基于Sentinel-2影像的橫山水庫葉綠素a反演算法研究
2024-01-03 12:58:08李小勇范春波
水利科學與寒區工程 2023年11期
關鍵詞:模型
李小勇,黃 鵬,孫 武,范春波,游 林
(1.武漢華夏理工學院 土木建設工程學院,湖北 武漢 430223;2.浙江時空智子大數據有限公司,浙江 寧波 315200;3.寧波市奉化區橫山水庫管理站,浙江 寧波 315511)
1 材料與方法
1.1 研究區域
寧波市橫山水庫是寧波、奉化城市供水的主要飲用水源地之一,是地方水資源時空分配調控的重要水利工程措施,承擔供水、防洪、灌溉、發電、養殖等方面重要任務[1-2]。水庫位于奉化江支流縣江上,集雨面積 150.8 km2,正常性蓄水水位111.5 m,相應庫容7.65×107m3。作為易受作物更替種植和城市擴張等人類活動干擾的水庫,其水質常年在Ⅱ~Ⅲ類之間,但水體富營養化的幾個重要指標逐年升高,尤其是在春季已爆發過輕微“水華”事件。
1.2 地面數據
自動站點監測數據來源于寧波市生態環境監測中心提供的2020—2022年每日8時、12時、16時3個時間點監測水庫水質。月度常規取樣化驗數據由寧波原水集團有限公司提供,于水庫壩前分別進行表層、供水層、底層水樣采集,送往實驗室測定水質參數。自動站點與月度常規取樣都測定了包含水溫、pH、溶解氧、濁度、電導率、高錳酸鹽指數、氨氮、總磷、總氮、Chl-a等常規水質參數。自動站點與采樣點位置如圖1所示。

圖1 自動站點與采樣點示意圖
通過自動站點監測數據與月度常規取樣化驗數據的相關性分析發現,站點監測數據與表層數據的相關系數都在0.79以上,鑒于Sentinel-2影像在10時左右過境拍攝,本文最終選取采用相關性較高的12時監測數據作為Chl-a濃度實測數據。
1.3 遙感影像數據
本文于Google Earth Engine(GEE)遙感信息管理與處理云平臺上,獲取Sentinel-2衛星(表1)地表反射率產品L2A級數據,其在L1C級數據的基礎上,已經進行大氣校正等處理。通過JavaScript API在線訪問覆蓋橫山水庫區域的遙感影像數據,選取受云霧影響較小,質量較好的影像共56景。
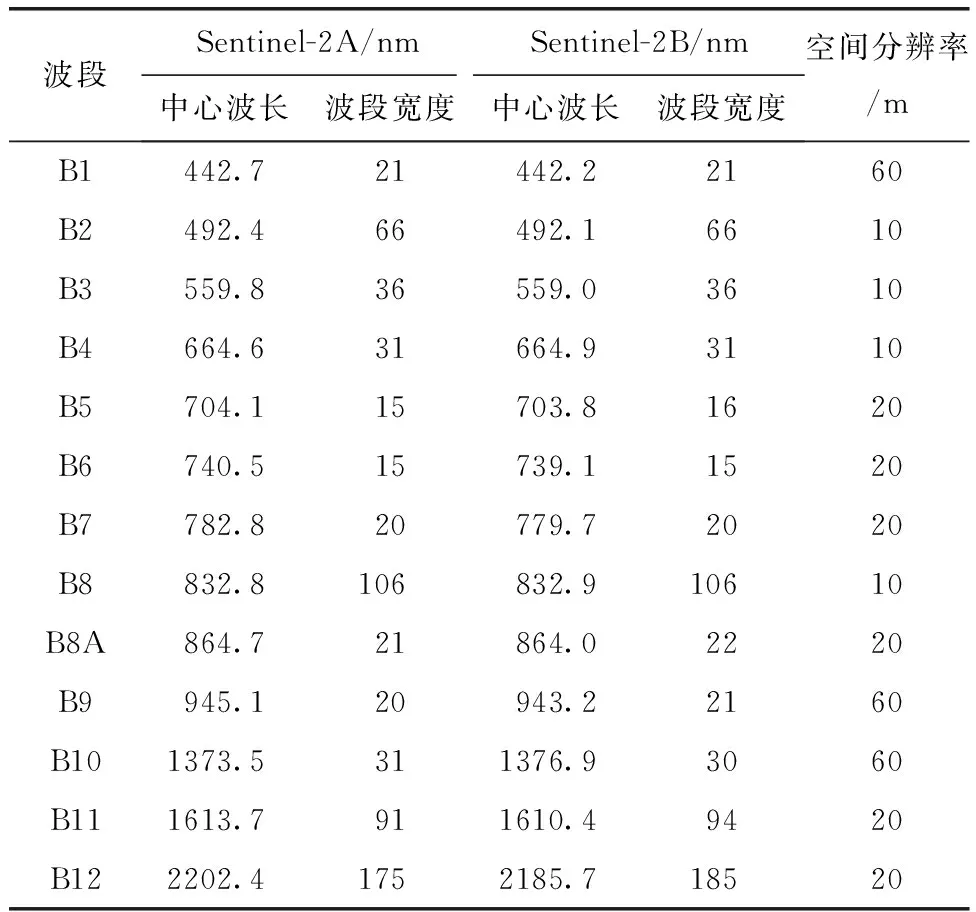
表1 Sentinel-2傳感器波段信息
風速、降水、流速等環境因素會對自動站點監測的Chl-a濃度測量值有所影響,水面鏡面反射以及大氣影響使得遙感波段值不是真實的地面反射率值,因此,需剔除異常值,以減少因為站點監測數據與遙感影像數據不能完全匹配所產生的Chl-a濃度的估算誤差。本文將監測站點Chl-a濃度值與遙感影像波段值繪制散點圖,剔除偏離回歸線的異常值之后的35對遙感數據與監測站點數據作為模型反演的訓練數據。
1.4 方 法
1.4.1 Chl-a經驗反演模型
歸一化Chl-a指數模型(NDCI)是Sentinel-2的水色產品數據集的官方算法,相對于單波段、波段比值、三波段方法,估算精度更高、適用性更強[3]。該Chl-a反演模型使用一個新的高質量合成數據集(9836個樣本),這些數據被分成7868個樣本的訓練數據集(80%)和1968個樣本的測試數據集(20%),利用這些數據集建立一個估算Chl-a濃度值y的經驗模型,如公式(1)所示。
y=17.441e4.7038NDCI
(1)
1.4.2 BP神經網絡
BP神經網絡是一種按照誤差逆向傳播算法訓練的多層前饋神經網絡,主要包含輸入層、隱含層、輸出層3個部分,是廣泛應用的神經網絡模型之一。其訓練過程分為信號的前向傳播與誤差的反向傳播兩個階段。通過不斷的信號前向傳播和誤差反向傳播,各層權值會不斷進行調整,直到訓練結束。
1.4.3 隨機森林
隨機森林(RF)算法是一種集成模型,其核心思想是采用集成學習三大分支中Bagging、Boosting 和 Stacking中最具有代表性的Bagging集成學習技術。隨機森林在保留決策樹處理多特征數據類型特點的同時,由于采取有放回的抽樣,解決了決策樹容易產生的缺陷——過度擬合,另外其預測結果是參考多個決策樹得到的結果,降低了異常值帶來的影響。隨機森林在非線性特征模擬等方面都有很好的表現,其所構建的Chl-a濃度遙感反演模型也更具有泛化性。
1.4.4 精度評價體系
各反演模型的精度通過3個指標進行評估,即均方根誤差(RMSE)、平均絕對誤差(MAE)和決定系數(R2),如公式(2)~公式(4)所示。
(2)
(3)
(4)
2 結果與討論
2.1 波段選擇
隨著葉綠素含量增加,水體反射光譜在藍光和紅光波段構成較強的吸收谷,在綠光波段出現反射率峰值,含量越高,峰值越高。通常影響因子與水質參數之間的關系不能利用單波段很好反應,采用 SPSS計算不同的波段組合與Chl-a濃度的皮爾遜相關系數,獲取相關性強、干擾小的敏感波段。本文利用35個自動監測站點實測的Chl-a濃度數據與遙感影像反射率數據,分別在單波段、單波段比值、雙波段比值、三波段、四波段以及NDCI中選擇相關系數最大的作為變量因子,各波段與Chl-a濃度值的相關性如表2所示。最終選取B8、B5/B4、(B5-B4)/(B5+B4)作為機器學習模型構建的輸入層。
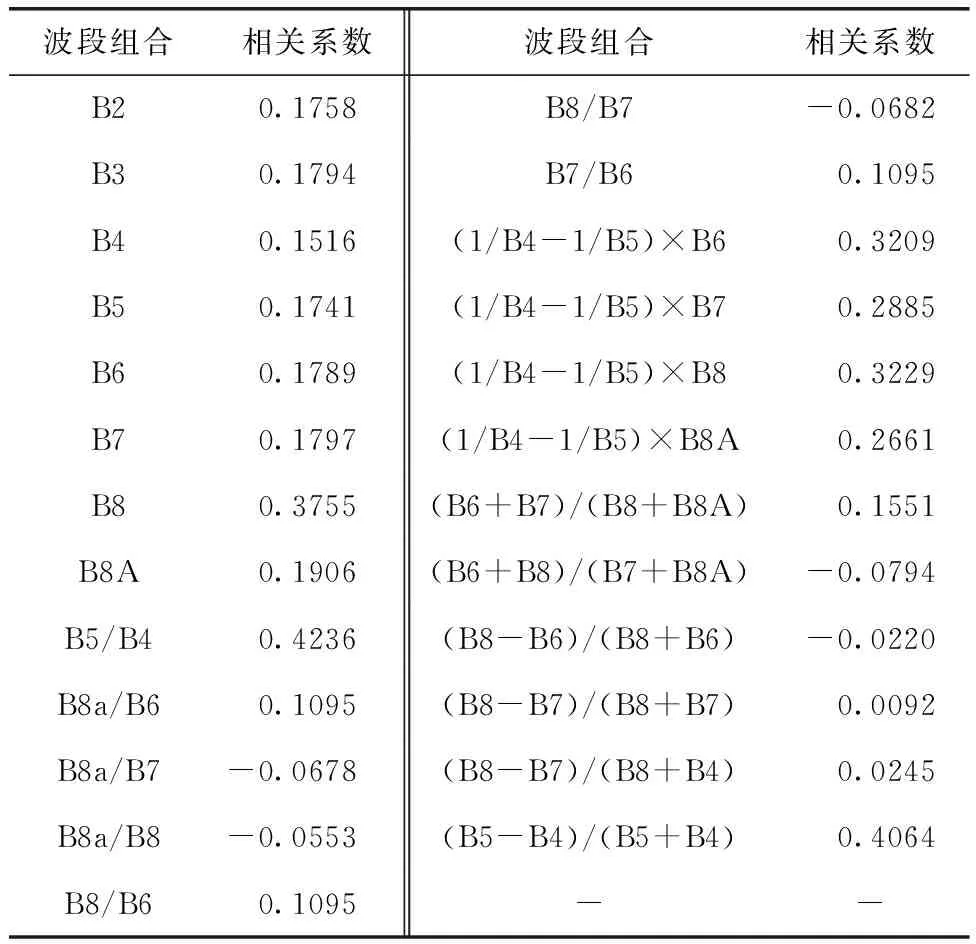
表2 各波組合與Chl-a濃度的相關系數
2.2 模型構建與驗證
本文將樣本數據劃分為訓練集以及測試集,并按照8∶2的比例隨機進行劃分,其中訓練集28個,測試集7個。然后基于Scikit-learn機器學習庫,根據上述篩選的重要特征變量,作為機器學習的輸入因子,與之相對應的自動站點監測Chl-a濃度作為輸出數據,分別構建BP神經網絡與隨機森林模型。
本文分別選擇不同的決策樹大小、決策樹的深度對隨機森林進行反復訓練,經調試,模型參數確定為n_estimators=20,max_depth=5時,訓練集RMSE為2.094、MAE為1.631、R2為0.876,此時的模型訓練效果最佳。BP神經網絡采用relu作為激活函數,學習速率為0.01,通過多次實驗確定隱含層節點數為10時,模型精度最高,訓練集RMSE為2.766、MAE為2.298、R2為0.785。利用經驗模型直接對訓練集進行預測,RMSE為 2.7063、MAE為 2.6197、R2為0.7544。三種模型的擬合曲線如圖2(a)~圖2(c)所示。

圖2 Chl-a遙感反演曲線擬合
為評價模型的普適性,將三種模型對劃分好的測試集分別反演Chl-a濃度,對反演結果進行模型驗證以及精度評價。從表3可以看出,隨機森林模型在測試集上,均方根誤差和平均絕對誤差都較低,決定系數R2大于另外兩種,精度更高。圖2(d)~圖2(f)為各模型在測試集上預測值與真實值的擬合曲線,經驗模型的預測值曲線雖然與真實值的曲線大致保持一致,但整體比真實值低得多;BP神經網絡模型預測值曲線同樣與真實值的曲線大致保持一致,但結果整體偏高,還出現高出真實值許多的異常情況;而隨機森林模型除了測試集的預測值曲線與真實值的曲線大致保持一致之外,其在訓練集上預測值曲線也大致保持一致,能夠較好地分布在真實值附近。因此后續基于Sentinel-2影像反演橫山水庫Chl-a濃度將采用隨機森林模型。
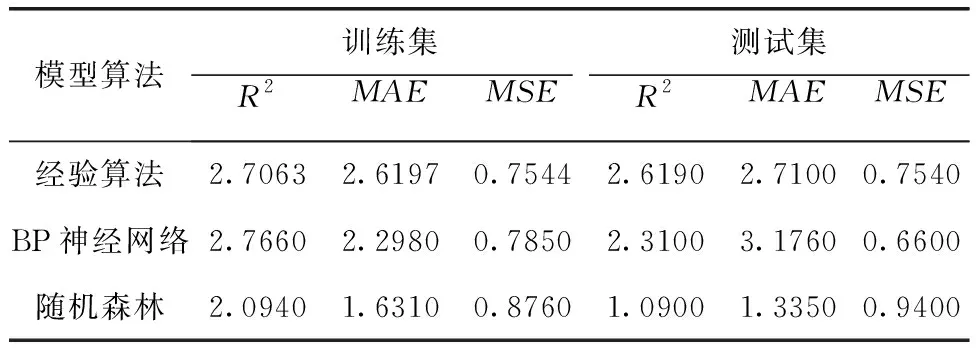
表3 不同模型預測Chl-a濃度的精度情況
2.3 葉綠素a濃度空間分布
為只對橫山水庫庫面進行Chl-a濃度反演,計算Sentinel-2的歸一化差分水體指數(NDWI),通過大津閾值法獲取水庫與陸地的分割閾值,掩膜出橫山水庫庫面水域。計算庫面區域內的B8、B5/B4、(B5-B4)/(B5+B4)等波段組合值,并作為隨機森林模型的輸入因子,對橫山水庫2020年4月20日及2022年10月22日兩期遙感影像進行Chl-a濃度反演。如圖3所示,其中標注的點位為相同日期自動站點監測的Chl-a濃度。2022年10月22日Chl-a濃度預測值為13.8936 μg/L,真實值為12.771 μg/L;2020年4月20日Chl-a濃度預測值為24.3188 μg/L,真實值為26.587 μg/L。由反演結果可以看出,2020年4月20日的Chl-a濃度整體普遍高于2022年10月22日,與橫山水庫易在春季發生水華時間點匹配,且該水庫在2020年春季發生過輕微水華事件,說明隨機森林反演模型對于橫山水庫的水質監測能夠提供一定參考。

圖3 橫山水庫Chl-a濃度空間分布
3 結 論
(1)對比Sentinel-2不同波段組合與Chl-a濃度的相關性發現,B8、B5/B4、(B5-B4)/(B5+B4)相關系數最大。
(2)使用相同數據集構建3 種不同的Chl-a濃度反演模型,對比發現隨機森林模型的MAE、MSE和R2均最小,比經驗模型和BP神經網絡構建的反演模型精度更高。因此,利用本文構建的隨機森林模型更適用于Sentinel-2數據在橫山水庫的Chl-a濃度反演。
(3)通過Sentinel-2影像監測發現,橫山水庫2020年4月20日Chl-a濃度比2022年10月22日整體較高,與橫山水庫易在春季發生水華時間點匹配,為水庫的水華和富營養化監測提供了參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
