細粒度云數(shù)據(jù)自適應(yīng)去重方法研究
2024-01-14 09:54:32王小紅
電腦與電信 2023年9期
王小紅
(宜春職業(yè)技術(shù)學(xué)院,江西 宜春 336000)
1 引言
數(shù)據(jù)粒度能夠有效地描述數(shù)據(jù)的詳細程度,粒度越小,數(shù)據(jù)包含的信息越具體,對于獲取數(shù)據(jù)本質(zhì)與規(guī)律越有幫助[1]。細粒度云數(shù)據(jù)指的是各個方面信息都非常詳細具體的云數(shù)據(jù),具有多層次化與高效化的特點。與傳統(tǒng)意義上的云數(shù)據(jù)存在一定差異,細粒度云數(shù)據(jù)獲取的難度較高,需要經(jīng)過大量的訓(xùn)練與學(xué)習(xí)才能獲得。隨著數(shù)據(jù)量的快速增長,細粒度云數(shù)據(jù)中不可避免會存在各類重復(fù)數(shù)據(jù)。相似重復(fù)的數(shù)據(jù)一方面消耗了大量不必要的存儲空間與人力開支,另一方面增大了云數(shù)據(jù)的管理難度,降低了云數(shù)據(jù)管理的效率與質(zhì)量[2]。
基于此,科學(xué)合理的細粒度云數(shù)據(jù)去重方法至關(guān)重要。當前,傳統(tǒng)的云數(shù)據(jù)去重方法逐步成熟完善,在實際應(yīng)用過程中,重復(fù)數(shù)據(jù)去除效果較好。文獻[3]采用哈希算法聚類、監(jiān)督判別投影降維、代數(shù)簽名預(yù)估數(shù)據(jù)和最小哈希樹生成校驗值等技術(shù)路徑,實現(xiàn)對網(wǎng)絡(luò)單信道數(shù)據(jù)的高效去重。文獻[4]采用基于廣義去重的跨用戶安全去重框架,通過將原始數(shù)據(jù)分解為基和偏移量,對基進行跨用戶去重,并在云端對偏移量進行去重。
然而,傳統(tǒng)的去重方法在細粒度云數(shù)據(jù)去重操作中仍然存在不足,主要體現(xiàn)在去重覆蓋范圍有限,不能從多個維度對細粒度云數(shù)據(jù)中重復(fù)的數(shù)據(jù)作出處理,去重質(zhì)量較低,實時性較差。針對上述問題,本文在傳統(tǒng)數(shù)據(jù)去重方法的基礎(chǔ)上,開展了細粒度云數(shù)據(jù)自適應(yīng)去重方法的深入研究。
2 細粒度云數(shù)據(jù)自適應(yīng)去重方法設(shè)計
2.1 檢測相似重復(fù)細粒度云數(shù)據(jù)
本文設(shè)計的細粒度云數(shù)據(jù)自適應(yīng)去重方法中,首先,需要采用相似重復(fù)數(shù)據(jù)檢測方法,對細粒度云數(shù)據(jù)作出全方位的檢測,判斷云數(shù)據(jù)集中是否存在相似重復(fù)數(shù)據(jù),為后續(xù)的數(shù)據(jù)自適應(yīng)去重奠定基礎(chǔ)。
通常情況下,重復(fù)的細粒度云數(shù)據(jù)包括兩種類型,分別為細粒度云數(shù)據(jù)完全重復(fù)與細粒度云數(shù)據(jù)相似重復(fù)[7]。本文對兩種重復(fù)類型的特征作出了分析:
(1)細粒度云數(shù)據(jù)完全重復(fù),指的是云數(shù)據(jù)標記相同,標記的屬性及元素內(nèi)容也相同的記錄。
(2)細粒度云數(shù)據(jù)相似重復(fù)。由于細粒度云數(shù)據(jù)的靈活性較強,同一實體會有不同的表現(xiàn)形式,受到云數(shù)據(jù)格式差異、拼寫差異、完整性差異等因素影響,數(shù)據(jù)庫無法準確地識別出數(shù)據(jù)部分屬性及元素內(nèi)容,即為細粒度云數(shù)據(jù)相似重復(fù)[8]。
綜合考慮兩種類型的重復(fù)細粒度云數(shù)據(jù)特征后,本文采用基于邊界距離的云數(shù)據(jù)字段匹配檢測算法。該算法是基于一系列字符串編輯操作而實現(xiàn)的,通過計算細粒度云數(shù)據(jù)字符串之間的邊界距離,來判斷字符串之間的相似重復(fù)性。
邊界距離是一種衡量字符串相似性的度量方法,它考慮了字符串中字符之間的位置關(guān)系。通過比較字符串的邊界距離,我們可以判斷字符串之間是否存在相似的重復(fù)數(shù)據(jù)。
通過采用基于邊界距離的云數(shù)據(jù)字段匹配檢測算法,本文能夠有效地發(fā)現(xiàn)并識別細粒度云數(shù)據(jù)中的相似重復(fù)數(shù)據(jù)。這種算法的應(yīng)用可以提高數(shù)據(jù)處理的準確性和效率,并為后續(xù)的數(shù)據(jù)去重和優(yōu)化提供基礎(chǔ)[9]。本文設(shè)計的相似重復(fù)細粒度云數(shù)據(jù)檢測流程,如圖1所示。

圖1 相似重復(fù)細粒度云數(shù)據(jù)檢測流程
如圖1所示,首先,從海量數(shù)據(jù)源中提取云數(shù)據(jù),并根據(jù)云數(shù)據(jù)的結(jié)構(gòu)特征,設(shè)置關(guān)鍵字排序。設(shè)定dist(a,b)表示細粒度云數(shù)據(jù)字符串A與字符串B之間的邊界距離,其中,a、b均表示字符串A與字符串B的長度。依據(jù)動態(tài)規(guī)范思想,獲取細粒度云數(shù)據(jù)動態(tài)規(guī)劃的狀態(tài)轉(zhuǎn)移方程式,如下:
通過細粒度云數(shù)據(jù)動態(tài)規(guī)劃的狀態(tài)轉(zhuǎn)移方程式,獲取云數(shù)據(jù)字符串A與字符串B之間的邊界距離,此時,dist(a,b)即為云數(shù)據(jù)字符串A與字符串B的重復(fù)相似度。當云數(shù)據(jù)字符串重復(fù)相似度超過一定的值,則認為這些細粒度云數(shù)據(jù)存在相似重復(fù)。根據(jù)相似度,判定細粒度云數(shù)據(jù)是否存在相似重復(fù),輸出檢測結(jié)果。
2.2 提取細粒度云數(shù)據(jù)去重特征
在上述相似重復(fù)細粒度云數(shù)據(jù)檢測完畢后,可以得知云數(shù)據(jù)是否存在相似重復(fù),并根據(jù)字符串相似度,判定云數(shù)據(jù)重復(fù)類型。接下來,壓縮存在相似重復(fù)性質(zhì)的細粒度云數(shù)據(jù),提取云數(shù)據(jù)去重特征。
首先,設(shè)定Ya表示引用細粒度云數(shù)據(jù)塊;Yb表示相似細粒度云數(shù)據(jù)塊,利用差量壓縮方法,對上述輸出的相似重復(fù)數(shù)據(jù)進行壓縮,壓縮過程表達式為:
其中,?表示差量編碼;△a,b表示細粒度云數(shù)據(jù)差量數(shù)據(jù)。通過該表達式,獲取細粒度云數(shù)據(jù)塊與相似細粒度云數(shù)據(jù)塊之間的差量數(shù)據(jù)。相似重復(fù)云數(shù)據(jù)壓縮完畢后,提取云數(shù)據(jù)的超級指紋,即去重超級特征值,能夠表示多個細粒度云數(shù)據(jù)的多個去重特征。基于云數(shù)據(jù)特征指紋,進行相似重復(fù)細粒度云數(shù)據(jù)的數(shù)據(jù)融合,融合后的特征即能夠代表一類相似重復(fù)云數(shù)據(jù)的去重特征,進而實現(xiàn)細粒度云數(shù)據(jù)去重特征提取的目標。
2.3 刪除重復(fù)數(shù)據(jù)
完成細粒度云數(shù)據(jù)去重特征提取后,能夠獲取各類相似重復(fù)云數(shù)據(jù)的去重特征。在此基礎(chǔ)上,采用重復(fù)數(shù)據(jù)刪除技術(shù),刪除細粒度云數(shù)據(jù)中的相似重復(fù)數(shù)據(jù)。本文采用的是重復(fù)數(shù)據(jù)刪除技術(shù)中的數(shù)據(jù)分塊去重技術(shù),其技術(shù)原理示意圖,如圖2所示。
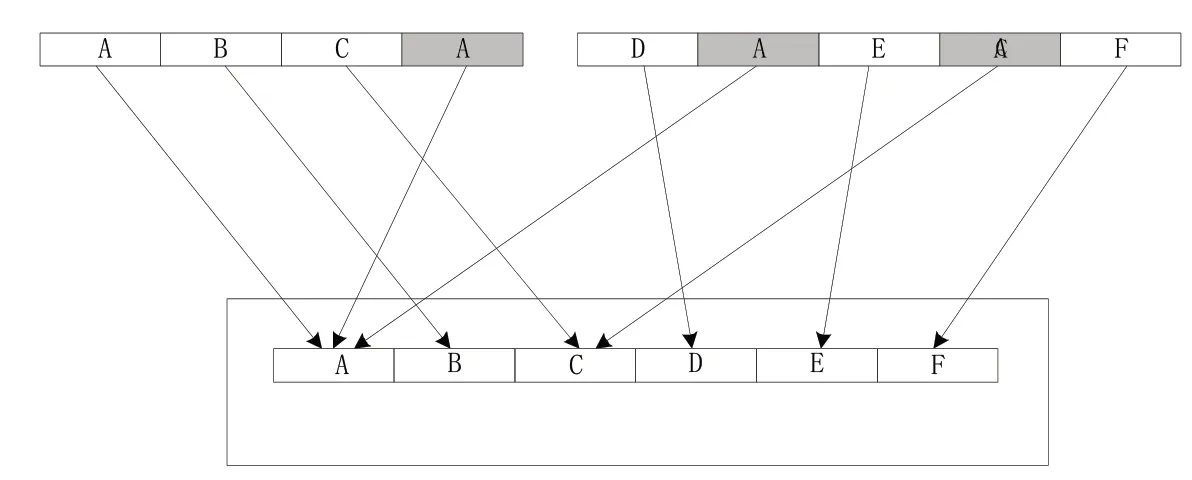
圖2 重復(fù)數(shù)據(jù)分塊去重技術(shù)原理示意圖
如圖2所示,本文采用的技術(shù)能夠多維度地將相同數(shù)據(jù)塊指向唯一的實例,避免數(shù)據(jù)集內(nèi)存儲相同數(shù)據(jù),進而節(jié)省存儲空間。
本文采用了一種基于細粒度云數(shù)據(jù)分塊去重的新方法,旨在解決云存儲系統(tǒng)中的數(shù)據(jù)冗余和存儲效率問題。傳統(tǒng)的去重方法通常是以文件為單位進行去重,而這種細粒度的分塊去重方法可以更精細地處理數(shù)據(jù),提高去重的準確性和效率。
具體而言,本文首先對細粒度云數(shù)據(jù)備份流中的所有文件進行分塊處理。通過將大文件劃分為更小的數(shù)據(jù)塊,可以實現(xiàn)對數(shù)據(jù)的精細管理和處理。接下來,采用哈希算法計算每個數(shù)據(jù)塊的哈希指紋,并將其與之前提取到的超級指紋共同設(shè)置為該數(shù)據(jù)塊的標識。哈希指紋是數(shù)據(jù)塊的唯一標識,可以用于后續(xù)的去重比對。
當云存儲系統(tǒng)接收到每個數(shù)據(jù)塊時,會將該數(shù)據(jù)塊的指紋與系統(tǒng)中已有的數(shù)據(jù)塊指紋進行比對。如果數(shù)據(jù)塊指紋已經(jīng)存在于系統(tǒng)中,說明接收到的數(shù)據(jù)塊是冗余的,即已經(jīng)存在相同的數(shù)據(jù)塊。為了避免存儲重復(fù)數(shù)據(jù),云存儲系統(tǒng)需要在網(wǎng)絡(luò)的兩個端點,即發(fā)送端和接收端,消除冗余數(shù)據(jù)包,并對該數(shù)據(jù)包進行編碼。通過編碼技術(shù),可以將冗余數(shù)據(jù)包轉(zhuǎn)換為校驗信息,減少上傳到服務(wù)器端的數(shù)據(jù)傳輸量,提高云數(shù)據(jù)去重的效率和速度。
另一方面,如果數(shù)據(jù)塊指紋在云存儲系統(tǒng)中不存在,則存儲該數(shù)據(jù)塊,并及時更新系統(tǒng)的指紋庫。這樣就能保證云存儲系統(tǒng)中只保存唯一的數(shù)據(jù)塊,避免了冗余存儲,節(jié)省了存儲空間。
綜上所述,本文所采用的細粒度云數(shù)據(jù)分塊去重方法能夠有效地解決云存儲系統(tǒng)中的數(shù)據(jù)冗余和存儲效率問題。通過分塊處理、哈希指紋比對、冗余數(shù)據(jù)包消除和數(shù)據(jù)編碼等關(guān)鍵步驟,可以實現(xiàn)高效的云數(shù)據(jù)去重,提高存儲效率和數(shù)據(jù)處理速度。這種方法在大規(guī)模的云存儲系統(tǒng)中具有重要的應(yīng)用價值。
3 實驗分析
3.1 實驗準備
上述內(nèi)容,便是本文提出的細粒度云數(shù)據(jù)自適應(yīng)去重方法的全部設(shè)計流程。在提出的數(shù)據(jù)去重方法投入實際使用前,進行了如下文所示的實驗分析,檢驗方法的可行性與去重效果,確認整個去重過程中無異常問題后,方可投入使用。
首先,對細粒度云數(shù)據(jù)自適應(yīng)去重實驗的環(huán)境配置進行設(shè)置,為實驗的順利開展奠定良好基礎(chǔ)。實驗環(huán)境配置如表1所示。

表1 細粒度云數(shù)據(jù)自適應(yīng)去重實驗環(huán)境配置
按照表1的配置,設(shè)置好實驗所需環(huán)境。其次,為了提高此次去重實驗測試的準確性,選用重復(fù)度較大的細粒度云數(shù)據(jù)集,如表2所示。

表2 細粒度云數(shù)據(jù)集說明
表2 中的Web 數(shù)據(jù)集中包含了100,000 個網(wǎng)頁,其中包括不同主題的新聞、博客、論壇等頁面。每個網(wǎng)頁的URL、標題和正文內(nèi)容都被提取存儲在數(shù)據(jù)集中。此外,還記錄了網(wǎng)頁之間的鏈接關(guān)系,如頁面A鏈接到頁面B等;同時,還包含了網(wǎng)頁的HTML 結(jié)構(gòu)和標簽信息,用于進一步的分析和處理。Linux 源碼數(shù)據(jù)集中包含了Linux 操作系統(tǒng)的源代碼文件。每個源代碼文件包含了函數(shù)定義、變量定義以及相關(guān)的注釋。源代碼組織成目錄結(jié)構(gòu),每個目錄代表不同的子系統(tǒng)或功能模塊;此外,還包含了Makefile、README文件等輔助信息。
實驗所需的細粒度云數(shù)據(jù)集準備完畢后,按照上述本文提出的云數(shù)據(jù)自適應(yīng)去重方法步驟,對云數(shù)據(jù)集進行去重處理,獲取細粒度云數(shù)據(jù)去重結(jié)果,進而檢驗方法的有效性與去重效果。
3.2 結(jié)果分析
在此次實驗中,本文特意引入了文獻[2]提出的基于最小哈希的數(shù)據(jù)去重方法、文獻[3]提出的基于Reed-Solomon 數(shù)據(jù)去重方法,分別作為對照組1與對照組2,將上述本文提出的細粒度云數(shù)據(jù)自適應(yīng)去重方法設(shè)置為實驗組,分別對比三種方法應(yīng)用后云數(shù)據(jù)的去重結(jié)果。采用對比分析的實驗方法,能夠更加直觀地得出此次云數(shù)據(jù)去重實驗的結(jié)果,避免結(jié)果存在偶然性,增強說服力。本次實驗選取細粒度云數(shù)據(jù)的空間壓縮率作為此次實驗的性能評價指標,云數(shù)據(jù)空間壓縮率越高,說明細粒度云數(shù)據(jù)中重復(fù)數(shù)據(jù)自適應(yīng)去重效果越好,反之則說明去重效果越差,不能有效消除數(shù)據(jù)集中的相似重復(fù)數(shù)據(jù)。
分別在云數(shù)據(jù)集1與云數(shù)據(jù)集2中,選取3個不同大小的細粒度云數(shù)據(jù)文件,將其編號為SJJ-101、SJJ-102、SJJ-103、SJJ-201、SJJ-202、SJJ-203。利用上述三種數(shù)據(jù)去重方法,對6個細粒度云數(shù)據(jù)文件進行去重處理,通過MATLAB 軟件的模擬作用與SPSS 軟件的數(shù)據(jù)統(tǒng)計作用,模擬云數(shù)據(jù)去重全過程,并統(tǒng)計三種方法的空間壓縮率,繪制成如圖3所示的性能評價指標對比圖。

圖3 實驗性能評價指標對比結(jié)果
通過圖3的性能評價指標對比結(jié)果可以得知,三種云數(shù)據(jù)去重方法應(yīng)用后,性能指標結(jié)果存在較大的差異。其中,本文提出的云數(shù)據(jù)自適應(yīng)去重方法應(yīng)用后,6 個不同大小的細粒度云數(shù)據(jù)文件的空間壓縮率始終高于對照組1與對照組2 提出的方法,空間壓縮率均達到了98%以上。由此對比結(jié)果不難看出,本文提出的細粒度云數(shù)據(jù)自適應(yīng)去重方法具有較高的可行性,能夠最大限度地去除細粒度云數(shù)據(jù)中的重復(fù)數(shù)據(jù),去重準確性優(yōu)勢顯著,可以大規(guī)模投入使用。
某個算法在相同數(shù)據(jù)集規(guī)模下處理時間較短,即呈現(xiàn)較低的計算開銷,相對于其他算法來說更高效,具有更高的去重效率。根據(jù)給定的實驗組別編號對不同組別的實驗結(jié)果進行了測量,并將結(jié)果匯總?cè)绫?所示。

表3 去重耗時對比/ms
通過對表3中的數(shù)據(jù)進行分析,可以得到以下結(jié)論:實驗組的平均去重耗時為254.8ms,對照組1 的平均去重耗時為485ms,對照組2 的平均去重耗時為492.5ms。由此可見,實驗組采用的細粒度云數(shù)據(jù)分塊去重方法相較于對照組1和對照組2的文件級別去重方法,在平均去重耗時上具有更好的性能表現(xiàn),進一步說明實驗組的計算開銷較小,可以有效提高去重效率。因此,根據(jù)實驗結(jié)果的平均值分析,得出結(jié)論:實驗組采用的細粒度云數(shù)據(jù)分塊去重方法相較于傳統(tǒng)的文件級別去重方法,在平均去重耗時上具有更好的性能表現(xiàn)。
存儲開銷是一個關(guān)鍵指標,可以影響系統(tǒng)的性能和擴展性。較低的存儲開銷意味著在處理數(shù)據(jù)時,所需的存儲空間較小,從而減少了存儲引擎的負載和磁盤IO操作,提高了系統(tǒng)的響應(yīng)速度和吞吐量。此外,較低的存儲開銷也意味著系統(tǒng)具有更大的擴展能力,能夠適應(yīng)更大規(guī)模的數(shù)據(jù)處理需求。為了進一步驗證本文提出的細粒度云數(shù)據(jù)自適應(yīng)去重方法的應(yīng)用性能,對比同一細粒度云數(shù)據(jù)文件下不同算法所需的存儲空間。如圖4所示。

圖4 存儲空間對比結(jié)果
通過圖4的存儲空間對比結(jié)果可知,三種云數(shù)據(jù)去重方法應(yīng)用后,對云數(shù)據(jù)進行去重處理時所占用的存儲空間有所不同。其中,應(yīng)用本文提出的云數(shù)據(jù)自適應(yīng)去重方法后,對于不同云數(shù)據(jù)文件進行去重處理時,所占用的存儲空間低于4GB;對照組1和對照組2所占用的存儲空間均低于8GB,較實驗組占用的存儲空間較大,表明本文提出的細粒度云數(shù)據(jù)自適應(yīng)去重方法具有較低的儲存開銷,相對于其他算法來說更高效。
4 結(jié)語
在當前云數(shù)據(jù)存儲能力指數(shù)級不斷提升的背景下,用戶對云數(shù)據(jù)私密性、安全性的重視程度大幅度提升。由于網(wǎng)絡(luò)信息安全系統(tǒng)長期處于工作運行狀態(tài),會實時產(chǎn)生大量的云數(shù)據(jù),其中存在較多的重復(fù)細粒度云數(shù)據(jù),占用存儲空間的同時,降低了云數(shù)據(jù)傳輸、加密、解密的效率。為了改善這一問題,本文提出了細粒度云數(shù)據(jù)自適應(yīng)去重方法的研究。通過本文的研究,有效地降低了細粒度云數(shù)據(jù)的重復(fù)率,且去重正確率較高,全方位滿足了網(wǎng)絡(luò)信息安全系統(tǒng)細粒度云數(shù)據(jù)去重實時性與準確性的要求,具有良好的應(yīng)用前景。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
