基于Python 爬蟲的招聘數據可視化分析
2024-01-23 07:32:38蔡文樂秦立靜
物聯網技術 2024年1期
蔡文樂,秦立靜
(甘肅農業大學 信息科學技術學院,甘肅 蘭州 730070)
0 引 言
近年來各個高校畢業人數增多,面對各類網絡招聘網站繁雜紛呈的招聘信息,畢業生常常要花費大量的時間和精力篩選,如果畢業生可以根據自身需求,直觀地了解到各個行業的崗位特征和變化趨勢,將有利于求職者快速做出選擇[1]。本文實現的招聘網數據可視化分析系統主要利用基于Python語言開發的高級Web 框架Django,整個系統架構可以分為數據的爬取、數據的預處理、數據的存儲、數據的可視化分析。
1 系統介紹
本文設計的系統功能模塊如圖1 所示。首先,通過Python 的爬蟲框架,利用爬蟲技術實現對目標網頁的爬取;對網站的URL 發出請求,在URL 接收到請求并返回結果后進行分析,通過Python 的BeautifulSoup 解析庫對系統所需要的數據信息進行解析;然后以CSV 文件的形式保存,主要提取返回結果中的薪資水平、工作經驗、學歷程度、公司規模、公司名稱等相關信息;其次,對數據進行處理,將導入到系統的數據文件進行讀入,連接MySQL 數據庫,再對數據進行增刪改查。在目標網頁上爬取相應的數據信息過程中,爬取到的數據信息中必然會存在一些重復冗雜的數據,是因為在運行爬蟲程序的過程中會出現反爬蟲機制,因此要實現數據去重、刪除文件空值行數據等操作;最后,數據分析是整個流程中最重要的階段,主要是將上一階段經過清洗處理的數據按照一定的規則方法進行分析處理,為之后的可視化展示提供數據支撐[2]。以可視化的形式去展現對所得數據信息分析的結果,主要采用Python 開發語言去實現結果的表達,讀入獲取的數據文件并進行統計分析,將分析的結果進行保存;連接相應的數據庫,HTML 頁面接收到相應的數據信息,并在HTML 頁面中使用相應的語法程序將結果數據動態添加到相應的柱狀圖、餅圖等圖表中。
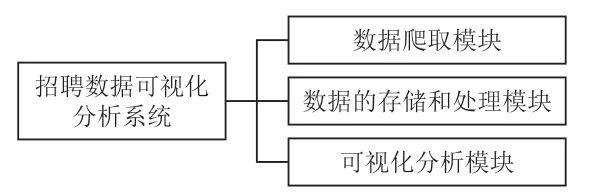
圖1 系統功能模塊
2 相關技術
2.1 Scrapy 爬蟲
網絡爬蟲技術是通過編寫計算機爬蟲程序,按照一定的規則,爬取目標網頁的數據信息。采集有價值的數據,過濾掉無效的數據,得到充足的數據資源,用于進行一系列相關項目的研究和分析。爬取目標網站的招聘信息,對網站的URL 發出請求,得到URL 的返回結果并進行分析,部分代碼如下:

2.2 MySQL 數據庫
關系型數據庫管理系統MySQL,是Oracle 旗下的產品,開發公司為MySQL AB,在當前盛行的數據庫中占據一席之地,在Web 應用方面是最好的RDBMS 應用軟件之一。關系數據庫中的數據并不是放置在一個大的數據倉庫,而是放在不同的表中,因此這樣的方式加快了處理速度并提高了靈活性。
2.3 Django 框架
Django 的程序編寫由Python 來實現,是一個開放源代碼的Web 應用框架,也是Python 編程語言驅動的主要來源。Django 架構能夠快速方便地創建出高品質、易維護、數據驅動的應用程序。除此之外,Django 還具有強大的可擴展性,這是因為它具有功能強大的第三方插件。Django 框架的設計模式與MVC 的設計模式異曲同工,稱為MTV。MTV 就是Model、Template 和View 三個單詞的簡寫,分別表示模型、模版和視圖[3-4]。由于在Django 里面更加關注模型(Model)、模板(Template)和視圖(Views),因此使用Django 框架會大大提高工作效率。
2.4 Selenium 應用測試
Web 程序的測試主要采用Selenium 在瀏覽器中進行。首先啟動瀏覽器后,Webdriver 會將瀏覽器綁定到特定端口作為Remote Server;創建Sessionld 是由客戶端借助ComandExecutor來實現的,同時發送請求給Remote Server;Remote Server 在收到請求后,調用Webdriver 進行操作,并將響應的結果返回給客戶端。
3 系統實現
3.1 數據采集模塊
為了能夠快速獲取到目標網頁的數據信息,實現數據信息的分析和可視化,所以在數據采集模塊主要采取的是網絡爬蟲技術。本文系統需要的數據量大,一般的爬取技術爬取數據信息的效率低下,而且容易遭受反爬蟲機制。因此,本文系統的實現主要采取Scrapy 分布式爬蟲框架。Scrapy 框架是基于Python 實現爬取Web 站點、提取結構化數據的應用框架,可用于數據挖掘、數據監測、自動化測試等,具有結構簡單、靈活性強、高效迅速的特點[5-6]。本文選用BOSS直聘網站進行相關數據的獲取。數據爬蟲的基本流程主要為發起請求、解析內容、獲取響應的內容以及數據保存。數據的采集過程就相當于用戶在網頁上對自己所需要的數據進行搜集。
(1)確定爬取對象
本文主要實現對BOSS 直聘網站的相關數據進行爬取,爬取數據信息的主要內容包括薪資、工作經驗、學歷要求、公司名稱、所在行業、崗位要求、公司地址等,將爬取的數據進行預處理,最后實現數據分析。
(2)分析網頁結構
網絡爬蟲并不會對所需網頁的界面進行一系列的操作,只需要模擬人工去訪問所需的網頁。因此,爬蟲之前對所需網頁結構的了解是必不可少的一個步驟。利用瀏覽器自帶的開發者工具對爬取網頁進行深入挖掘和分析,了解各個信息元素之間的異同點。最后實現網絡爬蟲程序的編寫,需要查看網頁HTML 的代碼,對所需數據信息進行核查。
(3)編寫Scrapy 爬蟲程序
發起請求、解析信息、獲取響應內容和存儲數據是爬蟲框架的基本流程。首先,HTTP 向目標站點發起Request 請求后等待服務器的響應,如果服務器的響應是正常的,則會得到一個Response,這個Response 中包含了獲取到網頁的數據信息,這些數據信息的類型可能有HTML、JSON 字符串、二進制數據等多種類型,并且保存的方式多樣化,可以是純文本形式,也可以保存至數據庫。
基于Scrapy 爬蟲框架的招聘數據信息可視化系統,主要由配置文件settings.py、主程序文件spiderMain.py等文件組成。其中,對抓取到的目標網頁數據信息和數據結構的分析主要通過數據字段的文件來實現,并且相應的數據字段是通過scrapy.Field()方法建立的。如圖2 所示是爬取到的部分信息。獲取到所需的部分崗位信息后進行存儲,如WorkExperience 存儲工作經驗、Salary 存儲工作薪資等,部分代碼如下:

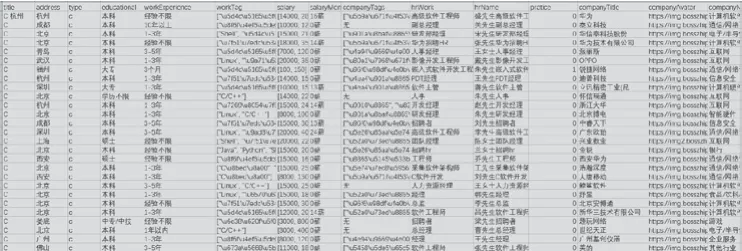
圖2 爬取數據
3.2 數據的存儲與處理模塊
通過網絡爬蟲技術能夠采集到多樣化的網頁數據,但同時也存在各種各樣的問題,如數據缺失、冗余、重復、不一致﹑數據結構錯亂等。如果對原始數據沒有進行處理而是直接進行分析,不僅會使數據決策的效率受到影響,甚至會出現直接決策的錯誤。因此,在系統的實現過程中,對原始數據的處理成為了至關重要的問題,原始數據中可能會存在數據的缺失、重復等問題,需要對獲取到的數據信息進行相關的預處理操作,最后提供給Hive 進行統計和分析。
在本文系統的搭建過程中,將數據導入使用Python 編寫的Pandas 庫的DataFrames 中,從而對數據進行數據清理,將重復無用的信息排查出去,并且對數據進行分類整理、聚類分析[7-8],如圖3 所示。將所獲取到的每一條崗位信息,按照一定的規則處理完成之后,存儲在MySQL 數據庫中,包括工資、學歷、工作經驗等。最后將處理得到的數據保存為CSV文件,同時篩選出有價值的數據信息以可視化的方式展現。
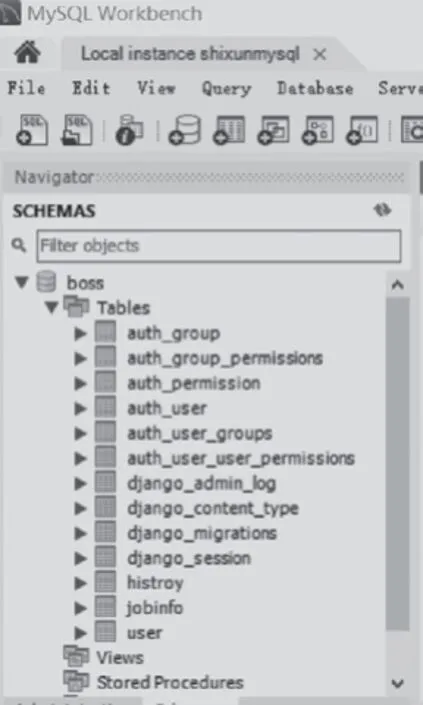
圖3 數據庫分類
3.3 數據的可視化分析模塊
數據可視化是一個比較抽象的概念,它的范圍在不斷地擴大,主要是從數據中抽象出信息,以一種清晰且簡單明了的方式展現出來。同時也是信息溝通的最有效手段。數據可視化分析主要就是將預處理后的原始數據使用一些比較有特色的技術方法,如圖形圖像處理、計算機視覺以及用戶界面,通過一定的表達、建模以及對表面、立體、屬性和動畫的顯示,以更加清晰的可視化方式呈現。數據可視化的主要目的在于:使用簡單的圖形圖像,更加清晰有效地傳達和溝通所獲取的數據信息。
此系統主要采用Python 的Django 框架對前端頁面進行設計,可視化圖表展示部分的實現采用EChart。EChart 是一個具備強大功能和強兼容性的可視化庫,會通過散點圖、餅圖、折線圖和不同頻次的詞云圖等可視化方式為求職人員清晰地展現招聘信息,使求職過程變得更快速高效。以下的可視化結果分析均以分析C 語言工程師崗位為例。
3.3.1 薪資情況
如圖4 所示,從薪資分布可以看出,計算機類行業的薪資待遇在高薪資職業中占據一定的地位,此類行業普遍薪資水平較高。薪資在0 ~1 萬元和4 萬元以上的人數所占比例較少,大多數求職者的薪資維持在1 ~2 萬元、2 ~3 萬元和3 ~4 萬元之間,趨于一個穩定的狀態。薪資的高低與求職者自身所具備的能力水平直接相關,也與該公司的價值有關,因此薪資是求職者所看重的一個非常重要的方面。

圖4 薪資分布
3.3.2 崗位需求
互聯網時代,我們被各種各樣的數據所包圍著,為了更快地將有價值的數據提取出來,并且很好地去利用這些數據,因此必須先通過計算機相關技術去處理這些冗雜的數據。隨著互聯網、大數據等公司越來越多,計算機行業的崗位在大學生求職中也越來越熱門化。以C 語言工程師崗位為例,如圖5 所示為行業求職崗位數量圖,可以看出計算機軟件行業所占的比例高于其他行業,當前計算機行業處于一種競爭激烈的狀態。
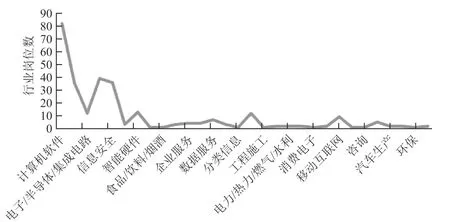
圖5 行業求職崗位分布
以C 語言工程師崗位為例,如圖6 所示,互聯網類的公司人數處于兩個邊緣,1 000 人以下的小型公司一般為大學畢業者創業的小型公司或者其他初創公司等,這些公司中100 人以下的公司所占比例較大;1 000 人以上的大型成熟穩步發展的公司中,10 000 人以上的公司所占比例最大。每一個公司的成員構成也體現出公司規模的大小、工作效率高低以及內核的成熟度等。因此公司規模的大小也是求職者尋找目標公司時所重點關注的一個方面。
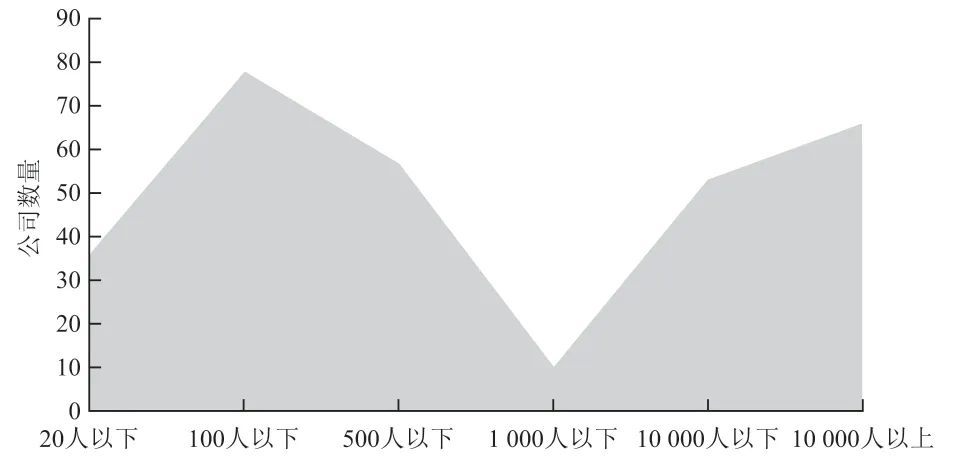
圖6 公司人數分布
3.3.3 城市分布
如圖7 所示,C 語言工程師人數主要分布在比較發達的一線城市,如北京、深圳等。原因在于這些城市的互聯網行業發展較好,求職者選擇這些城市會有較好的發展。

圖7 C 語言工程師地域分布
3.3.4 福利水平
以C 語言工程師崗位為例,如圖8 所示,可以看出在求職者所關注的眾多福利待遇之中,節日福利、年終獎、五險一金出現的頻次較高,這些對求職者來說都是最基本的保障;同時,帶薪年假、員工旅游和定期體檢等也是人們求職過程中所關心的。求職者在求職的過程中非常關注目標公司給員工創造的基本福利保障,同時各種福利保障也是激勵就業者創造工作業績、促進公司提升的重要手段[9-10]。

圖8 求職者關注的公司福利
3.3.5 公司名稱
如圖9 所示,隨著互聯網、大數據的熱度越來越高,互聯網公司越來越多,很多公司名稱中都會出現“科技”“信息”“軟件”等詞匯,并且出現頻次很高。可以看出,近年來信息科技公司已經逐漸發展起來,尤其是在上海、北京等一線城市分布得更為廣泛。

圖9 公司名稱
4 結 語
隨著網絡科技的高速發展,傳統的招聘方式已經不再適合企業和人才的需求。本文設計開發出一種基于網絡爬蟲的招聘信息數據可視化分析系統,通過此系統能夠篩選出有價值的招聘信息,使得求職者在求職的過程中對自己的崗位有清晰的認知和定位。本文所實現的招聘數據可視化分析系統,主要利用Python 爬蟲框架實現所需網頁數據信息的獲取,對采集到的原始數據進行預處理操作;然后采用Hive 針對薪資分布、行業數量、公司人數、城市分布,以及公司福利和名稱出現頻次進行統計及分析;最后通過ECharts 將采集到的信息以各類圖表和詞云圖的方式進行可視化展現,讓求職者更加直觀地看到各類分析結果,清楚地了解求職現狀,為求職者提供了一個更好的求職分析平臺,幫助求職者在求職的過程中找準自身定位,及時調整求職策略。
猜你喜歡
世界科學技術-中醫藥現代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
傳媒評論(2019年4期)2019-07-13 05:49:14
電子制作(2018年18期)2018-11-14 01:48:24
中華手工(2017年2期)2017-06-06 23:00:31
山東工業技術(2016年15期)2016-12-01 05:31:22
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
