基于集成學習的入侵檢測模型
2024-01-15 10:18:18李鉑初閻紅燦
華北理工大學學報(自然科學版) 2024年1期
李鉑初,閻紅燦,2
(1. 華北理工大學 理學院,河北 唐山 063210;2. 河北省數據科學與應用重點實驗室,河北 唐山 063210)
引言
隨著互聯網上的信息數據日益增加,病毒、滲透、網絡入侵等網絡安全問題也愈發頻繁。入侵檢測作為保證網絡安全的重要手段,可以檢測出用戶的異常行為,攔截惡意用戶的攻擊或入侵行為并檢測網絡中的惡意流量,是網絡信息安全的重要技術之一。而在目前網絡攻擊類型日趨多樣、攻擊方式逐漸多元化的趨勢下,使用人工智能技術進行異常行為檢測逐漸成為主流。
針對異常行為檢測模型許多專家和學者進行了諸多研究,而在算法改進方面,機器學習算法被廣泛應用:周杰英等[1]使用梯度提升決策樹進行特征選擇,使用隨機森林模型進行特征變換。文獻[2]通過高斯混合模型將數據聚類,為每個簇訓練不同的隨機森林分類器。文獻[3]使用CART(Classification And Regression Trees)決策樹進行特征選擇,并使用帶有網格追蹤法確定的超參數CART決策樹進行訓練。文獻[4]使用極限隨機樹進行遞歸特征消除,并使用LightGBM(Light Gradient Boosting Machine)模型進行分類訓練。
深度學習方法在入侵檢測中也被廣泛研究文獻[5-6]結合卷積神經網絡與長短期記憶網絡構建入侵檢測模型。文獻[7]將注意力機制與LSTM網絡結合。文獻[8]融合卷積神經網絡、Bi-GRU和注意力層,并進行數據擴增測試。文獻[9-10]將生成對抗網絡GAN(Generative Adversarial Network)[11]思想應用于異常行為檢測模型,有效提高了檢測精度。
除算法外,對于高維度數據的特征選擇也是學者的研究方向之一。如文獻[12]使用Kmeans聚類算法生成具有典型數據特征的數據集。文獻[13]通過ReliefF、XGBoost和Pearson相關系數計算特征權重,以此刪除權重較低的特征。文獻[14]運用基于特征值分布的評分系統DSM(distribution-based scoring mechanism)進行特征提取。
不平衡數據集的訓練問題也有學者進行了探究,Zhang等人[15]使用SMOTE算法(Synthetic Minority Over-sampling TEchnique)對少數類過采樣,并使用高斯混合模型聚類對多數類數據進行欠采樣得到平衡的數據集。文獻[16]將多分類檢測問題轉化為多個二分類問題,在每個二分類問題中選擇RBBoost[17],RUSBoost[18],SMOTEBoost[19]等不同的采樣方法。
針對UNSW-NB15數據集的特點,對UNSW-NB15數據集進行去除冗余數據、選擇維度、采樣等處理,提出了一種聯合深度學習與機器學習的算法,首先通過并行卷積神經網絡串聯LSTM網絡訓練出一個模型;之后將其結果與特征選擇后的特征拼接;對數據進行采樣后放入XGBoost模型進行訓練;本模型運用了boosting集成學習的思想,充分結合了深度學習與XGBoost算法的優勢,在不同規模、類別數量的數據集上都有良好表現。
1 相關工作
1.1 卷積神經網絡
卷積神經網絡包括卷積層、池化層、全連接層三個主要部分。卷積層通過卷積核實現從輸入數據中提取特征,卷積核的參數通過反向傳播進行更新,在訓練期間卷積核的權值保持不變。池化層用于降低特征圖的維度,減少計算量并增強對輸入圖像變化的魯棒性,減少過擬合。全連接層在神經網絡分類模型中用于將輸入向量轉化為最終輸出完成分類。
1.2 Bi-LSTM
(1)
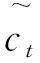
1.3 XGBoost算法
XGBoost[20]模型是通過Boosting方式構建的一種提升樹模型,是由多個弱分類器形成的一個強分類器,其利用上一顆樹預測的殘差值生成一顆新樹以此提升模型的總體性能。XGBoost算法是梯度提升決策樹(Gradient Boosting Decison Tree)即GBDT算法的改進算法,與GBDT相比,XGBoost對損失函數進行二階泰勒展開,并在使用CART作為基分類器時加入正則化項防止過擬合,同時XGBoost算法支持使用多種類型的基分類器。
XGBoost的目標函數如公式(2)所示:
(2)
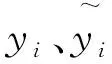
(3)
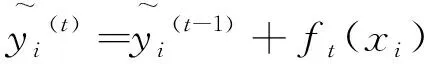
1.4 特征工程
在對數據建立模型進行分析前,首先需要對數據進行特征工程使其標準化、易于建模。特征工程包括數據降維、數據采樣等方法。數據降維可以去除冗余變量,提高模型訓練速度,主要分為特征選擇和特征提取兩類。特征選擇是提取原數據集的子特征,主要方法有遞歸特征消除、通過樹結構選擇重要特征等。特征提取則是將原始數據集變換為一個維度更低的新特征子集,主要有PCA(Principal Component Analysis)、LDA(Linear Discriminant Analysis)等方法。采樣方法分為過采樣、欠采樣以及組合采樣三大類。過采樣是對少數類樣本進行重復抽取或生成類似樣本,方法有簡單隨機過采樣、Synthetic Minority Oversampling Technique(SMOTE)、Adaptive Synthetic (ADASYN)[21]等等。欠采樣是將多數類樣本剔除,主要方法分為從多數類方法中選擇數據的簡單隨機欠采樣、NearMiss[22]、ClusterCentroids以及清洗數據的TomekLinks、EditedNearestNeighbours等等。組合采樣是將SMOTE與清洗數據的方法結合,去除SMOTE算法生成的與多數類樣本重疊的數據;例如SMOTEENN與SMOTETomek[23]算法。
2 數據預處理與模型搭建
2.1 數據集介紹
UNSW-NB15數據集[24]是一個入侵檢測領域的數據集,該數據集分為訓練集與測試集,其中訓練集包含175 341條數據,測試集包含82 332條數據。UNSW-NB15數據集中共有45個特征,包含'Generic'、'Exploits'、'Fuzzers'、'DoS'、'Reconnaissance'、'Analysis'、'Backdoor'、'Shellcode'、'Worms'9個攻擊類別以及正常樣本'Normal'類,可以進行"正常"與"攻擊"的二分類任務和十分類任務。
2.2 數據集預處理
原UNSW-NB15訓練集與測試集處理流程如圖1所示。由于原數據集中存在數據分布不均衡[25]的情況,首先將其訓練集與測試集合并,預處理后按照類別數量的比例重新劃分,使得訓練集與測試集中各類樣本比例相同。
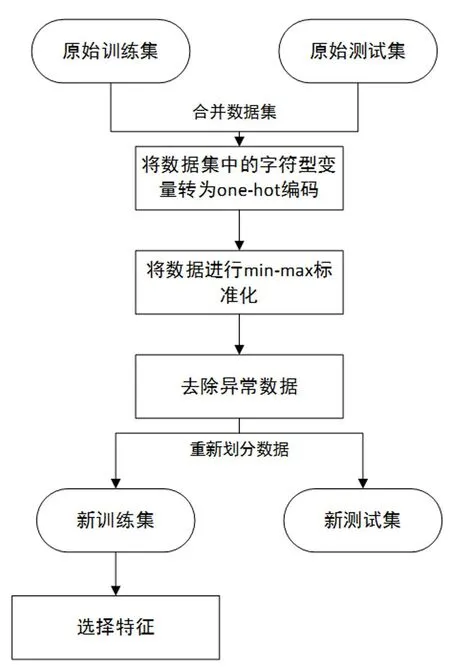
圖1 數據處理流程
(1)獨熱編碼
在UNSW-NB15數據集中存在proto,service,state3個字符型屬性,需要先將其轉為數字型數據才能參與計算,因此將這3列轉換為One-Hot(獨熱)編碼形式,轉變后的數據共有196維(刪除id、二分類標簽與多分類標簽三維)。
(2)數據標準化
由于UNSW-NB15數據集中各個特征的數值方差較大,為避免模型受到不同規模特征的影響、提高模型收斂速度,將所有數據進行標準化使其映射到[0,1]之間。本文選用最大-最小標準化法,計算公式如下:
(4)
其中X是樣本的值,Xmax和Xmin是該特征在所有樣本上的最大值和最小值,X'則是歸一化后樣本的值。
(3)去除冗余數據
在UNSW-NB15數據集中存在部分重復數據,且存在特征相同、類別標簽不同的數據;為提升模型訓練效果、去除共計40 400個特征相同而所屬類別不同的噪聲數據。表1中展示了去除噪聲數據后的數據集。

表1 去除冗余數據后的數據分布
(4) 數據降維
數據集在進行獨熱編碼后維數較高,因此采用數據降維。選擇隨機森林、遞歸特征消除等特征選擇方法進行數據降維。為保證數據降維不提前學習到測試集數據特征,本文進行數據降維時只使用訓練集數據。
(5) 采樣方法
在UNSW-NB15數據集中,同時存在超過萬條的類別以及不足一千條的類別,本文對上(過)采樣[26]、下(欠)采樣[27]與混合采樣幾種方法進行對比。
2.2 行為檢測模型架構
本文構建的入侵檢測模型分為2個部分,如圖2所示,分別是基于深度學習的并行卷積神經網絡連接LSTM模型與XGBoost模型。模型訓練流程分為3個步驟:首先通過訓練集訓練神經網絡模型,將訓練完成的模型在測試集上進行預測,得到模型對各個分類的概率(類別數*數據個數)。之后構建XGBoost模型輸入數據:采用K折交叉驗證,將訓練集分為K份,由每K-1份訓練生成一個神經網絡模型,得到最后一份數據對各個分類的預測概率;將K個模型預測得到的結果拼接成訓練集結果;之后將原數據與訓練集和測試集的預測概率拼接成XGBoost模型的訓練集與測試集。最后將拼接成的訓練集放入XGBoost模型中進行訓練,通過測試集得到預測結果。
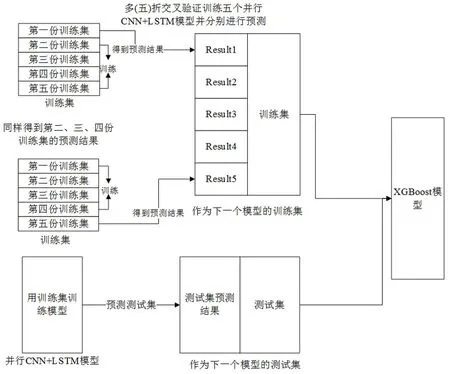
圖2 CNN-LSTM+XGBoost模型
2.2.1 并行CNN+LSTM模型
檢測模型的第一部分使用并行卷積神經網絡連接長短期記憶網絡LSTM,模型結構與參數如圖3所示。具體過程為:首先對數據進行轉化,變為可供卷積神經網絡輸入的三維數據流;輸入層獲取數據流后,通過并行卷積神經網絡進行特征提取,提取到數據不同深度的深層特征;再將不同深度的深層特征拼接傳入2層Bi-LSTM網絡獲取輸入的全局特征,最后由全連接層進行分類預測。
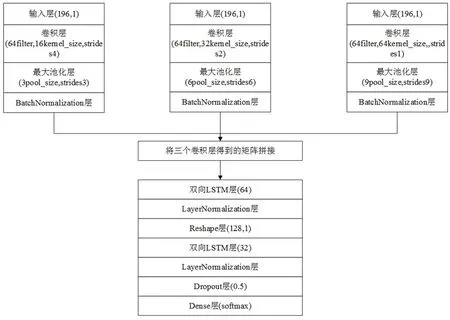
圖3 CNN+LSTM神經網絡模型結構
Stacking集成方法第一層的作用是生成元特征作為第二層的輸入,使用第一層可以減少過擬合、提高分類精確度。第一層可以采用一個或多個相同或不同的基分類器,該研究第一層采用的神經網絡結構具有較好的分類能力,對不同維度的特征進行訓練都有較好效果。
2.2.2 XGBoost模型
檢測模型的第二部分是XGBoost算法,經過CNN+LSTM神經網絡模型獲得預測概率后,將訓練集與測試集分別與得到的預測概率特征進行拼接,將得到的訓練集放入XGBoost模型進行訓練。數據集特征較多的情況下可以進行特征選擇來減少特征維度。流程圖如圖4所示。
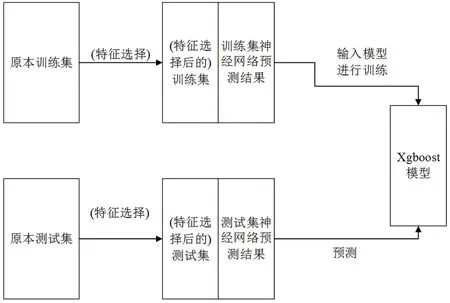
圖4 XGBoost模型訓練流程
XGBoost算法的參數如表2所示。

表2 XGBoost算法參數值
3 實驗結果與討論
3.1 實驗環境
本文實驗設備為Intel Core i7-10875H CPU,16GB內存以及NVIDIA的 GeForce RTX2060顯卡。實驗環境采用python3.8編程語言,采用Tensorflow2.4.1、scikit-learn 0.24.1構建模型。
3.2 評估指標
實驗采用準確率(accuracy)指標評估模型整體效果,其公式如下:
(5)
由于數據中各類樣本數量不均衡,因此全局準確率主要受數量多的數據影響,準確率的高低無法有效反應模型對于少數類樣本的分類效果,召回率(recall)、精準率(precision)、F1-score(f1-score)指標可以有效評價模型對于不同類別數據的分類效果。對于每一類樣本的recall、precision、f1-score值,其公式如下:
(6)
(7)
(8)
在多分類任務中,TP(true positives)是將本類樣本成功預測為本類的數量,TN(true negatives)是將其它類樣本預測為其他類的數量,FN(false negatives)是將本類樣本預測為其它類的數量,FP(false positives)是將其他類樣本預測為本類的數量。
3.3 模型與基準模型對比
(1) 準確率對比:
將本文提出的CNN+LSTM-In-XGBoost模型與Adaboost算法、KNN(K-Nearest Neighbor)算法、GBDT(Gradient Boosting Decision Tree)算法、隨機森林算法等常用機器學習、神經網絡基準模型進行對比分析,如圖5所示,該模型總準確率為91.31,高于其他常用算法。
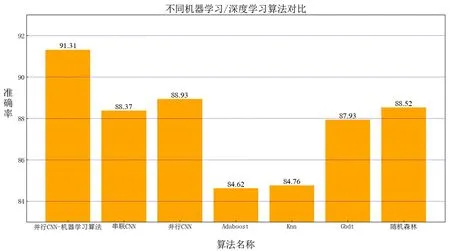
圖5 本文算法與其他算法結果對比
(2)算法對比
將本文算法與XGBoost算法進行對比,比較其在每一類上的f1值,同時將其他算法中對每一類預測的最高值加入比較。圖6所示為不同算法對于每一類預測的f1值,該模型對8個少數類的預測準確率最高。證明了本文算法有效改善了原有模型對于少數類別的預測成功率較低問題。
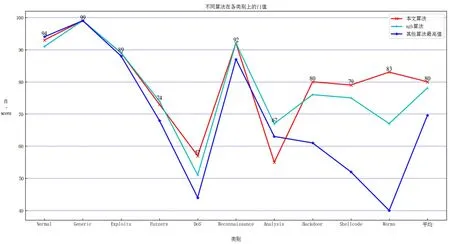
圖6 不同算法對在不同類別上的f1-score值
(3)算法加入預測概率特征與原本對比
圖7所示為不同算法對加入十維訓練準確率特征并進行特征選擇后訓練的模型與原本模型的結果對比。加入預測特征后的模型準確率平均提升1%,少數類樣本預測準確率提升較大,證明了準確率特征對少數類樣本的預測起到了作用。
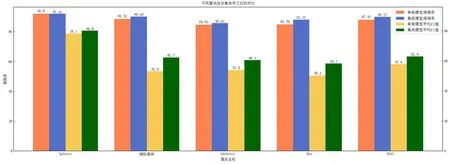
圖7 不同算法加入訓練準確率特征后的對比
3.4 采樣方法對比
圖8對比了幾種過采樣、欠采樣以及組合采樣方法預測準確率與十類平均f1值。
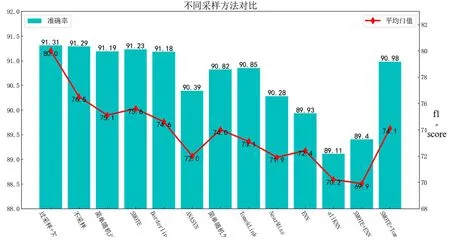
圖8 不同采樣方法對比
由圖8可知,對于本數據集,過采樣效果普遍高于欠采樣,猜測為清洗后的數據集中冗余數據較少。與此同時,不采樣與簡單隨機采樣也有較好的效果。表3所示為不同采樣方法下的平均準確率與召回率值以及五類少數類樣本(DoS、Analysis、Backdoor、Shellcode、Worms)的平均預測準確率。
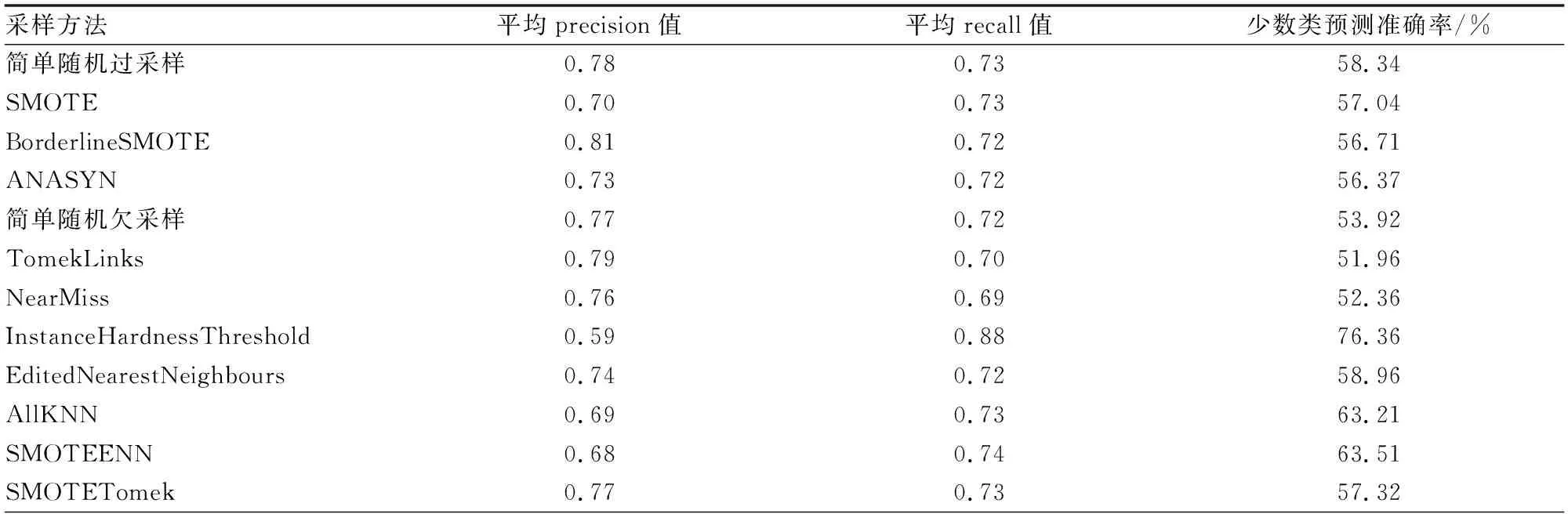
表3 不同采樣方法的平均precision與recall值
對比幾種采樣方法在各類樣本上的幾項指標可得:選用的12種方法采樣中有6種precision值超過0.75,平均recall值在0.7以上,其中過采樣方法的平均precision普遍高于其它方法,同時過采樣方法的平均precision和recall值較為平均,整體預測效果較好。 InstanceHardnessThreshold采樣方法對于所有類樣本的平均recall值達到0.88,該采樣方法會訓練一個分類器,將分類器中預測概率較低的樣本移除,因此,對少數類預測準確率達到76.36%,可以成功預測出少數類樣本,但該方法也會導致整體準確率降低。
總體而言,過采樣能保證整體預測效果提升,欠采樣能有效提高少數類預測效果,因此本文選擇先將Analysis、Backdoor、Shellcode、Worms幾個少數類進行SMOTE過采樣,再對Normal、Generic等多數類進行簡單隨機欠采樣。
3.5 數據維度選擇
經過數據預處理后的原始數據共有196維,神經網絡模型預測得到的特征為10維;為提升模型的訓練與預測速度,本文采用隨機森林算法對原始數據進行特征選擇,與神經網絡模型預測得到的10維特征拼接后分別構建模型;由于XGBoost本身為具有判斷特征重要性能力的樹結構,同時采用XGBoost算法進行特征排名,選出特征訓練模型。
圖9所示為由隨機森林與XGBoost進行特征重要性排名,選擇前20、35、50、65維特征同神經網絡十維預測結果分別拼接后作為訓練集的模型預測結果。對比可知,使用隨機森林選擇的特征訓練出的模型準確率均在91%以上,平均高于XGBoost選擇得到的特征0.5%,與使用全部特征相比平均準確率只下降了0.2%,效果最好的50維特征僅下降0.04%。
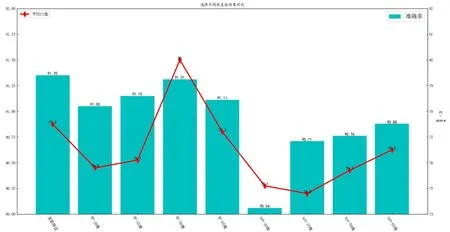
圖9 不同維度數預測結果對比比
4 結論
(1)提出了一種結合卷積神經網絡、LSTM網絡與XGBoost算法的網絡異常行為檢測模型,該模型在UNSW-NB15數據集上多分類準確率達到91.31%,在十個個類別上平均f1值為0.80,綜合效果高于非集成模型與未使用采樣方法的模型。同時證明了數據降維方法在高維度數據中的效果,采用數據降維后,模型在十個類別上平均f1值提升了0.025。
(2)針對多分類網絡異常行為檢測任務,在觀察實驗結果后,認為下一步改進計劃主要有兩點:一是發現DoS類預測準確率較低,DoS類樣本中近半數被預測為Exploits類,可以就對于DoS類的預測單獨構建模型;二是發現部分數據在多輪實驗中均預測到其它類,猜測其標簽可能標注錯誤,證明數據仍有進一步改進的空間。同時如何建立一個實時檢測系統,如何對大量數據進行快速檢測,將預測模型落實到應用層面也是未來的工作重點。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
