類別平衡調制的人臉表情識別
2023-12-08 11:49:18劉成廣王善敏劉青山
計算機與生活 2023年12期
關鍵詞:特征
劉成廣,王善敏,劉青山+
1.南京信息工程大學 計算機學院,南京 210044
2.南京信息工程大學 數字取證教育部工程研究中心,南京 210044
3.南京航空航天大學 計算機科學與技術學院,南京 211106
面部表情是人類傳達情感信息的最直接方式[1-2]。自動的人臉表情識別(facial expression recognition,FER)有著廣泛的應用,如人機交互[3]、心理健康問診[4]、疲勞駕駛檢測[5]等。近年來,由于大型數據集的出現,基于深度學習的表情識別技術取得了較大進展。然而,與實驗室環境下采集的數據集(例如CK+[6]、MMI[7]和JAFFE[8])相比,自然場景下采集的數據集存在明顯的類別不平衡問題[9-11]。圖1 展示了RAF-DB 數據集各類別樣本的分布和對應的識別精度。數據分布不平衡導致了模型對各類表情的識別精度差異較大。具體地,模型對樣本量大的類別識別精度較高,而對樣本量少的類別識別精度較低。
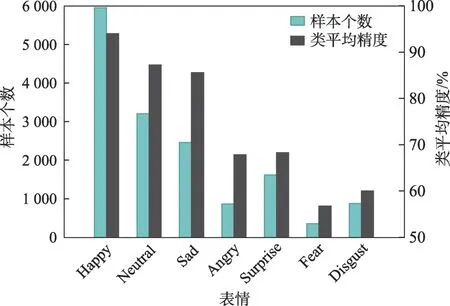
圖1 類別不平衡示例圖Fig.1 Example of class imbalance
為了解決類別不平衡問題,常用的方案通常統計數據集中各類別的樣本分布,對樣本進行重采樣(re-sampling)[12-15]或重加權(re-weighting)[16-20]。重采樣的方式通過數據增強對少樣本類別進行上采樣,或者對多樣本類別進行隨機刪除的下采樣。然而上采樣沒有給模型帶來更多實質性的信息,下采樣明顯減少了模型的訓練數據。因此,重采樣的方法沒有從本質上解決表情識別任務中樣本不平衡的問題。重加權的方法依據類別樣本數或樣本容量[21],對樣本反向加權,強化少樣本類別的學習[16-17]。但是,研究表明,圖像的特征分布和類別的標注分布是不耦合的[22-23],用類別的分布影響表征學習時的特征分布是不合適的。因此,將圖像表征學習和分類器優化過程聯合調制的重加權方法,不僅沒有平衡各類別的特征分布,而且會影響圖像表征的正常學習過程。
為此,本文將圖像表征學習和分類器優化過程分離,提出了一種新的類別平衡調制的人臉表情識別方法(class-balanced modulation mechanism for facial expression recognition,CBM-Net),以解決數據不平衡導致的特征分布不平衡和分類器優化不平衡問題。具體地,分別設計了特征調制和梯度調制兩個模塊。特征調制模塊通過增加類間的方向可分性,進而確保模型可以提取出小類樣本的區分性特征,使得不同類別在特征分布上保持平衡。梯度調制模塊利用每批次訓練樣本的統計信息來調節各類別分類器的梯度,使得樣本數較少的類獲得更多優化,獲得足夠的訓練嘗試,而不影響其他的類。為了驗證該方法的有效性,本文在RAF-DB[9]、AffectNet[10]、SFEW[24]和CAER-S[25]四個流行的數據集上進行了實驗。定性和定量結果都證明了CBM-Net在解決類別分布不平衡問題上的合理性和優越性。
本文工作的主要貢獻總結如下:
(1)提出了一種類別平衡調制的人臉表情識別方法,該方法從特征調制和分類器梯度調制兩方面解決類別不平衡問題。
(2)設計了一個特征調制模塊來保證特征間的類別可分性,進而解決類別不平衡導致的表情特征分布不平衡的問題。
(3)設計了一個梯度調制模塊對分類器的優化過程進行調制,進而解決分類器中收斂速度不一致的問題。
1 相關工作
對類別不平衡問題的現有解決方案可以被分為兩類:數據層面的重采樣[12-15]和算法層面的權重分配[16-20]。
1.1 重采樣
重采樣的方法分為上采樣和下采樣兩種。上采樣主要是對較小的類進行數據增強,以獲得更多的樣本[12-13]。然而,上采樣方式雖然增加了較小類的樣本數,但是完全依賴于數據增強的方式。通過旋轉、剪切、平移等簡單數據增強式獲得的上采樣樣本與原數據可能高度相似,對模型的訓練并沒有本質的性能提升[21]。通過生成模型(generative adversarial networks,GAN)來實現數據增強的方式,較難生成細粒度的表情圖像。下采樣主要是從較大的類中隨機選擇較少的樣本用于訓練,以平衡不同類的樣本量。然而,這種方式可能使得參與學習的有用信息減少,最終影響模型的學習性能。
1.2 重加權
重加權的方法常常為小類樣本在損失函數上賦予高權重,使其獲得更多的優化。各類別權重的計算方式主要分為統計樣本量占比[16-17]以及評估樣本難度兩種方式[18-20]。目前,統計樣本量占比的方法獲得了廣泛的應用。通常,分配的權重與該類樣本數成反比。此外,評估樣本難度的方法認為來自小類的樣本往往比來自大類的樣本更難學習,因為小類的樣本的表征學習更差。更難學習即預測損失函數值很大,將損失值作為樣本的權重[20]。部分工作[26-27]認為樣本難度與樣本數量之間沒有直接關系。由于圖像的特征分布和類別的標注分布不耦合的本質[22],利用分配權重的損失函數將影響模型對圖像的表征學習,并沒有為圖像表征過程帶來更多的提升,各類別的特征分布仍然是不平衡的。為此,采用兩階段,將圖像表征階段與分類器調制階段分離的平衡調制方式值得考慮。
2 本文方法
2.1 不平衡問題分析
人臉表情識別旨在對人臉圖片提取表情特征,并推斷表情的類別。具體來說,給定訓練數據集為其中,xi,yi分別是訓練樣本和標簽。yi∈{1,2,…,C},C為表情類別數。N為樣本總數。針對訓練樣本(xi,yi),首先,使用CNN 的骨干網絡φ(·)提取圖像的特征,提取過程表示如下:
其中,θ為骨干網絡參數。fi∈RM,M為特征維度。當類別不平衡時,由于小類樣本數量較少,在特征質量上也難以有與大類明顯區分的關鍵性特征,致使小類樣本的特征與大類樣本特征區分不明顯,分布不平衡,不利于后續分類。
在獲得圖像的特征fi后,使用線性分類器建立特征fi到各類別預測概率p的映射,取概率值最大的類別作為樣本的預測表情y′。各類別預測概率p計算如下:
其中,p(xi)∈RC。W為分類器最后一層線性參數,W∈RM×C。b為偏置項,b∈RC。預測表情y′=argmax(p)。根據輸入特征與各類別預測概率的對應關系,分類器W可進一步表示為W=[w1,w2,…,wC]。設該樣本xi屬于第c類,將第c類的邏輯輸出表示為p(xi)c,則xi的損失為L=-lb(p(xi)c)=-lb(fi?wc)。當模型根據樣本xi計算的損失函數優化分類器參數時,W的參數更新如下:
其中,η為學習率。由于xi的標簽為yi屬于第c類,損失反傳W梯度為:
即當樣本xi屬于第c類時,損失反傳僅更新第c類的權重wc。設訓練集中各類樣本數為[N1,N2,…,Nc,…,NC],其中,則交叉熵損失函數為:
2.2 方法概述
為了解決類別不平衡導致的特征分布不平衡和分類器優化不平衡的問題,本文提出了一種類別平衡調制的人臉表情識別方法(CBM-Net)。如圖2 所示,CBM-Net 包括常規的深度學習骨干網絡以及特征調制和梯度調制兩個分支模塊。CBM-Net 輸入為一批人臉表情圖像,輸出為對應的預測表情y′。為了應對數據不平衡情況,本文將圖像的表征階段與分類器調制階段分離。具體地,在反向的調制過程中,分別應用特征調制和梯度調制模塊優化特征分布和分類器參數。首先,針對骨干網絡提取的樣本特征fi,通過最大化類間的方向性,進而確保模型可以提取出小類樣本的區分性特征,使得不同類在特征分布上保持平衡。其次,針對輸出概率p,計算其與標簽y的交叉熵獲得分類器梯度,利用批次樣本統計信息k來調節分類器梯度,使得欠優化的小類獲得更多的優化。
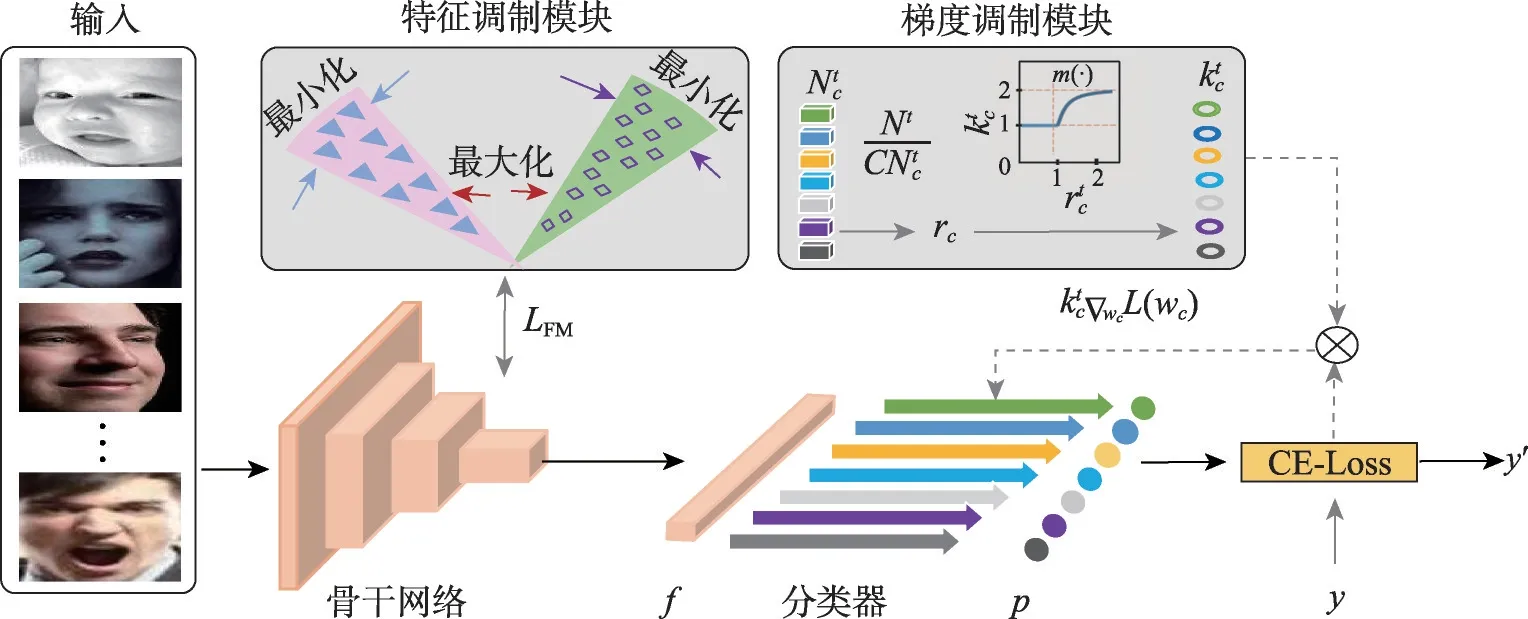
圖2 網絡框架圖Fig.2 Network framework diagram
2.3 特征調制模塊
特征調制模塊作用于圖像表征階段,通過約束類間特征的方向性,進而確保樣本不平衡的類在特征分布上保持平衡。該模塊的核心是特征調制損失LFM。受文獻[28]啟發,LFM依據特征的相似性,增加類間距離的同時,減少了類內距離。
對于給定的兩個樣本xi和xj,其特征分別為fi和fj,通過余弦相似度計算它們之間的特征相似性,即:
特征調制損失LFM可以表示如下:
其中,Nyi是屬于yi類的樣本數,是剩余類的樣本數,滿足,i,j是索引。
2.4 梯度調制模塊
如前所述,模型的優化過程通常由大類主導控制,從而小類的性能未能充分優化。為了解決該問題,梯度調制模塊作用于分類器調制階段,其利用批次樣本的統計信息來調節各類別梯度,使得小類獲得更多的優化。為簡單理解,以第c類為例。在第t批次中,定義為該批次第c類樣本數,c∈{1,2,…,C},C是表情類別數。Nt為該批次樣本總數。定義樣本比
即樣本數越少,該類在當前批次將獲得更多優化。為自適應調節梯度,設計梯度權重:
其中,a是控制調制程度的超參數。將系數整合到SGD(stochastic gradient descent)優化方法中,更新分類器第c類梯度,更新如下:
2.5 損失函數
在訓練過程中,CBM-Net 有兩個約束函數,分別是交叉熵損失函數LCE以及特征調制函數LFM。
綜上,本文所采用的損失函數為:
λ為平衡超參數。
3 實驗分析
3.1 實驗數據
RAF-DB[9]:包含了30 000 張帶有基本或復合注釋的表情圖片。在實驗中,為了對比公平,本文僅使用數據集中的7 種基本表情,包括6 種離散的基本表情和1種中性表情。
AffectNet[10]:從搜索引擎中查詢與情感相關關鍵詞收集的100 多萬張圖像,是目前公開可用的最大FER數據集。其中,超過44萬張圖像被手動標注為8種表情(7種基本表情+蔑視)。本文使用28萬個訓練樣本和4 萬個測試樣本,分別在7 種基本表情和包括蔑視的8種表情上進行實驗。
SFEW[24]:采集于同一個電影的靜態圖片,并被標注為了7 種基本情緒。被劃分為了958 張訓練圖片和436張測試圖片。
CAER-S[25]:基于CAER 選擇的視頻靜態幀獲得的數據集。該數據集被獨立注釋為7 類基本表情,包含65 983 張圖像,其中44 996 張圖像用于訓練,20 987 張圖像用于測試。
3.2 實驗設計
(1)預處理和面部特征。在CBM-Net 中,圖像通過RetinaFace[29]進行人臉檢測和對齊,并通過數據預處理進一步調整為224×224 像素。CBM-Net 由Pytorch實現,主干網為ResNet18[30],從主干網最后一個池化層提取512 維特征。隨后,特征由512 維降低到10 維。數據預處理過程包括基礎性數據增強和標準化。在與各種最先進的方法進行比較時,主干網ResNet-18 在MS-Celeb-1M[31]人臉識別數據集上進行預訓練。
(2)訓練。本文使用1 個Nvidia Titan 2080s GPU以端到端的方式訓練CBM-Net,并將批量大小設置為128。整個網絡采用LFM和LCE聯合優化。
3.3 消融實驗
3.3.1 評估CBM-Net的不同模塊
為驗證本文提出的各模塊的有效性,設計了一項消融研究以評估CBM-Net 中不同模塊的準確率。如表1,包括骨干網絡、特征調制模塊和梯度調制模塊。分別從不同模塊組合的效果進行分析,以證明網絡整體設計的有效性。為了更好地展示實驗效果,CBM-Net 采用的主干網絡不通過預訓練,而是從頭開始訓練,并對最優結果進行加粗展示。

表1 CBM-Net中兩個模塊的評估Table 1 Evaluation of two modules in CBM-Net
從表1 可以直觀地觀察到,在RAF-DB 和AffectNet-7 數據集上,僅使用特征調制時,精度分別比基礎提高了0.87 個百分點和0.99 個百分點;僅使用梯度調制時,精度分別比基礎提高了1.1 個百分點和0.88 個百分點。這表明了本文提出的各模塊的確有效。最終,CBM-Net 在沒有預訓練的情況下,在數據集RAF-DB 和AffectNet-7 上分別達到了87.71%和64.33%的精度。
3.3.2 評估CBM-Net中各模塊類平均精度
為了進一步驗證各模塊解決類別不平衡問題的能力,本文使用各模塊與僅使用ResNet-18 作為主干網絡的類平均精度對比,以定量地測試各模塊對尾部類的性能影響,直觀地展示各模塊的類別平衡調制效果。其中,在最有代表性的RAF-DB數據集上進行實驗,對梯度調制模塊中的超參數a進行多次不同賦值測試,以挑選最合適超參數a。最后,將兩模塊共同使用,以探索CBM-Net 的類平衡效果。為了更好地展示對比效果,網絡不通過預訓練。
如表2,可以直觀地觀察到,在樣本量較少的類Fear、Disgust 和Angry(加粗行),類平均精度均得到了明顯的提升,這表明了CBM-Net 中各模塊在解決類別不平衡問題的有效性。其中,當a設置為0.5時,梯度調制效果提升最為顯著,為了方便后續實驗,當批次大小為128時,本文將a統一設置為0.5。最終報告的結果也受a為0.5的限制。
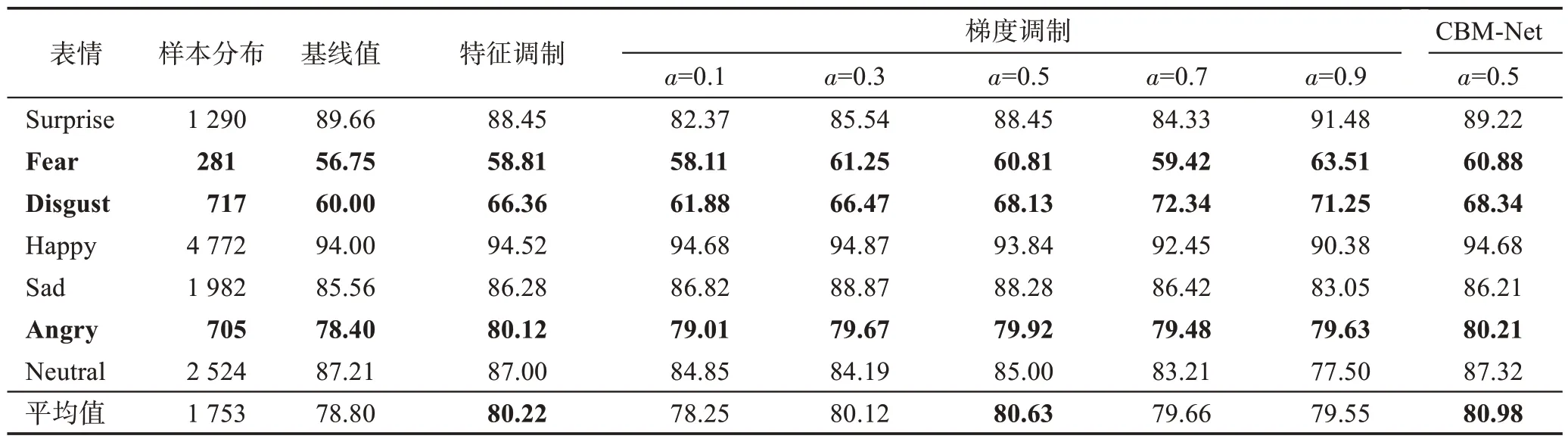
表2 各模塊在RAF-DB數據集上的類平均精度Table 2 Class average accuracy of each module on RAF-DB dataset 單位:%
3.3.3 評估損失函數的平衡超參數λ
超參數λ控制著分類交叉熵損失函數LCE以及特征調制函數LFM在訓練過程中的占比,為此,依次選取不同的λ取值進行實驗,以探索λ對CBM-Net的影響。同理,網絡不通過預訓練。
圖3 展示了超參數λ對CBM-Net 的影響,很明顯,過大或過小的選取都會降低CBM-Net 的性能。當λ在0.8 到1.2 的范圍,網絡可以獲得良好的性能。在后續實驗中,本文將λ統一設置為1.0。
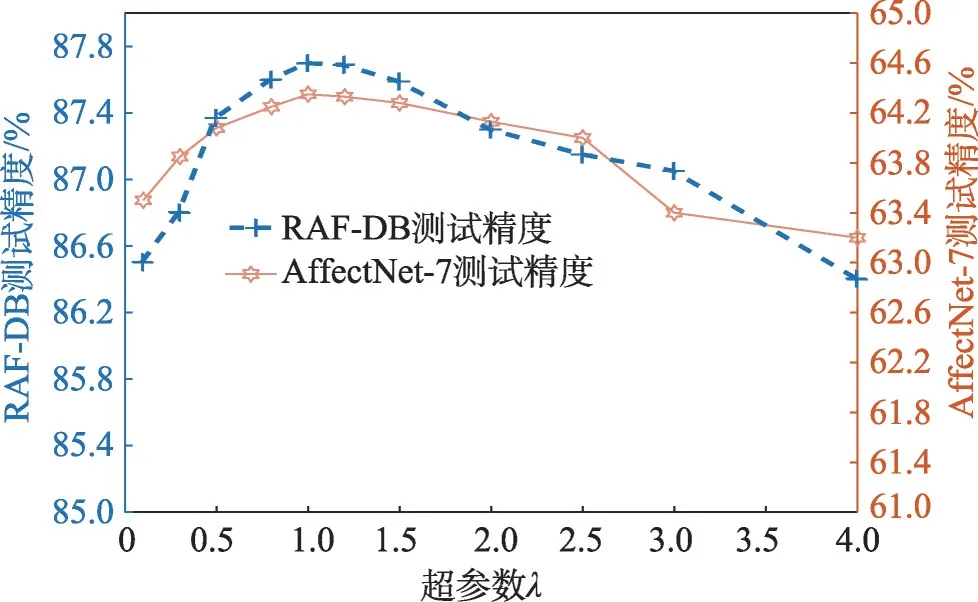
圖3 損失函數的平衡超參數λ評估Fig.3 Evaluation on hyperparameter λ of loss function
3.4 特征調制模塊的效果可視化
為了直觀展示特征調制模塊效果,本節采用TSNE(T-distributed stochastic neighbor embedding)[32]方法對骨干網絡提取的圖像特征進行可視化。為了比較公平,模型統一采用了在數據集MS-Celeb-1M預訓練的ResNet-18 作為主干網絡,在RAF-DB 測試集上進行可視化比較。圖4(a)顯示了僅使用分類損失LCE作為訓練約束的特征分布結果。圖4(b)顯示了除了分類損失LCE之外,還添加了特征調制模塊的LFM作為約束的特征分布結果。

圖4 特征調制效果可視化示意圖Fig.4 Diagram of feature modulation effect visualization
圖4(b)展示的帶特征調制模塊的效果,很明顯,最大化類間方向間隔約束使得較小的類也獲得更有差異性的特征,不同類在空間分布上保持了平衡。
3.5 梯度調制模塊的效果可視化
為了直觀展示梯度調制模塊的效果,本節對訓練迭代過程中RAF-DB 測試集的類平均精度進行了可視化。模型不通過預訓練,不使用特征調制模塊,直接在ResNet-18的骨干網絡下選擇是否使用梯度調制模塊,以體現本文設計的梯度調制優勢。圖5(a)顯示了僅使用ResNet-18 作為模型的類平均精度隨epoch的收斂過程。圖5(b)顯示了除了ResNet-18 之外,還添加了梯度調制模塊的各類收斂過程。
相較于圖5(a)展示的無梯度調制的效果,很明顯,圖5(b)中帶梯度調制的較小類優化更快地得到了收斂。各類的收斂速率更加協調,分類器的優化得到了平衡。此外,較小類的類平均精度得到顯著提升,致使總體的平均精度得到提升,這與表2 中的結論一致。
3.6 與常規類平衡方法對比
本文設計了一項對比實驗,統一使用ResNet-18作為骨干網絡,在同樣使用本文提出的特征調制損失LFM的前提條件下,將本文的梯度調制方法與使用不同的權重分配方法進行對比,以探索本文提出的梯度調制方法的有效性。如表3,使用權重分配的方法包括常規的帶權交叉熵損失函數(W-CE)以及Focal Loss[20]。為了更好地展示對比效果,網絡從頭進行訓練,不通過預訓練,并對最優結果進行加粗展示。
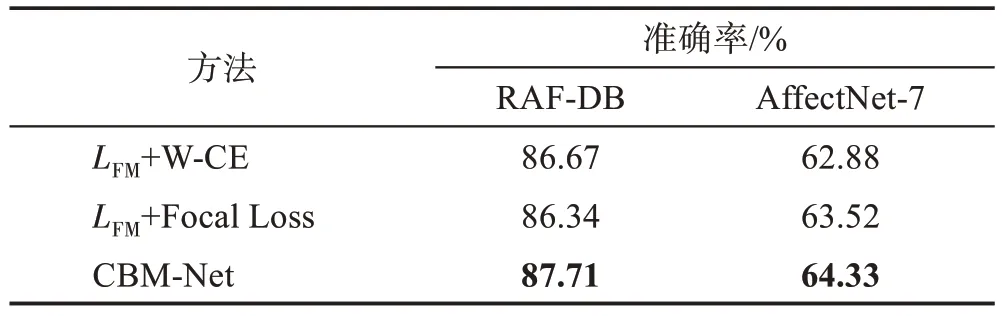
表3 CBM-Net與常規類平衡方法的對比Table 3 Comparison between CBM-Net and conventional class balance methods
從表3可以直觀地觀察到,在相同實驗設置的前提下,本文的梯度調制方法比常規的帶權重的交叉熵損失以及Focal Loss 效果更好。優異的對比性能得益于本文提出的兩階段的類別平衡調制方法,即分別對特征和分類器進行調制。而直接作用于最終分類損失的類平衡方式影響了模型對圖像的表征學習,進而影響了分類器分類性能,這也從側面印證了本文將圖像表征階段與分類器調制階段分離的合理性。
3.7 與最先進的方法對比
為了進一步展示CBM-Net 的優越性,本節將CBM-Net 在RAF-DB、SFEW、CAER-S 和AffectNet數據集上與最先進的方法進行定量實驗對比,如表4、表5和表6所示。最先進的方法包括SCN(self-cure network)[33]、EfficientFace[34]和DAN(distract your attention network)[37]等方法。SCN通過設計魯棒損失函數抑制不確定樣本參與網絡訓練。Efficient-Face 使用通道注意力以及標簽分布學習監督網絡訓練。DAN的代碼可以獲得,因此在相同的設置上復現了該算法,但重新實現的結果和報告的結果有一定的差距,這可能是由于不同的數據預處理和運行環境帶來的影響。為了公平,本實驗采用相同的設置,復現的結果用星號“*”在表中單獨標出。CAER-S 數據集比較新穎,在此上的研究比較少,因此DAN[37]和Res2Net-50[40]的結果由復現提供。ADDL(adaptive deep disturbance-disentangled learning)[36]在數據集Multi-Pie[43]上進行了預訓練,DAN、Efficient-Face、SCN 和DMEU(latent distribution mining and pairwise uncertainty estimation)[27]在MS-Celeb-1M 數據集[31]上進行了預訓練。CBM-Net 和大多數經典算法一樣采用的MSCeleb-1M數據集預訓練方式。
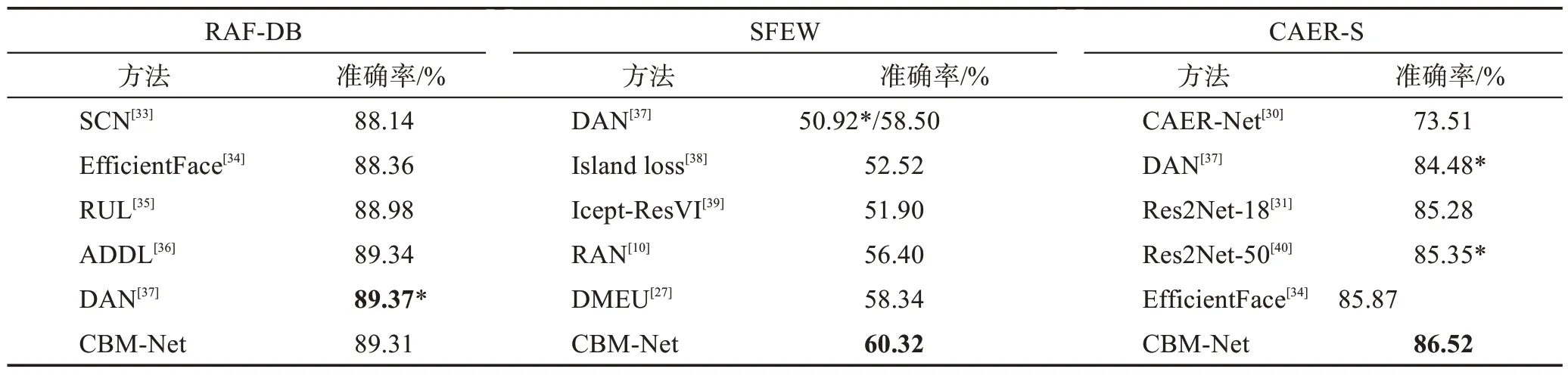
表4 與最先進的方法精度對比Table 4 Precision comparison with state-of-the-art methods
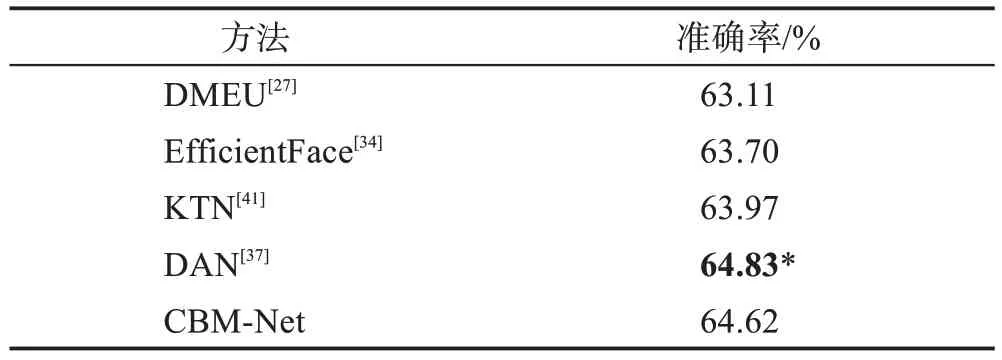
表5 AffectNet-7數據集上與最先進的方法對比Table 5 Comparison with state-of-the-art methods on AffectNet-7 dataset

表6 AffectNet-8數據集上與最先進的方法對比Table 6 Comparison with state-of-the-art methods on AffectNet-8 dataset
表4 給出了RAF-DB、SFEW 和CAER-S 數據集上的定量比較結果。如表4,在經典的RAF-DB 數據集上,CBM-Net 取得了與最先進的一些方法幾乎持平的結果。在SFEW 和CAER-S 數據集上,CBM-Net都取得了最好的效果,分別為60.32%和86.52%。對比的方法都沒有針對類別不平衡問題設計方法,而精度的巨大提高,也進一步說明在自然場景下采集的數據集需要進行類平衡調制。表5 和表6 給出了AffectNet-7 和AffectNet-8 數據集上的比較結果,CBM-Net 在這些基準測試中同樣獲得了不錯的表現。值得注意的是,RAF-DB 與AffectNet 均為經典數據集,為了提高識別精度,當前最先進的方法幾乎均采用了大網絡或設計特殊的注意力方法,如EfficientFace 與DAN。而CBM-Net 僅采用最基本的ResNet-18 模型,在增加有限的計算量和模型參數的基礎上,對各類別特征和分類器進行調制,帶來了性能大幅度的提升。一方面證明了數據分布不平衡問題確實對模型性能產生了負面的影響,另一方面證明了本文提出的類別平衡方法的有效性。
4 結束語
本文分析了人臉表情識別(FER)中的類別不平衡問題,并提出分別從圖像表征階段與分類器調制階段來解決這個問題。因此,本文提出了一種類別平衡調制的人臉表情識別方法(CBM-Net),設計了特征調制和梯度調制兩個模塊。具體的,特征調制模塊對圖像提取過程進行調制,確保不同類在特征分布上保持平衡。梯度調制模塊對分類器梯度進行調制,使得欠優化的小類獲得更多的優化。在四個公共數據集上的實驗驗證了所提出的CBM-Net的有效性和優越性。然而,CBM-Net 可能存在的問題是沒有脫離權重分配方法范疇,默認了類樣本數量等價于類別的信息量。然而,已經有工作指出[21],類別信息的增量隨著樣本數量的增加而減少,即同類樣本存在信息冗余的情況。因此,下一步將著重研究樣本數量與類信息量的具體關系,來調制各類別分布。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
