彈性自組織多集群管理系統設計與實現
2024-01-10 04:00:56夏令明
網絡安全與數據管理 2023年12期
關鍵詞:資源
夏令明,周 俊,趙 鋒
(網絡通信與安全紫金山實驗室 未來網絡研究中心,江蘇 南京 211111)
0 引言
單Kubernetes[1]集群無法滿足邊緣、地域、資源管理等需求,因此在東數西算等典型多集群場景中[2],將不得不解決集群的接入控制、集群資源抽象、權限管理、應用管理、多集群調度、服務維持、多租戶以及多集群服務發現等問題[3-5],這大大增加了多集群方案的復雜性和難度。目前社區和業界,集群拓撲均以父子兩層架構為主,父集群作為主控集群,其余集群為子集群,用于承載工作負載,其中主流的有Kubefed[6-7]聯邦方案、Karmada[8]、Clusternet[9]、Admiralty[10]四種。
Kubefed和 Karmada是一類,它們通過Template、Overide、Propgation 等定義負載的通用配置、專有配置和調度策略。Karmada 自Kubefederation發展而來,但是支持更豐富的插件化調度能力以及多集群服務(Multi cluster service)等特性,Karmada 也順利成為CNCF基金會孵化項目。但是這二者僅支持中心式的兩層架構,擴展性和承載力都存在理論瓶頸。
Clusternet 項目是一個踐行了OCM模型的多集群方案,也入選了CNCF沙箱項目,子集群通過受控的Token,在子集群啟動時,接入到父集群之中。父集群通過Aggregated API的方式對所有原生Kubernetes資源進行轉義形成Manifest文件推送到子集群中,Clusternet 同樣只能支持兩層架構,也存在上述擴展性的問題。
Admiralty 是一種多層調度模型,它達到了在使用多集群時和單集群一樣的體驗,特點是把負載依賴根據Pod 跟隨調度,支持軟件定義搭建多集群架構,但對應用沒有做任何抽象,所有的概念都是Kubernetes原生的。Admiralty在分布式云場景中難以實現應用的有效管理與維護。
以上四種方案,前三種無法實現多層自組織架構,這無法滿足擴展性要求,而東數西算等真實的組織架構一定是分層的。Admiralty 沒有對應用做抽象,只能基于Kubernetes 的調度框架去改造。為解決這些問題,本文提出了一種彈性的可自組織的多集群管理方案Gaia。
1 Gaia分布式云方案的設計
1.1 分布式云系統設計需要解決四個核心問題
(1)集群組織層級靈活多變
集群組織關系,即集群之間的關聯關系,也即它們是如何被組織在一起的,常見的模型有中心式、分布式、樹狀等。
(2)應用描述復雜
應用如何被抽象至關重要,它決定了調度的最小單元以及如何看待應用負載,例如Clusternet中的應用是Subscription,Admiralty的應用就是原生Pod。
(3)不依賴集群層級的調度器設計
調度器的設計依賴于集群組織模型,兩層架構的模型調度器就要求每層不同,但如果是N層模型,調度器就應該輸入輸出一致,這樣才能保證集群組織的靈活性。
(4)跨集群服務快速準確發現
應用被多集群部署后,需要快速準確地實施服務訪問,目前多集群方案均以集成為主,比如Admiralty集成了GSLB;早期Kubefed自研的Multi-Cluster Ingress DNS,后續陸續移除,并改為集成社區其他多集群服務發現的方案比如Istio;Karmada和Clusternet社區均集成Multi Cluster Service。
本文針對上述的第(1)、(3)個問題,提出彈性自組織的集群管理方法和多集群場景下的冪等分層調度方案。
1.2 概念
(1)集群關系
從軟件定義的理念出發,定義一個文件來描述集群兩兩之間的從屬關系,如圖1所示。其中Target描述了父集群的訪問方式和加入集群所需要的Bootstap Token。這樣可以將集群組成所期望的任意結構。需要說明的是,集群之間可以是雙向的,也可以是指向自己的。
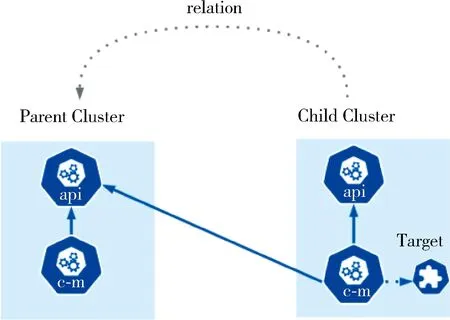
圖1 集群關系圖
(2)常見拓撲結構
①主備模式
主備模式中,子集群的Target指向父集群,同時父集群的Target 也指向自己,如圖2所示。這種模式可以將應用天然地配置到兩個集群中,是一種非常簡單的高可用模式,適合規模很小的環境,配置簡單。
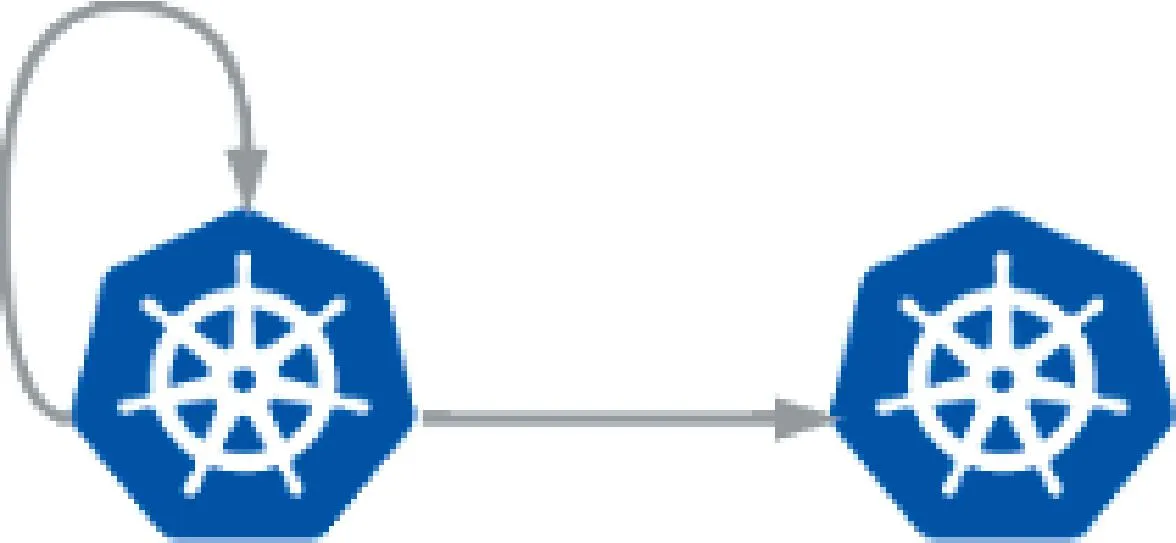
圖2 主備模式
②去中心化模式
該模式中,所有的集群既是父集群又是子集群,如圖3所示。這種去中心化的結構中,集群是Peer-to-Peer的關系,相較于主備模式該結構具有更強的穩定性和安全性。

圖3 去中心化模式
③中心式模式
這種方式有一個父集群做主控集群,托管N個子集群,如圖4所示。它適合中等規模的基礎設施環境,層級較少,管理簡單,但是拓展能力有限。

圖4 中心式模式
④樹狀模式
集群間根據Target 的指向,組成一個有層級的樹狀結構,如圖5所示。該結構適用于“云邊端”的復雜場景中,依靠冪等的分層調度器,可以輕松管理多云多廠商組成的大型且高復雜度的集群結構。
(3)冪等的分層調度器
在管控分布式云基礎設施時,無論采用哪種拓撲模型,Gaia控制器都不區分自己是什么位置。調度器的設計也必須堅持輸入輸出一致,這樣帶來的好處是,集群間的結構可以隨時變化,當有新的集群加入時,自己變成了父節點,但是它同時又是其他集群的子集群,所以每一個集群的組件都是一樣的。
1.3 Gaia分布式云調度設計
Gaia的控制面由Scheduler 和 Controller兩部分組成,如圖6所示。它的每一層集群所關注的資源只有輸入和輸出兩部分,其中調度器的輸入和輸出類型一樣,都是一種叫做APP的CRD資源,經過調度以后APP中會附加更詳細的調度結構信息。需要說明的是,在葉子集群上的調度器不對APP做任何調度處理,因為最底層的調度邏輯交給Kubernetes。
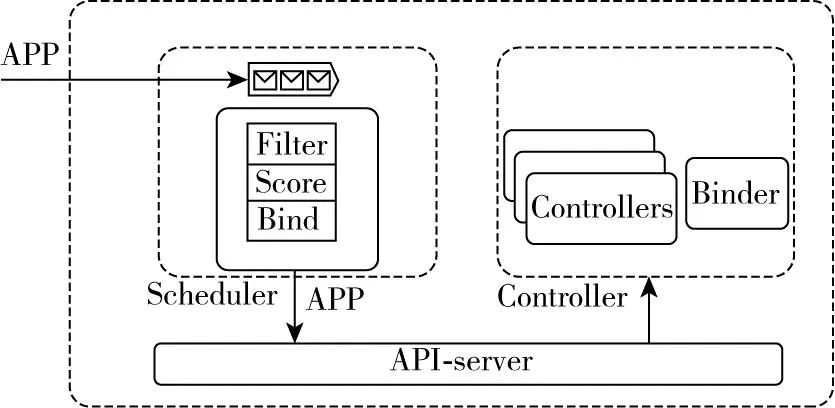
圖6 Gaia控制面圖
(1)Scheduler:只會把資源調度在注冊到自己的子集群中,所有調度器輸入和輸出都是APP。
(2)Controller:控制器包括集群注冊控制器、注冊審批控制器、狀態上報控制器、MCS(Multi Cluster Service)控制器等。
(3)Binder:僅在葉子集群發揮作用,當Binder發現APP調度成功且沒有子集群的時候,就把調度結果綁定到本集群。
2 方案功能實現
2.1 集群接入
葉子集群只用于承載工作負載,并不需要對外暴露公網地址,集群均為主動接入,資源同步采取Pull的模式。Gaia會被安裝在每一個集群中,等待Target資源指示如何接入Field集群,其接入過程如圖7所示。
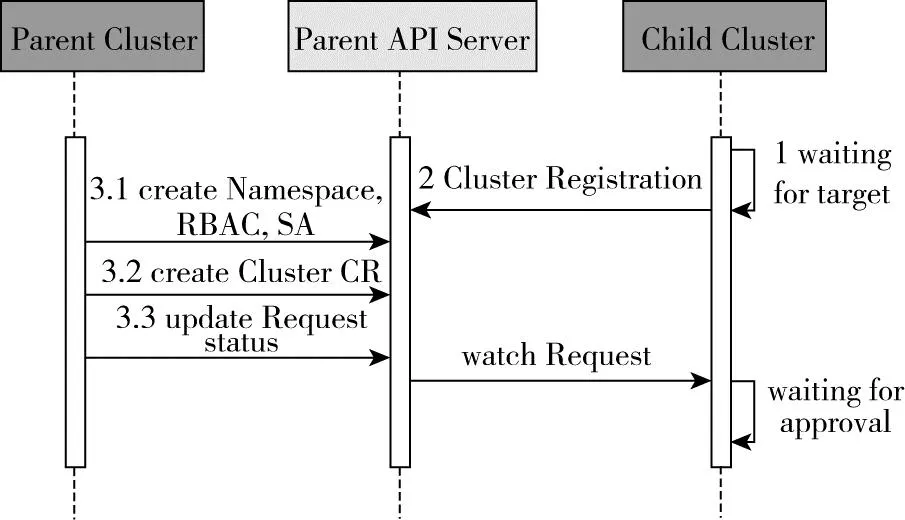
圖7 集群接入
(1)子集群Gaia組件啟動后,循環等待Target對象部署,期間不影響集群功能;
(2)部署Target對象后,本集群發起集群注冊過程,注冊為目標集群的子集群;
(3)在Parent Cluster創建命名空間(Namespace)、訪問規則(RBAC)、訪問賬戶(SA)、集群管理資源等,由Parent Cluster進行集群注冊審批;
(4)子集群持續等待審批結果,審批通過后便可拿到相應父集群的訪問權限,注冊為子集群。
一個典型的Target對象如表1所示,它包含父集群的地址、接入時的BootStrap Token以及本集群在父集群中的名字和一些其他信息。

表1 Target 對象
2.2 集群資源統計
集群接入后,子集群會根據上一步中Target配置的“reportFrequency”定時上報本集群的資源使用情況和結點的標簽匯總,這些信息被稱作Scheduler Cache。
2.3 APP資源調度
以三層的樹狀模型為例,每一個子集群在父集群中存在一個執行命名空間,在父集群接收到調度任務以后,會根據子集群上報的Scheduler Cache做基于水位的副本調度,每一級調度器都會經歷一系列插件,如圖8所示,不同層的插件沒有依賴關系。
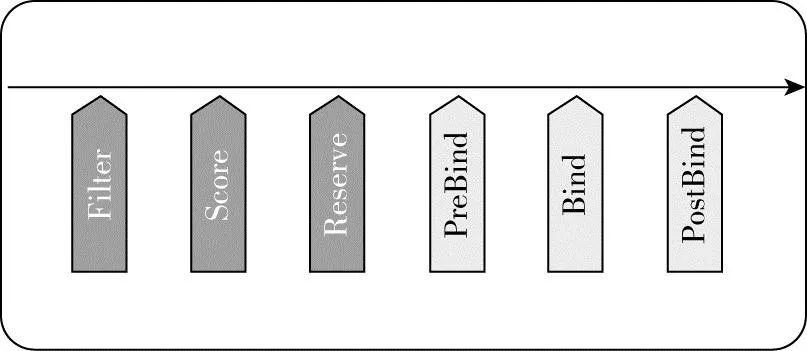
圖8 APP調度插件圖
完整的調度流程如圖9所示,在Binder判斷自己不存在子集群的時候,就會把本集群的調度結果推送到本集群,Binder的綁定過程比較簡單,不再詳述。
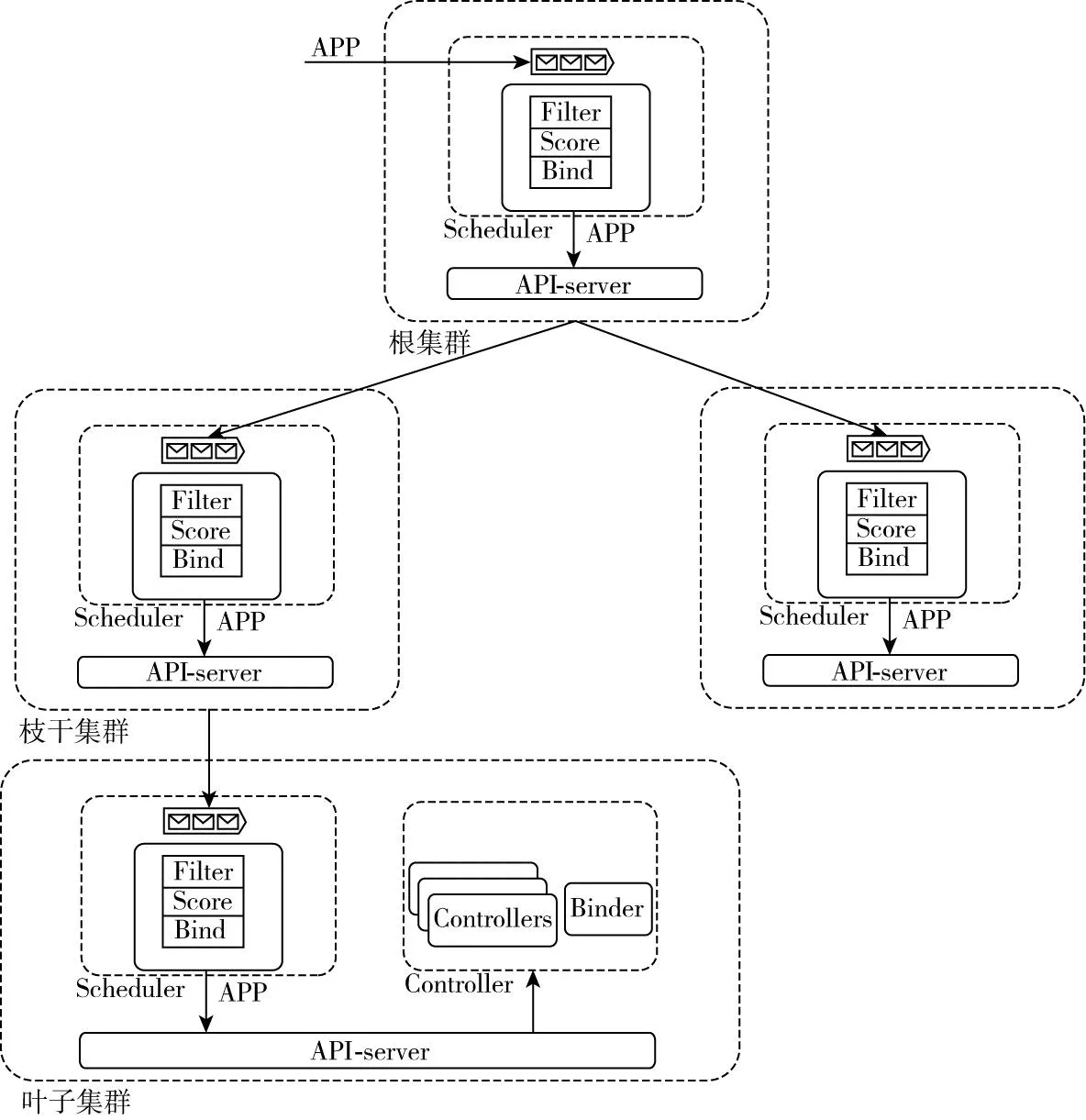
圖9 Gaia系統架構圖
該調度器的優點是:
(1)調度速度快,每一層都只負責自己當前層的調度;
(2)資源可以無限拓展,管理海量集群;
(3)拓撲結構靈活改動,應對多變的基礎設施;
(4)調度插件靈活可配。
缺點是資源上報信息粒度大,且沒有預占,集群高負載情況下會存在調度失敗的情況。
3 試驗驗證
基于以上描述,對集群注冊、分層調度器進行驗證。本文借助Kind工具部署1個Global集群、2個Field集群,每個Field下部署60個Cluster集群,搭建一個多集群的樹狀集群網絡的復雜基礎設施計算平臺,如圖10所示。
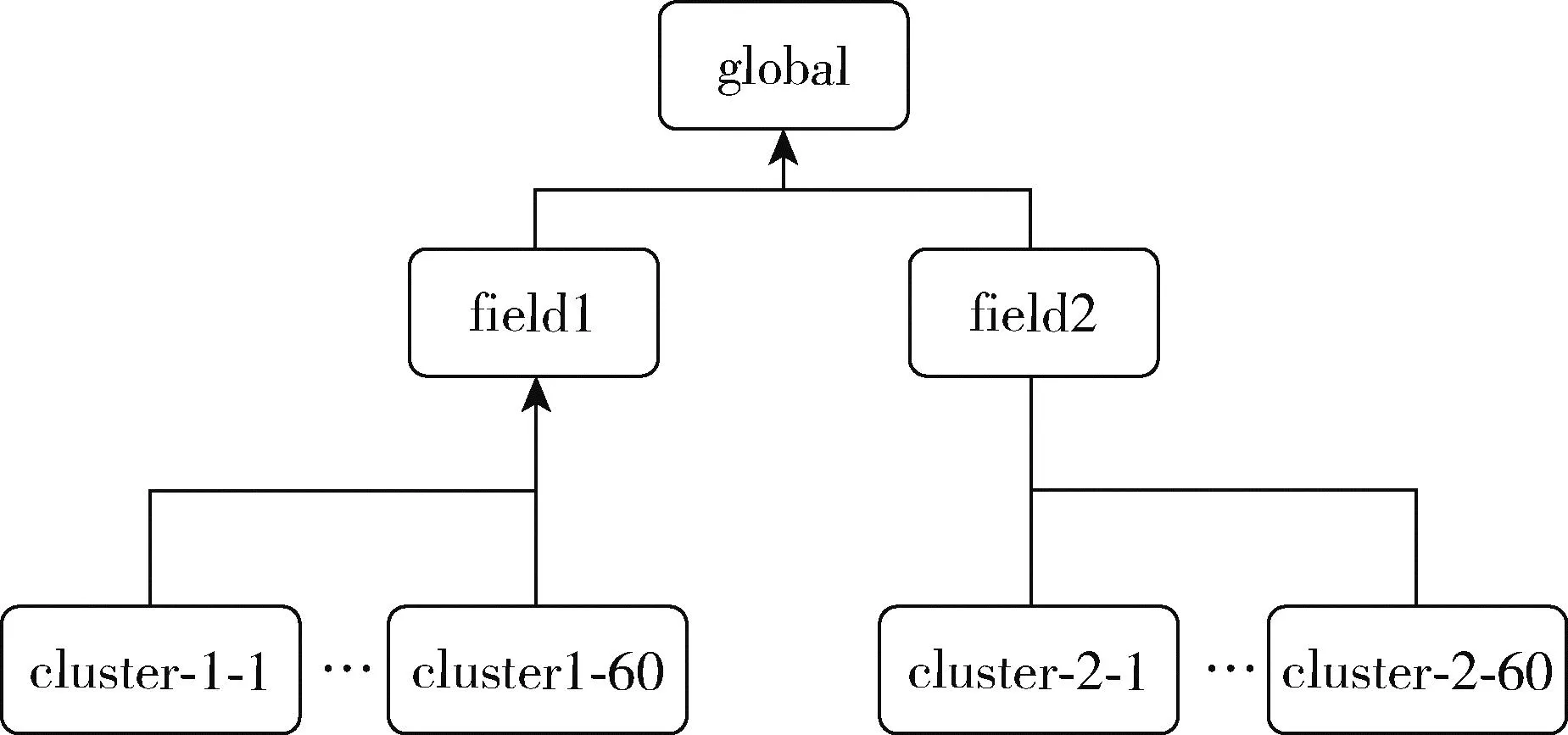
圖10 樹狀集群網絡結構
(1)集群準備
創建Kubernetes集群,在每一個集群上部署Gaia組件,這些Gaia組件還沒有通過Target資源去指定集群間關系,此時每一個集群都處于等待狀態。
(2)制作并創建Target
不同的集群依據Target對象文件,將本集群注冊為其他集群的子集群,其具體參數如表1所示。更改表中的“clusterName”為本集群提供唯一的注冊集群名稱;使用父集群的“parenturl”和“bootstraptoken”用于確認接入父集群的地址。
(3)集群狀態
除Global集群外,其他集群按圖10所示通過部署Target接入父集群,可以在各層查看管理的集群。集群注冊時延如圖11所示。在已有126個集群的規模下,集群的注冊延遲保持穩定在1 s。

圖11 集群注冊時延
作為對比,Karmada 方案做兩層集群管理模型時,其P50即中位數集群接入時間為5 356 ms[11],本方案的集群注冊時延遲穩定為1 012 ms。
(4)執行案例調度
在Global集群上部署應用,其應用調度時延如圖12所示,在126個集群的規模之下,應用平均調度延遲不高于200 ms,這里不包含資源創建的時間消耗。

圖12 應用調度時延
作為對比Karmada 的測試報告中提到,資源分發的用戶在聯邦控制面提交資源模板和下發策略后到資源在成員集群上被創建的P99時延,不考慮控制面與成員集群之間的網絡波動,P99≤2 s。
最后在Cluster級別集群上進行應用的綁定部署,提供相應服務。
4 結束語
本文分析了目前分布式云/多集群領域的研究現狀,并剖析了熱門開源社區的相關項目的特點,進一步歸納總結了分布式云系統設計面臨的4個核心問題。針對這些問題,提出了一種多層級、可軟件定義的多集群管理方案。它的每層調度邏輯都是冪等的。通過實際模擬126個超大規模的集群環境,驗證了該方案的可行性,試驗結果表明這種方案理論上可以無限擴展集群連接,同時保持應用調度和集群擴展的延遲保持在合理可用范圍,是東數西算等分布式云場景下的一種理想架構。
然而,多集群調度平臺不僅僅需要關注集群資源管理、負載調度的效率等問題,還要考慮應用抽象、多集群服務發現、多集群負載均衡等問題,目前這部分有一些解決方案,比如sigs/mcs-api、GSLB、Submariner等項目,后續工作需要繼續研究創新,使Gaia多集群方案功能得到進一步完善。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
資源節約與環保(2022年8期)2022-09-20 02:25:22
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
藝術品鑒(2020年7期)2020-09-11 08:04:44
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
當代貴州(2018年28期)2018-09-19 06:39:04
資源再生(2017年3期)2017-06-01 12:20:59
決策(2015年9期)2015-09-10 07:22:44
