的訓(xùn)練集隨機(jī)劃分為包含105 539 張圖像的train和11 727 張圖像的val,并在包含5 000 張圖像的COCO2017 驗(yàn)證集上進(jìn)行測(cè)試。主要評(píng)估不同IOU閾值下的平均精度。其中,不同IOU 閾值下的平均精度可以體現(xiàn)模型的定位效果,高IOU 閾值代表預(yù)測(cè)框和真實(shí)框重合度的標(biāo)準(zhǔn)更加嚴(yán)格。實(shí)驗(yàn)數(shù)據(jù)中YOLOX-S 和YOLO-T 通過(guò)實(shí)驗(yàn)得到,實(shí)驗(yàn)環(huán)境和參數(shù)設(shè)置如3.1節(jié)所示。
如表7 所示,在COCO 數(shù)據(jù)集上,YOLO-T 的mAP@0.50:0.95 達(dá)到了42.0%,較原YOLOX-S 提高了2.4 個(gè)百分點(diǎn),mAP@0.50 提高了0.8 個(gè)百分點(diǎn),mAP@0.75提高了2.8個(gè)百分點(diǎn)。在不同的IOU閾值下,mAP@0.50:0.95 指標(biāo)漲點(diǎn)最多,這也說(shuō)明本文算法對(duì)預(yù)測(cè)框定位以及邊界框回歸能力有著明顯的優(yōu)勢(shì)。對(duì)比其他的檢測(cè)算法YOLOv5-S、YOLOv3、RefineDet 和FAENet,mAP@0.50:0.95 也有著顯著的提高,由此說(shuō)明YOLO-T在復(fù)雜場(chǎng)景下也具有較好的預(yù)測(cè)框定位效果和檢測(cè)性能。
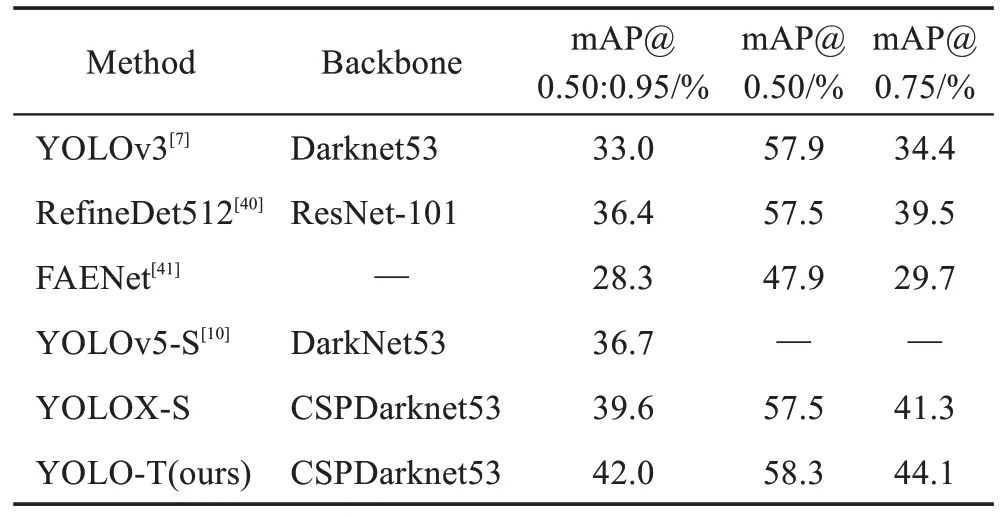
表7 COCO數(shù)據(jù)集上的對(duì)比實(shí)驗(yàn)Table 7 Comparative experiments on COCO dataset
4 結(jié)束語(yǔ)
本文基于YOLOX-S 網(wǎng)絡(luò)結(jié)構(gòu)提出了一種改進(jìn)的目標(biāo)檢測(cè)算法YOLO-T,目的是改進(jìn)YOLOX-S 算法對(duì)目標(biāo)預(yù)測(cè)框定位不準(zhǔn)確的問(wèn)題。采用TDCA、TPA-FPN 和Soft-QFL 結(jié)構(gòu)對(duì)網(wǎng)絡(luò)的精度和目標(biāo)框邊界的回歸能力進(jìn)行提升。使用Depthwise Separable Conv 改進(jìn)Backbone 中的卷積模塊使模型輕量化,平衡了檢測(cè)速度和檢測(cè)精度。在PASCAL VOC2007+2012 數(shù)據(jù)集上,YOLO-T 和YOLOX-S 相比,模型大小減少了64.3%,檢測(cè)速度提升了23.7%,mAP@0.50提高了1.3 個(gè)百分點(diǎn),mAP@0.50:0.95 提高了3.8 個(gè)百分點(diǎn)。因此YOLO-T是一種檢測(cè)精度較高、定位較準(zhǔn)確的目標(biāo)檢測(cè)模型,適用于對(duì)定位要求較高的現(xiàn)實(shí)場(chǎng)景。但YOLO-T 仍有改進(jìn)的空間,如Neck 部分可以再使用較低分辨率的特征圖,可以更好地對(duì)小目標(biāo)進(jìn)行檢測(cè)。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
