表端識別技術(shù)在燃氣行業(yè)中的應用
2024-01-07 05:31:38徐士林
無線互聯(lián)科技 2023年22期
關(guān)鍵詞:模型
王 彬,徐士林,侯 偉
(襄陽華潤燃氣有限公司,湖北 襄陽 441000)
0 引言
攝像燃氣表的原理是在普通燃氣基表的基礎上,通過加裝帶攝像頭模塊和通信模塊的卡扣來實現(xiàn)燃氣表的遠程感知。其中,光學字符識別算法(Optical Character Recognition,OCR)是攝像燃氣表研究的核心內(nèi)容,決定著攝像燃氣表的上報準確率。OCR的早期研究可以追溯到20世紀20年代和20世紀30年代,當時研究人員開始嘗試開發(fā)機械設備來自動識別印刷文本[1]。OCR技術(shù)經(jīng)歷了多個階段的發(fā)展,從早期的機械方法到基于光學的方法,再到數(shù)字圖像處理和深度學習方法。隨著深度學習和神經(jīng)網(wǎng)絡的崛起,OCR技術(shù)迎來了重大突破。深度學習方法使OCR系統(tǒng)能夠更好地適應不同字體、字號和手寫風格,大大提高了準確性,并廣泛用于文檔掃描、數(shù)字化圖書館、自動數(shù)據(jù)輸入等領域[2-5]。
1 研究現(xiàn)狀
在使用深度學習進行數(shù)字字符識別方面,Lecun等[6]于1998年提出了基于卷積神經(jīng)網(wǎng)絡的數(shù)字手寫體識別系統(tǒng)LeNet-5,并創(chuàng)建了著名的手寫數(shù)字圖像數(shù)據(jù)集MNIST,LeNet-5在MNIST數(shù)據(jù)上的準確率達到了99.2%。此后,深度學習在圖像處理領域進入高速發(fā)展期,2012年誕生的AlexNet是一個深度卷積神經(jīng)網(wǎng)絡,相對于之前的LeNet-5來說更深。它在ImageNet圖像分類競賽中取得了巨大成功,通過深層網(wǎng)絡和隨機裁剪等創(chuàng)新性方法,大幅提高了分類準確度[7]。2014年,VGG-Net在AlexNet的基礎上進一步增加了網(wǎng)絡的深度,它以均勻的卷積層堆疊為特點,使用小尺寸的卷積核和深層結(jié)構(gòu),提高了特征提取的性能[8]。2014年,GoogleNet引入了Inception模塊,這是一種結(jié)合不同尺寸的卷積核和池化操作的模塊。它通過多個分支的并行計算來提高特征表達能力,從而在ImageNet競賽中獲得了顯著的成功[9-11]。2016年何凱明提出了殘差網(wǎng)絡ResNet。ResNet是一種革命性的網(wǎng)絡結(jié)構(gòu),引入了殘差學習機制,允許網(wǎng)絡通過跳躍連接學習殘差,從而解決了深度網(wǎng)絡中的梯度消失和退化問題。ResNet可以訓練更深的網(wǎng)絡,提高了特征的表示能力[12-13]。
2 字輪圖像的識別模型
攝像燃氣表主要應用在普通基表的遠傳改造上。在這種場景下,由于基表所屬的廠商不同,字輪圖像存在顯著的差異。這些差異包括字符的大小、字符的類型、字體的亮度和字符所在子區(qū)域的圖像結(jié)構(gòu)。其中,子區(qū)域的圖像結(jié)構(gòu)是否包含干擾行是影響模型準確率的最主要因素(見圖1)。
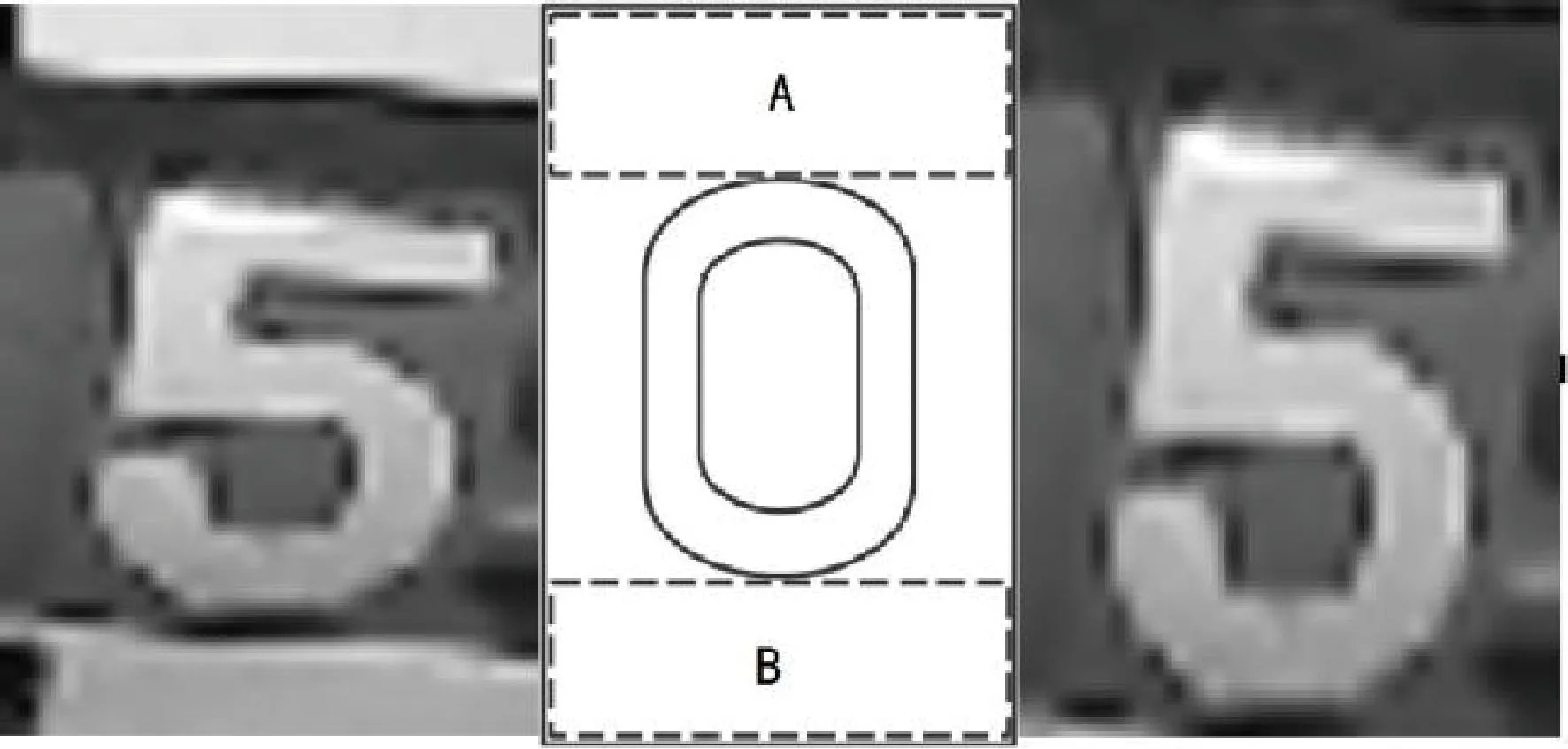
圖1 不同基表廠商字符區(qū)域結(jié)構(gòu)上的差異
這些干擾行存在3個特征:(1)干擾行主要集中在上/下兩端;(2)干擾行主要體現(xiàn)為背景,即純白色或純黑色;(3)以行為計量單位,干擾行的像素標準差遠低于數(shù)據(jù)行。因而,本文將行亮度標準差作為一個注意力機制引入識別模型。
如圖2所示,模型將字輪圖像統(tǒng)一為28×28的灰度圖像,將圖像輸入卷積神經(jīng)網(wǎng)絡的第1卷積層中,經(jīng)過6個5×5卷積核計算后,生成6×24×24的特征向量圖;經(jīng)過第1池化層2×2最大下采樣后,生成6個12×12規(guī)模的特征向量圖。第2卷積層經(jīng)過12個5×5×6卷積核后,生成12×8×8的特征向量圖;經(jīng)過第2池化層的1×2最大下采樣后,生成12個規(guī)模為8×4的特征向量圖。
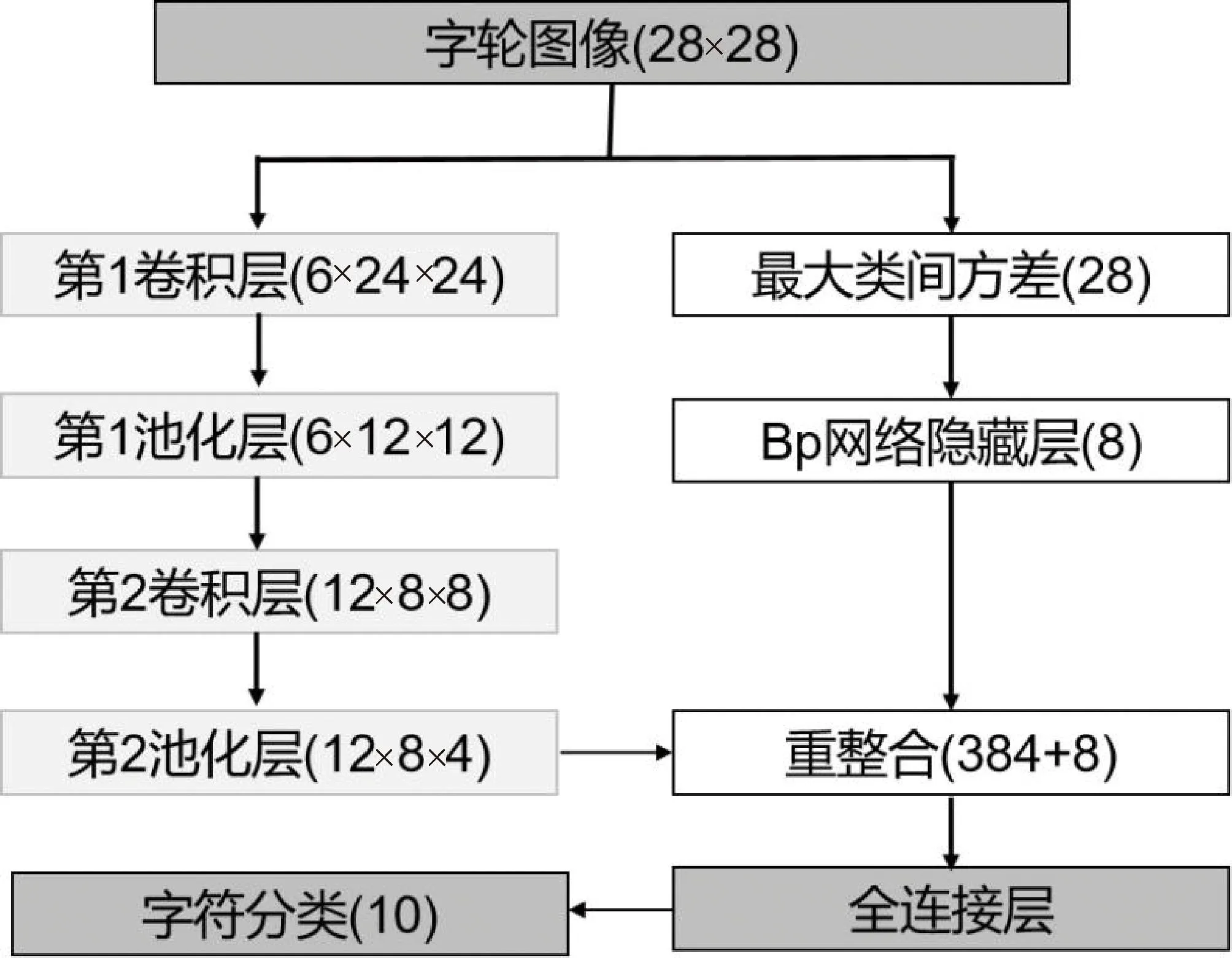
圖2 字符識別模型
計算字輪圖像每一行的最大類間方差總計28個數(shù)據(jù)輸入,通過包含4個神經(jīng)元的隱藏層接入第2池化層的輸出向量,構(gòu)建1個392維的特征向量,后接入全連接層完成圖像的模式分類。
最大類間方差通過逐行計算的方式獲得。統(tǒng)計每行像素的最小灰度值qmin,最大灰度值qmax。遍歷[qmin,qmax]之間的每一個灰度水平vi。在灰度水平vi下,統(tǒng)計該行灰度值小于vi的像素點數(shù)量ω0,像素平均值μ0;統(tǒng)計該行灰度值大于等于vi的像素點數(shù)量ω1,像素平均值μ1,則在灰度水平vi下,類間方差gi為:
gi=ω0ω1(μ0-μ1)2
(1)
行最大類間方差
gotu=maxv(g)
(2)
第2池化層輸出的特征圖上,由于每行特征點的感受野為原圖像的3~4行數(shù)據(jù)規(guī)模,因而等同于將原圖像按行劃分為了8塊。將行的最大類間方差引入模型,是為了給定每一特征塊的權(quán)重參考因子。這個模型是針對不同燃氣基表的圖像差異來設計的,從而在淺層網(wǎng)絡上擁有更好的泛化能力。
3 連續(xù)字輪的判別模型
燃氣表字輪圖像的數(shù)字識別是一種分界線模糊的圖像分類問題。這是因為燃氣表字輪的轉(zhuǎn)動是一個連續(xù)的過程,字輪的狀態(tài)既有可能出現(xiàn)完整字符的情況,也有可能出現(xiàn)半字符的情況。如圖3所示,左圖字符“5”和右圖字符“6”為完整字符,中間屬于字符“5”和字符“6”的半字符狀態(tài)。末位字輪有一定的概率處于完整字符與半字符之間的狀態(tài)。如果對于這種狀態(tài)不加以判別,模型收斂困難。

圖3 末位連續(xù)字輪圖像
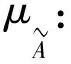
(3)
其中,m為2個完整字符之間齒輪轉(zhuǎn)動的總次數(shù);n為上一個完整字符后齒輪轉(zhuǎn)動的總次數(shù)。以任意2張圖像作為輸入,隸屬度函數(shù)差作為標簽,訓練一個孿生網(wǎng)絡。在孿生網(wǎng)絡的調(diào)整下,完整字符和半字符的n維特征在歐氏空間上可分。
在訓練階段模型輸入為2張圖像。狀態(tài)特征提取器用于分別提取2張字輪圖像的圖像特征,是一個淺層卷積神經(jīng)網(wǎng)絡(CNN)結(jié)構(gòu)(見圖4)。該淺層CNN的第1層為輸入層、第2層為卷積層A、第3層為池化層A、第4層為卷積層B、第5層為池化層B。度量計算為全連接層,拼接2個圖像的特征向量,輸出2張圖像的隸屬度函數(shù)差fout。
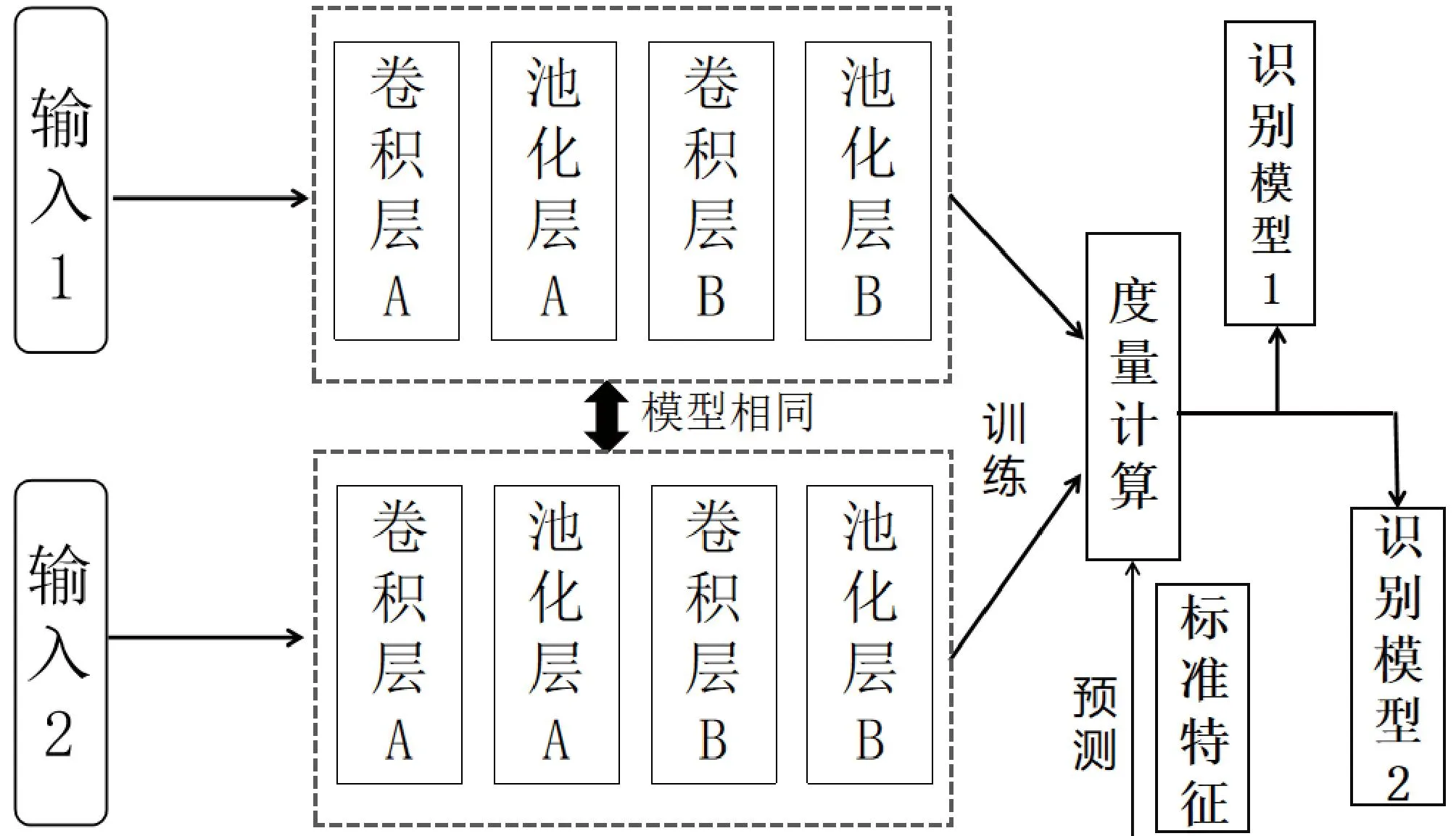
圖4 字符判別模型
4 模型的訓練和預測
定義一個隸屬度函數(shù)水平值λ(λ<0.4),將隸屬度函數(shù)xA<λ的全體圖像稱為第1水平截集,將(1-xA)<λ的全體圖像稱為第2水平截集,其余稱為第3水平截集。
訓練分為2個階段,第1階段使用全體數(shù)據(jù)訓練判別網(wǎng)絡。第2階段訓練字符識別網(wǎng)絡。使用第1水平截集和第3水平截集訓練字符識別模型1,由第2水平截集和第3水平截集訓練字符識別模型2。第3水平截集同時放置在2個識別模型的訓練集里以增加模型的泛化能力。
預測階段,首先使用判別網(wǎng)絡提取圖像特征,并與完整字符的標準特征做度量計算。然后,根據(jù)判別網(wǎng)絡的輸出fout與水平值λ的大小,判斷使用哪種識別網(wǎng)絡。若fout<λ,使用字符識別模型1;若fout>(1-λ),則使用判別模型2;介于其中則可使用任意模型。通過對數(shù)據(jù)集進行模糊截斷,識別網(wǎng)絡得以收斂。
5 設備試掛
攝像燃氣表在襄陽華潤燃氣有限公司開展試點跟蹤。芯片使用低功耗MCU,STM32 M4的內(nèi)核,Nb-IoT通信。工作電壓3.3 V,工作電流小于100 mA,設備休眠時工作電流小于10 μA。設備同時上報圖像和表端識別讀數(shù)以方便比對準確率。燃氣基表來自海立、山城 、丹東等不同廠商。自2020年12月30日—2021年04月07日,剔除掉通信異常數(shù)據(jù),總共進行了10 090次的表端識別,僅有1次識別錯誤,識別準確率大于99.99%。
6 結(jié)語
在可預見的相當一段時間內(nèi),傳統(tǒng)的機械字輪燃氣表仍然占有相當?shù)氖袌龇蓊~。攝像燃氣表以其成本低廉、不動火作業(yè)、可追溯等優(yōu)點在舊表改造中起到重要的作用。本文提出的燃氣字輪識別模型,針對不同燃氣基表廠商圖像結(jié)構(gòu)上的差異,引入了“行最大類間方差”作為注意力機制;針對連續(xù)字輪的問題,引入模糊數(shù)學隸屬度來作連續(xù)字輪圖像分類。試點應用結(jié)果表明,該模型可運行在單片機等低功耗設備上,從而可以降低網(wǎng)絡負載和功耗,且識別準確率大于99.99%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
