基于雙重SE注意力機制下的CNN-BiLSTM混合石墨電極位移預測模型
2023-12-25 03:25:04張淵碩王子涵
電腦知識與技術 2023年31期
張淵碩 王子涵


摘要:石墨化是石墨電極生產核心環節,石墨電極位移預測的準確性和有效性對電極的生產質量具有重大意義。文章針對內串石墨化工藝參數與位移數據之間的關系進行建模,提出了一種引入注意力機制下的卷積神經網絡(CNN)和雙向長短期記憶網絡(BiLSTM)混合石墨電極位移預測模型。為有效解決時間序列重要程度差異性問題,在傳統SE注意力機制中增加了雙重SE注意力并行模塊,并用BiLSTM通過兩個方向來發掘時間序列信息,有效提高模型預測度。實驗結果表明,文章提出的混合網絡模型能夠對石墨電極位移進行有效預測,且相比于傳統的SE-CNN-BiLSTM方法和主流預測方法預測準確度更高。
關鍵詞: 內串石墨化;石墨電極位移;卷積神經網絡;雙向長短期記憶;注意力機制
中圖分類號:TP391.41? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)31-0051-04
開放科學(資源服務)標識碼(OSID) :<G:\飛翔打包文件一\電腦2023年第三十一期打包文件\9.01xs202331\Image\image256.jpeg>
0 引言
石墨化工藝的作用是使焙燒品的六角碳原子平面網絡從二維空間的無序重疊轉變為三維空間的有序重疊并具有石墨結構的高溫熱處理過程[1],要達到這個目的,大多數碳素企業通過電流加熱的方式使制品溫度最終達到2300~3000℃。由于其利用電極本體發熱,通過電極的電流密度分布比較均勻[2],可有效地降低能耗。在內串石墨化生產過程中,隨著溫度的不斷升高,制品會產生膨脹,為保證在石墨化送電過程中制品不因加熱過快而出現裂紋等次品,整個串接柱的膨脹量是工藝師傅重點參考的數值,膨脹量主要通過外接的位移傳感器來實現數據監測。
石墨化爐阻、爐溫等工藝參數都呈現出很強的非線性和不確定性,用數學回歸方法很難得到精確模型[3]。將深度學習技術應用到石墨化時序數據的石墨電極位移預測中,可以更好地發掘出石墨化工藝參數與石墨電極位移之間的關系,對于石墨電極的生產質量有顯著提高。文獻[4-5]采用BP神經網絡預測技術對焙燒控制進行改進,但其對長期依賴問題表現不佳。文獻[6]采用LSTM模型對鋁用陽極質量進行預測,對焙燒成品率有顯著提高,但采用單一模型進行預測存在精度差和訓練時間較長的問題。文獻[7]基于CNN-LSTM模型對NOX濃度進行預測,利用CNN對機組運行相關參數的時間序列數據進行特征提取,使各參數的序列特征更加明顯。但LSTM僅在一個方向上傳遞信息,無法同時獲取過去和未來的上下文信息。文獻[8]基于CNN-BiLSTM混合模型對短期風電功率進行預測,雖然采用BiLSTM同時挖掘未來和過去的時間序列信息來提高預測精度,但CNN在進行特征提取時,對于每個通道的特征圖采用相同的權重和處理方式,沒有明確地考慮通道間的相關性和重要性差異。
根據上述情況,本文提出了一種在雙重SE注意力機制下的CNN-BiLSTM混合預測模型。首先應用CNN對輸入數據進行卷積處理,增強輸入與輸出之間的相關性;然后SE模塊對卷積得到的特征圖進行操作,從而增強重要通道的表達;最后通過BiLSTM網絡對時序數據進行預測。實驗結果表明,本文所提出的方法可以有效地提高預測精度。
1 模型建立
1.1 卷積神經網絡
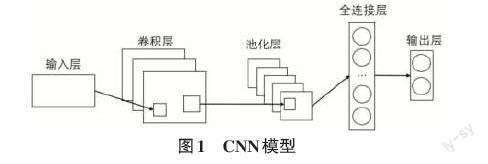
CNN(Convolutional Neural Networks,卷積神經網絡)[9]是一種常用于圖像處理、模式識別等領域的深度學習網絡。
CNN的核心思想是利用卷積運算提取局部特征,其結構圖如圖1所示,通過堆疊多層卷積層和池化層來逐漸抽象出更高層次的特征表示,并最終完成分類或回歸任務。在卷積層中,通常由多個特征平面組成,每個特征平面均由一組矩形排列的神經元構成,這些神經元共享同一組權重參數,即卷積核。在網絡前向傳播過程中,卷積核會與前一層的局部區域連接并進行卷積運算,以提取前一層特征的關鍵信息。計算公式如式(1)所示:
[XLj=f(i∈MjXL-1i*KLj+bLj)]? (1)
式中:[Mj]為輸入特征圖;[KLj]為特征對應的卷積核;[KLj],[XL-1i]分別為第L層、第L[-]1層的特征圖;*為卷積運算;[bLj]為第L層的偏置單元;[fx]為激活函數。
而在池化層中,則會對特征圖進行下采樣,減小特征圖大小,同時保留最顯著的特征。除了卷積和池化層之外,CNN還包括全連接層、激活函數、損失函數等一系列組件,可以通過反向傳播算法來更新權重和偏置參數,優化網絡性能。綜上所述,CNN具有局部感知性、權值共享、平移不變性等特點,使其在處理數據方面表現出色。
1.2 SE注意力機制
SE(Squeeze-and-Excitation)注意力機制[10]是一種用于提升神經網絡性能的自適應機制,它可以自適應地學習每個通道的重要性,并賦予網絡更強的區分能力。SE注意力模型由2個主要部分組成:擠壓(Squeeze)操作和激勵(Excitation)操作。其中,Squeeze操作是對輸入特征圖進行全局平均池化,將每個通道的特征壓縮成一個標量,以獲得全局的上下文信息。Excitation操作則是對Squeeze操作的輸出進行激活,通過多層感知機(MLP)模型來對每個通道賦予不同的權重,從而達到增強關鍵通道、壓縮無用通道的目的。
SE注意力模型的主要優點是可遷移性好,可以方便地嵌入各種結構中,例如卷積神經網絡、全連接層等。同時,由于可以精準地選擇需要關注的信息,因此大幅減少了模型的參數量,提高了網絡運行效率。圖2為SE模塊模型圖,[X']為原始輸入數據,[H']為原始輸入的空間高度,[W']為原始輸入的空間寬度,[C']為原始輸入的通道數,[X]為卷積操作后的特征圖,[H]為卷積操作后的高度,[W]為卷積操作后的空間寬度,[C]為卷積操作后特征的通道。
首先,Ftr這一步是轉換操作,是對輸入特征進行一次卷積,對于任何給定的變換Ftr映射輸入[X]到特征映射[U],定義如公式(2)所示:
[Ftr:X→U,X∈RH'×W'×C',U∈RH×W×C]? (2)
接下來就是Squeeze操作通過采用全局平均池化,將輸入特征圖在空間維度上進行降維,提取全局信息。這有助于捕捉輸入特征圖的整體上下文信息,不僅局限于局部區域,具體計算公式如式(3)所示:
[z=Fsq(x)=1H×Wi=1Hj=1Wuc(i,j)]? (3)
其中,[z]表示全局特征,[Fsq]表示擠壓操作,[x]表示輸入特征圖,[H]為特征圖的高度,[W]為特征圖的寬度,[uc(i,j)]為第[i]行第j列像素的特征向量。因此公式就將U[H×W×C]的輸入轉換成Z[1×1×C]的輸出,C為輸入特征圖的通道數。Excitation操作主要目的是激活學習到的通道相關性,通過使用Sigmoid函數將學習到的通道相關性轉化為0~1的概率值,表示每個通道重要性得分。這些得分用于加權每個通道的特征響應,使得重要的通道特征得到加強,而不重要的通道特征得到抑制,其公式如式(4)所示:
[s=fex(z,W)=σ(W2δ(W1z))]? (4)
其中,[s]表示激勵得分向量,[fex]表示為激勵操作,[W1∈RCr×C]表示[Cr]行[C]列的權重矩陣,[W2∈RC×Cr]表示[C]行[Cr]列的權重矩陣,[r]代表縮放比例,[σ]為Sigmoid函數,[δ]為ReLU激活函數。
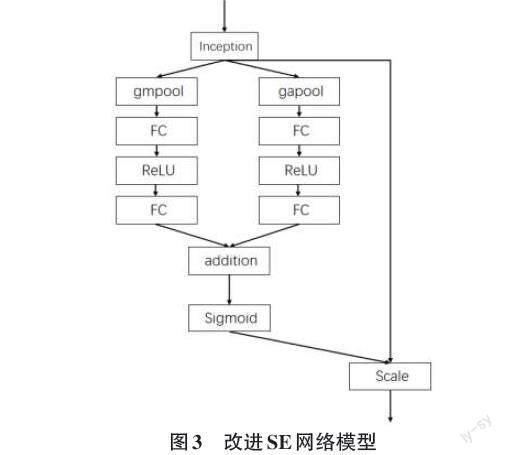
考慮到傳統SE注意力機制僅采用全局平均池化操作來壓縮特征圖信息,容易產生信息丟失問題。因此為了彌補SE注意力機制的這一缺陷,本文提出了一種雙重注意力機制[11]。即在傳統的SE注意力機制上,另設一條SE注意力機制,其中采用最大池化來提取整張特征圖的空間像素信息。進而將兩條SE注意力機制的初步加權結果相加,進而輸入至Sigmoid函數中,為各通道賦予0~1的權重,改進網絡模型圖如圖3所示。
其中,Inception表示Ftr轉化;gmpool、gapool分別表示最大池化和全局平均池化;FC表示全連接層,ReLU為激活函數;addition表示權重相加;Sigmoid表示激活函數。
1.3 BiLSTM模型
長短期記憶網絡[12]是循環神經網絡(Recurrent Neural Network,RNN)的一種,用于時序數據預測等。與傳統RNN相比,LSTM添加了更多的結構,通過設計門限結構解決了傳統RNN存在的缺陷,并且具有較長的短期記憶,效果更好。
LSTM是一種特殊的循環神經網絡,主要是通過精心設計的“門”結構來實現去除或增加信息到細胞狀態的功能。
其計算如公式(5)~公式(10)所示:
[it=σ(Wi?[ht-1,xt]+bi)]? (5)
[ft=σ(Wf?[ht-1,xt]+bf)]? (6)
[ot=σ(Wo?[ht-1,xt]+bo)]? (7)
[ct=tanh(Wc?[ht-1,xt]+bc)] (8)
[ct=it×ct+ct-1×ft]? (9)
[ht=ot×tanh(ct)]? (10)
其中,s 為 sigmoid 激活函數,[ft]、[ct]、[ot]分別表示遺忘門、輸入門和輸出門的輸出,[W]為神經元的權重,[b]為神經元的偏差。
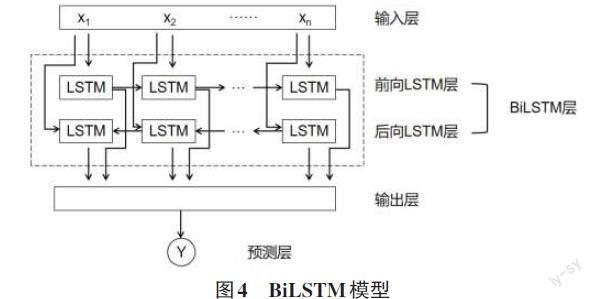
BiLSTM[13]由2個方向的LSTM組成,其中一個LSTM按時間順序處理序列,另一個LSTM按時間逆序處理序列,其結構圖4如所示,每個LSTM層都由多個LSTM神經元組成,每個神經元可以保留一個內部狀態,以便于捕捉序列中潛在的長期依賴關系。LSTM層還包括輸入門、遺忘門和輸出門,這些門控制著神經元如何處理輸入數據以及維護其內部狀態。
在正向和反向LSTM處理完輸入序列之后,它們的輸出會被拼接在一起作為BiLSTM的最終輸出結果,以提供更全面和豐富的特征信息。
2 模型設計
2.1 數據預處理
1) 數據采集
本文采用邯鄲市成安縣某炭素廠2022年4月27日—2023年6月20日的15分鐘數據,通過邊緣計算網關進行實時采集,在后端通過API接口獲取數據庫中的數據。由于獲取的數據較完整,只對數據中出現的個別空值采用向上賦值法進行賦值。
2) 數據處理
為了確保模型訓練的有效性,對于包含不同特征值且存在量綱差異和數值差異較大的數據集,采用輸入數據歸一化方法以降低其對模型訓練產生的消極影響。其計算公式如式(11)所示:
[x?=x-xmax+xmin2xmax-xmin2]? (11)
2.2 石墨電極位移預測模型設計
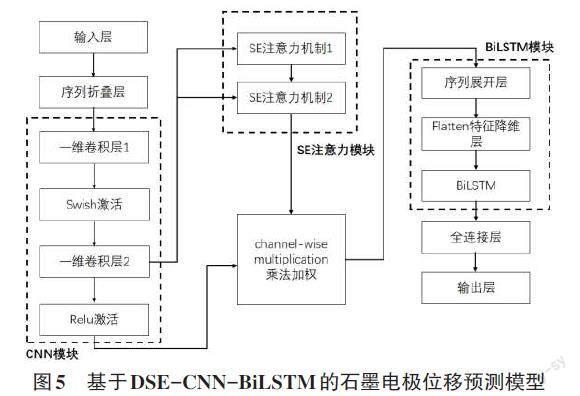
本文采用雙重SE注意力機制下的CNN-BiLSTM混合預測模型進行石墨電極位移預測,模型結構如圖5所示。首先,將經過預處理的數據輸入網絡,通過第一層卷積對數據進行特征提取,通過激活層到第二層卷積更加細致地對特征進行提取。本文的模型結構采用了兩層卷積作為特征提取層,考慮到池化層的加入會產生信息丟失的問題,因此不再引入池化操作。然后用SE注意力機制建立特征之間的相互依賴性,雙重SE注意力機制被放置在CNN最后一層卷積層與BiLSTM層之間的連接處。隨后通過Flatten降維層將SE注意力模塊與BiLSTM模塊相連接,最終通過全連接層輸出結果。
<G:\飛翔打包文件一\電腦2023年第三十一期打包文件\9.01xs202331\Image\image298.png>
圖5? 基于DSE-CNN-BiLSTM的石墨電極位移預測模型
2.3 模型評價指標
為了更進一步對所提出的DSE-CNN-BiLSTM混合網絡預測模型進行評估,本文采用RMSE和MAE作為誤差評價指標。上述指標值越小則代表預測準確性越高。具體計算公式如式(12)~式(13)所示:
[ERMSE=1Ni=1N(yi-y)2] (12)
[EMAE=1Ni=1Nyi-y] (13)
式中:[yi]為樣本[i]的真實值;[y]為真實值序列的均值;[y]為樣本[i]的模型預測值。
3 實驗分析
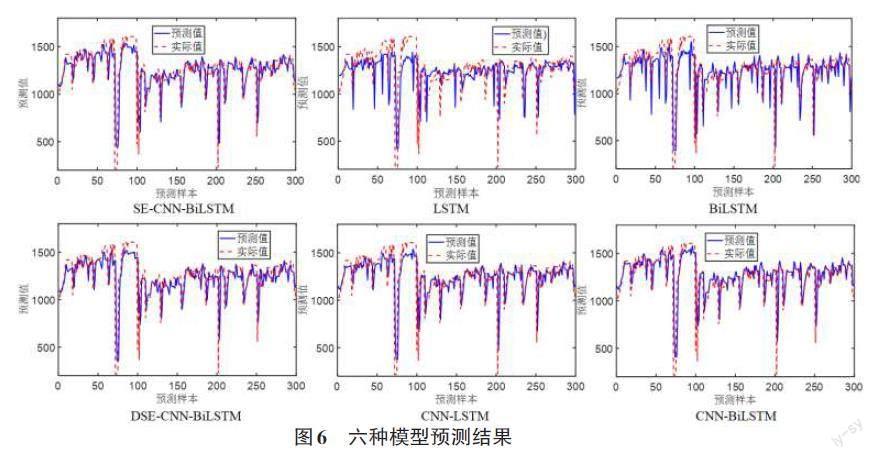
本文對采集到的數據集分為訓練集和測試集,前80%作為訓練集,總計4 800條;后20%作為測試集,總計1 200條。模型采用adam優化器和mini-batch梯度下降法,訓練批次設為256,迭代次數為100,進行15分鐘的石墨電極位移預測,圖6為6種模型的預測結果,分別為LSTM、GRU[13]、CNN-LSTM[14]、CNN-BiLSTM、SE-CNN-BiLSTM、DSE-CNN-BiLSTM模型。圖6中橫軸為預測樣本數,縱軸為石墨電極位移預測值。
為進一步驗證本文所提出模型的預測優勢,采用上述6種模型在相同數據和環境下進行對比,圖7為預測對比圖,圖中橫軸為預測樣本數,縱軸為石墨電極位移預測值。可以看出DSE-CNN-BiLSTM預測值與實際值更接近,優于其他5種模型。
其中,模型1~5分別為SE-CNN-BiLSTM、LSTM、GRU、CNN-LSTM、CNN-BiLSTM模型,主模型為DSE-CNN-BiLSTM模型[15]。
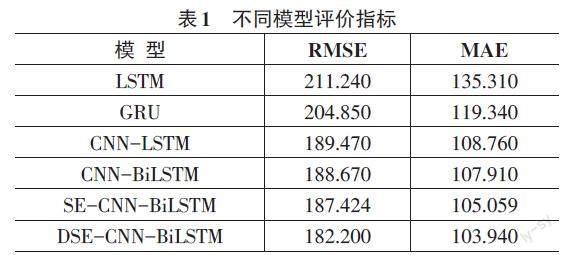
表1為6種模型對15min尺度的石墨電極位移預測評價指標值。從表1中可以看出,本文所提出的模型誤差低于其他5種模型誤差,對石墨電極位移可以更好地預測。
4 結束語
本文提出了一種引進注意力機制下的CNN和BiLSTM混合石墨電極位移預測模型。在傳統SE注意力機制中加入了并行模塊,通過加入最大池化操作來更好地挖掘重要的輸入信息。通過大量實驗和研究表明,基于DSE-CNN-BiLSTM模型相比傳統SE-CNN-BiLSTM和市面上主流的4種預測模型有著更高的預測精度,更小的誤差,對于石墨電極位移的預測有著更有效的預警意義。
參考文獻:
[1] 顧鵬,馮俊杰,張勝恩.內串石墨化爐爐體的優化與改進[J].炭素技術,2019,38(5):64-67.
[2] 劉炳強,趙修富,馬廣禧.淺談內串石墨化送電曲線的制定與調整[J].炭素技術,2010,29(5):41-43.
[3] 曲麗萍,曲永印,薛海波.石墨化爐人工神經網絡預測控制的研究[J].控制工程,2006,13(5):466-468.
[4] 姜潮陽,文克,劉予湘,等.BP神經網絡在預焙陽極生產中的應用[J].炭素技術,2001,20(1):38-41.
[5] 蘇志同,吳佳龍.預焙陽極配方焙燒塊質量預測模型研究[J].計算機與數字工程,2019,47(8):2066-2069.
[6] 蘇志同,王春雷.基于LSTM的焙燒時序數據的質量預測模型[J].軟件,2020,41(5):105-107,197.
[7] 王永林,白永峰,孔祥山,等.基于CNN-LSTM算法的脫硝優化控制模型研究[J].綜合智慧能源,2023,45(6):25-33.
[8] 楊子民,彭小圣,熊予涵,等.計及鄰近風電場信息與CNN-BiLSTM的短期風電功率預測[J].南方電網技術,2023,17(2):47-56.
[9] JIN K H,MCCANN M T,Froustey E,et al.Deep convolutional neural network for inverse problems in imaging[J].IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society,2017,26(9):4509-4522.
[10] 肖鵬程,徐文廣,張妍,等.基于SE注意力機制的廢鋼分類評級方法[J].工程科學學報,2023,45(8):1342-1352.
[11] 蘇向敬,周汶鑫,李超杰,等.基于雙重注意力LSTM神經網絡的可解釋海上風電出力預測[J].電力系統自動化,2022,46(7):141-151.
[12] YU Y,SI X S,HU C H,et al.A review of recurrent neural networks:LSTM cells and network architectures[J].Neural Computation,2019,31(7):1235-1270.
[13] MOHARM K,ELTAHAN M,Elsaadany E.Wind speed forecast using LSTM and Bi-LSTM algorithms over gabal el-zayt wind farm[C]//2020 International Conference on Smart Grids and Energy Systems (SGES).IEEE,2021:922-927.
[14] 李靜茹,姚方.引入注意力機制的CNN和LSTM復合風電預測模型[J].電氣自動化,2022,44(6):4-6.
[15] SHIRI F M,PERUMAL T,Mustapha N,et al.A comprehensive overview and comparative analysis on deep learning models:CNN,RNN,LSTM,GRU[EB/OL].[2023-06-01].2023:arXiv:2305.17473.https://arxiv.org/abs/2305.17473.pdf.
【通聯編輯:唐一東】
