基于特征選擇和改進K-均值聚類的異常用電行為檢測算法
2023-12-27 13:05:02楊利辛黃曉波李凱
計算技術與自動化 2023年4期
楊利辛,黃曉波,李凱
(1.南方電網能源發展研究院有限公司,廣東 廣州 510000; 2.南方電網數字電網集團有限公司, 廣東 廣州 510000;3.廣東電網有限責任公司,廣東 廣州 510000)
竊電等異常用電行為是造成電力系統非技術性損失的主要原因,給電網的安全、穩定和可靠運行帶來嚴重威脅。傳統異常用電行為檢測采用人工巡檢方式,需要消耗大量的人力物力資源,已不能滿足實際需求[1]。近年來,隨著我國智慧電網的建設和發展,電力公司在發電、輸電、配電和用電端安裝和部署了大量的智能電表等數據采集傳感器,這些傳感器可以按每天數十次的頻率采集和記錄電力系統各個環節的相關數據,這些數據中隱含著不同用戶用電行為信息,也為異常用電行為檢測提供了間接的“證據”[2],如何對這些信息進行有效挖掘利用,從而快速、準確地定位異常用電行為,是電力企業亟待解決的一個難題,也是當前研究的熱點[3-5]。
目前基于數據驅動的異常用電行為檢測方法總結起來可以分為有監督類方法和無監督類方法2類[6],兩者的主要差異在于是否需要帶標簽的數據集用于模型訓練,其中有監督類方法以支持向量機(Support Vector Machine, SVM)、隨機森林和卷積神經網絡等方法為代表,利用帶標簽數據集完成最優模型參數的學習,進而利用最優模型對未知用戶用電行為進行異常判決[7-9]。文獻[10]提出一種基于SVM的異常用電行為檢測模型,為了提升檢測性能,利用決策樹對SVM核函數進行優化,基于某臺區電力用戶真實用電數據驗證了該方法的有效性;文獻[11]將隨機森林算法應用于異常用電行為檢測領域,并構建Hadoop分布式計算框架以提升算法實時性;文獻[12]利用卷積神經網絡挖掘電力用戶用電量序列中的時間相關性信息,并建立分類模型實現對正常和異常用電行為的分類判決。上述有監督異常用電檢測模型由于用到了帶標簽訓練樣本集,通常能夠獲得較高的異常檢測性能,然而根據生產生活經驗可知,海量電力用戶中異常用戶占比很低,通常難以獲得足夠多異常用電行為對應的訓練樣本,限制了該類方法在實際中的應用[13]。無監督類方法不需要訓練樣本,基于相似性原理對數據進行自動劃分聚類,大多數正常用電數據會表現出一定的聚集性,而異常用電數據通常會以離群點的形式存在,無監督類方法以K-均值聚類,基于密度的帶噪聲空間聚類(Density-Based Spatial Clustering of Application with Noise, DBSCAN)等方法為代表,文獻[14]采用K-均值聚類對電力用戶用電量特征進行聚類分析,針對真實數據獲得了優于85%的異常用電行為檢測查準率;文獻[15]針對異常用電行為在線實時檢測需求,利用DBSCAN方法對用電趨勢特征進行實時聚類分析,最終獲得了優于87.5%的檢測正確率。無監督類方法不需要帶標簽訓練數據,大大降低了數據獲取難度,且具有算法簡單容易實現等優點,缺點是聚類性能對模型參數具有較強的依賴性,而參數選取往往并非易事[16,17]。
在此基礎上,提出了一種基于特征選擇和改進K-均值聚類的無監督異常用電行為檢測模型,首先從用電量變化,線路損耗和電力參數三個維度提取15維特征構成特征向量,實現高維用電數據的降維表征,然后利用相關向量機(Relevance Vector Machine, RVM)進行特征選擇自動確定最優特征集合,同時進一步實現數據降維,最后提出一種基于信息增益的改進K-均值聚類算法對最優特征集合進行聚類分析,實現異常用電檢測。相對于傳統K-均值,所提方法能夠自動確定聚類個數和初始聚類中心,從而提升聚類性能。基于愛爾蘭智能電表公開數據集開展實驗,并從精準率、召回率和ROC曲線AUC值三方面對所提方法的性能進行定量分析。
1 用電行為的特征表示
1.1 特征提取
智慧電網背景下,電力企業利用線路參數采集設備和智能電表等電能計量設備獲得輸電線路側和用電側的海量數據,這些數據中隱含著與用電行為相關的有用信息,同時也不可避免地會存在大量噪聲、干擾等無用信息,要從海量高維數據中挖掘出有用信息,實現去偽存真,特征提取是關鍵[18]。特征提取是指從原始高維數據中抽象凝練出一些能夠表征異常行為的特征參數,這些特征是原始數據的一種降維表征,能夠較好地描述不同用電行為之間的差異性,大大降低后續數據處理的難度。
通過對大量正常和異常用電行為數據進行分析,發現正常用戶的用電量變化曲線存在一定周期性,并且線路損耗和電壓電流值較為平穩,而異常用電行為的用電量通常表現出逐漸下降的趨勢,同時線路損耗值較大,電壓電流也會出現較大波動,因此從用電量變化趨勢、線路損耗和電壓電流波動三個方面提取表1所示15維特征構成特征向量。
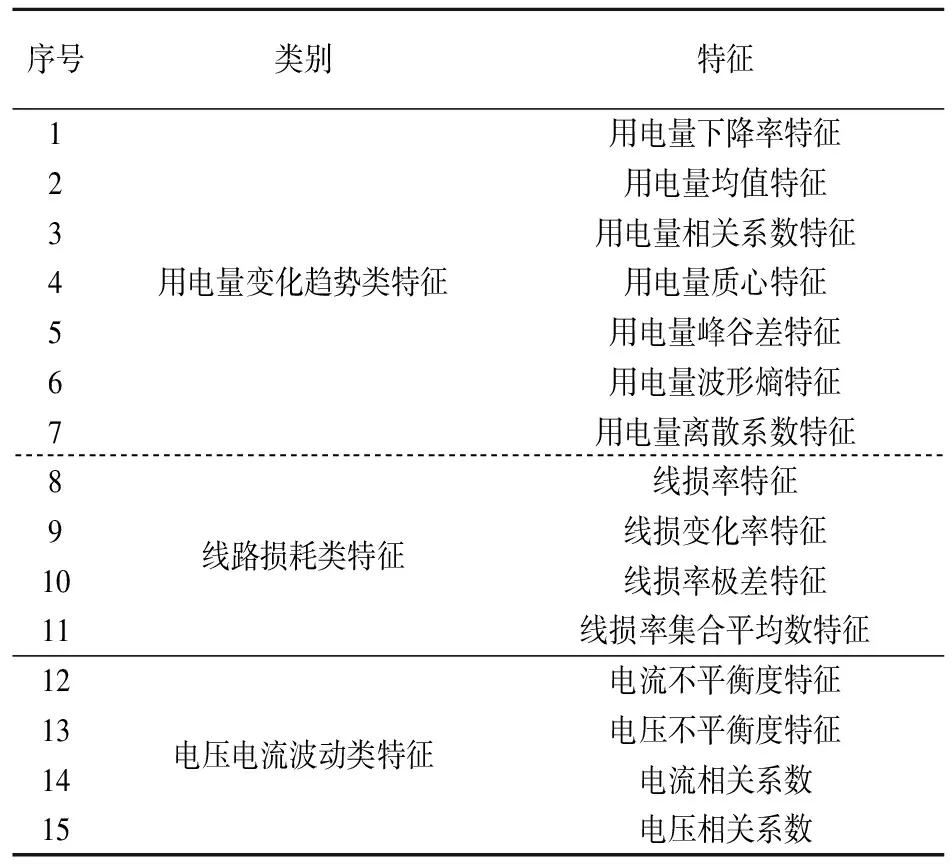
表1 特征向量組成
1.2 基于RVM的特征選擇
按照傳統的異常檢測模型,特征提取完成后需要進行分類器設計從而實現對不同用電行為的分類判決。然而,當前的特征提取過程與分類器設計過程是相互獨立的,特征提取過程并沒有考慮所提特征對于分類器而言是否最優,并且主觀提取的特征通常含有較多冗余信息,這些信息不僅對異常用電檢測沒有幫助,反而會誤導分類器訓練,因此有必要進行特征選擇,從特征向量中確定最優特征集合,從而提升分類性能。RVM是在SVM基礎上發展起來的一種基于貝葉斯框架的概率模型,相對于SVM具有更強的稀疏性,能夠實現特征選擇與分類器設計的聯合優化,因此本文選擇RVM對上述15維特征進行進一步分析,以獲得最優特征集合。利用RVM進行特征選擇的模型可以表示為:
(1)
其中,fm為第m個電力用戶對應的特征向量,K(f,fm)為核函數,w=[w1,w2,…,wm)]T為權向量,ε為數據中的噪聲成分,為了構建完整的貝葉斯模型,分別對權向量和噪聲成分進行概率模型設計,合理的概率模型為高斯分布[19],即w服從均值為零,協方差矩陣為α-1I的高斯分布,ε服從均值為零,協方差矩陣為γ-1I的高斯分布。
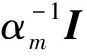
2 異常用電行為檢測模型
K-均值聚類是一種經典的基于劃分的聚類方法,被廣泛應用于異常檢測領域。然而,傳統K-均值的聚類性能與聚類數目K和初始聚類中心的設置密切相關,目前常用的基于專家知識庫或先驗信息的方法存在主觀性強且適應性差的問題。為了解決該問題,本文提出一種基于信息增益確定最優聚類個數的方法,同時考慮到K-均值是以歐式距離遠近作為聚類劃分準則的方法,選取空間密度最大的K個樣本作為初始聚類中心,通過信息增益和樣本空間密度的方式自動確定K-均值聚類的聚類個數和初始聚類中心,從而提升聚類性能。
所提改進K-均值聚類涉及的相關概念為:
定義1:特征空間的信息熵
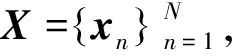
(2)
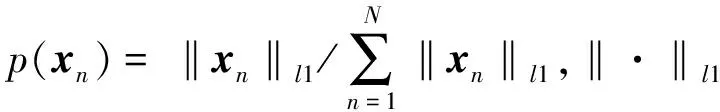
定義2:聚類后第k個子類的信息熵
根據式(2)給出的樣本空間信息熵定義,可以進一步得到聚類后第k個子類的信息熵為:
(3)
其中,Ck為第k個子類對應的特征序號集合。
定義3:聚類后的信息增益
假設聚類后得到K個子類,則該聚類對應的信息增益定義為:
定義4:樣本xn的空間密度dist(xn)
(5)
其中,‖·‖l2表示求變量的l2范數。
在上述定義的基礎上,所提改進K-均值聚類的具體算法流程可以總結為:
輸出:聚類結果和異常檢測結果。
算法流程:
設置聚類個數k=1,
步驟2:根據式(3)計算得到聚類個數為k情況下的信息熵Ek;
步驟3:根據式(4)計算得到此時的信息增益Ik,并將其記錄;
步驟4:令k=k+1,重復步驟1~步驟3,指導k=Kmax;
步驟5:選擇步驟3記錄的所有信息增益的最大值對應的k作為最優聚類個數K;
步驟6:選取空間密度最大的K個特征作為初始聚類中心;
步驟7:將特征空間中非聚類中心特征按照歐式距離的劃分至與其距離最近的聚類中;
步驟8:按式(6)計算得到新的聚類中心
(6)
其中,nk為第k個子集中的特征個數。
步驟9:根據步驟8得到新聚類中心對特征空間進行重新劃分,若相鄰兩次劃分得到的結果一致,則認為算法收斂,否則重復步驟7和步驟8。
3 實驗結果與分析
3.1 實驗數據
本部分內容中,采用愛爾蘭智能電表記錄的公開數據集開展驗證實驗,對所提方法的異常檢測性能進行驗證,該數據集來源于愛爾蘭Commission for Energy Regulation,本意是為智能電網研究提供相應的數據支撐,也是目前異常用電行為檢測領域應用最廣的數據集,該數據集的使用方式和下載地址見[21]。該數據集包括534個電力用戶536天的用電量數據,其中正常用戶數量為521,異常用戶數量為13,數據記錄頻率為30 min一次,異常用戶已被提前標準,由于本文方法為無監督方法,所以異常用戶標簽僅用于模型評估,不在檢測過程中使用。
采用精準率(Precision),召回率(Recall)和接收機工作特性曲線(Receiver Operating Characteristic, ROC)對應的AUC值三項指標定量評估所提模型的異常檢測性能,其中精準率和召回率的定義為:
(7)
其中,TP表示將異常用戶檢測為異常用戶的樣本數量,TN表示將正常用戶檢測為正常用戶的樣本數量,FP表示異常用戶檢測為正常用戶的樣本數量,FN表示將正常用戶檢測為異常用戶的樣本數量。
ROC曲線是以虛警概率和檢測概率為橫縱坐標繪制而成的一條用于評估分類模型性能的曲線,通常用ROC曲線與直線y=1之間區域的面積值AUC作為ROC曲線的量化指標,AUC值越大,表明分類模型性能越好。
3.2 實驗結果與分析
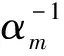
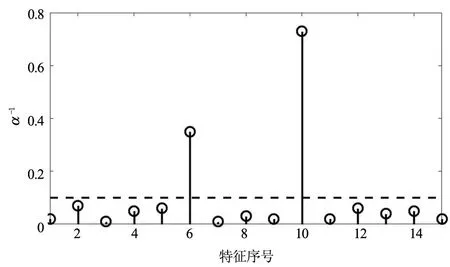
圖1 RVM特征選擇結果
獲得最優特征集合后,將其作為改進K-均值聚類的輸入進行自動聚類分析,實驗中設置最大聚類個數Kmax=8,根據改進K-均值聚類步驟進行聚類分析得到的信息增益隨聚類個數k的變化曲線如圖2所示,可以看出,當k=3時,信息增益最大,即最優聚類個數K=3。圖3(a)給出了所提方法得到的最終聚類結果,為了對比圖3(b)給出了傳統K-均值聚類得到聚類結果,可以看出所提方法獲得的聚類結果呈現出較好的聚集性,類內數據分布較為集中,類間數據分布較為疏遠,聚類結果較為理想,同時類別3即所提方法獲得異常用電行為聚類,而傳統K-均值聚類結果獲得的最優聚類數為K=4,將圖3(a)中的聚類1又分為了3個子類,但是將圖3(a)中聚類2和聚類3劃分為同一個子類,該聚類結果無法直接進行異常用電行為檢測,需要聯合其他手段才能實現對聚類3中異常用電行為的定位,增加了模型的復雜度。
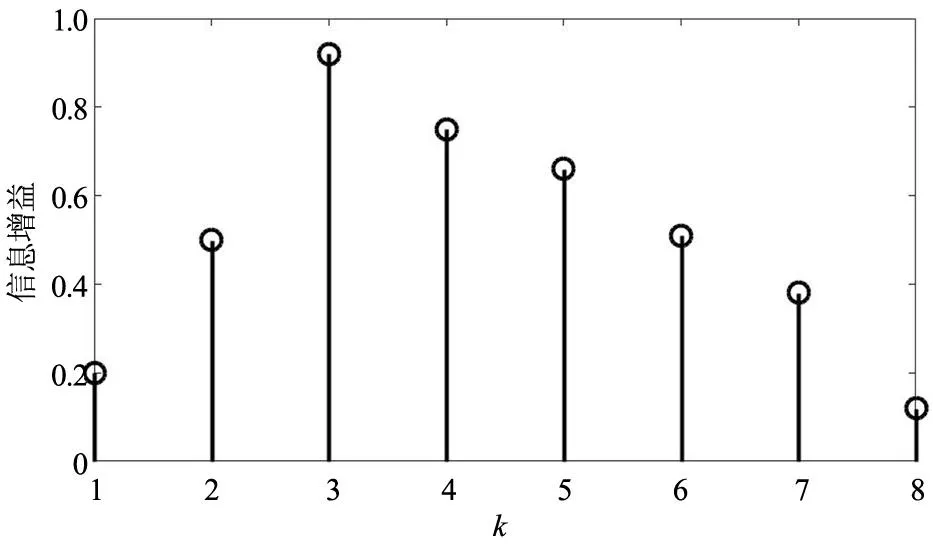
圖2 信息增益隨聚類個數變化
(a)所提改進K-均值聚類
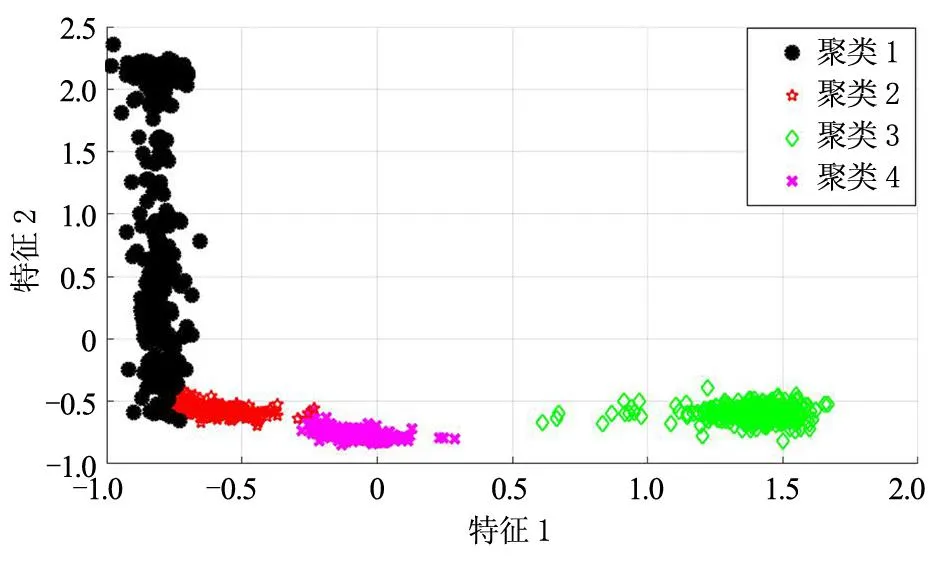
(b)傳統K-均值聚類
圖4給出了所提方法的ROC曲線,同時為了對比,圖4中給出了在相同條件下采用文獻[15]所提方法得到的異常檢測結果,可以看出在同一個坐標系內,所提方法的ROC曲線位于文獻[15]提出方法的左上方,與直線y=1圍成的面積更大、性能更優。表3給出了兩種方法的精準率、召回率和AUC值三項指標,可以看出,本文所提方法的精準率,召回率和AUC值三項指標均優于文獻[15]方法,精準率提升3.58%,召回率提升2.77%,AUC值提升3.75%,具有更優的異常檢測性能。
除了上述精準率、召回率和AUC值三項指標外,復雜度和實時性也是評估異常檢測算法性能的一個重要方面,表3中最后一列給出了所提方法和文獻[15]方法完成異常檢測所需的時間對比結果,可以看出所提方法在獲得更優異常檢測性能的同時,實時性也略優于文獻[15]方法,究其原因在于,所提方法通過特征選擇流程實現了數據降維,有效降低了后續異常檢測算法的復雜度,提升了實時性。
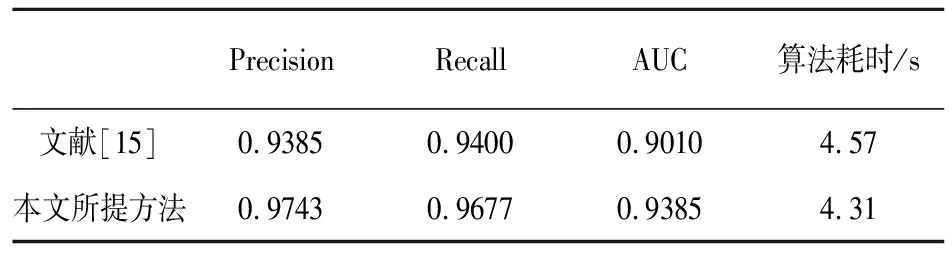
表3 不同方法異常檢測結果
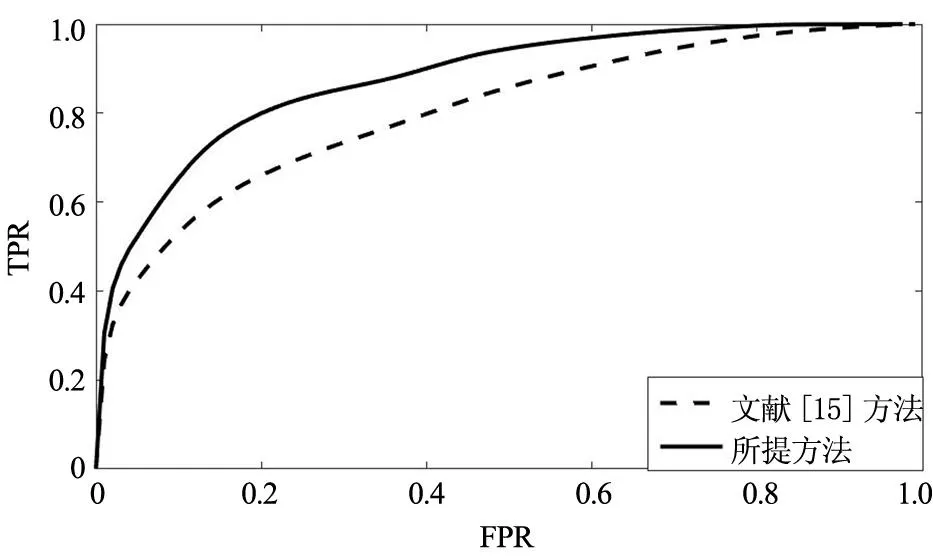
圖4 不同方法ROC曲線
4 結 論
K-均值聚類算法具有算法簡單、容易實現、不需要訓練數據集等優點,被廣泛應用于異常用電檢測領域。K-均值聚類性能受最優聚類個數和初始聚類中心的選擇影響較大。針對該問題,提出了一種基于RVM特征選擇和改進K-均值聚類的異常用電行為檢測算法。利用RVM對提取的15維用電量變化、線路損耗和電力參數特征進行自動特征選擇,確定2維最優特征向量,然后利用改進的K-均值聚類進行聚類實現異常檢測,改進后的K-均值聚類算法利用信息增益和樣本的空間密度自動確定最優聚類個數和初始聚類中心,能夠有效提升聚類性能。基于愛爾蘭公開數據集的實驗結果表明,所提方法的精準率、召回率和AUC值三項指標均優于對比方法。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
