基于集成學習的松遼盆地砂巖型鈾礦地層巖性自動識別研究
2023-12-26 01:23:56段忠義楊亞新羅齊彬
原子能科學技術 2023年12期
關鍵詞:模型
段忠義,肖 昆,*,楊亞新,黃 笑,姜 山,張 華,羅齊彬
(1.東華理工大學 核資源與環境國家重點實驗室,江西 南昌 330013;2.核工業二四三大隊,內蒙古 赤峰 024000)
北方沉積盆地砂巖型鈾礦作為我國儲量最多的鈾礦類型,區內仍有大面積的鈾異常亟待查證,鈾礦資源勘探潛力巨大[1]。在鈾礦勘查中,地球物理測井數據作為連接地球物理性質變化和地下地質環境的橋梁,是了解地下巖層結構和儲層特征的有效且不可替代的方法。因此,測井數據解釋在鈾礦勘查中具有重要意義[2-3]。對測井數據的分析和挖掘已成為提高勘查效率的重點之一[4-7]。隨著測井勘探技術的發展,在地下地質結構環境多變且復雜的情況下,對測井數據的解釋和地層分析也提出了更高的要求[8-11]。利用測井數據的分析結果對地下空間目標進行準確的識別與劃分是測井資料解釋的重要環節,包括地層結構劃分、沉積相、巖性識別、以及儲層識別等[12-13]。其中巖性識別在理解地質體結構、成礦信息預測等研究中發揮著重要作用[14-15];儲層識別是復雜儲層勘探開發的基礎,儲層的正確表征是降低勘探開發風險的重要手段,可為更好地設計和制定方案提供依據。
巖性識別是測井數據分析的核心,目前廣泛使用的巖性識別方法主要有:傳統巖性識別方法,包括交會圖法[16-18]、概率統計方法[19-20]、聚類分析方法[21-23];機器學習類巖性識別方法,包括支持向量機SVM[24-26]、神經網絡[27-28]、集成學習類方法[29]。傳統的巖性識別、儲層識別方法存在精度、識別效率和泛化能力低等問題[30]。針對異常值、不平衡性和高復雜性的測井數據,傳統的測井解釋方法有很大的局限性。隨著儲層地質條件的復雜性以及測井數據的多樣性和數量不斷增加,主觀的專業知識和經驗無法更好地解釋。在面對復雜且更具挑戰性問題時,機器學習類方法為實現自動化、性能提升提供了新的解決方案,在大量數據中學習復雜的模式和關系方面顯示出巨大的優勢,使得巖性識別、儲層識別有了新的突破[31-33]。
集成學習是通過融合兩個或多個模型的顯著屬性在預測中達成共識的方法,使得最終的學習框架較單個構成模型更全面,減少了誤差和其他因素影響。相對于普通機器學習算法,集成學習算法在數據處理方面有更多優勢,面對復雜度較高的問題,可以增強分類性能的信息融合,以獲取更可靠的決策。基于Boosting的XGBoost模型借助由回歸樹組成的強學習器,引入了正則項與并行計算技術,在提高效率的同時,確保了模型的可靠性[34];基于Bagging優化的SMOTE隨機森林算法借助人工合成少數過采樣技術,解決了數據樣本的不平衡問題[35]。因此,本文采用集成學習算法中的XGBoost和SMOTE隨機森林模型開展砂巖型鈾礦地層巖性識別研究,對松遼盆地的砂巖型鈾礦建立巖性自動識別模型,以模型巖性識別的準確率為評價標準,并與KNN模型和GBDT模型進行對比分析,考察改進集成模型的可行性,以提升我國北方砂巖型鈾礦儲層識別的效率與精度,為實現我國鈾礦資源勘查戰略性突破提供技術支撐。
1 理論與方法
1.1 XGBoost算法
在Friedman[36]提出的Boosting算法基礎上,Chen等[37]通過改進目標函數與優化導數信息,并針對性地處理缺失值和模型過擬合,提出了一種優于GBDT的模型,即XGBoost模型。相較于GBDT,XGBoost精度更高、靈活性更強,并行計算與列抽樣的引入提高了XGBoost的計算效率。
XGBoost的目標函數如下:
(1)
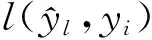
經過t次迭代得到目標函數:
(2)
對式(2)進行二階泰勒展開:
(3)
(4)
1.2 基于SMOTE的隨機森林算法
隨機森林算法屬于集成算法中的Bagging方法,作為一種集成學習方法,它在隨機選擇的數據樣本上構建了許多決策樹。然后從每棵樹上獲得預測,并通過多數投票,選擇獲得多數票的決定。其中構建隨機森林算法模型的步驟如下:1) 從給定數據或訓練集中隨機挑選K個數據點作為隨機樣本;2) 構建與K個數據點相關聯的決策樹;3) 選擇要構建的樹的數量,定義為N,然后重復前兩步;4) 對于一個新數據點,讓已經構建的N棵樹來預測新數據點所屬的類別,并將新數據點分配給贏得多數票的類別。
對于處理高維數據的分類問題,隨機森林表現出不錯的效果,通過Bagging算法彌補了單個決策樹對訓練集噪聲的敏感問題,降低了訓練多棵決策樹存在的關聯問題,有效解決了模型過擬合問題。
針對數據集中出現的分類不平衡問題,采用SMOTE合成少數過采樣技術,在保持樣本各自形態的基礎上進行插值,使各類數據平衡,以此提高少數類的分類精度[38-39],在SMOTE合成鄰近樣本示意圖中,橫縱坐標通常代表數據點的某些特征。假設一個二維數據集的每個數據點都有兩個特征組成:特征1和特征2。這種情況下,示意圖的橫坐標通常代表特征1,縱坐標則代表特征2。具體過程如圖1所示。
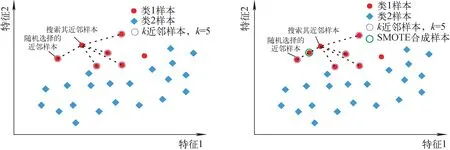
圖1 SMOTE合成鄰近樣本(據Chawla等[39])Fig.1 SMOTE composite adjacent sample (modified from Chawla et al[39])
2 建模與應用
本文以我國北方松遼盆地典型砂巖型鈾礦區為研究對象,砂巖型鈾礦地球物理測井資料為基礎數據,提取研究區目的井次2 860個數據點作為訓練數據集,1 270個數據點作為驗證數據集。
2.1 樣本構建
根據巖石粒級的粗細程度與綜合測井曲線對巖性進行劃分,依次為黏土、泥巖、粉砂巖、細砂巖、中砂巖、粗砂巖和砂礫巖。以多維數據為樣本進行訓練,劃分巖性作為樣本的可靠分類標簽,結合砂巖型鈾礦中不同巖性在不同地球物理測井數據中的響應規律,進行測井屬性的優選,挑選在砂巖型鈾礦巖性研究中常見的測井曲線作為輸入變量:井徑(CAL)、巖石密度(DEN)、聲波時差(DT)、放射性(γ)、自然伽馬(GR)、三側向電阻率(LLD3)、視電阻率(RT)、自然電位(SP)共8條曲線[40],每種巖性的不同測井曲線幅值差異如表1所列。
由表1可知,巖石的致密程度與各物性參數存在一定的相關性,如密度和視電阻率隨巖石粒級的增加呈增長趨勢,聲波時差則相反;自然伽馬數值相對較高,但在中砂巖中存在局部高自然伽馬值,表明研究區含礦主巖為砂巖。對于同巖性的巖石,其數值變化范圍較大。泥巖一般放射性伽馬值相對較高,砂巖放射性伽馬值相對較低。但從粉砂巖、細砂巖以及中砂巖的自然伽馬值來看,出現了部分高自然伽馬值,指示一定的鈾礦異常或礦化特征。
為了進一步分析巖性類別在測井變量組合之間的區分度,通過交會圖分析測井響應參數對巖性儲層的敏感性,結果如圖2所示。
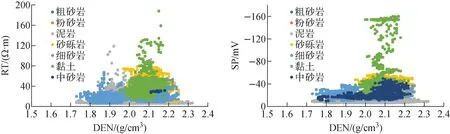
圖2 二維測井參數交會圖Fig.2 Cross plot of two-dimensional logging parameters

a——密度校深曲線;b——視電阻率校深曲線圖3 曲線校深圖Fig.3 Corrected depth chart
由圖2可看出,在二維測井交會圖中,巖性樣本點的分布越離散,對巖性的區分度越好。黏土較其他3種巖性分區明顯,其密度相對較高,聚集程度較高,而粉砂巖、中砂巖、細砂巖與粗砂巖重疊在一起,不易分類。總體來看,二維測井曲線交會圖不能很好地劃分砂巖型鈾礦巖性,故需要采用分類功能更全面的集成學習法來進行精確巖性劃分。
2.2 數據處理
1) 曲線校深與曲線濾波
測井過程中,受地下地質環境客觀因素以及操作方法等影響,測井響應值在深度上存在不一致性,不能有效完成后續處理解釋工作。本文采用CIF Log2.1測井軟件中的數據預處理模塊對工區原始測井數據進行校深和濾波,使同一口井中所有測井數據之間的深度關系保持一致,以滿足后續測井資料處理與訓練要求,具體過程如圖3所示。濾波采用10點移動平均濾波以過濾序列中的高頻擾動,保留有用低頻趨勢。
2) 標準化
在利用集成算法進行巖性識別時,不同類型的測井曲線具有不同的量綱和數量級,其差異性會對模型的識別精度產生影響[41]。本文采用Scikit-learn中的StandardScaler模塊對數據的特征維度進行去均值和方差歸一化,使數據符合正態分布,轉化函數如下:
(5)
其中:μ為所有樣本的均值;σ為所有樣本數據的標準差。
2.3 模型應用與對比
1) 模型參數設置
對于由XGBoost模型建立的巖性識別模型,可以根據其高度的靈活性優勢,自定義優化目標和評價標準,在參數調優過程中,除通用參數和學習目標函數外,對模型預測結果影響較大的參數是學習率(learning_rate)和樹的最大深度(max_depth)。
在初始化模型參數時,盡量讓模型的復雜度較高,然后通過網格搜索GridSearchCV超參數空間調優來降低模型復雜度。學習率和最大迭代次數這兩個參數的調優是聯系在一起的,學習率越大,達到相同性能的模型所需要的最大迭代次數越小;學習率越小,達到相同性能的模型所需要的最大迭代次數越大。XGBoost每個參數的更新都需要進行多次迭代,因此,學習率和最大迭代次數是首先需要考慮的參數,且學習率和最大迭代參數的重點不是提高模型的分類準確率,而是提高模型的泛化能力。因此,當模型的分類準確率很高時,最后一步應減小學習率的是調節樹的最大深度,以提高模型的泛化能力,逐步降低模型復雜度。調參過程如圖4所示,其中,縱坐標為數損失函數(Log Loss),用于衡量模型對真實標簽的概率預測與實際標簽之間的差異,較小的學習率通常需要在模型中添加更多的樹,可以通過調整參數組合來探索這種決策關系;橫坐標表示樹的最大深度,從5~40不等;學習率從0.1~0.5不等,max_depth有8個變量,learning_rate有5個變量。每個組合使用10倍交叉驗證進行評估,因此共需要訓練和評估400個XGBoost模型。調參目標是針對給定的學習率,使性能隨樹的數量的增加而提高,然后穩定下來。由于算法或評估過程的隨機性或數值精度的差異,結果可能會有所不同,需要多次運行并比較平均結果,多次迭代后將輸出每個評估的最佳組合以及對數損失函數。最終可以得到最佳結果的學習率為0.2,樹的最大深度為10。
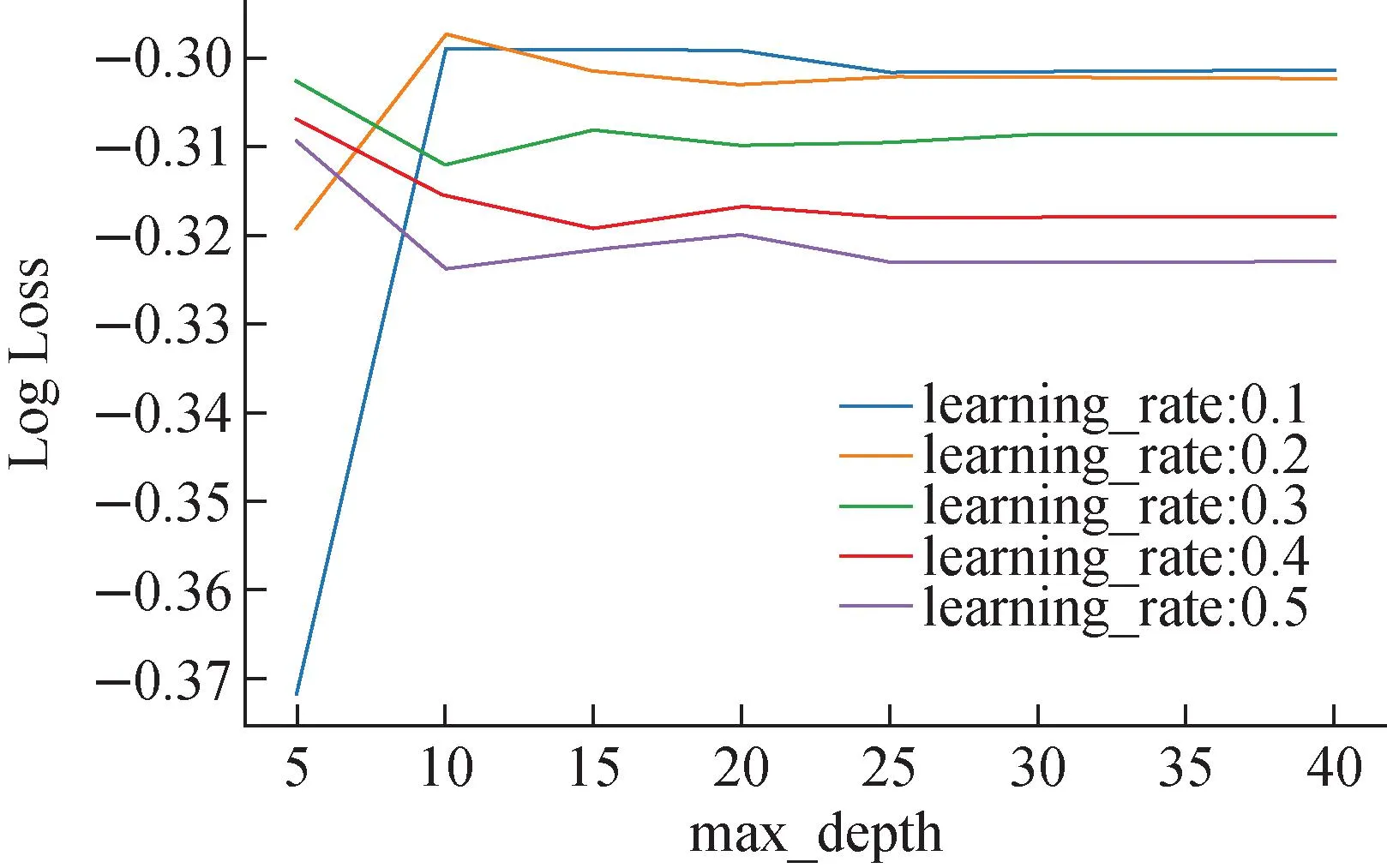
圖4 學習率和樹最大深度的變化Fig.4 Learning_rate and max_depth tendency chart
在構建提升樹之后,檢索每個屬性的重要性分數。通常,重要性分數反映的是每個特征在構建模型內的增強決策樹中的有用性或價值。使用決策樹做出關鍵決策的屬性越多,其相對重要性就越高,為數據集中的每個屬性明確計算此重要性,允許對屬性進行排名和相互比較。單個決策樹的重要性是通過每個屬性分割點改進性能度量的量計算的,由節點負責的觀察數加權。性能度量可以是用于選擇分割點的純度(Gini指數)也可以是另一個更具體的誤差函數。對于集成模型中的多棵決策樹,可以計算每個決策樹的特征重要性,并對所有決策樹的特征重要性取平均值,以此更全面地評估特征的重要性。
使用的內置XGBoost特征重要性圖,因算法或評估程序的隨機性或數值精度的差異而有所不同,因此多次運行該示例,并比較平均結果,如圖5所示,其中橫坐標F score表示每個特征的重要性得分,衡量的是特征在模型中的相對重要程度;縱坐標Features表示測井特征參數。從圖5可知,重要性相對較高的特征參數為CAL和DEN。
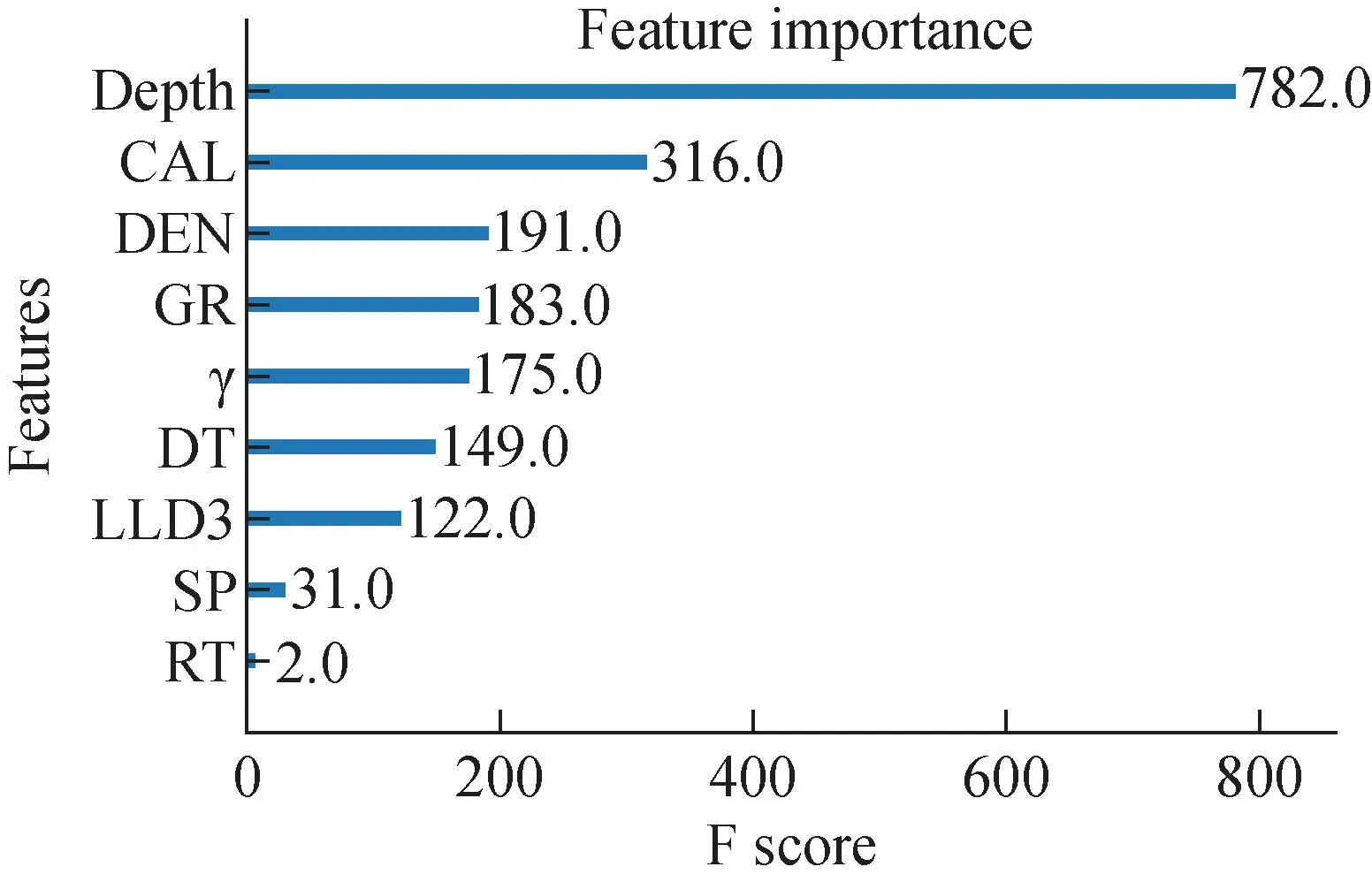
圖5 XGBoost特征重要性篩選Fig.5 XGBoost feature importance screening
2) 模型預測結果及與真實結果的對比
經過模型參數調整和交叉驗證后,兩種模型樣本測試集中的巖性分類結果如圖6所示,其中橫坐標為巖性:1,粗砂巖;2,粉砂巖;3,泥巖;4,砂礫巖;5,細砂巖;6,黏土;7,中砂巖。用混淆矩陣分析模型的分類結果,按照真實類別與模型預測類別兩個標準進行統計,最終以矩陣形式呈現。其中矩陣的行表示真實值,矩陣的列表示預測值。

圖6 混淆矩陣預測數據Fig.6 Confusion matrix prediction data
上述混淆矩陣的每個單元格(i,j)表示模型將真實類別為i的樣本預測為類別j的數量,觀測值在對角線位置,數值越多越好;反之,在其他位置出現的觀測值則越少越好。對于7種巖性,兩種集成模型都表現出較好的識別效果,其中泥巖和細砂巖的分類結果與其他巖性的差異明顯,XGBoost模型略優于SMOTE隨機森林模型。
受試者工作特征(ROC)曲線是模型的另一種評價指標,ROC曲線下與坐標軸圍成的面積(AUC)用于衡量分類模型的準確性。ROC曲線反映的是不同閾值下真正例率和假正例率之間的權衡關系。在ROC曲線中,完美測試的AUC值為1,表示模型在所有閾值下都能完美區分正例和反例。對角線表示隨機猜測的模型性能,即真正例率等于假正例率。利用所計算的AUC值,可以衡量分類器在不同閾值下的整體性能,面積越大,表示模型的分類準確性越高。ROC曲線越接近左上角,說明模型在預測樣本為正樣本的同時還盡可能地減少了錯誤分類。采用XGBoost模型和SMOTE隨機森林模型所得ROC曲線如圖7所示。由圖7可知,兩個模型的ROC曲線都靠近左上角的點,且AUC值均大于0.7,說明兩種模型都具有較高的診斷價值,最佳邊界點是曲線最靠近左上角的點,其中XGBoost模型最佳邊界點的敏感度為0.8,特異度為0.25。SMOTE隨機森林模型最佳邊界點的敏感度為0.6,特異度為0.26。可見XGBoost模型較SMOTE隨機森林模型診斷價值更高,整體預測結果更優。
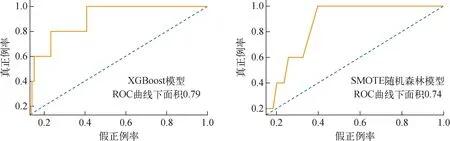
圖7 ROC曲線Fig.7 ROC curve
為了檢驗本文所建立的集成模型的準確性,將XGBoost模型與SMOTE隨機森林模型的識別結果與KNN模型和GBDT模型的識別結果進行對比。利用CIFLog2.1測井軟件繪制部分井段鉆井取心的巖性剖面與模型預測剖面,如圖8所示。從圖8可知,XGBoost模型和SMOTE隨機森林模型能更準確地對地層不同巖性做出響應,與鉆井取心的巖性剖面的對比可知,XGBoost模型和SMOTE隨機森林模型對于砂巖型鈾礦巖性的識別較其他模型更準確。針對巖性連續變化的井段,XGBoost模型的巖性識別效果與鉆井取心巖性剖面基本一致,SMOTE隨機森林模型的巖性識別效果與鉆井取心巖性剖面絕大部分對應較好,但對于少部分數據集較少的井段會出現巖性不對應的情況,這是因為隨機森林算法對于小數據或低維數據(特征較少的數據),不能達到很好的分類效果。而KNN模型和GBDT模型在面對高維數據和不平衡數據時所表現出的局限性,導致部分巖性不能準確對應,識別效果與XGBoost模型和SMOTE隨機森林模型相比較差。各模型的運行時間和準確性如表2所列。
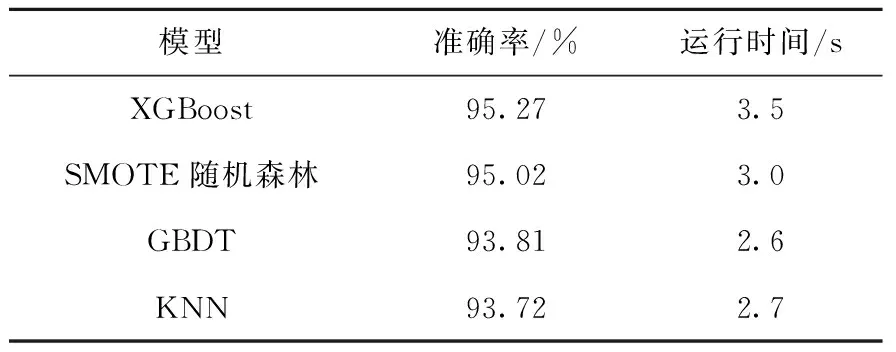
表2 各模型的準確率和運行時間Table2 Accuracy and running time of each model
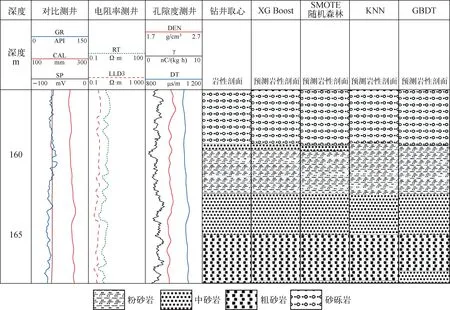
圖8 單井段巖性識別效果Fig.8 Single well interval lithology identification result
由表2可知:XGBoost模型的識別效果最好,準確率高達95.27%,其次是SMOTE隨機森林模型,準確率為95.02%;GBDT模型和KNN模型的分類效果較弱,準確率分別為93.81%和93.72%。XGBoost模型之所以準確率最高,在于XGBoost模型采用并行計算技術使得多個弱分類器組合進行學習,模型學習的結果優于以決策樹作為基學習器的GBDT模型,同時還借鑒了隨機森林的列抽樣,降低過擬合。從運行時間來看,基于模型本身的原理簡單,模型訓練較快來考慮,KNN模型和GBDT模型所用時間較短。整體上,XGBoost模型和SMOTE隨機森林模型優于KNN模型和GBDT模型,這是因為集成學習通過不同方法改變原始訓練樣本的分布構建分類器,最終集合弱分類器成強分類器,并且在每輪迭代中使用內置交叉驗證,方便獲得最優迭代次數,減少了計算量,提高了模型準確率。其中Boosting方法每次迭代時訓練集的選擇與前面各輪的學習結果有關,而且每次通過更新各樣本權重的方式來改變數據分布;Bagging方法每次迭代前,采用有放回的隨機抽樣來獲取訓練數據,這使得每次迭代不依賴之前建立的模型,生成的各弱模型之間沒有關聯,可以徹底實現訓練數據之間的并行訓練。
3 結論
1) 通過測井資料和交會圖分析,確定了與模型相關的8條曲線作為輸入變量,并運用模型評價指標對兩種集成學習模型進行評估,驗證了模型的可行性;利用網格搜索GridSearchCV從超參數空間尋找最優的參數組合,運用10倍交叉驗證結合參數組合,通過迭代確定了初步最優化模型。
2) XGBoost模型對損失函數添加正則項以及二階泰勒展開,彌補了傳統Boosting算法的缺陷,提升了優化效果,通過對缺失值切分方法的優化,使得每個特征的缺失值學習到一個最優的切分方向,特征的正確排序與分割結合多線程并行極大提高了運算準確率。
3) Boosting和Bagging兩種集成學習在預測分類中都表現出不錯的性能,XGBoost模型對砂巖型鈾礦地層巖性識別的準確率最高,達到了95.27%,SMOTE隨機森林模型次之,KNN模型的識別效果最差。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
