
數據生命周期視角下的醫療健康大數據質量評價研究
2024-01-27 13:40:27翟運開郭瑞芳王宇等
現代情報 2024年1期
翟運開 郭瑞芳 王宇等










關鍵詞: 醫療健康大數據; 數據質量評價; 數據生命周期; 模糊最優最劣法; 熵權法
DOI:10.3969 / j.issn.1008-0821.2024.01.011
〔中圖分類號〕G203 〔文獻標識碼〕A 〔文章編號〕1008-0821 (2024) 01-0116-14
近年來, 隨著信息技術的快速發展, 可穿戴設備、電子健康監測儀器等智能醫療設備在生活中廣泛應用, 使得醫療健康相關數據呈指數增長并最終匯聚成醫療健康大數據。醫療健康大數據涵蓋與自然人醫療健康相關的多種數據, 涉及個人健康、公共衛生、醫藥服務等諸多方面, 是互聯網、物聯網、人工智能等領域與醫療健康相結合的產物[1-2] 。醫療健康大數據是國家重要的基礎性戰略資源, 它的發展和應用對改進醫療健康服務模式和促進社會經濟發展有著重要作用。我國已將醫療健康大數據納入了國家大數據戰略布局, 并出臺了《關于促進和規范健康醫療大數據應用發展的指導意見》等相關政策[3] , 成立了國家醫療數據中心、中國健康醫療大數據產業聯盟, 啟動了健康醫療大數據中心與產業園建設國家試點工程。
然而, 在大數據背景下, 醫療健康大數據快速累積的同時也暴露出了質量差、利用率低等問題。Burnum J F[4] 指出, 電子病歷等衛生信息技術的引入提高了醫療健康數據的寫入效率, 但同時也記錄了更多不良數據導致醫療健康數據質量下降。醫療健康領域的發展直接影響著人們的生活質量和社會穩定, 對服務的精準性要求較高[5] , 數據質量的下降增大了依托醫療健康大數據決策失誤的風險。良好的數據質量是高效利用數據、充分挖掘數據價值的前提和基礎, 醫療健康大數據的開放共享和深入應用離不開高質量的數據。
數據質量評價是數據質量管理和控制的基礎[6] , 通過數據質量評價可以發現我國醫療健康大數據質量的薄弱方面, 進而促進醫療健康大數據質量提升。現有醫療健康數據質量評價相關研究以構建評價指標體系為主, 指標多涉及準確性、完整性、規范性等通用指標, 同一指標的定義存在差別[7-8] , 多以主觀方法確定指標權重, 且缺乏完整評價模型的構建與應用[9] 。鑒于此, 本文考慮了醫療健康大數據的自身特點, 結合數據生命周期理論, 構建了醫療健康大數據質量評價指標體系, 并采用主客觀相結合的方法確定各指標權重, 最終選取多家單位數據庫中真實存儲的醫療健康大數據作為評價對象, 驗證本文所構建的評價指標體系和綜合評價模型的科學性與有效性, 進而為醫療健康大數據的質量控制與提升提供指導, 為醫療健康大數據的深入應用與產業發展打下堅實基礎。
1 文獻綜述
數據質量與實體產品質量不同, 在數據的生產、儲存、使用中, 涉及到數據生產者、數據管理者、數據消費者三種角色, 對于每種角色而言數據質量的含義側重有所不同。數據質量多從消費者的角度進行定義, 對于數據消費者即使用者來說, 有用性和可用性是數據質量的重要方面[10] , 由國家市場監督管理總局、中國國家標準化管理委員會發布的《信息技術數據質量評價指標》將數據質量定義為,在指定條件下使用數據時, 數據的特性滿足明確的或隱含的要求的程度[11] 。對數據質量進行評價的視角有數據產品視角、數據平臺視角、數據用戶視角、數據生命流程或周期視角[12-13] , 現有研究多以用戶需求視角和數據生命周期視角為主[14-15] , 評價方法涉及訪談、德爾菲法、層次分析、模糊綜合評價等方法[16-17] , 主觀性較強且多以提出概念框架為主, 模型理論性強可行性差。
現有研究中, 與醫療健康數據相關的質量評價涉及電子病歷數據、醫院信息系統數據、公共衛生信息數據等。袁莎等[9] 基于文獻分析和專家咨詢的方法, 依據原始質量、過程質量、結果質量3 個維度, 構建了醫療數據評價指標體系。楊善林等[5] 將醫療健康大數據中的醫療健康案例質量把控劃分為了入庫階段和使用階段, 通過人機融合的方法, 分別從信息完整性、典型性、外部特征以及有用性、易用性、總體質量等方面對案例進行評價。在評價指標體系的相關研究中, 美國國立衛生研究院衛生保健系統研究實驗室對電子健康檔案(EHR)數據質量從完整性、準確性、一致性3 個維度進行了評估。Weiskopf N G 等[7] 通過相關文獻分析提出使用完整性、正確性、一致性、可信性、通用性5 個維度和7 類質量評估方法對電子病歷數據質量進行評估, 以促進電子病歷數據的重用。已有的研究中涉及指標范圍較廣, 但對于數據質量各個維度和指標缺乏明確、統一的含義[18] , 對醫療健康大數據自身特性考慮不足, 缺少系統的評價程序, 難以全面、準確地對醫療健康大數據的質量進行評價。
此外還有一系列信息化評估工具, 如對EHR 數據質量進行評估的可視化、開源、可拓展的DQe-c工具, 可以生成基于Web 的報告, 通過描述性圖表體現EHR 數據庫的完整性和一致性[19] ; 使用Hadoop Map/ Reduce 對醫療資源描述框架(RDF)數據集進行質量評估和異常數據檢測[20] , 以提供更加準確和可靠的數據集。以上工具多針對某種明確數據源, 對被評價數據要求較高, 普適性較差, 并且多基于西方國家醫療健康大數據發展現狀, 難以在我國直接外推使用[21] 。
針對以往數據質量評價指標體系中存在的定義不明確、對醫療健康大數據特點針對性不強等問題,本文基于已有文獻中的指標和該領域多位專家意見, 基于數據生命周期視角并充分考慮醫療健康大數據自身特性, 結合醫療健康大數據質量生命周期模型, 對數據質量評價指標進行重新定義和階段劃分, 構建了符合醫療健康大數據特點的質量評價指標體系。為了彌補已有研究中評價方法主觀性較強的問題, 在指標權重確定過程中, 本文充分考慮評價過程的模糊性和不確定性, 使用模糊最優最劣法(模糊BWM) 和熵權法(EWM) 綜合確定指標主、客觀權重, 在考慮專家經驗和主觀判斷的同時又有可量化數據支撐。為了增強評價結果的直觀性和綜合性, 本文將專家語言變量轉化為三角模糊數, 以定性與定量相結合的方法進行評價, 并引入TOP?SIS 方法進行綜合排序。最后, 對本文所構建的指標體系和綜合評價模型進行了實際應用, 獲得了具有現實意義的醫療健康大數據質量評價結果。綜上所述, 本文構建了較為完善的醫療健康大數據質量評價指標體系和評價模型, 可以全面、系統地對醫療健康大數據的質量進行綜合評價。
2 醫療健康大數據質量評價指標體系構建
基于數據生命周期理論, 構建了醫療健康大數據質量生命周期模型, 基于此并結合醫療健康大數據特點, 初步構建了醫療健康大數據質量評價指標體系, 而后根據專家意見對指標進行優化, 形成3個階段、9 個指標組成的醫療健康大數據質量評價指標體系。
2.1 醫療健康大數據質量生命周期模型
數據生命周期的概念提出于上世紀60 年代,進入21 世紀數據量快速增加, 數據生命周期理論得到進一步重視。數據資產管理組織(Data AssetManagement Association, DAMA)將數據生命周期定義為從創建、采集、使用到消亡的全過程。國內外對于數據生命周期的階段劃分有所不同, 涌現出了大量應用廣泛的模型, 如表1 所示。這些模型的階段劃分、適用對象和側重內容有所不同, 如DCC模型是較為通用的數據生命周期模型[22] ; DDI 模型主要針對社會科學數據[23] ; CSA 模型主要側重數據安全方面, 考慮了每一個階段可能會產生的數據安全問題[24] ; 數據質量生命周期模型劃分了創建、存儲、檢索、使用4 個主要周期, 有助于更好地理解數據質量問題且具有很強的通用性[25] 。國內學者周寧[26] 認為, 數據生命周期包括創建、存儲、使用、歸檔、銷毀5 個狀態, 數據一旦創建,可以在任意兩個狀態跳轉, 不一定經歷所有狀態。根據研究對象和研究問題的不同, 數據生命周期的階段劃分也會有所不同, 但廣泛存在交叉重疊。如研究較多的科研數據生命周期, 存在多種劃分方法, 但主要圍繞產生、收集、處理與存儲、共享與利用4 個階段。
本文以數據生命周期理論為基礎, 借鑒以往研究, 從醫療健康大數據管理者的角度出發, 以數據質量評價為目的, 重點關注醫療健康大數據從產生到利用過程中的質量, 構建了醫療健康大數據質量生命周期模型, 如圖1 所示。該模型將其生命周期劃分為數據采集、數據預處理與儲存、數據分析與使用3 個階段, 并設定評價指標對醫療健康大數據質量進行全面評價。
數據采集階段指獲取數據的過程, 從不同數據源實時或定時收集數據, 并發送給存儲系統或數據中間件系統進行后續處理。采集的醫療健康大數據包括電子病歷數據、公共衛生數據、個人健康數據、醫院運營數據等, 數據來源包括患者或用戶個人、醫療機構、醫保部門、公共衛生部門等多種主體。在該階段, 醫療健康大數據質量會受到數據源、數據采集方式和技術等因素的影響[27] 。
數據預處理與儲存階段指對上階段采集到的醫療健康大數據按照相關規范、標準進行預處理(ETL 抽取、轉換、加載)、存儲及更新, 同時采用相關措施確保數據安全存儲和訪問。采集的數據需要按照相關標準和規范經過清洗、篩選、排序等操作才能進入數據存儲系統, 對于隱私數據或敏感數據, 需要有相應的加密和脫敏措施。此外, 醫療健康大數據是時刻產生、動態變化和不斷累積的,需要對數據進行更新。在該階段, 醫療健康大數據質量會受到數據預處理技術、數據存儲和訪問方式、數據管理機制等因素的影響。
數據分析與應用階段指使用已經儲存在數據庫中的醫療健康大數據, 包括業務系統內、外的調用、查看和使用數據進行統計分析、可視化分析與預測, 并將其應用于管理決策、戰略規劃、科學研究、市場營銷等。在該階段, 醫療健康大數據質量會受到數據系統、數據分析技術、數據應用等因素的影響。
2.2 指標體系初步構建
醫療健康大數據在具備大數據“5V” 特點的基礎上, 還具有隱私性、冗余性、時效性、不完整性等特點[28-29] 。隱私性表現在電子病歷、健康檔案等大多包含患者身份信息以及如傳染病、遺傳病等較為敏感的疾病信息, 一旦發生泄露會給患者帶來嚴重影響。醫療健康大數據中非結構化數據較多, 相似文本和相似圖像的重復記錄、患者自述中的大量無關信息、疾病癥狀的多種表達方式等原因使得醫療健康數據產生重復、冗余。時效性表現在醫療健康大數據實時產生并隨時間變化, 多數疾病的發病、診治過程有時間線, 醫學檢驗結果受時間影響, 所以醫療健康大數據采集、存儲、使用的及時性也是質量的一個重要方面。不完整性主要表現在由于患者表述不完整、醫生水平有限、疾病本身復雜程度高或早期數據缺乏電子化記錄等原因導致數據在輸入時不完整[29] , 或在數據存儲過程中發生損壞、丟失。
基于現有文獻中關于數據質量評價指標體系的相關研究, 并結合醫療健康大數據的隱私性、冗余性、時效性、不完整性等特點, 本文從醫療健康大數據質量生命周期模型的3 個階段出發, 初步建立了醫療健康大數據質量評價指標體系。在數據采集階段考慮準確性、完整性、可靠性、時效性指標,在數據預處理與存儲階段考慮規范性、安全性、隱私性、一致性指標, 在數據分析與應用階段考慮流通性、可訪問性、價值性指標。
其中, 準確性、完整性、可靠性、時效性、規范性、安全性等指標多次出現在數據質量評價及管理相關文獻中, 是較為通用的數據質量評價指標[11,27] 。準確性指標指醫療健康大數據反映數據主體情況的準確程度; 針對醫療健康大數據所具備的不完整性特點, 設置完整性指標從數據規模、數據類型、數據內容三方面對醫療健康大數據質量進行評價; 可靠性指標指醫療健康大數據內容和來源的真實和可靠程度; 時效性指標指醫療健康大數據反映數據主體當前狀態以及變化情況的程度, 對應醫療健康大數據時效性強的特點; 規范性指標指醫療健康大數據格式和內容符合國家標準、區域標準的程度; 安全性指標指對醫療健康大數據的加密存儲、訪問控制、身份驗證、備份恢復等措施。
此外, 隱私性、一致性、流通性、可訪問性、價值性指標在已有文獻基礎上進一步考慮了醫療健康大數據自身特點和存儲及應用現狀。隱私性指標指對醫療健康大數據中所包含隱私信息的保護和匿名化處理[30] , 對應醫療健康大數據隱私性較強且隱私問題貫穿多個生命周期環節的特點; 由于醫療健康大數據儲存在多個單位的數據系統或第三方數據庫中, 故設置一致性指標[7] , 用以評價不同單位存儲的相同或相關數據的內容及格式的一致程度以及數據描述與數據實體的對應程度; 由于醫療機構間存在“數據孤島”、醫療信息系統建設水平不均衡, 故考慮流通性指標, 評價數據可以在不同系統或不同單位間進行共享、傳輸的程度[31-32] ; 可訪問性指標考慮了醫療健康大數據的冗余性, 指是否可以訪問、查看、下載已存儲的醫療健康大數據,以確保其是可操作、可用的[32] , 而非無用的垃圾數據; 價值性指標指醫療健康大數據能夠為機構、社會、國家等層面帶來的價值[34] 。
2.3 指標體系優化
采用專家意見法, 邀請醫療健康大數據領域的研究人員、技術人員、管理人員共9 位專家對初步構建的指標體系發表修改意見。綜合專家意見, 將具有交叉重疊的指標進行合并或剔除。將9 位專家的修改意見綜合如下: ①剔除可靠性指標, 將可靠性指標側重的數據真實可靠性合并到準確性指標;②將時效性指標修改為及時性, 主要關注醫療健康大數據記錄和更新的及時性; ③將隱私性指標合并到安全性指標, 除對醫療健康大數據的安全保障措施進行評價外, 還關注其隱私保護措施; ④將流通性指標修改為互聯互通性指標, 關注醫療健康大數據在不同系統間進行流動、傳輸、兼容的程度; ⑤將可訪問性指標修改為可用性, 指醫療健康大數據中包含有用信息并且可用于下載、查看、統計分析,并且可以進行可視化分析、實現大數據分析與應用的程度。
根據本文提出的醫療健康大數據質量生命周期模型的3 個階段并結合專家意見, 對確定的9 個評價指標進行階段劃分, 指標處于某個階段代表該指標所包含的內容在該階段需重點關注。指標說明和階段劃分如表2 所示。
本文所構建的醫療健康大數據質量評價指標體系是在已有相關研究和標準的基礎上提出的, 涵蓋了通用的數據質量評價指標。因此, 如要對一般領域的數據質量進行評價, 可在本文提出的評價指標體系的基礎上進行調整, 剔除與所評價數據相關性較低或不相關的指標, 并對指標權重進行調整, 以更加符合所評價數據的特點, 進而獲得更為科學合理的數據質量評價結果。
3 醫療健康大數據質量綜合評價模型構建
采用主、客觀相結合的方法, 使用模糊BWM和EWM 兩種方法綜合確定指標權重, 邀請專家對醫療健康大數據質量進行評價, 并將專家語言變量轉化為三角模糊數進行定量分析, 最后使用TOP?SIS 方法進行綜合排序, 構建了醫療健康大數據質量綜合評價模型。
使用以上兩種方法相結合確定指標權重具有以下幾點優勢: 首先, 模糊BWM 屬于主觀方法, 而EWM 屬于客觀方法, 兩種方法相結合可以綜合考慮專家經驗和主觀判斷以及可量化的數據信息, 減少使用單一方法存在的局限性, 得到更為全面、準確的權重結果; 其次, 模糊BWM 方法相較于傳統主觀權重確定方法如AHP, 其一致性和可靠性更強, 而EWM 方法又為權重計算結果提供了數據支持, 兩種方法結合可以增強權重計算結果的可信度; 最后, 主客觀相結合的權重計算方法可以根據不同決策場景進行調整, 以適應實際需求, 并且可以對權重結果進行解釋, 提高權重計算的靈活性和可解釋性。因此, 采用模糊BWM 和EWM 兩種方法綜合確定指標權重, 與傳統方法相比更具綜合性、可信性以及可解釋性。
3.1.1 模糊BWM 方法
2015 年, Razaei J[36-37]提出了最優最劣法(BWM,Best-worst Method), 該方法的主要步驟是專家確定最優和最劣的兩個屬性, 并將最優屬性與其他屬性、其他屬性與最劣屬性分別進行比較, 獲得兩組偏好向量, 然后建立并求解數學規劃模型獲得指標最優權重, 為了提高結果的準確性還需進行一致性檢驗。三角模糊數由Zadeh L A[38] 于1965 年為了解決不確定環境下的問題而提出, 被廣泛應用于質量管理、風險管理等領域, 通過將模糊的、不確定的語言變量轉化為三角模糊數, 可以很好的解決由于被評價對象的模糊性和復雜性所導致的只能用自然語言進行模糊評價的問題。以BWM 方法為基礎,Guo S 等[39] 將三角模糊數引入其中, 建立了模糊BWM 模型, 并通過3 個實例驗證了模糊BWM 方法的可行性和有效性。
在定性比較的過程中, 存在著模糊性和無形性。常用的權重確定方法AHP 需對比n?(n-1) / 2 次才可獲得判斷矩陣, 而BWM 方法只需要比較2n -3次, 具有較少的冗余, 減小了評價過程中的誤差,提高了結果的一致性、可靠性以及決策效率。由于用以評價醫療健康大數據質量的指標較多, 在進行指標重要程度比較的過程中存在不確定性和模糊性, 所以使用三角模糊數來代替清晰值可以獲得更符合實際情況的特點。因此, 本文使用模糊BWM方法進行指標主觀權重確定, 重要程度對比以語言變量呈現, 分別對應不同三角模糊數, 對應規則如表3 所示。該方法的主要步驟如下:
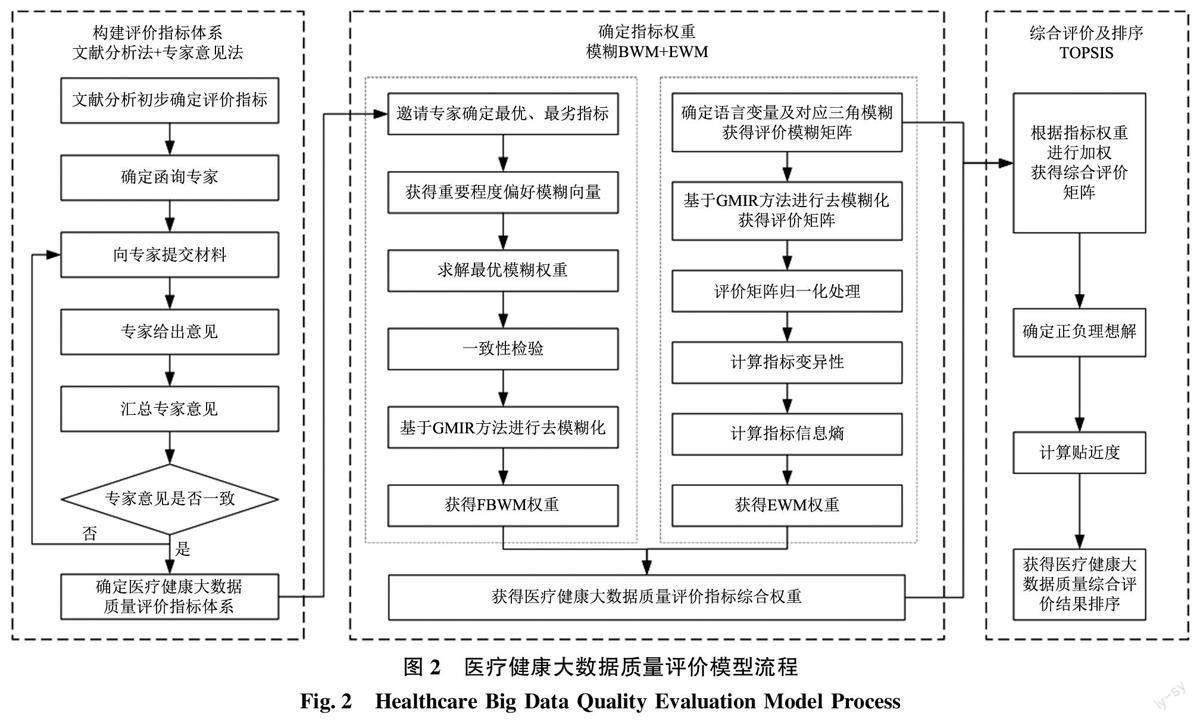
綜上, 本文采用文獻分析法和專家意見法構建醫療健康大數據質量指標體系, 使用模糊BWM 與EWM 結合確定指標權重, 最后使用TOPSIS 方法獲得醫療健康大數據質量評價結果, 構建了一個醫療健康大數據質量綜合評價模型, 模型流程如圖2所示。
4 醫療健康大數據質量評價實證研究
受醫療健康數據采集方式和數據特點的限制及影響, 當前醫療健康大數據多儲存于醫院、醫療數據相關公司各自的系統或第三方數據庫中。為了驗證本文所構建的評價指標體系和綜合評價模型的合理性及有效性, 并全面了解醫療健康大數據的質量現狀, 本文共選取了9 個醫療健康大數據存儲單位, 其中包括多家三甲醫院、知名大數據公司、醫療數據實驗室等, 應用本文構建的評價指標體系及評價模型進行實證研究。
4.1 指標權重確定
本研究邀請了9 位醫療健康大數據領域的專家對本文所構建的指標體系中的9 個指標進行重要程度偏好比較, 得到的偏好向量如表5 所示。
根據專家的偏好向量, 求解模糊BWM 模型,獲得各專家對應的指標最優模糊權重, 并通過GMIR方法進行去模糊化, 結果如表6 所示。
本文所邀請的醫療健康數據領域的9 位專家包括了多家醫院信息科(處)負責人、醫療大數據實驗室和企業負責人、醫療健康領域科技公司總經理、醫療信息化科研人員, 考慮了醫療健康大數據在醫療、商業、科研等不同產生和應用場景中的質量, 因此獲得的指標權重是較為全面的, 可以適用于不同領域的醫療健康大數據質量。如若對較為特殊的醫療健康大數據進行質量評價, 如關于某項疾病的醫療健康大數據的質量, 可以使用本文的權重確定方法邀請與評價對象相關的細分領域專家進行指標權重確定。
4.2 質量結果排序
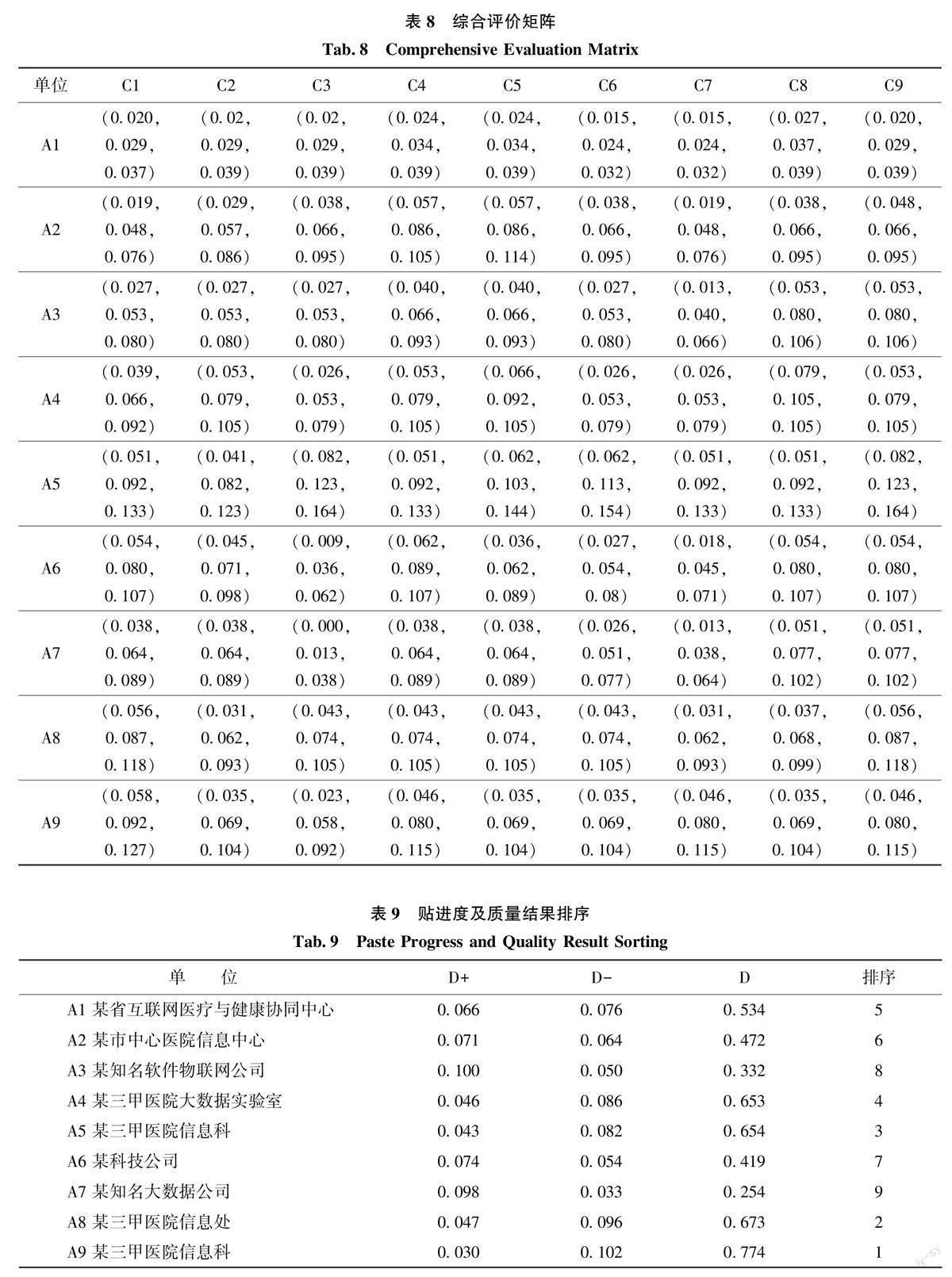
根據上節中確定的指標權重, 將專家初始評價矩陣進行加權, 獲得綜合評價矩陣如表8 所示。確定PIS、NIS 如下: PIS = [(0.027,0.037,0.039)(0.057, 0.086, 0.114 ) (0.053, 0.080, 0.106 )(0.079, 0.105, 0.105 ) ( 0.082,0.123, 0.164 )(0.054, 0.080, 0.107 ) ( 0.051, 0.077, 0.102 )(0.056, 0.087, 0.118) ( 0.058,0.092, 0.127)],PIN = [(0.015, 0.024, 0.032 ) (0.019, 0.048,0.076) (0.013, 0.040, 0.066 ) (0.026, 0.053,0.079) (0.041, 0.082, 0.123 ) (0.018, 0.045,0.071) (0.000, 0.013, 0.038 ) (0.031, 0.062,0.093)(0.023,0.058,0.092)]。計算貼進度并進行排序, 結果如表9 所示, 9 個單位醫療健康大數據質量排序為A9>A8>A5>A4>A1>A2>A6>A3>A7。通過質量結果排序發現, 醫院存儲的醫療健康大數據相較于其他機構質量較高, 且三甲醫院存儲的醫療健康大數據質量綜合排序靠前。
4.3 醫療健康大數據質量結果分析
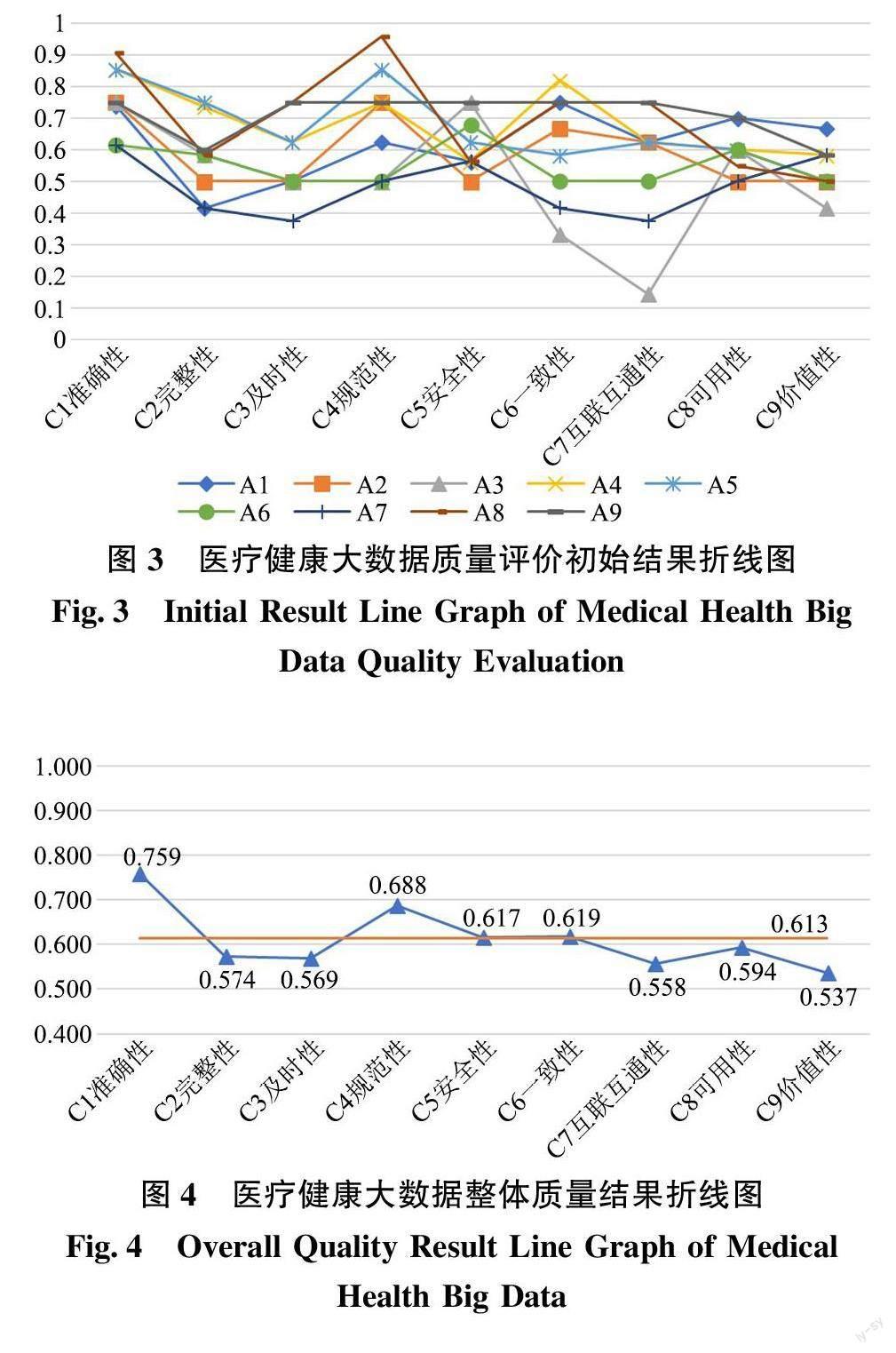
將專家評價獲得的初始模糊矩陣通過GMIR 方法進行去模糊化, 得到各個評價對象的醫療健康大數據質量在各個指標下的初始未加權評價結果如圖3 所示, 以更好地分析醫療健康大數據在各個指標下的質量。此外, 為更直觀地獲得醫療健康大數據的整體質量, 計算每個指標下9 個評價對象的得分平均值以及9 個指標得分均值, 獲得整體質量結果如圖4 所示。
據圖4 顯示, 得分相對較高的指標有準確性(C1)、規范性(C4), 均明顯高于總體均值, 得分相對較低的指標有完整性(C2)、及時性(C3)、互聯互通性(C7)、價值性(C9), 均明顯低于總體均值。
在數據采集階段, 醫療健康大數據的準確性(C1)較好, 完整性(C2)和及時性(C3)較差。醫療健康大數據多來源于醫療信息系統、公共衛生系統等, 數據來源可靠, 數據準確性較好。醫療健康大數據中包含的數據類型多且結構復雜, 受數據采集方式及能力限制, 無法涵蓋所有數據, 數據完整性較差。醫療健康數據本身具有較好的時效性[44] ,由于系統延遲、數據庫效率低、管理落后等原因,導致數據采集或更新不及時, 因此及時性較差。
在數據預處理與儲存階段, 醫療健康大數據的規范性(C4)較好, 安全性(C5)和一致性(C6)一般。醫療健康大數據在采集錄入和存儲時都要遵循相關的規范、標準, 因此規范性較好。據圖3 可得醫療健康大數據在安全性指標上得分差異較小, 在一致性指標上的得分差異較大。醫療健康大數據隱私性較強, 《數據安全保護法》等相關法律法規為各個單位在數據安全保障方面提出了硬性要求, 因此數據安全性差異較小。由于各個單位采用的數據系統不同, 信息化程度不一, 對于同種類數據的采集方法、存儲形式、更新頻率等存在差異, 因此數據的一致性一般, 并在各個單位間呈現較大差異。
在數據分析與使用階段, 互聯互通性(C7)和價值性(C9)較差, 可用性(C8)一般。醫療健康大數據分散地儲存在各個醫療機構或第三方數據庫中, 缺少統一平臺對數據進行整合, 受限于數據格式、隱私保護和權屬劃分等原因, 在數據整合和共享等方面存在困難, 互聯互通性較差, 并且在不同單位之間存在較大差異。醫療健康大數據中所含信息的有用性已經得到了廣泛認可, 但受限于數據權屬、隱私安全以及大數據利用能力, 醫療健康大數據的可用性一般。目前, 基于醫療健康大數據進行的醫療決策占比較小, 公眾對于醫療健康大數據缺乏清晰認知[18] , 其應用尚處于落地實踐初始階段,價值挖掘仍不夠深入, 價值性較差。
本研究中選取的評價對象涉及了醫院、實驗室、企業等多類型的醫療健康大數據儲存單位, 通過對其所存儲的醫療健康大數據的質量從3 個階段、9個指標出發做出綜合評價, 較為全面地揭示了醫療健康大數據質量的現狀。從整體來看, 我國醫療健康大數據質量水平一般, 在完整性、及時性、互聯互通性、價值性上仍有待提高。
5 結論與展望
本文從數據生命周期視角出發, 構建了醫療健康大數據質量評價指標體系和綜合評價模型, 為醫療健康大數據質量問題發現和數據質量提升提供了指導。首先, 建立了醫療健康大數據質量生命周期模型, 參考國內外文獻、結合醫療健康大數據特點構建指標體系并進行優化, 采用模糊BWM 法和EWM 綜合確定指標權重, 形成了完善、科學的指標體系。其次, 使用專家語言評價結合三角模糊數將定性評價轉化為定量評價, 并使用TOPSIS 方法進行綜合排序, 構建了一個綜合評價模型。最后,應用本文構建的指標體系和綜合評價模型, 獲得了醫療健康大數據質量現狀, 發現其完整性、及時性、互聯互通性、價值性還需進一步提升。為了促進醫療健康大數據的質量提升和深入開發應用, 本文提出如下建議:
1) 加強數據采集階段的質量控制, 從源頭上提高醫療健康大數據質量。要從技術上優化數據采集系統, 提高數據采集的完整性, 改進數據收集傳輸流程, 減少數據延遲和滯后。要制定數據采集和錄入的標準和流程, 加強對數據采集范圍和內容的把控, 減少低質量數據進入數據庫, 同時減輕數據庫的儲存壓力。建立數據質量檢測和反饋機制, 對醫療健康數據進行定期檢查和評估, 同時設定激勵機制, 鼓勵醫療機構、個人等數據主體更好地記錄和報告數據, 減少數據遺漏或丟失。
2) 進一步推動醫療健康大數據多平臺協同建設, 提升醫療健康大數據的互聯互通性。要推進醫療健康大數據國內、國際標準和規范的統一, 建立統一的數據接口和數據交換平臺, 促進醫療健康大數據跨單位、跨平臺互聯互通和數據整合, 打破數據孤島, 形成成熟完善的應用體系。要持續加強醫療健康大數據平臺監管、細化隱私保護粒度, 保障醫療健康大數據互聯互通過程中的安全性和隱私保護。要建立健全數據治理機制, 完善數據共享機制和協議, 提升醫療健康大數據的流通和應用水平。
3) 深入挖掘醫療健康大數據價值, 提升醫療健康大數據的利用水平。要加強醫療健康大數據分析人才培養, 通過可實現、可落地的應用提高數據利用率, 充分挖掘醫療健康大數據的價值, 增強醫療健康大數據的活性。要積極推廣醫療健康大數據的重大價值和重要作用, 形成價值認同, 為醫療健康大數據深入應用發展打下堅實基礎。要繼續推進醫療健康大數據中心及產業園建設, 充分利用已建成的數據中心及平臺, 推動醫療機構、企業、高校等元多主體協同參與, 營造良好的產業環境。
本文還存在一些局限: 本研究的評價視角為數據生命周期視角, 后續應當從多視角出發, 獲得對醫療健康大數據質量更為全面、客觀、真實的評價。此外, 受限于醫療健康數據的復雜性, 目前尚無法直接對評價指標進行量化, 后續研究中應當尋求合適的醫療健康大數據質量評價指標量化方法。良好的數據質量是實現醫療健康大數據更深層次應用的重要前提, 后續可以從醫療健康大數據共享、資產管理、再利用等多個方面進行醫療健康大數據治理的相關研究, 促進醫療健康大數據的價值實現與增值。
