基于成對約束的三視圖對比聚類算法
2024-01-17 00:00:00譚思婧李艷彭磊盧虹妃蒙柏錡
企業科技與發展 2024年12期


0 引言
聚類是將數據集中的樣本根據相似性或特定特征進行分組的過程,目的在于確保同一組內樣本之間相似度較高,而不同組之間相似度較低。聚類算法主要分為以下兩類:一是基于機器學習的聚類方法,典型代表有K-Means(K均值算法)[1]和譜聚類[2-3]等;二是深度聚類算法,該類算法通過深度神經網絡學習特征進行聚類,相較于傳統的機器學習聚類方法,能夠取得更好的聚類效果。Guo等[4]提出的深度嵌入聚類IDEC算法通過結合聚類損失和自編碼器重構損失,有效優化了聚類結果并保持了數據的局部結構。隨后,Guo等[5]又提出了一種深度卷積嵌入聚類DCEC算法,利用卷積自編碼器聯合優化重構和聚類損失,有效提升了特征學習和聚類性能。然而,多數深度聚類算法需要迭代進行表示學習和聚類,通過不斷優化表示學習來提高聚類性能,這不僅增加了計算復雜度,而且還可能導致迭代過程中的誤差累積。為解決這些問題,基于對比學習的聚類方法應運而生。對比學習能夠自主學習樣本之間的相似性和差異性,從而獲得更優的特征表示。將對比學習的優勢與聚類任務相結合,基于對比學習的聚類算法已在聚類領域得到了廣泛應用。Deng等[6]提出的層次對比選擇編碼HCSC框架,通過動態更新層次原型并改進對比學習配對選擇,提升了圖像表示的語義結構適應性;Xu等[7]針對現有對比學習方法在深度聚類中的弱增強限制,提出強增強對比聚類(SACC)方法,該方法引入了多個視圖并聯合運用強弱增強策略;Li等[8]提出了一種新的深度圖像聚類方法——IcicleGCN,該方法結合了卷積神經網絡(CNN)和圖卷積網絡(GCN),并融入對比學習和多尺度結構學習,從而有效提升了圖像的表示學習與聚類性能。盡管如此,這些方法仍存在一些不足,如數據增強方法有限且變換手段單一,大多僅使用兩種增強視圖,限制了多視圖學習所能提供的豐富表示學習機會;同時,負樣本對通常由不同類別的增強樣本構成,并且數量遠超正樣本對,這對模型性能產生了直接影響[8]。尤為突出的是,基于對比學習的聚類通常僅從未標注數據中學習特征信息,缺乏對標注數據(即先驗信息)的利用。將半監督學習引入無監督聚類算法中,能有效引導學習過程并提升聚類效果[9-10]。
針對上述問題,本文提出了一種基于成對約束的三視圖對比聚類算法(TCCPC)。該算法由主干網絡(采用深度殘差網絡-34,ResNet-34)、實例級投影網絡[兩層多層感知機(MLP)]和聚類級投影網絡(帶有softmax層的兩層MLP)3個網絡模塊組成。本文的創新之處主要體現在以下幾個方面:①采用14種強增強和5種弱增強方法,使模型能夠學習到更深層次的特征。②引入3種增強視圖進行實例級與聚類級的對比學習,增加了模型的特征學習機會。③通過成對約束引導聚類,減弱了負樣本的影響,提升了聚類效果。TCCPC結合了對比學習與成對約束聚類的優勢,為模型提供了更多特征學習的機會。
1 成對約束及其定義
成對約束包括必連約束(Must-Link,ML)和勿連約束(Cannot-Link,CL)。必連約束表示兩個樣本必須被分配到同一類別中,而勿連約束則要求兩個樣本必須歸屬于不同的類別。通過引入這些約束條件,聚類模型能夠更有效地避免錯誤的分類決策,并增強對數據內在結構的認知,從而提升聚類的準確性和整體效果。成對約束使得聚類算法能夠充分利用已知的樣本之間的關系信息,更精確地挖掘數據中的潛在模式。
定義1:Must-Link集合M定義為 [M=xi,xj],若 [xi,xj∈M],則表明數據[ xi ]和 [xj] 必定屬于同一類別,即滿足必連約束關系。
定義2:Cannot-Link集合C定義為 [C=xi,xk],若" [xi,xk∈C],則表明數據[ xi ]和 [xk ]必定屬于不同類別,即滿足勿連約束關系。
2 算法表述
本文采用3個網絡結構,并引入成對約束,構建了TCCPC基本框架(如圖1所示)。這3個網絡分別為五重共享權重骨干網絡 [fθ](基于ResNet-34)、實例級投影網絡 [gθ](由兩層MLP構成)和聚類級投影網絡[?θ](包含softmax層的兩層MLP)。在輸入骨干網絡[fθ]之前,所有不同維度的數據均統一調整為224×224像素。其中,五重共享權重骨干網絡 [fθ] 需輸入成對約束信息及某一樣本的3種數據增強視圖 [vji](包括2個強增強視圖和1個弱增強視圖,或2個弱增強視圖和1個強增強視圖)。對于每個增強視圖[ vji] ,通過骨干網絡 [fθ] 后的輸出表示為[ zji,其中 i∈1,N,j∈1,2,3]。隨后,這些輸出被送入實例級投影網絡[ gθ] 和聚類級網絡[ ?θ ],以構建兩種類型的特征矩陣。最后,通過優化實例級對比損失、聚類級對比損失及成對約束損失來訓練模型。
2.1 視圖增強
同一樣本的3個增強視圖搭配分為以下兩種情形:一是2個強增強視圖搭配1個弱增強視圖;二是2個弱增強視圖搭配1個強增強視圖。本文采用14種強增強方式[11]生成強增強視圖,同時采用5種對比學習中常用的數據增強方法(隨機裁剪、水平翻轉、色彩抖動、灰度轉換和高斯濾波處理)生成弱增強視圖。增強視圖的組合方式見表1。
給定N個樣本數據,對每個輸入的樣本都進行3種不同方式的數據增強,共得到3N個數據增強樣本:[v11, …, v1N ,v21 , … , v2N , v31 , … , v3N]。隨后,這3個增強視圖經骨干網絡[ fθ] 處理后,得到輸出集合[zji ]:
[ z11 , … , z1N , z21 , … , z2N , z31 , … , z3N]" ,
[其中:i∈1, N,j∈1, 2, 3]。3個數據增強樣本經過神經網絡進行嵌入表示的過程可用以下公式表示:
[z1i=fv1i, z2i=fv2i, z3i=fv3i。]" " " " " "(1)
2.2 實例級投影
3個增強視圖經過骨干網絡 [fθ] 后生成特征表示[zji],隨后通過實例級投影網絡[gθ]進一步處理,得到最終的實例級投影表示[ pji],具體過程可用以下公式表示:
[p1i=gz1i, p2i=gz2i, p3i=gz3i。]" " " " " "(2)
其中:i∈[1, N];j∈[1, 2, 3]。
為了優化模型性能,增強視圖采用表1中的組合方式。采用余弦相似度來度量實例對之間的相似程度,以提高正樣本對之間的相似度,具體表示如下:
[su,v=uΤvuv]," " " " " " " " " " " " "(3)
其中,u和v為2個特征向量。假設每個數據i的某2種數據增強方式分別為a和b,為了優化所有正對的一致性,需計算每個數據增強視圖的實例級對比損失。對于某個數據增強視圖[ vai ],其實例級對比損失為
[?ai=?logexpspai,pbiτgj=1Nexpspai,pbiτg+expspai,pbiτg]," (4)
其中:[i, j∈1, N],且 [a, b∈1, 2, 3] ;[τg]為溫度系數。
本文算法將除正樣本對之外的其他聚類增強視圖作為負樣本對。同樣地,對于某個數據增強視圖 [vbi],其實例級對比損失為
[?bi=?logexpspbi, paiτgj=1Nexpspai, pbjτg+expspbi, pajτg] 。" (5)
對于某個正樣本對,增強視圖[ vai ]與[ vbi ]的對比損失為
[Linstance(a, b)=][i=1N?ai+?bi];" " " " " " " " "(6)
每個數據的兩組正樣本對的實例級對比損失為
[Linstance=Linstance(1, 2)+Linstance(1, 3)] 。" " " " " (7)
2.3 聚類級投影
假設聚類結果中簇的數量為 [M],即數據集被劃分為 [M ]類。本文將3個增強視圖通過骨干網絡 [fθ ]處理后得到的特征[ zji]通過聚類級投影網絡 [?θ ]進行處理,得到聚類級投影表示 [qji]。過程公式為
[q1i=hz1i, q2i=hz2i, q3i=hz3i]," " " " " (8)
其中,[qji] 為每個增強樣本的軟標簽,即每個樣本都有屬于不同類別的概率。
聚類級投影網絡也采用余弦相似度來衡量正樣本對之間的相似程度。假設數據 [i] 經歷了2種不同的增強方式 [a] 和 [b] ,并進行聚類級對比。此時,[qam]表示增強視圖[ vai ]屬于第 [m] 類的概率,其中[i∈1, N]。對于某個增強視圖[ vai],其聚類級對比損失表示為
[?am=?logexpsqam, qbmτ?n=1Mexpsqam, qanτ?+expsqam, qbnτ?。] (9)
同樣地,對于某個數據增強視圖[ vbi],其聚類級對比損失表示為
[?bm=?logexpsqbm,qamτ?n=1Mexpsqbm,qbnτ?+expsqbm,qanτ?。] (10)
某對正樣本對的聚類級對比損失可表示為
[Lclustera,b=12Mm=1Mlam+lbm?HY。]" " " (11)
為避免大多數樣本聚集到同一個簇中,本文引入了一種新方法,該方法通過計算每個數據增強視圖在1個min-batch內的聚類分配概率[Pqkm]的熵 [HY]來衡量聚類的多樣性。具體計算公式如下:
[Pqkm=n=1NYkn mY1, k∈a, b,]" " " " "(12)
[HY=?m=1MPqamlogPqam+PqbmlogPqbm]。" " " " " " " " "(13)
將同一數據的3種增強視圖構成3組正樣本對,對其進行聚類級對比損失,具體表示如下:
[Lcluster=Lcluster1,2+Lcluster2,3+Lcluster1,3。]" " "(14)
2.4 成對約束
如果2個數據的標簽相同,則它們之間建立必連約束,要求經過骨干網絡[fθ]處理后的特征盡可能相似;反之,則建立勿連約束,要求經過骨干網絡[fθ]處理后的特征盡可能相互遠離。成對約束損失表示為
[Lpair=Cdrd=1n||zd?zr||22 / n]," " " " " " " " " (15)
其中,n為成對約束對的個數。根據Klein等[12]對成對約束的使用,[Cdr]的取值可進行如下定義:
[cdr=+1, xd, xr∈ML ?1, xd, xr∈CL]。" " " " " (16)
當數據[ xd ]與 [xr] 為必連約束對時,[cdr]為1;當數據[ xd ]與 [xr] 為勿連約束對時,[cdr] 為-1。最后,總目標損失函數由聚類級對比損失、實例級對比損失與成對約束損失共同組成,定義為
[L=Lcluster+γLinstance+λLpair] ," " " " " "(17)
其中,[ γ ]與[ λ] 為平衡系數。
3 實驗分析
3.1 數據集及實驗環境
本文采用了5個公開的數據集:CIFAR-10[13]、CIFAR-100[13]、STL-10[14]、ImageNet-10[15]和ImageNet-Dogs[15],并將所提算法與多種聚類算法進行了性能對比。實驗環境配置如下:Intel(R)Xeon(R)CPU E7-4820 v4@2.00G Hz處理器、4張NVIDIA GeForce RTX 2080 Ti顯卡、Ubuntu 18.04.6 LTS 操作系統、Python 3.10.9及PyTorch 1.21.1。
3.2 算法對比
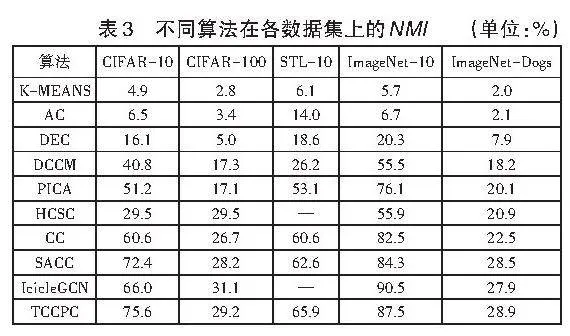
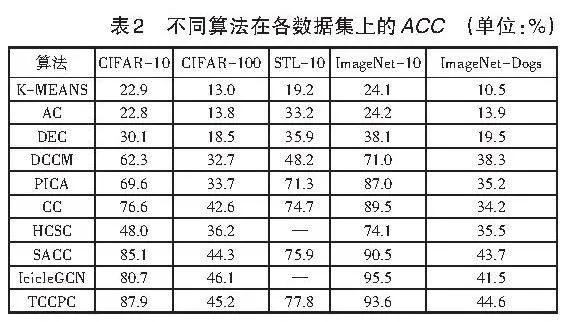
本文在5個公開數據集上采用準確率ACC(Accuracy)和歸一化互信息NMI(Normalized Mutual Information)作為指標,對算法性能進行了對比評估。結果顯示,TCCPC算法在性能上有顯著提升。K-Means、AC(凝聚聚類)、DEC(深度嵌入聚類算法)、DCCM(圖像聚類的深度綜合關聯挖掘)、PICA(劃分置信度最大化深度語義聚類)、CC(對比聚類算法)、SACC(強增強對比聚類)等算法的指標數據引自文獻[7],而HCSC(層次對比選擇編碼)和IcicleGCN(基于對比學習和多尺度圖卷積網絡的深度圖像聚類)的指標數據則分別來自文獻[7]和文獻[8]。TCCPC算法的性能通過所有評價指標的平均值來體現。
(1)K-Means:一種經典的聚類算法,通過最小化類內均方誤差將n個樣本分為k個簇。
(2)AC:一種自底而上的層次聚類方法,逐步合并最相似的類,直至所有元素歸為一個整體類別。
(3)DEC:利用深度神經網絡同時學習特征表示和聚類分配,將數據映射到低維特征空間并優化聚類目標。
(4)DCCM:基于深度挖掘的圖像聚類算法,全面提取不同樣本之間的相關性及局部魯棒性特征。
(5)PICA:通過劃分置信度最大化進行深度語義聚類,旨在找到語義上最適合的類間分離方式。
(6)CC: 利用數據增強技術進行正負樣本對的實例級與聚類級對比學習。
(7)HCSC:通過層次原型捕獲數據的層次語義結構,改進實例和原型之間的對比學習。
(8)SACC:構建了2個弱增強視圖與1個強增強視圖進行對比聚類分析。
(9)IcicleGCN:結合了對比學習和多尺度圖卷積網絡進行深度圖像聚類,同時加入多尺度鄰域結構學習。
不同算法在各數據集上的ACC和NMI分別見表2和表3。從ACC指標來看,TCCPC算法在ImageNet-Dogs、CIFAR-10、STL-10數據集上表現較優,特別是在CIFAR-10數據集上比HCSC算法平均提升了39.9%,與DCCM、PICA、CC、SACC、IcicleGCN相比,分別提升了25.6%、18.3%、11.3%、2.8%和7.2%。從NMI指標來看,TCCPC算法在STL-10數據集上表現最佳,與DCCM、PICA、CC、SACC相比,分別提升了29.6%、6.5%、3.1%、1.9%。
3.3 消融實驗
3.3.1 成對約束消融分析
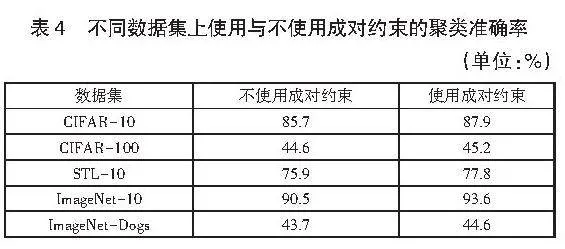
為充分驗證成對約束的有效性,本文設計了消融實驗,對比了使用成對約束與不使用成對約束兩種情況下的聚類結果(見表4)。實驗結果表明,成對約束信息的引入能夠顯著提升模型的聚類效果。
3.3.2 實例級與聚類級投影網絡分析
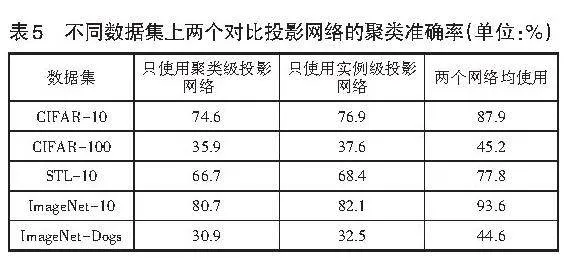
為探究實例級投影[gθ]與聚類級投影 [hθ] 對聚類性能的影響,設計相應的消融實驗。在確定數據集的最優迭代次數、最優數據增強視圖組合以及最優成對約束數量后,針對以下3種情況進行了實驗:①僅采用實例級投影網絡,并通過K-means算法獲得聚類結果。②僅采用聚類級投影網絡。③同時采用兩個投影網絡進行對比學習。不同數據集上兩個對比投影網絡的聚類準確率對比結果見表5。根據表5中的數據,同時采用實例級投影網絡與聚類級投影網絡的模型準確率最高,驗證了本文所提框架的合理性。
4 結語
本文提出了一種基于成對約束的三視圖對比聚類算法,解決了傳統對比學習聚類方法中數據增強手段單一和視圖對比受限的問題。具體而言,該算法結合14種強增強和5種弱增強方法,引入了3個數據增強視圖以提高模型的泛化能力,并利用成對約束來指導聚類過程,從而提升了聚類效果和模型能力。在5個公開數據集上的對比實驗結果顯示,本文算法取得了良好成效,驗證了所提框架的有效性。盡管基于成對約束的對比聚類方法表現優異,但是其仍受限于高標注成本、對噪聲的敏感性以及跨領域泛化能力的不足。未來可以從自動生成成對約束、設計抗噪機制、提升跨領域適應性等方面結合預訓練模型與動態約束調整策略展開更深入的研究,以期進一步提升聚類性能和實用性。
5 參考文獻
[1]KANUNGO T,MOUNT D M,NETANYAHU N S,et al. An efficient k-means clustering algorithm: analysis and implementation[J].IEEE Transactions on Pattern Analysis amp; Machine Intelligence,2002,24(7):881-892.
[2]LUXBURG U V.A Tutorial on spectral clustering[J].Statistics and Computing,2004,17(4):395-416.
[3]LIANG Z,YUAN C,QIN X,et al.Hot region mining approach based on improved spectral clustering[J].Journal of Chongqing University of Technology(Natural Science),2021.35(1):129-137.
[4]GUO X,LIU X,ZHU E,et al.Deep clustering with convolutional autoencoders[C]//Neural Information Processing: 24th International Conference(ICONIP 2017).Guangzhou, China,2017:373-382.
[5]GUO Y,XI M,LI J,et al.HCSC:hierarchical contrastive selective coding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).New Orleans,LA,USA,2022:9706-9715.
[6]DENG X,HUANG D,CHEN D H,et al. Strongly augmented contrastive clustering[J].Pattern Recognition,2023,139:109470.
[7]XU Y,HUANG D,WANG C D,et al.Deep image clustering with contrastive learning and multi-scale graph convolutional networks[J].Pattern Recognition,2024,146:110065.
[8]LI P,DENG Z.Use of distributed semi-supervised clustering for text classification[J].Journal of Circuits,Systems and Computers,2019,28(8):1950121-1950127.
[9]LI G Z,YOU M,GE L,et al.Feature selection for semi-supervised multi-label learning with application to gene function analysis[C]//Proceedings of the First ACM International Conference on Bioinformatics and Computational Biology(BCB). Niagara Falls,NY,USA,2010:354-357.
[10]HE K,ZHANG X,REN S,et al.Deep residual learning for image recognition[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas,Nevada,USA,2016:770-778.
[11]CUBUK E D,ZOPH B,MANE D,et al.Autoaugment:Learning augmentation strategies from data[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR)).Seoul,South Korea,2019:113-123.
[12]KLEIN D,KAMVAR S D,MANNING C D.From instance-level constraints to space-level constraints:making the most of prior knowledge in data clustering[C]//International Conference on Machine Learning(ICML). University of New South Wales,Sydney,Australia,2002:307-314.
[13]KRIZHEVSKY A,HINTON G.Learning multiple layers of features from tiny images[J].Handbook of Systemic Autoimmune Diseases,2009,1(4):1-60.
[14]COATES A,NG A,LEE H.An analysis of single-layer networks in unsupervised feature learning[C]//Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics(JMLR).Ft.Lauderdale, FL,USA,2011:215-223.
[15]CHANG J,WANG L,MENG G,et al.Deep adaptive image clustering[C]//Proceedings of the IEEE International Conference on Computer Vision(ICCV).Venice,Italy,2017:5879-5887.
*2022年廣西科技重大專項“人工智能混合架構計算平臺構建與項目研究”(AA22068057)。
【作者簡介】譚思婧,女,廣西南寧人,在讀碩士研究生,研究方向:深度聚類;李艷(通信作者),女,山西忻州人,碩士,研究方向:深度聚類;彭磊,男,廣西欽州人,在讀碩士研究生,研究方向:圖神經網絡;盧虹妃,女,廣西玉林人,在讀碩士研究生,研究方向:數據挖掘;蒙柏錡,男,廣西梧州人,在讀碩士研究生,研究方向:自監督學習。
【引用本文】譚思婧,李艷,彭磊,等.基于成對約束的三視圖對比聚類算法[J].企業科技與發展,2024(12):108-112.
