ChpoBERT:面向中文政策文本的預訓練模型
2024-01-03 09:10:12沈思陳猛馮暑陽許乾坤劉江峰王飛王東波
情報學報 2023年12期
沈思,陳猛,馮暑陽,許乾坤,劉江峰,王飛,王東波
(1. 南京理工大學經濟管理學院,南京 210094;2. 南京農業大學信息管理學院,南京 210095;3. 江蘇省科技情報研究所,南京 210042)
0 引 言
政策文本是政府政策行為的反映,也是記錄政策發展走勢、政策意圖的重要載體,而政策文本研究則是觀察、梳理政策過程的重要途徑[1]。對于政策文本的類別,Chilton等[2]從3個層面進行了劃分,本研究的政策文本主要為“政府或國家或地區的各級權力或行政機關以文件形式頒布的法律、法規、部門規章等官方文獻”。目前,政策文本研究主要分為兩類:定性研究與定量研究。其中,定性研究要求研究者擁有較高的實踐經驗和分析能力[3],而定量研究則需要研究者擁有大量的數據和高性能的計算模型。隨著我國治理體系的不斷完善和政府信息公開化的發展,政策文本研究所能獲取的數據量愈加龐大,分類體系愈加復雜,同時相應增長的還有定性分析所需的人力成本。在數據驅動下的政策文本研究中,將政策文本轉換為結構化的數據,再基于相應的機器學習模型進行計算和分析,這種定量研究的方法極大降低了人力成本,成為政策文本研究的發展趨勢[3]。當前,政策定量化研究的內涵越來越豐富,涌現出政策文本計算、政策計量、政策文獻計量等研究方向[4-7]。政策文本計算主要通過自然語言處理、機器學習、可視化技術等進行政策文本分析,其中在機器學習方面,比較受關注的是深度學習領域的預訓練語言模型技術。2003年,Bengio等[8]提出NNLM模型(neural network lan‐guage model),神經網絡技術開始被用于語言模型的構建。在此基礎上,word2vec[9]、GloVe[10]模型進一步優化性能,靜態詞向量的誕生使神經網絡方法大規模應用于自然語言處理成為可能。隨著深度學習的發展,CNN(convolutional neural network)、RNN(recurrent neural network)和LSTM(long short-term memory)等神經網絡模型誕生[11-13]。2018年,Google基于Transformer編碼器提出了BERT(bidirectional encoder representations from transform‐ers)模型[14],其在預訓練方法上的創新推動了預訓練模型的發展。在BERT模型的基礎上,Facebook AI團隊推出了RoBERTa[15]模型。由于其突出的性能,BERT與RoBERTa模型被廣泛應用于自然語言處理研究,提高了自然語言處理理解和文本挖掘研究的整體水平。隨著深度學習技術的不斷發展,政策文本研究與深度學習的關聯也愈發密切。已有學者通過具體探究驗證了深度學習技術和預訓練模型對政策文本研究的推動作用[16-18]。
目前,針對政策全文本數據的預訓練模型構建尚處于起步階段,為了提升政策文本領域知識挖掘的整體性能,本研究通過爬取259個政府官方網站的政策文本構建了較為完備的中文政策全文本數據集,在數據集上繼續預訓練獲得了關于中文政策文本的預訓練模型,彌補了在中文政策文本研究上預訓練模型的缺失,且在3個自然語言處理的下游任務上模型的性能得到了驗證。
1 研究回顧
在大數據時代,對海量的政策文本進行深度挖掘和利用成為一個亟待解決的重要問題。通過對已有政策研究的梳理可以發現,政策文本方面的研究已從定性分析逐漸轉移到定量分析。政策文本量化通過一系列的轉換范式將非結構化政策文本轉換為抽象化、特征化的計算機可處理的結構化數據[19]。近年來,在數據驅動研究范式的推進下,預訓練技術與政策文本相結合逐漸成為政策文本知識挖掘的主流趨勢。
政策文本知識挖掘主要通過機器學習挖掘政策文本中所蘊含的知識,實現政策文本的智能化分析,在一定程度上彌補了內容分析法和文獻計量方法研究的不足。在傳統機器學習和自然語言處理基礎上的政策文本知識挖掘代表性研究如下。在對政策文本進行自動分詞的基礎上,王晶金等[20]借助政策分析工具,對兩份科技成果轉移轉化的部委政策文本進行了分析,針對科技成果轉移轉化過程中存在的缺陷提出了有效的建議。基于科技政策的功能定位和用語特征,鄭新曼等[21]通過PMI(pointwise mutual information)和TextRank算法構建了科技政策文本的程度詞典。通過把自然語言處理技術融入政策文本,魏宇等[22]構建了基于語義分析的政策量化模型,借助所挖掘出來的語義知識分析了中央及地方的旅游交通政策的外部屬性和內部結構的差異。基于LDA(latent Dirichlet allocation)模型,Du等[23]考察了4種JPCAP(joint prevention and control of atmospheric pollution)政策中政策強度對大氣污染物排放的影響,并提出了優化對策和解決問題的建議。通過構建LDA主題模型和k-means聚類模型,Song等[24]識別了食品安全政策中的熱點話題,并從4個方面對中國的食品安全政策進行了分析。基于教師隊伍建設改革的政策文本,杜燕萍[25]通過LDA主題模型的知識挖掘,提出了有針對性的改革對策。上述自然語言處理和文本挖掘技術能夠快速、高效地處理大量的政策文本,在一定程度上彌補了定性方法分析深度不夠和效率低的問題。但隨著政策文本數據的增加及對深度語義知識挖掘需求的提升,把深度學習特別是預訓練模型與政策文本數據結合起來進行知識挖掘,成為獲取深層、多維和細顆粒度知識的關鍵。
神經網絡語言模型(neural network language model,NNLM)是最早的詞嵌入(word embed‐dings)模型。word2vec模型采用無監督的方式學習語義知識,優化了計算效率,被廣泛地應用于工業界。為了彌補word2vec模型難以統計全局信息的不足,GloVe模型進一步利用詞共現矩陣,使得詞向量充分兼顧到語料庫的全局特征,但word2vec和GloVe仍不能解決一詞多義性問題。上下文嵌入模型ELMo(embeddings from language models)通過學習單詞、句法以及語義特征,實現了根據輸入句的上下文語境獲得每個詞的詞嵌入向量。BERT預訓練模型采用雙向語言模型能夠更好地利用上下文的雙向信息,同時基于Transformer結構更好地捕捉全局信息。
從預訓練模型生成的流程上看,預訓練技術一般是在一個基礎數據集上進行任務訓練,生成一個基礎網絡,并通過將基礎網絡學習到的特征進行微調或訓練新的任務,進而解決人工智能相應的下游任務。因此,預訓練模型只需從共性出發,學習特定任務的特征,不僅節省了大量的時間,而且擁有更好的泛化效果。在這一范式下,基于BERT的相應領域化預訓練模型得以構建并應用。圍繞自然科學的學術全文本和人文社會科學摘要,在BERT模型的基礎上,Beltagy等[26]和Shen等[27]分別訓練和構建了SciBERT和SsciBERT模型,并在相應的下游任務上進行了驗證,整體上效果較為突出。Lee等[28]在生物醫學語料庫上對BERT完成了進一步的訓練,構建了BioBERT領域化預訓練模型,同時在生物醫學文本的驗證上取得了較好的成績。在法律文本上,Chalkidis等[29]構建了LEGAL-BERT預訓練模型,并在領域任務上驗證了所構建模型的性能。在金融文本數據上,Araci[30]提出了一種基于BERT的FinBERT用于處理金融領域的NLP(natural lan‐guage processing)任務,并在具體數據集上驗證了FinBERT的效果。楊晨等[31]在BERT的基礎上提出一種側重學習情感特征的預訓練方法,所得到的SentiBERT在情感任務上取得了更優的效果。在藏文文本上,李亮[32]構建了藏文ALBERT預訓練模型,并在分類任務上對模型進行了驗證,效果較為突出。一方面,上述領域化模型的構建為本研究政策文本預訓練模型的構建提供了探究視角和方案上的支持;另一方面,為模型具體的訓練提供了方法和技術上的支撐。相關學者已將通用預訓練模型引入與政策相關的研究當中。Zhang等[33]基于《紐約時報》的大規模新聞語料庫對預訓練模型進行微調,提出了一個基于BERT的模型用于預測美國的政策變化。朱娜娜等[34]提出了基于預訓練語言模型的政策識別方法,在小規模數據上獲得了較優的結果。基于預訓練語言模型BERT,關海山等[35]在融入規則的基礎上,實現了在稅收優惠政策法規的表征、關鍵要素抽取和稅收優惠的可視化查詢等多個維度上的探究。在政策文本的知識建模與關聯問答中,華斌等[36]采用BERT語義相似度計算并完成了對答案的評估。上述研究表明,預訓練技術與政策文本研究的融合是大勢所趨,一方面,通過預訓練技術對政策文本進行挖掘,可以更好地獲取政策文本的多維知識;另一方面,通過預訓練模型對政策文本進行識別、分析、表示等處理,可以在更大程度上提高政策文本處理的效率。但當前政策文本領域所使用的預訓練模型均是通用的預訓練模型,缺乏基于大規模政策文本構建的政策文本預訓練模型,本研究對此進行了探究。
2 研究方法
本研究由模型的預訓練和模型的性能驗證兩個部分構成。在預訓練階段,利用掩碼語言模型(masked language model,MLM)和全詞掩碼(whole word masking,WWM)任務分別基于BERT-base-Chinese和Chinese-RoBERTa-wwm-ext模型對政策全文本數據集進行預訓練,模型初步評價的指標為困惑度。在模型的性能驗證階段,通過對比預訓練語言模型和基準模型在自動分詞、詞性標注和命名實體識別上的效果來評判政策文本預訓練模型的性能。
2.1 研究框架
目前,采用領域數據構建預訓練模型的研究通常分為模型的預訓練和模型的性能驗證兩大部分。
在模型的預訓練階段中,實驗步驟設計的整體性呈現如圖1所示。
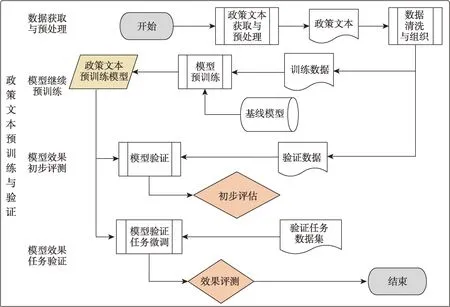
圖1 模型預訓練實驗步驟
(1)數據獲取與預處理。首先,進行系統而全面的調研,確定政策數據源的網站;其次,通過開發Python爬蟲工具,獲取全國及各省市的政策文本數據,進行數據清洗,同時將政策文本的標題與全文作為預訓練數據的基本單元;最后,將所有基本單元合并,并將數據按99∶1劃分為訓練數據集和驗證數據集。
(2)模型預訓練。基準模型使用Huggingface網站(https://github.com/sinovation/ZEN)提供的Py‐torch版BERT-base-Chinese和Chinese-RoBERTawwm-ext,并設定訓練集任務為MLM和WWM。
(3)預訓練模型性能初步測評。在信息論中,困惑度(perplexity)[37]被用于度量一個概率分布或概率模型預測樣本的好壞程度。在語言模型評測中,困惑度被定義為測試集概率的倒數,一般認為困惑度較低時語言模型性能較好。因此,本研究將其作為初步評價預訓練模型性能指標。
2.2 數據源
本研究中預訓練模型構建所使用的政策文本數據來自全國及省市的政策發布平臺,具體包括國家發展和改革委員會、財政部、科學技術部和工業和信息化部,北京、天津、河北等省和直轄市的中小企業公共服務平臺、發改委、財政廳、科技廳、工業和信息化廳,以及深圳、廣州、蘇州等經濟發展前沿城市的中小企業公共服務平臺、發改委、財政局、科技局、工業和信息化局。政策文本按照政策發布平臺劃分為國家級政策文本、省級政策文本與市級政策文本。國家級政策主要著重于宏觀層面、面向全國,且在法律效力上高于省級政策和市級政策,而省級政策和市級政策則根據地方經濟社會發展制定,側重點有所不同。在出現政策內容相矛盾時,市級政策一般服從省級政策,省級政策一般服從國家級政策。不同平臺所發布的政策在內容上也存在差異,發改委擬定經濟和社會發展政策,財政部(廳、局)發布財稅政策,科技部(廳、局)發布科技創新政策,工信部(廳、局)發布產業政策,中小企業公共服務平臺發布針對中小企業發展的政策方針。基于所設計的網絡爬蟲共獲取到145043份政策文本,經過剔除明顯非政策文本的政策新聞、政策解釋等內容,最后得到131390份政策全文本,總字數為305648206,政策文本具體的分布情況如表1所示。為了確保所獲取數據的全面性,在獲取國家級數據的基礎上,也獲取了省級的政策數據,但部分省級數據公開度有待提高,所以,在具體獲取到的數據量上各個省份存在差異,具體如表2所示。

表1 數據基本信息表
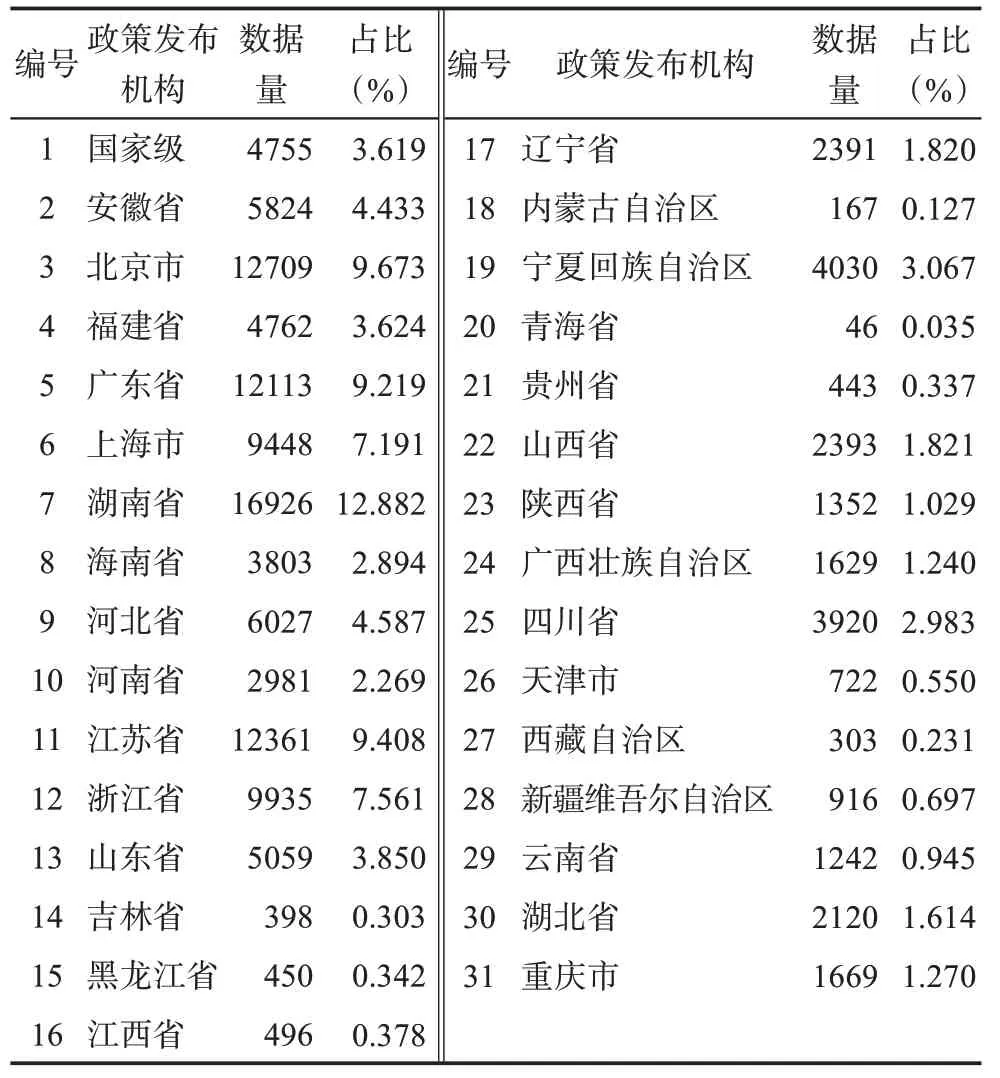
表2 政策文本發布機構分布表
2.3 數據預處理
通過對抓取數據的分析,本研究發現少量數據存在非法字符、字符中夾帶內容標簽(如【一圖讀懂】【問答解讀】等)以及文本中存在大量空白、換行等問題。對于上述數據存在的問題,本研究的具體操作和處理如下:針對數據中存在的非法字符,搜集所有非法字符的類別,替換去除;對于字符中夾帶的內容標簽,將標簽連同內容一并去除;對于文本中存在大量空白、換行的問題,遍歷文本內容替換去除;對于存在大量html標簽的文本,觀察發現該類文本通常存在內容缺失,利用Python正則表達式甄別出該類數據并剔除。數據預處理示例如表3所示。

表3 數據預處理示例
2.4 基線模型選取
當前,預訓練技術已成為自然語言處理領域的標志性技術,并且極大地提升了自然語言處理任務的性能。面對不同的任務,通過微調已有基礎預訓練模型而不是從頭訓練已經成為一種共識。通過遷移預訓練模型并進行微調,可有效地從大量標記以及未標記的數據中獲取領域特征知識。針對中文政策文本,本研究以BERT-base-Chinese和Chinese-Ro‐BERTa-wwm-ext兩個中文預訓練模型為基線,基于MLM和WWM任務進行預訓練,得到了被命名為ChpoBERT-mlm、ChpoRoBERTa-mlm、ChpoBERT-wwm和ChpoRoBERTa-wwm的中文政策預訓練模型,其中Chpo為Chinese policy的簡稱,同時ChpoBERT系列模型全部在Github進行了開源,鏈接為https://github.com/S-T-Full-Text-Knowledge-Min‐ing/ChpoBERT。
(1)BERT-base-Chinese
BERT是2018年由Google AI研究院發布的一種預訓練模型,在自然語言處理的各項下游任務上取得了優異的成績,成為自然語言處理發展史上的一個里程碑。BERT設計了兩個任務:一個是MLM,它用15%的概率隨機地對訓練序列中的token用mask token([MASK])進行替換,然后預測[MASK]處原有的單詞;另一個是NSP(next sen‐tence prediction),用于預測兩個句子是否連在一起。在BERT的基礎上,谷歌還發布了一個多語言版本BERT-base-multilingual和一個中文版本BERT-base-Chinese。在繼續預訓練階段使用中文語料數據的情形下,BERT-base-Chinese通常會有更好的效果。在文本內容上,政策文本有其獨特的語言表述方式,例如,政策文本中會大量出現“請”“經”“為”“各”等單字詞,且政策文本的行文邏輯較強,政策文本數據的這兩個特點正好對應了BERT-base-Chinese的兩個任務。
(2)RoBERTa-wwm
在BERT基礎上的改進版RoBERTa模型能支持更大的模型參數量、更大的batch size(批處理量)、更多的訓練數據。WWM與MLM的區別在于當一個詞的部分被MASK之后,整個詞都會被MASK。這是專門針對像中文這種語言文本而設計的任務,因為在處理中文語料時,MLM只能MASK獨立的文本,而WWM會將被MASK的字的整個詞全部MASK。中文政策文本中除了大量出現的單字詞外,也存在中文政策文本特有的多字詞,如“關于”“根據”“務必”“通知”“批準”等,而WWM在處理多字詞方面有著更為突出的性能。針對同一個基準模型,利用MLM和WWM任務對語料庫進行預訓練,對比不同任務下預訓練模型的性能更有助于把握語料文本的特性及更合適的繼續預訓練方式。
(3)ERNIE-Gram-zh
ERNIE(enhanced representation through knowl‐edge integration)是百度基于飛槳平臺研發的語義理解框架,其基于BERT模型做了進一步優化,并且在中文的NLP任務上達到了較為突出的性能。ERNIE-Gram模型更進一步地提出顯示、完備的ngram掩碼語言模型,以實現顯示的n-gram語義單元知識建模。在語義理解能力上,ERNIE-Gram可以實現同時學習細粒度和粗粒度語義信息,能在預訓練過程中實現單一位置多語義粒度層次預測和顯示的語義信號學習,并在中文任務的NLI、閱讀理解等語義理解任務上取得了較好的成績。針對前兩種模型基于token的掩碼方式,本研究增加了ERNIEGram-zh進行對照,以進一步驗證所預訓練的中文政策文本模型的性能。
2.5 實驗環境與參數
訓練語料文本的每一行都包括兩列,分別是標題和內容。本研究對國家級和省市級的文本內容平均字數進行了統計,絕大多數政策文本的內容遠遠大于512個字,所以在實驗前設置最大序列長度為512的基礎上去除了line by line參數,將單個文本內容混合多行處理,而不是每超過512個字符就另外算作一個文本內容。基于所獲取預訓練政策文本的整體規模,為了取得較好的預訓練學習效果,本研究將初始學習率設置為2e-5,進行5輪訓練,根據服務器配置和模型限制,將train_batch_size設置為8和16。基于所獲取預訓練政策文本的整體數據規模和神經網絡模型在訓練過程中所需的整體算力,本研究采用高性能NVIDIA Tesla P40處理器來完成實驗。計算機配置如下:操作系統為CentOS 3.10.0;CPU為48顆Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz;內存256GB;GPU為2塊NVIDIA Tesla P40;顯存24GB。模型預訓練參數值如表4所示。
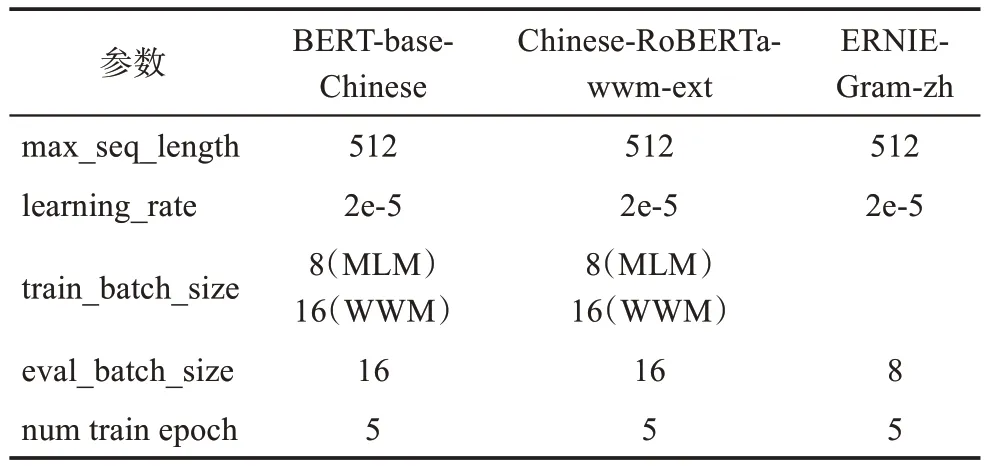
表4 預訓練模型參數設置
2.6 預訓練模型的評價指標
本研究采用困惑度(perplexity)初步評價預訓練模型的性能。在信息論中,perplexity被用于度量一個概率分布或概率模型預測樣本的好壞程度,被應用到自然語言處理中,則可用于衡量語言概率模型的優劣。相較于其他衡量方式,使用perplexity來度量更加直觀,在perplexity值相差較大的情況下,perplexity值越低,模型性能越好。具體計算公式為
其中,S表示句子;N表示句子長度;p(wi)是第i個詞的概率,而第一個詞的概率為p(w1|w0),w0是占位符,表示句子的起始。以sentence=“國務院關于同意在全面深化服務貿易創新發展試點地區暫時調整實施有關行政法規和國務院文件規定的批復國函”為例,p(w1|w0)表示sentence這句話以“國”字開頭的概率,同理p(w2|w1)表示該句在第一個字為“國”的條件下,第二個字為“務”的概率,由公式(1)可知,預測效果越好,則p的概率越大,per‐plexity值越小。本研究進行了MLM和WWM兩個任務在兩個模型上的預訓練實驗,所得語言模型perplexity值如表5所示。

表5 預訓練模型perplexity值
由表5可知,預訓練模型和基準模型的perplex‐ity差值并不顯著。一般來說,perplexity值越小,模型越好。其中,ChpoBERT-mlm的perplexity小于基準模型,而ChpoBERT-wwm的perplexity值大于基準模型,初步判斷ChpoBERT-mlm的性能優于ChpoB‐ERT-wwm。同樣地,ChpoRoBERTa-mlm的perplexi‐ty值小于基準模型,ChpoRoBERTa-wwm的perplexi‐ty大于基準模型,初步判斷ChpoRoBERTa-mlm的性能優于ChpoRoBERTa-wwm。在微調階段,初步認為ChpoBERT-mlm和ChpoRoBERTa-mlm的效果要優于基準模型,而ChpoBERT-wwm和ChpoRoBERTawwm的效果要遜于基準模型。
3 預訓練模型性能驗證
困惑度能夠在某種程度上反映預訓練模型的效果,但為了進一步判斷預訓練模型是否能夠更好地完成自然語言處理的相應任務,仍需對其進行更進一步的性能驗證實驗。結合所篩選、整理和加工的語料數據,本研究設計了自動分詞、自動詞性標注和實體識別3個驗證實驗。
3.1 驗證數據
(1)自動分詞語料數據
自動分詞驗證語料數據集來源于南京農業大學新時代人民日報分詞語料庫(http://corpus.njau.edu.cn/)[38],該語料庫由黃水清等基于2015年至2018年之間共9個月的《人民日報》數據構建而成,在多項測評上,比北京大學計算語言研究所構建的1988年人民日報分詞語料性能表現更為突出。基于該語料庫,經過人工多次和反復的篩選,從中選取與政策相關的文本共374篇,總字數為78311字,并按照9∶1劃分訓練集和測試集。所選出來的驗證數據集完成了人工的分詞精加工,可以支撐對所構建的預訓練模型在自動分詞任務上的驗證,具體的分詞的政策文本樣例如表6所示。

表6 驗證數據樣例
(2)自動詞性標注語料數據
自動詞性標注驗證數據集來源于經過詞性標注的北京大學人民日報語料,該語料由北京大學計算語言學研究所俞士汶等[39]基于《人民日報》1998年的純文本語料構建,是我國第一個大型的現代漢語詞性標注語料庫。基于詞性標注語料庫,在人工精篩選的基礎上,獲取了445篇有關政策的語料文本,共計112028字。該語料以詞為單位切分并標注了詞性,按照9∶1劃分訓練集和測試集。選出來的語料經過人工詞性標注,在漢語自然語言處理領域具有權威性和標志性。具體的詞性標注的語料樣例如表6所示。
(3)實體識別語料數據
基于所獲取的政策文本,本研究選取了982篇用于標注實體,其中682篇為科技政策文本(共計902048字),300篇為其他領域的政策文本(共計1016346字),按照9∶1劃分訓練集和測試集。在制定的實體標注規范的基礎上,基于“BIOES”標注集完成對所獲取政策文本中實體的人工標注,從而構建中文政策預訓練模型的驗證數據集。數據集中所標注的實體共有4類,分別為政策性質、政策時間、適用區域和政策領域,具體的標注實體樣例如表6所示。
3.2 驗證指標及模型參數
本研究的預訓練模型驗證將結合混淆矩陣,對于詞匯的分詞、詞性的標注和實體的識別性能使用精確率P(precision)、召回率R(recall)、F1值(F1-score)指標進行評價。對于總體分詞、標注和識別性能,使用宏平均(macro-avg)和加權平均(weighted-avg)中的P、R、F1-score指標進行評價,混淆矩陣表如表7所示。具體計算公式為
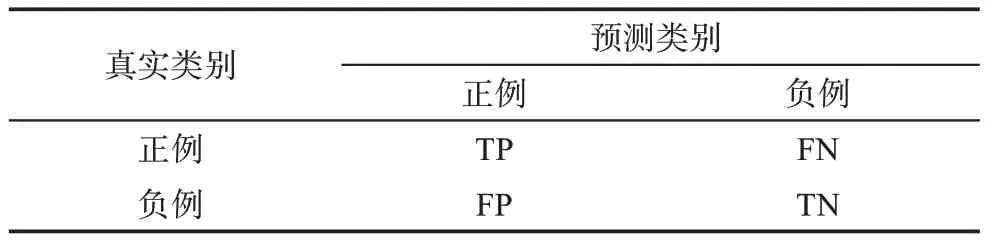
表7 混淆矩陣表
同時,宏平均為所有類別的指標值的算數平均值,即宏精確率、宏召回率和宏F1值,具體計算公式為
同理,加權平均將樣本數量占樣本總數比例作為計算平均值的權重,指標為加權精確率、加權召回率和加權F1值,具體計算公式為
在自動分詞、詞性標注和實體識別的參數設置上,本研究將訓練階段的batch size和測試階段的batch size均設為32,最大句長設為256,共訓練3輪。為避免模型在訓練初期因學習率過大而造成訓練誤差加大,設置warmup_propotion為0.4。此外,本研究針對不同的下游任務測試了不同的學習率,使模型在下游任務中均獲得了較好的表現。
3.3 驗證結果分析
(1)詞匯分詞結果
分詞是自然語言處理領域的基礎任務,對政策文本的精確分詞是挖掘政策文本知識內涵的基礎。由表8可知,ChpoBERT系列模型在分詞任務上的表現相較于基準模型上均有一定程度的提升,除ChpoRoBERTa-wwm在分詞的召回率上略低于基準模型Chinese-RoBERTa-wwm-ext外,ChopBERT系列模型在全部3項指標上均超越了基準模型。在所有模型中,ChpoBERT-wwm在分詞任務上的準確率、召回率和調和平均值上表現均為最佳,分別為97.27%、97.60%和97.43%。ERNIE模型在7個模型中表現最差,分詞的準確率、召回率和調和值均低于其他模型。在分詞驗證任務中,原始BERT模型在準確率、召回率和調和平均值上均優于原始Ro‐BERTa模型,而基于MLM和WWM任務繼續預訓練的ChpoBERT-mlm和ChpoBERT-wwm在準確率、召回率和調和平均值上的表現也均優于ChpoRo‐BERTa-mlm和ChpoRoBERTa-wwm。政策文本分詞驗證的結果如表8所示。
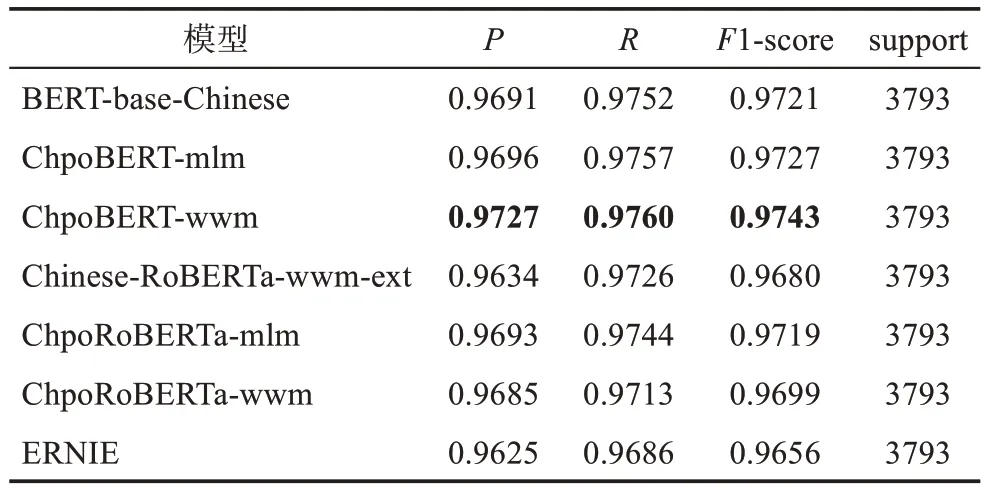
表8 政策文本分詞結果
(2)詞性標注結果
詞性標注是自然語言處理的基礎模塊,是句法分析、信息抽取等工作的基礎。語料中不同詞性的詞在數量上存在較大差異,導致整體宏平均值較低,因此,只以準確率、召回率、調和平均值的加權平均值作為詞性標注任務的評價指標。由表9可知,ChpoBERT系列模型在全部3項指標上均超越了基準模型,其中ChpoBRET-mlm在準確率上的加權平均值上表現最優,達到89.02%,比基準模型提升了1.14個百分點,ChpoRoBERTa-mlm在召回率與調和平均值上的加權平均值表現最優,分別為91.44%、90.12%,比基準模型提升了0.94個和1.09個百分點。ERNIE表現最差,與其他模型存在較大差距,準確率、召回率與調和平均值的加權平均值分別為84.05%、88.35%和85.95%。此外,Chpo‐BRET-mlm在詞性標注任務上的表現優于Chpo‐BRET-wwm,ChpoRoBERTa-mlm在詞性標注任務上的表現同樣也優于ChpoRoBERTa-wwm。基于預訓練模型的詞性標注結果比較如表9所示。
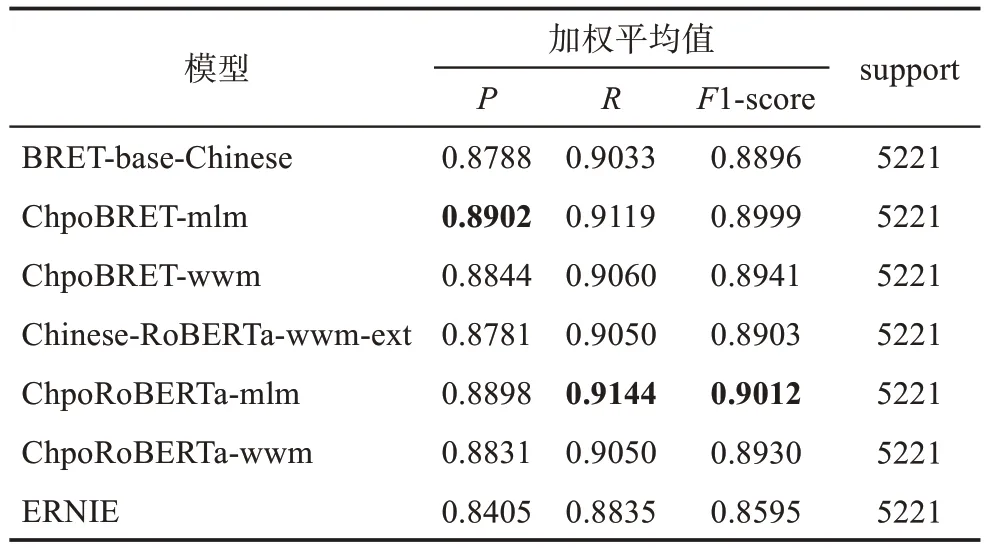
表9 基于預訓練模型的詞性標注識別結果比較
(3)實體識別結果
實體識別作為自然語言處理的基礎任務,能夠為信息檢索、關系抽取、知識問答系統等提供有效的實體知識支撐。為了進一步確認預訓練模型的性能,本研究在政策文本預訓練模型以及基準模型上,使用驗證數據集進行實體識別任務以進行比對,具體結果如表10所示。
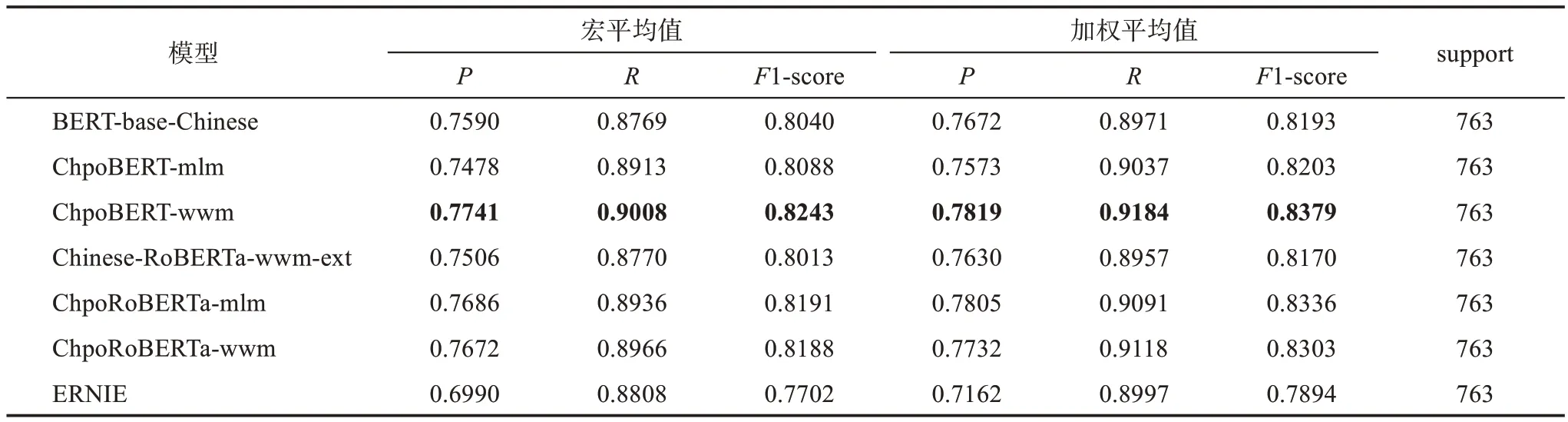
表10 實體識別結果驗證
從實驗結果可以看出,ChpoBERT系列模型在實體識別效果上均高于其他3種模型。在宏平均上,ChpoBERT-wwm在準確率、召回率和F1值上表現最優,分別為77.41%、90.08%和82.43%,分別比基準模型BERT-base-Chinese提升了1.51個、2.39個和2.03個百分點。ChpoRoBERTa-mlm和ChpoRoBERTa-wwm在準確率、召回率和F1值上均優于基準模型,與基準模型Chinese-RoBERTa-wwmext相比,ChpoRoBERTa-mlm在3項指標上分別提升了1.80個、1.66個和1.78個百分點,ChpoRoBERTawwm在3項指標上分別提升了1.66個、1.96個和1.75個百分點。ERNIE在所有模型中表現最差,準確率、召回率和F1值分別為69.90%、88.08%和77.02%。
在加權平均上,ChpoBERT-wwm在準確率、召回率和F1值上表現最優,分別為78.19%、91.84%和83.79%,比基準模型提升了1.47個、2.13個和1.86個百分點。ChpoRoBERTa-mlm和ChpoRoBERTa-wwm在準確率、召回率和F1值相較于基準模型Chinese-RoBERTa-wwm-ext均有一定的提升,ChpoRoBERTamlm在準確率、召回率和F1值上分別提升了1.75個、1.34個和1.66個百分點,ChpoRoBERTa-wwm在準確率、召回率和F1值上分別提升了1.02個、1.61個和1.33個百分點。ERNIE在所有模型中表現最差,準確率、召回率和F1值分別為71.62%、89.97%和78.94%。
4 討 論
首先,以BERT-base-Chinese和Chinese-RoBERTawwm-ext兩個中文預訓練模型為基準模型,結合海量中文政策文本所構建的ChpoBERT系列模型在困惑度上相較于基準模型,最優的模型低了0.7924,表現出了較優的性能。在自動分詞、詞性標注和實體識別的自然語言處理下游任務上,政策文本預訓練模型也表現得較為突出。上述性能判定和驗證實驗結果表明,在政策文本的這一領域化數據上所構建的預訓練模型具有較強的應用性。一方面,從人工智能大語言模型的角度,所構建的預訓練模型成為政策文本知識挖掘的基礎模型支撐資源,在一定程度上確保了政策文本領域展開領域化信息智能處理的可能性;另一方面,所構建的預訓練模型可以直接應用于中文政策文本的自動分詞、詞性標注、實體識別、關鍵詞抽取和語義標注等自然語言處理的基礎任務,同時也可以支撐政策文本的自動分類、自動聚類、智能信息檢索、智能知識推送和智能評估等應用性探究。
其次,面向259個國家級、省級和市級等目標網站,所獲取的3億多字的中文政策文本不僅為相關研究者展開數據驅動下的政策全文本計量、內容分析和文體風格等的研究提供了有力的數據支撐,而且為構建中文政策預訓練模型奠定了堅實的數據基礎。但目前所獲取的政策文本數據存在兩個方面的問題,一方面,目前通過網站所獲取的國家級、省級和市級政策文本是不全面的,并且缺乏對過去政策文本的搜集;另一方面,目前沒有獲取縣級以下的政策文本。上述數據缺失的問題導致了預訓練模型的整體性能有待提升,這是因為在預訓練模型構建過程中數據量是基礎和關鍵。通過各種渠道和方法增加政策文本數據的總量是未來進一步提升政策預訓練模型性能所需要重點強化的任務。
最后,通過選取精加工的經過分詞和詞性標注的政策文本和精標注政策文本中的實體,本研究構建了自動分詞、詞性標注和實體識別的數據集,并設計了相對應的政策文本預訓練模型的3個驗證實驗。從驗證結果來看,所構建的預訓練模型整體性能較為突出,這也說明了所構建模型的領域適應性和構建領域預訓練模型的必要性。但由于目前沒有公開的與政策文本相關的精加工數據集,本研究在有限的時間和人力基礎上所搜集和加工的驗證數據集存在數據規模小、精標注淺和覆蓋面窄等問題。上述問題在一定程度上影響了驗證所構建政策預訓練模型性能的完整性、精準性和全面性。在未來的研究中,擴大、拓展和增強驗證數據集的規模、深度和廣度是構建政策預訓練模型必須要完善的工作。
5 結 論
近年來,政策文本的智能信息處理是信息科學領域的研究熱點之一。基于中文政策全文本語料庫,本研究構建了中文政策文本的預訓練模型,一方面,通過困惑度指標對所構建預訓練模型進行了初步的性能判定;另一方面,通過對比預訓練語言模型和基準模型在下游任務上的性能進一步驗證所構建預訓練模型的性能。研究結果表明,政策文本的預訓練模型在自動分詞、詞性標注、實體識別上相較于基準模型取得了較優的效果。誠然,本研究也存在不足之處,一方面,政策文本的數據量有待于擴大,特別是非網上的數據;另一方面,驗證集的數量、類別和加工的精細度均有待于完善。因此,通過擴大政策文本的規模訓練性能更加突出的預訓練模型,同時結合不同主題的政策文本細化預訓練模型是未來需要探究的內容。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
制造技術與機床(2019年10期)2019-10-26 02:48:08
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
