融合知識圖譜的影視視頻標簽分類算法研究
2024-01-11 13:15:14蔣洪迅孫彩虹
計算機與生活 2024年1期
蔣洪迅,張 琳,孫彩虹
中國人民大學 信息學院,北京 100872
隨著視頻的形式越來越成為互聯網信息主體,文本的比例越來越低,視頻內容理解和識別變得越來越重要。內容理解(content understanding)是計算機的一種能力,包括對內容的吸收、處理、關聯,最后形成結構化數據。在影視場景下,視頻的類目體系是視頻網站運營中的重要工具,也是進行數據分析和推薦算法中提升冷啟動效果的重要手段,因此構建一套合理、準確率高、覆蓋率高的視頻標簽類目體系必不可少。
視頻標簽可以理解成描述一個視頻的幾個關鍵詞,當看到視頻標簽的時候就可以大概知道這個視頻的內容,作為內容理解的一環,層級分類的視頻標簽是很有效的一種管理方式,可以達到讓機器理解海量的視頻中的關鍵信息的目的,有助于視頻網站中基于內容的推薦和分發。具體來說,類目體系是一套類目的劃分標準,這個標準具有多層次的、經過討論定義明確的、視頻內容涵蓋全面的特點。在影視場景下,一般來說會構建一個如圖1所示的三級類目體系,包括類型標簽、題材標簽和實體標簽;其中類型標簽、題材標簽、實體標簽都是內容標簽的更細粒度標簽。
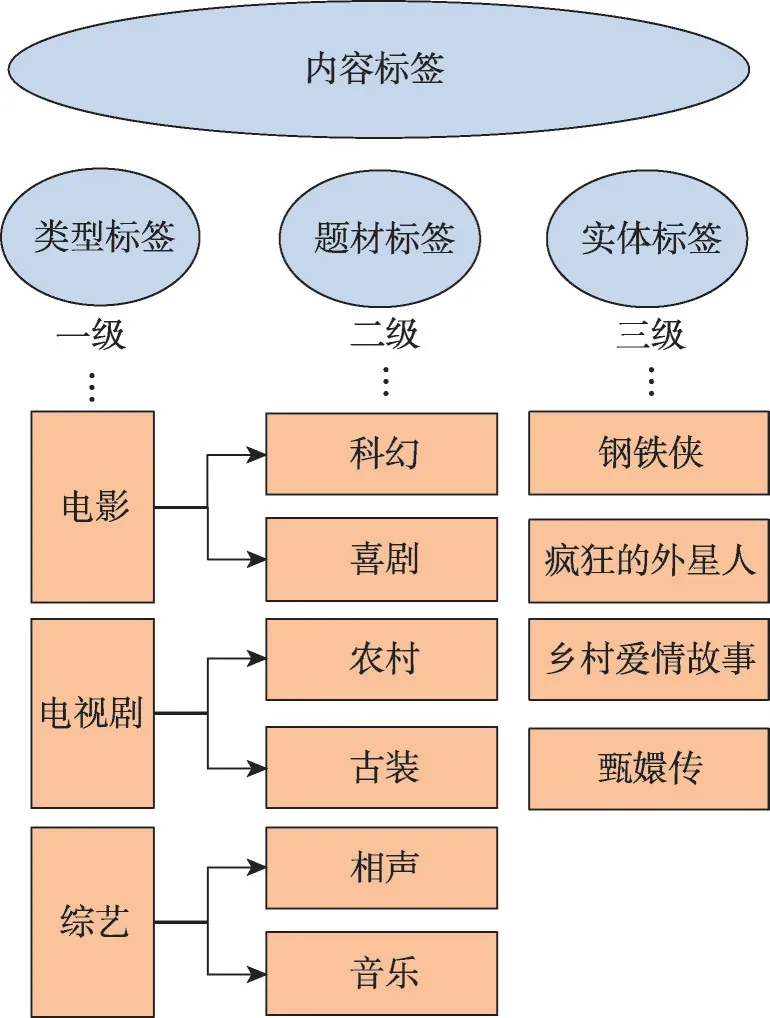
圖1 影視視頻標簽體系示意圖Fig.1 Diagram of video labeling system
標簽分類模型是依據標簽類目體系構建的,通過算法賦能,使得視頻標簽類目體系可以在各個業務方面發揮價值。根據實踐的經驗發現,當前影視場景下的視頻標簽分類模型存在以下兩個問題:(1)數據標注少。互聯網用戶上傳的視頻在內容和質量方面存在很大的差異,用戶生成的標題通常不完整或者模棱兩可,并且可能包含錯誤。雖然有很多的視頻影視劇,但是高質量數據標注量較少。(2)實體標簽細粒度不夠。雖然當前一些視頻標簽分類的基線模型在影視場景下整體的標簽識別上得到不錯的效果,但對于一些在視覺上相似的劇集處理得不好,需要增加特征做進一步識別。
本文的貢獻主要體現在多任務標簽預測的研究角度和最細粒度內容標簽的實體糾錯處理上。相比以往的同類研究,本文跳脫了通常的大規模語料訓練標簽分類算法,更多著眼于實體糾錯的新研究角度,在方法上也不再局限于傳統的按級別的分層標簽預測分析,而是基于多模態預訓練模型和影視資料知識圖譜提出了一個兩階段的視頻標簽分類框架和實施方法,如圖2 所示。具體來說,創新點主要體現在三個方面:在特征輸入方面,使用了基于大規模通用數據訓練的多模態預訓練模型提取視覺和文本的特征,訓練了一個多任務的視頻標簽預測模型,同時獲取視頻的類型、題材和實體三級標簽;在模型結構方面,提出了一種基于多任務學習框架的視頻標簽分類模型,在多任務學習網絡中引入相似性任務提高了分類模型訓練的難度,使得同類樣本特征更加緊密,同時保證所學特征能更好地表達樣本差異,避免了樣本偏斜造成的局限性和過擬合,保證預測效果、客觀性和泛化能力;在實體糾錯方面,不再局限于現有語料內的孤立信息,而是引入外部知識圖譜的共現信息,通過一個局部注意力頭擴展的實體糾錯模型,對前置模型的預測結果做修正,得到更準確的實體標簽預測結果。本文后續的多任務消融實驗也驗證了所提方法在較細粒度標簽分類問題上的有效性,而且新方法可以在少量樣本上達到較好的分類效果,表明該模型也適用于其他領域內的數據集較少的情況下的分類任務。
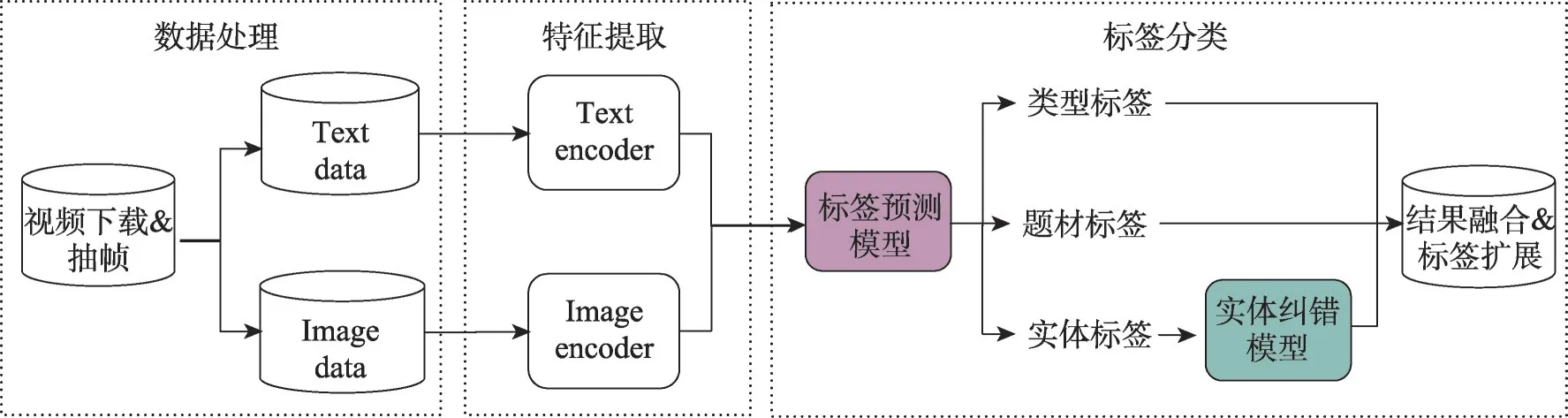
圖2 影視視頻標簽分類模型架構圖Fig.2 Architecture diagram of proposed video labeling model
1 影視視頻標簽分類相關工作
1.1 視頻標簽分類模型
視頻標簽研究屬于分類任務,學術界中視頻標簽分類算法的研究經過了長時間的發展。一般來說,視頻標簽分類的處理流程可以分為以下三個步驟:第一,數據的采樣和預處理;第二,學習視頻的時間和空間特征;第三,時序特征的動態融合。視頻標簽研究可以分為純視頻標簽分類算法和多模態預訓練模型兩個方向。
傳統視頻標簽分類算法是指只涉及視頻圖像幀輸入的算法。得益于近些年深度學習的快速發展和機器性能的大幅提升,視頻標簽分類主流算法已經從傳統手工設計特征變成端到端深度學習的方法。視頻標簽分類的相關工作中,使用深度卷積神經網絡和時間序列模型相結合的方式學習時間和空間特征是目前的研究熱點。一般的做法是,將視頻抽幀之后,用二維的卷積神經網絡(two dimensional convolutional neural network,2D-CNN)抽取視頻里面每一幀的特征,然后將所有幀的特征平均池化到一起變成視頻特征進行分類[1]。但是這種做法的問題在于視頻往往包含的幀數非常多,對每一幀都抽取特征會有非常大的計算開銷,并且對特征做平均池化難以捕捉視頻的時序信息。針對視頻抽幀問題,TSN(temporal segment networks)模型[2]提出基于片段間隔采樣的方法來解決連續抽幀導致計算開銷大的問題,同時采用分段共識函數來聚合采樣片段中的信息,在整個視頻上對長時間依賴的結構進行建模。針對視頻時序信息,引入了循環神經網絡來學習視頻序列數據,TT-RNN(tensor-train recurrent neural networks)模型[3]將張量分解的方式應用于循環神經網絡模型,使用訓練好的張量替換原始輸入層到隱藏層的權重矩陣,在同樣效果下計算復雜度低于原始循環神經網絡模型。NetVLAD(net vector of locally aggregated descriptors)模 型[4]、NextVLAD(next vector of locally aggregated descriptors)模型[5]使用聚類算法聚合視頻幀中圖像局部特征,在降低特征維度的同時還能很好地保證模型的性能。由于NetVLAD模型的缺點是特征維度高且計算復雜,分類模型需要上百萬的參數。為了解決NetVLAD 中參數爆炸的問題,在NetVLAD 模型的基礎上,在其VLAD 層增加了非線性參數,降低了其輸出層參數[6],從而整體參數量下降,但性能并不下降。同時還使用了注意力機制來聚合時間維度的信息,得到視頻中不同幀的分類貢獻度。在最近的研究中,3D CNN(three dimensional convolutional neural network)對圖像序列采用3D 卷積核進行卷積操作,同時捕獲視頻中的時間和空間特征信息。I3D 模型[7]在網絡中加入了光流信息作為輸入,將特征提取網絡里面的2D 卷積核展開成3D 卷積核來處理整個視頻,視頻圖像和堆疊的光流兩個流的結果融合作為最終輸出結果。Non-Local模型[8]則在3D ResNet 模型里面引入了自注意力機制,通過注意力學習時間和空間的全局信息,相當于擴大了卷積核的感受野。同樣基于注意力機制,Attention Cluster 模型[9]將經過卷積神經網絡模型抽取的特征使用堆疊的注意力模塊集成局部關鍵特征。Slow-Fast模型[10]引入快和慢兩個不同時間分辨率的通道,分開處理空間維度信息和時間維度信息,學習視頻的靜態和動態變化。同時,通過快和慢兩個分支,SlowFast 模型探討了不同采樣率下雙流信息交互融合的方式。此外,Regularized-DNN(regularized deep neural networks)模型[11]提出了一種正則化特征融合網絡,在神經網絡中加入正則化來利用特征之間的關系和類別之間的關系自動學習維度特征相關性,可見多特征融合也是一個研究的方向。
在視頻標簽分類領域,多模態預訓練模型通常包括圖像模態的信息和文本模態的信息。對于圖片和文本的多模態預訓練模型,從模態的交互方式上,可以分為單流模型和雙流模型兩種。在單流模型中,語言模態的信息和視覺模態的信息融合之后整體作為輸入,然后直接輸入到編碼器中。單流模型代表的模型有VisualBERT(visual bidirectional encoder representation from transformers)[12]、Unicoder-VL(universal encoder for vision and language)[13]、ImageBERT(image bidirectional encoder representation from transformers)[14]、VL-BERT(vision and language bidirectional encoder representation from transformers)[15]等。基于圖像切塊投影的ViL-Transformer(vision-and-language transformer without convolution or region supervision)模型[16]也延用了單流交互方式,減少引入額外的計算量,將圖片拆分成若干個Token 進行編碼。在雙流模型中,語言模態的信息和視覺模態的信息會先分別經過兩個獨立的編碼器,得到編碼特征后再輸入到模態的交互層,不同模態的信息在語義上的對齊和融合是在模態交互層上完成的。在交互編碼層中,模型使用共同注意力機制,即自注意力模塊中的查詢向量(Query)來自一個模態,而鍵向量(Key)和值向量(Value)來自另一個模態。經過交互層的編碼后,圖像特征和語言特征會分別再經過一個自注意力網絡層來學習高階特征。雙流模型代表有ViLBERT[17]等模型。目前單流模型和雙流模型的特征編碼器都是基于Transformer 框架搭建的,不同在于模態融合時是否進行了關鍵向量的交互學習。這些多模態預模型在訓練時需要標簽類別信息進行有監督訓練,依然存在對大規模標簽類別標注的依賴性。而對比自監督訓練方式則可以較好地解決這個問題。對比自監督學習是一種訓練編碼器的簡單思路,關鍵思想是在特征空間中最小化正樣本對之間的距離,最大化負樣本對之間的距離,使得編碼器對相似內容輸出相似的結果。基于對比自監督學習的思想,通過編碼點積計算即可獲得兩個內容之間的匹配程度。CLIP(contrastive language-image pre-training)模型[18]基于比對自監督方式采用4 億對圖像-文字進行預訓練,將分類模型轉換為圖文匹配任務,用文本弱監督圖片分類,學習文本與圖片相關性,在多個下游任務中獲得了非常好的實驗效果。
1.2 多任務學習
多任務學習是指基于共享表示,同時訓練多個任務的機器學習方法。訓練過程中,多個任務共享樣本信息、模型參數以及底層的表征信息,多個任務的損失值合并計算后同時驅動梯度進行反向傳播,從而完成層次結構信息的使用,優化模型的網絡層參數[19]。細粒度識別的關鍵挑戰是生成有效的特征表示,以減少類同圖像之間的差異,同時擴大不同類圖像之間的差異。Parkhi 等人[20]提出首先使用分類損失函數學習人臉分類的同時使用相似性損失函數來微調和提升性能,最終提升了人臉識別的準確性。秦佳佳[21]也在心理研究角度說明了相似性任務在類別學習中的有效性。在本文中,細粒度的圖像理解旨在區分每一個影視劇集,這個任務存在兩個挑戰:一方面,許多影視劇集之間具有高度相關性,并且場景圖像之間存在細微差異難以區分(類間方差小);另一方面,同一部影視劇存在場景、人物、背景的轉換,當以不同的姿勢、光照、場景、人物和遮擋物呈現時,同一部劇集的畫面看起來會有很大不同,視覺上效果差異較大(類內方差大)。在分類預測階段,本文設計了一個多任務深度學習框架,將多個任務合并學習,通過分層非線性映射來學習細粒度圖像識別的有效特征。
基于視覺信息訓練的單模態視頻標簽分類模型一般是對數據進行端到端的訓練,需要較大規模的數據量。不過數據標注成本較大并且大規模數據集的訓練也非常消耗算力[22],零樣本學習、基于預訓練模型的遷移學習逐漸成為新的研究趨勢,旨在達到從已知樣本到未知類別的知識泛化學習[23]。基于圖片、文本等信息的多模態視頻標簽分類模型則可以很好地利用文本和圖片信息的交互知識,但有監督學習仍然存在數據依賴,而CLIP 可以利用文本對圖片進行弱監督學習。
1.3 待解決問題
本文要研究的影視視頻標簽分類算法屬于視頻標簽分類任務,即從一段視頻提取若干關鍵幀,為它們打若干標簽后再聚成該視頻的標簽。但是影視視頻標簽分類與通用領域的視頻標簽分類不同的是,其關鍵區分特征多與畫面內容、人物關系、場景布局、臺詞字幕等因素有關,不能直接使用在通用領域數據集上預訓練的模型完成預測。況且影視領域目前還沒有一個標注好的大規模數據集,本文將在CLIP 圖文預訓練模型下游添加影視數據集,采用圖文預訓練模型+下游分類任務微調的形式,將多層級標簽視為多個分類任務,每一個分類任務同時結合分類損失函數和相似性度量損失函數進行標簽預測,在少量樣本上達到較好的分類效果。
2 融合知識圖譜的影視視頻標簽分類算法
本文提出了一種融合知識圖譜的影視視頻標簽分類模型,該模型旨在通過圖像-文本兩個模態建模,利用視頻中豐富的語義信息為視頻內容打上多層次的標簽;同時,針對更細粒度標簽識別的困難樣本,結合知識圖譜信息完成進一步的知識推理過程,最終得到影視視頻更準確的內容標簽。
2.1 標簽預測模型
本文構建的標簽預測模型,其總體架構如圖3所示,由輸入模塊、特征提取模塊、模態融合模塊和多任務分類預測模塊組成。具體來說,模型采用了圖文預訓練模型+下游分類任務微調的形式,將多層級標簽的識別視為多個孤立的分類任務,對于每一個分類任務都結合分類損失函數和相似性度量損失函數進行預測。
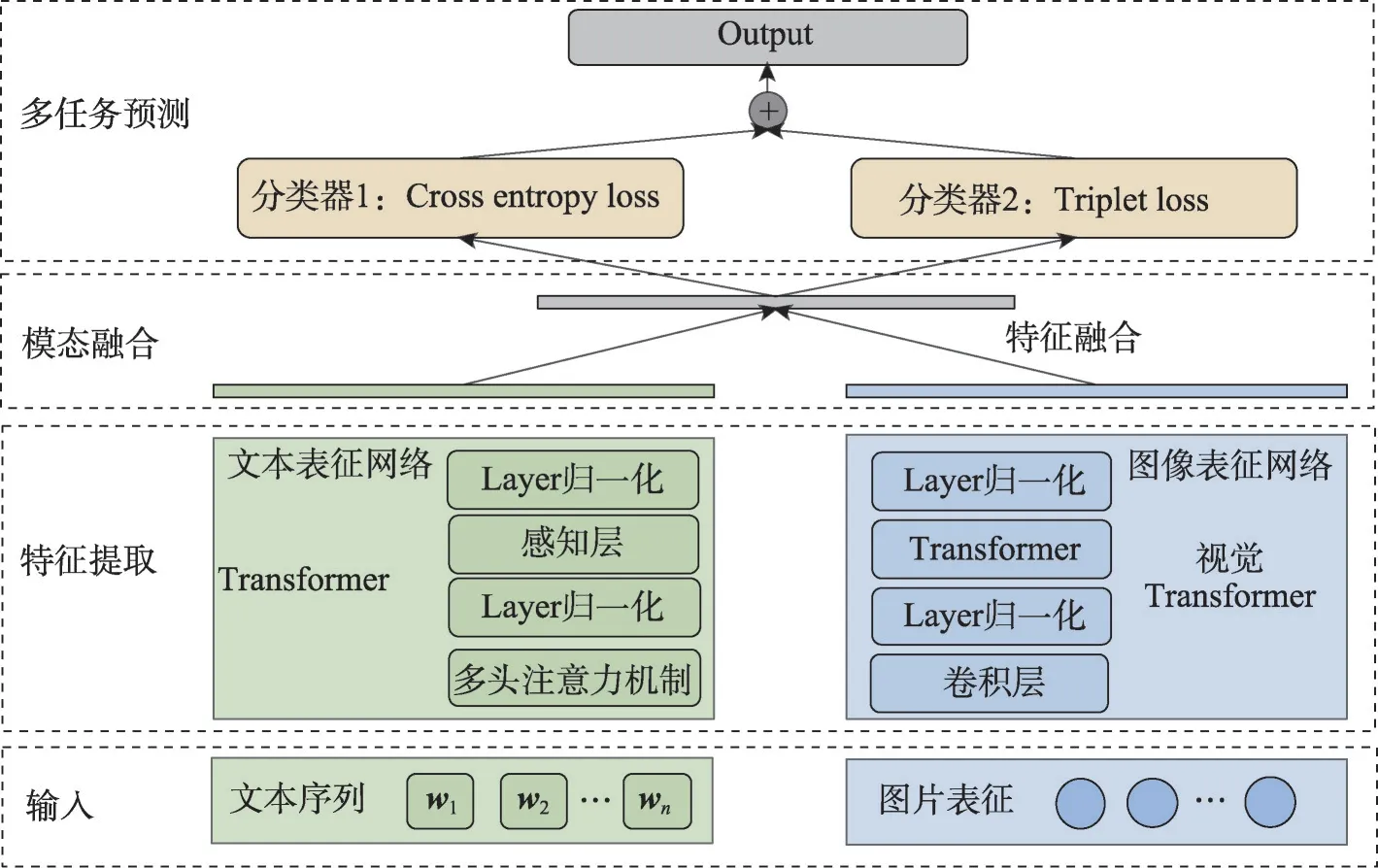
圖3 標簽預測模型的算法框架圖Fig.3 Algorithmic framework diagram of label prediction model
標簽預測流程可以概括為,給定一組圖文對輸入,包括文本序列{w1,w2,…,wn}和圖片編碼{r1,r2,…,rn},其中每條文本會被切分為若干個Token 進行編碼,兩個序列分別經過文本和圖像特征提取分支,訓練獲得同一語義空間下的表征,特征融合后饋送到下游任務層進行預測,優化模型參數最小化損失值,最終得到預測結果。
2.1.1 特征提取網絡
特征提取模塊采用了基于大規模通用圖文數據訓練出的多模態預訓練模型,文本、圖像表征網絡接收文本、圖片兩個模態的輸入,分別通過一個圖像編碼器和一個文本編碼器計算圖像和文本的特征,再分別進行L2 范數的歸一化操作,讓文本特征和圖像特征的特征尺度保持一致,得到文本特征Embt和圖像特征Embi。具體過程參見算法1。
算法1特征提取網絡
在文本分支中,將{w1,w2,…,wn}中每個token 的詞向量和位置向量相加作為輸入向量。文本是有序的,位置向量是指將token 的前后語序信息編碼成特征向量的形式,把單詞的位置關系信息引入到模型中,從而獲取文本天生的有序信息。然后將輸入向量饋送到Transformer的Encoder中來編碼輸入,每一個Encoder 中包含兩個子層:第一層是多頭自注意力機制,包括12 個注意力頭;第二層是前向傳播層,用來提高模型的非線性擬合能力。每個子層都使用了殘差網絡,在訓練過程中可以緩解梯度消失的問題,使之可以構建更深層的網絡。整個Transformer 共堆疊了12 個這樣的Encoder 結構。最后將Transformer的輸入饋送到layer norm 網絡中對樣本特征做歸一化,得到1 024維特征Embt。
在圖像分支中,深度卷積網絡中的卷積和池化操作用于分層提取視覺特征。輸入是單張圖片,首先調整輸入圖片的大小格式,將給定圖像縮放到224×224 的大小,按比例裁剪圖片,保留最中間的圖像部分,再對圖片每個通道的像素值執行歸一化操作。這里使用由若干個殘差模塊構成的ResNet-50網絡作為圖像特征提取的骨干結構。ResNet-50包含49 個2D 卷積操作和一個全連接層,首先對輸入做卷積操作,然后輸入到4個不同卷積核尺寸的殘差模塊中,最后進行全連接操作以便進行分類任務。在2D網絡中,卷積和池化的操作主要在空間上進行,最終得到1 024維特征Embi。
2.1.2 模態融合網絡
本文采用中間融合的方式,將上一層特征提取網絡得到的文本特征Embt(N,1 024) 和圖像特征Embi(N,512)分別看作兩個token,將這兩個token 拼接之后得到Emb(N,2,1 024),再饋送到Transformer的Encoder模塊中對兩個token融合。
本質上,基于Encoder 模塊做特征之間的融合,可以解釋為將查詢向量Query、鍵向量Key、值向量Value 3 個向量在注意力的多個輸出頭分別進行點積計算,并分別得到自適應的加權方案。對于不同區域的信息,按照不同的加權值結合起來最終得到整體的向量表達[24]。在這里,Encoder 的主要作用是學習同一樣本中文本token和圖片token的交互特征,最終得到一個固定長度的向量表示Embattention。
其中,Emb*Wq為查詢向量Query,Emb*Wk為鍵向量Key,Emb*Wv即值向量Value,Wq、Wk、Wv分別代表3組不同的參數矩陣,用于將輸入的同一個Emb映射到3個不同的向量空間。本文的特征融合Encoder堆疊了6 層這樣的編碼層,每一層使用了8-head 的注意力模塊,相當于在8 個不同的通道進行了圖片、文本模態特征的融合學習。
2.1.3 多任務預測網絡
標簽預測模型學習的目的就是學習一組參數,使得模型預測的結果與樣本的真實標簽一致,也就是損失函數的值最小。本文將分類任務的交叉熵損失函數和相似性損失函數結合在同一個網絡中進行多任務訓練和聯合優化。如圖4 所示是多任務網絡層的結構圖,經過模態融合之后的特征先經過若干個全連接層,然后被輸入到分類網絡和相似性網絡同時進行訓練。
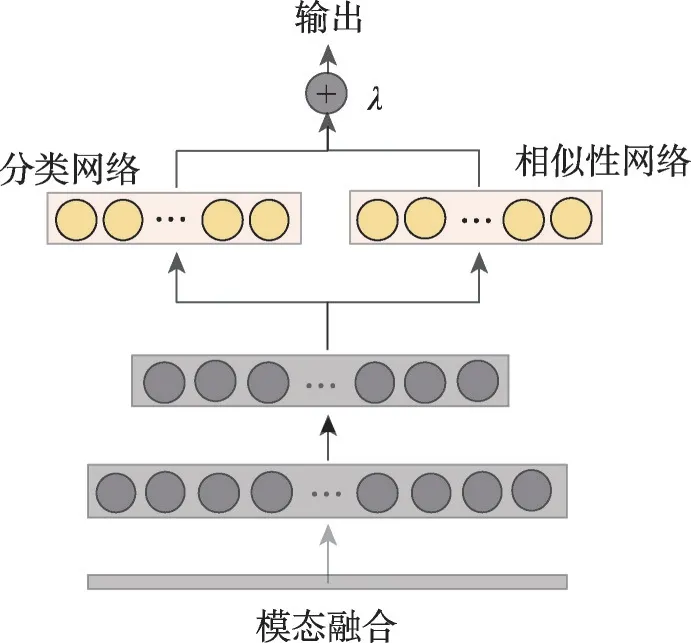
圖4 多任務網絡層結構Fig.4 Layer-structure of multitasking network
交叉熵損失函數(cross entropy loss)是經典的分類損失函數,由softmax公式和交叉熵(cross-entropy)公式兩個組合。假設有N個訓練樣本,歸屬于C個類別,其中每個樣本ri被標記為類li。如式(3),假定最終全連接層的輸出是fs(ri,c),交叉熵損失函數的計算公式如下:
其中,fs(ri,c)表示最后的全連接層在輸入為ri下,第c類的輸出,li為對應輸入的類別標簽。可以看到,這個計算公式旨在將相同類的數據“擠壓”到特征空間的同一個角落,因此沒有保留類內方差,而類內方差對于發現視覺和語義相似的實例至關重要。
度量學習則可以通過學習特征表示來解決這個問題,使得來自同一類的樣本聚集在一起,來自不同類的樣本則相互遠離,即擴大類間距離和縮小類內距離。除了單獨使用分類損失函數進行約束之外,相似性任務使用了Triplet Loss[25]與分類損失融合起來用于特征表示學習。在計算時,有3個樣本表示為(ri,pi,ni),其中ri是來自特定類的參考樣本,pi是來自同一類的樣本,ni是來自不同類的樣本。給定一個輸入樣本ri,Triplet Loss 驅動的網絡可以生成一個特征向量ft(ri) ∈RD,其中超參數D是特征維度。理想情況下,對于每一個參考樣本ri,期望它與不同類的任何ni的距離比同一類中的pi大一定的邊距m>0,也就是說D(ri,pi)+m<D(ri,ni)。
式(4)是Triplet Loss 的計算方式。為了計算Triplet Loss,還將特征進行了L2 范數歸一操作,其中D(.,.)是Triplet 網絡中兩個融合特征經過L2 范數歸一化之后的平方歐幾里德距離,m為最小邊距。
損失函數是指導模型學習方向的準則,根據損失函數的求導方向可以做反向傳播來修改模型參數。在多任務框架中,模態融合之后的特征表示會同時被輸入到Softmax 分類網絡和Triplet 相似性網絡,Softmax 分類網絡的輸出fs(r)被轉發到Softmax損失層以計算分類誤差Losss(r,l),Triplet 相似性網絡的輸出ft(r)被轉發到Triplet 損失層以計算分類誤差Losst(r,p,n,m)。分類任務和相似性任務的輸出可以看作兩個獨立的預測場景,在多任務融合階段,如式(5),本文通過加權組合來整合這兩種類型的損失。λ是兩個任務的權重系數,取值范圍在0~1之間。
2.2 實體糾錯模型
實體糾錯模型服務于第三級標簽的識別任務,進一步對實體標簽的識別結果做優化。標簽預測模型根據概率選取最終分類結果。然而實體標簽的粒度非常細,對于在視覺畫風相似、場景人物相似的情況下往往會出現多個相似影視劇集難以區分的情況,導致出現錯誤識別的實體標簽。以圖5 場景為例,正確的標簽是“延禧攻略”,而分類模型給出的結果排序是“陳情令、延禧攻略”。由于“陳情令”的預測分數大于“延禧攻略”,導致其作為概率最大的標簽被輸出。這種情況來自于兩方面的原因:其一,這個樣本的文本信息無法給出與“延禧攻略”劇集相關信息;其二,樣本的圖像在視覺畫風、場景布局上與“陳情令”相似,導致難以區分。

圖5 錯誤預測的一個實例Fig.5 Example of wrong labeling prediction
本文采用引入外部知識圖片中的元數據(metadata)信息來解決上述問題。根據圖像中出鏡的人臉識別和現實生活中的人物關系知識圖譜,可以獲知視頻中出現了演員“許凱”,結合該演員的出演歷史可排除“陳情令”,從而得到正確標簽。基于此,本文提出了優化視頻標簽分類的第二階段模型,一種融合知識圖譜的實體糾錯方法。引入預先構建的知識圖譜節點和節點關系作為對文本信息和視覺信息的補充,訓練擴展注意力機制的先驗知識模型,提高影視實體標簽識別的準確性和覆蓋率。
實體糾錯任務可以形式化為:給定一批訓練樣本G={g1,g2,…,gn},其中g∈{n1,n2,…,N}。對于每一個輸入g,隨機將一部分節點信息掩蔽之后得到g∈{n1,[mask],n3,…,N},節點ni包括影視名稱節點和演員節點以及一個特殊的MASK 節點。本文目標是訓練一個重構缺失節點模型,預測其出現概率最大的節點ni∈g。在圖神經網絡中,圖卷積層會計算當前節點與所有鄰居的得分,加上注意力機制可以為其提供自適應加權方案,為不同節點分配不同權重,并且只需要計算鄰居或者多階范圍內的鄰居。基于圖注意力網絡思路,本文添加局部注意力頭擴展Transformer模型,并采用BERT類似的掩蔽機制來預測最終標簽結果,同時結合知識圖譜的節點關系考慮節點預測的合理性。
實體糾錯模型的總體架構如圖6 所示。對于某個待定視頻,將一定概率的候選名稱看作影視節點,出鏡人物識別出的演員看作演員節點,每個節點為一個token向量輸入模型。訓練模型時提取影視知識圖譜中的劇集-演員兩類實體,構建成一個二部圖,將其鄰接矩陣輸入模型中。在預測階段,例如輸入“張若昀”“郭麒麟”“宋軼”3 個演員名字,就能得到與之相關性最高的影視劇名稱是《慶余年》。
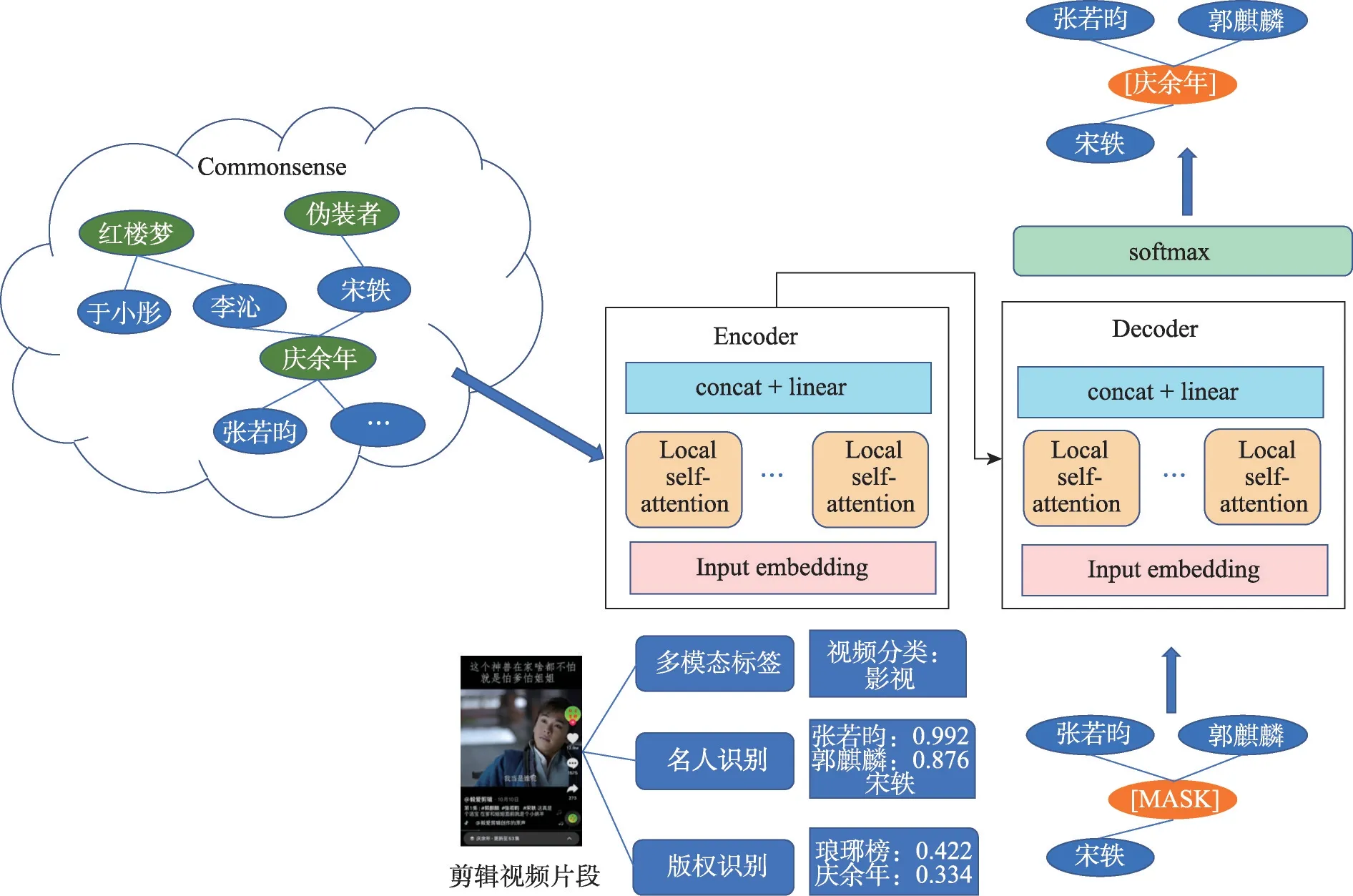
圖6 實體糾錯模型的體系結構圖Fig.6 Structural diagram of entity error correction model
本文改進了Transformer 的Encoder 部分。傳統Transformer自注意力機制需要計算所有token的Query向量、Key向量和Value向量,相當于算得全局注意力分數;細粒度的實體標簽糾錯,本文更關注相鄰節點的作用,只需計算具有出演或合作關系的明星與影視劇名兩個實體間的注意力分數,無需對所有實體計算token,本文將Encoder中一部分注意力頭替換成了局部注意力,基于知識圖譜來修正計算視野,將非鄰居節點間注意力強制為零。具體過程參見算法2。
算法2實體糾錯模型
其中,Hl是第l層的注意力頭集合,Wl和bl為該層訓練權重和偏差,沿矩陣列進行concatenate操作。在實際訓練過程中,本文將使用兩種類型的注意力頭,即全局注意力頭和局部注意力頭:
對于全局注意力頭,每個節點可以通過全局注意力關注所有其他節點,與每一個節點都進行交互并計算注意力分數。全局注意力是典型的自注意力計算方式,每個注意力頭具有獨立的初始化參數和訓練參數,但是計算過程是相同的:
其中,q(?)、k(?)、v(?)分別表示節點表征X(l)經過3 個不同的參數矩陣映射之后的Query 向量、Key 向量和Value 向量。對于局部注意力頭也是同樣的思路,不同之處是查詢向量只能與其直接鄰居節點的關鍵向量進行交互并計算注意力分數:
其中,As是知識圖譜的鄰接矩陣,包含影視劇節點和演員節點,影視劇和演員之間有交互關系,在出演關系的影視劇-演員之間為1,其余地方為0。最后,本文使用交叉熵損失函數來訓練網絡計算所有類別的概率分布來預測輸出節點類別,具有最高概率的類就是經過糾正之后的標簽。
3 實驗與分析
3.1 數據描述
當前有很多視頻片段數據集,但是在影視劇領域還沒有一個標注好的、可供訓練的標準數據集。目前已有的一些視頻標簽的公開數據集,難以符合三級標簽的影視劇視頻的應用場景,這些數據標簽都在相同層次上,譬如類型標簽或題材標簽,但缺乏更細粒度的實體標簽,況且影視視頻標簽分類的關鍵特征跟畫面內容、人物關系、場景美工、拍攝風格、臺詞字幕等因素都有關,本文也難以借用其他領域的通用視頻標簽數據集。此外由于視頻數據源較難獲取,在數據預處理時,需要同時完成抽幀和文本識別操作,本文考慮以(圖片,文本)對的形式組織數據,用多張相似圖片模擬視頻連續抽幀結果。一個視頻包括圖像信息和文本信息,本文最終分別爬取了圖片和對應的文本作為多模態信息。也就是說,利用搜索引擎構造了數據集。其中,文本和圖片信息均來自百度圖搜,例如輸入query=“小敏家電視劇”,可以獲取網站返回的若干張圖片,選取自劇集截圖且保留該圖的標題文本描述。百度圖搜返回的結果是經過排序篩選的,相關性較高,本文可以將此類(圖片,文本)對作為訓練數據。
本文最終收集的數據如表1所示,數據來自于豆瓣電影平臺的標簽體系,共包含24 000 圖文對,分別歸屬于240 部影視劇集,每個影視劇集包含100 個(圖片,文本)對。其中,視頻真實標簽的信息來自豆瓣,輸入query=“小敏家”,本文可以從豆瓣爬取到該劇集的詳細信息,包括一級標簽“電視劇”、二級標簽“劇情/家庭”、三級標簽“小敏家”,甚至可以獲得編劇、演員、上映日期等信息,便于以后構建影視領域的知識圖譜。
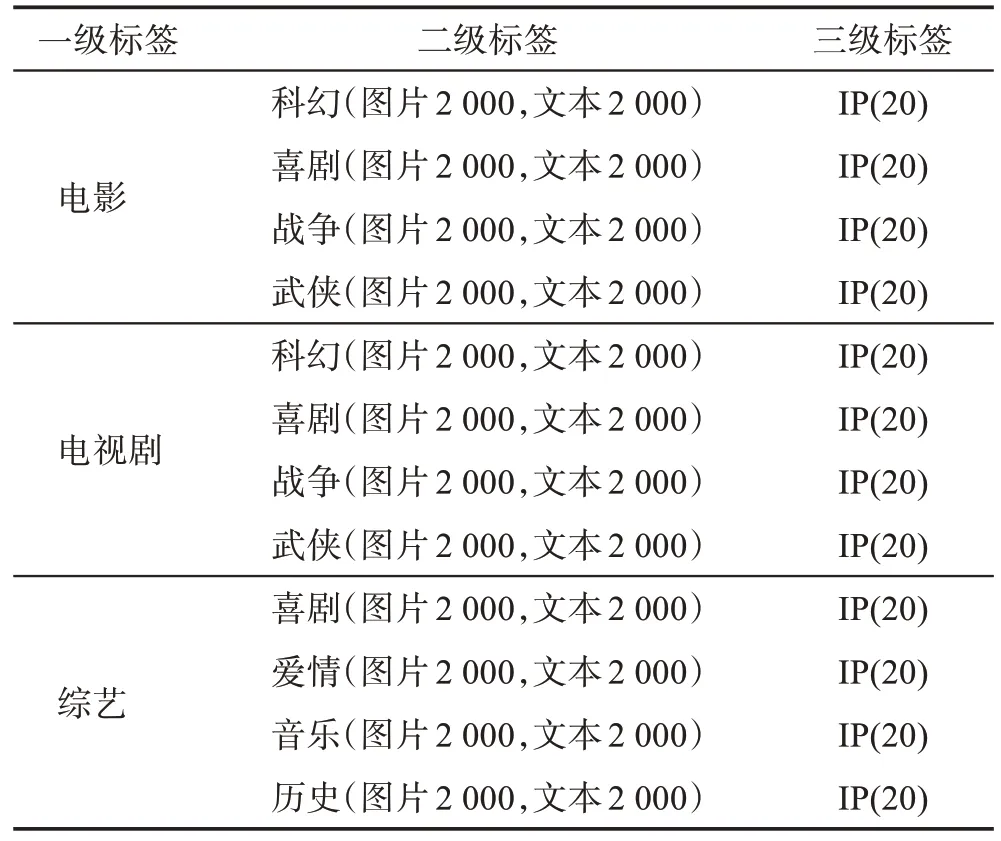
表1 數據集標簽統計表Table 1 Statistics of dataset
3.2 實驗設置
在評價指標方面,本文采用Top-N Acc、MacroP、MacroR和MacroF1作為評價指標,多分類問題中真實的樣本標簽有多類,學習器預測的類別也有多類,混淆矩陣在高維情況下難以直觀表示分類效果。本文將多分類的評價拆分成若干個二分類的評價,計算每個二分類的F1-score 平均值作為MacroF1 評價指標。Top-N Acc是視頻多分類的常用評價指標,計算公式如下:
其中,M是總樣本數量,I(x)為指示函數,當x為真時,表達式為1,否則為0。在Top-N準確率指標中,N的取值一般在1 到10 之間,Top-1 的分類準確率是指,在預測結果得分中,排名第一的類別與實際標簽一致的準確率;Top-5 的分類準確率是指,預測結果前五名的類別中,包含與實際標簽一致的準確率。本文兩個階段的任務都是分類任務,均采用MacroF1指標和Top-N Acc指標。
在基準模型方面,本文使用了三種不同結構的CLIP 模型和兩種消融模型,包括CLIP-RN50、CLIPRN101、CLIP-ViT 模型、只訓練標簽預測階段的多任務分類模型以及本文提出的兩階段融合模型。其中,CLIP-RN50 使用ResNet-50 架構作為圖像特征編碼器,包含50 層卷積和全連接網絡;CLIP-RN101 ResNet-101 架構作為圖像特征編碼器,包含101 層卷積和全連接網絡;CLIP-ViT Vision Transformer 架構作為圖像編碼器,圖像輸入是將原始224×224像素圖片分塊展開成的序列。文本標簽預測模型是實體糾錯模型的前置模型,本文對比了兩個階段模型的輸出結果,以驗證實體糾錯模型帶來的效果差異。在標簽預測模型的實驗過程中,各個基線模型的參數設置都是一致的。批量大小設置為64,訓練持續200個epoch。使用自適應矩估計Adam 優化器,初始學習率為0.001,動量為0.9,每2 000 個樣本做一次學習率衰減,衰減系數為0.1。在實體糾錯模型的實驗過程中,批量大小設置為64,訓練持續40 個epoch。其中,兩個階段的模型的可學習參數通過均值為0、方差為0.02 的正態分布進行初始化。所有的模型超參數通過在驗證集上進行網格調參獲得,每10個epoch會保存一次在驗證數據集上具有最佳性能的模型,根據損失來進行替換每次保存的最優模型,然后用于測試分類任務中的性能。針對第三級標簽識別結果的優化,本文將圖片-文本對數據集的標簽結果和影視知識圖譜融合輸入到實體糾錯模型中進行細粒度標簽糾錯任務。實體糾錯模型是基于Transformer框架的,整個Transformer模型包含6層Encoder,每一層含有8 個注意力頭,其中每個節點都有300 維表示。在訓練時,本文隨機屏蔽了30%的節點。
在實驗過程方面,本文先將構建的圖片-文本對數據集輸入到多任務標簽預測模型中進行多級標簽識別。標簽預測模型是基于對比自監督CLIP 模型的,其中圖像編碼器使用的是ResNet-50 主干網絡,文本編碼器使用的是文本Transformer 主干網絡。特征融合階段使用的是一個基于注意力機制的Encoder模塊,多任務架構將分類損失函數和相似性損失函數進行權重相加。
3.3 實驗結果與分析
本文分別在類型、題材、實體三種不同粒度級別標簽上進行測試。其中,類型標簽包含三類,即電影、電視劇、綜藝;題材標簽分為八類,包含科幻、喜劇、戰爭、農村、武俠、愛情、音樂、歷史等;三級標簽是最細粒度的實體標簽,每一個影視劇屬于一類,總共有228 類。對于各層級標簽各種模型的分類性能比較結果如表2所示,從中可以發現三個方面的主要結論:首先,在小規模影視數據集上各種CLIP模型分類效果差異不大。基于同樣的輸入圖片大小進行預訓練,相比ResNet 系列模型的卷積層堆疊,視覺Transformer 模型將圖片按位置切分并拼接成序列。在本文數據集上,CLIP-RN50、CLIP-RN101、CLIP-ViT 3個不同架構在類型標簽Top-1 中三者精確度分別是78.3%、78.9%、78.8%,MacroF1 分別是76.8%、78.0%、77.8%;在題材標簽Top-1中三者精確度分別是62.6%、63.1%、62.8%,MacroF1 分別是50.7%、53.9%、52.0%;在最細粒度的實體標簽Top-1 中三者精確度分別是33.2%、33.4%、33.9%,MacroF1 分別是31.2%、31.4%、31.9%,顯然性能差異不顯著。其次,本文提出的多任務學習框架可以顯著提升分類性能。可以看到,將相似性任務加入到多任務訓練框架后,模型對于3個級別標簽的識別準確性上都有提升。其中在類型標簽上多任務框架的Top-1識別精確度從78.3%提升到81.2%,MacroF1從76.8%提升到79.7%;在題材標簽上Top-1 識別精確度從62.6%提升到64.7%,MacroF1 從50.7%提升到53.5%;新模型在第三級實體標簽識別性能上提升最明顯,Top-1 精確度從33.2%提升到38.7%,MacroF1 從31.2%提升到34.8%。本文所提出的新模型之所以能取得性能上的顯著提升,是相似性任務訓練模型學習到了樣本之間特征表達的差異,而傳統分類任務較少考慮樣本差異化特性。實驗結果也驗證了本文提出的多任務框架對于細粒度標簽識別的有效性。最后,本文提出的實體糾錯模型可以在標簽預測模型基礎上進一步提升對實體標簽的分類性能。實體標簽是最細粒度的內容標簽,這里的實體糾錯模型實際視作針對于困難樣本改進多任務框架標簽預測模型的一個優化算法。從表2中可以看出,引入知識圖譜中的演員節點和出演關系之后,第三級實體標簽識別的Top-1 精確度從38.7%提升到45.6%,而且Top-3精確度也從52.5%提升到了58.3%,實驗結果表明在影視圖文數據集中引入實體糾錯模型可以有效提升粒度較細的標簽的分類效果。
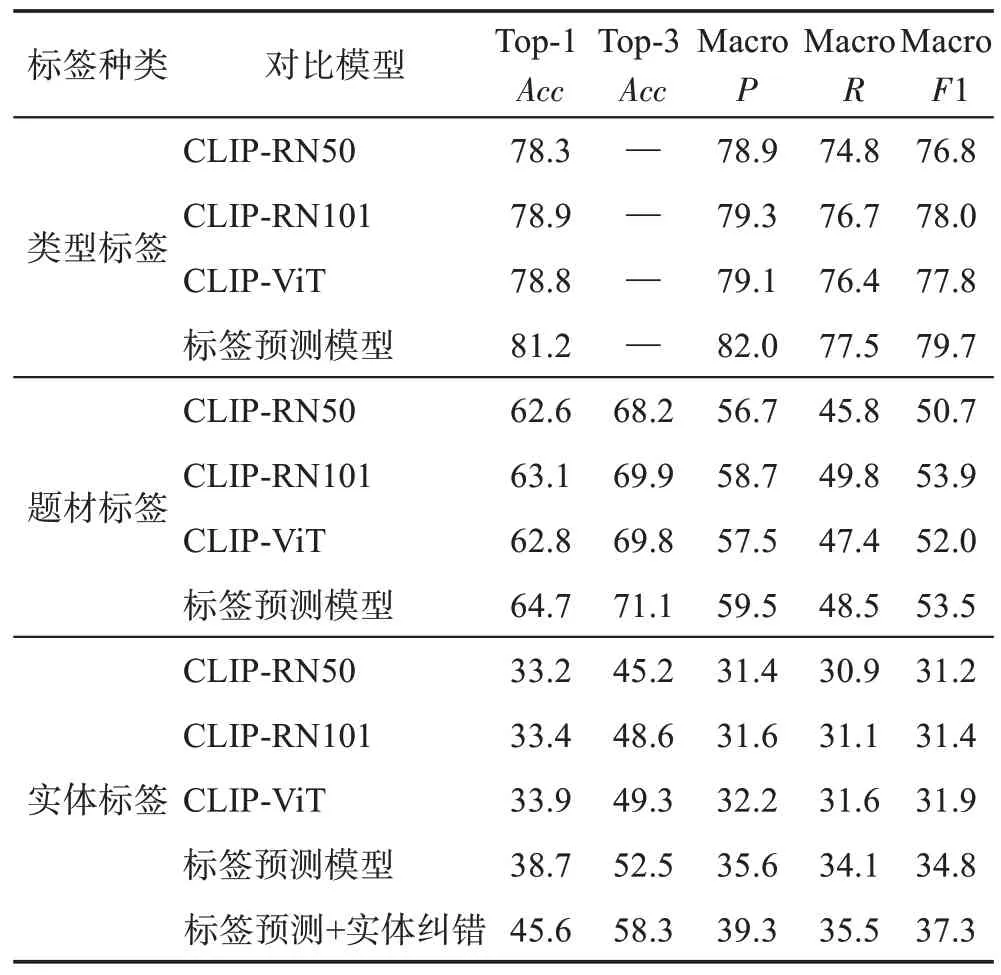
表2 在各類標簽上模型分類性能對比Table 2 Comparison of model classification performance on various types of labels 單位:%
3.4 參數影響分析
針對多任務框架中分類任務和相似性任務權重系數λ,本文執行了參數敏感性分析的多重對比實驗以確定其最優取值。λ的取值范圍是[0,1.0],λ越小時,多目標學習網絡模型更關注分類損失的優化;反之,λ越大時,模型更關注度量損失的優化。通過將λ從0 變化到1.0,可以探究分類任務和相似性任務對特征學習的作用。在實驗過程中,從模型中分別提取分類網絡和相似性網絡的倒數第二層特征,將分類特征和相似性網絡特征拼接起來,通過相應的平均特征方差進行歸一化后得到每個樣本的128 維特征。根據第三級實體標簽的預測結果,計算所有樣本輸出特征在特征空間下的類內距離和類間距離值。
基于參數λ的多重對比實驗結果,如圖7 所示。在λ=0時,相似性任務不起作用,此時只有分類任務生效,不同類別間樣本之間距離達到最大,可以較好區分不同的影視劇集;但是這時類內的距離也較大,表明同類樣本之間存在較大的差異,各個樣本的特征在特征空間分布較分散。隨著λ增加,相似性任務逐漸主導多任務網絡的訓練過程。從圖7 中可以看到,不同類別樣本之間距離稍有下降,但變動不大;類內的距離隨著訓練過程穩定地逐漸減小,說明相似性任務的損失函數優化使得同類別樣本之間逐漸減少差異。最終當λ=1.0 時,只剩下了相似性任務,不同類別樣本之間的距離和同類別的樣本之間的差異都很小。這時沒有分類任務優化的引領,無法形成多樣化的特征,類與類之間的差異低,在特征空間里各類難以區分,分類性能顯著下降。綜合來看,在λ=0.4時,模型在第三級實體標簽的分類精度最高。
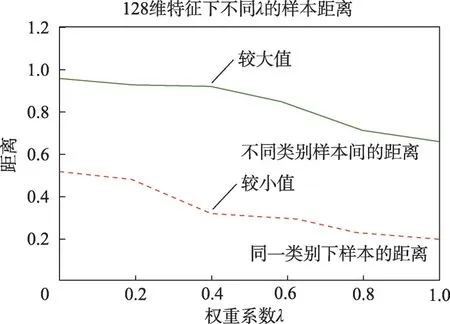
圖7 不同權重系數時類內和類間距離Fig.7 Intra-class and inter-class distances at different weighting factors
實驗結果表明,單獨的分類任務或者單獨的相似性任務都不是學習特征的最佳方案,有效的特征來自于兩者的適當結合。分類任務沒有考慮到樣本差異化的重要性,而相似性任務則為樣本之間的特征表達學習到了差異,這也說明了本文提出的多任務框架對于細粒度標簽的識別的有效性,通過同時使用兩個任務來學習樣本特征是有效的。
3.5 相似性任務驗證
本文進一步驗證多任務分類網絡中引入相似性任務的有效性。相似性任務也是一種監督學習,用在分類任務中研究的是如何通過基于距離度量(如歐式距離、余弦距離等)的損失函數學到更好的特征表示[26]。相似性任務對數據標注質量要求較高,分類訓練時將所有非標簽類別當作負樣本,在模型參數優化過程中,同一類樣本之間的距離需要比不同類樣本之間的距離更小。基于距離度量的損失函數在人臉識別、圖像檢索等領域被廣泛使用,代表方法除了Triplet Loss之外還有Sphereface[27]、Arcface[28]等。
通過對比相似性任務中使用不同損失函數約束模型的分類效果,本文驗證相似目標學習的有效性。在所有200 個epoch 的訓練過程中,每一個消融實驗都是保存最優的模型之后比較性能。其中基線是只使用了分類任務的交叉熵損失函數,相當于單任務框架;其他任務框架均在λ=0.4 下進行,實驗結果如表3所示。
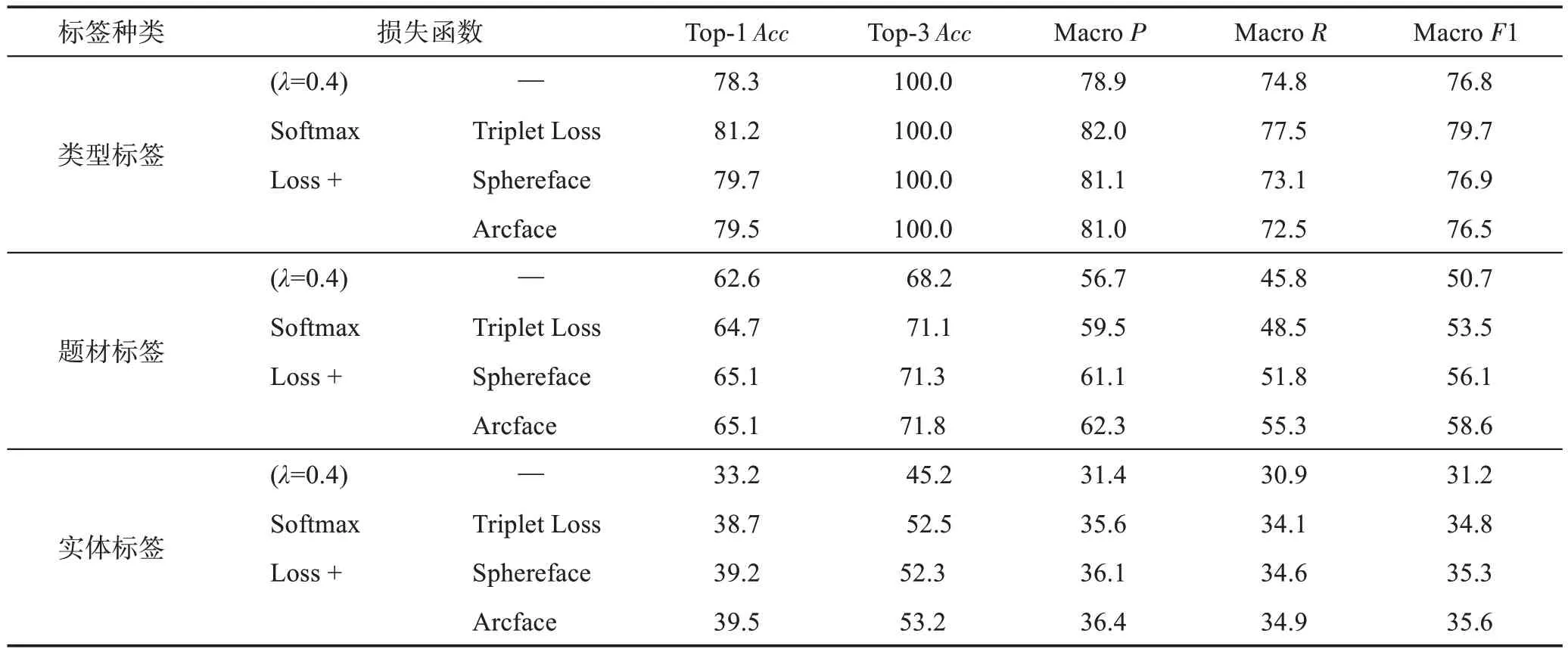
表3 在各類標簽上不同損失函數分類性能比較Table 3 Comparison of classification performance of different loss functions on various types of labels 單位:%
表3 呈現了相似性任務使用三種不同度量損失函數的各種層級標簽分類效果。從中可以看出,加入了Triplet Loss、Sphereface、Arcface 等相似性任務的度量損失函數作為優化方向的模型,分類準確率均優于基線。在類型標簽上Top-1 精確度分別提升了3.70%、1.79%和1.53%;在題材標簽上Top-1 精確度也分別提升了3.35%、3.99%和3.99%;關鍵是在第三級實體標簽上Top-1 精確度分別提升了16.57%、18.07%和18.98%,說明引入相似性任務的效益,也表明多任務學習網絡的魯棒性。更值得關注的是,添加相似性任務對于細粒度標簽的識別具有更優的提升效果。相似性損失函數的原理是對多分類交叉熵損失函數進行修改,通過增加一個差值(Margin)提高分類模型訓練的難度,使得所學特征更加緊密。在第一級類型標簽和第二級題材標簽中,以Triplet Loss為例,相似性任務的Top-1 精確度相比基線模型分別提升了3.70%和3.35%,相似性任務的MacroF1 值相比于基線模型分別提升了3.78%和5.52%;而三級標簽中Top-1 精確度提升了16.57%,MacroF1 提升了11.54%,提升幅度是最大的。實驗結果表明,對于識別力度越細的標簽類別,度量損失函數提升的效果越好。
4 結束語
融合知識圖譜的影視視頻標簽分類方法嘗試解決視頻標簽不同細粒度層級分類的問題,基于碎片化信息生成清晰、合理的層級標簽對于視頻運營網站十分關鍵,該類方法具有較強的現實應用價值。視頻標簽分類算法在經歷了較長時間的圖像時序和音頻的研究之后,當前的研究越來越多地將文本作為一種監督信息融合到分類模型中。基于影視類短視頻數據,本文提出了一個融合知識圖譜的影視視頻標簽分類模型。首先,整合半結構化數據建立影視知識圖譜,為細粒度的標簽識別提供數據支撐;其次,在大規模預訓練模型上訓練多個分類任務為數據集生成標簽集合;最后,利用影視知識圖譜中節點和節點關系,將分類結果修正為更合理的標簽。
本文采集豆瓣的半結構化數據構建了影視知識圖譜并對影視視頻標簽分類模型進行了實證研究。視頻標簽分類的實驗結果表明:首先,基于多任務網絡結構,在訓練分類任務時加入相似性損失函數對模型進行共同約束優化了特征表達,在類型、題材、實體標簽的Top-1 分類準確率分別提升了3.70%、3.35%和16.57%;其次,本文針對前置模型的困難樣本提出的全局-局部注意力機制模型,在引入了知識圖譜信息之后,實體標簽的Top-1 分類準確率從38.7%提升到了45.6%;最后,當計算多任務網絡的損失值時,權重系數λ設置為0.4,模型的層級標簽識別效果最優。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
