基于改進YOLOv5s的道路行人與車輛檢測算法
2023-12-25 03:25:04秦憶南施衛張馳皓陳程
電腦知識與技術 2023年31期
秦憶南 施衛 張馳皓 陳程


摘要:針對在城市街道中檢測目標因為相互遮擋、尺寸小、密集分布等問題導致檢測困難,檢測目標丟失,提出一種改進的YOLOv5s算法。首先通過將CA注意力模塊與C3模塊相結合加入C3CA注意力模塊;其次加入SPPFCSPC空間金字塔池化模塊代替SPPF,進一步擴大感受野,提升模型的精度。最后改變Neck結構變為Slim-Neck結構,通過替換Conv模塊為GSConv模塊,并將Slim-Neck中的C3模塊中的Conv模塊替換為GSConv模塊。實驗使用優化后的KITTI數據集。實驗結果表明,改進后的算法與YOLOv5s相比在平均精度值上提升了2.3%,小目標漏檢的情況也有了明顯改善。
關鍵詞:目標檢測;YOLOv5s;CA注意力模塊;空間金字塔;Slim-Neck
中圖分類號:TP18? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)31-0005-04
開放科學(資源服務)標識碼(OSID) :
0 引言
隨著科技發展與城市道路規劃的推陳出新,對自動駕駛的要求也越來越嚴苛。如何能夠更快更加精準地進行目標檢測一直是自動駕駛汽車所需要解決的關鍵問題。
對目標準確檢測主要包括兩方面:一方面是在復雜的道路環境下識別出檢測目標的信息,并用邊界框將其在圖片或影像中標識出。另一方面則是通過深度學習等模擬人思維的決策對邊界框中的目標進行識別檢測,確定類別與名稱以及置信度。這個過程中由于環境的復雜性和行人狀態的多樣性以及行人行為的不可確定性,需要自動駕駛擁有模擬人的思維做出相應的對策。機器學習、深度學習可以幫助行駛車輛在不同的場景環境下學習并識別各種物體,并通過識別的結果做出相應的對策,這就使得機器學習、深度學習顯得尤為重要。
目前的深度學習主要分為二階段和一階段這兩大類[1]。二階段的代表算法有R-CNN[2]、Fast R-CNN[3]、Faster R-CNN[4]等,二階段算法這一類的算法是先生成候選框,然后對這些選框進行分類。兩階段目標檢測為了追求高精度,增加了復雜性,降低了檢測速度。相較于兩階段目標檢測,一階段直接通過卷積后在圖像上直接生成預測目標的位置和分類,大大降低了運算的復雜性,提升了速度,但在提升速度的同時,也犧牲了一定的精度。這一類代表的算法有SSD[5]、YOLO系類[6]等。在自動駕駛中檢測速度和檢測精度一樣重要,一階段目標檢測因為速度與精度都有涉及,而廣泛用于自動駕駛。
在自動駕駛中行人檢測因其不確定性,狀態復雜性一直是目標檢測的難點,行人檢測的難點主要存在小目標漏檢,密集行人漏檢以及遮擋目標漏檢。為了降低行人目標檢測過程中誤檢、漏檢,本文以YOLOv5算法為基礎模型,提出了一種城市街道場景中目標檢測的改進YOLOv5算法。首先加入Coordinate Attention (CA) [7]注意力模塊,增加檢測精度;之后將SPPF[8]池化金字塔與CSP結構相結合生成SPPFCSPC模塊,擴大感受野,降低誤檢、漏檢;最后通過GSConv[9]卷積替換Conv降低模型參數量,提高速度。通過上述網絡結構調整后,使本文的算法能夠更好地適應城市街道,獲得較好的檢測效果。
1 YOLOv5網絡模型改進
針對在城市街道中檢測目標因為相互遮擋、尺寸小、密集分布等問題導致檢測困難,檢測目標丟失,對YOLOv5算法進行改進。首先加入C3CA注意力模塊,通過將CA注意力模塊與C3模塊相結合,在增加長距離關系提取能力,擁有橫向與縱向位置信息提取能力的同時,單獨降低加CA的計算量、參數量。其次加入SPPFCSPC空間金字塔池化模塊代替SPPF,進一步擴大感受野,提升模型的精度。最后在Neck層加入GSConv模塊代替Conv模塊,通過降低計算量的方法來提升速度,并替換Neck層中使用Conv的C3,使Neck層變為Slim-Neck。
1.1 注意力添加-CA模塊
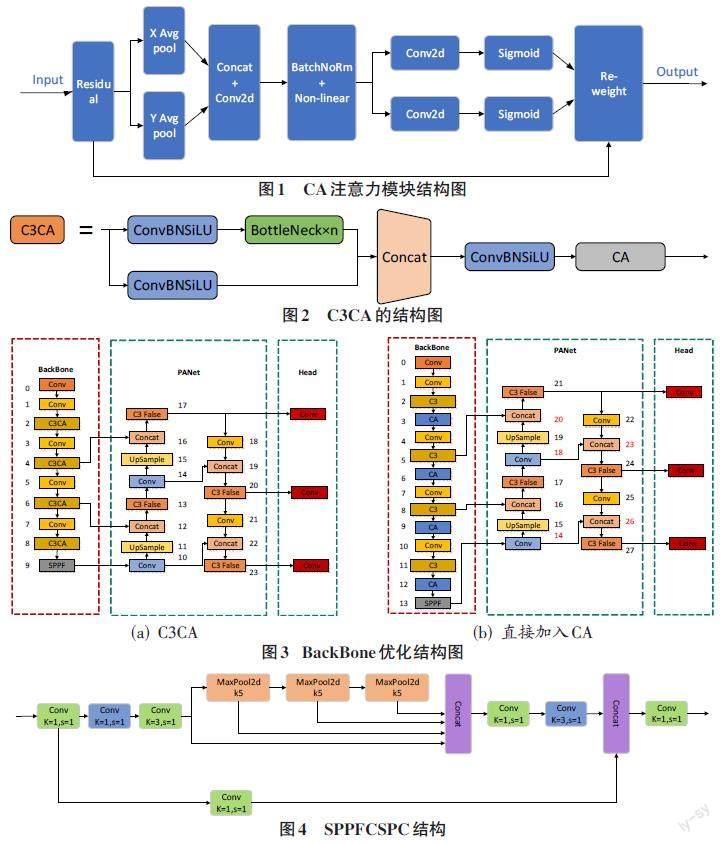
YOLOv5s在對目標進行檢測時,某些小目標或者被遮擋的目標往往會漏檢,導致檢測效果不佳。因此,本文將Coordinate Attention(CA)注意力模塊與C3模塊相結合,在不改變Backbone網絡主體架構的情況下加入注意力模塊。如圖1為CA注意力模塊結構圖。
開始時沒有使用全局平均池化,而是分別向X水平軸方向和Y垂直軸方向進行平均池化。這樣能夠允許在捕捉單方向上的長距離關系的同時,保留另一個方向上空間的信息,幫助準確定位目標。通過兩個方向池化過后,會得到兩個單獨方向的特征圖,將這兩個特征圖進行拼接并用1×1大小的卷積核進行卷積,生成過渡特征圖。通過批量歸一化以及線性回歸的操作后再次將過渡特征圖拆分成單獨方向的特征圖,并再次使用1×1大小的卷積核進行卷積,獲得與輸入時相一致的通道數。通過激活函數,分配其權重比并與開始的通道輸入值相乘獲得最后的輸出值,從而達到強化特征的目的。
C3CA模塊是在C3模塊內部的最后添加了CA注意力模塊。本文沒有選擇直接在BackBone網絡中加入CA模塊,而是選擇在Bottleneck C3中加入CA模塊。如圖2所示是C3CA的結構圖。
如圖3(a)是在Bottleneck C3模塊加入CA的網絡結構圖和圖3(b)CA模塊直接加入BackBone網絡結構圖。可以看出,在Bottleneck C3模塊加入CA后,整個YOLOv5s的框架并不會發生改變,而在BackBone網絡加入后,因為是完整地插入了一個新的層,所以后面的層要往后推一個位置。雖然因為輸入的關系,上下兩層會自己調節,但有4個Concat還額外接受其他層的信息,而它所接受的C3層和Conv層因為CA模塊的加入需要進行調節。當CA直接加入BackBone網絡后,整個網絡結構發生了改變。當其被訓練時,會因為結構與預訓練權重中結構不符合而增加多余的訓練量。同時因為無法找到結構中對應的位置,YOLOv5s.pt中的權重將不再采用,map值將會從很低的值開始運算,大大增加了訓練時間和訓練次數。
1.2 空間金字塔池化SPPFCSPC
在復雜場景中,會出現目標遮擋漏檢或者小目標漏檢。為了滿足在增大感受野的同時加快運行速度,本文提出了將SPPF與CSP結構相結合而成的SPPFCSPC模塊,如圖4所示。
SPPF是在SPP空洞卷積的基礎上提出的,能在計算量不變的同時降低FLOPS。SPPF的作用是增大感受野,通過5、9、13、1這4種不同尺度的最大池化獲得4種不同的感受野,來區分大小目標。
CSP結構將原輸入分為2個分支。一支通過1×1的卷積降維使通道數減少,另一支通過1×1卷積降維后升維來降低計算量并進行SPPF模塊處理。最后兩者再相結合并通過1×1的卷積升維,實現輸入與輸出維度一致。
通過SPPF模塊與CSP結構結合后的SPPFCSPC與SPPF相比較,獲得更高的精度和感受野,與SPPCSPC相比,速度方面得到了提升。
1.3 Neck網絡輕量化改進
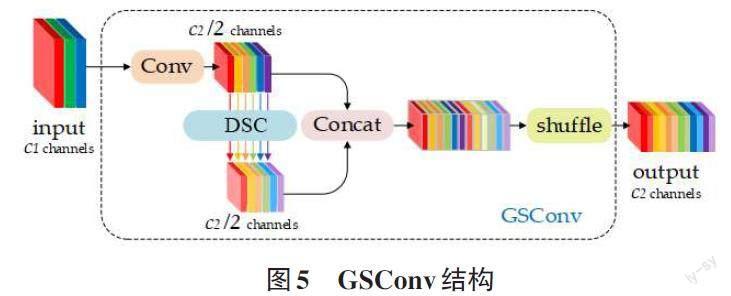
在自動駕駛中因為目標的復雜性和場景的實時性,對檢測算法的準確性和速度都有比較高的要求。標準卷積SC在卷積過程中因為卷積核的通道與圖片通道相同,所以可以直接得到卷積結果,并且可以保留各通道之間的隱藏連接。而深度可分離卷積DSC先是將圖片的各通道分別卷積得到3個通道數,而后再通過一個pointwise核將這3個數卷積。由于行人檢測的復雜性,需要在圖片上提取眾多的屬性,此時DSC相較于SC可以節省很多的參數,提升了預測的速度。但DSC由于通道分開卷積的原因屬于稀疏卷積,丟失了各通道之間的隱藏連接,直接導致了精確度的下降。
本文采用GSConv卷積來代替一部分Conv卷積,在降低計算量提升預測速度的同時提高精度。GSConv卷積中融合了深度可分離卷積DSC與標準卷積SC。如圖5所示,通過分組卷積,一半使用SC,一半采用DSC并將兩者進行Concat。之后使用shuffle將SC生成的密集卷積操作信息融入DSC生成的信息中,如圖5所示。
GSConv盡可能地保存了這些連接,同時因為調用了DSC也降低了運算的參數量。但如果所有的卷積Conv都用GSConv來代替,只會導致網絡升度的進一步加深,計算量參數量的增大只會增加推理時間。對于駕駛中的汽車來說,速度與準確同樣重要,所以GSConv替換的最好方式就是僅在Neck中使用。當GSConv僅在Neck中運行時可以將自身所產生的冗余信息降到最小,同時可以讓加入的注意力CA效果更好。
輕量化Neck層使其變為Slim-Neck就是替換掉其中的Conv,用更加輕量級的GSConv代替。GSConv計算成本大約只有標準卷積的60%~70%,但精確度毫不遜色。除了Neck中的Conv以外,還能夠更改Neck中同樣由Conv組成的C3模塊變成VoV-GSCSP。通過對比VoV-GSCSP與C3模塊,發現前者的FLOPs降低了20%。
2 實驗設置與結果分析
實驗環境配置基于Windows 10操作系統,CPU為AMD Ryzen 5 5600X 6-Core Processor 3.70 GHz,GPU 為NVIDIA GeForce RTX 3060 Ti,深度學習框架為PyTorch 1.12.1搭建網絡模型,Python 3.9編譯代碼。
2.1 數據集
本文所使用的數據集是KITTI數據集,KITTI數據集是著名的交通場景分析數據集,該數據集主要包括行人與車輛在不同的交通場景下的現實圖像數據,圖像素材大小為1 224×370。原數據集包括Car、Van、Truck、Pedestrian、Pedestrian(sitting)、Cyclist、Tram和Misc這8種類別。對原始數據集進行種類重劃分以及格式轉換。由于Cyclist和Misc在整個數據集中數量較少且識別度不高,所以去除這2類。將Car、Van、Truck、Cyclist、Tram合并為Car這一類,將 Pedestrian和Pedestrian(sitting)合并為Pedestrian一類。處理過后獲得7 481張圖片,包含Car和Pedestrian兩種類別作為實驗數據,按照8∶2的比例劃分出5 885張圖片作為訓練集,1 596張圖片作為驗證集。
2.2 消融實驗
為了驗證改進部分對YOLOv5模型的影響,對上述的改進方法進行消融實驗。評估指標包括多類別平均精度(mAP50/%、mAP50:95/%)、計算量(FLOPS)和參數量(Params),實驗結果如表1所示。
表1結果說明,直接加入CA注意力模塊雖然在mAP上會有所上漲,但Params以及FLOPS都會上漲不少,而融合過后的C3CA的mAP提升了0.9%,同時Params以及FLOPS幾乎沒有什么變化,證明了C3CA模塊優于直接加入CA模塊。Slim-Neck通過替換Conv為GSConv的操作,每個卷積可以節約70%的計算量,在mAP提升0.7%的同時降低了1.3個GFLOPS。最后替換SPPFCSPC金字塔模塊因為本身的模型復雜程度大于SPPF增加了不少計算量,但同時也增加了0.7%的mAP值,總體上mAP50/%漲了2.3%,mAP50:95/%上漲了5%。
2.3 檢測結果
本文采用訓練完成的YOLOv5權重以及改進過后的權重對從測試集中選取的四組圖片進行檢測,檢測結果如圖6所示。
由圖6可以看出,通過改進后的算法相較于原始的YOLOv5在目標檢測方面,置信度更高,漏檢誤檢率下降,一些漏檢測的小目標也在改進后的算法檢測中被檢測到。
3 結論
本文提出了一種YOLOv5的改進方式,主要用于降低被檢目標由于目標小、重疊等于原因出現漏檢、誤檢的問題。首先加入C3CA模塊代替C3模塊,相較于直接添加CA注意力模塊,不僅使mAP值有了一部分的提升,在速度和計算效率方面也大大降低了計算量(FLOPS)和參數量(Params);之后將原SPPF與CSP結構相結合設計出SPPFCSPC池化金字塔模塊,擁有了更大的感受野,降低目標漏檢情況;最后使用GSConv模塊代替原始的Conv卷積模塊,每一個GSConv都只需要Conv的70%計算量。通過卷積模塊的替換,Neck網絡變為Slim-Neck網絡,在輕量化網絡模型的同時,進一步提升算法的平均精度。將改進的算法與原始YOLOv5作對比,在檢測精度方面改進后的算法提升了2.3%,在檢測速度方面因為SPPFCSPC的加入,總體參數量變多,計算量相較于YOLOv5還相對減少了一些。
參考文獻:
[1] 劉穎,劉紅燕,范九倫,等.基于深度學習的小目標檢測研究與應用綜述[J].電子學報,2020,48(3):590-601.
[2] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[EB/OL].[2022-06-20].2013:arXiv:1311.2524.https://arxiv.org/abs/1311.2524.pdf.
[3] GIRSHICK R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision (ICCV).IEEE,2016:1440-1448.
[4] REN S Q,HE K M,GIRSHICK R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[5] 侯慶山,邢進生.基于Grad-CAM與KL損失的SSD目標檢測算法[J].電子學報,2020,48(12):2409-2416.
[6] BOCHKOVSKIY A,WANG C Y,LIAO H Y M.YOLOv4:optimal speed and accuracy of object detection[EB/OL].[2022-06-20].2020:arXiv:2004.10934.https://arxiv.org/abs/2004.10934.pdf.
[7] HOU Q B,ZHOU D Q,FENG J S.Coordinate attention for efficient mobile network design[C]//2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).IEEE,2021:13713-13722.
[8] HE K M,ZHANG X Y,REN S Q,et al.Spatial pyramid pooling in deep convolutional networks for visual recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904-1916.
[9] LI H L,LI J,WEI H B,et al.Slim-neck by GSConv:a better design paradigm of detector architectures for autonomous vehicles[EB/OL].[2023-02-20].2022:arXiv:2206.02424.https://arxiv.org/abs/2206.02424.pdf.
【通聯編輯:唐一東】
