視頻流環(huán)境下基于深度學(xué)習(xí)的動(dòng)作識(shí)別
2024-01-31 13:23:26嚴(yán)倩倩
電子制作 2024年2期
嚴(yán)倩倩
(西安職業(yè)技術(shù)學(xué)院,陜西西安,710077)
0 引言
近些年來,神經(jīng)網(wǎng)絡(luò)在圖像分類領(lǐng)域取得了不凡的成績,并隨著研究的深入提出了很多新的網(wǎng)絡(luò)模型,比如雙流網(wǎng)絡(luò)、卷積神經(jīng)網(wǎng)絡(luò)CNN[1](Convolutional Neural Network)、循環(huán)神經(jīng)網(wǎng)絡(luò)RNN[2](Recurrent Neural Network)等。
雙流網(wǎng)絡(luò)由光流網(wǎng)絡(luò)和RGB 網(wǎng)絡(luò)并行組成,需要同時(shí)處理圖像序列和光流圖像,對(duì)計(jì)算資源要求較高,且兩個(gè)網(wǎng)絡(luò)的融合方式和策略的不同也會(huì)對(duì)性能產(chǎn)生較大的影響。CNN 分為2D CNN 和3D CNN,2D CNN 經(jīng)常被用于處理和分析二維數(shù)據(jù)(比如圖像),只能提取空間特征;3D CNN可以同時(shí)提取時(shí)空特征,但是訓(xùn)練模型時(shí)需要更多的計(jì)算資源和更大的數(shù)據(jù)集,會(huì)出現(xiàn)計(jì)算復(fù)雜度高、內(nèi)存消耗大等問題,并且隨著網(wǎng)絡(luò)層數(shù)的增加會(huì)出現(xiàn)梯度消失和梯度爆炸問題。殘差網(wǎng)絡(luò)ResNet[3](Residual Network,ResNet)是一種特殊類型的卷積網(wǎng)絡(luò),允許信息在網(wǎng)絡(luò)中容易地進(jìn)行流動(dòng),有助于解決層數(shù)增加而網(wǎng)絡(luò)性能越差的問題。
RNN 引入循環(huán)結(jié)構(gòu)來對(duì)序列中先前的信息進(jìn)行建模,用于處理序列數(shù)據(jù),但是在處理長序列時(shí)可能會(huì)遇到梯度消失或爆炸問題,為了解決傳統(tǒng)的RNN 問題,引入門控機(jī)制來控制信息的流動(dòng)和遺忘,代表模型有長短期記憶網(wǎng)絡(luò)LSTM(Long-Short Term Memory)和門控循環(huán)單元GRU[4](Gated Recurrent Unit),而GRU 較少的門控?cái)?shù)量使得它在某些情況下對(duì)于處理較短序列的任務(wù)來說是一個(gè)更輕量級(jí)的選擇。
視頻流環(huán)境下的動(dòng)作識(shí)別是目前各位學(xué)者的重要研究方向,其識(shí)別包括時(shí)空兩個(gè)維度的特征提取[5],使用單一網(wǎng)絡(luò)很難取得良好的識(shí)別效果,因此很多學(xué)者會(huì)融合多個(gè)模型的特點(diǎn)提出新的網(wǎng)絡(luò)模型。為了解決傳統(tǒng)網(wǎng)絡(luò)模型層數(shù)增加,網(wǎng)絡(luò)性能更差的問題,以及更好地獲取到視頻之間的上下文信息,本文提出了一種基于殘差網(wǎng)絡(luò)(Residual Network,ResNet)與GRU 的動(dòng)作識(shí)別模型G-ResNet。
1 時(shí)空特征提取
■1.1 空域特征提取ResNet
2015 年Kaiming He 等人在論文《Deep Residual Learning for Image Recognition》中提出殘差網(wǎng)絡(luò)ResNet,其通過引入殘差塊和跳躍連接,解決了深度神經(jīng)網(wǎng)絡(luò)退化的問題。殘差網(wǎng)絡(luò)的基本結(jié)構(gòu)如圖1 所示。
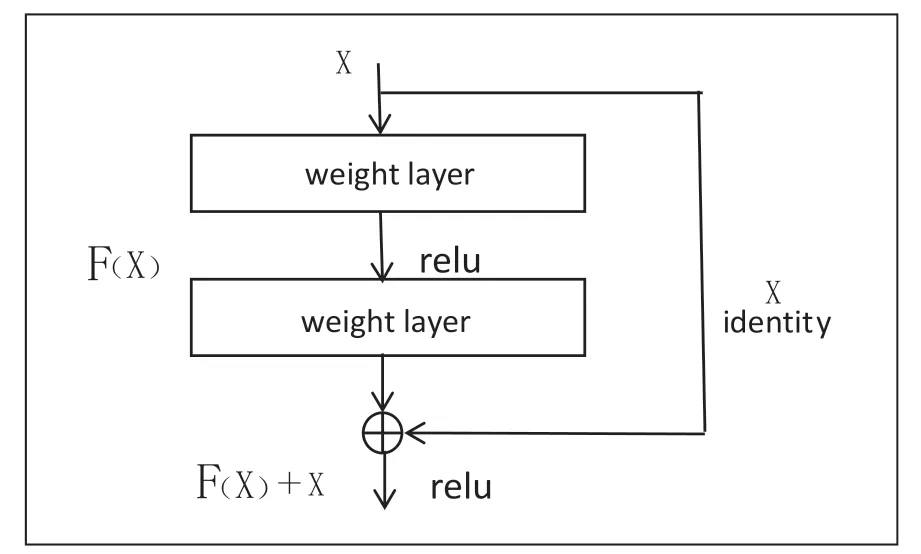
圖1 殘差結(jié)構(gòu)
從圖1 中可以看出相比于之前增加了一個(gè)恒等映射,這樣便很好的解決了由于網(wǎng)絡(luò)層數(shù)的增加而帶來的網(wǎng)絡(luò)梯度不明顯的復(fù)雜問題,因此殘差網(wǎng)絡(luò)可以把網(wǎng)絡(luò)層數(shù)做的很深。到目前為止網(wǎng)絡(luò)的層數(shù)可以達(dá)到上千層,同時(shí)又能保證很好的訓(xùn)練效果;并且簡單的層數(shù)疊加也并未給整個(gè)網(wǎng)絡(luò)的訓(xùn)練增加額外的參數(shù),與此同時(shí)也提高了網(wǎng)絡(luò)訓(xùn)練的效果與處理數(shù)據(jù)的效率。本文進(jìn)行空間維度特征提取的網(wǎng)絡(luò)是ResNet 34,該網(wǎng)絡(luò)的具體參數(shù)如表1 所示。
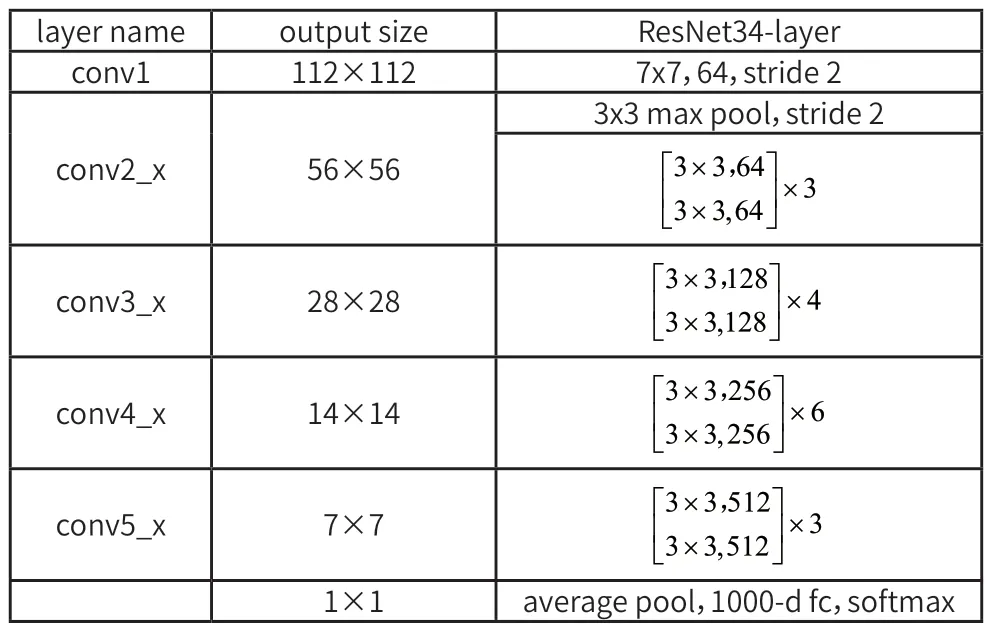
表1 ResNet34網(wǎng)絡(luò)結(jié)構(gòu)參數(shù)表
■1.2 時(shí)域特征提取GRU
2014 年Cho 等人在論文《Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling》中提出GRU,其能夠建立視頻序列間的依賴關(guān)系,在時(shí)間序列問題方面表現(xiàn)良好。本文使用GRU 進(jìn)行時(shí)序特征的提取,該網(wǎng)絡(luò)主要包括兩個(gè)門模塊,更新門決定了過去時(shí)刻的隱藏狀態(tài)對(duì)當(dāng)前時(shí)刻的影響,重置門決定了過去時(shí)刻的隱藏狀態(tài)在當(dāng)前時(shí)刻所需的重置程度。GRU 的結(jié)構(gòu)圖如圖2 所示。
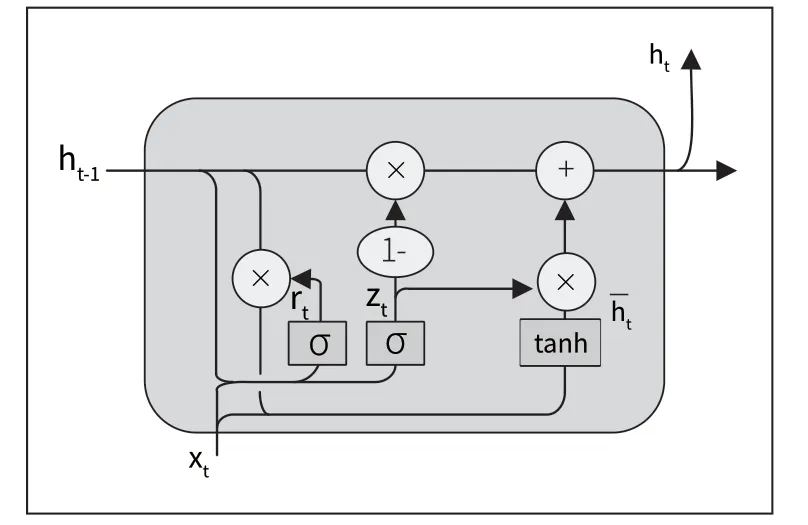
圖2 GRU 門控循環(huán)單元結(jié)構(gòu)
在圖2 中,zt代表更新門,rt代表重置門。其中zt的取值范圍是0 到1,值越接近于0 說明越依賴于過去的隱藏狀態(tài),而忽略當(dāng)前的信息;值越接近于1 說明會(huì)更多的利用當(dāng)前的輸入信息來更新隱藏狀態(tài)。rt的取值范圍是0 到1,值越接近0 說明過去的信息越傾向于被丟棄;值越接近于1 說明越傾向于保留更多的過去信息。根據(jù)圖2 的GRU 單元結(jié)構(gòu)圖,則前向傳播公式為:
在上述的公式中,[ ]表示兩個(gè)向量相乘,*表示矩陣的乘積。
GRU 網(wǎng)絡(luò)的分類模型如圖3 所示。
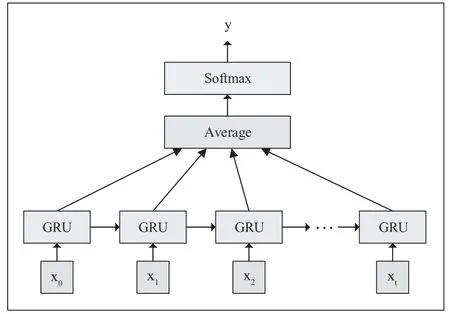
圖3 GRU 分類模型
在圖3 中,x1、x2...為輸入層,即特征向量,使用GRU進(jìn)行特征提取,對(duì)提取到的特征進(jìn)行加權(quán)操作,然后對(duì)加權(quán)之后的特征進(jìn)行全連接操作,最終得到分類預(yù)測結(jié)果。
2 網(wǎng)絡(luò)模型G-ResNet
■2.1 模型設(shè)計(jì)
本文的G-ResNet 網(wǎng)絡(luò)模型包含兩大基本構(gòu)成:圖像的空間特征提取模塊、幀之間的時(shí)序信息提取模塊。視頻動(dòng)作識(shí)別算法整體框架如圖4 所示,首先進(jìn)行視頻幀提取,對(duì)進(jìn)行圖像預(yù)處理,然后利用深度殘差網(wǎng)絡(luò)ResNet34 提取深層空間特征,GRU 網(wǎng)絡(luò)獲取視頻的時(shí)序信息,對(duì)G-ResNet 模型進(jìn)行訓(xùn)練,最后使用訓(xùn)練好的模型完成視頻流的動(dòng)作識(shí)別。
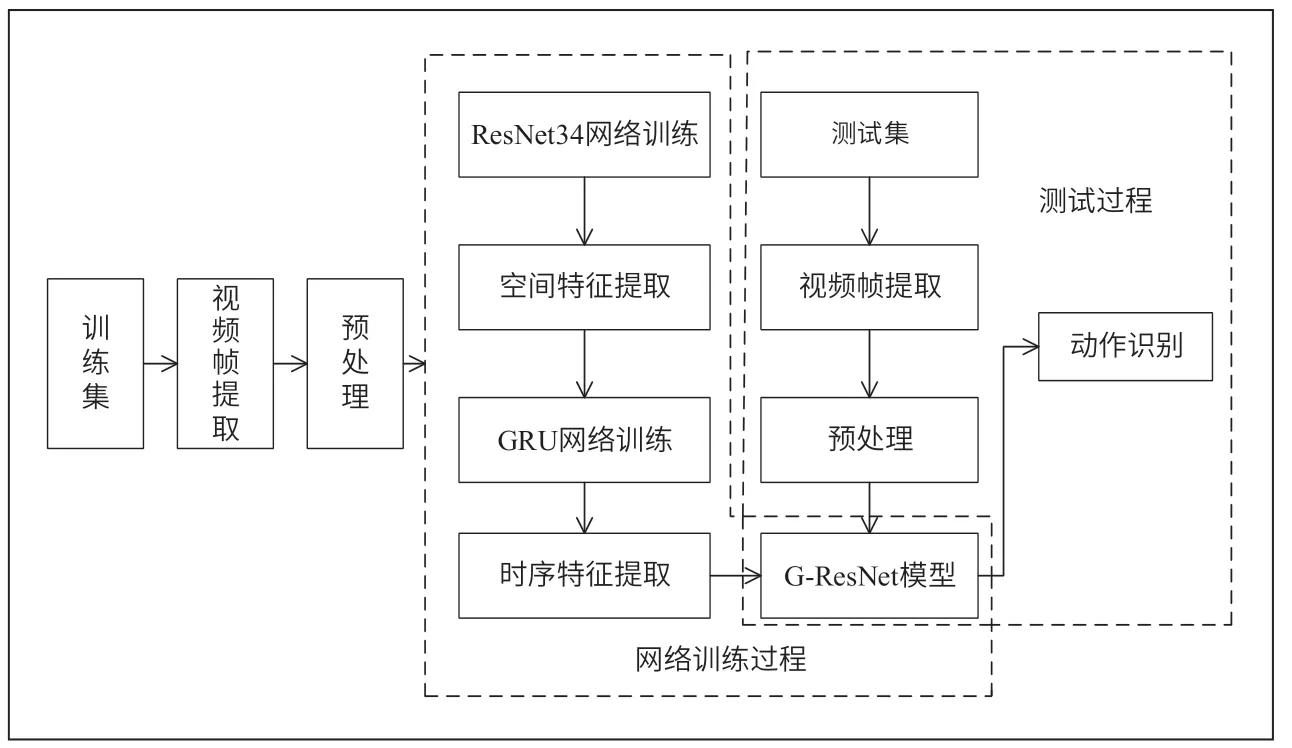
圖4 基于G-ResNet 網(wǎng)絡(luò)的動(dòng)作識(shí)別算法框架
對(duì)于視頻流中動(dòng)作的識(shí)別,本文采用ResNet34 與GRU 結(jié)合的方式進(jìn)行,首先將圖像視頻輸入到ResNet34中提取空間維度特征;然后將提取到的特征輸入到GRU 中,用于時(shí)序信息的提取建模;接著對(duì)提取到的特征進(jìn)行加權(quán)操作,將加權(quán)之后的特征進(jìn)行全連接操作,最終得到分類預(yù)測結(jié)果。建立的G-ResNet 網(wǎng)絡(luò)模型如圖5 所示。
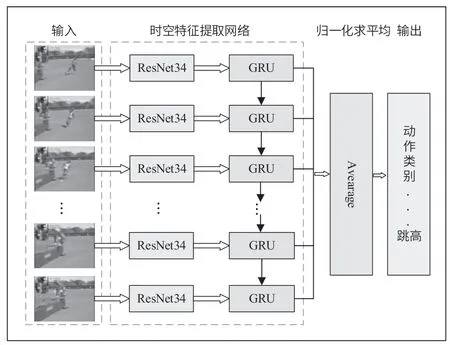
圖5 G-ResNet 網(wǎng)絡(luò)模型結(jié)構(gòu)
■2.2 模型訓(xùn)練損失函數(shù)
損失函數(shù)CrossEntropy(交叉熵?fù)p失函數(shù))在計(jì)算損失時(shí)會(huì)將預(yù)測值和真實(shí)值直接比較,要求預(yù)測值必須無限接近真實(shí)標(biāo)簽的one-hot 編碼形式,然而one-hot 編碼會(huì)導(dǎo)致網(wǎng)絡(luò)評(píng)估時(shí)對(duì)于類別的預(yù)測非常自信,忽略其他類別的可能性,會(huì)使得模型對(duì)于噪聲或者異常樣本過度敏感;而SmoothCrossEntropy(標(biāo)簽平滑交叉熵?fù)p失函數(shù))通過對(duì)標(biāo)簽平滑來緩解這種情況,它將one-hot 編碼轉(zhuǎn)化為概率分布,這樣每個(gè)類別不再是非此即彼,可以取到介于0 到1 之間的值,這樣的操作可以增加模型對(duì)于不確定性的魯棒性、減少過擬合、提升分類性能。因此在第三次訓(xùn)練時(shí)將損失函數(shù)CrossEntropy 轉(zhuǎn)換成SmoothCrossEntropy,目的是讓預(yù)測值向真實(shí)結(jié)果靠攏。
對(duì)多分類問題一般采用Softmax 方法。首先將數(shù)據(jù)(即視頻圖像)輸入到架構(gòu)好的網(wǎng)絡(luò)模型中提取特征,計(jì)算出輸入數(shù)據(jù)所屬類別的置信度范圍,然后使用激活函數(shù)Softmax 將輸出轉(zhuǎn)化為概率分布,即對(duì)應(yīng)各個(gè)類別的概率值,如式(6):
式(6)使用交叉熵函數(shù)來計(jì)算損失值,其中i表示多類中的某一類,公式為式(7)、式(8):
最后,對(duì)預(yù)估的概率和分類所屬真實(shí)概率的交叉熵進(jìn)行最小化操作,得出最優(yōu)估計(jì)概率的分布,公式如式(9):
在訓(xùn)練過程中,模型會(huì)趨向于正確和錯(cuò)誤分類相差較大的范圍。當(dāng)樣本數(shù)據(jù)較少時(shí)就會(huì)出現(xiàn)過擬合現(xiàn)象,而Label Smoothing(標(biāo)簽平滑)通過引入噪聲、將標(biāo)簽轉(zhuǎn)化為概率分布形式等操作,達(dá)到減少過擬合、緩解標(biāo)簽不確定性的目標(biāo),變換過程如式(10):
其中K表示多分類的類別總數(shù),ε是一個(gè)較小的超參數(shù)。
與之對(duì)應(yīng),將交叉熵?fù)p失函數(shù)作如式(11)的改變:
同理,將最優(yōu)的預(yù)測概率分布作如式(12)的改變:
代表任意的實(shí)數(shù),最后是經(jīng)過弱化正、負(fù)訓(xùn)練數(shù)據(jù)輸出之間的一個(gè)范圍差,使模型的泛化效果更強(qiáng)、性能更穩(wěn)定。
3 實(shí)驗(yàn)與分析
實(shí)驗(yàn)環(huán)境:Intel(R) Core(TM) i7-11390H CPU @3.40GHz的PC 機(jī),Windows11 64 位操作系統(tǒng),通過xshell 和xftp遠(yuǎn)程連接服務(wù)器基于Ubutun 系統(tǒng),OpenCV 版本4.2.0,采用Pytorch 框架,Python 開發(fā)語言編程實(shí)現(xiàn)。使用兩個(gè)公開的數(shù)據(jù)集UCF101、HMDB51 驗(yàn)證G-ResNet 網(wǎng)絡(luò)模型的識(shí)別效果。
■3.1 視頻數(shù)據(jù)預(yù)處理
(1)圖像插值化處理
數(shù)據(jù)清洗、特征轉(zhuǎn)換、簡單縮放等操作都是數(shù)據(jù)預(yù)處理的常用方法,其中數(shù)據(jù)清洗用于去除噪聲、處理缺失值等,確保數(shù)據(jù)的完整性和一致性;特征轉(zhuǎn)換是通過數(shù)學(xué)變換將原始特征轉(zhuǎn)換為更具有可分性或表示能力的新特征;簡單縮放用于將數(shù)值型特征的取值范圍縮放到一個(gè)較小的區(qū)間內(nèi)。對(duì)于單一動(dòng)作數(shù)據(jù)而言,其是一組包含時(shí)序信息的圖像,且每個(gè)動(dòng)作持續(xù)的時(shí)間也是不一致的,為了方便計(jì)算提高效率,需要對(duì)圖像隊(duì)列做插值化處理進(jìn)行縮放,最終選擇縮放到16 張。
(2)數(shù)據(jù)增強(qiáng)
數(shù)據(jù)增強(qiáng)技術(shù)是通過對(duì)原始訓(xùn)練數(shù)據(jù)進(jìn)行變換和處理,生成新的訓(xùn)練樣本來擴(kuò)充數(shù)據(jù)集的方法。在網(wǎng)絡(luò)訓(xùn)練過程中,為了使模型具有更好的魯棒性、泛化能力和對(duì)不同場景的適應(yīng)能力,需要對(duì)數(shù)據(jù)進(jìn)行增強(qiáng)。常用的數(shù)據(jù)增強(qiáng)技術(shù)包括平移、旋轉(zhuǎn)、縮放、剪切、增加噪聲、彈性變形等,本文對(duì)數(shù)據(jù)增強(qiáng)的具體操作如下:
①圖像顏色的增強(qiáng),包括飽和度、亮度、對(duì)比度等。
②圖像大小的剪切,偏移中心點(diǎn),并裁剪出固定大小的區(qū)域圖像。
■3.2 網(wǎng)絡(luò)訓(xùn)練策略
G-ResNet 網(wǎng)絡(luò)模型使用三次訓(xùn)練優(yōu)化,以達(dá)到最優(yōu)效果,具體網(wǎng)絡(luò)訓(xùn)練策略如圖6 所示。
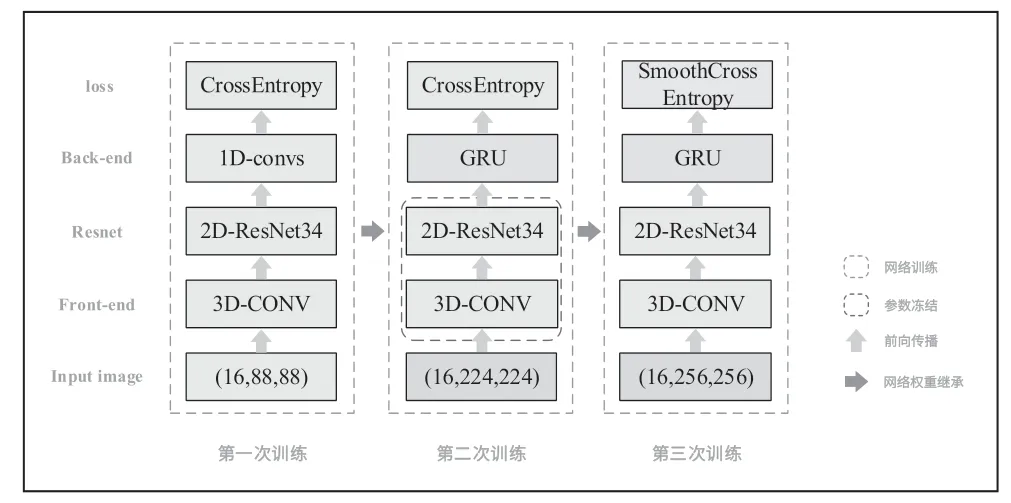
圖6 網(wǎng)絡(luò)訓(xùn)練策略原理
(1)第一次訓(xùn)練時(shí),輸入16 張連續(xù)的圖像,并將圖像縮放至88×88,目的是得到較大的Batch Size,加快模型訓(xùn)練速度,降低訓(xùn)練過程中的噪聲影響。接下來對(duì)16 張圖像使用3D-CONV 進(jìn)行特征預(yù)提取,輸入尺寸為(Batch Size,16,88,88),卷積后尺寸為(Batch Size,16×64,44,44),變形為(Batch Size×16,64,44,44),把temestep 維合并到batchsize 維,目的是使用2D-ResNet34進(jìn)行二維卷積,timestep 維數(shù)據(jù)則保留到GRU 模塊再處理。
(2)第一次訓(xùn)練完成后,將得到的權(quán)重值初始化第二次訓(xùn)練的模型。與第一次訓(xùn)練模型不同,將Back-end 模塊的1D-conv 替換成GRU,輸入圖像尺寸為(224×224),以便學(xué)習(xí)到更多的特征信息,同時(shí)固定紅框內(nèi)的模塊參數(shù)。
(3)使用第二次訓(xùn)練得到的權(quán)重來初始化第三次訓(xùn)練的模型,與第二次訓(xùn)練模型不同,將Loss 模塊的損失函數(shù)CrossEntropy 替換成SmoothCrossEntropy,輸入圖像尺寸為(256×256),以便學(xué)習(xí)到更加細(xì)微的特征信息。
第三次訓(xùn)練完成后,即可得到G-ResNet 模型。
■3.3 實(shí)驗(yàn)結(jié)果與分析
針對(duì)G-ResNet 模型的訓(xùn)練,本文將數(shù)據(jù)集UCF101 和HMDB51 以9:1 的比例劃分為訓(xùn)練集和測試集分別進(jìn)行訓(xùn)練、測試,訓(xùn)練過程的損失值和識(shí)別準(zhǔn)確率變化如圖7、圖8 所示。
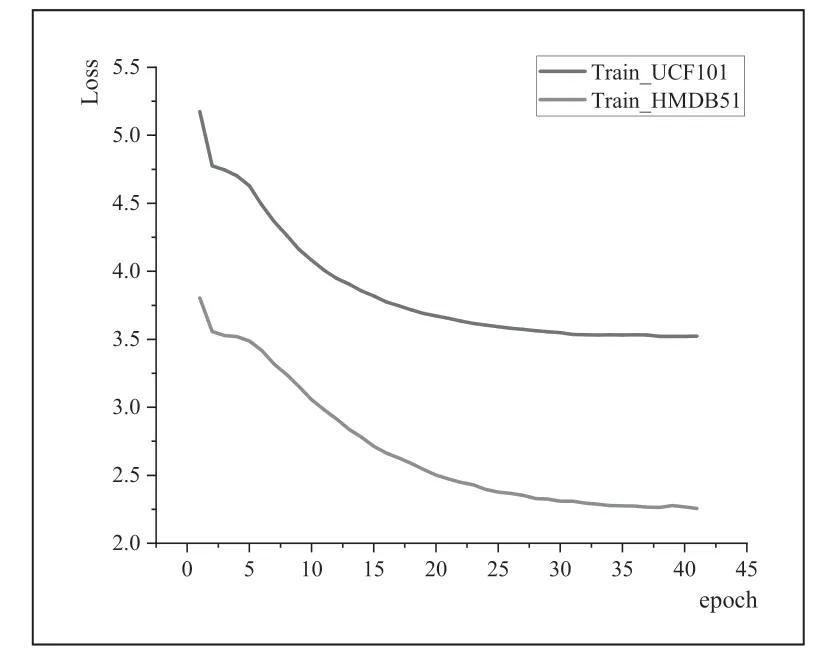
圖7 UCF101 和HMDB51 數(shù)據(jù)集變化損失
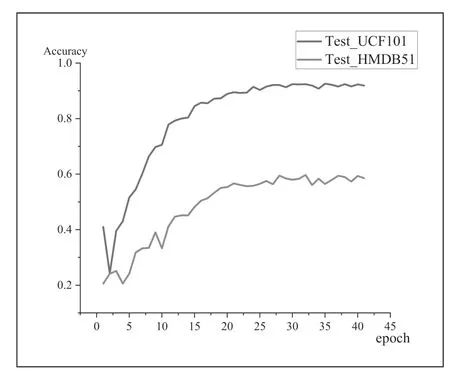
圖8 UCF101 和HMDB51 測試集準(zhǔn)確率變化曲線
圖7 為G-ResNet 模型在UCF101 和HMDB51 在 訓(xùn)練過程中的損失值變化,從圖中可以看出,隨著訓(xùn)練輪次的增加,損失值不斷減小,最終趨于平穩(wěn),說明網(wǎng)絡(luò)模型已經(jīng)接近了最優(yōu)解,即分類結(jié)果逐漸趨于正確。圖8 為G-ResNet模型在訓(xùn)練過程中的準(zhǔn)確率變化,從圖中可以看出,隨著訓(xùn)練輪次的增加,準(zhǔn)確率逐漸增加,最終趨于平穩(wěn),說明網(wǎng)絡(luò)模型已經(jīng)達(dá)到相對(duì)穩(wěn)定的性能水平。
為了更加直觀的看到G-ResNet 模型性能上的優(yōu)勢(shì),本文將C3D[6]、Veep deep two stream[7]、LRCN[8]、P3D[9]、ST-ResNet[10]等模型在UCF101 和HMDB51 數(shù)據(jù)集上進(jìn)行測試,并與G-ResNet 模型進(jìn)行對(duì)比,各模型識(shí)別的準(zhǔn)確率如表2 所示。
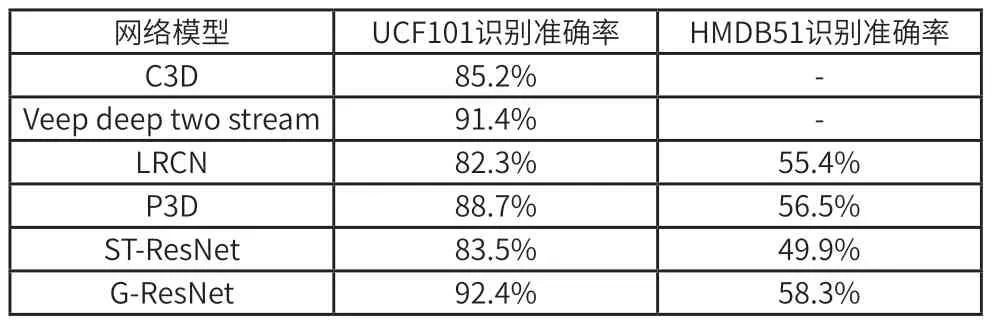
表2 人體動(dòng)作識(shí)別準(zhǔn)確率對(duì)比
從表2 可以看出,G-ResNet 模型在UCF101 和HMDB51數(shù)據(jù)集上的識(shí)別準(zhǔn)確率明顯高于其他網(wǎng)絡(luò)模型,說明基于深度殘差網(wǎng)絡(luò)與門控循環(huán)神經(jīng)網(wǎng)絡(luò)的G-ResNet 能夠很好的應(yīng)用于視頻領(lǐng)域的動(dòng)作識(shí)別。
4 總結(jié)
本文提出了一種基于視頻流的人體動(dòng)作識(shí)別的網(wǎng)絡(luò)模型G-ResNet,該模型使用深度殘差網(wǎng)絡(luò)ResNet34 提取空間域特征信息,使用循環(huán)神經(jīng)網(wǎng)絡(luò)GRU 提取時(shí)間域信息進(jìn)行建模。實(shí)驗(yàn)結(jié)果表明,G-ResNet 模型在一定程度上提高了識(shí)別準(zhǔn)確率,但是該方式的對(duì)輸入圖像進(jìn)行了一系列的裁剪、拉伸操作,改變長寬的比例,可能會(huì)導(dǎo)致某些特征不被注意到。在后期的研究中,可以探尋如何在輸入任意尺寸圖像,或者即使修改了圖像的大小,也能提取足夠多的特征,提高識(shí)別準(zhǔn)確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
